
neo4j-genai-python
Neo4j GenAI for Python
Stars: 88
This repository contains the official Neo4j GenAI features for Python. The purpose of this package is to provide a first-party package to developers, where Neo4j can guarantee long-term commitment and maintenance as well as being fast to ship new features and high-performing patterns and methods.
README:
This repository contains the official Neo4j GenAI features for Python.
The purpose of this package is to provide a first party package to developers, where Neo4j can guarantee long term commitment and maintenance as well as being fast to ship new features and high performing patterns and methods.
Documentation: https://neo4j.com/docs/neo4j-genai-python/
Python versions supported:
- Python 3.12 supported.
- Python 3.11 supported.
- Python 3.10 supported.
- Python 3.9 supported.
- Python 3.8 supported.
This package requires Python (>=3.8.1).
To install the latest stable version, use:
pip install neo4j-genaiWhen creating a vector index, make sure you match the number of dimensions in the index with the number of dimensions the embeddings have.
Assumption: Neo4j running
from neo4j import GraphDatabase
from neo4j_genai.indexes import create_vector_index
URI = "neo4j://localhost:7687"
AUTH = ("neo4j", "password")
INDEX_NAME = "vector-index-name"
# Connect to Neo4j database
driver = GraphDatabase.driver(URI, auth=AUTH)
# Creating the index
create_vector_index(
driver,
INDEX_NAME,
label="Document",
embedding_property="vectorProperty",
dimensions=1536,
similarity_fn="euclidean",
)Note that the below example is not the only way you can upsert data into your Neo4j database. For example, you could also leverage the Neo4j Python driver.
Assumption: Neo4j running with a defined vector index
from neo4j import GraphDatabase
from neo4j_genai.indexes import upsert_vector
URI = "neo4j://localhost:7687"
AUTH = ("neo4j", "password")
# Connect to Neo4j database
driver = GraphDatabase.driver(URI, auth=AUTH)
# Upsert the vector
vector = ...
upsert_vector(
driver,
node_id=1,
embedding_property="vectorProperty",
vector=vector,
)Assumption: Neo4j running with populated vector index in place.
Limitation: The query over the vector index is an approximate nearest neighbor search and may not give exact results. See this reference for more details.
While the library has more retrievers than shown here, the following examples should be able to get you started.
In the following example, we use a simple vector search as retriever,
that will perform a similarity search over the index-name vector index
in Neo4j.
from neo4j import GraphDatabase
from neo4j_genai.retrievers import VectorRetriever
from neo4j_genai.llm import OpenAILLM
from neo4j_genai.generation import GraphRAG
from neo4j_genai.embeddings.openai import OpenAIEmbeddings
URI = "neo4j://localhost:7687"
AUTH = ("neo4j", "password")
INDEX_NAME = "vector-index-name"
# Connect to Neo4j database
driver = GraphDatabase.driver(URI, auth=AUTH)
# Create Embedder object
embedder = OpenAIEmbeddings(model="text-embedding-3-large")
# Initialize the retriever
retriever = VectorRetriever(driver, INDEX_NAME, embedder)
# Initialize the LLM
# Note: An OPENAI_API_KEY environment variable is required here
llm = OpenAILLM(model_name="gpt-4o", model_params={"temperature": 0})
# Initialize the RAG pipeline
rag = GraphRAG(retriever=retriever, llm=llm)
# Query the graph
query_text = "How do I do similarity search in Neo4j?"
response = rag.search(query_text=query_text, retriever_config={"top_k": 5})
print(response.answer)poetry installIf you have a bug to report or feature to request, first search to see if an issue already exists. If a related issue doesn't exist, please raise a new issue using the relevant issue form.
If you're a Neo4j Enterprise customer, you can also reach out to Customer Support.
If you don't have a bug to report or feature request, but you need a hand with the library; community support is available via Neo4j Online Community and/or Discord.
- Fork the repository.
- Install Python and Poetry.
- Create a working branch from
mainand start with your changes!
When you're finished with your changes, create a pull request, also known as a PR.
- Ensure that you have signed the CLA.
- Ensure that the base of your PR is set to
main. - Don't forget to link your PR to an issue if you are solving one.
- Enable the checkbox to allow maintainer edits so that maintainers can make any necessary tweaks and update your branch for merge.
- Reviewers may ask for changes to be made before a PR can be merged, either using suggested changes or normal pull request comments. You can apply suggested changes directly through the UI, and any other changes can be made in your fork and committed to the PR branch.
- As you update your PR and apply changes, mark each conversation as resolved.
- Update the
CHANGELOG.mdif you have made significant changes to the project, these include:- Major changes:
- New features
- Bug fixes with high impact
- Breaking changes
- Minor changes:
- Documentation improvements
- Code refactoring without functional impact
- Minor bug fixes
- Major changes:
- Keep
CHANGELOG.mdchanges brief and focus on the most important changes.
- When opening a PR, you can generate an edit suggestion by commenting on the GitHub PR using CodiumAI:
@CodiumAI-Agent /update_changelog
- Use this as a suggestion and update the
CHANGELOG.mdcontent under 'Next'. - Commit the changes.
This should run out of the box once the dependencies are installed.
poetry run pytest tests/unitTo run e2e tests you'd need to have some services running locally:
- neo4j
- weaviate
- weaviate-text2vec-transformers
The easiest way to get it up and running is via Docker compose:
docker compose -f tests/e2e/docker-compose.yml up(pro tip: if you suspect something in the databases are cached, run docker compose -f tests/e2e/docker-compose.yml down to remove them completely)
Once the services are running, execute the following command to run the e2e tests.
poetry run pytest tests/e2eFor Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for neo4j-genai-python
Similar Open Source Tools
neo4j-genai-python
This repository contains the official Neo4j GenAI features for Python. The purpose of this package is to provide a first-party package to developers, where Neo4j can guarantee long-term commitment and maintenance as well as being fast to ship new features and high-performing patterns and methods.

aiac
AIAC is a library and command line tool to generate Infrastructure as Code (IaC) templates, configurations, utilities, queries, and more via LLM providers such as OpenAI, Amazon Bedrock, and Ollama. Users can define multiple 'backends' targeting different LLM providers and environments using a simple configuration file. The tool allows users to ask a model to generate templates for different scenarios and composes an appropriate request to the selected provider, storing the resulting code to a file and/or printing it to standard output.

tonic_validate
Tonic Validate is a framework for the evaluation of LLM outputs, such as Retrieval Augmented Generation (RAG) pipelines. Validate makes it easy to evaluate, track, and monitor your LLM and RAG applications. Validate allows you to evaluate your LLM outputs through the use of our provided metrics which measure everything from answer correctness to LLM hallucination. Additionally, Validate has an optional UI to visualize your evaluation results for easy tracking and monitoring.
dravid
Dravid (DRD) is an advanced, AI-powered CLI coding framework designed to follow user instructions until the job is completed, including fixing errors. It can generate code, fix errors, handle image queries, manage file operations, integrate with external APIs, and provide a development server with error handling. Dravid is extensible and requires Python 3.7+ and CLAUDE_API_KEY. Users can interact with Dravid through CLI commands for various tasks like creating projects, asking questions, generating content, handling metadata, and file-specific queries. It supports use cases like Next.js project development, working with existing projects, exploring new languages, Ruby on Rails project development, and Python project development. Dravid's project structure includes directories for source code, CLI modules, API interaction, utility functions, AI prompt templates, metadata management, and tests. Contributions are welcome, and development setup involves cloning the repository, installing dependencies with Poetry, setting up environment variables, and using Dravid for project enhancements.
cog-comfyui
Cog-comfyui allows users to run ComfyUI workflows on Replicate. ComfyUI is a visual programming tool for creating and sharing generative art workflows. With cog-comfyui, users can access a variety of pre-trained models and custom nodes to create their own unique artworks. The tool is easy to use and does not require any coding experience. Users simply need to upload their API JSON file and any necessary input files, and then click the "Run" button. Cog-comfyui will then generate the output image or video file.

cog-comfyui
Cog-ComfyUI is a tool designed to run ComfyUI workflows on Replicate. It allows users to easily integrate their own workflows into their app or website using the Replicate API. The tool includes popular model weights and custom nodes, with the option to request more custom nodes or models. Users can get their API JSON, gather input files, and use custom LoRAs from CivitAI or HuggingFace. Additionally, users can run their workflows and set up their own dedicated instances for better performance and control. The tool provides options for private deployments, forking using Cog, or creating new models from the train tab on Replicate. It also offers guidance on developing locally and running the Web UI from a Cog container.

vectara-answer
Vectara Answer is a sample app for Vectara-powered Summarized Semantic Search (or question-answering) with advanced configuration options. For examples of what you can build with Vectara Answer, check out Ask News, LegalAid, or any of the other demo applications.

ray-llm
RayLLM (formerly known as Aviary) is an LLM serving solution that makes it easy to deploy and manage a variety of open source LLMs, built on Ray Serve. It provides an extensive suite of pre-configured open source LLMs, with defaults that work out of the box. RayLLM supports Transformer models hosted on Hugging Face Hub or present on local disk. It simplifies the deployment of multiple LLMs, the addition of new LLMs, and offers unique autoscaling support, including scale-to-zero. RayLLM fully supports multi-GPU & multi-node model deployments and offers high performance features like continuous batching, quantization and streaming. It provides a REST API that is similar to OpenAI's to make it easy to migrate and cross test them. RayLLM supports multiple LLM backends out of the box, including vLLM and TensorRT-LLM.
MCP2Lambda
MCP2Lambda is a server that acts as a bridge between MCP clients and AWS Lambda functions, allowing generative AI models to access and run Lambda functions as tools. It enables Large Language Models (LLMs) to interact with Lambda functions without code changes, providing access to private resources, AWS services, private networks, and the public internet. The server supports autodiscovery of Lambda functions and their invocation by name with parameters. It standardizes AI model access to external tools using the MCP protocol.
Bard-API
The Bard API is a Python package that returns responses from Google Bard through the value of a cookie. It is an unofficial API that operates through reverse-engineering, utilizing cookie values to interact with Google Bard for users struggling with frequent authentication problems or unable to authenticate via Google Authentication. The Bard API is not a free service, but rather a tool provided to assist developers with testing certain functionalities due to the delayed development and release of Google Bard's API. It has been designed with a lightweight structure that can easily adapt to the emergence of an official API. Therefore, using it for any other purposes is strongly discouraged. If you have access to a reliable official PaLM-2 API or Google Generative AI API, replace the provided response with the corresponding official code. Check out https://github.com/dsdanielpark/Bard-API/issues/262.

Guardrails
Guardrails is a security tool designed to help developers identify and fix security vulnerabilities in their code. It provides automated scanning and analysis of code repositories to detect potential security issues, such as sensitive data exposure, injection attacks, and insecure configurations. By integrating Guardrails into the development workflow, teams can proactively address security concerns and reduce the risk of security breaches. The tool offers detailed reports and actionable recommendations to guide developers in remediation efforts, ultimately improving the overall security posture of the codebase. Guardrails supports multiple programming languages and frameworks, making it versatile and adaptable to different development environments. With its user-friendly interface and seamless integration with popular version control systems, Guardrails empowers developers to prioritize security without compromising productivity.

SWELancer-Benchmark
SWE-Lancer is a benchmark repository containing datasets and code for the paper 'SWE-Lancer: Can Frontier LLMs Earn $1 Million from Real-World Freelance Software Engineering?'. It provides instructions for package management, building Docker images, configuring environment variables, and running evaluations. Users can use this tool to assess the performance of language models in real-world freelance software engineering tasks.

langchain
LangChain is a framework for developing Elixir applications powered by language models. It enables applications to connect language models to other data sources and interact with the environment. The library provides components for working with language models and off-the-shelf chains for specific tasks. It aims to assist in building applications that combine large language models with other sources of computation or knowledge. LangChain is written in Elixir and is not aimed for parity with the JavaScript and Python versions due to differences in programming paradigms and design choices. The library is designed to make it easy to integrate language models into applications and expose features, data, and functionality to the models.
LLMFlex
LLMFlex is a python package designed for developing AI applications with local Large Language Models (LLMs). It provides classes to load LLM models, embedding models, and vector databases to create AI-powered solutions with prompt engineering and RAG techniques. The package supports multiple LLMs with different generation configurations, embedding toolkits, vector databases, chat memories, prompt templates, custom tools, and a chatbot frontend interface. Users can easily create LLMs, load embeddings toolkit, use tools, chat with models in a Streamlit web app, and serve an OpenAI API with a GGUF model. LLMFlex aims to offer a simple interface for developers to work with LLMs and build private AI solutions using local resources.

vulnerability-analysis
The NVIDIA AI Blueprint for Vulnerability Analysis for Container Security showcases accelerated analysis on common vulnerabilities and exposures (CVE) at an enterprise scale, reducing mitigation time from days to seconds. It enables security analysts to determine software package vulnerabilities using large language models (LLMs) and retrieval-augmented generation (RAG). The blueprint is designed for security analysts, IT engineers, and AI practitioners in cybersecurity. It requires NVAIE developer license and API keys for vulnerability databases, search engines, and LLM model services. Hardware requirements include L40 GPU for pipeline operation and optional LLM NIM and Embedding NIM. The workflow involves LLM pipeline for CVE impact analysis, utilizing LLM planner, agent, and summarization nodes. The blueprint uses NVIDIA NIM microservices and Morpheus Cybersecurity AI SDK for vulnerability analysis.
ygo-agent
YGO Agent is a project focused on using deep learning to master the Yu-Gi-Oh! trading card game. It utilizes reinforcement learning and large language models to develop advanced AI agents that aim to surpass human expert play. The project provides a platform for researchers and players to explore AI in complex, strategic game environments.
For similar tasks
neo4j-genai-python
This repository contains the official Neo4j GenAI features for Python. The purpose of this package is to provide a first-party package to developers, where Neo4j can guarantee long-term commitment and maintenance as well as being fast to ship new features and high-performing patterns and methods.
neo4j-graphrag-python
The Neo4j GraphRAG package for Python is an official repository that provides features for creating and managing vector indexes in Neo4j databases. It aims to offer developers a reliable package with long-term commitment, maintenance, and fast feature updates. The package supports various Python versions and includes functionalities for creating vector indexes, populating them, and performing similarity searches. It also provides guidelines for installation, examples, and development processes such as installing dependencies, making changes, and running tests.

genai-os
Kuwa GenAI OS is an open, free, secure, and privacy-focused Generative-AI Operating System. It provides a multi-lingual turnkey solution for GenAI development and deployment on Linux and Windows. Users can enjoy features such as concurrent multi-chat, quoting, full prompt-list import/export/share, and flexible orchestration of prompts, RAGs, bots, models, and hardware/GPUs. The system supports various environments from virtual hosts to cloud, and it is open source, allowing developers to contribute and customize according to their needs.
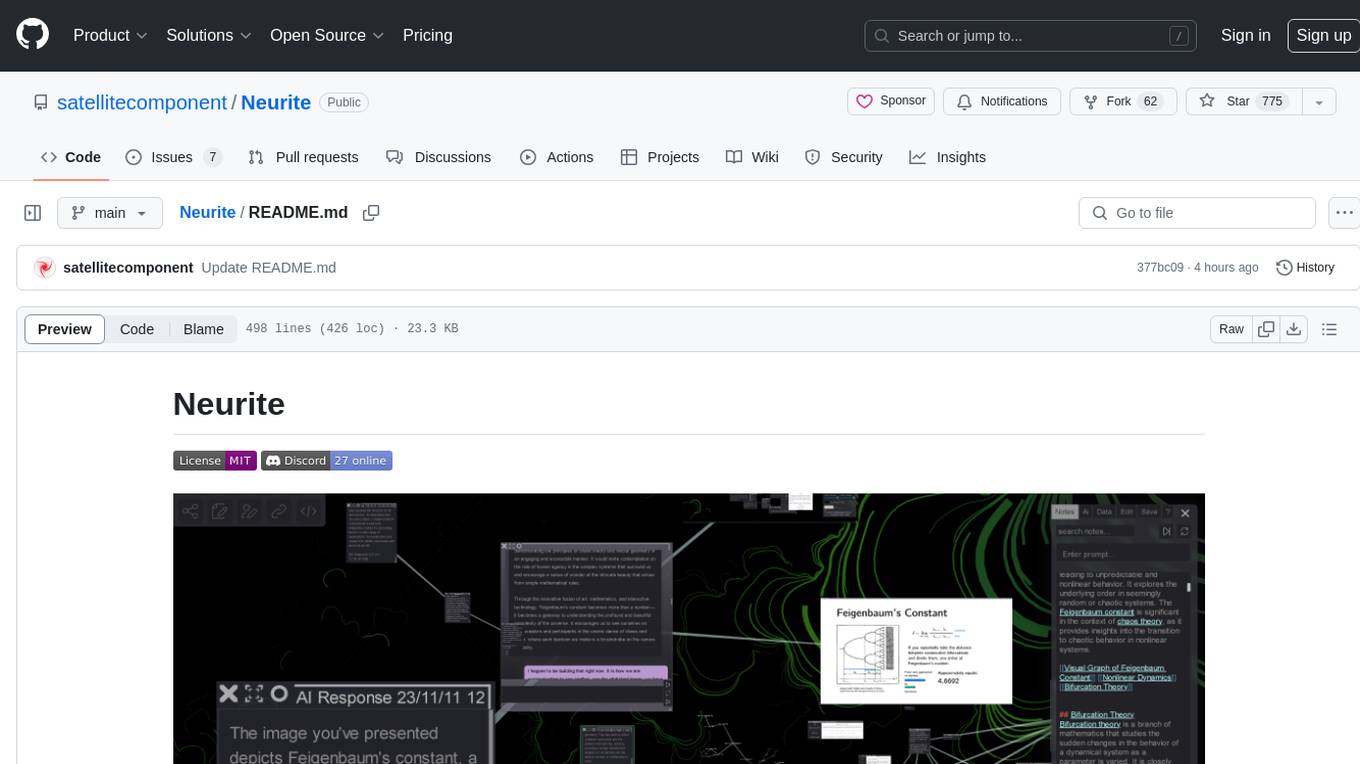
Neurite
Neurite is an innovative project that combines chaos theory and graph theory to create a digital interface that explores hidden patterns and connections for creative thinking. It offers a unique workspace blending fractals with mind mapping techniques, allowing users to navigate the Mandelbrot set in real-time. Nodes in Neurite represent various content types like text, images, videos, code, and AI agents, enabling users to create personalized microcosms of thoughts and inspirations. The tool supports synchronized knowledge management through bi-directional synchronization between mind-mapping and text-based hyperlinking. Neurite also features FractalGPT for modular conversation with AI, local AI capabilities for multi-agent chat networks, and a Neural API for executing code and sequencing animations. The project is actively developed with plans for deeper fractal zoom, advanced control over node placement, and experimental features.

fast-stable-diffusion
Fast-stable-diffusion is a project that offers notebooks for RunPod, Paperspace, and Colab Pro adaptations with AUTOMATIC1111 Webui and Dreambooth. It provides tools for running and implementing Dreambooth, a stable diffusion project. The project includes implementations by XavierXiao and is sponsored by Runpod, Paperspace, and Colab Pro.
big-AGI
big-AGI is an AI suite designed for professionals seeking function, form, simplicity, and speed. It offers best-in-class Chats, Beams, and Calls with AI personas, visualizations, coding, drawing, side-by-side chatting, and more, all wrapped in a polished UX. The tool is powered by the latest models from 12 vendors and open-source servers, providing users with advanced AI capabilities and a seamless user experience. With continuous updates and enhancements, big-AGI aims to stay ahead of the curve in the AI landscape, catering to the needs of both developers and AI enthusiasts.
generative-ai
This repository contains codes related to Generative AI as per YouTube video. It includes various notebooks and files for different days covering topics like map reduce, text to SQL, LLM parameters, tagging, and Kaggle competition. The repository also includes resources like PDF files and databases for different projects related to Generative AI.
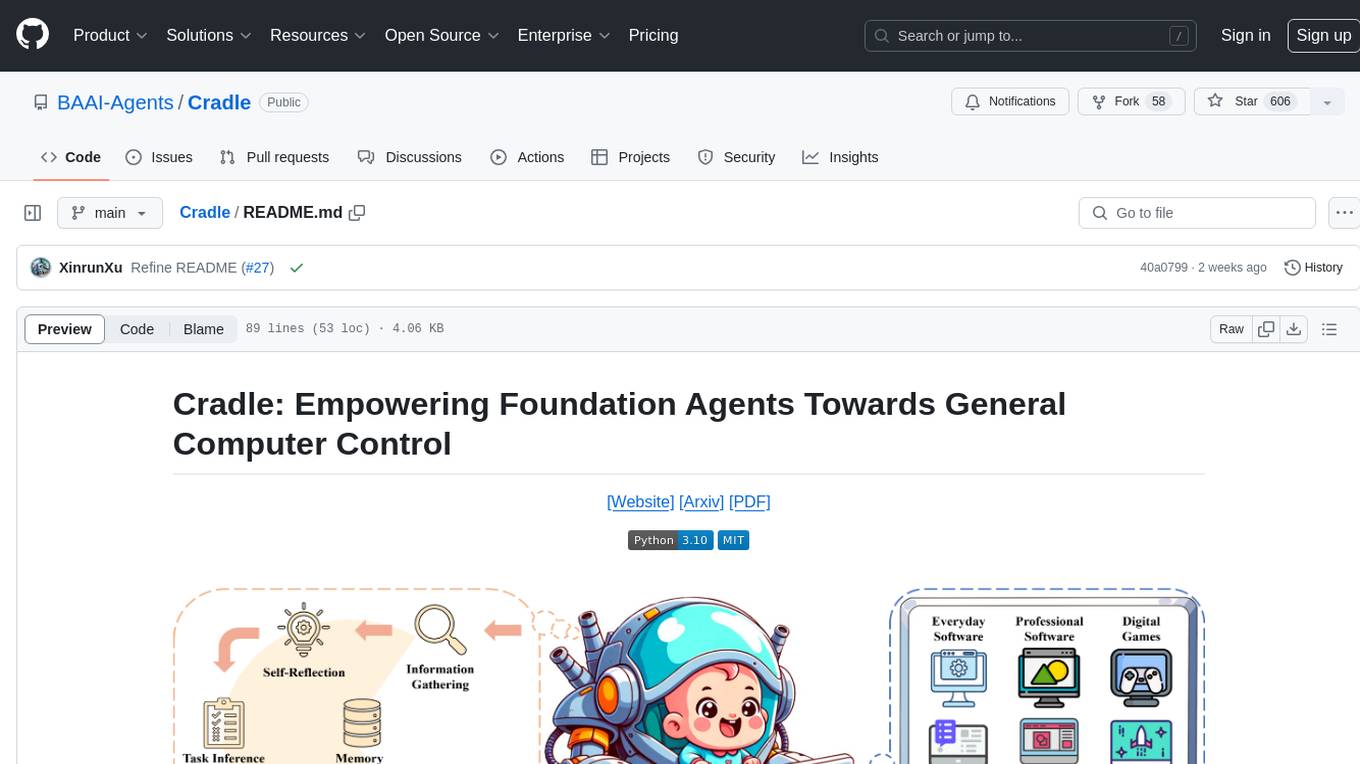
Cradle
The Cradle project is a framework designed for General Computer Control (GCC), empowering foundation agents to excel in various computer tasks through strong reasoning abilities, self-improvement, and skill curation. It provides a standardized environment with minimal requirements, constantly evolving to support more games and software. The repository includes released versions, publications, and relevant assets.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.