
logfire
AI observability platform for production LLM and agent systems.
Stars: 4009
Pydantic Logfire is an observability platform that provides simple and powerful dashboard, Python-centric insights, SQL querying, OpenTelemetry integration, and Pydantic validation analytics. It offers unparalleled visibility into Python applications' behavior and allows querying data using standard SQL. Logfire is an opinionated wrapper around OpenTelemetry, supporting traces, metrics, and logs. The Python SDK for logfire is open source, while the server application for recording and displaying data is closed source.
README:
![]()



From the team behind Pydantic Validation, Pydantic Logfire is an observability platform built on the same belief as our open source library — that the most powerful tools can be easy to use.
What sets Logfire apart:
- Simple and Powerful: Logfire's dashboard is simple relative to the power it provides, ensuring your entire engineering team will actually use it.
- Python-centric Insights: From rich display of Python objects, to event-loop telemetry, to profiling Python code and database queries, Logfire gives you unparalleled visibility into your Python application's behavior.
- SQL: Query your data using standard SQL — all the control and (for many) nothing new to learn. Using SQL also means you can query your data with existing BI tools and database querying libraries.
- OpenTelemetry: Logfire is an opinionated wrapper around OpenTelemetry, allowing you to leverage existing tooling, infrastructure, and instrumentation for many common Python packages, and enabling support for virtually any language. We offer full support for all OpenTelemetry signals (traces, metrics and logs).
- Pydantic Integration: Understand the data flowing through your Pydantic Validation models and get built-in analytics on validations.
See the documentation for more information.
Feel free to report issues and ask any questions about Logfire in this repository!
This repo contains the Python SDK for logfire and documentation; the server application for recording and displaying data is closed source.
This is a very brief overview of how to use Logfire, the documentation has much more detail.
pip install logfirelogfire authHere's a simple manual tracing (aka logging) example:
from datetime import date
import logfire
logfire.configure()
logfire.info('Hello, {name}!', name='world')
with logfire.span('Asking the user their {question}', question='age'):
user_input = input('How old are you [YYYY-mm-dd]? ')
dob = date.fromisoformat(user_input)
logfire.debug('{dob=} {age=!r}', dob=dob, age=date.today() - dob)Or you can also avoid manual instrumentation and instead integrate with lots of popular packages, here's an example of integrating with FastAPI:
from fastapi import FastAPI
from pydantic import BaseModel
import logfire
app = FastAPI()
logfire.configure()
logfire.instrument_fastapi(app)
# next, instrument your database connector, http library etc. and add the logging handler
class User(BaseModel):
name: str
country_code: str
@app.post('/')
async def add_user(user: User):
# we would store the user here
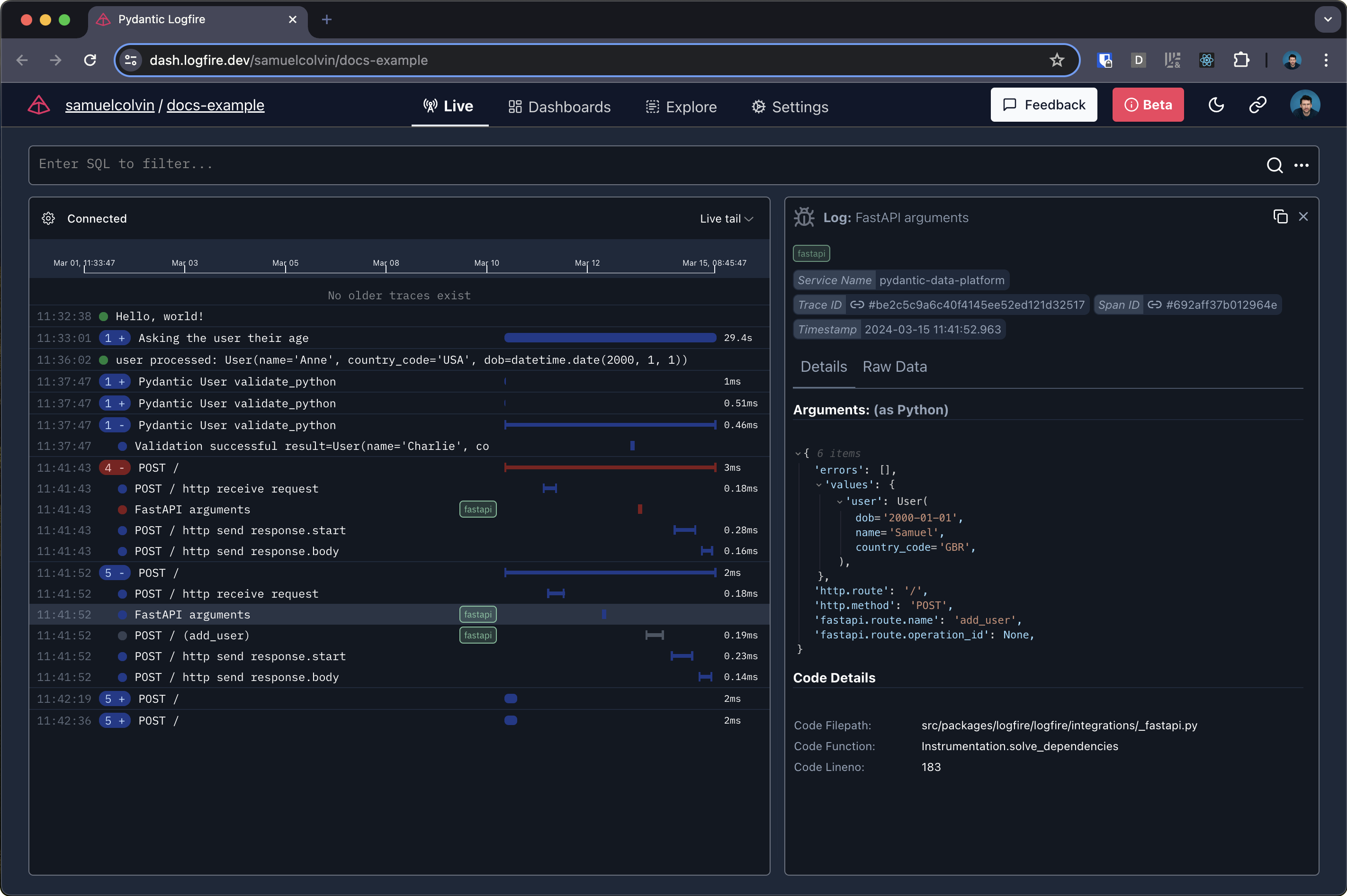
return {'message': f'{user.name} added'}Logfire gives you a view into how your code is running like this:
We'd love anyone interested to contribute to the Logfire SDK and documentation, see the contributing guide.
See our security policy.
The Logfire SDKs (we also have them for TypeScript and Rust) are open source, and you can use them to export data to any OTel-compatible backend.
The Logfire platform (the UI and backend) is closed source. You can self-host it by purchasing an enterprise license.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for logfire
Similar Open Source Tools
logfire
Pydantic Logfire is an observability platform that provides simple and powerful dashboard, Python-centric insights, SQL querying, OpenTelemetry integration, and Pydantic validation analytics. It offers unparalleled visibility into Python applications' behavior and allows querying data using standard SQL. Logfire is an opinionated wrapper around OpenTelemetry, supporting traces, metrics, and logs. The Python SDK for logfire is open source, while the server application for recording and displaying data is closed source.

graphiti
Graphiti is a framework for building and querying temporally-aware knowledge graphs, tailored for AI agents in dynamic environments. It continuously integrates user interactions, structured and unstructured data, and external information into a coherent, queryable graph. The framework supports incremental data updates, efficient retrieval, and precise historical queries without complete graph recomputation, making it suitable for developing interactive, context-aware AI applications.

llama_index
LlamaIndex is a data framework for building LLM applications. It provides tools for ingesting, structuring, and querying data, as well as integrating with LLMs and other tools. LlamaIndex is designed to be easy to use for both beginner and advanced users, and it provides a comprehensive set of features for building LLM applications.

BentoML
BentoML is an open-source model serving library for building performant and scalable AI applications with Python. It comes with everything you need for serving optimization, model packaging, and production deployment.

deep-research
Deep Research is a lightning-fast tool that uses powerful AI models to generate comprehensive research reports in just a few minutes. It leverages advanced 'Thinking' and 'Task' models, combined with an internet connection, to provide fast and insightful analysis on various topics. The tool ensures privacy by processing and storing all data locally. It supports multi-platform deployment, offers support for various large language models, web search functionality, knowledge graph generation, research history preservation, local and server API support, PWA technology, multi-key payload support, multi-language support, and is built with modern technologies like Next.js and Shadcn UI. Deep Research is open-source under the MIT License.

premsql
PremSQL is an open-source library designed to help developers create secure, fully local Text-to-SQL solutions using small language models. It provides essential tools for building and deploying end-to-end Text-to-SQL pipelines with customizable components, ideal for secure, autonomous AI-powered data analysis. The library offers features like Local-First approach, Customizable Datasets, Robust Executors and Evaluators, Advanced Generators, Error Handling and Self-Correction, Fine-Tuning Support, and End-to-End Pipelines. Users can fine-tune models, generate SQL queries from natural language inputs, handle errors, and evaluate model performance against predefined metrics. PremSQL is extendible for customization and private data usage.
lunary
Lunary is an open-source observability and prompt platform for Large Language Models (LLMs). It provides a suite of features to help AI developers take their applications into production, including analytics, monitoring, prompt templates, fine-tuning dataset creation, chat and feedback tracking, and evaluations. Lunary is designed to be usable with any model, not just OpenAI, and is easy to integrate and self-host.
tinystruct
Tinystruct is a simple Java framework designed for easy development with better performance. It offers a modern approach with features like CLI and web integration, built-in lightweight HTTP server, minimal configuration philosophy, annotation-based routing, and performance-first architecture. Developers can focus on real business logic without dealing with unnecessary complexities, making it transparent, predictable, and extensible.

sdialog
SDialog is an MIT-licensed open-source toolkit for building, simulating, and evaluating LLM-based conversational agents end-to-end. It aims to bridge agent construction, user simulation, dialog generation, and evaluation in a single reproducible workflow, enabling the generation of reliable, controllable dialog systems or data at scale. The toolkit standardizes a Dialog schema, offers persona-driven multi-agent simulation with LLMs, provides composable orchestration for precise control over behavior and flow, includes built-in evaluation metrics, and offers mechanistic interpretability. It allows for easy creation of user-defined components and interoperability across various AI platforms.

Biomni
Biomni is a general-purpose biomedical AI agent designed to autonomously execute a wide range of research tasks across diverse biomedical subfields. By integrating cutting-edge large language model (LLM) reasoning with retrieval-augmented planning and code-based execution, Biomni helps scientists dramatically enhance research productivity and generate testable hypotheses.

llm-answer-engine
This repository contains the code and instructions needed to build a sophisticated answer engine that leverages the capabilities of Groq, Mistral AI's Mixtral, Langchain.JS, Brave Search, Serper API, and OpenAI. Designed to efficiently return sources, answers, images, videos, and follow-up questions based on user queries, this project is an ideal starting point for developers interested in natural language processing and search technologies.

exospherehost
Exosphere is an open source infrastructure designed to run AI agents at scale for large data and long running flows. It allows developers to define plug and playable nodes that can be run on a reliable backbone in the form of a workflow, with features like dynamic state creation at runtime, infinite parallel agents, persistent state management, and failure handling. This enables the deployment of production agents that can scale beautifully to build robust autonomous AI workflows.

TaskWeaver
TaskWeaver is a code-first agent framework designed for planning and executing data analytics tasks. It interprets user requests through code snippets, coordinates various plugins to execute tasks in a stateful manner, and preserves both chat history and code execution history. It supports rich data structures, customized algorithms, domain-specific knowledge incorporation, stateful execution, code verification, easy debugging, security considerations, and easy extension. TaskWeaver is easy to use with CLI and WebUI support, and it can be integrated as a library. It offers detailed documentation, demo examples, and citation guidelines.

helix-db
HelixDB is a database designed specifically for AI applications, providing a single platform to manage all components needed for AI applications. It supports graph + vector data model and also KV, documents, and relational data. Key features include built-in tools for MCP, embeddings, knowledge graphs, RAG, security, logical isolation, and ultra-low latency. Users can interact with HelixDB using the Helix CLI tool and SDKs in TypeScript and Python. The roadmap includes features like organizational auth, server code improvements, 3rd party integrations, educational content, and binary quantisation for better performance. Long term projects involve developing in-house tools for knowledge graph ingestion, graph-vector storage engine, and network protocol & serdes libraries.

RainbowGPT
RainbowGPT is a versatile tool that offers a range of functionalities, including Stock Analysis for financial decision-making, MySQL Management for database navigation, and integration of AI technologies like GPT-4 and ChatGlm3. It provides a user-friendly interface suitable for all skill levels, ensuring seamless information flow and continuous expansion of emerging technologies. The tool enhances adaptability, creativity, and insight, making it a valuable asset for various projects and tasks.

cognee
Cognee is an open-source framework designed for creating self-improving deterministic outputs for Large Language Models (LLMs) using graphs, LLMs, and vector retrieval. It provides a platform for AI engineers to enhance their models and generate more accurate results. Users can leverage Cognee to add new information, utilize LLMs for knowledge creation, and query the system for relevant knowledge. The tool supports various LLM providers and offers flexibility in adding different data types, such as text files or directories. Cognee aims to streamline the process of working with LLMs and improving AI models for better performance and efficiency.
For similar tasks
logfire
Pydantic Logfire is an observability platform that provides simple and powerful dashboard, Python-centric insights, SQL querying, OpenTelemetry integration, and Pydantic validation analytics. It offers unparalleled visibility into Python applications' behavior and allows querying data using standard SQL. Logfire is an opinionated wrapper around OpenTelemetry, supporting traces, metrics, and logs. The Python SDK for logfire is open source, while the server application for recording and displaying data is closed source.

indexify
Indexify is an open-source engine for building fast data pipelines for unstructured data (video, audio, images, and documents) using reusable extractors for embedding, transformation, and feature extraction. LLM Applications can query transformed content friendly to LLMs by semantic search and SQL queries. Indexify keeps vector databases and structured databases (PostgreSQL) updated by automatically invoking the pipelines as new data is ingested into the system from external data sources. **Why use Indexify** * Makes Unstructured Data **Queryable** with **SQL** and **Semantic Search** * **Real-Time** Extraction Engine to keep indexes **automatically** updated as new data is ingested. * Create **Extraction Graph** to describe **data transformation** and extraction of **embedding** and **structured extraction**. * **Incremental Extraction** and **Selective Deletion** when content is deleted or updated. * **Extractor SDK** allows adding new extraction capabilities, and many readily available extractors for **PDF**, **Image**, and **Video** indexing and extraction. * Works with **any LLM Framework** including **Langchain**, **DSPy**, etc. * Runs on your laptop during **prototyping** and also scales to **1000s of machines** on the cloud. * Works with many **Blob Stores**, **Vector Stores**, and **Structured Databases** * We have even **Open Sourced Automation** to deploy to Kubernetes in production.
For similar jobs

db2rest
DB2Rest is a modern low-code REST DATA API platform that simplifies the development of intelligent applications. It seamlessly integrates existing and new databases with language models (LMs/LLMs) and vector stores, enabling the rapid delivery of context-aware, reasoning applications without vendor lock-in.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

airflow
Apache Airflow (or simply Airflow) is a platform to programmatically author, schedule, and monitor workflows. When workflows are defined as code, they become more maintainable, versionable, testable, and collaborative. Use Airflow to author workflows as directed acyclic graphs (DAGs) of tasks. The Airflow scheduler executes your tasks on an array of workers while following the specified dependencies. Rich command line utilities make performing complex surgeries on DAGs a snap. The rich user interface makes it easy to visualize pipelines running in production, monitor progress, and troubleshoot issues when needed.

airbyte-platform
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's low-code Connector Development Kit (CDK). Airbyte is used by data engineers and analysts at companies of all sizes to move data for a variety of purposes, including data warehousing, data analysis, and machine learning.

chronon
Chronon is a platform that simplifies and improves ML workflows by providing a central place to define features, ensuring point-in-time correctness for backfills, simplifying orchestration for batch and streaming pipelines, offering easy endpoints for feature fetching, and guaranteeing and measuring consistency. It offers benefits over other approaches by enabling the use of a broad set of data for training, handling large aggregations and other computationally intensive transformations, and abstracting away the infrastructure complexity of data plumbing.