
mini-sglang
A compact implementation of SGLang, designed to demystify the complexities of modern LLM serving systems.
Stars: 3406

Mini-SGLang is a lightweight yet high-performance inference framework for Large Language Models. With a compact codebase of ~5,000 lines of Python, it serves as both a capable inference engine and a transparent reference for researchers and developers. It achieves state-of-the-art throughput and latency with advanced optimizations such as Radix Cache, Chunked Prefill, Overlap Scheduling, Tensor Parallelism, and Optimized Kernels integrating FlashAttention and FlashInfer for maximum efficiency. Mini-SGLang is designed to demystify the complexities of modern LLM serving systems, providing a clean, modular, and fully type-annotated codebase that is easy to understand and modify.
README:
![]()
A lightweight yet high-performance inference framework for Large Language Models.
Mini-SGLang is a compact implementation of SGLang, designed to demystify the complexities of modern LLM serving systems. With a compact codebase of ~5,000 lines of Python, it serves as both a capable inference engine and a transparent reference for researchers and developers.
- High Performance: Achieves state-of-the-art throughput and latency with advanced optimizations.
- Lightweight & Readable: A clean, modular, and fully type-annotated codebase that is easy to understand and modify.
-
Advanced Optimizations:
- Radix Cache: Reuses KV cache for shared prefixes across requests.
- Chunked Prefill: Reduces peak memory usage for long-context serving.
- Overlap Scheduling: Hides CPU scheduling overhead with GPU computation.
- Tensor Parallelism: Scales inference across multiple GPUs.
- Optimized Kernels: Integrates FlashAttention and FlashInfer for maximum efficiency.
- ...
⚠️ Platform Support: Mini-SGLang currently supports Linux only (x86_64 and aarch64). Windows and macOS are not supported due to dependencies on Linux-specific CUDA kernels (sgl-kernel,flashinfer). We recommend using WSL2 on Windows or Docker for cross-platform compatibility.
We recommend using uv for a fast and reliable installation (note that uv does not conflict with conda).
# Create a virtual environment (Python 3.10+ recommended)
uv venv --python=3.12
source .venv/bin/activatePrerequisites: Mini-SGLang relies on CUDA kernels that are JIT-compiled. Ensure you have the NVIDIA CUDA Toolkit installed and that its version matches your driver's version. You can check your driver's CUDA capability with nvidia-smi.
Install Mini-SGLang directly from the source:
git clone https://github.com/sgl-project/mini-sglang.git
cd mini-sglang && uv venv --python=3.12 && source .venv/bin/activate
uv pip install -e .💡 Installing on Windows (WSL2)
Since Mini-SGLang requires Linux-specific dependencies, Windows users should use WSL2:
-
Install WSL2 (if not already installed):
# In PowerShell (as Administrator) wsl --install
-
Install CUDA on WSL2:
- Follow NVIDIA's WSL2 CUDA guide
- Ensure your Windows GPU drivers support WSL2
-
Install Mini-SGLang in WSL2:
# Inside WSL2 terminal git clone https://github.com/sgl-project/mini-sglang.git cd mini-sglang && uv venv --python=3.12 && source .venv/bin/activate uv pip install -e .
-
Access from Windows: The server will be accessible at
http://localhost:8000from Windows browsers and applications.
Launch an OpenAI-compatible API server with a single command.
# Deploy Qwen/Qwen3-0.6B on a single GPU
python -m minisgl --model "Qwen/Qwen3-0.6B"
# Deploy meta-llama/Llama-3.1-70B-Instruct on 4 GPUs with Tensor Parallelism, on port 30000
python -m minisgl --model "meta-llama/Llama-3.1-70B-Instruct" --tp 4 --port 30000Once the server is running, you can send requests using standard tools like curl or any OpenAI-compatible client.
Chat with your model directly in the terminal by adding the --shell flag.
python -m minisgl --model "Qwen/Qwen3-0.6B" --shell
You can also use /reset to clear the chat history.
See bench.py for more details. Set MINISGL_DISABLE_OVERLAP_SCHEDULING=1 for ablation study on overlap scheduling.
Test Configuration:
- Hardware: 1xH200 GPU.
- Model: Qwen3-0.6B, Qwen3-14B
- Total Requests: 256 sequences
- Input Length: Randomly sampled between 100-1024 tokens
- Output Length: Randomly sampled between 100-1024 tokens

See benchmark_qwen.py for more details.
Test Configuration:
- Hardware: 4xH200 GPU, connected by NVLink.
- Model: Qwen3-32B
- Dataset: Qwen trace, replaying first 1000 requests.
Launch command:
# Mini-SGLang
python -m minisgl --model "Qwen/Qwen3-32B" --tp 4 --cache naive
# SGLang
python3 -m sglang.launch_server --model "Qwen/Qwen3-32B" --tp 4 \
--disable-radix --port 1919 --decode-attention flashinfer
- Detailed Features: Explore all available features and command-line arguments.
- System Architecture: Dive deep into the design and data flow of Mini-SGLang.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for mini-sglang
Similar Open Source Tools
mini-sglang
Mini-SGLang is a lightweight yet high-performance inference framework for Large Language Models. With a compact codebase of ~5,000 lines of Python, it serves as both a capable inference engine and a transparent reference for researchers and developers. It achieves state-of-the-art throughput and latency with advanced optimizations such as Radix Cache, Chunked Prefill, Overlap Scheduling, Tensor Parallelism, and Optimized Kernels integrating FlashAttention and FlashInfer for maximum efficiency. Mini-SGLang is designed to demystify the complexities of modern LLM serving systems, providing a clean, modular, and fully type-annotated codebase that is easy to understand and modify.
Visionatrix
Visionatrix is a project aimed at providing easy use of ComfyUI workflows. It offers simplified setup and update processes, a minimalistic UI for daily workflow use, stable workflows with versioning and update support, scalability for multiple instances and task workers, multiple user support with integration of different user backends, LLM power for integration with Ollama/Gemini, and seamless integration as a service with backend endpoints and webhook support. The project is approaching version 1.0 release and welcomes new ideas for further implementation.
rkllama
RKLLama is a server and client tool designed for running and interacting with LLM models optimized for Rockchip RK3588(S) and RK3576 platforms. It allows models to run on the NPU, with features such as running models on NPU, partial Ollama API compatibility, pulling models from Huggingface, API REST with documentation, dynamic loading/unloading of models, inference requests with streaming modes, simplified model naming, CPU model auto-detection, and optional debug mode. The tool supports Python 3.8 to 3.12 and has been tested on Orange Pi 5 Pro and Orange Pi 5 Plus with specific OS versions.

llamafarm
LlamaFarm is a comprehensive AI framework that empowers users to build powerful AI applications locally, with full control over costs and deployment options. It provides modular components for RAG systems, vector databases, model management, prompt engineering, and fine-tuning. Users can create differentiated AI products without needing extensive ML expertise, using simple CLI commands and YAML configs. The framework supports local-first development, production-ready components, strategy-based configuration, and deployment anywhere from laptops to the cloud.

layra
LAYRA is the world's first visual-native AI automation engine that sees documents like a human, preserves layout and graphical elements, and executes arbitrarily complex workflows with full Python control. It empowers users to build next-generation intelligent systems with no limits or compromises. Built for Enterprise-Grade deployment, LAYRA features a modern frontend, high-performance backend, decoupled service architecture, visual-native multimodal document understanding, and a powerful workflow engine.
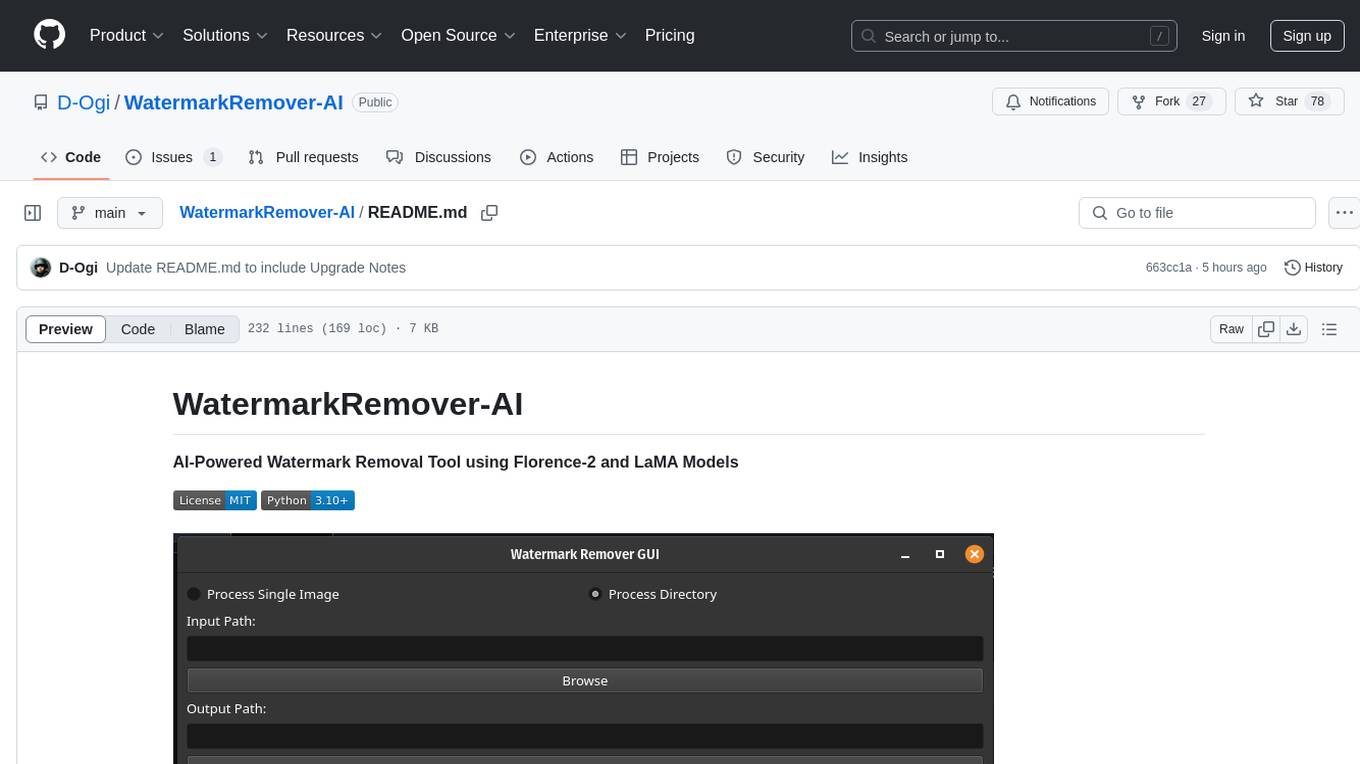
WatermarkRemover-AI
WatermarkRemover-AI is an advanced application that utilizes AI models for precise watermark detection and seamless removal. It leverages Florence-2 for watermark identification and LaMA for inpainting. The tool offers both a command-line interface (CLI) and a PyQt6-based graphical user interface (GUI), making it accessible to users of all levels. It supports dual modes for processing images, advanced watermark detection, seamless inpainting, customizable output settings, real-time progress tracking, dark mode support, and efficient GPU acceleration using CUDA.

mistral.rs
Mistral.rs is a fast LLM inference platform written in Rust. We support inference on a variety of devices, quantization, and easy-to-use application with an Open-AI API compatible HTTP server and Python bindings.
tingly-box
Tingly Box is a tool that helps in deciding which model to call, compressing context, and routing requests efficiently. It offers secure, reliable, and customizable functional extensions. With features like unified API, smart routing, context compression, auto API translation, blazing fast performance, flexible authentication, visual control panel, and client-side usage stats, Tingly Box provides a comprehensive solution for managing AI models and tokens. It supports integration with various IDEs, CLI tools, SDKs, and AI applications, making it versatile and easy to use. The tool also allows seamless integration with OAuth providers like Claude Code, enabling users to utilize existing quotas in OpenAI-compatible tools. Tingly Box aims to simplify AI model management and usage by providing a single endpoint for multiple providers with minimal configuration, promoting seamless integration with SDKs and CLI tools.
backend.ai
Backend.AI is a streamlined, container-based computing cluster platform that hosts popular computing/ML frameworks and diverse programming languages, with pluggable heterogeneous accelerator support including CUDA GPU, ROCm GPU, TPU, IPU and other NPUs. It allocates and isolates the underlying computing resources for multi-tenant computation sessions on-demand or in batches with customizable job schedulers with its own orchestrator. All its functions are exposed as REST/GraphQL/WebSocket APIs.
AgC
AgC is an open-core platform designed for deploying, running, and orchestrating AI agents at scale. It treats agents as first-class compute units, providing a modular, observable, cloud-neutral, and production-ready environment. Open Agentic Compute empowers developers and organizations to run agents like cloud-native workloads without lock-in.
miner-release
Heurist Miner is a tool that allows users to contribute their GPU for AI inference tasks on the Heurist network. It supports dual mining capabilities for image generation models and Large Language Models, offers flexible setup on Windows or Linux with multiple GPUs, ensures secure rewards through a dual-wallet system, and is fully open source. Users can earn rewards by hosting AI models and supporting applications in the Heurist ecosystem.
figma-console-mcp
Figma Console MCP is a Model Context Protocol server that bridges design and development, giving AI assistants complete access to Figma for extraction, creation, and debugging. It connects AI assistants like Claude to Figma, enabling plugin debugging, visual debugging, design system extraction, design creation, variable management, real-time monitoring, and three installation methods. The server offers 53+ tools for NPX and Local Git setups, while Remote SSE provides read-only access with 16 tools. Users can create and modify designs with AI, contribute to projects, or explore design data. The server supports authentication via personal access tokens and OAuth, and offers tools for navigation, console debugging, visual debugging, design system extraction, design creation, design-code parity, variable management, and AI-assisted design creation.
RealtimeSTT_LLM_TTS
RealtimeSTT is an easy-to-use, low-latency speech-to-text library for realtime applications. It listens to the microphone and transcribes voice into text, making it ideal for voice assistants and applications requiring fast and precise speech-to-text conversion. The library utilizes Voice Activity Detection, Realtime Transcription, and Wake Word Activation features. It supports GPU-accelerated transcription using PyTorch with CUDA support. RealtimeSTT offers various customization options for different parameters to enhance user experience and performance. The library is designed to provide a seamless experience for developers integrating speech-to-text functionality into their applications.
CyberStrikeAI
CyberStrikeAI is an AI-native security testing platform built in Go that integrates 100+ security tools, an intelligent orchestration engine, role-based testing with predefined security roles, a skills system with specialized testing skills, and comprehensive lifecycle management capabilities. It enables end-to-end automation from conversational commands to vulnerability discovery, attack-chain analysis, knowledge retrieval, and result visualization, delivering an auditable, traceable, and collaborative testing environment for security teams. The platform features an AI decision engine with OpenAI-compatible models, native MCP implementation with various transports, prebuilt tool recipes, large-result pagination, attack-chain graph, password-protected web UI, knowledge base with vector search, vulnerability management, batch task management, role-based testing, and skills system.
DreamLayer
DreamLayer AI is an open-source Stable Diffusion WebUI designed for AI researchers, labs, and developers. It automates prompts, seeds, and metrics for benchmarking models, datasets, and samplers, enabling reproducible evaluations across multiple seeds and configurations. The tool integrates custom metrics and evaluation pipelines, providing a streamlined workflow for AI research. With features like automated benchmarking, reproducibility, built-in metrics, multi-modal readiness, and researcher-friendly interface, DreamLayer AI aims to simplify and accelerate the model evaluation process.
FastFlowLM
FastFlowLM is a Python library for efficient and scalable language model inference. It provides a high-performance implementation of language model scoring using n-gram language models. The library is designed to handle large-scale text data and can be easily integrated into natural language processing pipelines for tasks such as text generation, speech recognition, and machine translation. FastFlowLM is optimized for speed and memory efficiency, making it suitable for both research and production environments.
For similar tasks
LLM_Web_search
LLM_Web_search project gives local LLMs the ability to search the web by outputting a specific command. It uses regular expressions to extract search queries from model output and then utilizes duckduckgo-search to search the web. LangChain's Contextual compression and Okapi BM25 or SPLADE are used to extract relevant parts of web pages in search results. The extracted results are appended to the model's output.
node-llama-cpp
node-llama-cpp is a tool that allows users to run AI models locally on their machines. It provides pre-built bindings with the option to build from source using cmake. Users can interact with text generation models, chat with models using a chat wrapper, and force models to generate output in a parseable format like JSON. The tool supports Metal and CUDA, offers CLI functionality for chatting with models without coding, and ensures up-to-date compatibility with the latest version of llama.cpp. Installation includes pre-built binaries for macOS, Linux, and Windows, with the option to build from source if binaries are not available for the platform.

Jlama
Jlama is a modern Java inference engine designed for large language models. It supports various model types such as Gemma, Llama, Mistral, GPT-2, BERT, and more. The tool implements features like Flash Attention, Mixture of Experts, and supports different model quantization formats. Built with Java 21 and utilizing the new Vector API for faster inference, Jlama allows users to add LLM inference directly to their Java applications. The tool includes a CLI for running models, a simple UI for chatting with LLMs, and examples for different model types.

torchchat
torchchat is a codebase showcasing the ability to run large language models (LLMs) seamlessly. It allows running LLMs using Python in various environments such as desktop, server, iOS, and Android. The tool supports running models via PyTorch, chatting, generating text, running chat in the browser, and running models on desktop/server without Python. It also provides features like AOT Inductor for faster execution, running in C++ using the runner, and deploying and running on iOS and Android. The tool supports popular hardware and OS including Linux, Mac OS, Android, and iOS, with various data types and execution modes available.

chatgpt-cli
ChatGPT CLI provides a powerful command-line interface for seamless interaction with ChatGPT models via OpenAI and Azure. It features streaming capabilities, extensive configuration options, and supports various modes like streaming, query, and interactive mode. Users can manage thread-based context, sliding window history, and provide custom context from any source. The CLI also offers model and thread listing, advanced configuration options, and supports GPT-4, GPT-3.5-turbo, and Perplexity's models. Installation is available via Homebrew or direct download, and users can configure settings through default values, a config.yaml file, or environment variables.
elmer
Elmer is a user-friendly wrapper over common APIs for calling llm’s, with support for streaming and easy registration and calling of R functions. Users can interact with Elmer in various ways, such as interactive chat console, interactive method call, programmatic chat, and streaming results. Elmer also supports async usage for running multiple chat sessions concurrently, useful for Shiny applications. The tool calling feature allows users to define external tools that Elmer can request to execute, enhancing the capabilities of the chat model.
mlx-lm
MLX LM is a Python package designed for generating text and fine-tuning large language models on Apple silicon using MLX. It offers integration with the Hugging Face Hub for easy access to thousands of LLMs, support for quantizing and uploading models to the Hub, low-rank and full model fine-tuning capabilities, and distributed inference and fine-tuning with `mx.distributed`. Users can interact with the package through command line options or the Python API, enabling tasks such as text generation, chatting with language models, model conversion, streaming generation, and sampling. MLX LM supports various Hugging Face models and provides tools for efficient scaling to long prompts and generations, including a rotating key-value cache and prompt caching. It requires macOS 15.0 or higher for optimal performance.
mini-sglang
Mini-SGLang is a lightweight yet high-performance inference framework for Large Language Models. With a compact codebase of ~5,000 lines of Python, it serves as both a capable inference engine and a transparent reference for researchers and developers. It achieves state-of-the-art throughput and latency with advanced optimizations such as Radix Cache, Chunked Prefill, Overlap Scheduling, Tensor Parallelism, and Optimized Kernels integrating FlashAttention and FlashInfer for maximum efficiency. Mini-SGLang is designed to demystify the complexities of modern LLM serving systems, providing a clean, modular, and fully type-annotated codebase that is easy to understand and modify.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.