
postgres-new
In-browser Postgres sandbox with AI assistance
Stars: 2246
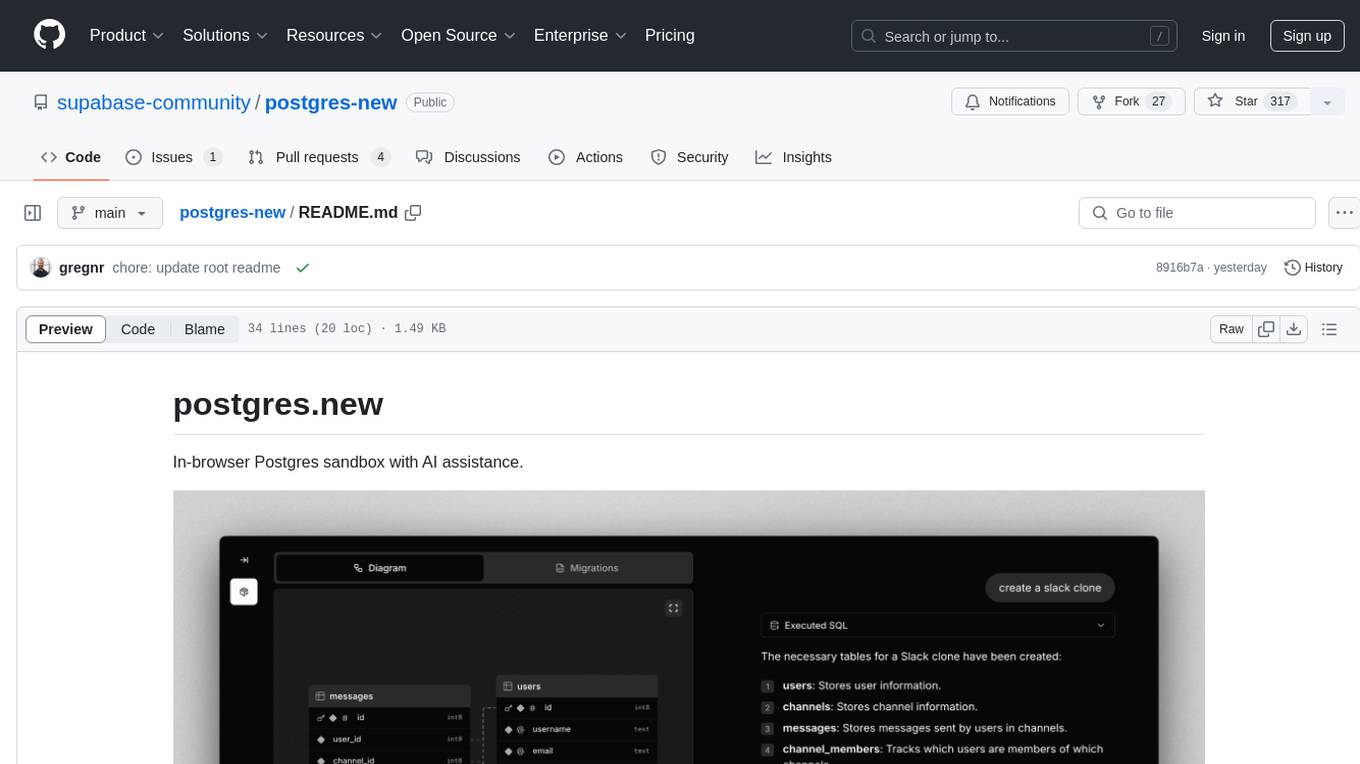
Postgres.new is an in-browser Postgres sandbox with AI assistance that allows users to spin up unlimited Postgres databases directly in the browser. Each database comes with a large language model (LLM) enabling features like drag-and-drop CSV import, report generation, chart creation, and database diagram building. The tool utilizes PGlite, a WASM version of Postgres, to run databases in the browser and store data in IndexedDB for persistence. The monorepo includes a frontend built with Next.js and a backend serving S3-backed PGlite databases over the PG wire protocol using pg-gateway.
README:
database.build (formerly postgres.new)
In-browser Postgres sandbox with AI assistance.
With database.build, you can instantly spin up an unlimited number of Postgres databases that run directly in your browser (and soon, deploy them to S3).
Each database is paired with a large language model (LLM) which opens the door to some interesting use cases:
- Drag-and-drop CSV import (generate table on the fly)
- Generate and export reports
- Generate charts
- Build database diagrams
All queries in database.build run directly in your browser. There’s no remote Postgres container or WebSocket proxy.
How is this possible? PGlite, a WASM version of Postgres that can run directly in your browser. Every database that you create spins up a new instance of PGlite that exposes a fully-functional Postgres database. Data is stored in IndexedDB so that changes persist after refresh.
This is a monorepo split into the following projects:
- Frontend (Next.js): This contains the primary web app built with Next.js
- Backend (pg-gateway): This serves S3-backed PGlite databases over the PG wire protocol using pg-gateway
This project is not an official Postgres project and we don’t want to mislead anyone! We’re renaming to database.build because, well, that’s what this does. This will still be 100% Postgres-focused, just with a different URL.
Apache 2.0
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for postgres-new
Similar Open Source Tools
postgres-new
Postgres.new is an in-browser Postgres sandbox with AI assistance that allows users to spin up unlimited Postgres databases directly in the browser. Each database comes with a large language model (LLM) enabling features like drag-and-drop CSV import, report generation, chart creation, and database diagram building. The tool utilizes PGlite, a WASM version of Postgres, to run databases in the browser and store data in IndexedDB for persistence. The monorepo includes a frontend built with Next.js and a backend serving S3-backed PGlite databases over the PG wire protocol using pg-gateway.

llm-app
Pathway's LLM (Large Language Model) Apps provide a platform to quickly deploy AI applications using the latest knowledge from data sources. The Python application examples in this repository are Docker-ready, exposing an HTTP API to the frontend. These apps utilize the Pathway framework for data synchronization, API serving, and low-latency data processing without the need for additional infrastructure dependencies. They connect to document data sources like S3, Google Drive, and Sharepoint, offering features like real-time data syncing, easy alert setup, scalability, monitoring, security, and unification of application logic.
csghub-server
CSGHub Server is a part of the open source and reliable large model assets management platform - CSGHub. It focuses on management of models, datasets, and other LLM assets through REST API. Key features include creation and management of users and organizations, auto-tagging of model and dataset labels, search functionality, online preview of dataset files, content moderation for text and image, download of individual files, tracking of model and dataset activity data. The tool is extensible and customizable, supporting different git servers, flexible LFS storage system configuration, and content moderation options. The roadmap includes support for more Git servers, Git LFS, dataset online viewer, model/dataset auto-tag, S3 protocol support, model format conversion, and model one-click deploy. The project is licensed under Apache 2.0 and welcomes contributions.

coral-cloud
Coral Cloud Resorts is a sample hospitality application that showcases Data Cloud, Agents, and Prompts. It provides highly personalized guest experiences through smart automation, content generation, and summarization. The app requires licenses for Data Cloud, Agents, Prompt Builder, and Einstein for Sales. Users can activate features, deploy metadata, assign permission sets, import sample data, and troubleshoot common issues. Additionally, the repository offers integration with modern web development tools like Prettier, ESLint, and pre-commit hooks for code formatting and linting.

singulatron
Singulatron is an AI Superplatform that runs on your computer(s) and server(s) without using third party APIs, providing complete control over data and privacy. It offers AI functionality, user management, supports different database backends, collaboration, and mini-apps. It aims to be a desktop app for local usage and a distributed daemon for servers, with a web app frontend client. The tool is stack-based on Electron, Angular, and Go, and currently dual-licensed under AGPL-3.0-or-later and a commercial license.

airbyte-platform
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's low-code Connector Development Kit (CDK). Airbyte is used by data engineers and analysts at companies of all sizes to move data for a variety of purposes, including data warehousing, data analysis, and machine learning.

super-agent-party
A 3D AI desktop companion with endless possibilities! This repository provides a platform for enhancing the LLM API without code modification, supporting seamless integration of various functionalities such as knowledge bases, real-time networking, multimodal capabilities, automation, and deep thinking control. It offers one-click deployment to multiple terminals, ecological tool interconnection, standardized interface opening, and compatibility across all platforms. Users can deploy the tool on Windows, macOS, Linux, or Docker, and access features like intelligent agent deployment, VRM desktop pets, Tavern character cards, QQ bot deployment, and developer-friendly interfaces. The tool supports multi-service providers, extensive tool integration, and ComfyUI workflows. Hardware requirements are minimal, making it suitable for various deployment scenarios.

PulsarRPA
PulsarRPA is a high-performance, distributed, open-source Robotic Process Automation (RPA) framework designed to handle large-scale RPA tasks with ease. It provides a comprehensive solution for browser automation, web content understanding, and data extraction. PulsarRPA addresses challenges of browser automation and accurate web data extraction from complex and evolving websites. It incorporates innovative technologies like browser rendering, RPA, intelligent scraping, advanced DOM parsing, and distributed architecture to ensure efficient, accurate, and scalable web data extraction. The tool is open-source, customizable, and supports cutting-edge information extraction technology, making it a preferred solution for large-scale web data extraction.

pathway
Pathway is a Python data processing framework for analytics and AI pipelines over data streams. It's the ideal solution for real-time processing use cases like streaming ETL or RAG pipelines for unstructured data. Pathway comes with an **easy-to-use Python API** , allowing you to seamlessly integrate your favorite Python ML libraries. Pathway code is versatile and robust: **you can use it in both development and production environments, handling both batch and streaming data effectively**. The same code can be used for local development, CI/CD tests, running batch jobs, handling stream replays, and processing data streams. Pathway is powered by a **scalable Rust engine** based on Differential Dataflow and performs incremental computation. Your Pathway code, despite being written in Python, is run by the Rust engine, enabling multithreading, multiprocessing, and distributed computations. All the pipeline is kept in memory and can be easily deployed with **Docker and Kubernetes**. You can install Pathway with pip: `pip install -U pathway` For any questions, you will find the community and team behind the project on Discord.

agentok
Agentok Studio is a visual tool built for AutoGen, a cutting-edge agent framework from Microsoft and various contributors. It offers intuitive visual tools to simplify the construction and management of complex agent-based workflows. Users can create workflows visually as graphs, chat with agents, and share flow templates. The tool is designed to streamline the development process for creators and developers working on next-generation Multi-Agent Applications.
buildel
Buildel is an AI automation platform that empowers users to create versatile workflows without writing code. It supports multiple providers and interfaces, offers pre-built use cases, and allows users to bring their own API keys. Ideal for AI-powered document retrieval, conversational interfaces, and data integration. Users can get started at app.buildel.ai or run Buildel locally with Node.js, Elixir/Erlang, Docker, Git, and JQ installed. Join the community on Discord for support and discussions.
genai-factory
GenAI Factory is a collection of end-to-end blueprints to deploy generative AI infrastructures in Google Cloud Platform (GCP), following security best practices. It embraces Infrastructure as Code (IaC) best practices, implements infrastructure in Terraform, and follows the least-privilege principle. The tool is compatible with Cloud Foundation Fabric FAST project-factory and application templates, allowing users to deploy various AI applications and systems on GCP.

modus
Modus is an open-source, serverless framework for building APIs powered by WebAssembly. It simplifies integrating AI models, data, and business logic with sandboxed execution. Modus extracts metadata, compiles code with optimizations, caches compiled modules, prepares invocation plans, generates API schema, and activates endpoints. Users query the endpoint, and Modus loads compiled code into a sandboxed environment, runs code securely, queries data and AI models, and responds via API. It provides a production-ready scalable endpoint for AI-enabled apps, optimized for sub-second response times. Modus supports programming languages like AssemblyScript and Go, and can be hosted on Hypermode or any platform. Developed by Hypermode as an open-source project, Modus welcomes external contributions.
nocobase
NocoBase is an extensible AI-powered no-code platform that offers total control, infinite extensibility, and AI collaboration. It enables teams to adapt quickly and reduce costs without the need for years of development or wasted resources. With NocoBase, users can deploy the platform in minutes and have complete control over their projects. The platform is data model-driven, allowing for unlimited possibilities by decoupling UI and data structure. It integrates AI capabilities seamlessly into business systems, enabling roles such as translator, analyst, researcher, or assistant. NocoBase provides a simple and intuitive user experience with a 'what you see is what you get' approach. It is designed for extension through its plugin-based architecture, allowing users to customize and extend functionalities easily.

nucliadb
NucliaDB is a robust database that allows storing and searching on unstructured data. It is an out of the box hybrid search database, utilizing vector, full text and graph indexes. NucliaDB is written in Rust and Python. We designed it to index large datasets and provide multi-teanant support. When utilizing NucliaDB with Nuclia cloud, you are able to the power of an NLP database without the hassle of data extraction, enrichment and inference. We do all the hard work for you.
ainodes-engine
aiNodes Engine is a Python-based AI image/motion picture generator node engine with a live execution chain, python code editor node, and plug-in support. It offers full modularity, colored background drop, and easy node creation with IDE annotations. The project is officially supported by Deforum and incorporates various open-source projects like ComfyUI. It is designed to be flexible, with an Unreal-like execution chain, supporting features such as Deforum, Stable Diffusion, Upscalers, Kandinsky, ControlNet, and more. The engine allows for background separation, human matting/masking, compositing, drag and drop, subgraphs, and graph saving/loading from image metadata. It aims to provide a unique, controllable manner of working with a strict user-declared execution chain.
For similar tasks
postgres-new
Postgres.new is an in-browser Postgres sandbox with AI assistance that allows users to spin up unlimited Postgres databases directly in the browser. Each database comes with a large language model (LLM) enabling features like drag-and-drop CSV import, report generation, chart creation, and database diagram building. The tool utilizes PGlite, a WASM version of Postgres, to run databases in the browser and store data in IndexedDB for persistence. The monorepo includes a frontend built with Next.js and a backend serving S3-backed PGlite databases over the PG wire protocol using pg-gateway.

TableLLM
TableLLM is a large language model designed for efficient tabular data manipulation tasks in real office scenarios. It can generate code solutions or direct text answers for tasks like insert, delete, update, query, merge, and chart operations on tables embedded in spreadsheets or documents. The model has been fine-tuned based on CodeLlama-7B and 13B, offering two scales: TableLLM-7B and TableLLM-13B. Evaluation results show its performance on benchmarks like WikiSQL, Spider, and self-created table operation benchmark. Users can use TableLLM for code and text generation tasks on tabular data.

ai-analyst
AI Analyst by E2B is an AI-powered code and data analysis tool built with Next.js and the E2B SDK. It allows users to analyze data with Meta's Llama 3.1, upload CSV files, and create interactive charts. The tool is powered by E2B Sandbox, Vercel's AI SDK, Next.js, and echarts library for interactive charts. Supported LLM providers include TogetherAI and Fireworks, with various chart types available for visualization.
xpert
Xpert is a powerful tool for data analysis and visualization. It provides a user-friendly interface to explore and manipulate datasets, perform statistical analysis, and create insightful visualizations. With Xpert, users can easily import data from various sources, clean and preprocess data, analyze trends and patterns, and generate interactive charts and graphs. Whether you are a data scientist, analyst, researcher, or student, Xpert simplifies the process of data analysis and visualization, making it accessible to users with varying levels of expertise.

doris
Doris is a lightweight and user-friendly data visualization tool designed for quick and easy exploration of datasets. It provides a simple interface for users to upload their data and generate interactive visualizations without the need for coding. With Doris, users can easily create charts, graphs, and dashboards to analyze and present their data in a visually appealing way. The tool supports various data formats and offers customization options to tailor visualizations to specific needs. Whether you are a data analyst, researcher, or student, Doris simplifies the process of data exploration and presentation.
clewdr
Clewdr is a collaborative platform for data analysis and visualization. It allows users to upload datasets, perform various data analysis tasks, and create interactive visualizations. The platform supports multiple users working on the same project simultaneously, enabling real-time collaboration and sharing of insights. Clewdr is designed to streamline the data analysis process and facilitate communication among team members. With its user-friendly interface and powerful features, Clewdr is suitable for data scientists, analysts, researchers, and anyone working with data to gain valuable insights and make informed decisions.

ciso-assistant-community
CISO Assistant is a tool that helps organizations manage their cybersecurity posture and compliance. It provides a centralized platform for managing security controls, threats, and risks. CISO Assistant also includes a library of pre-built frameworks and tools to help organizations quickly and easily implement best practices.

supersonic
SuperSonic is a next-generation BI platform that integrates Chat BI (powered by LLM) and Headless BI (powered by semantic layer) paradigms. This integration ensures that Chat BI has access to the same curated and governed semantic data models as traditional BI. Furthermore, the implementation of both paradigms benefits from the integration: * Chat BI's Text2SQL gets augmented with context-retrieval from semantic models. * Headless BI's query interface gets extended with natural language API. SuperSonic provides a Chat BI interface that empowers users to query data using natural language and visualize the results with suitable charts. To enable such experience, the only thing necessary is to build logical semantic models (definition of metric/dimension/tag, along with their meaning and relationships) through a Headless BI interface. Meanwhile, SuperSonic is designed to be extensible and composable, allowing custom implementations to be added and configured with Java SPI. The integration of Chat BI and Headless BI has the potential to enhance the Text2SQL generation in two dimensions: 1. Incorporate data semantics (such as business terms, column values, etc.) into the prompt, enabling LLM to better understand the semantics and reduce hallucination. 2. Offload the generation of advanced SQL syntax (such as join, formula, etc.) from LLM to the semantic layer to reduce complexity. With these ideas in mind, we develop SuperSonic as a practical reference implementation and use it to power our real-world products. Additionally, to facilitate further development we decide to open source SuperSonic as an extensible framework.
For similar jobs
vscode-dbt-power-user
The vscode-dbt-power-user is an open-source extension that enhances the functionality of Visual Studio Code to seamlessly work with dbt™. It provides features such as auto-complete for dbt™ code, previewing query results, column lineage visualization, generating dbt™ models, documentation generation, deferring model builds, running parent/child models and tests with a click, compiled query preview and explanation, project health check, SQL validation, BigQuery cost estimation, and other features like dbt™ logs viewer. The extension is fully compatible with dev containers, code spaces, and remote extensions, supporting dbt™ versions above 1.0.

SheetCopilot
SheetCopilot is an assistant agent that manipulates spreadsheets by following user commands. It leverages Large Language Models (LLMs) to interact with spreadsheets like a human expert, enabling non-expert users to complete tasks on complex software such as Google Sheets and Excel via a language interface. The tool observes spreadsheet states, polishes generated solutions based on external action documents and error feedback, and aims to improve success rate and efficiency. SheetCopilot offers a dataset with diverse task categories and operations, supporting operations like entry & manipulation, management, formatting, charts, and pivot tables. Users can interact with SheetCopilot in Excel or Google Sheets, executing tasks like calculating revenue, creating pivot tables, and plotting charts. The tool's evaluation includes performance comparisons with leading LLMs and VBA-based methods on specific datasets, showcasing its capabilities in controlling various aspects of a spreadsheet.

wren-engine
Wren Engine is a semantic engine designed to serve as the backbone of the semantic layer for LLMs. It simplifies the user experience by translating complex data structures into a business-friendly format, enabling end-users to interact with data using familiar terminology. The engine powers the semantic layer with advanced capabilities to define and manage modeling definitions, metadata, schema, data relationships, and logic behind calculations and aggregations through an analytics-as-code design approach. By leveraging Wren Engine, organizations can ensure a developer-friendly semantic layer that reflects nuanced data relationships and dynamics, facilitating more informed decision-making and strategic insights.
mslearn-knowledge-mining
The mslearn-knowledge-mining repository contains lab files for Azure AI Knowledge Mining modules. It provides resources for learning and implementing knowledge mining techniques using Azure AI services. The repository is designed to help users explore and understand how to leverage AI for knowledge mining purposes within the Azure ecosystem.

extension-gen-ai
The Looker GenAI Extension provides code examples and resources for building a Looker Extension that integrates with Vertex AI Large Language Models (LLMs). Users can leverage the power of LLMs to enhance data exploration and analysis within Looker. The extension offers generative explore functionality to ask natural language questions about data and generative insights on dashboards to analyze data by asking questions. It leverages components like BQML Remote Models, BQML Remote UDF with Vertex AI, and Custom Fine Tune Model for different integration options. Deployment involves setting up infrastructure with Terraform and deploying the Looker Extension by creating a Looker project, copying extension files, configuring BigQuery connection, connecting to Git, and testing the extension. Users can save example prompts and configure user settings for the extension. Development of the Looker Extension environment includes installing dependencies, starting the development server, and building for production.
postgres-new
Postgres.new is an in-browser Postgres sandbox with AI assistance that allows users to spin up unlimited Postgres databases directly in the browser. Each database comes with a large language model (LLM) enabling features like drag-and-drop CSV import, report generation, chart creation, and database diagram building. The tool utilizes PGlite, a WASM version of Postgres, to run databases in the browser and store data in IndexedDB for persistence. The monorepo includes a frontend built with Next.js and a backend serving S3-backed PGlite databases over the PG wire protocol using pg-gateway.

text-to-sql-bedrock-workshop
This repository focuses on utilizing generative AI to bridge the gap between natural language questions and SQL queries, aiming to improve data consumption in enterprise data warehouses. It addresses challenges in SQL query generation, such as foreign key relationships and table joins, and highlights the importance of accuracy metrics like Execution Accuracy (EX) and Exact Set Match Accuracy (EM). The workshop content covers advanced prompt engineering, Retrieval Augmented Generation (RAG), fine-tuning models, and security measures against prompt and SQL injections.
airflow-provider-great-expectations
The 'airflow-provider-great-expectations' repository contains a set of Airflow operators for Great Expectations, a Python library used for testing and validating data. The operators enable users to run Great Expectations validations and checks within Apache Airflow workflows. The package requires Airflow 2.1.0+ and Great Expectations >=v0.13.9. It provides functionalities to work with Great Expectations V3 Batch Request API, Checkpoints, and allows passing kwargs to Checkpoints at runtime. The repository includes modules for a base operator and examples of DAGs with sample tasks demonstrating the operator's functionality.