
niledatabase
A Postgres platform to ship multi-tenant AI applications - fast, safe and limitless
Stars: 621
Nile is a serverless Postgres database designed for modern SaaS applications. It virtualizes tenants/customers/organizations into Postgres to enable native tenant data isolation, performance isolation, per-tenant backups, and tenant placement on shared or dedicated compute globally. With Nile, you can manage multiple tenants effortlessly, without complex permissions or buggy scripts. Additionally, it offers opt-in user management capabilities, customer-specific vector embeddings, and instant tenant admin dashboards. Built for the cloud, Nile provides a true serverless experience with effortless scaling.
README:
Nile is a Postgres platform that decouples storage from compute, virtualizes tenants, and supports vertical and horizontal scaling globally to ship AI-native B2B applications fast while being safe with limitless scale. All B2B applications are multi-tenant. A tenant/customer is primarily a company, an organization, or a workspace in your product that contains a group of users. A B2B application provides services to multiple tenants. Tenant is the basic building block of all B2B applications.
- Unlimited Postgres databases, Unlimited virtual tenant databases
- Secure isolation for customer's data and embeddings
- Customer-specific vector embeddings at 10x lower cost
- Autoscale to millions of tenants and billions of embeddings
- Place tenants on serverless or provisioned compute - globally
- Tenant-level branching, backups, schema migration, and insights
We are in public preview currently. You can sign up to Nile at https://console.thenile.dev/
This is a great resource to read more about Nile in 3 minutes https://www.thenile.dev/docs/nile-in-3-minutes
Nile is in public preview. For documentation, you can check out https://www.thenile.dev/docs. You can sign up to Nile at https://console.thenile.dev/.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for niledatabase
Similar Open Source Tools
niledatabase
Nile is a serverless Postgres database designed for modern SaaS applications. It virtualizes tenants/customers/organizations into Postgres to enable native tenant data isolation, performance isolation, per-tenant backups, and tenant placement on shared or dedicated compute globally. With Nile, you can manage multiple tenants effortlessly, without complex permissions or buggy scripts. Additionally, it offers opt-in user management capabilities, customer-specific vector embeddings, and instant tenant admin dashboards. Built for the cloud, Nile provides a true serverless experience with effortless scaling.
baserow
Baserow is a secure, open-source platform that allows users to build databases, applications, automations, and AI agents without writing any code. With enterprise-grade security compliance and both cloud and self-hosted deployment options, Baserow empowers teams to structure data, automate processes, create internal tools, and build custom dashboards. It features a spreadsheet database hybrid, AI Assistant for natural language database creation, GDPR, HIPAA, and SOC 2 Type II compliance, and seamless integration with existing tools. Baserow is API-first, extensible, and uses frameworks like Django, Vue.js, and PostgreSQL.

llmariner
LLMariner is an extensible open source platform built on Kubernetes to simplify the management of generative AI workloads. It enables efficient handling of training and inference data within clusters, with OpenAI-compatible APIs for seamless integration with a wide range of AI-driven applications.

enthusiast
Enthusiast is a production-ready agentic AI framework for E-commerce, offering tools like Retrieval-Argumented Generation (RAG), vector search, and workflow orchestrator. It helps in building AI-powered tools with customized agents for tasks like smart information search, customer support, content generation, and knowledge base automation. Enthusiast provides validation and evaluation components to ensure responses are grounded in actual data, reducing time, cost, and complexity in AI development.
bedrock-agentcore-starter-toolkit
Amazon Bedrock AgentCore Starter Toolkit enables developers to deploy and operate highly effective AI agents securely at scale using any framework and model. It provides tools and capabilities to make agents more effective and capable, purpose-built infrastructure to securely scale agents, and controls to operate trustworthy agents. The toolkit includes modular services like Runtime, Memory, Gateway, Code Interpreter, Browser, Observability, Identity, and Import Agent for seamless migration of existing agents. It is currently in public preview and offers enterprise-grade security and reliability for accelerating AI agent development.
dapr-agents
Dapr Agents is a developer framework for building production-grade resilient AI agent systems that operate at scale. It enables software developers to create AI agents that reason, act, and collaborate using Large Language Models (LLMs), while providing built-in observability and stateful workflow execution to ensure agentic workflows complete successfully. The framework is scalable, efficient, Kubernetes-native, data-driven, secure, observable, vendor-neutral, and open source. It offers features like scalable workflows, cost-effective AI adoption, data-centric AI agents, accelerated development, integrated security and reliability, built-in messaging and state infrastructure, and vendor-neutral and open source support. Dapr Agents is designed to simplify the development of AI applications and workflows by providing a comprehensive API surface and seamless integration with various data sources and services.

langchain
LangChain is a framework for building LLM-powered applications that simplifies AI application development by chaining together interoperable components and third-party integrations. It helps developers connect LLMs to diverse data sources, swap models easily, and future-proof decisions as technology evolves. LangChain's ecosystem includes tools like LangSmith for agent evals, LangGraph for complex task handling, and LangGraph Platform for deployment and scaling. Additional resources include tutorials, how-to guides, conceptual guides, a forum, API reference, and chat support.
kgateway
Kgateway is a feature-rich, fast, and flexible Kubernetes-native API gateway built on top of Envoy proxy and the Kubernetes Gateway API. It excels in function-level routing, supports legacy apps, microservices, and serverless, offers robust discovery capabilities, integrates seamlessly with open-source projects, and is designed to support hybrid applications with various technologies, architectures, protocols, and clouds.

doris
Doris is a lightweight and user-friendly data visualization tool designed for quick and easy exploration of datasets. It provides a simple interface for users to upload their data and generate interactive visualizations without the need for coding. With Doris, users can easily create charts, graphs, and dashboards to analyze and present their data in a visually appealing way. The tool supports various data formats and offers customization options to tailor visualizations to specific needs. Whether you are a data analyst, researcher, or student, Doris simplifies the process of data exploration and presentation.
coco-app
Coco AI is a unified search platform that connects enterprise applications and data into a single, powerful search interface. The COCO App allows users to search and interact with their enterprise data across platforms. It also offers a Gen-AI Chat for Teams tailored to team's unique knowledge and internal resources, enhancing collaboration by making information instantly accessible and providing AI-driven insights based on enterprise's specific data.
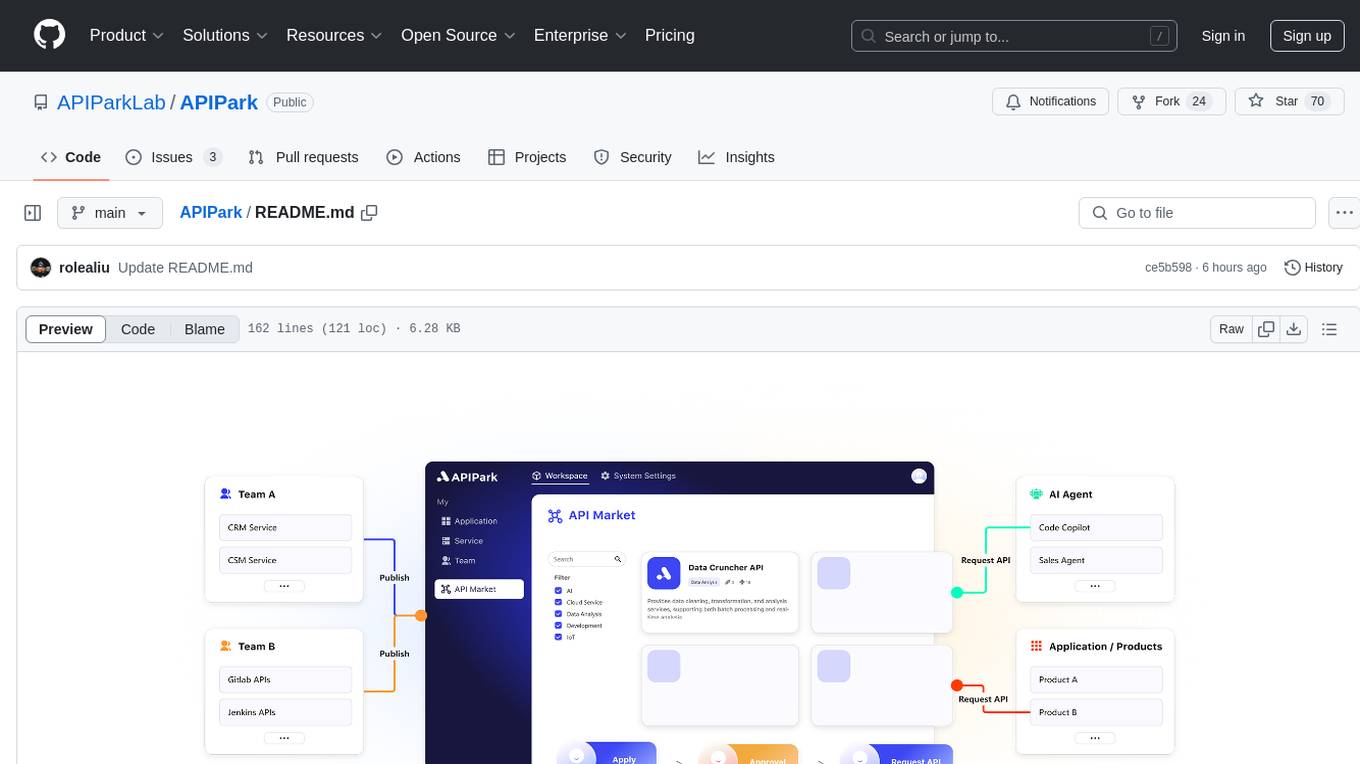
APIPark
APIPark is an open-source AI Gateway and Developer Portal that enables users to easily manage, integrate, and deploy AI and API services. It provides robust API management features, including creation, monitoring, and access control, to help developers efficiently and securely develop and manage their APIs. The platform aims to solve challenges such as connecting to powerful AI models, managing complex AI & API call relationships, overseeing API creation and security, simplifying fault detection and troubleshooting, and enhancing the visibility and valuation of data assets.

ClicShopping_V3
ClicShoppingAI is a powerful open-source Ecommerce solution that supports B2B, B2C, and B2B-B2C. Integrated with cutting-edge generative artificial intelligence systems like Gpt and Ollama, it helps merchants increase turnover and competitiveness for free. With AI capabilities, it optimizes inventory, offers personalized recommendations, and provides top-notch customer service. The solution is modular, lightweight, and user-friendly, with a seamless, responsive design for all devices. Installation is easy, empowering ongoing development through community support. Features include GPT API integration, generative AI functionalities, real-time safety stock predictive, WYSIWYG product description creation, image editor management, full SEO optimization, payment and shipping modules, extension system, GDPR compliance, multi-language support, and more.
psychic
Finic is an open source python-based integration platform designed to simplify integration workflows for both business users and developers. It offers a drag-and-drop UI, a dedicated Python environment for each workflow, and generative AI features to streamline transformation tasks. With a focus on decoupling integration from product code, Finic aims to provide faster and more flexible integrations by supporting custom connectors. The tool is open source and allows deployment to users' own cloud environments with minimal legal friction.
finic
Finic is an open source python-based integration platform designed for business users to create v1 integrations with minimal code, while also being flexible for developers to build complex integrations directly in python. It offers a low-code web UI, a dedicated Python environment for each workflow, and generative AI features. Finic decouples integration from product code, supports custom connectors, and is open source. It is not an ETL tool but focuses on integrating functionality between applications via APIs or SFTP, and it is not a workflow automation tool optimized for complex use cases.
ClicShopping
ClicShopping AI™ is an open-source Ecommerce platform powered by Generative AI, designed for B2B, B2C, and B2B-B2C businesses. It offers seamless shopping experiences, advanced AI integration, modular architecture for customization, and responsive design across devices. With features like GPT API integration, RAG-powered Business Intelligence Agent, multi-model AI support, and security compliance, ClicShopping AI™ is a comprehensive solution for online businesses. It also provides internationalization support, performance analytics, server performance optimization, content management, API connections, shipping and payment options, and a marketplace for additional modules and apps.
holoinsight
HoloInsight is a cloud-native observability platform that provides low-cost and high-performance monitoring services for cloud-native applications. It offers deep insights through real-time log analysis and AI integration. The platform is designed to help users gain a comprehensive understanding of their applications' performance and behavior in the cloud environment. HoloInsight is easy to deploy using Docker and Kubernetes, making it a versatile tool for monitoring and optimizing cloud-native applications. With a focus on scalability and efficiency, HoloInsight is suitable for organizations looking to enhance their observability and monitoring capabilities in the cloud.
For similar tasks

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.
niledatabase
Nile is a serverless Postgres database designed for modern SaaS applications. It virtualizes tenants/customers/organizations into Postgres to enable native tenant data isolation, performance isolation, per-tenant backups, and tenant placement on shared or dedicated compute globally. With Nile, you can manage multiple tenants effortlessly, without complex permissions or buggy scripts. Additionally, it offers opt-in user management capabilities, customer-specific vector embeddings, and instant tenant admin dashboards. Built for the cloud, Nile provides a true serverless experience with effortless scaling.

1Panel
1Panel is an open-source, modern web-based control panel for Linux server management. It provides efficient management through a user-friendly web graphical interface, enabling users to effortlessly manage their Linux servers. Key features include host monitoring, file management, database administration, container management, rapid website deployment with WordPress integration, an application store for easy installation and updates, security and reliability through containerization and secure application deployment practices, integrated firewall management, log auditing capabilities, and one-click backup & restore functionality supporting various cloud storage solutions.
job-hunting
Job Hunting is a browser extension designed to enhance the job searching experience on popular recruitment platforms in China. It aims to improve job listing visibility, provide personalized job search capabilities, analyze job data, facilitate job discussions, and offer company insights. The extension offers features such as job card display, company reputation checks, quick company information lookup, job and company data storage, job and company tagging, data analysis, data sharing, personal job preferences, automation tasks, discussion forums, data backup and recovery, and data sharing plans. It supports platforms like BOSS 直聘, 前程无忧, 智联招聘, 拉钩网, and 猎聘网, and provides visualizations for job posting trends and company data.
Con-Nav-Item
Con-Nav-Item is a modern personal navigation system designed for digital workers. It is not just a link bookmark but also an all-in-one workspace integrated with AI smart generation, multi-device synchronization, card-based management, and deep browser integration.

ai-toolbox
AI Toolbox is a cross-platform desktop application designed to efficiently manage various AI programming assistant configurations. It supports Windows, macOS, and Linux. The tool provides visual management of OpenCode, Oh-My-OpenCode, Slim plugin configurations, Claude Code API supplier configurations, Codex CLI configurations, MCP server management, Skills management, WSL synchronization, AI supplier management, system tray for quick configuration switching, data backup, theme switching, multilingual support, and automatic update checks.
LunaBox
LunaBox is a lightweight, fast, and feature-rich tool for managing and tracking visual novels, with the ability to customize game categories, automatically track playtime, generate personalized reports through AI analysis, import data from other platforms, backup data locally or on cloud services, and ensure privacy and security by storing sensitive data locally. The tool supports multi-dimensional statistics, offers a variety of customization options, and provides a user-friendly interface for easy navigation and usage.

free-for-life
A massive list including a huge amount of products and services that are completely free! ⭐ Star on GitHub • 🤝 Contribute # Table of Contents * APIs, Data & ML * Artificial Intelligence * BaaS * Code Editors * Code Generation * DNS * Databases * Design & UI * Domains * Email * Font * For Students * Forms * Linux Distributions * Messaging & Streaming * PaaS * Payments & Billing * SSL
For similar jobs

AirGo
AirGo is a front and rear end separation, multi user, multi protocol proxy service management system, simple and easy to use. It supports vless, vmess, shadowsocks, and hysteria2.

mosec
Mosec is a high-performance and flexible model serving framework for building ML model-enabled backend and microservices. It bridges the gap between any machine learning models you just trained and the efficient online service API. * **Highly performant** : web layer and task coordination built with Rust 🦀, which offers blazing speed in addition to efficient CPU utilization powered by async I/O * **Ease of use** : user interface purely in Python 🐍, by which users can serve their models in an ML framework-agnostic manner using the same code as they do for offline testing * **Dynamic batching** : aggregate requests from different users for batched inference and distribute results back * **Pipelined stages** : spawn multiple processes for pipelined stages to handle CPU/GPU/IO mixed workloads * **Cloud friendly** : designed to run in the cloud, with the model warmup, graceful shutdown, and Prometheus monitoring metrics, easily managed by Kubernetes or any container orchestration systems * **Do one thing well** : focus on the online serving part, users can pay attention to the model optimization and business logic

llm-code-interpreter
The 'llm-code-interpreter' repository is a deprecated plugin that provides a code interpreter on steroids for ChatGPT by E2B. It gives ChatGPT access to a sandboxed cloud environment with capabilities like running any code, accessing Linux OS, installing programs, using filesystem, running processes, and accessing the internet. The plugin exposes commands to run shell commands, read files, and write files, enabling various possibilities such as running different languages, installing programs, starting servers, deploying websites, and more. It is powered by the E2B API and is designed for agents to freely experiment within a sandboxed environment.

pezzo
Pezzo is a fully cloud-native and open-source LLMOps platform that allows users to observe and monitor AI operations, troubleshoot issues, save costs and latency, collaborate, manage prompts, and deliver AI changes instantly. It supports various clients for prompt management, observability, and caching. Users can run the full Pezzo stack locally using Docker Compose, with prerequisites including Node.js 18+, Docker, and a GraphQL Language Feature Support VSCode Extension. Contributions are welcome, and the source code is available under the Apache 2.0 License.

learn-generative-ai
Learn Cloud Applied Generative AI Engineering (GenEng) is a course focusing on the application of generative AI technologies in various industries. The course covers topics such as the economic impact of generative AI, the role of developers in adopting and integrating generative AI technologies, and the future trends in generative AI. Students will learn about tools like OpenAI API, LangChain, and Pinecone, and how to build and deploy Large Language Models (LLMs) for different applications. The course also explores the convergence of generative AI with Web 3.0 and its potential implications for decentralized intelligence.

gcloud-aio
This repository contains shared codebase for two projects: gcloud-aio and gcloud-rest. gcloud-aio is built for Python 3's asyncio, while gcloud-rest is a threadsafe requests-based implementation. It provides clients for Google Cloud services like Auth, BigQuery, Datastore, KMS, PubSub, Storage, and Task Queue. Users can install the library using pip and refer to the documentation for usage details. Developers can contribute to the project by following the contribution guide.

fluid
Fluid is an open source Kubernetes-native Distributed Dataset Orchestrator and Accelerator for data-intensive applications, such as big data and AI applications. It implements dataset abstraction, scalable cache runtime, automated data operations, elasticity and scheduling, and is runtime platform agnostic. Key concepts include Dataset and Runtime. Prerequisites include Kubernetes version > 1.16, Golang 1.18+, and Helm 3. The tool offers features like accelerating remote file accessing, machine learning, accelerating PVC, preloading dataset, and on-the-fly dataset cache scaling. Contributions are welcomed, and the project is under the Apache 2.0 license with a vendor-neutral approach.

aiges
AIGES is a core component of the Athena Serving Framework, designed as a universal encapsulation tool for AI developers to deploy AI algorithm models and engines quickly. By integrating AIGES, you can deploy AI algorithm models and engines rapidly and host them on the Athena Serving Framework, utilizing supporting auxiliary systems for networking, distribution strategies, data processing, etc. The Athena Serving Framework aims to accelerate the cloud service of AI algorithm models and engines, providing multiple guarantees for cloud service stability through cloud-native architecture. You can efficiently and securely deploy, upgrade, scale, operate, and monitor models and engines without focusing on underlying infrastructure and service-related development, governance, and operations.