
open-responses
OpenResponses API empowers developers to leverage the incredible capabilities of various LLM providers through a familiar interface - the OpenAI Responses API structure.
Stars: 56
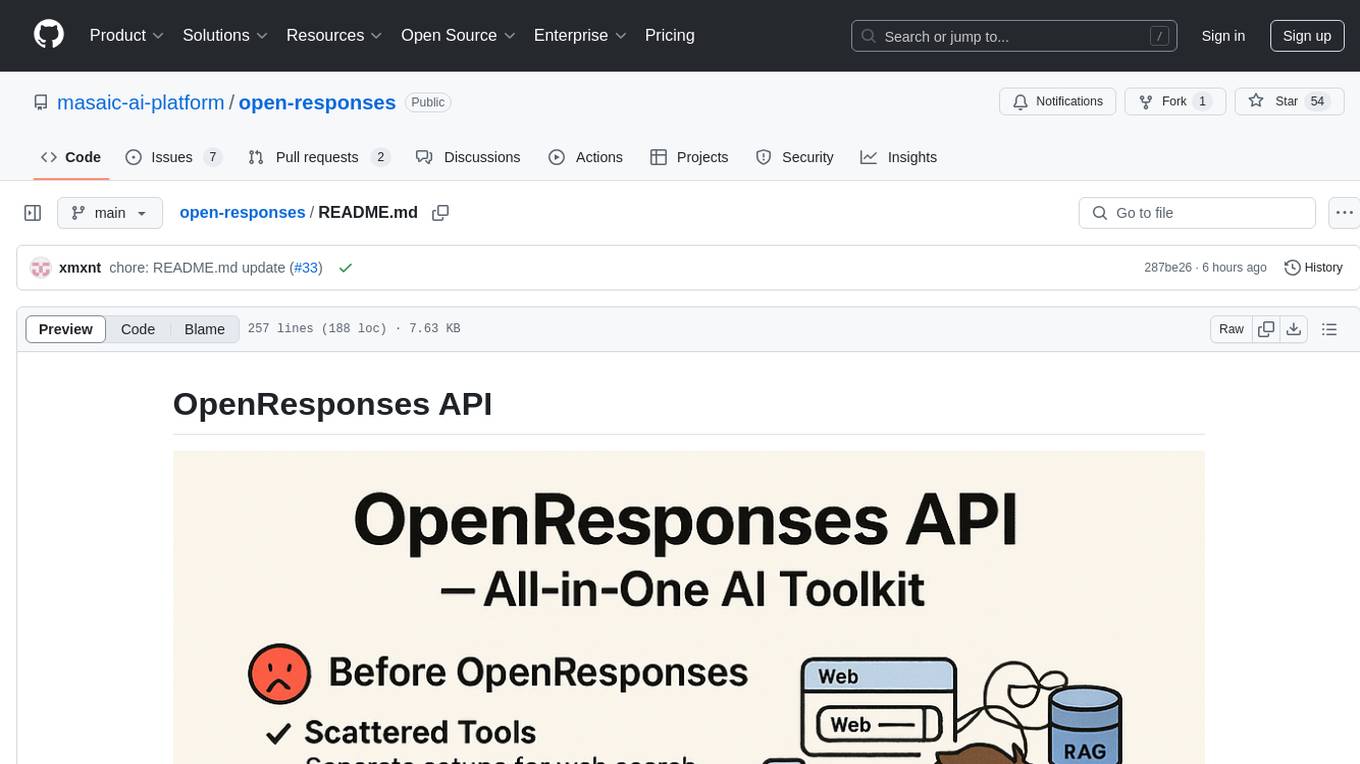
OpenResponses API provides enterprise-grade AI capabilities through a powerful API, simplifying development and deployment while ensuring complete data control. It offers automated tracing, integrated RAG for contextual information retrieval, pre-built tool integrations, self-hosted architecture, and an OpenAI-compatible interface. The toolkit addresses development challenges like feature gaps and integration complexity, as well as operational concerns such as data privacy and operational control. Engineering teams can benefit from improved productivity, production readiness, compliance confidence, and simplified architecture by choosing OpenResponses.
README:

Unlock enterprise-grade AI capabilities through a single, powerful API — simplify development, accelerate deployment, and maintain complete data control


OpenResponses revolutionizes how developers build AI applications by providing a comprehensive, production-ready toolkit with essential enterprise features—all through an elegantly simplified API interface. Stop cobbling together disparate tools and start building what matters.
Run OpenResponses locally to access an OpenAI-compatible API that works seamlessly with multiple model providers and supports unlimited tool integrations. Deploy a complete AI infrastructure on your own hardware with full data sovereignty.
docker run -p 8080:8080 masaicai/open-responses:latestopenai_client = OpenAI(base_url="http://localhost:8080/v1", api_key=os.getenv("OPENAI_API_KEY"), default_headers={'x-model-provider': 'openai'})
response = openai_client.responses.create(
model="gpt-4o-mini",
input="Write a poem on Masaic"
)client = AsyncOpenAI(base_url="http://localhost:8080/v1", api_key=os.getenv("OPENAI_API_KEY"), default_headers={'x-model-provider': 'openai'})
agent = Agent(
name="Assistant",
instructions="You are a humorous poet who can write funny poems of 4 lines.",
model=OpenAIResponsesModel(model="gpt-4o-mini", openai_client=client)
)curl --location 'http://localhost:8080/v1/responses' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer OPENAI_API_KEY' \
--header 'x-model-provider: openai' \
--data '{
"model": "gpt-4o",
"stream": false,
"input": [
{
"role": "user",
"content": "Write a poem on Masaic"
}
]
}'For detailed implementation instructions, see our Quick Start Guide.
- Getting Started
- Core Capabilities
- Key Problems Solved
- Why Engineering Teams Should Choose OpenResponses
- API Reference
- Coming Soon
- Frequently Asked Questions
- Configuration
- Documentation
- Local Development
- Production Use
- Contributing
- License
| Feature | Description | Benefit |
|---|---|---|
| Automated Tracing | Comprehensive request and response monitoring | Track performance and usage without additional code |
| Integrated RAG | Contextual information retrieval | Enhance responses with relevant external data automatically |
| Pre-built Tool Integrations | Web search, GitHub access, and more | Deploy advanced capabilities instantly |
| Self-Hosted Architecture | Full control of deployment infrastructure | Maintain complete data sovereignty |
| OpenAI-Compatible Interface | Drop-in replacement for existing OpenAI implementations | Minimal code changes for migration |
- Feature Gap: Most open-source AI models lack critical enterprise capabilities required for production environments
- Integration Complexity: Implementing supplementary features like retrieval augmentation and monitoring requires significant development overhead
- Resource Diversion: Engineering teams spend excessive time on infrastructure rather than core application logic
- Data Privacy: Organizations with sensitive data face compliance barriers when using cloud-hosted AI services
- Operational Control: Many applications require full control over the AI processing pipeline
- Developer Productivity: Focus engineering efforts on application features rather than infrastructure
- Production Readiness: Enterprise capabilities and batteries included out-of-the-box
- Compliance Confidence: Deploy with data privacy requirements fully addressed
- Simplified Architecture: Consolidate AI infrastructure through widely used OpenAI API Specifications
The API implements the following OpenAI-compatible endpoints:
| Endpoint | Description |
|---|---|
POST /v1/responses |
Create a new model response |
GET /v1/responses/{responseId} |
Retrieve a specific response |
DELETE /v1/responses/{responseId} |
Delete a response |
GET /v1/responses/{responseId}/input_items |
List input items for a response |
Replace the placeholder API keys with your own values.
curl --location 'http://localhost:8080/v1/responses' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer GROQ_API_KEY' \
--data '{
"model": "llama-3.2-3b-preview",
"stream": true,
"input": [
{
"role": "user",
"content": "Write a poem on OpenResponses"
}
]
}'curl --location 'http://localhost:8080/v1/responses' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer ANTHROPIC_API_KEY' \
--header 'x-model-provider: claude' \
--data '{
"model": "claude-3-5-sonnet-20241022",
"stream": false,
"input": [
{
"role": "user",
"content": "Write a poem on OpenResponses"
}
]
}'curl --location 'http://localhost:8080/v1/responses' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer YOUR_API_KEY' \
--data '{
"model": "your-model",
"stream": false,
"tools": [
{
"type": "brave_web_search"
}
],
"input": [
{
"role": "user",
"content": "What are the latest developments in AI?"
}
]
}'We're continuously evolving OpenResponses with powerful new features to elevate your AI applications even further. Stay tuned!
Yes! OpenResponses acts as a pass-through to the provider APIs using your own keys.
Our benchmarks show minimal overhead compared to direct API calls.
OpenResponses standardizes error responses across providers:
{
"type": "rate_limit_exceeded",
"message": "Rate limit exceeded. Please try again in 30 seconds.",
"param": null,
"code": "rate_limit"
}The application supports the following environment variables:
| Variable | Description | Default |
|---|---|---|
MCP_SERVER_CONFIG_FILE_PATH |
Path to MCP server configuration | - |
MASAIC_MAX_TOOL_CALLS |
Maximum number of allowed tool calls | 10 |
MASAIC_MAX_STREAMING_TIMEOUT |
Maximum streaming timeout in ms | 60000 |
SPRING_PRODFILES_ACTIVE |
otel profile enables open telemetry exports |
- |
For more details on granular configurations refer:
Explore our comprehensive documentation to learn more about OpenResponses features, configuration options, and integration methods.
Follow these instructions to set up the project locally for development:
- Java JDK 21+
- Gradle (optional, as project includes Gradle Wrapper)
- Docker (optional, for containerized setup)
- Clone the repository
git clone https://github.com/masaic-ai-platform/open-responses.git
cd open-responses- Build the project
Use the Gradle Wrapper included in the project:
./gradlew build- Configure Environment Variables
Create or update the application.properties file with necessary configuration under src/main/resources:
server.port: 8080Set any additional configuration required by your project.
- Run the server
To start the server in development mode:
./gradlew bootRunBuild and run the application using Docker:
./gradlew build
docker build -t openresponses .
docker run -p 8080:8080 -d openresponsesRun the tests with:
./gradlew testAlpha Release Disclaimer: This project is currently in alpha stage. The API and features are subject to breaking changes as we continue to evolve and improve the platform. While we strive to maintain stability, please be aware that updates may require modifications to your integration code.
Contributions are welcome! Please feel free to submit a Pull Request.
"Alone we can do so little; together we can do so much." — Helen Keller
This project is licensed under the Apache License 2.0 - see the LICENSE file for details.
Made with ❤️ by the Masaic AI Team
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for open-responses
Similar Open Source Tools
open-responses
OpenResponses API provides enterprise-grade AI capabilities through a powerful API, simplifying development and deployment while ensuring complete data control. It offers automated tracing, integrated RAG for contextual information retrieval, pre-built tool integrations, self-hosted architecture, and an OpenAI-compatible interface. The toolkit addresses development challenges like feature gaps and integration complexity, as well as operational concerns such as data privacy and operational control. Engineering teams can benefit from improved productivity, production readiness, compliance confidence, and simplified architecture by choosing OpenResponses.
ai-gateway
LangDB AI Gateway is an open-source enterprise AI gateway built in Rust. It provides a unified interface to all LLMs using the OpenAI API format, focusing on high performance, enterprise readiness, and data control. The gateway offers features like comprehensive usage analytics, cost tracking, rate limiting, data ownership, and detailed logging. It supports various LLM providers and provides OpenAI-compatible endpoints for chat completions, model listing, embeddings generation, and image generation. Users can configure advanced settings, such as rate limiting, cost control, dynamic model routing, and observability with OpenTelemetry tracing. The gateway can be run with Docker Compose and integrated with MCP tools for server communication.
claude-task-master
Claude Task Master is a task management system designed for AI-driven development with Claude, seamlessly integrating with Cursor AI. It allows users to configure tasks through environment variables, parse PRD documents, generate structured tasks with dependencies and priorities, and manage task status. The tool supports task expansion, complexity analysis, and smart task recommendations. Users can interact with the system through CLI commands for task discovery, implementation, verification, and completion. It offers features like task breakdown, dependency management, and AI-driven task generation, providing a structured workflow for efficient development.
orra
Orra is a tool for building production-ready multi-agent applications that handle complex real-world interactions. It coordinates tasks across existing stack, agents, and tools run as services using intelligent reasoning. With features like smart pre-evaluated execution plans, domain grounding, durable execution, and automatic service health monitoring, Orra enables users to go fast with tools as services and revert state to handle failures. It provides real-time status tracking and webhook result delivery, making it ideal for developers looking to move beyond simple crews and agents.

quantalogic
QuantaLogic is a ReAct framework for building advanced AI agents that seamlessly integrates large language models with a robust tool system. It aims to bridge the gap between advanced AI models and practical implementation in business processes by enabling agents to understand, reason about, and execute complex tasks through natural language interaction. The framework includes features such as ReAct Framework, Universal LLM Support, Secure Tool System, Real-time Monitoring, Memory Management, and Enterprise Ready components.
code_puppy
Code Puppy is an AI-powered code generation agent designed to understand programming tasks, generate high-quality code, and explain its reasoning. It supports multi-language code generation, interactive CLI, and detailed code explanations. The tool requires Python 3.9+ and API keys for various models like GPT, Google's Gemini, Cerebras, and Claude. It also integrates with MCP servers for advanced features like code search and documentation lookups. Users can create custom JSON agents for specialized tasks and access a variety of tools for file management, code execution, and reasoning sharing.

evalchemy
Evalchemy is a unified and easy-to-use toolkit for evaluating language models, focusing on post-trained models. It integrates multiple existing benchmarks such as RepoBench, AlpacaEval, and ZeroEval. Key features include unified installation, parallel evaluation, simplified usage, and results management. Users can run various benchmarks with a consistent command-line interface and track results locally or integrate with a database for systematic tracking and leaderboard submission.

factorio-learning-environment
Factorio Learning Environment is an open source framework designed for developing and evaluating LLM agents in the game of Factorio. It provides two settings: Lab-play with structured tasks and Open-play for building large factories. Results show limitations in spatial reasoning and automation strategies. Agents interact with the environment through code synthesis, observation, action, and feedback. Tools are provided for game actions and state representation. Agents operate in episodes with observation, planning, and action execution. Tasks specify agent goals and are implemented in JSON files. The project structure includes directories for agents, environment, cluster, data, docs, eval, and more. A database is used for checkpointing agent steps. Benchmarks show performance metrics for different configurations.
dspy.rb
DSPy.rb is a Ruby framework for building reliable LLM applications using composable, type-safe modules. It enables developers to define typed signatures and compose them into pipelines, offering a more structured approach compared to traditional prompting. The framework embraces Ruby conventions and adds innovations like CodeAct agents and enhanced production instrumentation, resulting in scalable LLM applications that are robust and efficient. DSPy.rb is actively developed, with a focus on stability and real-world feedback through the 0.x series before reaching a stable v1.0 API.
CrackSQL
CrackSQL is a powerful SQL dialect translation tool that integrates rule-based strategies with large language models (LLMs) for high accuracy. It enables seamless conversion between dialects (e.g., PostgreSQL → MySQL) with flexible access through Python API, command line, and web interface. The tool supports extensive dialect compatibility, precision & advanced processing, and versatile access & integration. It offers three modes for dialect translation and demonstrates high translation accuracy over collected benchmarks. Users can deploy CrackSQL using PyPI package installation or source code installation methods. The tool can be extended to support additional syntax, new dialects, and improve translation efficiency. The project is actively maintained and welcomes contributions from the community.
SwiftAI
SwiftAI is a modern, type-safe Swift library for building AI-powered apps. It provides a unified API that works seamlessly across different AI models, including Apple's on-device models and cloud-based services like OpenAI. With features like model agnosticism, structured output, agent tool loop, conversations, extensibility, and Swift-native design, SwiftAI offers a powerful toolset for developers to integrate AI capabilities into their applications. The library supports easy installation via Swift Package Manager and offers detailed guidance on getting started, structured responses, tool use, model switching, conversations, and advanced constraints. SwiftAI aims to simplify AI integration by providing a type-safe and versatile solution for various AI tasks.

plexe
Plexe is a tool that allows users to create machine learning models by describing them in plain language. Users can explain their requirements, provide a dataset, and the AI-powered system will build a fully functional model through an automated agentic approach. It supports multiple AI agents and model building frameworks like XGBoost, CatBoost, and Keras. Plexe also provides Docker images with pre-configured environments, YAML configuration for customization, and support for multiple LiteLLM providers. Users can visualize experiment results using the built-in Streamlit dashboard and extend Plexe's functionality through custom integrations.

crawl4ai
Crawl4AI is a powerful and free web crawling service that extracts valuable data from websites and provides LLM-friendly output formats. It supports crawling multiple URLs simultaneously, replaces media tags with ALT, and is completely free to use and open-source. Users can integrate Crawl4AI into Python projects as a library or run it as a standalone local server. The tool allows users to crawl and extract data from specified URLs using different providers and models, with options to include raw HTML content, force fresh crawls, and extract meaningful text blocks. Configuration settings can be adjusted in the `crawler/config.py` file to customize providers, API keys, chunk processing, and word thresholds. Contributions to Crawl4AI are welcome from the open-source community to enhance its value for AI enthusiasts and developers.
core
CORE is an open-source unified, persistent memory layer for all AI tools, allowing developers to maintain context across different tools like Cursor, ChatGPT, and Claude. It aims to solve the issue of context switching and information loss between sessions by creating a knowledge graph that remembers conversations, decisions, and insights. With features like unified memory, temporal knowledge graph, browser extension, chat with memory, auto-sync from apps, and MCP integration hub, CORE provides a seamless experience for managing and recalling context. The tool's ingestion pipeline captures evolving context through normalization, extraction, resolution, and graph integration, resulting in a dynamic memory that grows and changes with the user. When recalling from memory, CORE utilizes search, re-ranking, filtering, and output to provide relevant and contextual answers. Security measures include data encryption, authentication, access control, and vulnerability reporting.
sdg_hub
sdg_hub is a modular Python framework designed for building synthetic data generation pipelines using composable blocks and flows. Users can mix and match LLM-powered and traditional processing blocks to create sophisticated data generation workflows. The toolkit offers features such as modular composability, async performance, built-in validation, auto-discovery, rich monitoring, dataset schema discovery, and easy extensibility. sdg_hub provides detailed documentation and supports high-throughput processing with error handling. It simplifies the process of transforming datasets by allowing users to chain blocks together in YAML-configured flows, enabling the creation of complex data generation pipelines.
Scrapling
Scrapling is a high-performance, intelligent web scraping library for Python that automatically adapts to website changes while significantly outperforming popular alternatives. For both beginners and experts, Scrapling provides powerful features while maintaining simplicity. It offers features like fast and stealthy HTTP requests, adaptive scraping with smart element tracking and flexible selection, high performance with lightning-fast speed and memory efficiency, and developer-friendly navigation API and rich text processing. It also includes advanced parsing features like smart navigation, content-based selection, handling structural changes, and finding similar elements. Scrapling is designed to handle anti-bot protections and website changes effectively, making it a versatile tool for web scraping tasks.
For similar tasks

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.

AI-in-a-Box
AI-in-a-Box is a curated collection of solution accelerators that can help engineers establish their AI/ML environments and solutions rapidly and with minimal friction, while maintaining the highest standards of quality and efficiency. It provides essential guidance on the responsible use of AI and LLM technologies, specific security guidance for Generative AI (GenAI) applications, and best practices for scaling OpenAI applications within Azure. The available accelerators include: Azure ML Operationalization in-a-box, Edge AI in-a-box, Doc Intelligence in-a-box, Image and Video Analysis in-a-box, Cognitive Services Landing Zone in-a-box, Semantic Kernel Bot in-a-box, NLP to SQL in-a-box, Assistants API in-a-box, and Assistants API Bot in-a-box.

spring-ai
The Spring AI project provides a Spring-friendly API and abstractions for developing AI applications. It offers a portable client API for interacting with generative AI models, enabling developers to easily swap out implementations and access various models like OpenAI, Azure OpenAI, and HuggingFace. Spring AI also supports prompt engineering, providing classes and interfaces for creating and parsing prompts, as well as incorporating proprietary data into generative AI without retraining the model. This is achieved through Retrieval Augmented Generation (RAG), which involves extracting, transforming, and loading data into a vector database for use by AI models. Spring AI's VectorStore abstraction allows for seamless transitions between different vector database implementations.
ragstack-ai
RAGStack is an out-of-the-box solution simplifying Retrieval Augmented Generation (RAG) in GenAI apps. RAGStack includes the best open-source for implementing RAG, giving developers a comprehensive Gen AI Stack leveraging LangChain, CassIO, and more. RAGStack leverages the LangChain ecosystem and is fully compatible with LangSmith for monitoring your AI deployments.
breadboard
Breadboard is a library for prototyping generative AI applications. It is inspired by the hardware maker community and their boundless creativity. Breadboard makes it easy to wire prototypes and share, remix, reuse, and compose them. The library emphasizes ease and flexibility of wiring, as well as modularity and composability.
cloudflare-ai-web
Cloudflare-ai-web is a lightweight and easy-to-use tool that allows you to quickly deploy a multi-modal AI platform using Cloudflare Workers AI. It supports serverless deployment, password protection, and local storage of chat logs. With a size of only ~638 kB gzip, it is a great option for building AI-powered applications without the need for a dedicated server.
app-builder
AppBuilder SDK is a one-stop development tool for AI native applications, providing basic cloud resources, AI capability engine, Qianfan large model, and related capability components to improve the development efficiency of AI native applications.
cookbook
This repository contains community-driven practical examples of building AI applications and solving various tasks with AI using open-source tools and models. Everyone is welcome to contribute, and we value everybody's contribution! There are several ways you can contribute to the Open-Source AI Cookbook: Submit an idea for a desired example/guide via GitHub Issues. Contribute a new notebook with a practical example. Improve existing examples by fixing issues/typos. Before contributing, check currently open issues and pull requests to avoid working on something that someone else is already working on.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.
griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.