
volga
Real-time data processing/feature engineering in Rust and Python. Tailored for modern AI/ML systems.
Stars: 70

Volga is a general purpose real-time data processing engine in Python for modern AI/ML systems. It aims to be a Python-native alternative to Flink/Spark Streaming with extended functionality for real-time AI/ML workloads. It provides a hybrid push+pull architecture, Entity API for defining data entities and feature pipelines, DataStream API for general data processing, and customizable data connectors. Volga can run on a laptop or a distributed cluster, making it suitable for building custom real-time AI/ML feature platforms or general data pipelines without relying on third-party platforms.
README:
![]()





Volga is a general purpose real-time data processing engine aiming to be a fully functional Python-native Flink/Spark Streaming alternative with extended functionality to support modern real-time AI/ML systems without dependency on 3rd party feature platforms.
- 📖 Table of contents
- 🤯 What and why
- 🏠 Architecture
- 🌳 Features
- 🚅 Quick Start
- 🚢 Installation
- 🙇 Running Locally
- 🧁 Roadmap
Volga is a general purpose real-time data processing engine tailored for modern AI/ML applications. It aims to be a fully functional Python-native Flink/Spark Streaming alternative with extended functionality to execute environment-agnostic event-time/request-time computations (common in real-time AI/ML workloads - fraud detection, recommender systems, search personalization, dynamic pricing, credit risk, ETA calculation, personalized real-time context-aware RAG, etc.).
Volga is designed to be a backbone for your custom real-time AI/ML feature platforms or general data pipelines without relying on heterogenous data processors like Flink/Spark/custom data processing layers (e.g. Chronon) or third party data/feature platforms (e.g. Tecton.ai, Fennel.ai, Chalk.ai).
Check the blog, join Slack, see v1.0 Relaese Roadmap.
Volga provides a Python-native runtime in conjunction with Rust for performance, runs on Ray, uses a hybrid push(streaming) + pull(on-demand) architecture to run arbitrary request-time/event-time computation DAGs, features convenient Pandas-like Entity API to define data entities and online/offline feature pipelines and on-demand features as well as general purpose DataStream API for more general data processing cases, consistent online+offline feature calculation semantics, configurable storage, real-time data serving and request-time compute. It can run on a laptop or a distributed cluster.

- Hybrid push+pull architecture: custom Streaming Engine (the Push part) and On-Demand Compute Layer (the Pull part) to execute environment-agnostic computation DAGs.
- Streaming Engine built with Ray Actors, ZeroMQ, Rust and PyO3. Python-native Flink alternative with flexible DataStream API to build custom streaming pipelines that scale to millitons of messages per second with latency in milliseconds.
- On-Demand Compute Layer to perform arbitrary DAGs of request time/inference time calculations in sync with streaming engine (real-time feature serving, request-time heavy embedding dot products, meta-models query/feature enrichment or simply calculating users age in milliseconds).
-
Entity API to build standardized data models with compile-time schema validation, Pandas-like operators like
transform,filter,join,groupby/aggregate,drop, etc. to build modular AI/ML features with consistent online/offline semantics. - Built on top of Ray - Easily integrates with Ray ecosystem, runs on Kubernetes and local machines, provides a homogeneous platform with no heavy dependencies on multiple JVM-based systems.
- Highly customizable data connectors to read/write data from/to any third party system.

Volga provides two sets of APIs to build and run data pipelines: high-level Entity API to build environment-agnostic computation DAGs (commonly used in real-time AI/ML feature pipelines) and low-level Flink-like DataStream API for general streaming/batch pipelines. In a nutshell, Entity API is built on top of DataStream API (for streaming/batch features calculated on streaming engine) and also includes interface for On-Demand Compute Layer (for features calculated at request time) and consistent data models/abstractions to stitch both systems together.
Entity API distinguishes between two types of features: @pipeline (online/streaming + offline/batch which are executed on streaming engine) and @on_demand (request time execution on On-Demand Compute Layer), both types operate on @entity annotated data models.
- Use
@entityto decorate data models. Notekeyandtimestamp: keys are used to group/join/lookup features, timestamps are used for point-in-time correctness, range queries and lookups by on-demand features. Entities should also have logically matching schemas - this is enforced at compile-time which is extremely useful for data consistency.
from volga.api.entity import Entity, entity, field
# User, Order and OnSaleUserSpentInfo are used by @pipeline features
@entity
class User:
user_id: str = field(key=True)
registered_at: datetime.datetime = field(timestamp=True)
name: str
@entity
class Order:
buyer_id: str = field(key=True)
product_id: str = field(key=True)
product_type: str
purchased_at: datetime.datetime = field(timestamp=True)
product_price: float
@entity
class OnSaleUserSpentInfo:
user_id: str = field(key=True)
timestamp: datetime.datetime = field(timestamp=True)
avg_spent_7d: float
num_purchases_1h: int
# UserStats is an entity returned to user as a resutl of corresponding @on_demand feature
@entity
class UserStats:
user_id: str = field(key=True)
timestamp: datetime.datetime = field(timestamp=True)
total_spent: float
purchase_count: int- Define pipeline features (streaming/batch) using
@sourceand@pipelinedecorators. We explicilty specify dependant features independencieswhich our engine automatically maps to function arguments at job graph compile time. Note that pipelines can only depend on other pipelines
from volga.api.pipeline import pipeline
from volga.api.source import Connector, MockOnlineConnector, source, MockOfflineConnector
users = [...] # sample User entities
orders = [...] # sample Order entities
@source(User)
def user_source() -> Connector:
return MockOfflineConnector.with_items([user.__dict__ for user in users])
@source(Order)
def order_source(online: bool = True) -> Connector: # this will generate appropriate connector based on param we pass during execution
if online:
return MockOnlineConnector.with_periodic_items([order.__dict__ for order in orders], period_s=purchase_event_delays_s)
else:
return MockOfflineConnector.with_items([order.__dict__ for order in orders])
@pipeline(dependencies=['user_source', 'order_source'], output=OnSaleUserSpentInfo)
def user_spent_pipeline(users: Entity, orders: Entity) -> Entity:
on_sale_purchases = orders.filter(lambda x: x['product_type'] == 'ON_SALE')
per_user = on_sale_purchases.join(
users,
left_on=['buyer_id'],
right_on=['user_id'],
how='left'
)
return per_user.group_by(keys=['buyer_id']).aggregate([
Avg(on='product_price', window='7d', into='avg_spent_7d'),
Count(window='1h', into='num_purchases_1h'),
]).rename(columns={
'purchased_at': 'timestamp',
'buyer_id': 'user_id'
})- Run batch (offline) materialization. This is needed if you want offline features for model training.
from volga.client.client import Client
from volga.api.feature import FeatureRepository
client = Client()
pipeline_connector = InMemoryActorPipelineDataConnector(batch=False) # store data in-memory, can be any other user-defined connector, e.g. Redis/Cassandra/S3
# Note that offline materialization only works for pipeline features at the moment, so offline data points you get will match event time, not request time
client.materialize(
features=[FeatureRepository.get_feature('user_spent_pipeline')],
pipeline_data_connector=InMemoryActorPipelineDataConnector(batch=False),
_async=False,
params={'global': {'online': False}}
)
# Get results from storage. This will be specific to what db you use
keys = [{'user_id': user.user_id} for user in users]
# we user in-memory actor
offline_res_raw = ray.get(cache_actor.get_range.remote(feature_name='user_spent_pipeline', keys=keys, start=None, end=None, with_timestamps=False))
offline_res_flattened = [item for items in offline_res_raw for item in items]
offline_res_flattened.sort(key=lambda x: x['timestamp'])
offline_df = pd.DataFrame(offline_res_flattened)
pprint(offline_df)
...
user_id timestamp avg_spent_7d num_purchases_1h
0 0 2025-03-22 13:54:43.335568 100.0 1
1 1 2025-03-22 13:54:44.335568 100.0 1
2 2 2025-03-22 13:54:45.335568 100.0 1
3 3 2025-03-22 13:54:46.335568 100.0 1
4 4 2025-03-22 13:54:47.335568 100.0 1
.. ... ... ... ...
796 96 2025-03-22 14:07:59.335568 100.0 8
797 97 2025-03-22 14:08:00.335568 100.0 8
798 98 2025-03-22 14:08:01.335568 100.0 8
799 99 2025-03-22 14:08:02.335568 100.0 8
800 0 2025-03-22 14:08:03.335568 100.0 9- For online inference, define on-demand features using
@on_demand- this will be executed at request time. Unlike@pipeline,@on_demandcan depend on both pipelines and on-demands. If we just want to serve pipeline results, we can skip this.
from volga.api.on_demand import on_demand
@on_demand(dependencies=[(
'user_spent_pipeline', # name of dependency, matches positional argument in function
'latest' # name of the query defined in OnDemandDataConnector - how we access dependant data (e.g. latest, last_n, average, etc.).
)])
def user_stats(spent_info: OnSaleUserSpentInfo) -> UserStats:
# logic to execute at request time
return UserStats(
user_id=spent_info.user_id,
timestamp=spent_info.timestamp,
total_spent=spent_info.avg_spent_7d * spent_info.num_purchases_1h,
purchase_count=spent_info.num_purchases_1h
)- To be able to request results in real-time, run streaming (online) materialization.
client.materialize(
features=[FeatureRepository.get_feature('user_spent_pipeline')],
pipeline_data_connector=pipeline_connector,
job_config=DEFAULT_STREAMING_JOB_CONFIG,
scaling_config={},
_async=True,
params={'global': {'online': True}}
)- In a separate thread/process/node, request results in real-time - simulate inference feature time requests
# Start OnDemand coordinator
coordinator = create_on_demand_coordinator(OnDemandConfig(
num_servers_per_node=1,
server_port=DEFAULT_ON_DEMAND_SERVER_PORT,
data_connector=OnDemandDataConnectorConfig(
connector_class=InMemoryActorOnDemandDataConnector, # defines how OnDemand layer reads pipeline data, maps custom queries to query arguments from OnDemandRequest
connector_args={}
)
))
await coordinator.start.remote() # create OnDemand workers on the cluster
# register features to execute
await coordinator.register_features.remote(FeatureRepository.get_all_features())
# query results
client = OnDemandClient(DEFAULT_ON_DEMAND_CLIENT_URL)
user_ids = [...] # user ids you want to query
while True:
request = OnDemandRequest(
target_features=['user_stats'],
feature_keys={
'user_stats': [
{'user_id': user_id}
for user_id in user_ids
]
},
query_args={
'user_stats': {}, # empty for 'latest', can be time range if we have 'last_n' query or any other query/params configuration defined in data connector
}
)
response = await self.client.request(request)
for user_id, user_stats_raw in zip(user_ids, response.results['user_stats']):
user_stats = UserStats(**user_stats_raw[0])
pprint(f'New feature: {user_stats.__dict__}')
...
("New feature: {'user_id': '98', 'timestamp': '2025-03-22T10:04:54.685096', "
"'total_spent': 400.0, 'purchase_count': 4}")
("New feature: {'user_id': '99', 'timestamp': '2025-03-22T10:04:55.685096', "
"'total_spent': 400.0, 'purchase_count': 4}")
("New feature: {'user_id': '0', 'timestamp': '2025-03-22T10:04:56.685096', "
"'total_spent': 500.0, 'purchase_count': 5}")
("New feature: {'user_id': '1', 'timestamp': '2025-03-22T10:04:57.685096', "
"'total_spent': 500.0, 'purchase_count': 5}")
("New feature: {'user_id': '2', 'timestamp': '2025-03-22T10:04:58.685096', "
"'total_spent': 500.0, 'purchase_count': 5}")If we want to have more control over streaming engine and build any other custom pipeline, Volga exposes general purpose Flink-like DataStream API to define consistent streaming/batch pipelines.
from volga.streaming.api.context.streaming_context import StreamingContext
from volga.streaming.api.context.streaming_context import StreamingContext
from volga.streaming.api.function.function import SinkToCacheDictFunction
from volga.streaming.api.stream.sink_cache_actor import SinkCacheActor
from volga.streaming.runtime.sources.wordcount.timed_source import WordCountSource
# simple word count
sink_cache = SinkCacheActor.remote() # simple actor with list and dict to store data
ctx = StreamingContext(job_config=job_config)
source = WordCountSource(
streaming_context=ctx,
dictionary=dictionary,
run_for_s=run_for_s
) # round robins words from dictionary to each peer worker based on parallelism
source.set_parallelism(2) # 2 workers/tasks per operator
s = source.map(lambda wrd: (wrd, 1)) \
.key_by(lambda e: e[0]) \
.reduce(lambda old_value, new_value: (old_value[0], old_value[1] + new_value[1]))
s.sink(SinkToCacheDictFunction(sink_cache, key_value_extractor=(lambda e: (e[0], e[1]))))
ctx.execute()The project is currently in dev stage and has no published packages/binaries yet. To run locally/dev locally, clone the repository and in your dev env run:
pip install .
After that make sure to compile rust binaries and build Python binding using PyO3's maturin :
cd rust
maturin develop
If on Apple Silicon, when installing Ray you may get an error regarding grpcio on Apple Silicon. To fix, run:
pip uninstall grpcio; conda install grpcio
To enable graph visualization install GraphViz:
brew install graphviz
pip install pygraphviz
To develop locally and have Ray pick up local changes, you need to uninstall local volga package and append PYTHONPATH env var with a path to your local volga project folder:
pip uninstall volga
export PYTHONPATH=/path/to/local/volga/folder:$PYTHONPATH # you need to set it in each new shell/window. Alternatively, use env vars setting in you virtual env maanger
Since Volga uses Ray's distributed runtime you'll need a running Ray Cluster to run pipelines. The easiest way is to launch a local one-node cluster:
ray start --head
Make sure your program's entry point is in the same virtual env where you launched the cluster. You can run sample e2e tests to see the engine's workflow:
- test_volga_e2e.py - Sample high-level on-demand/pipeline workflow
- test_streaming_e2e.py - Sample low-level streaming job
python test_volga_e2e.py
python test_streaming_e2e.py
The development is done with Python 3.10.8 and Ray 2.22.0, in case of any import/installation related errors, please try rolling your dev env back to these versions.
Volga is in active development and requires a number of features to get to prod-ready release (mostly around fault-tolerance: streaming engine checkpointing and state backend, watermarks, on-demand worker health, etc.), you can see the release roadmap here:
Any feedback is extremely valuable, issues and PRs are always welcome.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for volga
Similar Open Source Tools
volga
Volga is a general purpose real-time data processing engine in Python for modern AI/ML systems. It aims to be a Python-native alternative to Flink/Spark Streaming with extended functionality for real-time AI/ML workloads. It provides a hybrid push+pull architecture, Entity API for defining data entities and feature pipelines, DataStream API for general data processing, and customizable data connectors. Volga can run on a laptop or a distributed cluster, making it suitable for building custom real-time AI/ML feature platforms or general data pipelines without relying on third-party platforms.
pixeltable
Pixeltable is a Python library designed for ML Engineers and Data Scientists to focus on exploration, modeling, and app development without the need to handle data plumbing. It provides a declarative interface for working with text, images, embeddings, and video, enabling users to store, transform, index, and iterate on data within a single table interface. Pixeltable is persistent, acting as a database unlike in-memory Python libraries such as Pandas. It offers features like data storage and versioning, combined data and model lineage, indexing, orchestration of multimodal workloads, incremental updates, and automatic production-ready code generation. The tool emphasizes transparency, reproducibility, cost-saving through incremental data changes, and seamless integration with existing Python code and libraries.

CodeTF
CodeTF is a Python transformer-based library for code large language models (Code LLMs) and code intelligence. It provides an interface for training and inferencing on tasks like code summarization, translation, and generation. The library offers utilities for code manipulation across various languages, including easy extraction of code attributes. Using tree-sitter as its core AST parser, CodeTF enables parsing of function names, comments, and variable names. It supports fast model serving, fine-tuning of LLMs, various code intelligence tasks, preprocessed datasets, model evaluation, pretrained and fine-tuned models, and utilities to manipulate source code. CodeTF aims to facilitate the integration of state-of-the-art Code LLMs into real-world applications, ensuring a user-friendly environment for code intelligence tasks.

req_llm
ReqLLM is a Req-based library for LLM interactions, offering a unified interface to AI providers through a plugin-based architecture. It brings composability and middleware advantages to LLM interactions, with features like auto-synced providers/models, typed data structures, ergonomic helpers, streaming capabilities, usage & cost extraction, and a plugin-based provider system. Users can easily generate text, structured data, embeddings, and track usage costs. The tool supports various AI providers like Anthropic, OpenAI, Groq, Google, and xAI, and allows for easy addition of new providers. ReqLLM also provides API key management, detailed documentation, and a roadmap for future enhancements.

rl
TorchRL is an open-source Reinforcement Learning (RL) library for PyTorch. It provides pytorch and **python-first** , low and high level abstractions for RL that are intended to be **efficient** , **modular** , **documented** and properly **tested**. The code is aimed at supporting research in RL. Most of it is written in python in a highly modular way, such that researchers can easily swap components, transform them or write new ones with little effort.

LightRAG
LightRAG is a repository hosting the code for LightRAG, a system that supports seamless integration of custom knowledge graphs, Oracle Database 23ai, Neo4J for storage, and multiple file types. It includes features like entity deletion, batch insert, incremental insert, and graph visualization. LightRAG provides an API server implementation for RESTful API access to RAG operations, allowing users to interact with it through HTTP requests. The repository also includes evaluation scripts, code for reproducing results, and a comprehensive code structure.
sdg_hub
sdg_hub is a modular Python framework designed for building synthetic data generation pipelines using composable blocks and flows. Users can mix and match LLM-powered and traditional processing blocks to create sophisticated data generation workflows. The toolkit offers features such as modular composability, async performance, built-in validation, auto-discovery, rich monitoring, dataset schema discovery, and easy extensibility. sdg_hub provides detailed documentation and supports high-throughput processing with error handling. It simplifies the process of transforming datasets by allowing users to chain blocks together in YAML-configured flows, enabling the creation of complex data generation pipelines.
mcphub.nvim
MCPHub.nvim is a powerful Neovim plugin that integrates MCP (Model Context Protocol) servers into your workflow. It offers a centralized config file for managing servers and tools, with an intuitive UI for testing resources. Ideal for LLM integration, it provides programmatic API access and interactive testing through the `:MCPHub` command.

continuous-eval
Open-Source Evaluation for LLM Applications. `continuous-eval` is an open-source package created for granular and holistic evaluation of GenAI application pipelines. It offers modularized evaluation, a comprehensive metric library covering various LLM use cases, the ability to leverage user feedback in evaluation, and synthetic dataset generation for testing pipelines. Users can define their own metrics by extending the Metric class. The tool allows running evaluation on a pipeline defined with modules and corresponding metrics. Additionally, it provides synthetic data generation capabilities to create user interaction data for evaluation or training purposes.
ShannonBase
ShannonBase is a HTAP database provided by Shannon Data AI, designed for big data and AI. It extends MySQL with native embedding support, machine learning capabilities, a JavaScript engine, and a columnar storage engine. ShannonBase supports multimodal data types and natively integrates LightGBM for training and prediction. It leverages embedding algorithms and vector data type for ML/RAG tasks, providing Zero Data Movement, Native Performance Optimization, and Seamless SQL Integration. The tool includes a lightweight JavaScript engine for writing stored procedures in SQL or JavaScript.
next-token-prediction
Next-Token Prediction is a language model tool that allows users to create high-quality predictions for the next word, phrase, or pixel based on a body of text. It can be used as an alternative to well-known decoder-only models like GPT and Mistral. The tool provides options for simple usage with built-in data bootstrap or advanced customization by providing training data or creating it from .txt files. It aims to simplify methodologies, provide autocomplete, autocorrect, spell checking, search/lookup functionalities, and create pixel and audio transformers for various prediction formats.
monty
Monty is a minimal, secure Python interpreter written in Rust for use by AI. It allows safe execution of Python code written by an LLM embedded in your agent, with fast startup times and performance similar to CPython. Monty supports running a subset of Python code, blocking access to the host environment, calling host functions, typechecking, snapshotting interpreter state, controlling resource usage, collecting stdout and stderr, and running async or sync code. It is designed for running code written by agents, providing a sandboxed environment without the complexity of a full container-based solution.

openvino.genai
The GenAI repository contains pipelines that implement image and text generation tasks. The implementation uses OpenVINO capabilities to optimize the pipelines. Each sample covers a family of models and suggests certain modifications to adapt the code to specific needs. It includes the following pipelines: 1. Benchmarking script for large language models 2. Text generation C++ samples that support most popular models like LLaMA 2 3. Stable Diffuison (with LoRA) C++ image generation pipeline 4. Latent Consistency Model (with LoRA) C++ image generation pipeline
funcchain
Funcchain is a Python library that allows you to easily write cognitive systems by leveraging Pydantic models as output schemas and LangChain in the backend. It provides a seamless integration of LLMs into your apps, utilizing OpenAI Functions or LlamaCpp grammars (json-schema-mode) for efficient structured output. Funcchain compiles the Funcchain syntax into LangChain runnables, enabling you to invoke, stream, or batch process your pipelines effortlessly.

IntelliNode
IntelliNode is a javascript module that integrates cutting-edge AI models like ChatGPT, LLaMA, WaveNet, Gemini, and Stable diffusion into projects. It offers functions for generating text, speech, and images, as well as semantic search, multi-model evaluation, and chatbot capabilities. The module provides a wrapper layer for low-level model access, a controller layer for unified input handling, and a function layer for abstract functionality tailored to various use cases.

instructor
Instructor is a tool that provides structured outputs from Large Language Models (LLMs) in a reliable manner. It simplifies the process of extracting structured data by utilizing Pydantic for validation, type safety, and IDE support. With Instructor, users can define models and easily obtain structured data without the need for complex JSON parsing, error handling, or retries. The tool supports automatic retries, streaming support, and extraction of nested objects, making it production-ready for various AI applications. Trusted by a large community of developers and companies, Instructor is used by teams at OpenAI, Google, Microsoft, AWS, and YC startups.
For similar tasks
volga
Volga is a general purpose real-time data processing engine in Python for modern AI/ML systems. It aims to be a Python-native alternative to Flink/Spark Streaming with extended functionality for real-time AI/ML workloads. It provides a hybrid push+pull architecture, Entity API for defining data entities and feature pipelines, DataStream API for general data processing, and customizable data connectors. Volga can run on a laptop or a distributed cluster, making it suitable for building custom real-time AI/ML feature platforms or general data pipelines without relying on third-party platforms.
For similar jobs
Awesome_Mamba
Awesome Mamba is a curated collection of groundbreaking research papers and articles on Mamba Architecture, a pioneering framework in deep learning known for its selective state spaces and efficiency in processing complex data structures. The repository offers a comprehensive exploration of Mamba architecture through categorized research papers covering various domains like visual recognition, speech processing, remote sensing, video processing, activity recognition, image enhancement, medical imaging, reinforcement learning, natural language processing, 3D recognition, multi-modal understanding, time series analysis, graph neural networks, point cloud analysis, and tabular data handling.

unilm
The 'unilm' repository is a collection of tools, models, and architectures for Foundation Models and General AI, focusing on tasks such as NLP, MT, Speech, Document AI, and Multimodal AI. It includes various pre-trained models, such as UniLM, InfoXLM, DeltaLM, MiniLM, AdaLM, BEiT, LayoutLM, WavLM, VALL-E, and more, designed for tasks like language understanding, generation, translation, vision, speech, and multimodal processing. The repository also features toolkits like s2s-ft for sequence-to-sequence fine-tuning and Aggressive Decoding for efficient sequence-to-sequence decoding. Additionally, it offers applications like TrOCR for OCR, LayoutReader for reading order detection, and XLM-T for multilingual NMT.
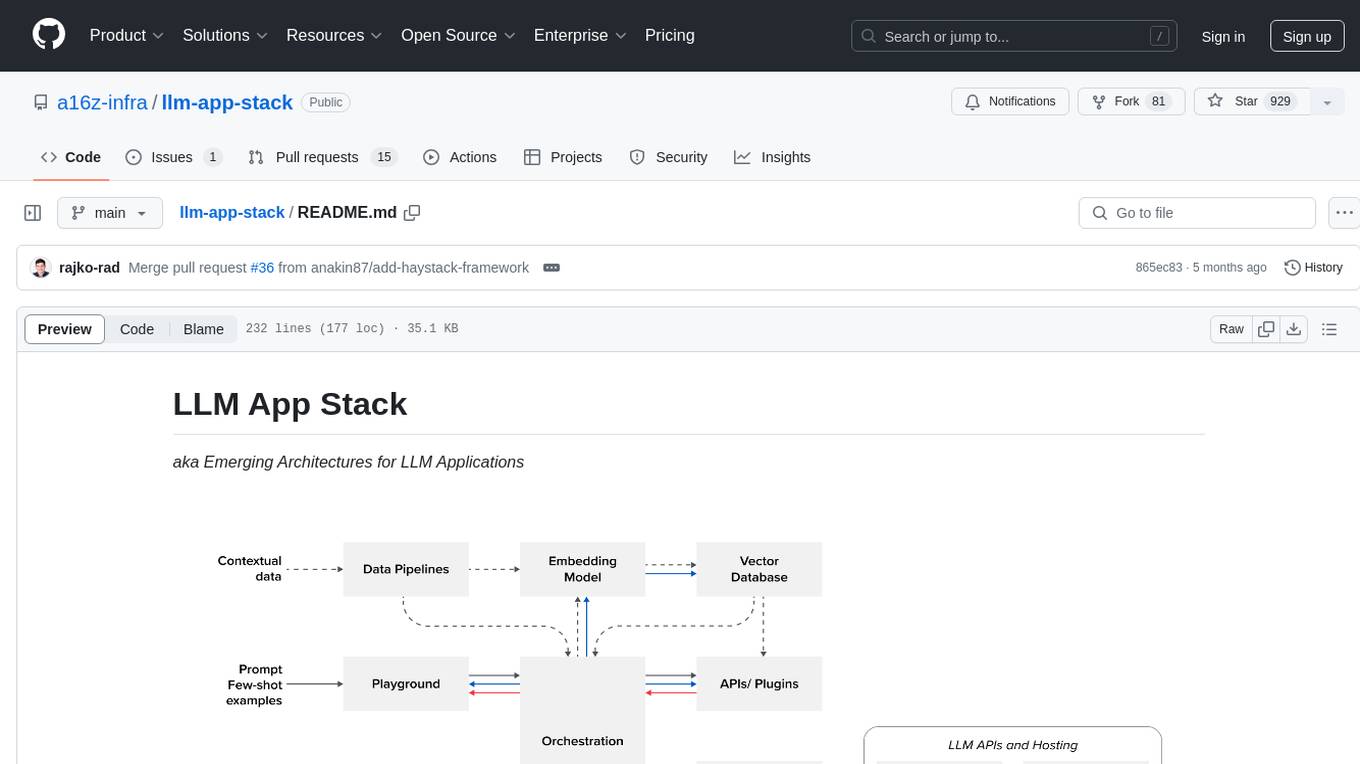
llm-app-stack
LLM App Stack, also known as Emerging Architectures for LLM Applications, is a comprehensive list of available tools, projects, and vendors at each layer of the LLM app stack. It covers various categories such as Data Pipelines, Embedding Models, Vector Databases, Playgrounds, Orchestrators, APIs/Plugins, LLM Caches, Logging/Monitoring/Eval, Validators, LLM APIs (proprietary and open source), App Hosting Platforms, Cloud Providers, and Opinionated Clouds. The repository aims to provide a detailed overview of tools and projects for building, deploying, and maintaining enterprise data solutions, AI models, and applications.
awesome-deeplogic
Awesome deep logic is a curated list of papers and resources focusing on integrating symbolic logic into deep neural networks. It includes surveys, tutorials, and research papers that explore the intersection of logic and deep learning. The repository aims to provide valuable insights and knowledge on how logic can be used to enhance reasoning, knowledge regularization, weak supervision, and explainability in neural networks.

Awesome-LLMs-on-device
Welcome to the ultimate hub for on-device Large Language Models (LLMs)! This repository is your go-to resource for all things related to LLMs designed for on-device deployment. Whether you're a seasoned researcher, an innovative developer, or an enthusiastic learner, this comprehensive collection of cutting-edge knowledge is your gateway to understanding, leveraging, and contributing to the exciting world of on-device LLMs.
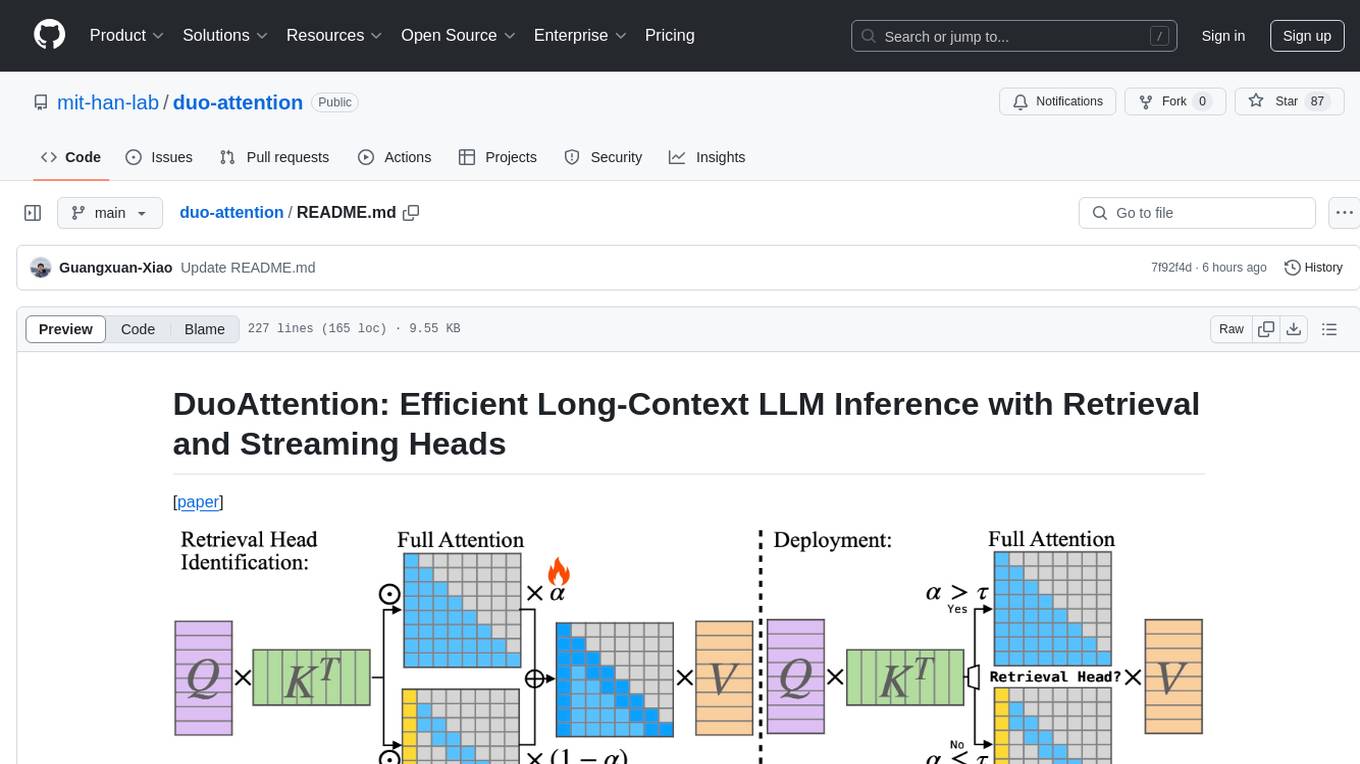
duo-attention
DuoAttention is a framework designed to optimize long-context large language models (LLMs) by reducing memory and latency during inference without compromising their long-context abilities. It introduces a concept of Retrieval Heads and Streaming Heads to efficiently manage attention across tokens. By applying a full Key and Value (KV) cache to retrieval heads and a lightweight, constant-length KV cache to streaming heads, DuoAttention achieves significant reductions in memory usage and decoding time for LLMs. The framework uses an optimization-based algorithm with synthetic data to accurately identify retrieval heads, enabling efficient inference with minimal accuracy loss compared to full attention. DuoAttention also supports quantization techniques for further memory optimization, allowing for decoding of up to 3.3 million tokens on a single GPU.
llm_note
LLM notes repository contains detailed analysis on transformer models, language model compression, inference and deployment, high-performance computing, and system optimization methods. It includes discussions on various algorithms, frameworks, and performance analysis related to large language models and high-performance computing. The repository serves as a comprehensive resource for understanding and optimizing language models and computing systems.

Awesome-Resource-Efficient-LLM-Papers
A curated list of high-quality papers on resource-efficient Large Language Models (LLMs) with a focus on various aspects such as architecture design, pre-training, fine-tuning, inference, system design, and evaluation metrics. The repository covers topics like efficient transformer architectures, non-transformer architectures, memory efficiency, data efficiency, model compression, dynamic acceleration, deployment optimization, support infrastructure, and other related systems. It also provides detailed information on computation metrics, memory metrics, energy metrics, financial cost metrics, network communication metrics, and other metrics relevant to resource-efficient LLMs. The repository includes benchmarks for evaluating the efficiency of NLP models and references for further reading.