
datahub
The Metadata Platform for your Data and AI Stack
Stars: 11572
DataHub is an open-source data catalog designed for the modern data stack. It provides a platform for managing metadata, enabling users to discover, understand, and collaborate on data assets within their organization. DataHub offers features such as data lineage tracking, data quality monitoring, and integration with various data sources. It is built with contributions from Acryl Data and LinkedIn, aiming to streamline data management processes and enhance data discoverability across different teams and departments.
README:
![]()



🏠 Docs: docs.datahub.com
Quickstart | Features | Roadmap | Adoption | Demo | Town Hall
📣 DataHub Town Hall is the 4th Thursday at 9am US PT of every month - add it to your calendar!
- Town-hall Zoom link: zoom.datahubproject.io
- Meeting details & past recordings
✨ DataHub Community Highlights:
- Read our Monthly Project Updates here.
- Bringing The Power Of The DataHub Real-Time Metadata Graph To Everyone At DataHub: Data Engineering Podcast
- Check out our most-read blog post, DataHub: Popular Metadata Architectures Explained @ LinkedIn Engineering Blog.
- Join us on Slack! Ask questions and keep up with the latest announcements.
DataHub is an open-source data catalog for the modern data stack. Read about the architectures of different metadata systems and why DataHub excels here. Also read our LinkedIn Engineering blog post, check out our Strata presentation and watch our Crunch Conference Talk. You should also visit DataHub Architecture to get a better understanding of how DataHub is implemented.
Check out DataHub's Features & Roadmap.
There's a hosted demo environment courtesy of DataHub where you can explore DataHub without installing it locally.
Please follow the DataHub Quickstart Guide to run DataHub locally using Docker.
If you're looking to build & modify datahub please take a look at our Development Guide.
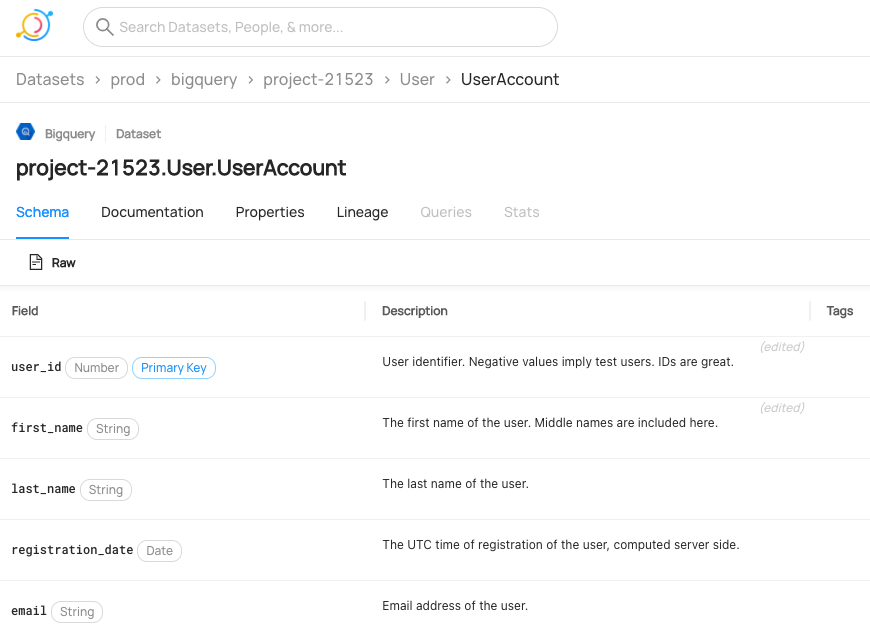
- datahub-project/datahub: This repository contains the complete source code for DataHub's metadata model, metadata services, integration connectors and the web application.
- acryldata/datahub-actions: DataHub Actions is a framework for responding to changes to your DataHub Metadata Graph in real time.
- acryldata/datahub-helm: Helm charts for deploying DataHub on a Kubernetes cluster
- acryldata/meta-world: A repository to store recipes, custom sources, transformations and other things to make your DataHub experience magical.
- dbt-impact-action: A github action for commenting on your PRs with a summary of the impact of changes within a dbt project.
- datahub-tools: Additional python tools to interact with the DataHub GraphQL endpoints, built by Notion.
- business-glossary-sync-action: A github action that opens PRs to update your business glossary yaml file.
- mcp-server-datahub: A Model Context Protocol server implementation for DataHub.
See Releases page for more details. We follow the SemVer Specification when versioning the releases and adopt the Keep a Changelog convention for the changelog format.
We welcome contributions from the community. Please refer to our Contributing Guidelines for more details. We also have a contrib directory for incubating experimental features.
Join our Slack workspace for discussions and important announcements. You can also find out more about our upcoming town hall meetings and view past recordings.
See Security Stance for information on DataHub's Security.
Here are the companies that have officially adopted DataHub. Please feel free to add yours to the list if we missed it.
- ABLY
- Adevinta
- Banksalad
- Cabify
- ClassDojo
- Coursera
- CVS Health
- DefinedCrowd
- DFDS
- Digital Turbine
- Expedia Group
- Experius
- Geotab
- Grofers
- Haibo Technology
- hipages
- inovex
- Inter&Co
- IOMED
- Klarna
- Moloco
- N26
- Optum
- Peloton
- PITS Global Data Recovery Services
- Razer
- Rippling
- Showroomprive
- SpotHero
- Stash
- Shanghai HuaRui Bank
- s7 Airlines
- ThoughtWorks
- TypeForm
- Udemy
- Uphold
- Viasat
- Wealthsimple
- Wikimedia
- Wolt
- Zynga
- DataHub Blog
- DataHub YouTube Channel
- Optum: Data Mesh via DataHub
- Saxo Bank: Enabling Data Discovery in Data Mesh
- Bringing The Power Of The DataHub Real-Time Metadata Graph To Everyone At DataHub
- DataHub: Popular Metadata Architectures Explained
- Driving DataOps Culture with LinkedIn DataHub @ DataOps Unleashed 2021
- The evolution of metadata: LinkedIn’s story @ Strata Data Conference 2019
- Journey of metadata at LinkedIn @ Crunch Data Conference 2019
- DataHub Journey with Expedia Group
- Data Discoverability at SpotHero
- Data Catalogue — Knowing your data
- DataHub: A Generalized Metadata Search & Discovery Tool
- Open sourcing DataHub: LinkedIn’s metadata search and discovery platform
- Emerging Architectures for Modern Data Infrastructure
See the full list here.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for datahub
Similar Open Source Tools
datahub
DataHub is an open-source data catalog designed for the modern data stack. It provides a platform for managing metadata, enabling users to discover, understand, and collaborate on data assets within their organization. DataHub offers features such as data lineage tracking, data quality monitoring, and integration with various data sources. It is built with contributions from Acryl Data and LinkedIn, aiming to streamline data management processes and enhance data discoverability across different teams and departments.
docq
Docq is a private and secure GenAI tool designed to extract knowledge from business documents, enabling users to find answers independently. It allows data to stay within organizational boundaries, supports self-hosting with various cloud vendors, and offers multi-model and multi-modal capabilities. Docq is extensible, open-source (AGPLv3), and provides commercial licensing options. The tool aims to be a turnkey solution for organizations to adopt AI innovation safely, with plans for future features like more data ingestion options and model fine-tuning.

dify
Dify is an open-source LLM app development platform that combines AI workflow, RAG pipeline, agent capabilities, model management, observability features, and more. It allows users to quickly go from prototype to production. Key features include: 1. Workflow: Build and test powerful AI workflows on a visual canvas. 2. Comprehensive model support: Seamless integration with hundreds of proprietary / open-source LLMs from dozens of inference providers and self-hosted solutions. 3. Prompt IDE: Intuitive interface for crafting prompts, comparing model performance, and adding additional features. 4. RAG Pipeline: Extensive RAG capabilities that cover everything from document ingestion to retrieval. 5. Agent capabilities: Define agents based on LLM Function Calling or ReAct, and add pre-built or custom tools. 6. LLMOps: Monitor and analyze application logs and performance over time. 7. Backend-as-a-Service: All of Dify's offerings come with corresponding APIs for easy integration into your own business logic.
xpert
Xpert is a powerful tool for data analysis and visualization. It provides a user-friendly interface to explore and manipulate datasets, perform statistical analysis, and create insightful visualizations. With Xpert, users can easily import data from various sources, clean and preprocess data, analyze trends and patterns, and generate interactive charts and graphs. Whether you are a data scientist, analyst, researcher, or student, Xpert simplifies the process of data analysis and visualization, making it accessible to users with varying levels of expertise.

instill-core
Instill Core is an open-source orchestrator comprising a collection of source-available projects designed to streamline every aspect of building versatile AI features with unstructured data. It includes Instill VDP (Versatile Data Pipeline) for unstructured data, AI, and pipeline orchestration, Instill Model for scalable MLOps and LLMOps for open-source or custom AI models, and Instill Artifact for unified unstructured data management. Instill Core can be used for tasks such as building, testing, and sharing pipelines, importing, serving, fine-tuning, and monitoring ML models, and transforming documents, images, audio, and video into a unified AI-ready format.
nexent
Nexent is a powerful tool for analyzing and visualizing network traffic data. It provides comprehensive insights into network behavior, helping users to identify patterns, anomalies, and potential security threats. With its user-friendly interface and advanced features, Nexent is suitable for network administrators, cybersecurity professionals, and anyone looking to gain a deeper understanding of their network infrastructure.
sourcegraph-public-snapshot
Sourcegraph is a tool that simplifies reading, writing, and fixing code in large and complex codebases. It offers features such as code search across repositories, code intelligence for code navigation and history tracing, and the ability to roll out large-scale changes to multiple repositories simultaneously. Sourcegraph can be used on the cloud or self-hosted, and provides public code search on Sourcegraph.com. The tool is designed to enhance code understanding and collaboration within development teams.
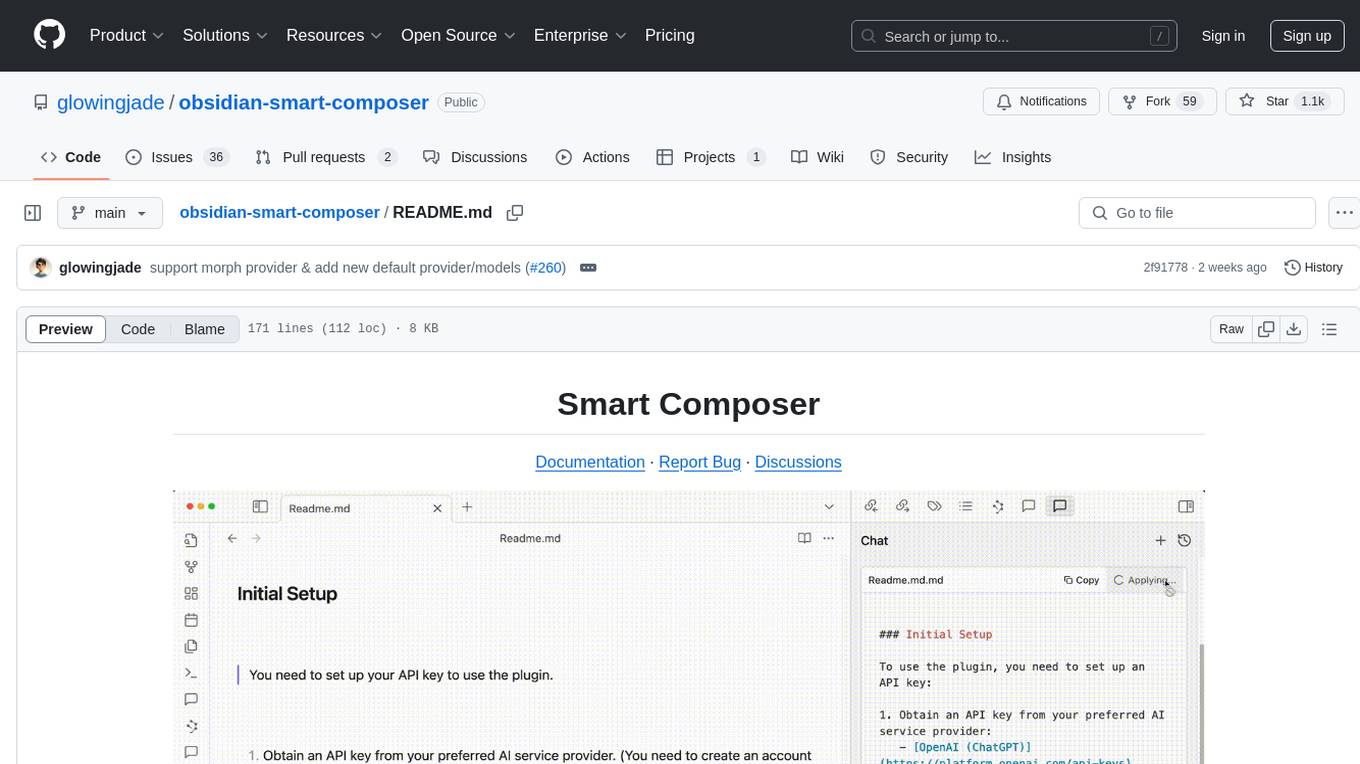
obsidian-smart-composer
Smart Composer is an Obsidian plugin that enhances note-taking and content creation by integrating AI capabilities. It allows users to efficiently write by referencing their vault content, providing contextual chat with precise context selection, multimedia context support for website links and images, document edit suggestions, and vault search for relevant notes. The plugin also offers features like custom model selection, local model support, custom system prompts, and prompt templates. Users can set up the plugin by installing it through the Obsidian community plugins, enabling it, and configuring API keys for supported providers like OpenAI, Anthropic, and Gemini. Smart Composer aims to streamline the writing process by leveraging AI technology within the Obsidian platform.

clearml
ClearML is a suite of tools designed to streamline the machine learning workflow. It includes an experiment manager, MLOps/LLMOps, data management, and model serving capabilities. ClearML is open-source and offers a free tier hosting option. It supports various ML/DL frameworks and integrates with Jupyter Notebook and PyCharm. ClearML provides extensive logging capabilities, including source control info, execution environment, hyper-parameters, and experiment outputs. It also offers automation features, such as remote job execution and pipeline creation. ClearML is designed to be easy to integrate, requiring only two lines of code to add to existing scripts. It aims to improve collaboration, visibility, and data transparency within ML teams.
zero-true
Zero-True is a Python and SQL reactive computational notebook designed for building and collaborating on data-driven applications. It offers an integrated and simple environment with transparent updates, dynamic and interactive UI rendering, fast prototyping capabilities, and open-source community contributions. Users can create rich, reactive apps with ease and publish them confidently. Zero-True aims to improve data accessibility and foster collaboration among users.
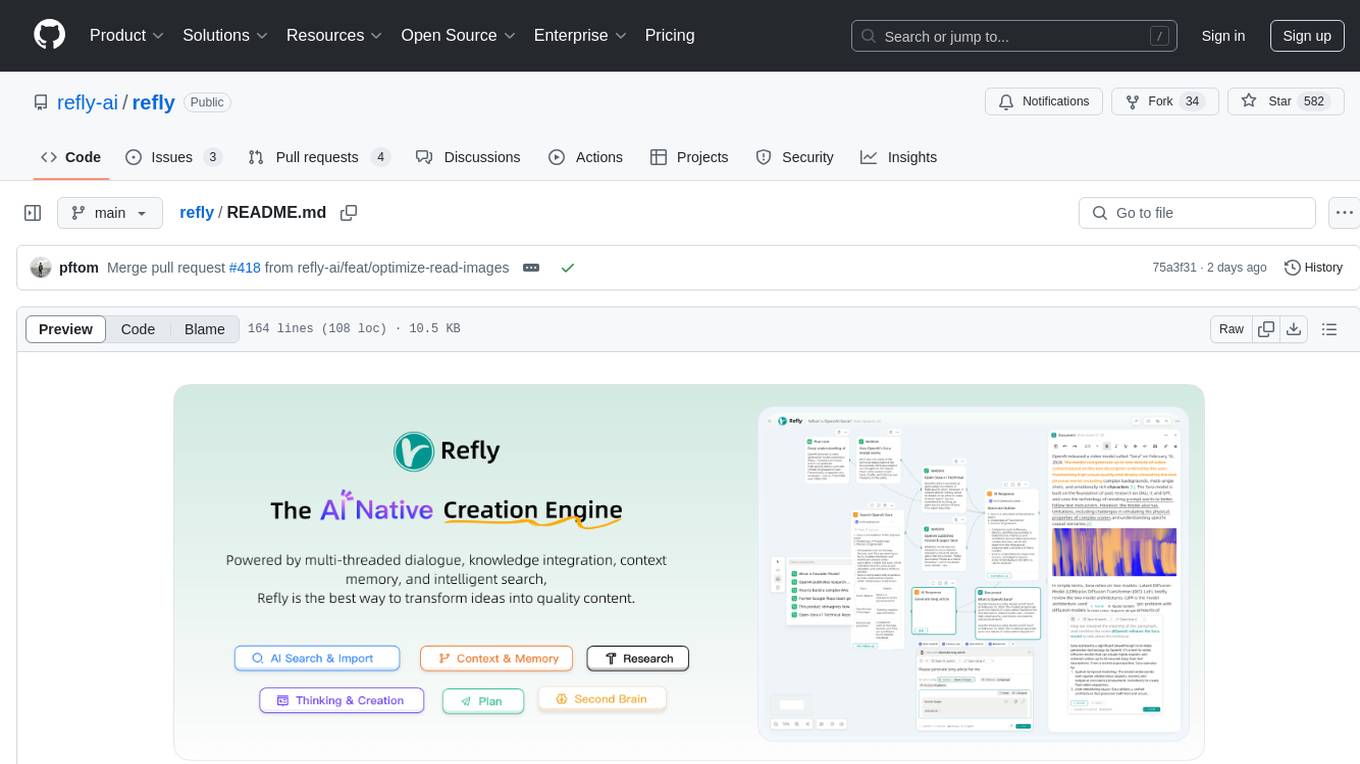
refly
Refly.AI is an open-source AI-native creation engine that empowers users to transform ideas into production-ready content. It features a free-form canvas interface with multi-threaded conversations, knowledge base integration, contextual memory, intelligent search, WYSIWYG AI editor, and more. Users can leverage AI-powered capabilities, context memory, knowledge base integration, quotes, and AI document editing to enhance their content creation process. Refly offers both cloud and self-hosting options, making it suitable for individuals, enterprises, and organizations. The tool is designed to facilitate human-AI collaboration and streamline content creation workflows.

client
DagsHub is a platform for machine learning and data science teams to build, manage, and collaborate on their projects. With DagsHub you can: 1. Version code, data, and models in one place. Use the free provided DagsHub storage or connect it to your cloud storage 2. Track Experiments using Git, DVC or MLflow, to provide a fully reproducible environment 3. Visualize pipelines, data, and notebooks in and interactive, diff-able, and dynamic way 4. Label your data directly on the platform using Label Studio 5. Share your work with your team members 6. Stream and upload your data in an intuitive and easy way, while preserving versioning and structure. DagsHub is built firmly around open, standard formats for your project. In particular: * Git * DVC * MLflow * Label Studio * Standard data formats like YAML, JSON, CSV Therefore, you can work with DagsHub regardless of your chosen programming language or frameworks.

cherry-studio
Cherry Studio is a desktop client that supports multiple LLM providers on Windows, Mac, and Linux. It offers diverse LLM provider support, AI assistants & conversations, document & data processing, practical tools integration, and enhanced user experience. The tool includes features like support for major LLM cloud services, AI web service integration, local model support, pre-configured AI assistants, document processing for text, images, and more, global search functionality, topic management system, AI-powered translation, and cross-platform support with ready-to-use features and themes for a better user experience.
agentgateway
Agentgateway is an open source data plane optimized for agentic AI connectivity within or across any agent framework or environment. It provides drop-in security, observability, and governance for agent-to-agent and agent-to-tool communication, supporting leading interoperable protocols like Agent2Agent (A2A) and Model Context Protocol (MCP). Highly performant, security-first, multi-tenant, dynamic, and supporting legacy API transformation, agentgateway is designed to handle any scale and run anywhere with any agent framework.
tidb.ai
TiDB.AI is a conversational search RAG (Retrieval-Augmented Generation) app based on TiDB Serverless Vector Storage. It provides an out-of-the-box and embeddable QA robot experience based on knowledge from official and documentation sites. The platform features a Perplexity-style Conversational Search page with an advanced built-in website crawler for comprehensive coverage. Users can integrate an embeddable JavaScript snippet into their website for instant responses to product-related queries. The tech stack includes Next.js, TypeScript, Tailwind CSS, shadcn/ui for design, TiDB for database storage, Kysely for SQL query building, NextAuth.js for authentication, Vercel for deployments, and LlamaIndex for the RAG framework. TiDB.AI is open-source under the Apache License, Version 2.0.
legacy-sourcegraph
Sourcegraph is a tool that simplifies reading, writing, and fixing code in large and complex codebases. It offers features such as code search across repositories and hosts, code intelligence for navigation and references, and the ability to roll out large-scale changes and track migrations. Sourcegraph can be used on the cloud or self-hosted, with public code search available on Sourcegraph.com. The tool provides high-level architecture documentation, database setup best practices, Go and documentation style guides, tips for modifying the GraphQL API, and guidelines for contributing.
For similar tasks
Oxen
Oxen is a data version control library, written in Rust. It's designed to be fast, reliable, and easy to use. Oxen can be used in a variety of ways, from a simple command line tool to a remote server to sync to, to integrations into other ecosystems such as python.
datahub
DataHub is an open-source data catalog designed for the modern data stack. It provides a platform for managing metadata, enabling users to discover, understand, and collaborate on data assets within their organization. DataHub offers features such as data lineage tracking, data quality monitoring, and integration with various data sources. It is built with contributions from Acryl Data and LinkedIn, aiming to streamline data management processes and enhance data discoverability across different teams and departments.
panda-etl
PandaETL is an open-source, no-code ETL tool designed to extract and parse data from various document types including PDFs, emails, websites, audio files, and more. With an intuitive interface and powerful backend, PandaETL simplifies the process of data extraction and transformation, making it accessible to users without programming skills.
supavec
Supavec is an open-source tool that serves as an alternative to Carbon.ai. It allows users to build powerful RAG applications using any data source and at any scale. The tool is designed to provide a simple API endpoint for easy integration and usage. Supavec is built with Next.js, Supabase, Tailwind CSS, Bun, and Upstash, offering a robust and flexible solution for application development. Users can refer to the API documentation for detailed information on how to utilize the tool effectively.
pipeshub-ai
Pipeshub-ai is a versatile tool for automating data pipelines in AI projects. It provides a user-friendly interface to design, deploy, and monitor complex data workflows, enabling seamless integration of various AI models and data sources. With Pipeshub-ai, users can easily create end-to-end pipelines for tasks such as data preprocessing, model training, and inference, streamlining the AI development process and improving productivity. The tool supports integration with popular AI frameworks and cloud services, making it suitable for both beginners and experienced AI practitioners.
supavec
Supavec is an open-source tool that serves as an alternative to Carbon.ai. It allows users to build powerful RAG applications using any data source and at any scale. The tool is designed to provide a cloud version for easy access and offers simple API endpoints for seamless integration. Built with Next.js, Supabase, Tailwind CSS, Bun, and Upstash, Supavec empowers users to create innovative applications with ease. The API documentation is available for reference, making it convenient for developers to get started and explore the tool's capabilities.
bagofwords
Bag of words is an open-source AI platform that helps data teams deploy and manage chat-with-your-data agents in a controlled, reliable, and self-learning environment. It enables users to create charts, tables, and dashboards by chatting with their data, capture AI decisions and user feedback, automatically improve AI quality, integrate with various data sources and APIs, and ensure governance and integrations. The platform supports self-hosting in VPC via VMs, Docker/Compose, or Kubernetes, and offers additional integrations for AI Analyst in Slack, Excel, Google Sheets, and more. Users can start in minutes and scale to org-wide analytics.
dapr-agents
Dapr Agents is a developer framework for building production-grade resilient AI agent systems that operate at scale. It enables software developers to create AI agents that reason, act, and collaborate using Large Language Models (LLMs), while providing built-in observability and stateful workflow execution to ensure agentic workflows complete successfully. The framework is scalable, efficient, Kubernetes-native, data-driven, secure, observable, vendor-neutral, and open source. It offers features like scalable workflows, cost-effective AI adoption, data-centric AI agents, accelerated development, integrated security and reliability, built-in messaging and state infrastructure, and vendor-neutral and open source support. Dapr Agents is designed to simplify the development of AI applications and workflows by providing a comprehensive API surface and seamless integration with various data sources and services.
For similar jobs

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.