
llm-price-compass
This project collects GPU benchmarks from various cloud providers and compares them to fixed per token costs. Use our tool for efficient LLM GPU selections and cost-effective AI models. LLM provider price comparison, gpu benchmarks to price per token calculation, gpu benchmark table
Stars: 197
LLM price compass is an open-source tool for comparing inference costs on different GPUs across various cloud providers. It collects benchmark data to help users select the right GPU, cloud, and provider for their models. The project aims to provide insights into fixed per token costs from different providers, aiding in decision-making for model deployment.
README:
Open-Source LLM inference cost comparison for compute nomads




This project aims to collect benchmark data from different GPUs on various clouds/providers and compare it to fixed per token costs from other providers. By utilizing our platform, you can make informed decisions on cost-effective LLM options, affordable language models, and efficient LLM GPU selections.
Our comprehensive LLM Price Comparison tool empowers users to evaluate multiple AI models and provides insights into AI model pricing guides. This project will help you choose the right GPU and cloud provider for the model of your choice—facilitating GPU inference and LLM GPU benchmarks.
Please refer to the CONTRIBUTING.md file for information about how to get involved. We welcome issues, questions, and pull requests. If you have insights on GPU comparisons, benchmarks, or AI model evaluations, please share them with our community.
Source Providers Source Self-hosted
We as members, contributors, and leaders, pledge to make participation in our community a harassment-free experience for everyone, regardless of age, body size, visible or invisible disability, ethnicity, sex characteristics, gender identity and expression, level of experience, education, socio-economic status, nationality, personal appearance, race, religion, or sexual identity and orientation. Please refer to the CODE_OF_CONDUCT.md file for more information about contributing.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llm-price-compass
Similar Open Source Tools
llm-price-compass
LLM price compass is an open-source tool for comparing inference costs on different GPUs across various cloud providers. It collects benchmark data to help users select the right GPU, cloud, and provider for their models. The project aims to provide insights into fixed per token costs from different providers, aiding in decision-making for model deployment.
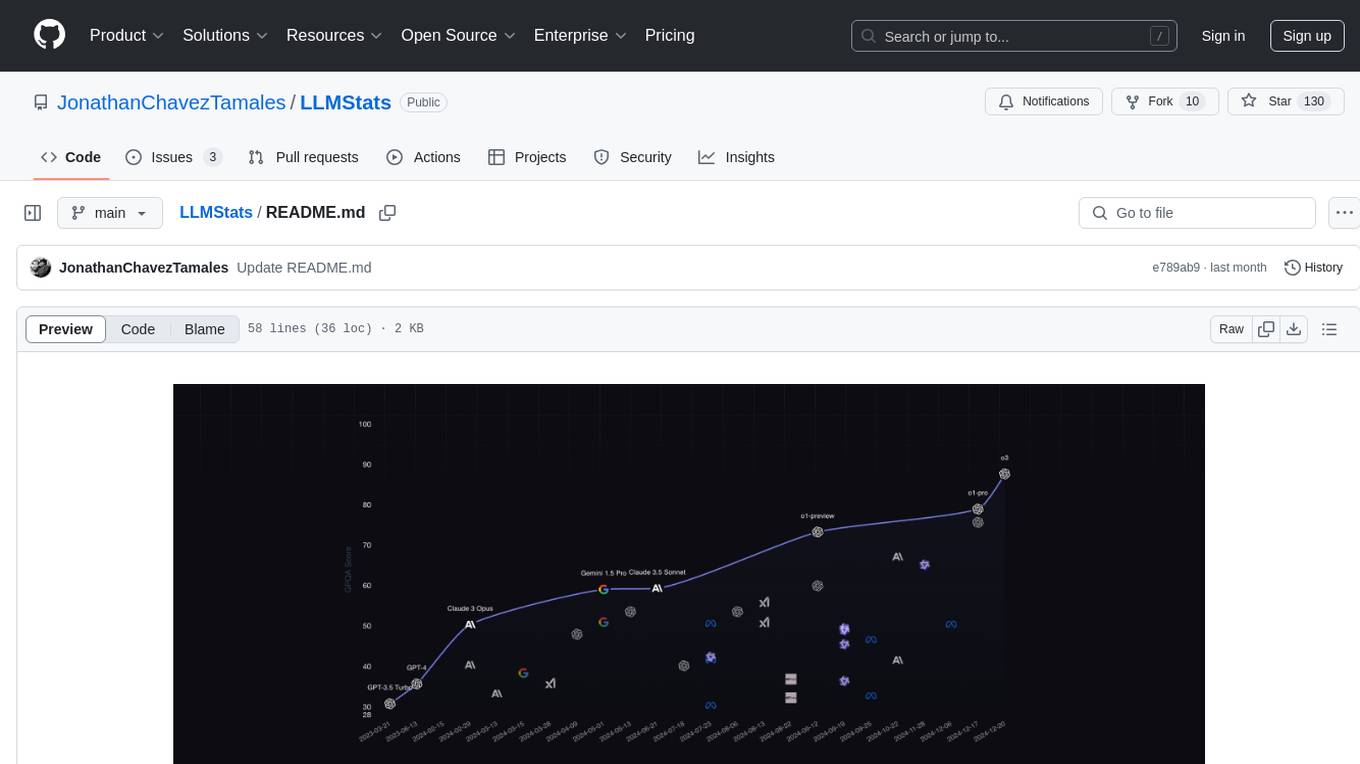
LLMStats
LLMStats is a community-driven repository providing detailed information on hundreds of Language Models (LLMs). Users can compare and explore LLMs through an interactive dashboard at llm-stats.com. The repository includes model parameters, context window sizes, licensing details, capabilities, provider pricing, performance metrics, and standardized benchmark results. Community contributions are welcome to maintain data accuracy. The platform prioritizes data quality through verifiable source links, community review processes, multiple source citations, and regular data validation. While not guaranteed to be 100% accurate, efforts are made to ensure the information is as reliable as possible.

llm-d
LLM-D is a machine learning model for sentiment analysis. It is designed to classify text data into positive, negative, or neutral sentiment categories. The model is trained on a large dataset of labeled text samples and uses natural language processing techniques to analyze and predict sentiment in new text inputs. LLM-D is a powerful tool for businesses and researchers looking to understand customer feedback, social media sentiment, and other text data sources. It can be easily integrated into existing applications or used as a standalone tool for sentiment analysis tasks.
csghub
CSGHub is an open source platform for managing large model assets, including datasets, model files, and codes. It offers functionalities similar to a privatized Huggingface, managing assets in a manner akin to how OpenStack Glance manages virtual machine images. Users can perform operations such as uploading, downloading, storing, verifying, and distributing assets through various interfaces. The platform provides microservice submodules and standardized OpenAPIs for easy integration with users' systems. CSGHub is designed for large models and can be deployed On-Premise for offline operation.

CodeFuse-muAgent
CodeFuse-muAgent is a Multi-Agent framework designed to streamline Standard Operating Procedure (SOP) orchestration for agents. It integrates toolkits, code libraries, knowledge bases, and sandbox environments for rapid construction of complex Multi-Agent interactive applications. The framework enables efficient execution and handling of multi-layered and multi-dimensional tasks.

mindsdb
MindsDB is a platform for customizing AI from enterprise data. You can create, serve, and fine-tune models in real-time from your database, vector store, and application data. MindsDB "enhances" SQL syntax with AI capabilities to make it accessible for developers worldwide. With MindsDB’s nearly 200 integrations, any developer can create AI customized for their purpose, faster and more securely. Their AI systems will constantly improve themselves — using companies’ own data, in real-time.

SuperKnowa
SuperKnowa is a fast framework to build Enterprise RAG (Retriever Augmented Generation) Pipelines at Scale, powered by watsonx. It accelerates Enterprise Generative AI applications to get prod-ready solutions quickly on private data. The framework provides pluggable components for tackling various Generative AI use cases using Large Language Models (LLMs), allowing users to assemble building blocks to address challenges in AI-driven text generation. SuperKnowa is battle-tested from 1M to 200M private knowledge base & scaled to billions of retriever tokens.
miyagi
Project Miyagi showcases Microsoft's Copilot Stack in an envisioning workshop aimed at designing, developing, and deploying enterprise-grade intelligent apps. By exploring both generative and traditional ML use cases, Miyagi offers an experiential approach to developing AI-infused product experiences that enhance productivity and enable hyper-personalization. Additionally, the workshop introduces traditional software engineers to emerging design patterns in prompt engineering, such as chain-of-thought and retrieval-augmentation, as well as to techniques like vectorization for long-term memory, fine-tuning of OSS models, agent-like orchestration, and plugins or tools for augmenting and grounding LLMs.

agentUniverse
agentUniverse is a multi-agent framework based on large language models, providing flexible capabilities for building individual agents. It focuses on collaborative pattern components to solve problems in various fields and integrates domain experience. The framework supports LLM model integration and offers various pattern components like PEER and DOE. Users can easily configure models and set up agents for tasks. agentUniverse aims to assist developers and enterprises in constructing domain-expert-level intelligent agents for seamless collaboration.

ServerlessLLM
ServerlessLLM is a fast, affordable, and easy-to-use library designed for multi-LLM serving, optimized for environments with limited GPU resources. It supports loading various leading LLM inference libraries, achieving fast load times, and reducing model switching overhead. The library facilitates easy deployment via Ray Cluster and Kubernetes, integrates with the OpenAI Query API, and is actively maintained by contributors.
agentUniverse
agentUniverse is a multi-agent framework based on large language models, providing flexible capabilities for building individual agents. It focuses on multi-agent collaborative patterns, integrating domain experience to help agents solve problems in various fields. The framework includes pattern components like PEER and DOE for event interpretation, industry analysis, and financial report generation. It offers features for agent construction, multi-agent collaboration, and domain expertise integration, aiming to create intelligent applications with professional know-how.
langchain4j
LangChain for Java simplifies integrating Large Language Models (LLMs) into Java applications by offering unified APIs for various LLM providers and embedding stores. It provides a comprehensive toolbox with tools for prompt templating, chat memory management, function calling, and high-level patterns like Agents and RAG. The library supports 15+ popular LLM providers and 15+ embedding stores, offering numerous examples to help users quickly start building LLM-powered applications. LangChain4j is a fusion of ideas from various projects and actively incorporates new techniques and integrations to keep users up-to-date. The project is under active development, with core functionality already in place for users to start building LLM-powered apps.

SpecForge
SpecForge is a powerful tool for generating API specifications from code. It helps developers to easily create and maintain accurate API documentation by extracting information directly from the codebase. With SpecForge, users can streamline the process of documenting APIs, ensuring consistency and reducing manual effort. The tool supports various programming languages and frameworks, making it versatile and adaptable to different development environments. By automating the generation of API specifications, SpecForge enhances collaboration between developers and stakeholders, improving overall project efficiency and quality.

agentUniverse
agentUniverse is a framework for developing applications powered by multi-agent based on large language model. It provides essential components for building single agent and multi-agent collaboration mechanism for customizing collaboration patterns. Developers can easily construct multi-agent applications and share pattern practices from different fields. The framework includes pre-installed collaboration patterns like PEER and DOE for complex task breakdown and data-intensive tasks.

langchain
LangChain is a framework for building LLM-powered applications that simplifies AI application development by chaining together interoperable components and third-party integrations. It helps developers connect LLMs to diverse data sources, swap models easily, and future-proof decisions as technology evolves. LangChain's ecosystem includes tools like LangSmith for agent evals, LangGraph for complex task handling, and LangGraph Platform for deployment and scaling. Additional resources include tutorials, how-to guides, conceptual guides, a forum, API reference, and chat support.

CSGHub
CSGHub is an open source, trustworthy large model asset management platform that can assist users in governing the assets involved in the lifecycle of LLM and LLM applications (datasets, model files, codes, etc). With CSGHub, users can perform operations on LLM assets, including uploading, downloading, storing, verifying, and distributing, through Web interface, Git command line, or natural language Chatbot. Meanwhile, the platform provides microservice submodules and standardized OpenAPIs, which could be easily integrated with users' own systems. CSGHub is committed to bringing users an asset management platform that is natively designed for large models and can be deployed On-Premise for fully offline operation. CSGHub offers functionalities similar to a privatized Huggingface(on-premise Huggingface), managing LLM assets in a manner akin to how OpenStack Glance manages virtual machine images, Harbor manages container images, and Sonatype Nexus manages artifacts.
For similar tasks

byteir
The ByteIR Project is a ByteDance model compilation solution. ByteIR includes compiler, runtime, and frontends, and provides an end-to-end model compilation solution. Although all ByteIR components (compiler/runtime/frontends) are together to provide an end-to-end solution, and all under the same umbrella of this repository, each component technically can perform independently. The name, ByteIR, comes from a legacy purpose internally. The ByteIR project is NOT an IR spec definition project. Instead, in most scenarios, ByteIR directly uses several upstream MLIR dialects and Google Mhlo. Most of ByteIR compiler passes are compatible with the selected upstream MLIR dialects and Google Mhlo.

ScandEval
ScandEval is a framework for evaluating pretrained language models on mono- or multilingual language tasks. It provides a unified interface for benchmarking models on a variety of tasks, including sentiment analysis, question answering, and machine translation. ScandEval is designed to be easy to use and extensible, making it a valuable tool for researchers and practitioners alike.

opencompass
OpenCompass is a one-stop platform for large model evaluation, aiming to provide a fair, open, and reproducible benchmark for large model evaluation. Its main features include: * Comprehensive support for models and datasets: Pre-support for 20+ HuggingFace and API models, a model evaluation scheme of 70+ datasets with about 400,000 questions, comprehensively evaluating the capabilities of the models in five dimensions. * Efficient distributed evaluation: One line command to implement task division and distributed evaluation, completing the full evaluation of billion-scale models in just a few hours. * Diversified evaluation paradigms: Support for zero-shot, few-shot, and chain-of-thought evaluations, combined with standard or dialogue-type prompt templates, to easily stimulate the maximum performance of various models. * Modular design with high extensibility: Want to add new models or datasets, customize an advanced task division strategy, or even support a new cluster management system? Everything about OpenCompass can be easily expanded! * Experiment management and reporting mechanism: Use config files to fully record each experiment, and support real-time reporting of results.

openvino.genai
The GenAI repository contains pipelines that implement image and text generation tasks. The implementation uses OpenVINO capabilities to optimize the pipelines. Each sample covers a family of models and suggests certain modifications to adapt the code to specific needs. It includes the following pipelines: 1. Benchmarking script for large language models 2. Text generation C++ samples that support most popular models like LLaMA 2 3. Stable Diffuison (with LoRA) C++ image generation pipeline 4. Latent Consistency Model (with LoRA) C++ image generation pipeline

GPT4Point
GPT4Point is a unified framework for point-language understanding and generation. It aligns 3D point clouds with language, providing a comprehensive solution for tasks such as 3D captioning and controlled 3D generation. The project includes an automated point-language dataset annotation engine, a novel object-level point cloud benchmark, and a 3D multi-modality model. Users can train and evaluate models using the provided code and datasets, with a focus on improving models' understanding capabilities and facilitating the generation of 3D objects.

octopus-v4
The Octopus-v4 project aims to build the world's largest graph of language models, integrating specialized models and training Octopus models to connect nodes efficiently. The project focuses on identifying, training, and connecting specialized models. The repository includes scripts for running the Octopus v4 model, methods for managing the graph, training code for specialized models, and inference code. Environment setup instructions are provided for Linux with NVIDIA GPU. The Octopus v4 model helps users find suitable models for tasks and reformats queries for effective processing. The project leverages Language Large Models for various domains and provides benchmark results. Users are encouraged to train and add specialized models following recommended procedures.

Awesome-LLM-RAG
This repository, Awesome-LLM-RAG, aims to record advanced papers on Retrieval Augmented Generation (RAG) in Large Language Models (LLMs). It serves as a resource hub for researchers interested in promoting their work related to LLM RAG by updating paper information through pull requests. The repository covers various topics such as workshops, tutorials, papers, surveys, benchmarks, retrieval-enhanced LLMs, RAG instruction tuning, RAG in-context learning, RAG embeddings, RAG simulators, RAG search, RAG long-text and memory, RAG evaluation, RAG optimization, and RAG applications.

stm32ai-modelzoo
The STM32 AI model zoo is a collection of reference machine learning models optimized to run on STM32 microcontrollers. It provides a large collection of application-oriented models ready for re-training, scripts for easy retraining from user datasets, pre-trained models on reference datasets, and application code examples generated from user AI models. The project offers training scripts for transfer learning or training custom models from scratch. It includes performances on reference STM32 MCU and MPU for float and quantized models. The project is organized by application, providing step-by-step guides for training and deploying models.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.