
morph
Morph is a python-centric full-stack framework for building and deploying AI apps.
Stars: 72
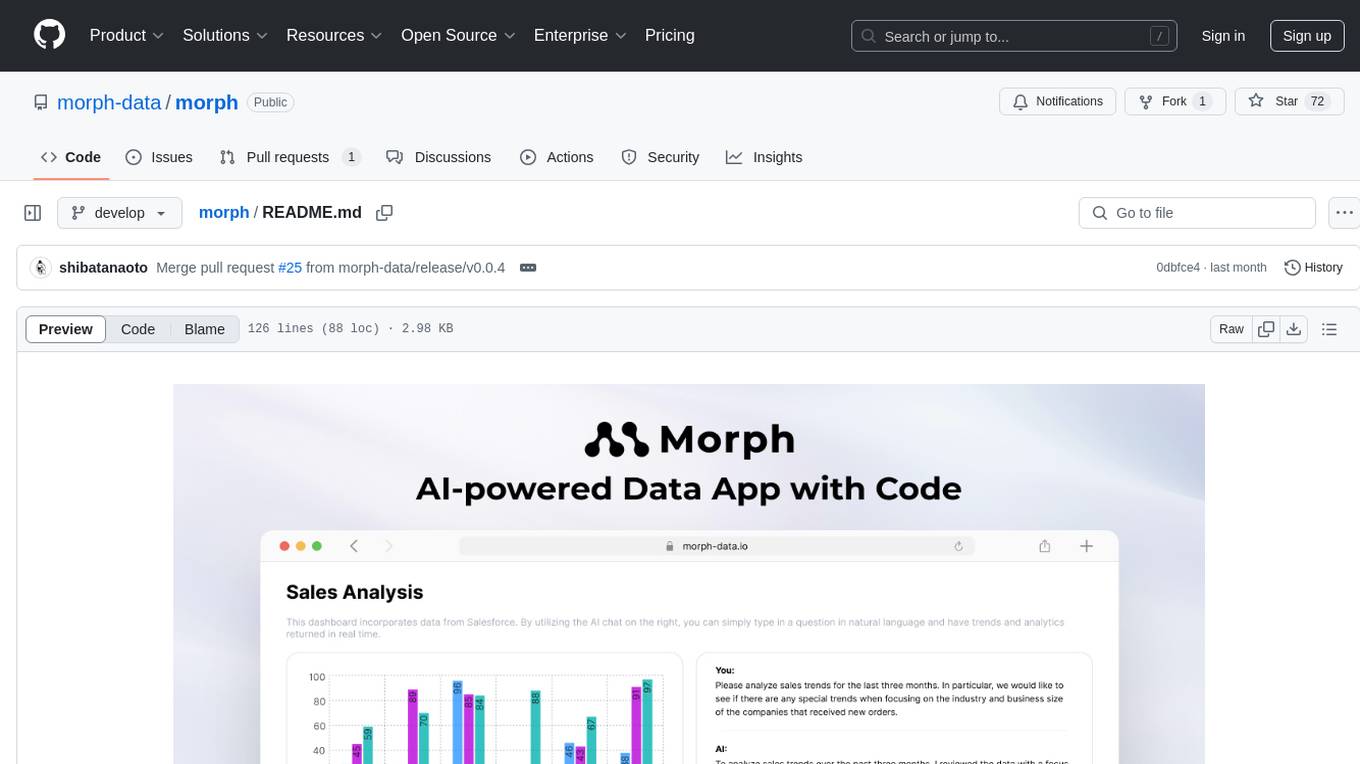
Morph is a python-centric full-stack framework for building and deploying data apps. It is fast to start, deploy and operate, requires no HTML/CSS knowledge, and is customizable with Python and SQL for advanced data workflows. With Markdown-based syntax and pre-made components, users can create visually appealing designs without writing HTML or CSS.
README:

Morph is a python-centric full-stack framework for building and deploying data apps.
- Fast to start 🚀 - Allows you to get up and running with just three commands.
- Deploy and operate 🌐 - Easily deploy your data apps and manage them in production. Managed cloud is available for user authentication and secure data connection.
- No HTML/CSS knowledge required🔰 - With Markdown-based syntax and pre-made components, you can create flexible, visually appealing designs without writing a single line of HTML or CSS.
- Customizable 🛠️ - Chain Python and SQL for advanced data workflows. Custom CSS and custom React components are available for building tailored UI.
- Install morph
pip install morph-data- Create a new project
morph new- Start dev server
morph serve- Visit
http://localhsot:8080on browser.
Understanding the concept of developing a data app in Morph will let you do a flying start.
- Develop the data processing in Python and give it an alias.
- Create an .mdx file. Each .mdx file becomes a page of your app.
- Place the component in the MDX file and specify the alias to connect to.
.
├─ pages
│ └─ index.mdx
├─ python
│ └─ closing_deals_vis.py
└─ sql
└─ closing_deals.sql
- Create each files in
sql,pythonandpagesdirectories.
SQL: Using DuckDB to read CSV file.
{{
config(
name = "example_data",
connection = "DUCKDB"
)
}}
select
*
from
read_csv("example.csv")Python: Using Plotly to create a chart.
import plotly.express as px
import morph
from morph import MorphGlobalContext
@morph.func
@morph.load_data("example_data")
def example_chart(context: MorphGlobalContext):
df = context.data["example_data"].groupby("state").sum(["population"]).reset_index()
fig = px.bar(df, x="state", y="population")
return figMDX: Define the page and connect the data.
export const title = "Starter App"
# Starter App
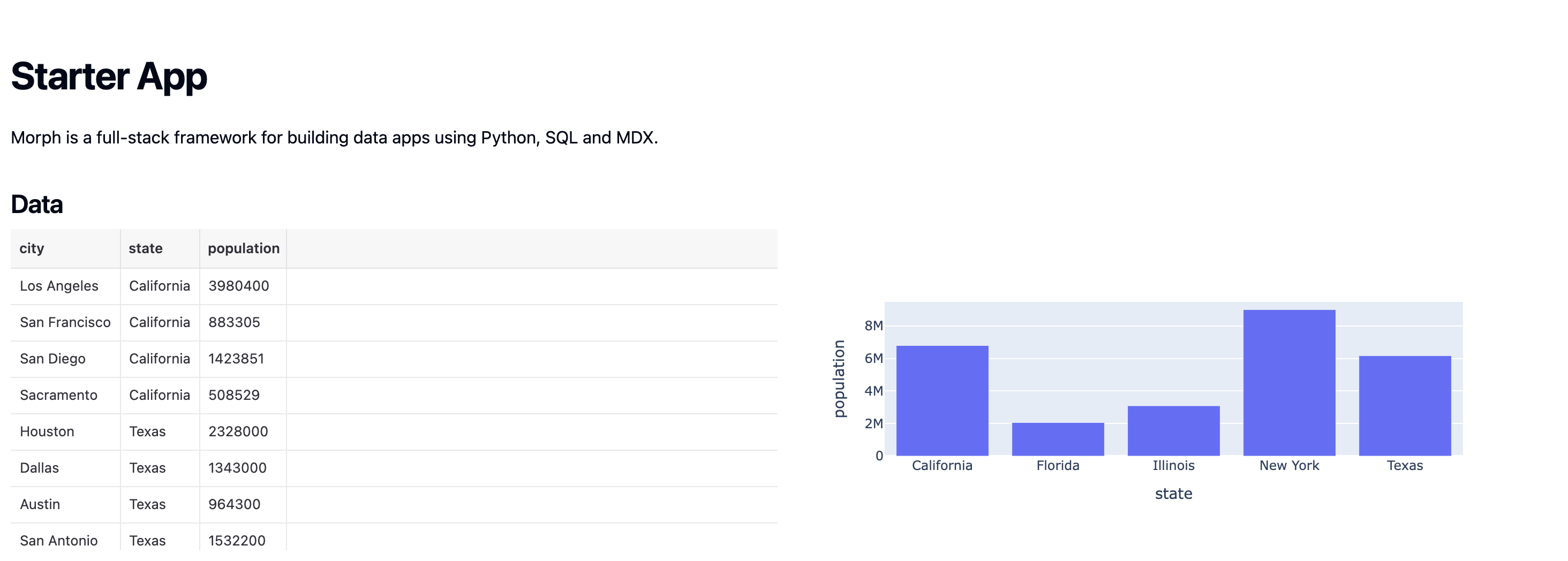
Morph is a full-stack framework for building data apps using Python, SQL and MDX.
## Data
<Grid cols="2">
<div>
<DataTable loadData="example_data" height={300} />
</div>
<div>
<Embed loadData="example_chart" height={300} />
</div>
</Grid>- Run
morph serveto open the app!
Visit https://docs.morph-data.io for more documentation.
Thanks for your interest in helping improve Morph ❤️
- Before contributing, please read the CONTRIBUTING.md.
- If you find any issues, please let us know and open an issue.
Morph is Apache 2.0 licensed.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for morph
Similar Open Source Tools
morph
Morph is a python-centric full-stack framework for building and deploying data apps. It is fast to start, deploy and operate, requires no HTML/CSS knowledge, and is customizable with Python and SQL for advanced data workflows. With Markdown-based syntax and pre-made components, users can create visually appealing designs without writing HTML or CSS.
panda-etl
PandaETL is an open-source, no-code ETL tool designed to extract and parse data from various document types including PDFs, emails, websites, audio files, and more. With an intuitive interface and powerful backend, PandaETL simplifies the process of data extraction and transformation, making it accessible to users without programming skills.

company-research-agent
Agentic Company Researcher is a multi-agent tool that generates comprehensive company research reports by utilizing a pipeline of AI agents to gather, curate, and synthesize information from various sources. It features multi-source research, AI-powered content filtering, real-time progress streaming, dual model architecture, modern React frontend, and modular architecture. The tool follows an agentic framework with specialized research and processing nodes, leverages separate models for content generation, uses a content curation system for relevance scoring and document processing, and implements a real-time communication system via WebSocket connections. Users can set up the tool quickly using the provided setup script or manually, and it can also be deployed using Docker and Docker Compose. The application can be used for local development and deployed to various cloud platforms like AWS Elastic Beanstalk, Docker, Heroku, and Google Cloud Run.
logfire
Pydantic Logfire is an observability platform that provides simple and powerful dashboard, Python-centric insights, SQL querying, OpenTelemetry integration, and Pydantic validation analytics. It offers unparalleled visibility into Python applications' behavior and allows querying data using standard SQL. Logfire is an opinionated wrapper around OpenTelemetry, supporting traces, metrics, and logs. The Python SDK for logfire is open source, while the server application for recording and displaying data is closed source.
AutoDocs
AutoDocs by Sita is a tool designed to automate documentation for any repository. It parses the repository using tree-sitter and SCIP, constructs a code dependency graph, and generates repository-wide, dependency-aware documentation and summaries. It provides a FastAPI backend for ingestion/search and a Next.js web UI for chat and exploration. Additionally, it includes an MCP server for deep search capabilities. The tool aims to simplify the process of generating accurate and high-signal documentation for codebases.

extension-gen-ai
The Looker GenAI Extension provides code examples and resources for building a Looker Extension that integrates with Vertex AI Large Language Models (LLMs). Users can leverage the power of LLMs to enhance data exploration and analysis within Looker. The extension offers generative explore functionality to ask natural language questions about data and generative insights on dashboards to analyze data by asking questions. It leverages components like BQML Remote Models, BQML Remote UDF with Vertex AI, and Custom Fine Tune Model for different integration options. Deployment involves setting up infrastructure with Terraform and deploying the Looker Extension by creating a Looker project, copying extension files, configuring BigQuery connection, connecting to Git, and testing the extension. Users can save example prompts and configure user settings for the extension. Development of the Looker Extension environment includes installing dependencies, starting the development server, and building for production.
xlang
XLang™ is a cutting-edge language designed for AI and IoT applications, offering exceptional dynamic and high-performance capabilities. It excels in distributed computing and seamless integration with popular languages like C++, Python, and JavaScript. Notably efficient, running 3 to 5 times faster than Python in AI and deep learning contexts. Features optimized tensor computing architecture for constructing neural networks through tensor expressions. Automates tensor data flow graph generation and compilation for specific targets, enhancing GPU performance by 6 to 10 times in CUDA environments.

datalore-localgen-cli
Datalore is a terminal tool for generating structured datasets from local files like PDFs, Word docs, images, and text. It extracts content, uses semantic search to understand context, applies instructions through a generated schema, and outputs clean, structured data. Perfect for converting raw or unstructured local documents into ready-to-use datasets for training, analysis, or experimentation, all without manual formatting.

langmanus
LangManus is a community-driven AI automation framework that combines language models with specialized tools for tasks like web search, crawling, and Python code execution. It implements a hierarchical multi-agent system with agents like Coordinator, Planner, Supervisor, Researcher, Coder, Browser, and Reporter. The framework supports LLM integration, search and retrieval tools, Python integration, workflow management, and visualization. LangManus aims to give back to the open-source community and welcomes contributions in various forms.
code2prompt
code2prompt is a command-line tool that converts your codebase into a single LLM prompt with a source tree, prompt templating, and token counting. It automates generating LLM prompts from codebases of any size, customizing prompt generation with Handlebars templates, respecting .gitignore, filtering and excluding files using glob patterns, displaying token count, including Git diff output, copying prompt to clipboard, saving prompt to an output file, excluding files and folders, adding line numbers to source code blocks, and more. It helps streamline the process of creating LLM prompts for code analysis, generation, and other tasks.
middleware
Middleware is an open-source engineering management tool that helps engineering leaders measure and analyze team effectiveness using DORA metrics. It integrates with CI/CD tools, automates DORA metric collection and analysis, visualizes key performance indicators, provides customizable reports and dashboards, and integrates with project management platforms. Users can set up Middleware using Docker or manually, generate encryption keys, set up backend and web servers, and access the application to view DORA metrics. The tool calculates DORA metrics using GitHub data, including Deployment Frequency, Lead Time for Changes, Mean Time to Restore, and Change Failure Rate. Middleware aims to provide DORA metrics to users based on their Git data, simplifying the process of tracking software delivery performance and operational efficiency.

open-parse
Open Parse is a Python library for visually discerning document layouts and chunking them effectively. It is designed to fill the gap in open-source libraries for handling complex documents. Unlike text splitting, which converts a file to raw text and slices it up, Open Parse visually analyzes documents for superior LLM input. It also supports basic markdown for parsing headings, bold, and italics, and has high-precision table support, extracting tables into clean Markdown formats with accuracy that surpasses traditional tools. Open Parse is extensible, allowing users to easily implement their own post-processing steps. It is also intuitive, with great editor support and completion everywhere, making it easy to use and learn.

graphiti
Graphiti is a framework for building and querying temporally-aware knowledge graphs, tailored for AI agents in dynamic environments. It continuously integrates user interactions, structured and unstructured data, and external information into a coherent, queryable graph. The framework supports incremental data updates, efficient retrieval, and precise historical queries without complete graph recomputation, making it suitable for developing interactive, context-aware AI applications.
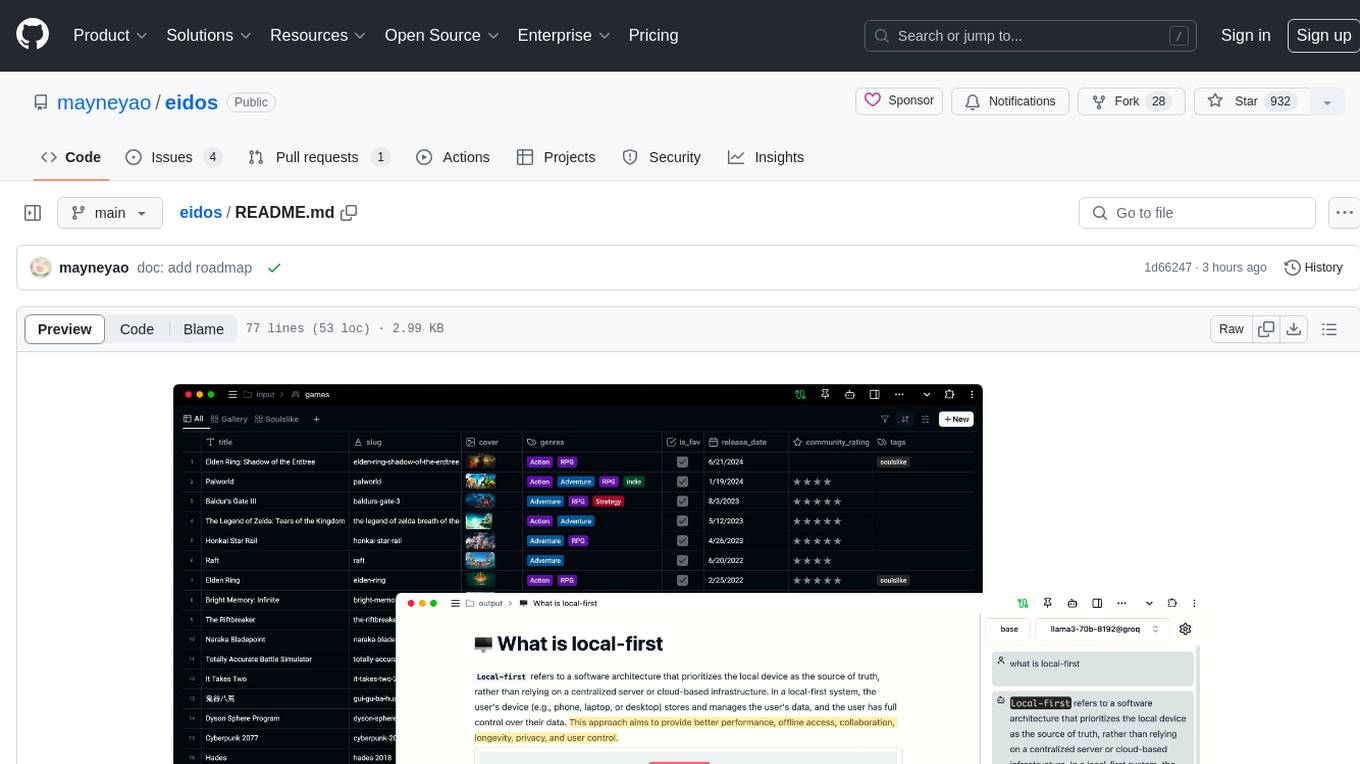
eidos
Eidos is an extensible framework for managing personal data in one place. It runs inside the browser as a PWA with offline support. It integrates AI features for translation, summarization, and data interaction. Users can customize Eidos with Prompt extension, JavaScript for Formula functions, TypeScript/JavaScript for data processing logic, and build apps using any framework. Eidos is developer-friendly with API & SDK, and uses SQLite standardization for data tables.
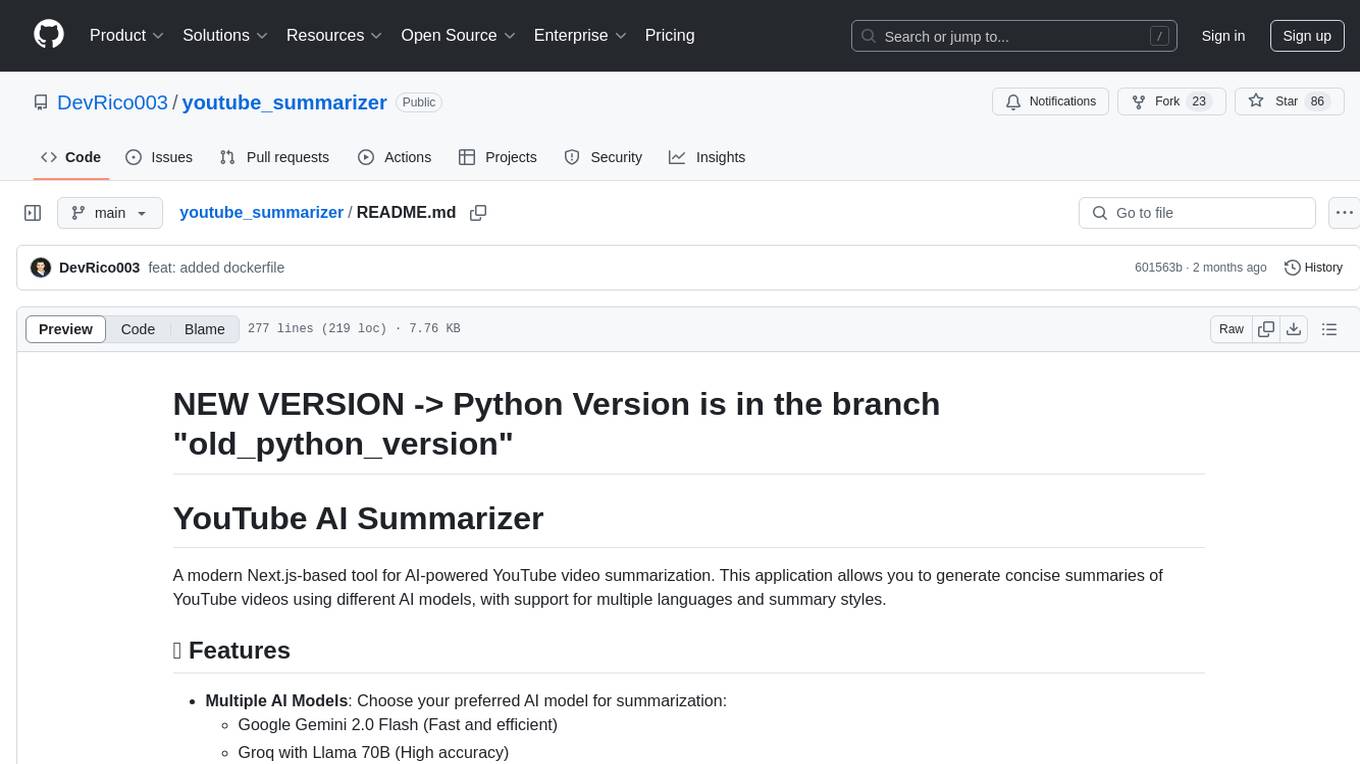
youtube_summarizer
YouTube AI Summarizer is a modern Next.js-based tool for AI-powered YouTube video summarization. It allows users to generate concise summaries of YouTube videos using various AI models, with support for multiple languages and summary styles. The application features flexible API key requirements, multilingual support, flexible summary modes, a smart history system, modern UI/UX design, and more. Users can easily input a YouTube URL, select language, summary type, and AI model, and generate summaries with real-time progress tracking. The tool offers a clean, well-structured summary view, history dashboard, and detailed history view for past summaries. It also provides configuration options for API keys and database setup, along with technical highlights, performance improvements, and a modern tech stack.

helix-db
HelixDB is a database designed specifically for AI applications, providing a single platform to manage all components needed for AI applications. It supports graph + vector data model and also KV, documents, and relational data. Key features include built-in tools for MCP, embeddings, knowledge graphs, RAG, security, logical isolation, and ultra-low latency. Users can interact with HelixDB using the Helix CLI tool and SDKs in TypeScript and Python. The roadmap includes features like organizational auth, server code improvements, 3rd party integrations, educational content, and binary quantisation for better performance. Long term projects involve developing in-house tools for knowledge graph ingestion, graph-vector storage engine, and network protocol & serdes libraries.
For similar tasks

DB-GPT
DB-GPT is an open source AI native data app development framework with AWEL(Agentic Workflow Expression Language) and agents. It aims to build infrastructure in the field of large models, through the development of multiple technical capabilities such as multi-model management (SMMF), Text2SQL effect optimization, RAG framework and optimization, Multi-Agents framework collaboration, AWEL (agent workflow orchestration), etc. Which makes large model applications with data simpler and more convenient.
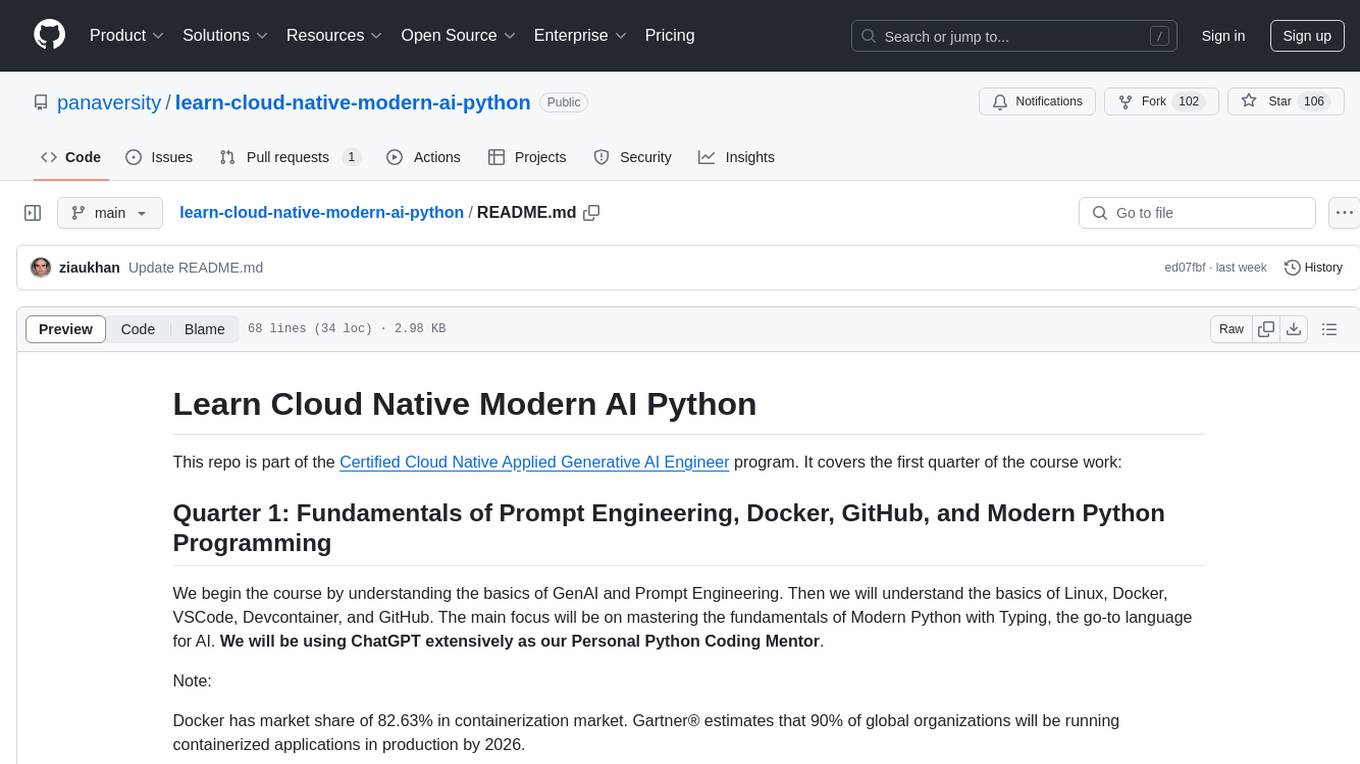
learn-cloud-native-modern-ai-python
This repository is part of the Certified Cloud Native Applied Generative AI Engineer program, focusing on the fundamentals of Prompt Engineering, Docker, GitHub, and Modern Python Programming. It covers the basics of GenAI, Linux, Docker, VSCode, Devcontainer, and GitHub. The main emphasis is on mastering Modern Python with Typing, using ChatGPT as a Personal Python Coding Mentor. The course material includes tools installation, study materials, and projects related to Python development in Docker containers and GitHub usage.
morph
Morph is a python-centric full-stack framework for building and deploying data apps. It is fast to start, deploy and operate, requires no HTML/CSS knowledge, and is customizable with Python and SQL for advanced data workflows. With Markdown-based syntax and pre-made components, users can create visually appealing designs without writing HTML or CSS.
For similar jobs

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.