
graph-llm-asynchow-plan
Code and dataset repo for ICML-2024 paper Graph-enhanced Large Language Models in Asynchronous Plan Reasoning.
Stars: 60
Graph-enhanced Large Language Models in Asynchronous Plan Reasoning is a repository containing code and datasets for the ICML-2024 paper. It includes naturalistic datasets, code for generating data, benchmarking experiments, and prototypical experiments. The repository also offers a train/test-split version of the dataset on huggingface. The paper focuses on utilizing large language models with graph enhancements for asynchronous plan reasoning.
README:
Code and dataset repo for ICML-2024 paper Graph-enhanced Large Language Models in Asynchronous Plan Reasoning.
Naturalistic datasets used in the paper is in the folder data
You can use the code to generate naturalistic data in folder data_gen
The code for the benchmarking experiment is in folder benchmark_llm
The code and data for prototypical experiment can be found in prototypical
You can also see a quick preview of our recent train/test-split version of this dataset on huggingface.
If you find this repo useful, please cite our paper as
@inproceedings{lingraph,
title={Graph-enhanced Large Language Models in Asynchronous Plan Reasoning},
author={Lin, Fangru and La Malfa, Emanuele and Hofmann, Valentin and Yang, Elle Michelle and Cohn, Anthony G and Pierrehumbert, Janet B},
booktitle={Forty-first International Conference on Machine Learning}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for graph-llm-asynchow-plan
Similar Open Source Tools
graph-llm-asynchow-plan
Graph-enhanced Large Language Models in Asynchronous Plan Reasoning is a repository containing code and datasets for the ICML-2024 paper. It includes naturalistic datasets, code for generating data, benchmarking experiments, and prototypical experiments. The repository also offers a train/test-split version of the dataset on huggingface. The paper focuses on utilizing large language models with graph enhancements for asynchronous plan reasoning.
suql
SUQL (Structured and Unstructured Query Language) is a tool that augments SQL with free text primitives for building chatbots that can interact with relational data sources containing both structured and unstructured information. It seamlessly integrates retrieval models, large language models (LLMs), and traditional SQL to provide a clean interface for hybrid data access. SUQL supports optimizations to minimize expensive LLM calls, scalability to large databases with PostgreSQL, and general SQL operations like JOINs and GROUP BYs.

xlstm-jax
The xLSTM-jax repository contains code for training and evaluating the xLSTM model on language modeling using JAX. xLSTM is a Recurrent Neural Network architecture that improves upon the original LSTM through Exponential Gating, normalization, stabilization techniques, and a Matrix Memory. It is optimized for large-scale distributed systems with performant triton kernels for faster training and inference.

aitlas
The AiTLAS toolbox (Artificial Intelligence Toolbox for Earth Observation) includes state-of-the-art machine learning methods for exploratory and predictive analysis of satellite imagery as well as a repository of AI-ready Earth Observation (EO) datasets. It can be easily applied for a variety of Earth Observation tasks, such as land use and cover classification, crop type prediction, localization of specific objects (semantic segmentation), etc. The main goal of AiTLAS is to facilitate better usability and adoption of novel AI methods (and models) by EO experts, while offering easy access and standardized format of EO datasets to AI experts which allows benchmarking of various existing and novel AI methods tailored for EO data.

Main
This repository contains material related to the new book _Synthetic Data and Generative AI_ by the author, including code for NoGAN, DeepResampling, and NoGAN_Hellinger. NoGAN is a tabular data synthesizer that outperforms GenAI methods in terms of speed and results, utilizing state-of-the-art quality metrics. DeepResampling is a fast NoGAN based on resampling and Bayesian Models with hyperparameter auto-tuning. NoGAN_Hellinger combines NoGAN and DeepResampling with the Hellinger model evaluation metric.
Graph-CoT
This repository contains the source code and datasets for Graph Chain-of-Thought: Augmenting Large Language Models by Reasoning on Graphs accepted to ACL 2024. It proposes a framework called Graph Chain-of-thought (Graph-CoT) to enable Language Models to traverse graphs step-by-step for reasoning, interaction, and execution. The motivation is to alleviate hallucination issues in Language Models by augmenting them with structured knowledge sources represented as graphs.
ai-algorithms
This repository is a work in progress that contains first-principle implementations of groundbreaking AI algorithms using various deep learning frameworks. Each implementation is accompanied by supporting research papers, aiming to provide comprehensive educational resources for understanding and implementing foundational AI algorithms from scratch.

ManipVQA
ManipVQA is a framework that enhances Multimodal Large Language Models (MLLMs) with manipulation-centric knowledge through a Visual Question-Answering (VQA) format. It addresses the deficiency of conventional MLLMs in understanding affordances and physical concepts crucial for manipulation tasks. By infusing robotics-specific knowledge, including tool detection, affordance recognition, and physical concept comprehension, ManipVQA improves the performance of robots in manipulation tasks. The framework involves fine-tuning MLLMs with a curated dataset of interactive objects, enabling robots to understand and execute natural language instructions more effectively.
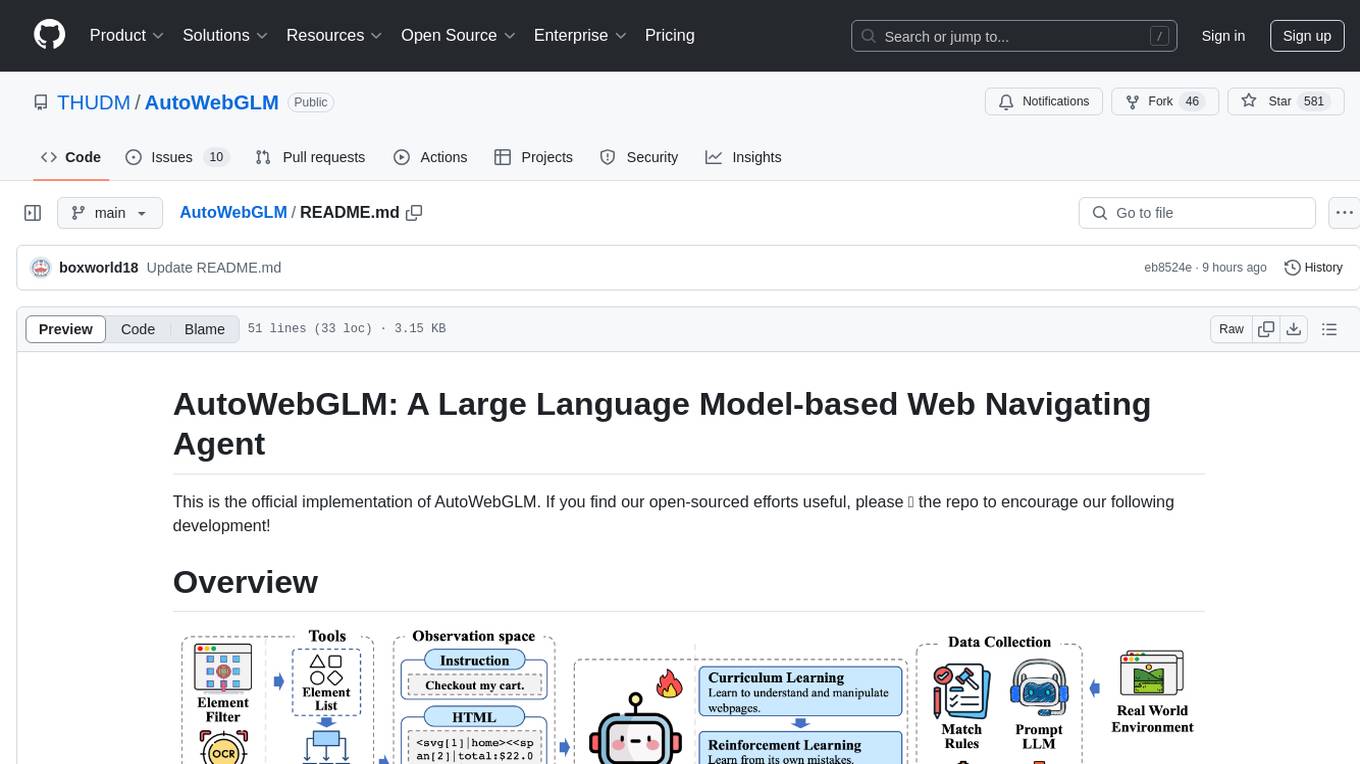
AutoWebGLM
AutoWebGLM is a project focused on developing a language model-driven automated web navigation agent. It extends the capabilities of the ChatGLM3-6B model to navigate the web more efficiently and address real-world browsing challenges. The project includes features such as an HTML simplification algorithm, hybrid human-AI training, reinforcement learning, rejection sampling, and a bilingual web navigation benchmark for testing AI web navigation agents.

Me-LLaMA
Me LLaMA introduces a suite of open-source medical Large Language Models (LLMs), including Me LLaMA 13B/70B and their chat-enhanced versions. Developed through innovative continual pre-training and instruction tuning, these models leverage a vast medical corpus comprising PubMed papers, medical guidelines, and general domain data. Me LLaMA sets new benchmarks on medical reasoning tasks, making it a significant asset for medical NLP applications and research. The models are intended for computational linguistics and medical research, not for clinical decision-making without validation and regulatory approval.

RAGFoundry
RAG Foundry is a library designed to enhance Large Language Models (LLMs) by fine-tuning models on RAG-augmented datasets. It helps create training data, train models using parameter-efficient finetuning (PEFT), and measure performance using RAG-specific metrics. The library is modular, customizable using configuration files, and facilitates prototyping with various RAG settings and configurations for tasks like data processing, retrieval, training, inference, and evaluation.
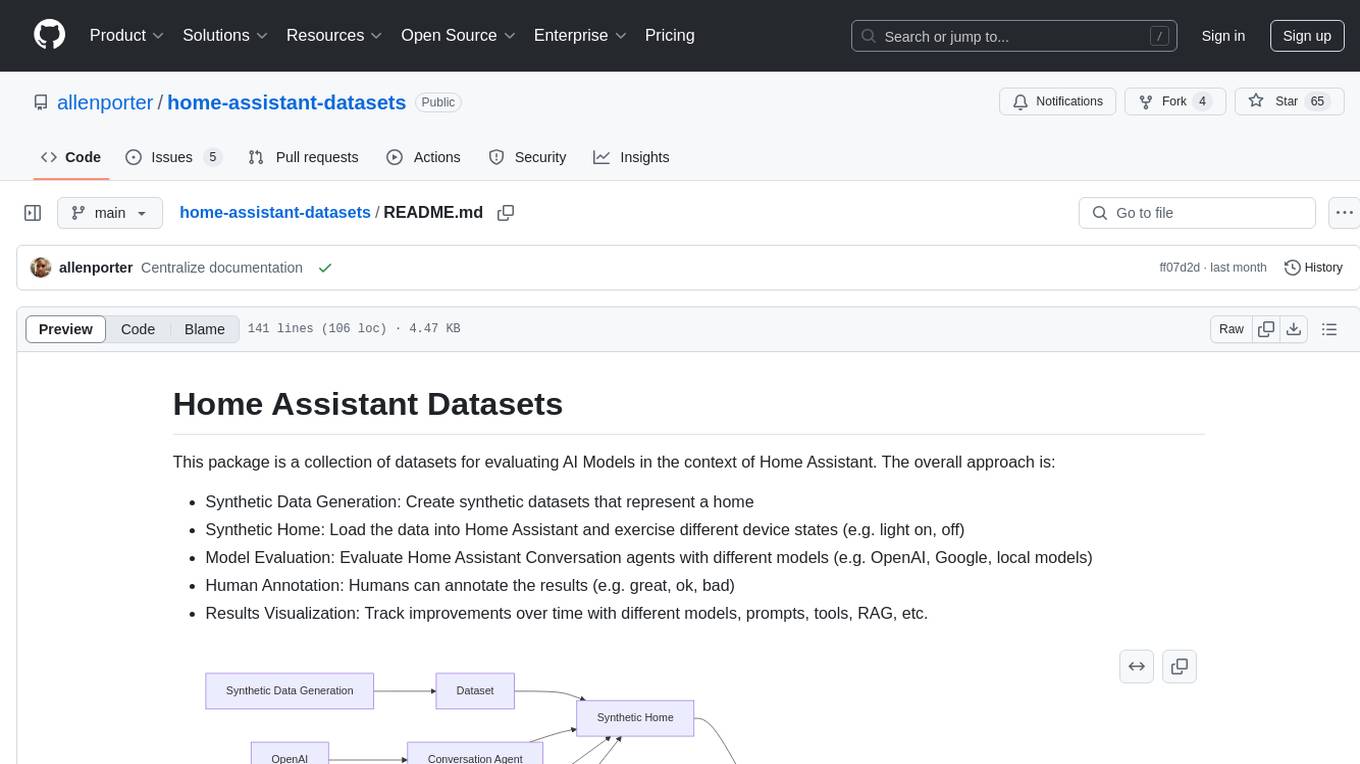
home-assistant-datasets
This package provides a collection of datasets for evaluating AI Models in the context of Home Assistant. It includes synthetic data generation, loading data into Home Assistant, model evaluation with different conversation agents, human annotation of results, and visualization of improvements over time. The datasets cover home descriptions, area descriptions, device descriptions, and summaries that can be performed on a home. The tool aims to build datasets for future training purposes.

LLM-Viewer
LLM-Viewer is a tool for visualizing Language and Learning Models (LLMs) and analyzing performance on different hardware platforms. It enables network-wise analysis, considering factors such as peak memory consumption and total inference time cost. With LLM-Viewer, users can gain valuable insights into LLM inference and performance optimization. The tool can be used in a web browser or as a command line interface (CLI) for easy configuration and visualization. The ongoing project aims to enhance features like showing tensor shapes, expanding hardware platform compatibility, and supporting more LLMs with manual model graph configuration.

SuperKnowa
SuperKnowa is a fast framework to build Enterprise RAG (Retriever Augmented Generation) Pipelines at Scale, powered by watsonx. It accelerates Enterprise Generative AI applications to get prod-ready solutions quickly on private data. The framework provides pluggable components for tackling various Generative AI use cases using Large Language Models (LLMs), allowing users to assemble building blocks to address challenges in AI-driven text generation. SuperKnowa is battle-tested from 1M to 200M private knowledge base & scaled to billions of retriever tokens.
awesome-synthetic-datasets
This repository focuses on organizing resources for building synthetic datasets using large language models. It covers important datasets, libraries, tools, tutorials, and papers related to synthetic data generation. The goal is to provide pragmatic and practical resources for individuals interested in creating synthetic datasets for machine learning applications.

nlp-llms-resources
The 'nlp-llms-resources' repository is a comprehensive resource list for Natural Language Processing (NLP) and Large Language Models (LLMs). It covers a wide range of topics including traditional NLP datasets, data acquisition, libraries for NLP, neural networks, sentiment analysis, optical character recognition, information extraction, semantics, topic modeling, multilingual NLP, domain-specific LLMs, vector databases, ethics, costing, books, courses, surveys, aggregators, newsletters, papers, conferences, and societies. The repository provides valuable information and resources for individuals interested in NLP and LLMs.
For similar tasks
graph-llm-asynchow-plan
Graph-enhanced Large Language Models in Asynchronous Plan Reasoning is a repository containing code and datasets for the ICML-2024 paper. It includes naturalistic datasets, code for generating data, benchmarking experiments, and prototypical experiments. The repository also offers a train/test-split version of the dataset on huggingface. The paper focuses on utilizing large language models with graph enhancements for asynchronous plan reasoning.

marvin
Marvin is a lightweight AI toolkit for building natural language interfaces that are reliable, scalable, and easy to trust. Each of Marvin's tools is simple and self-documenting, using AI to solve common but complex challenges like entity extraction, classification, and generating synthetic data. Each tool is independent and incrementally adoptable, so you can use them on their own or in combination with any other library. Marvin is also multi-modal, supporting both image and audio generation as well using images as inputs for extraction and classification. Marvin is for developers who care more about _using_ AI than _building_ AI, and we are focused on creating an exceptional developer experience. Marvin users should feel empowered to bring tightly-scoped "AI magic" into any traditional software project with just a few extra lines of code. Marvin aims to merge the best practices for building dependable, observable software with the best practices for building with generative AI into a single, easy-to-use library. It's a serious tool, but we hope you have fun with it. Marvin is open-source, free to use, and made with 💙 by the team at Prefect.

data-juicer
Data-Juicer is a one-stop data processing system to make data higher-quality, juicier, and more digestible for LLMs. It is a systematic & reusable library of 80+ core OPs, 20+ reusable config recipes, and 20+ feature-rich dedicated toolkits, designed to function independently of specific LLM datasets and processing pipelines. Data-Juicer allows detailed data analyses with an automated report generation feature for a deeper understanding of your dataset. Coupled with multi-dimension automatic evaluation capabilities, it supports a timely feedback loop at multiple stages in the LLM development process. Data-Juicer offers tens of pre-built data processing recipes for pre-training, fine-tuning, en, zh, and more scenarios. It provides a speedy data processing pipeline requiring less memory and CPU usage, optimized for maximum productivity. Data-Juicer is flexible & extensible, accommodating most types of data formats and allowing flexible combinations of OPs. It is designed for simplicity, with comprehensive documentation, easy start guides and demo configs, and intuitive configuration with simple adding/removing OPs from existing configs.

ChainForge
ChainForge is a visual programming environment for battle-testing prompts to LLMs. It is geared towards early-stage, quick-and-dirty exploration of prompts, chat responses, and response quality that goes beyond ad-hoc chatting with individual LLMs. With ChainForge, you can: * Query multiple LLMs at once to test prompt ideas and variations quickly and effectively. * Compare response quality across prompt permutations, across models, and across model settings to choose the best prompt and model for your use case. * Setup evaluation metrics (scoring function) and immediately visualize results across prompts, prompt parameters, models, and model settings. * Hold multiple conversations at once across template parameters and chat models. Template not just prompts, but follow-up chat messages, and inspect and evaluate outputs at each turn of a chat conversation. ChainForge comes with a number of example evaluation flows to give you a sense of what's possible, including 188 example flows generated from benchmarks in OpenAI evals. This is an open beta of Chainforge. We support model providers OpenAI, HuggingFace, Anthropic, Google PaLM2, Azure OpenAI endpoints, and Dalai-hosted models Alpaca and Llama. You can change the exact model and individual model settings. Visualization nodes support numeric and boolean evaluation metrics. ChainForge is built on ReactFlow and Flask.
Vodalus-Expert-LLM-Forge
Vodalus Expert LLM Forge is a tool designed for crafting datasets and efficiently fine-tuning models using free open-source tools. It includes components for data generation, LLM interaction, RAG engine integration, model training, fine-tuning, and quantization. The tool is suitable for users at all levels and is accompanied by comprehensive documentation. Users can generate synthetic data, interact with LLMs, train models, and optimize performance for local execution. The tool provides detailed guides and instructions for setup, usage, and customization.
hCaptcha-Solver
hCaptcha-Solver is an AI-based hcaptcha text challenge solver that utilizes the playwright module to generate the hsw N data. It can solve any text challenge without any problem, but may be flagged on some websites like Discord. The tool requires proxies since hCaptcha also rate limits. Users can run the 'hsw_api.py' before running anything and then integrate the usage shown in 'main.py' into their projects that require hCaptcha solving. Please note that this tool only works on sites that support hCaptcha text challenge.
seahorse
A handy package for kickstarting AI contests. This Python framework simplifies the creation of an environment for adversarial agents, offering various functionalities for game setup, playing against remote agents, data generation, and contest organization. The package is user-friendly and provides easy-to-use features out of the box. Developed by an enthusiastic team of M.Sc candidates at Polytechnique Montréal, 'seahorse' is distributed under the 3-Clause BSD License.
app
WebDB is a comprehensive and free database Integrated Development Environment (IDE) designed to maximize efficiency in database development and management. It simplifies and enhances database operations with features like DBMS discovery, query editor, time machine, NoSQL structure inferring, modern ERD visualization, and intelligent data generator. Developed with robust web technologies, WebDB is suitable for both novice and experienced database professionals.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.