
aws-reference-architecture-pulumi
Pinecone AWS Reference Architecture
Stars: 97
The Pinecone AWS Reference Architecture with Pulumi is a distributed system designed for vector-database-enabled semantic search over Postgres records. It serves as a starting point for specific use cases or as a learning resource. The architecture is permissively licensed and supported by Pinecone's open-source team, facilitating the setup of high-scale use cases for Pinecone's scalable vector database.
README:
![]()
![]()
The Pinecone AWS Reference Architecture is a distributed system that performs vector-database-enabled semantic search over Postgres records. It is appropriate for use as a starting point to a more specific use case or as a learning resource.
It is permissively licensed and supported by Pinecone's open-source team in order to ease getting started with high-scale use cases for Pinecone's highly scalable vector database.

- Introduction
- Getting started
- Detailed setup instructions
- Core concepts
- Architecture overview
- Common tasks
- Troubleshooting and FAQs
- Code of conduct
- Contribution guidelines
- License
-
Set Up AWS IAM User
- Create a New IAM User: In your AWS account, create a new IAM user.
- Security Credentials: Generate new security credentials for this IAM user.
- Attach Administrator Policy: Attach the Administrator IAM policy to your IAM user, either directly or by adding the user to an appropriate IAM group.
-
Configure AWS Credentials
- Add Credentials to AWS Profile: Insert your IAM user's access key ID and secret access key into your
~/.aws/credentialsfile.
- Add Credentials to AWS Profile: Insert your IAM user's access key ID and secret access key into your
-
Install Pulumi CLI
- Download and install the Pulumi CLI.
- Link GitHub Account: Complete your Pulumi account setup using your GitHub account.
-
Configure Pulumi
- Set AWS Profile: Run
pulumi config set aws:profile <your-aws-profile-name>to configure the AWS profile in Pulumi.
- Set AWS Profile: Run
-
Obtain Pinecone API Key
- Log into Pinecone's dashboard or create a free account to obtain your Pinecone API key and environment values.
-
Set Configuration Variables
- Create a Pulumi stack: Run
pulumi stack init <your-stack-name>
- Create a Pulumi stack: Run
Configure the required configuration values. Replace $VALUE in the command below with your Pinecone and AWS configuration.
# Currently us-west-2 is the only supported region for deploying the Reference Architecture to, because Pinecone Serverless
# is in public preview and only available in some regions
pulumi config set aws:region us-west-2
# From your Pinecone account at https://app.pinecone.io
pulumi config set --secret PINECONE_API_KEY "$PINECONE_API_KEY"
# The PINECONE_INDEX can be any value to create an index with that name when the app starts.
pulumi config set PINECONE_INDEX "$PINECONE_INDEX"-
Install SDK Dependencies
- Run
pulumi installto install the required dependencies.
- Run
-
Initialize and Run Pulumi Stack
- Deploy Resources: Execute
pulumi upto start the deployment. - Review and Confirm: Review the Pulumi preview of resources to be created. Confirm by selecting
Yesto proceed.
- Deploy Resources: Execute
The Pinecone AWS Reference Architecture is licensed under the Apache 2.0 license.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for aws-reference-architecture-pulumi
Similar Open Source Tools
aws-reference-architecture-pulumi
The Pinecone AWS Reference Architecture with Pulumi is a distributed system designed for vector-database-enabled semantic search over Postgres records. It serves as a starting point for specific use cases or as a learning resource. The architecture is permissively licensed and supported by Pinecone's open-source team, facilitating the setup of high-scale use cases for Pinecone's scalable vector database.

langmanus
LangManus is a community-driven AI automation framework that combines language models with specialized tools for tasks like web search, crawling, and Python code execution. It implements a hierarchical multi-agent system with agents like Coordinator, Planner, Supervisor, Researcher, Coder, Browser, and Reporter. The framework supports LLM integration, search and retrieval tools, Python integration, workflow management, and visualization. LangManus aims to give back to the open-source community and welcomes contributions in various forms.
clearml-server
ClearML Server is a backend service infrastructure for ClearML, facilitating collaboration and experiment management. It includes a web app, RESTful API, and file server for storing images and models. Users can deploy ClearML Server using Docker, AWS EC2 AMI, or Kubernetes. The system design supports single IP or sub-domain configurations with specific open ports. ClearML-Agent Services container allows launching long-lasting jobs and various use cases like auto-scaler service, controllers, optimizer, and applications. Advanced functionality includes web login authentication and non-responsive experiments watchdog. Upgrading ClearML Server involves stopping containers, backing up data, downloading the latest docker-compose.yml file, configuring ClearML-Agent Services, and spinning up docker containers. Community support is available through ClearML FAQ, Stack Overflow, GitHub issues, and email contact.

cosdata
Cosdata is a cutting-edge AI data platform designed to power the next generation search pipelines. It features immutability, version control, and excels in semantic search, structured knowledge graphs, hybrid search capabilities, real-time search at scale, and ML pipeline integration. The platform is customizable, scalable, efficient, enterprise-grade, easy to use, and can manage multi-modal data. It offers high performance, indexing, low latency, and high requests per second. Cosdata is designed to meet the demands of modern search applications, empowering businesses to harness the full potential of their data.
deer-flow
DeerFlow is a community-driven Deep Research framework that combines language models with specialized tools for tasks like web search, crawling, and Python code execution. It supports FaaS deployment and one-click deployment based on Volcengine. The framework includes core capabilities like LLM integration, search and retrieval, RAG integration, MCP seamless integration, human collaboration, report post-editing, and content creation. The architecture is based on a modular multi-agent system with components like Coordinator, Planner, Research Team, and Text-to-Speech integration. DeerFlow also supports interactive mode, human-in-the-loop mechanism, and command-line arguments for customization.

swark
Swark is a VS Code extension that automatically generates architecture diagrams from code using large language models (LLMs). It is directly integrated with GitHub Copilot, requires no authentication or API key, and supports all languages. Swark helps users learn new codebases, review AI-generated code, improve documentation, understand legacy code, spot design flaws, and gain test coverage insights. It saves output in a 'swark-output' folder with diagram and log files. Source code is only shared with GitHub Copilot for privacy. The extension settings allow customization for file reading, file extensions, exclusion patterns, and language model selection. Swark is open source under the GNU Affero General Public License v3.0.

kollektiv
Kollektiv is a Retrieval-Augmented Generation (RAG) system designed to enable users to chat with their favorite documentation easily. It aims to provide LLMs with access to the most up-to-date knowledge, reducing inaccuracies and improving productivity. The system utilizes intelligent web crawling, advanced document processing, vector search, multi-query expansion, smart re-ranking, AI-powered responses, and dynamic system prompts. The technical stack includes Python/FastAPI for backend, Supabase, ChromaDB, and Redis for storage, OpenAI and Anthropic Claude 3.5 Sonnet for AI/ML, and Chainlit for UI. Kollektiv is licensed under a modified version of the Apache License 2.0, allowing free use for non-commercial purposes.
gitdiagram
GitDiagram is a tool that turns any GitHub repository into an interactive diagram for visualization in seconds. It offers instant visualization, interactivity, fast generation, customization, and API access. The tool utilizes a tech stack including Next.js, FastAPI, PostgreSQL, Claude 3.5 Sonnet, Vercel, EC2, GitHub Actions, PostHog, and Api-Analytics. Users can self-host the tool for local development and contribute to its development. GitDiagram is inspired by Gitingest and has future plans to use larger context models, allow user API key input, implement RAG with Mermaid.js docs, and include font-awesome icons in diagrams.

comfyui_LLM_Polymath
LLM Polymath Chat Node is an advanced Chat Node for ComfyUI that integrates large language models to build text-driven applications and automate data processes, enhancing prompt responses by incorporating real-time web search, linked content extraction, and custom agent instructions. It supports both OpenAI’s GPT-like models and alternative models served via a local Ollama API. The core functionalities include Comfy Node Finder and Smart Assistant, along with additional agents like Flux Prompter, Custom Instructors, Python debugger, and scripter. The tool offers features for prompt processing, web search integration, model & API integration, custom instructions, image handling, logging & debugging, output compression, and more.

deep-research
Deep Research is a lightning-fast tool that uses powerful AI models to generate comprehensive research reports in just a few minutes. It leverages advanced 'Thinking' and 'Task' models, combined with an internet connection, to provide fast and insightful analysis on various topics. The tool ensures privacy by processing and storing all data locally. It supports multi-platform deployment, offers support for various large language models, web search functionality, knowledge graph generation, research history preservation, local and server API support, PWA technology, multi-key payload support, multi-language support, and is built with modern technologies like Next.js and Shadcn UI. Deep Research is open-source under the MIT License.
Whisper-TikTok
Discover Whisper-TikTok, an innovative AI-powered tool that leverages the prowess of Edge TTS, OpenAI-Whisper, and FFMPEG to craft captivating TikTok videos. Whisper-TikTok effortlessly generates accurate transcriptions from audio files and integrates Microsoft Edge Cloud Text-to-Speech API for vibrant voiceovers. The program orchestrates the synthesis of videos using a structured JSON dataset, generating mesmerizing TikTok content in minutes.

postgresml
PostgresML is a powerful Postgres extension that seamlessly combines data storage and machine learning inference within your database. It enables running machine learning and AI operations directly within PostgreSQL, leveraging GPU acceleration for faster computations, integrating state-of-the-art large language models, providing built-in functions for text processing, enabling efficient similarity search, offering diverse ML algorithms, ensuring high performance, scalability, and security, supporting a wide range of NLP tasks, and seamlessly integrating with existing PostgreSQL tools and client libraries.
sd-webui-agent-scheduler
AgentScheduler is an Automatic/Vladmandic Stable Diffusion Web UI extension designed to enhance image generation workflows. It allows users to enqueue prompts, settings, and controlnets, manage queued tasks, prioritize, pause, resume, and delete tasks, view generation results, and more. The extension offers hidden features like queuing checkpoints, editing queued tasks, and custom checkpoint selection. Users can access the functionality through HTTP APIs and API callbacks. Troubleshooting steps are provided for common errors. The extension is compatible with latest versions of A1111 and Vladmandic. It is licensed under Apache License 2.0.

Upsonic
Upsonic offers a cutting-edge enterprise-ready framework for orchestrating LLM calls, agents, and computer use to complete tasks cost-effectively. It provides reliable systems, scalability, and a task-oriented structure for real-world cases. Key features include production-ready scalability, task-centric design, MCP server support, tool-calling server, computer use integration, and easy addition of custom tools. The framework supports client-server architecture and allows seamless deployment on AWS, GCP, or locally using Docker.
FinAnGPT-Pro
FinAnGPT-Pro is a financial data downloader and AI query system that downloads quarterly and annual financial data for stocks from EOD Historical Data, storing it in MongoDB and Google BigQuery. It includes an AI-powered natural language interface for querying financial data. Users can set up the tool by following the prerequisites and setup instructions provided in the README. The tool allows users to download financial data for all stocks in a watchlist or for a single stock, query financial data using a natural language interface, and receive responses in a structured format. Important considerations include error handling, rate limiting, data validation, BigQuery costs, MongoDB connection, and security measures for API keys and credentials.
LocalAIVoiceChat
LocalAIVoiceChat is an experimental alpha software that enables real-time voice chat with a customizable AI personality and voice on your PC. It integrates Zephyr 7B language model with speech-to-text and text-to-speech libraries. The tool is designed for users interested in state-of-the-art voice solutions and provides an early version of a local real-time chatbot.
For similar tasks
aws-reference-architecture-pulumi
The Pinecone AWS Reference Architecture with Pulumi is a distributed system designed for vector-database-enabled semantic search over Postgres records. It serves as a starting point for specific use cases or as a learning resource. The architecture is permissively licensed and supported by Pinecone's open-source team, facilitating the setup of high-scale use cases for Pinecone's scalable vector database.
enterprise-azureai
Azure OpenAI Service is a central capability with Azure API Management, providing guidance and tools for organizations to implement Azure OpenAI in a production environment with an emphasis on cost control, secure access, and usage monitoring. It includes infrastructure-as-code templates, CI/CD pipelines, secure access management, usage monitoring, load balancing, streaming requests, and end-to-end samples like ChatApp and Azure Dashboards.
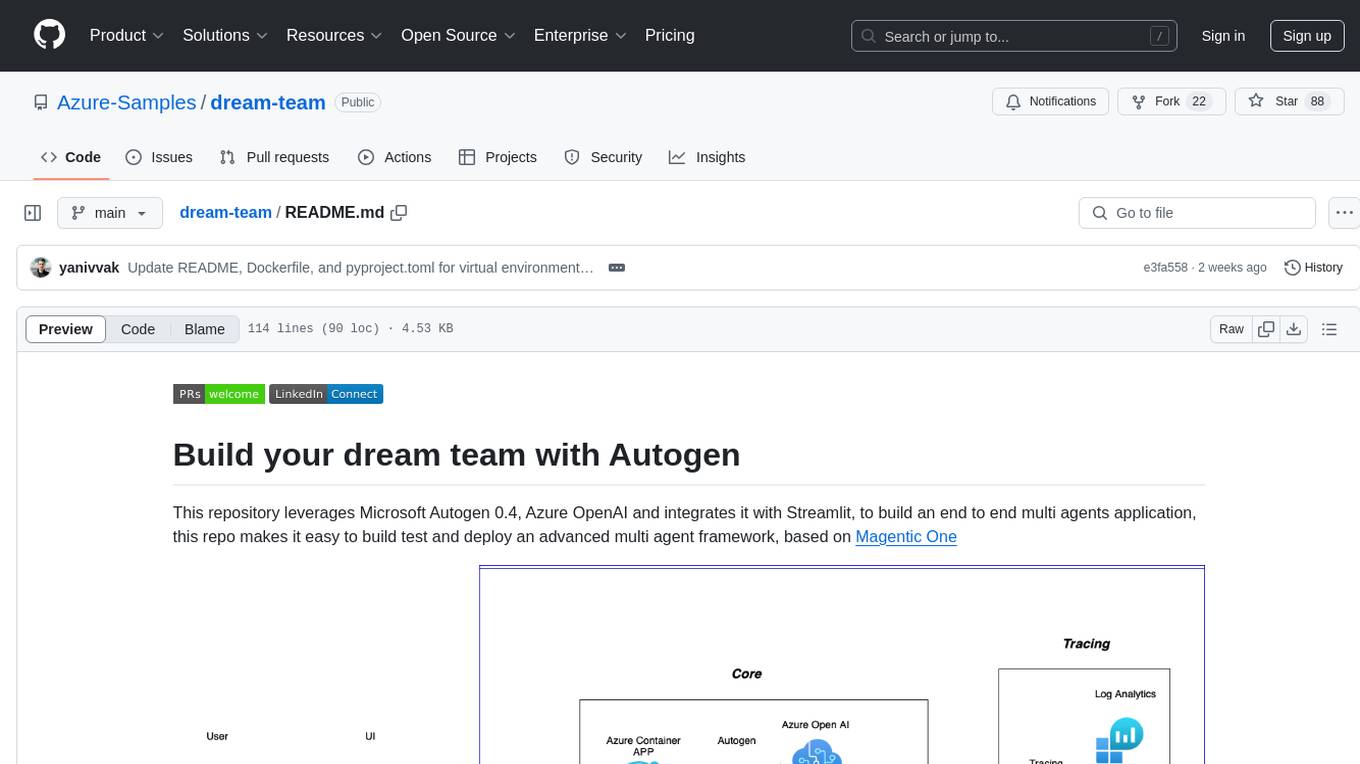
dream-team
Build your dream team with Autogen is a repository that leverages Microsoft Autogen 0.4, Azure OpenAI, and Streamlit to create an end-to-end multi-agent application. It provides an advanced multi-agent framework based on Magentic One, with features such as a friendly UI, single-line deployment, secure code execution, managed identities, and observability & debugging tools. Users can deploy Azure resources and the app with simple commands, work locally with virtual environments, install dependencies, update configurations, and run the application. The repository also offers resources for learning more about building applications with Autogen.
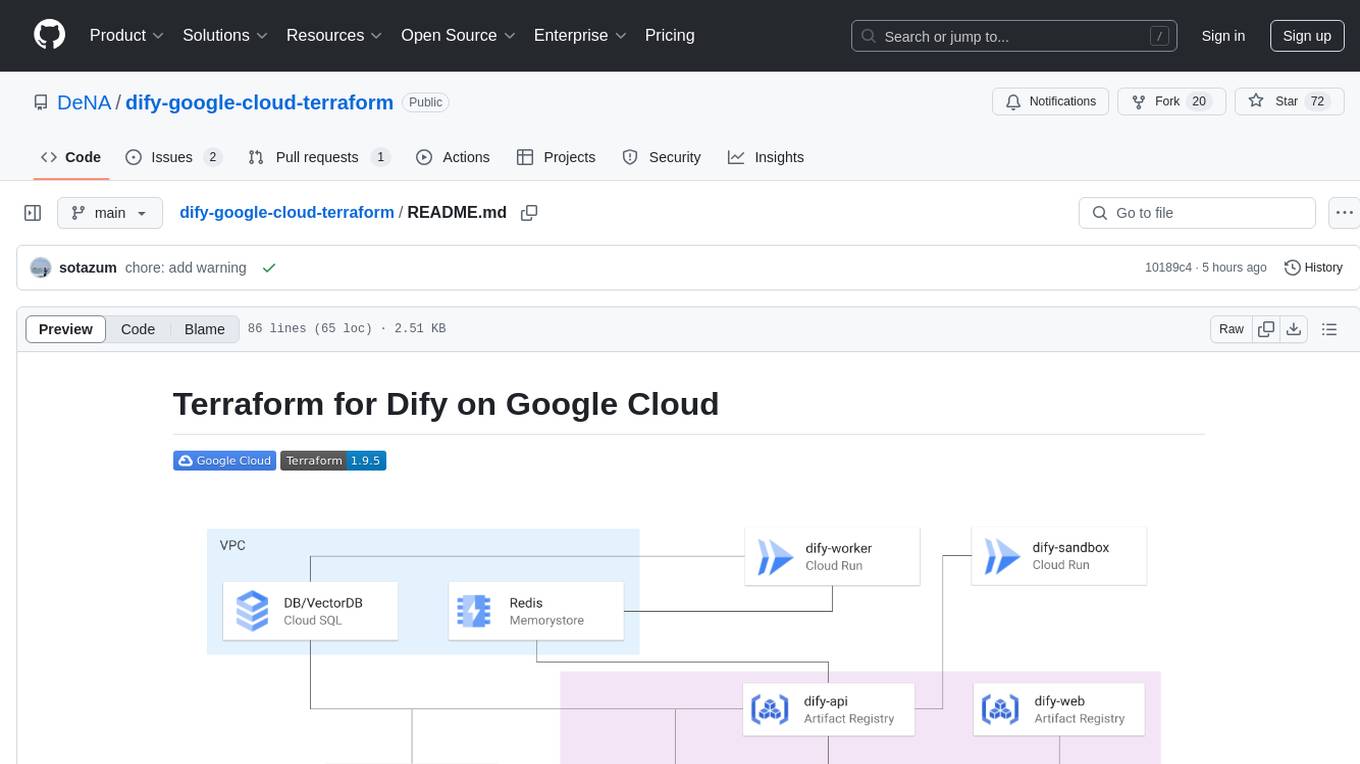
dify-google-cloud-terraform
This repository provides Terraform configurations to automatically set up Google Cloud resources and deploy Dify in a highly available configuration. It includes features such as serverless hosting, auto-scaling, and data persistence. Users need a Google Cloud account, Terraform, and gcloud CLI installed to use this tool. The configuration involves setting environment-specific values and creating a GCS bucket for managing Terraform state. The tool allows users to initialize Terraform, create Artifact Registry repository, build and push container images, plan and apply Terraform changes, and cleanup resources when needed.
action_mcp
Action MCP is a powerful tool for managing and automating your cloud infrastructure. It provides a user-friendly interface to easily create, update, and delete resources on popular cloud platforms. With Action MCP, you can streamline your deployment process, reduce manual errors, and improve overall efficiency. The tool supports various cloud providers and offers a wide range of features to meet your infrastructure management needs. Whether you are a developer, system administrator, or DevOps engineer, Action MCP can help you simplify and optimize your cloud operations.
For similar jobs

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.

ai-on-gke
This repository contains assets related to AI/ML workloads on Google Kubernetes Engine (GKE). Run optimized AI/ML workloads with Google Kubernetes Engine (GKE) platform orchestration capabilities. A robust AI/ML platform considers the following layers: Infrastructure orchestration that support GPUs and TPUs for training and serving workloads at scale Flexible integration with distributed computing and data processing frameworks Support for multiple teams on the same infrastructure to maximize utilization of resources

kong
Kong, or Kong API Gateway, is a cloud-native, platform-agnostic, scalable API Gateway distinguished for its high performance and extensibility via plugins. It also provides advanced AI capabilities with multi-LLM support. By providing functionality for proxying, routing, load balancing, health checking, authentication (and more), Kong serves as the central layer for orchestrating microservices or conventional API traffic with ease. Kong runs natively on Kubernetes thanks to its official Kubernetes Ingress Controller.

AI-in-a-Box
AI-in-a-Box is a curated collection of solution accelerators that can help engineers establish their AI/ML environments and solutions rapidly and with minimal friction, while maintaining the highest standards of quality and efficiency. It provides essential guidance on the responsible use of AI and LLM technologies, specific security guidance for Generative AI (GenAI) applications, and best practices for scaling OpenAI applications within Azure. The available accelerators include: Azure ML Operationalization in-a-box, Edge AI in-a-box, Doc Intelligence in-a-box, Image and Video Analysis in-a-box, Cognitive Services Landing Zone in-a-box, Semantic Kernel Bot in-a-box, NLP to SQL in-a-box, Assistants API in-a-box, and Assistants API Bot in-a-box.

awsome-distributed-training
This repository contains reference architectures and test cases for distributed model training with Amazon SageMaker Hyperpod, AWS ParallelCluster, AWS Batch, and Amazon EKS. The test cases cover different types and sizes of models as well as different frameworks and parallel optimizations (Pytorch DDP/FSDP, MegatronLM, NemoMegatron...).
generative-ai-cdk-constructs
The AWS Generative AI Constructs Library is an open-source extension of the AWS Cloud Development Kit (AWS CDK) that provides multi-service, well-architected patterns for quickly defining solutions in code to create predictable and repeatable infrastructure, called constructs. The goal of AWS Generative AI CDK Constructs is to help developers build generative AI solutions using pattern-based definitions for their architecture. The patterns defined in AWS Generative AI CDK Constructs are high level, multi-service abstractions of AWS CDK constructs that have default configurations based on well-architected best practices. The library is organized into logical modules using object-oriented techniques to create each architectural pattern model.

model_server
OpenVINO™ Model Server (OVMS) is a high-performance system for serving models. Implemented in C++ for scalability and optimized for deployment on Intel architectures, the model server uses the same architecture and API as TensorFlow Serving and KServe while applying OpenVINO for inference execution. Inference service is provided via gRPC or REST API, making deploying new algorithms and AI experiments easy.
dify-helm
Deploy langgenius/dify, an LLM based chat bot app on kubernetes with helm chart.