
vscode-dbt-power-user
This extension makes vscode seamlessly work with dbt™: Auto-complete, preview, column lineage, AI docs generation, health checks, cost estimation etc
Stars: 489
The vscode-dbt-power-user is an open-source extension that enhances the functionality of Visual Studio Code to seamlessly work with dbt™. It provides features such as auto-complete for dbt™ code, previewing query results, column lineage visualization, generating dbt™ models, documentation generation, deferring model builds, running parent/child models and tests with a click, compiled query preview and explanation, project health check, SQL validation, BigQuery cost estimation, and other features like dbt™ logs viewer. The extension is fully compatible with dev containers, code spaces, and remote extensions, supporting dbt™ versions above 1.0.
README:



![]()
This open source extension makes VSCode seamlessly work with dbt™.
If you need help with setting up the extension, please check the documentation. For any issues or bugs, please contact us via chat or Slack.
Features:
| Feature | Details |
|---|---|
| Auto-complete dbt™ code | Auto-fill model names, macros, sources and docs. Click on model names, macros, sources to go to definitions. |
| Preview Query results and Analyze | Generate dbt™ model / query results. Export as CSV or analyze results by creating graphs, filters, groups |
| Column lineage | Model lineage as well as column lineage |
| Generate dbt™ Models | from source files or convert SQL to dbt™ Model (docs) |
| Generate documentation | Generate model and column descriptions or write in the UI editor. Save formatted text in YAML files. |
| Defer to prod | Build your model in development without building (by defering) your upstream models |
| Click to run parent / child models and tests | Just click to do common dbt™ operations like running tests, parent / child models or previewing data. |
| Compiled query preview and explanation | Get live preview of compiled query as your write code. Also, generate explanations for dbt™ code written previously (by somebody else) |
| Project health check | Identify issues in your dbt™ project like columns not present, models not materialized |
| SQL validator | Identify issues in SQL like typos in keywords, missing or extra parentheses, non-existent columns |
| Big Query cost estimator | Estimate data that will be processed by dbt™ model in BigQuery |
| Other features | dbt™ logs viewer (force tailing) |
Note: This extension is fully compatible with dev containers, code spaces and remote extension. See Visual Studio Code Remote - Containers and Visual Studio Code Remote - WSL. The extension is supported for dbt™ versions above 1.0.
Auto-fill model names, macros, sources and docs. Click on model names, macros, sources to go to definitions. (docs)

Generate dbt™ model / query results. Export as CSV or analyze results by creating graphs, filters, groups. (docs)

View model lineage as well as column lineage with components like models, seeds, sources, exposures and info like model types, tests, documentation, linkage types. (docs)

Generate dbt™ models from sources defined in YAML. You can also convert existing SQL to a dbt™ model where references get populated automatically. (docs)

Generate model and column descriptions automatically or write descriptions manually in the UI editor. Your descriptions are automatically formatted and saved in YAML files. (docs)

Defer building your upstream models when you make changes in development by referencing production models. Here's (more info) about the concept. This functionality can be used in dbt™ core with the extension. (docs)
Just click to do common button operations like executing tests, building or running parent / child models. (docs)

Get live preview of compiled query as your write code. Also, generate explanations for dbt™ code written previously (by somebody else). (docs)

Identify issues in your dbt™ project like columns not present, models not materialized. (docs)

Validate SQL to identify issues like mistyped keywords, extra parentheses, columns no present in database (docs)

Estimate data that will be processed by dbt™ model in BigQuery (docs)

dbt™ logs view (force tailing)

Please check documentation for additional info. For any issues or bugs, please contact us via chat or Slack.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for vscode-dbt-power-user
Similar Open Source Tools
vscode-dbt-power-user
The vscode-dbt-power-user is an open-source extension that enhances the functionality of Visual Studio Code to seamlessly work with dbt™. It provides features such as auto-complete for dbt™ code, previewing query results, column lineage visualization, generating dbt™ models, documentation generation, deferring model builds, running parent/child models and tests with a click, compiled query preview and explanation, project health check, SQL validation, BigQuery cost estimation, and other features like dbt™ logs viewer. The extension is fully compatible with dev containers, code spaces, and remote extensions, supporting dbt™ versions above 1.0.

WrenAI
WrenAI is a data assistant tool that helps users get results and insights faster by asking questions in natural language, without writing SQL. It leverages Large Language Models (LLM) with Retrieval-Augmented Generation (RAG) technology to enhance comprehension of internal data. Key benefits include fast onboarding, secure design, and open-source availability. WrenAI consists of three core services: Wren UI (intuitive user interface), Wren AI Service (processes queries using a vector database), and Wren Engine (platform backbone). It is currently in alpha version, with new releases planned biweekly.
OpenContracts
OpenContracts is a free and open-source document analytics platform designed to empower knowledge owners and subject matter experts. It supports multiple document formats, ingestion pipelines, and custom document analytics tools. Users can manage documents, define metadata schemas, extract layout features, generate vector embeddings, deploy custom analyzers, support new document formats, annotate documents, extract bulk data, and create bespoke data extraction workflows. The tool aims to provide a standardized architecture for analyzing contracts and making data portable, with a focus on PDF and text-based formats. It includes features like document management, layout parsing, pluggable architectures, human annotation interface, and a custom LLM framework for conversation management and real-time streaming.
AIQC
AIQC is an open source Python package that provides a declarative API for end-to-end MLOps in order to make deep learning more accessible to researchers. It utilizes a SQLite object-relational model for machine learning objects and stacks standardized workflows for various analyses, data types, and libraries. The benefits include a 90% reduction in data wrangling, reproducibility, and no need to install and maintain application and database servers for experiment tracking. AIQC is pip-installable and provides a Dash-Plotly UI for real-time experiment tracking.

OmAgent
OmAgent is an open-source agent framework designed to streamline the development of on-device multimodal agents. It enables agents to empower various hardware devices, integrates speed-optimized SOTA multimodal models, provides SOTA multimodal agent algorithms, and focuses on optimizing the end-to-end computing pipeline for real-time user interaction experience. Key features include easy connection to diverse devices, scalability, flexibility, and workflow orchestration. The architecture emphasizes graph-based workflow orchestration, native multimodality, and device-centricity, allowing developers to create bespoke intelligent agent programs.
docling
Docling is a tool that bundles PDF document conversion to JSON and Markdown in an easy, self-contained package. It can convert any PDF document to JSON or Markdown format, understand detailed page layout, reading order, recover table structures, extract metadata such as title, authors, references, and language, and optionally apply OCR for scanned PDFs. The tool is designed to be stable, lightning fast, and suitable for macOS and Linux environments.
MaixCDK
MaixCDK (Maix C/CPP Development Kit) is a C/C++ development kit that integrates practical functions such as AI, machine vision, and IoT. It provides easy-to-use encapsulation for quickly building projects in vision, artificial intelligence, IoT, robotics, industrial cameras, and more. It supports hardware-accelerated execution of AI models, common vision algorithms, OpenCV, and interfaces for peripheral operations. MaixCDK offers cross-platform support, easy-to-use API, simple environment setup, online debugging, and a complete ecosystem including MaixPy and MaixVision. Supported devices include Sipeed MaixCAM, Sipeed MaixCAM-Pro, and partial support for Common Linux.
docling
Docling simplifies document processing, parsing diverse formats including advanced PDF understanding, and providing seamless integrations with the general AI ecosystem. It offers features such as parsing multiple document formats, advanced PDF understanding, unified DoclingDocument representation format, various export formats, local execution capabilities, plug-and-play integrations with agentic AI tools, extensive OCR support, and a simple CLI. Coming soon features include metadata extraction, visual language models, chart understanding, and complex chemistry understanding. Docling is installed via pip and works on macOS, Linux, and Windows environments. It provides detailed documentation, examples, integrations with popular frameworks, and support through the discussion section. The codebase is under the MIT license and has been developed by IBM.

cognee
Cognee is an open-source framework designed for creating self-improving deterministic outputs for Large Language Models (LLMs) using graphs, LLMs, and vector retrieval. It provides a platform for AI engineers to enhance their models and generate more accurate results. Users can leverage Cognee to add new information, utilize LLMs for knowledge creation, and query the system for relevant knowledge. The tool supports various LLM providers and offers flexibility in adding different data types, such as text files or directories. Cognee aims to streamline the process of working with LLMs and improving AI models for better performance and efficiency.

macai
Macai is a native macOS client for interacting with modern AI tools, such as ChatGPT and Ollama. It features organized chats with custom system messages, system-defined light/dark themes, backup and restore functionality, customizable context size, support for any model with a compatible API, formatted code blocks and tables, multiple chat tabs, CoreData data storage, streamed responses, and automatic chat name generation. Macai is in active development, with contributions welcome.
Chat2DB
Chat2DB is an AI-driven data development and analysis platform that enables users to communicate with databases using natural language. It supports a wide range of databases, including MySQL, PostgreSQL, Oracle, SQLServer, SQLite, MariaDB, ClickHouse, DM, Presto, DB2, OceanBase, Hive, KingBase, MongoDB, Redis, and Snowflake. Chat2DB provides a user-friendly interface that allows users to query databases, generate reports, and explore data using natural language commands. It also offers a variety of features to help users improve their productivity, such as auto-completion, syntax highlighting, and error checking.
tidb.ai
TiDB.AI is a conversational search RAG (Retrieval-Augmented Generation) app based on TiDB Serverless Vector Storage. It provides an out-of-the-box and embeddable QA robot experience based on knowledge from official and documentation sites. The platform features a Perplexity-style Conversational Search page with an advanced built-in website crawler for comprehensive coverage. Users can integrate an embeddable JavaScript snippet into their website for instant responses to product-related queries. The tech stack includes Next.js, TypeScript, Tailwind CSS, shadcn/ui for design, TiDB for database storage, Kysely for SQL query building, NextAuth.js for authentication, Vercel for deployments, and LlamaIndex for the RAG framework. TiDB.AI is open-source under the Apache License, Version 2.0.
StableDiffusion.NET
StableDiffusion.NET is a tool for creating images from text prompts using stable diffusion models. It allows users to build models with various configurations and options, supporting GPU acceleration for faster processing. The tool provides flexibility in choosing backends and integrating native libraries. Users can easily convert text prompts into images with default or custom parameters, and save the resulting images in PNG format. Additionally, users can extend the tool's functionality by writing custom extensions or installing pre-built extension sets like HPPH.System.Drawing and HPPH.SkiaSharp.

TokenFormer
TokenFormer is a fully attention-based neural network architecture that leverages tokenized model parameters to enhance architectural flexibility. It aims to maximize the flexibility of neural networks by unifying token-token and token-parameter interactions through the attention mechanism. The architecture allows for incremental model scaling and has shown promising results in language modeling and visual modeling tasks. The codebase is clean, concise, easily readable, state-of-the-art, and relies on minimal dependencies.

superduperdb
SuperDuperDB is a Python framework for integrating AI models, APIs, and vector search engines directly with your existing databases, including hosting of your own models, streaming inference and scalable model training/fine-tuning. Build, deploy and manage any AI application without the need for complex pipelines, infrastructure as well as specialized vector databases, and moving our data there, by integrating AI at your data's source: - Generative AI, LLMs, RAG, vector search - Standard machine learning use-cases (classification, segmentation, regression, forecasting recommendation etc.) - Custom AI use-cases involving specialized models - Even the most complex applications/workflows in which different models work together SuperDuperDB is **not** a database. Think `db = superduper(db)`: SuperDuperDB transforms your databases into an intelligent platform that allows you to leverage the full AI and Python ecosystem. A single development and deployment environment for all your AI applications in one place, fully scalable and easy to manage.
For similar tasks

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

sorrentum
Sorrentum is an open-source project that aims to combine open-source development, startups, and brilliant students to build machine learning, AI, and Web3 / DeFi protocols geared towards finance and economics. The project provides opportunities for internships, research assistantships, and development grants, as well as the chance to work on cutting-edge problems, learn about startups, write academic papers, and get internships and full-time positions at companies working on Sorrentum applications.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

zep-python
Zep is an open-source platform for building and deploying large language model (LLM) applications. It provides a suite of tools and services that make it easy to integrate LLMs into your applications, including chat history memory, embedding, vector search, and data enrichment. Zep is designed to be scalable, reliable, and easy to use, making it a great choice for developers who want to build LLM-powered applications quickly and easily.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

mojo
Mojo is a new programming language that bridges the gap between research and production by combining Python syntax and ecosystem with systems programming and metaprogramming features. Mojo is still young, but it is designed to become a superset of Python over time.

pandas-ai
PandasAI is a Python library that makes it easy to ask questions to your data in natural language. It helps you to explore, clean, and analyze your data using generative AI.

databend
Databend is an open-source cloud data warehouse that serves as a cost-effective alternative to Snowflake. With its focus on fast query execution and data ingestion, it's designed for complex analysis of the world's largest datasets.
For similar jobs
vscode-dbt-power-user
The vscode-dbt-power-user is an open-source extension that enhances the functionality of Visual Studio Code to seamlessly work with dbt™. It provides features such as auto-complete for dbt™ code, previewing query results, column lineage visualization, generating dbt™ models, documentation generation, deferring model builds, running parent/child models and tests with a click, compiled query preview and explanation, project health check, SQL validation, BigQuery cost estimation, and other features like dbt™ logs viewer. The extension is fully compatible with dev containers, code spaces, and remote extensions, supporting dbt™ versions above 1.0.

SheetCopilot
SheetCopilot is an assistant agent that manipulates spreadsheets by following user commands. It leverages Large Language Models (LLMs) to interact with spreadsheets like a human expert, enabling non-expert users to complete tasks on complex software such as Google Sheets and Excel via a language interface. The tool observes spreadsheet states, polishes generated solutions based on external action documents and error feedback, and aims to improve success rate and efficiency. SheetCopilot offers a dataset with diverse task categories and operations, supporting operations like entry & manipulation, management, formatting, charts, and pivot tables. Users can interact with SheetCopilot in Excel or Google Sheets, executing tasks like calculating revenue, creating pivot tables, and plotting charts. The tool's evaluation includes performance comparisons with leading LLMs and VBA-based methods on specific datasets, showcasing its capabilities in controlling various aspects of a spreadsheet.

wren-engine
Wren Engine is a semantic engine designed to serve as the backbone of the semantic layer for LLMs. It simplifies the user experience by translating complex data structures into a business-friendly format, enabling end-users to interact with data using familiar terminology. The engine powers the semantic layer with advanced capabilities to define and manage modeling definitions, metadata, schema, data relationships, and logic behind calculations and aggregations through an analytics-as-code design approach. By leveraging Wren Engine, organizations can ensure a developer-friendly semantic layer that reflects nuanced data relationships and dynamics, facilitating more informed decision-making and strategic insights.
mslearn-knowledge-mining
The mslearn-knowledge-mining repository contains lab files for Azure AI Knowledge Mining modules. It provides resources for learning and implementing knowledge mining techniques using Azure AI services. The repository is designed to help users explore and understand how to leverage AI for knowledge mining purposes within the Azure ecosystem.

extension-gen-ai
The Looker GenAI Extension provides code examples and resources for building a Looker Extension that integrates with Vertex AI Large Language Models (LLMs). Users can leverage the power of LLMs to enhance data exploration and analysis within Looker. The extension offers generative explore functionality to ask natural language questions about data and generative insights on dashboards to analyze data by asking questions. It leverages components like BQML Remote Models, BQML Remote UDF with Vertex AI, and Custom Fine Tune Model for different integration options. Deployment involves setting up infrastructure with Terraform and deploying the Looker Extension by creating a Looker project, copying extension files, configuring BigQuery connection, connecting to Git, and testing the extension. Users can save example prompts and configure user settings for the extension. Development of the Looker Extension environment includes installing dependencies, starting the development server, and building for production.
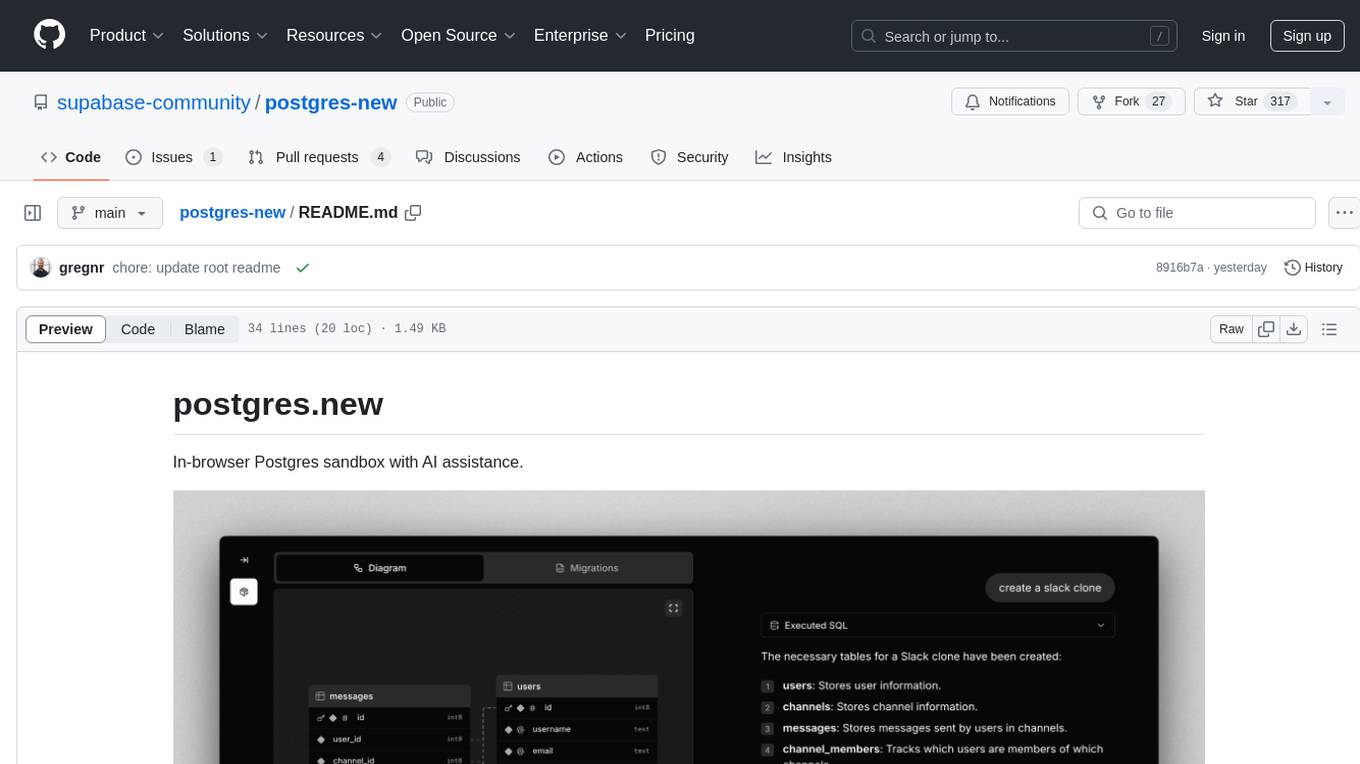
postgres-new
Postgres.new is an in-browser Postgres sandbox with AI assistance that allows users to spin up unlimited Postgres databases directly in the browser. Each database comes with a large language model (LLM) enabling features like drag-and-drop CSV import, report generation, chart creation, and database diagram building. The tool utilizes PGlite, a WASM version of Postgres, to run databases in the browser and store data in IndexedDB for persistence. The monorepo includes a frontend built with Next.js and a backend serving S3-backed PGlite databases over the PG wire protocol using pg-gateway.

text-to-sql-bedrock-workshop
This repository focuses on utilizing generative AI to bridge the gap between natural language questions and SQL queries, aiming to improve data consumption in enterprise data warehouses. It addresses challenges in SQL query generation, such as foreign key relationships and table joins, and highlights the importance of accuracy metrics like Execution Accuracy (EX) and Exact Set Match Accuracy (EM). The workshop content covers advanced prompt engineering, Retrieval Augmented Generation (RAG), fine-tuning models, and security measures against prompt and SQL injections.
airflow-provider-great-expectations
The 'airflow-provider-great-expectations' repository contains a set of Airflow operators for Great Expectations, a Python library used for testing and validating data. The operators enable users to run Great Expectations validations and checks within Apache Airflow workflows. The package requires Airflow 2.1.0+ and Great Expectations >=v0.13.9. It provides functionalities to work with Great Expectations V3 Batch Request API, Checkpoints, and allows passing kwargs to Checkpoints at runtime. The repository includes modules for a base operator and examples of DAGs with sample tasks demonstrating the operator's functionality.