
sdg_hub
Synthetic Data Generation Toolkit for LLMs
Stars: 102
sdg_hub is a modular Python framework designed for building synthetic data generation pipelines using composable blocks and flows. Users can mix and match LLM-powered and traditional processing blocks to create sophisticated data generation workflows. The toolkit offers features such as modular composability, async performance, built-in validation, auto-discovery, rich monitoring, dataset schema discovery, and easy extensibility. sdg_hub provides detailed documentation and supports high-throughput processing with error handling. It simplifies the process of transforming datasets by allowing users to chain blocks together in YAML-configured flows, enabling the creation of complex data generation pipelines.
README:
![]()


![]()

A modular Python framework for building synthetic data generation pipelines using composable blocks and flows. Transform datasets through building-block composition - mix and match LLM-powered and traditional processing blocks to create sophisticated data generation workflows.
📖 Full documentation available at: https://ai-innovation.team/sdg_hub
🔧 Modular Composability - Mix and match blocks like Lego pieces. Build simple transformations or complex multi-stage pipelines with YAML-configured flows.
⚡ Async Performance - High-throughput LLM processing with built-in error handling.
🛡️ Built-in Validation - Pydantic-based type safety ensures your configurations and data are correct before execution.
🔍 Auto-Discovery - Automatic block and flow registration. No manual imports or complex setup.
📊 Rich Monitoring - Detailed logging with progress bars and execution summaries.
📋 Dataset Schema Discovery - Instantly discover required data formats. Get empty datasets with correct schema for easy validation and data preparation.
🧩 Easily Extensible - Create custom blocks with simple inheritance. Rich logging and monitoring built-in.
Recommended: Install uv — see https://docs.astral.sh/uv/getting-started/installation/
# Production
uv pip install sdg-hub
# Development
git clone https://github.com/Red-Hat-AI-Innovation-Team/sdg_hub.git
cd sdg_hub
uv pip install .[dev]
# or: uv sync --extra dev# For vLLM support
uv pip install sdg-hub[vllm]
# For examples
uv pip install sdg-hub[examples]Blocks are composable units that transform datasets - think of them as data processing Lego pieces. Each block performs a specific task: LLM chat, text parsing, evaluation, or transformation.
Flows orchestrate multiple blocks into complete pipelines defined in YAML. Chain blocks together to create complex data generation workflows with validation and parameter management.
# Simple concept: Blocks transform data, Flows chain blocks together
dataset → Block₁ → Block₂ → Block₃ → enriched_datasetfrom sdg_hub import FlowRegistry, Flow
# Auto-discover all available flows (no setup needed!)
FlowRegistry.discover_flows()
# List available flows
flows = FlowRegistry.list_flows()
print(f"Available flows: {flows}")
# Search for specific types
qa_flows = FlowRegistry.search_flows(tag="question-generation")
print(f"QA flows: {qa_flows}")Each flow has a unique, human-readable ID automatically generated from its name. These IDs provide a convenient shorthand for referencing flows:
# Every flow gets a deterministic ID
# Same flow name always generates the same ID
flow_id = "small-rock-799"
# Use ID to reference the flow
flow_path = FlowRegistry.get_flow_path(flow_id)
flow = Flow.from_yaml(flow_path)# Discover recommended models
default_model = flow.get_default_model()
recommendations = flow.get_model_recommendations()
# Configure model settings at runtime
# This assumes you have a hosted vLLM instance of meta-llama/Llama-3.3-70B-Instruct running at http://localhost:8000/v1
flow.set_model_config(
model=f"hosted_vllm/{default_model}",
api_base="http://localhost:8000/v1",
api_key="your_key",
)# First, discover what data the flow needs
# Get an empty dataset with the exact schema needed
schema_dataset = flow.get_dataset_schema() # Get empty dataset with correct schema
print(f"Required columns: {schema_dataset.column_names}")
print(f"Schema: {schema_dataset.features}")
# Option 1: Add data directly to the schema dataset
dataset = schema_dataset.add_item({
'document': 'Your document text here...',
'document_outline': '1. Topic A; 2. Topic B; 3. Topic C',
'domain': 'Computer Science',
'icl_document': 'Example document for in-context learning...',
'icl_query_1': 'Example question 1?',
'icl_response_1': 'Example answer 1',
'icl_query_2': 'Example question 2?',
'icl_response_2': 'Example answer 2',
'icl_query_3': 'Example question 3?',
'icl_response_3': 'Example answer 3'
})
# Option 2: Create your own dataset and validate the schema
my_dataset = Dataset.from_dict(my_data_dict)
if my_dataset.features == schema_dataset.features:
print("✅ Schema matches - ready to generate!")
dataset = my_dataset
else:
print("❌ Schema mismatch - check your columns")
# Option 3: Get raw requirements for detailed inspection
requirements = flow.get_dataset_requirements()
if requirements:
print(f"Required: {requirements.required_columns}")
print(f"Optional: {requirements.optional_columns}")
print(f"Min samples: {requirements.min_samples}")# Quick Testing with Dry Run
dry_result = flow.dry_run(dataset, sample_size=1)
print(f"Dry run completed in {dry_result['execution_time_seconds']:.2f}s")
print(f"Output columns: {dry_result['final_dataset']['columns']}")
# Generate high-quality QA pairs
result = flow.generate(dataset)
# Access generated content
questions = result['question']
answers = result['response']
faithfulness_scores = result['faithfulness_judgment']
relevancy_scores = result['relevancy_score']This project is licensed under the Apache License 2.0 - see the LICENSE file for details.
We welcome contributions! Please see CONTRIBUTING.md for guidelines on how to contribute to this project.
Built with ❤️ by the Red Hat AI Innovation Team
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for sdg_hub
Similar Open Source Tools
sdg_hub
sdg_hub is a modular Python framework designed for building synthetic data generation pipelines using composable blocks and flows. Users can mix and match LLM-powered and traditional processing blocks to create sophisticated data generation workflows. The toolkit offers features such as modular composability, async performance, built-in validation, auto-discovery, rich monitoring, dataset schema discovery, and easy extensibility. sdg_hub provides detailed documentation and supports high-throughput processing with error handling. It simplifies the process of transforming datasets by allowing users to chain blocks together in YAML-configured flows, enabling the creation of complex data generation pipelines.

lionagi
LionAGI is a robust framework for orchestrating multi-step AI operations with precise control. It allows users to bring together multiple models, advanced reasoning, tool integrations, and custom validations in a single coherent pipeline. The framework is structured, expandable, controlled, and transparent, offering features like real-time logging, message introspection, and tool usage tracking. LionAGI supports advanced multi-step reasoning with ReAct, integrates with Anthropic's Model Context Protocol, and provides observability and debugging tools. Users can seamlessly orchestrate multiple models, integrate with Claude Code CLI SDK, and leverage a fan-out fan-in pattern for orchestration. The framework also offers optional dependencies for additional functionalities like reader tools, local inference support, rich output formatting, database support, and graph visualization.

plexe
Plexe is a tool that allows users to create machine learning models by describing them in plain language. Users can explain their requirements, provide a dataset, and the AI-powered system will build a fully functional model through an automated agentic approach. It supports multiple AI agents and model building frameworks like XGBoost, CatBoost, and Keras. Plexe also provides Docker images with pre-configured environments, YAML configuration for customization, and support for multiple LiteLLM providers. Users can visualize experiment results using the built-in Streamlit dashboard and extend Plexe's functionality through custom integrations.
orra
Orra is a tool for building production-ready multi-agent applications that handle complex real-world interactions. It coordinates tasks across existing stack, agents, and tools run as services using intelligent reasoning. With features like smart pre-evaluated execution plans, domain grounding, durable execution, and automatic service health monitoring, Orra enables users to go fast with tools as services and revert state to handle failures. It provides real-time status tracking and webhook result delivery, making it ideal for developers looking to move beyond simple crews and agents.
ai-microcore
MicroCore is a collection of python adapters for Large Language Models and Vector Databases / Semantic Search APIs. It allows convenient communication with these services, easy switching between models & services, and separation of business logic from implementation details. Users can keep applications simple and try various models & services without changing application code. MicroCore connects MCP tools to language models easily, supports text completion and chat completion models, and provides features for configuring, installing vendor-specific packages, and using vector databases.

GraphRAG-SDK
Build fast and accurate GenAI applications with GraphRAG SDK, a specialized toolkit for building Graph Retrieval-Augmented Generation (GraphRAG) systems. It integrates knowledge graphs, ontology management, and state-of-the-art LLMs to deliver accurate, efficient, and customizable RAG workflows. The SDK simplifies the development process by automating ontology creation, knowledge graph agent creation, and query handling, enabling users to interact and query their knowledge graphs effectively. It supports multi-agent systems and orchestrates agents specialized in different domains. The SDK is optimized for FalkorDB, ensuring high performance and scalability for large-scale applications. By leveraging knowledge graphs, it enables semantic relationships and ontology-driven queries that go beyond standard vector similarity, enhancing retrieval-augmented generation capabilities.

lionagi
LionAGI is a powerful intelligent workflow automation framework that introduces advanced ML models into any existing workflows and data infrastructure. It can interact with almost any model, run interactions in parallel for most models, produce structured pydantic outputs with flexible usage, automate workflow via graph based agents, use advanced prompting techniques, and more. LionAGI aims to provide a centralized agent-managed framework for "ML-powered tools coordination" and to dramatically lower the barrier of entries for creating use-case/domain specific tools. It is designed to be asynchronous only and requires Python 3.10 or higher.
agentpress
AgentPress is a collection of simple but powerful utilities that serve as building blocks for creating AI agents. It includes core components for managing threads, registering tools, processing responses, state management, and utilizing LLMs. The tool provides a modular architecture for handling messages, LLM API calls, response processing, tool execution, and results management. Users can easily set up the environment, create custom tools with OpenAPI or XML schema, and manage conversation threads with real-time interaction. AgentPress aims to be agnostic, simple, and flexible, allowing users to customize and extend functionalities as needed.
fast-mcp
Fast MCP is a Ruby gem that simplifies the integration of AI models with your Ruby applications. It provides a clean implementation of the Model Context Protocol, eliminating complex communication protocols, integration challenges, and compatibility issues. With Fast MCP, you can easily connect AI models to your servers, share data resources, choose from multiple transports, integrate with frameworks like Rails and Sinatra, and secure your AI-powered endpoints. The gem also offers real-time updates and authentication support, making AI integration a seamless experience for developers.

R2R
R2R (RAG to Riches) is a fast and efficient framework for serving high-quality Retrieval-Augmented Generation (RAG) to end users. The framework is designed with customizable pipelines and a feature-rich FastAPI implementation, enabling developers to quickly deploy and scale RAG-based applications. R2R was conceived to bridge the gap between local LLM experimentation and scalable production solutions. **R2R is to LangChain/LlamaIndex what NextJS is to React**. A JavaScript client for R2R deployments can be found here. ### Key Features * **🚀 Deploy** : Instantly launch production-ready RAG pipelines with streaming capabilities. * **🧩 Customize** : Tailor your pipeline with intuitive configuration files. * **🔌 Extend** : Enhance your pipeline with custom code integrations. * **⚖️ Autoscale** : Scale your pipeline effortlessly in the cloud using SciPhi. * **🤖 OSS** : Benefit from a framework developed by the open-source community, designed to simplify RAG deployment.
open-responses
OpenResponses API provides enterprise-grade AI capabilities through a powerful API, simplifying development and deployment while ensuring complete data control. It offers automated tracing, integrated RAG for contextual information retrieval, pre-built tool integrations, self-hosted architecture, and an OpenAI-compatible interface. The toolkit addresses development challenges like feature gaps and integration complexity, as well as operational concerns such as data privacy and operational control. Engineering teams can benefit from improved productivity, production readiness, compliance confidence, and simplified architecture by choosing OpenResponses.
ahnlich
Ahnlich is a tool that provides multiple components for storing and searching similar vectors using linear or non-linear similarity algorithms. It includes 'ahnlich-db' for in-memory vector key value store, 'ahnlich-ai' for AI proxy communication, 'ahnlich-client-rs' for Rust client, and 'ahnlich-client-py' for Python client. The tool is not production-ready yet and is still in testing phase, allowing AI/ML engineers to issue queries using raw input such as images/text and features off-the-shelf models for indexing and querying.

req_llm
ReqLLM is a Req-based library for LLM interactions, offering a unified interface to AI providers through a plugin-based architecture. It brings composability and middleware advantages to LLM interactions, with features like auto-synced providers/models, typed data structures, ergonomic helpers, streaming capabilities, usage & cost extraction, and a plugin-based provider system. Users can easily generate text, structured data, embeddings, and track usage costs. The tool supports various AI providers like Anthropic, OpenAI, Groq, Google, and xAI, and allows for easy addition of new providers. ReqLLM also provides API key management, detailed documentation, and a roadmap for future enhancements.

Acontext
Acontext is a context data platform designed for production AI agents, offering unified storage, built-in context management, and observability features. It helps agents scale from local demos to production without the need to rebuild context infrastructure. The platform provides solutions for challenges like scattered context data, long-running agents requiring context management, and tracking states from multi-modal agents. Acontext offers core features such as context storage, session management, disk storage, agent skills management, and sandbox for code execution and analysis. Users can connect to Acontext, install SDKs, initialize clients, store and retrieve messages, perform context engineering, and utilize agent storage tools. The platform also supports building agents using end-to-end scripts in Python and Typescript, with various templates available. Acontext's architecture includes client layer, backend with API and core components, infrastructure with PostgreSQL, S3, Redis, and RabbitMQ, and a web dashboard. Join the Acontext community on Discord and follow updates on GitHub.
BrowserAI
BrowserAI is a tool that allows users to run large language models (LLMs) directly in the browser, providing a simple, fast, and open-source solution. It prioritizes privacy by processing data locally, is cost-effective with no server costs, works offline after initial download, and offers WebGPU acceleration for high performance. It is developer-friendly with a simple API, supports multiple engines, and comes with pre-configured models for easy use. Ideal for web developers, companies needing privacy-conscious AI solutions, researchers experimenting with browser-based AI, and hobbyists exploring AI without infrastructure overhead.
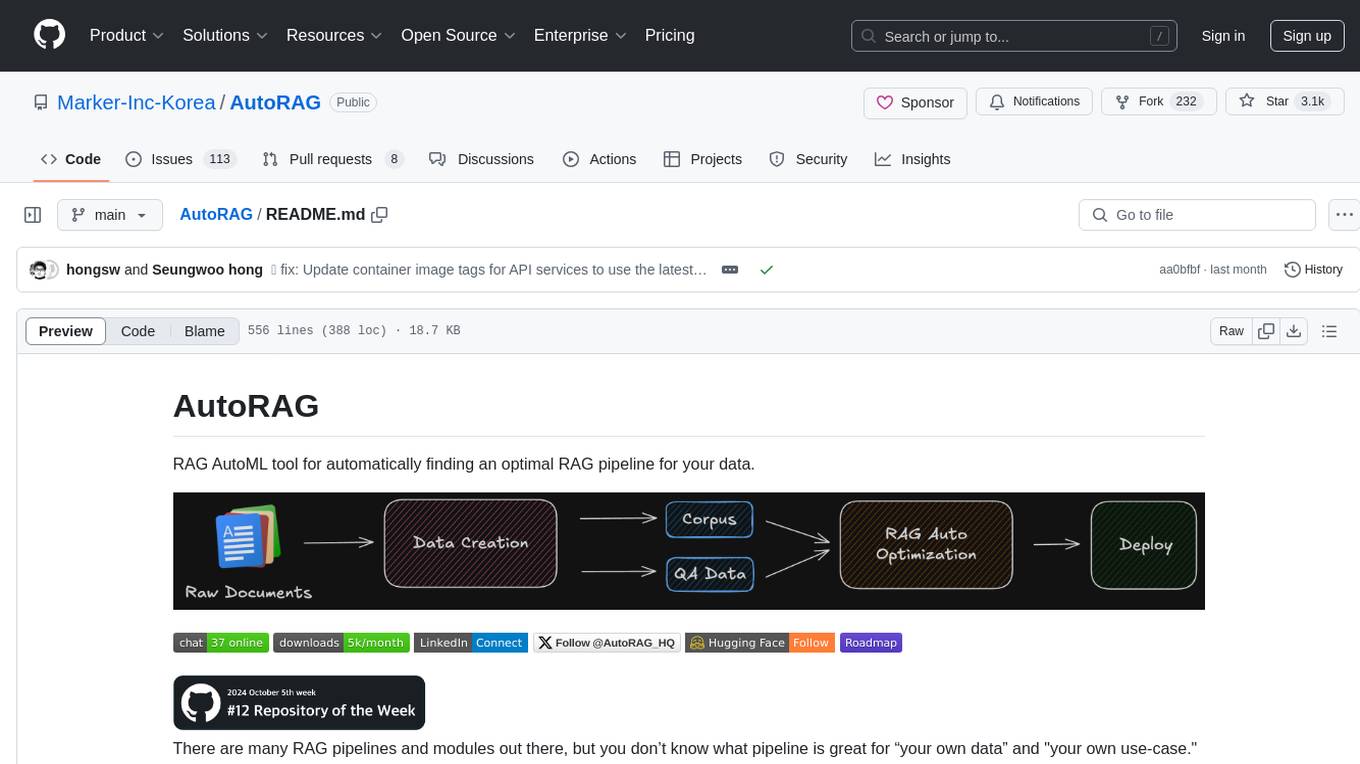
AutoRAG
AutoRAG is an AutoML tool designed to automatically find the optimal RAG pipeline for your data. It simplifies the process of evaluating various RAG modules to identify the best pipeline for your specific use-case. The tool supports easy evaluation of different module combinations, making it efficient to find the most suitable RAG pipeline for your needs. AutoRAG also offers a cloud beta version to assist users in running and optimizing the tool, along with building RAG evaluation datasets for a starting price of $9.99 per optimization.
For similar tasks
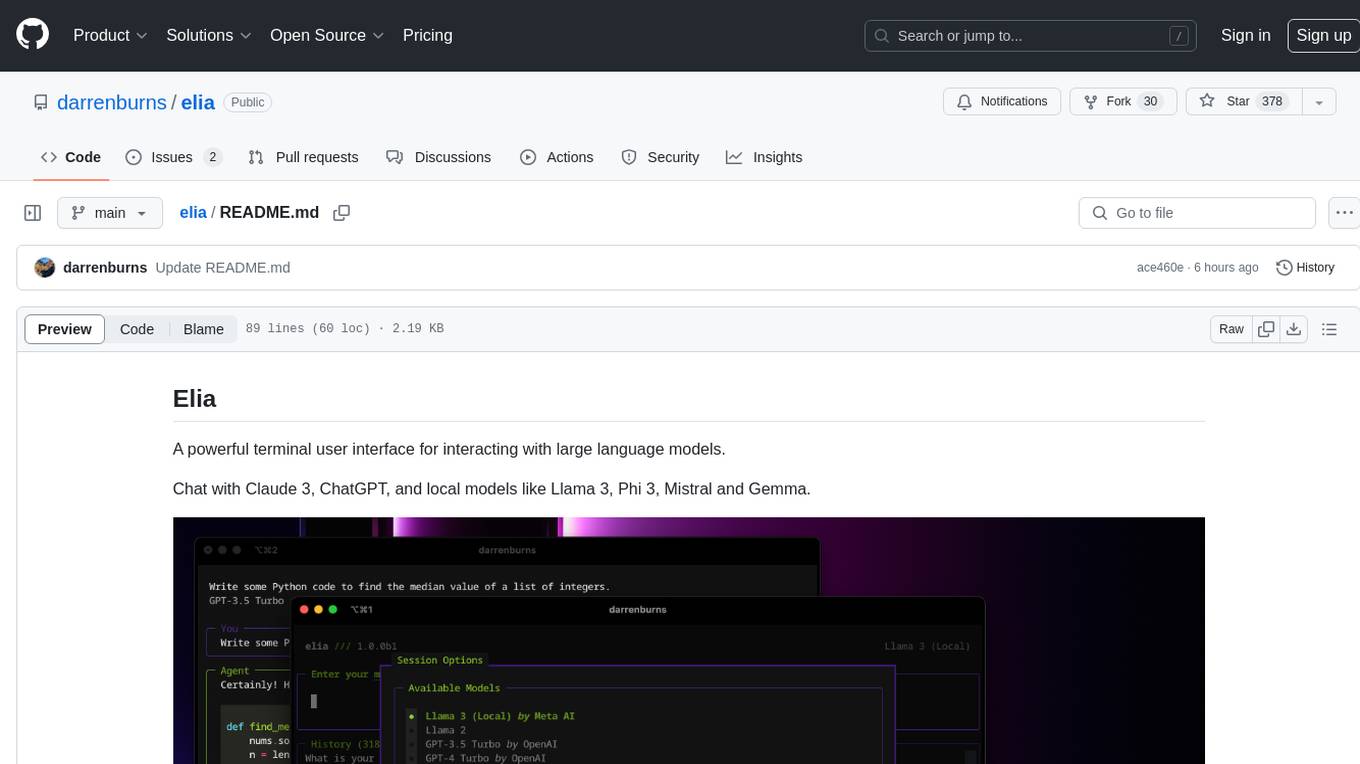
elia
Elia is a powerful terminal user interface designed for interacting with large language models. It allows users to chat with models like Claude 3, ChatGPT, Llama 3, Phi 3, Mistral, and Gemma. Conversations are stored locally in a SQLite database, ensuring privacy. Users can run local models through 'ollama' without data leaving their machine. Elia offers easy installation with pipx and supports various environment variables for different models. It provides a quick start to launch chats and manage local models. Configuration options are available to customize default models, system prompts, and add new models. Users can import conversations from ChatGPT and wipe the database when needed. Elia aims to enhance user experience in interacting with language models through a user-friendly interface.
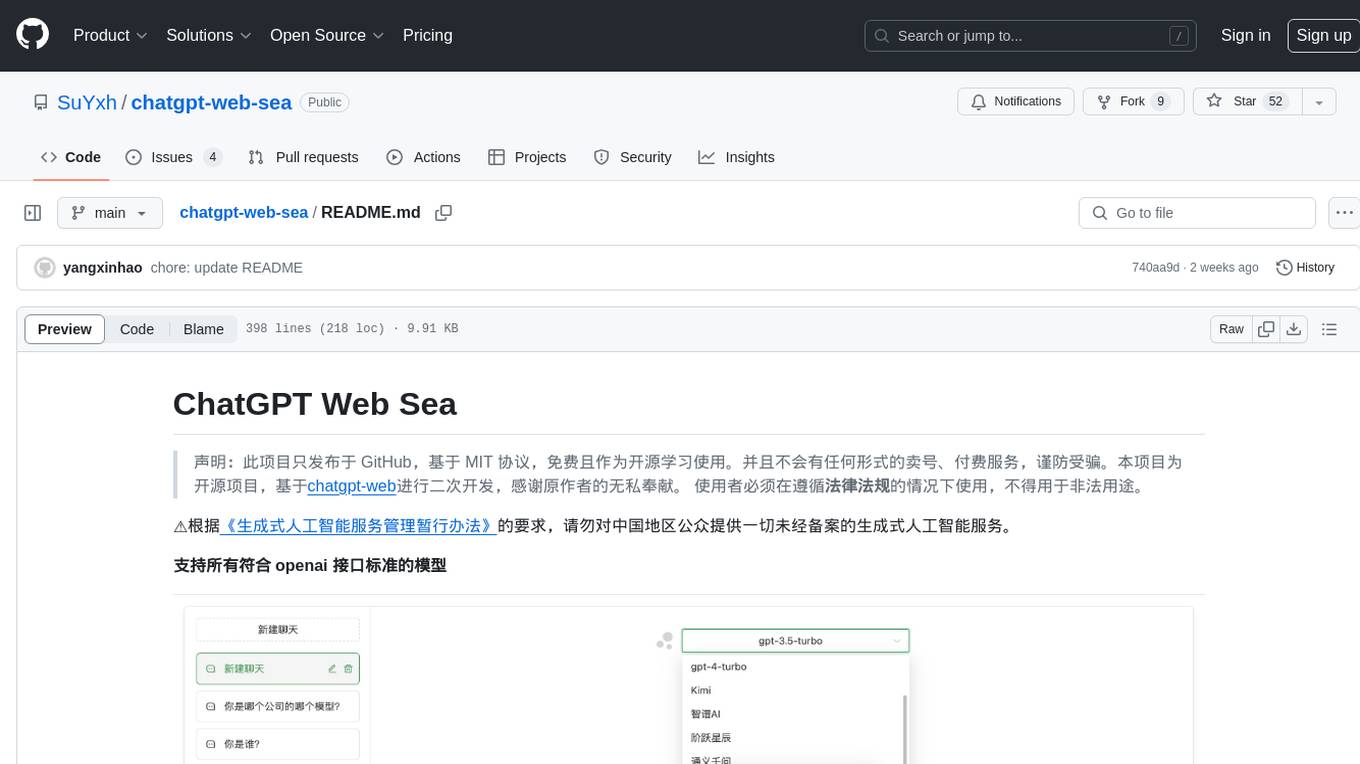
chatgpt-web-sea
ChatGPT Web Sea is an open-source project based on ChatGPT-web for secondary development. It supports all models that comply with the OpenAI interface standard, allows for model selection, configuration, and extension, and is compatible with OneAPI. The tool includes a Chinese ChatGPT tuning guide, supports file uploads, and provides model configuration options. Users can interact with the tool through a web interface, configure models, and perform tasks such as model selection, API key management, and chat interface setup. The project also offers Docker deployment options and instructions for manual packaging.
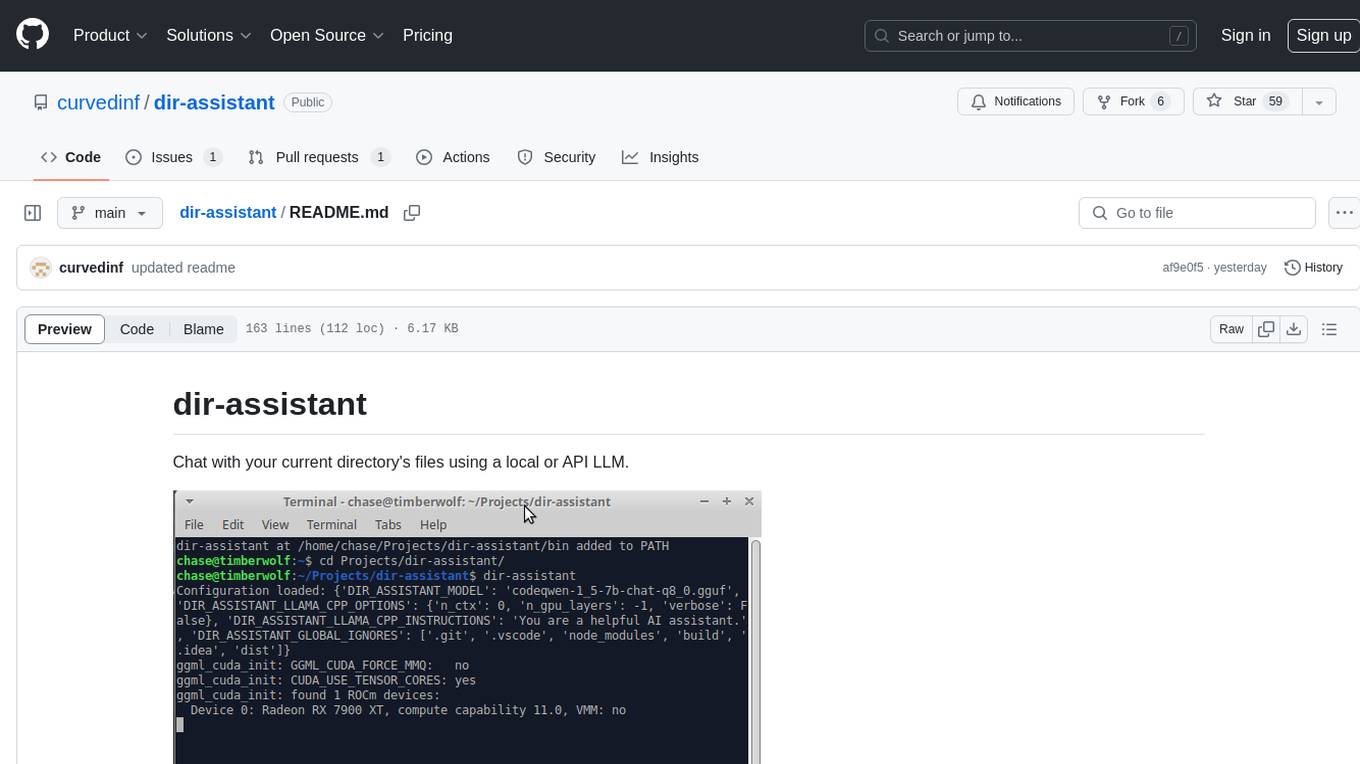
dir-assistant
Dir-assistant is a tool that allows users to interact with their current directory's files using local or API Language Models (LLMs). It supports various platforms and provides API support for major LLM APIs. Users can configure and customize their local LLMs and API LLMs using the tool. Dir-assistant also supports model downloads and configurations for efficient usage. It is designed to enhance file interaction and retrieval using advanced language models.
kubeai
KubeAI is a highly scalable AI platform that runs on Kubernetes, serving as a drop-in replacement for OpenAI with API compatibility. It can operate OSS model servers like vLLM and Ollama, with zero dependencies and additional OSS addons included. Users can configure models via Kubernetes Custom Resources and interact with models through a chat UI. KubeAI supports serving various models like Llama v3.1, Gemma2, and Qwen2, and has plans for model caching, LoRA finetuning, and image generation.
renumics-rag
Renumics RAG is a retrieval-augmented generation assistant demo that utilizes LangChain and Streamlit. It provides a tool for indexing documents and answering questions based on the indexed data. Users can explore and visualize RAG data, configure OpenAI and Hugging Face models, and interactively explore questions and document snippets. The tool supports GPU and CPU setups, offers a command-line interface for retrieving and answering questions, and includes a web application for easy access. It also allows users to customize retrieval settings, embeddings models, and database creation. Renumics RAG is designed to enhance the question-answering process by leveraging indexed documents and providing detailed answers with sources.
llm-term
LLM-Term is a Rust-based CLI tool that generates and executes terminal commands using OpenAI's language models or local Ollama models. It offers configurable model and token limits, works on both PowerShell and Unix-like shells, and provides a seamless user experience for generating commands based on prompts. Users can easily set up the tool, customize configurations, and leverage different models for command generation.
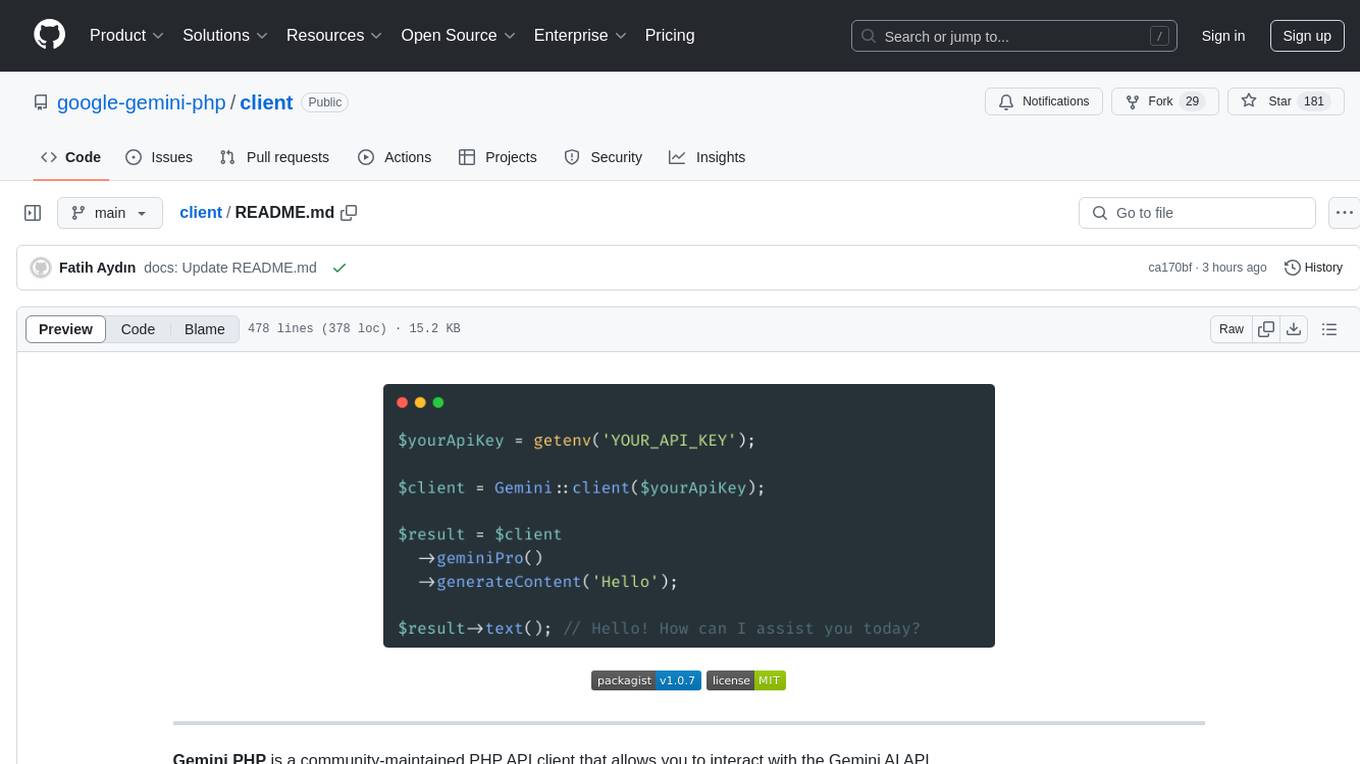
client
Gemini PHP is a PHP API client for interacting with the Gemini AI API. It allows users to generate content, chat, count tokens, configure models, embed resources, list models, get model information, troubleshoot timeouts, and test API responses. The client supports various features such as text-only input, text-and-image input, multi-turn conversations, streaming content generation, token counting, model configuration, and embedding techniques. Users can interact with Gemini's API to perform tasks related to natural language generation and text analysis.
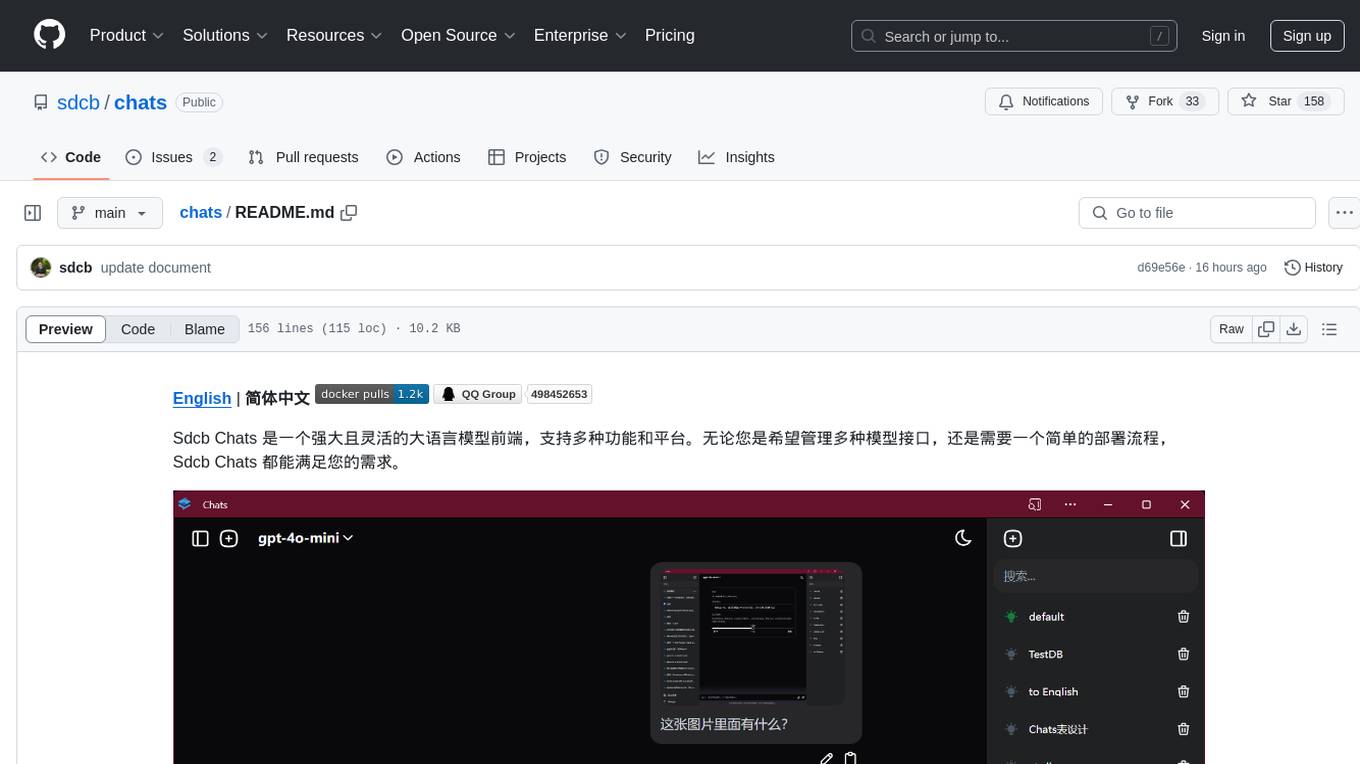
chats
Sdcb Chats is a powerful and flexible frontend for large language models, supporting multiple functions and platforms. Whether you want to manage multiple model interfaces or need a simple deployment process, Sdcb Chats can meet your needs. It supports dynamic management of multiple large language model interfaces, integrates visual models to enhance user interaction experience, provides fine-grained user permission settings for security, real-time tracking and management of user account balances, easy addition, deletion, and configuration of models, transparently forwards user chat requests based on the OpenAI protocol, supports multiple databases including SQLite, SQL Server, and PostgreSQL, compatible with various file services such as local files, AWS S3, Minio, Aliyun OSS, Azure Blob Storage, and supports multiple login methods including Keycloak SSO and phone SMS verification.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.