
miner-release
Stable Diffusion and LLM miner for Heurist
Stars: 73
Heurist Miner is a tool that allows users to contribute their GPU for AI inference tasks on the Heurist network. It supports dual mining capabilities for image generation models and Large Language Models, offers flexible setup on Windows or Linux with multiple GPUs, ensures secure rewards through a dual-wallet system, and is fully open source. Users can earn rewards by hosting AI models and supporting applications in the Heurist ecosystem.
README:
- Introduction
- System Requirements
- Quick Start Guide
- Detailed Setup Instructions
- Advanced Configuration
- Troubleshooting
- FAQ
- Support and Community
Welcome to the Heurist Miner, the entrance to decentralized generative AI. Whether you have a high-end gaming PC with NVIDIA GPU or you're a datacenter owner ready to explore the world of AI and cryptocurrency, this guide will help you get started on an exciting journey!
Heurist Miner allows you to contribute your GPU to perform AI inference tasks on the Heurist network. By running this miner, you'll earn rewards by hosting AI models and supporting various applications in Heurist ecosystem.
- 🖼️ Dual Mining Capabilities: Support for both image generation models and Large Language Models.
- 🖥️ Flexible Setup: Run on Windows or Linux, with support for multiple GPUs.
- 🔐 Secure Rewards: Utilizes a dual-wallet system for enhanced security.
- 🌐 Open Source: The code is fully open and transparent. Download and run with ease.
Before you begin, ensure your system meets the following requirements:
- GPU: NVIDIA GPU with at least 12GB VRAM (24GB+ recommended for optimal performance)
- CPU: Multi-core processor (4+ cores recommended)
- RAM: 16GB+ system RAM
- Storage: At least 50GB free space (NVMe recommended for faster model loading)
-
Operating System:
- Windows 10/11 (64-bit)
- Linux (Ubuntu 20.04 LTS or later recommended)
- CUDA: Version 12.1, or 12.2
- Python: Version 3.10 or 3.11
- Git: For cloning the repository
- Stable internet connection (100 Mbps+ recommended)
- Ability to access HuggingFace and GitHub repositories
- Some models (especially larger LLMs) may require more VRAM. Check the model-specific requirements in the detailed setup sections.
- Ensure your system is up-to-date with the latest NVIDIA GPU drivers.
- Stable Diffusion models need at least 8-10GB VRAM, while LLMs can require 16GB to 40GB+ depending on the model size.
For experienced users, here's a quick overview to get you mining:
- Clone the Repository
git clone https://github.com/heurist-network/miner-release.git
cd miner-release- Set Up Environment
- Install Miniconda (if not already installed)
- Create and activate a new conda environment:
conda create --name heurist-miner python=3.11
conda activate heurist-miner- Install Dependencies
pip install -r requirements.txt- Configure Miner ID
- Create a
.envfile in the root directory - Add your Ethereum wallet address:
MINER_ID_0=0xYourWalletAddressHereFollow "Multiple GPU Configuration" section if you have multiple GPUs.
- Choose Your Miner
- For Stable Diffusion:
python sd-miner.py- For LLM:
./llm-miner-starter.sh <model_id>For detailed instructions, troubleshooting, and advanced configuration, please refer to the sections below.
(current version only supports Flux model)
For users who prefer using Docker, follow these steps:
- Build the Docker Image
docker build -t heurist-miner:latest .- Run the Docker Container
Single GPU:
sudo docker run -d --gpus all \
-e MINER_ID_0=0xWalletAddressHere \
-e LOG_LEVEL=INFO \
-v $HOME/.cache/heurist:/app/.cache/heurist \
heurist-miner:latestReplace 0xYourWalletAddressHere with your wallet address to receive rewards.
Multiple GPUs:
sudo docker run -d --gpus all \
-e MINER_ID_0=0xYourFirstWalletAddressHere \
-e MINER_ID_1=0xYourSecondWalletAddressHere \
-e MINER_ID_2=0xYourThirdWalletAddressHere \
-e LOG_LEVEL=INFO \
-v $HOME/.cache/heurist:/app/.cache/heurist \
heurist-miner:latestReplace 0xYourFirstWalletAddressHere, 0xYourSecondWalletAddressHere, and 0xYourThirdWalletAddressHere with your actual wallet addresses.
This command:
- Runs the container in detached mode (
-d) - Allows access to all GPUs (
--gpus all) - Sets environment variables for miner IDs and log level
- Mounts a volume for persistent cache storage
- Uses the image we just built (
heurist-miner:latest)
Note: Ensure you have the NVIDIA Container Toolkit installed for GPU support in Docker.
Heurist Miner uses a dual-wallet system for security and reward distribution:
- Identity Wallet: Used for authentication, stored locally. Do not store funds here.
- Reward Wallet (Miner ID): Receives points, Heurist Token rewards, potential ecosystem benefits.
- Create a
.envfile in the root directory of your miner installation. - Add your Ethereum wallet address(es) as Miner ID(s):
MINER_ID_0=0xYourFirstWalletAddressHere MINER_ID_1=0xYourSecondWalletAddressHere - (Optional) Add custom tags for tracking:
MINER_ID_0=0xYourFirstWalletAddressHere-GamingPC4090 MINER_ID_1=0xYourSecondWalletAddressHere-GoogleCloudT4 - Generate or import identity wallets:
Follow the prompts to create new wallets or import existing ones.
python3 ./auth/generator.py
-
Install Miniconda:
- Download from Miniconda website
- Choose the latest Windows 64-bit version for Python 3.11
-
Create Conda Environment:
conda create --name heurist-miner python=3.11 conda activate heurist-miner
-
Install CUDA Toolkit:
- Download CUDA 12.1 from NVIDIA website
- Follow the installation prompts
-
Install PyTorch with GPU Support:
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia
-
Clone Miner Repository and Install Dependencies:
git clone https://github.com/heurist-network/miner-release cd miner-release pip install -r requirements.txt -
Run the Miner:
python3 sd-miner.py
-
Update GPU Drivers (if necessary):
sudo apt update sudo ubuntu-drivers autoinstall
-
Install Miniconda:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh bash Miniconda3-latest-Linux-x86_64.sh
-
Create Conda Environment:
conda create --name heurist-miner python=3.11 conda activate heurist-miner
- Install CUDA Toolkit:
- Follow instructions on NVIDIA CUDA Installation Guide
-
Install PyTorch with GPU Support:
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia
-
Clone Miner Repository and Install Dependencies:
git clone https://github.com/heurist-network/miner-release cd miner-release pip install -r requirements.txt -
Run the Miner:
python3 sd-miner.py
-
Ensure CUDA Driver is Installed:
- Check with
nvidia-smi
- Check with
-
Select a Model ID:
- Choose based on your GPU's VRAM capacity
- Example models:
-
dolphin-2.9-llama3-8b(24GB VRAM) -
openhermes-mixtral-8x7b-gptq(40GB VRAM)
-
-
Run the Setup Script:
Options:
chmod +x llm-miner-starter.sh ./llm-miner-starter.sh <model_id> --miner-id-index 0 --port 8000 --gpu-ids 0
-
--miner-id-index: Index of miner_id in.env(default: 0) -
--port: Port for vLLM process (default: 8000) -
--gpu-ids: GPU ID to use (default: 0)
- Wait for Model Download:
- First run will download the model (can take time)
- Models are saved in
$HOME/.cache/huggingface
Note: 8x7b, 34b, and 70b models may take up to an hour to load on some devices.
When running the SD miner, you can use various CLI options to customize its behavior. You can combine multiple flags.
-
Log Level
- Set the verbosity of log messages:
python3 sd-miner.py --log-level DEBUG
- Options: DEBUG, INFO, WARNING, ERROR, CRITICAL (default: INFO)
- Set the verbosity of log messages:
-
Auto-Confirm
- Automatically confirm model downloads:
python3 sd-miner.py --auto-confirm yes
- Options: yes, no (default: no)
- Automatically confirm model downloads:
-
Exclude SDXL
- Exclude SDXL models to reduce VRAM usage:
python3 sd-miner.py --exclude-sdxl
- Exclude SDXL models to reduce VRAM usage:
-
Specify Model ID
- Run the miner with a specific model:
python3 sd-miner.py --model-id <model_id>
- For example, run FLUX.1-dev model with:
python3 sd-miner.py --model-id FLUX.1-dev --skip-checksum
- Run the miner with a specific model:
-
CUDA Device ID
- Specify which GPU to use:
python3 sd-miner.py --cuda-device-id 0
- Specify which GPU to use:
-
Skip checksum to speed up miner start-up time
- This skips checking the validity of model files. However, if incompleted files are present on the disk, the miner process will crash without this check.
python3 sd-miner.py --skip-checksum
- This skips checking the validity of model files. However, if incompleted files are present on the disk, the miner process will crash without this check.
For LLM miner, use the following CLI options to customize its behavior:
-
Specify Model ID
- Run the miner with a specific model (mandatory):
./llm-miner-starter.sh <model_id>
- Example:
dolphin-2.9-llama3-8b(requires 24GB VRAM)
- Run the miner with a specific model (mandatory):
-
Miner ID Index
- Specify which miner ID from the
.envfile to use:./llm-miner-starter.sh <model_id> --miner-id-index 1
- Default: 0 (uses the first address configured)
- Specify which miner ID from the
-
Port
- Set the port for communication with the vLLM process:
./llm-miner-starter.sh <model_id> --port 8001
- Default: 8000
- Set the port for communication with the vLLM process:
-
GPU IDs
-
Specify which GPU(s) to use:
./llm-miner-starter.sh <model_id> --gpu-ids 1
-
Default: 0
-
Example combining multiple options:
./llm-miner-starter.sh dolphin-2.9-llama3-8b --miner-id-index 1 --port 8001 --gpu-ids 1
-
Advanced usage: To deploy large models using multiple GPUs on the same machine.
./llm-miner-starter.sh openhermes-mixtral-8x7b-gptq --miner-id-index 0 --port 8000 --gpu-ids 0,1
-
To utilize multiple GPUs:
- Assign unique Miner IDs in your
.envfile:MINER_ID_0=0xWalletAddress1 MINER_ID_1=0xWalletAddress2 - Set
num_cuda_devicesinconfig.toml:[system] num_cuda_devices = 2
- Run the miner without specifying a CUDA device ID to use all available GPUs.
Running into issues? Don't worry, we've got you covered! Here are some common problems and their solutions:
-
🚨 CUDA not found
- Ensure CUDA is properly installed
- Check if the CUDA version matches PyTorch requirements
✅ Solution: Reinstall CUDA or update PyTorch to match your CUDA version
-
🚨 Dependencies installation fails
- Check your Python version (should be 3.10 or 3.11)
- Ensure you're in the correct Conda environment
✅ Solution: Create a new Conda environment and reinstall dependencies
-
🚨 CUDA out of memory error
- Check available GPU memory using
nvidia-smi - Stop other programs occupying VRAM, or use a smaller model
✅ Solution: Add--exclude-sdxlflag for SD miner or choose a smaller LLM
- Check available GPU memory using
-
🚨 Miner not receiving tasks
- Check your internet connection
- Verify your Miner ID is correctly set in the
.envfile
✅ Solution: Restart the miner and check logs for connection issues
-
🚨 Model loading takes too long
- This is normal for large models, especially on first run
- Check disk space and internet speed
✅ Solution: Be patient (grab a coffee! ☕), or choose a smaller model
- 🔍 Always check the console output for specific error messages
- 🔄 Ensure you're using the latest version of the miner software
- 💬 If problems persist, don't hesitate to ask for help in our Discord community!
Got questions? We've got answers!
1️⃣ Can I run both SD and LLM miners simultaneously? 🖥️🖥️
2️⃣ How do I know if I'm earning rewards? 💰
3️⃣ What's the difference between Identity Wallet and Reward Wallet? 🎭💼
4️⃣ Can I use my gaming PC for mining when I'm not gaming? 🎮➡️💻
5️⃣ How often should I update the miner software? 🔄
Join our lively community on Discord - it's where all the cool miners hang out! 🔗 Heurist Discord #dev-chat channel
- 📚 Check our Troubleshooting guide and FAQ - you might find a quick fix!
- 🆘 Still stuck? Head over to our GitHub Issues page: 🔗 Heurist Miner Issues
- 📝 When reporting, remember to include:
- Miner version
- Model
- Operating System
- Console error messages and log files
- Steps to reproduce
Keep up with the latest Heurist happenings:
- 📖 Medium: Heurist Blogs
- 📣 Discord: Tune into our #miner-announcements channel
- 🐦 X/Twitter: Follow Heurist for the latest updates
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for miner-release
Similar Open Source Tools
miner-release
Heurist Miner is a tool that allows users to contribute their GPU for AI inference tasks on the Heurist network. It supports dual mining capabilities for image generation models and Large Language Models, offers flexible setup on Windows or Linux with multiple GPUs, ensures secure rewards through a dual-wallet system, and is fully open source. Users can earn rewards by hosting AI models and supporting applications in the Heurist ecosystem.

horde-worker-reGen
This repository provides the latest implementation for the AI Horde Worker, allowing users to utilize their graphics card(s) to generate, post-process, or analyze images for others. It offers a platform where users can create images and earn 'kudos' in return, granting priority for their own image generations. The repository includes important details for setup, recommendations for system configurations, instructions for installation on Windows and Linux, basic usage guidelines, and information on updating the AI Horde Worker. Users can also run the worker with multiple GPUs and receive notifications for updates through Discord. Additionally, the repository contains models that are licensed under the CreativeML OpenRAIL License.
DesktopCommanderMCP
Desktop Commander MCP is a server that allows the Claude desktop app to execute long-running terminal commands on your computer and manage processes through Model Context Protocol (MCP). It is built on top of MCP Filesystem Server to provide additional search and replace file editing capabilities. The tool enables users to execute terminal commands with output streaming, manage processes, perform full filesystem operations, and edit code with surgical text replacements or full file rewrites. It also supports vscode-ripgrep based recursive code or text search in folders.
AI-Solana_Bot
MevBot Solana is an advanced trading bot for the Solana blockchain with an interactive and user-friendly interface. It offers features like scam token scanning, automatic network connection, and focus on trading $TRUMP and $MELANIA tokens. Users can set stop-loss and take-profit thresholds, filter tokens based on market cap, and configure purchase amounts. The bot requires a starting balance of at least 3 SOL for optimal performance. It can be managed through a main menu in VS Code and requires prerequisites like Git, Node.js, and VS Code for installation and usage.
Devon
Devon is an open-source pair programmer tool designed to facilitate collaborative coding sessions. It provides features such as multi-file editing, codebase exploration, test writing, bug fixing, and architecture exploration. The tool supports Anthropic, OpenAI, and Groq APIs, with plans to add more models in the future. Devon is community-driven, with ongoing development goals including multi-model support, plugin system for tool builders, self-hostable Electron app, and setting SOTA on SWE-bench Lite. Users can contribute to the project by developing core functionality, conducting research on agent performance, providing feedback, and testing the tool.

Hacx-GPT
Hacx GPT is a cutting-edge AI tool developed by BlackTechX, inspired by WormGPT, designed to push the boundaries of natural language processing. It is an advanced broken AI model that facilitates seamless and powerful interactions, allowing users to ask questions and perform various tasks. The tool has been rigorously tested on platforms like Kali Linux, Termux, and Ubuntu, offering powerful AI conversations and the ability to do anything the user wants. Users can easily install and run Hacx GPT on their preferred platform to explore its vast capabilities.

xFasterTransformer
xFasterTransformer is an optimized solution for Large Language Models (LLMs) on the X86 platform, providing high performance and scalability for inference on mainstream LLM models. It offers C++ and Python APIs for easy integration, along with example codes and benchmark scripts. Users can prepare models in a different format, convert them, and use the APIs for tasks like encoding input prompts, generating token ids, and serving inference requests. The tool supports various data types and models, and can run in single or multi-rank modes using MPI. A web demo based on Gradio is available for popular LLM models like ChatGLM and Llama2. Benchmark scripts help evaluate model inference performance quickly, and MLServer enables serving with REST and gRPC interfaces.

easydiffusion
Easy Diffusion 3.0 is a user-friendly tool for installing and using Stable Diffusion on your computer. It offers hassle-free installation, clutter-free UI, task queue, intelligent model detection, live preview, image modifiers, multiple prompts file, saving generated images, UI themes, searchable models dropdown, and supports various image generation tasks like 'Text to Image', 'Image to Image', and 'InPainting'. The tool also provides advanced features such as custom models, merge models, custom VAE models, multi-GPU support, auto-updater, developer console, and more. It is designed for both new users and advanced users looking for powerful AI image generation capabilities.
AiR
AiR is an AI tool built entirely in Rust that delivers blazing speed and efficiency. It features accurate translation and seamless text rewriting to supercharge productivity. AiR is designed to assist non-native speakers by automatically fixing errors and polishing language to sound like a native speaker. The tool is under heavy development with more features on the horizon.

ebook2audiobook
ebook2audiobook is a CPU/GPU converter tool that converts eBooks to audiobooks with chapters and metadata using tools like Calibre, ffmpeg, XTTSv2, and Fairseq. It supports voice cloning and a wide range of languages. The tool is designed to run on 4GB RAM and provides a new v2.0 Web GUI interface for user-friendly interaction. Users can convert eBooks to text format, split eBooks into chapters, and utilize high-quality text-to-speech functionalities. Supported languages include Arabic, Chinese, English, French, German, Hindi, and many more. The tool can be used for legal, non-DRM eBooks only and should be used responsibly in compliance with applicable laws.
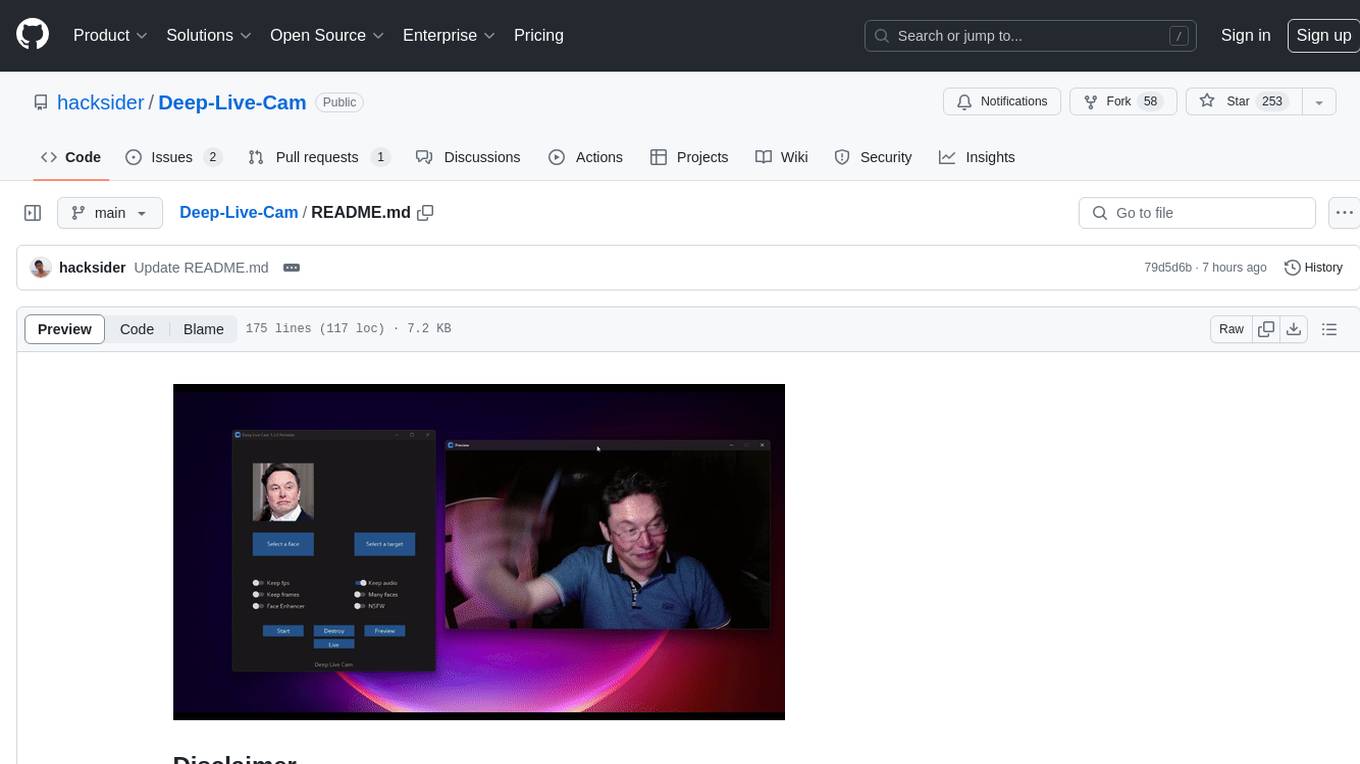
Deep-Live-Cam
Deep-Live-Cam is a software tool designed to assist artists in tasks such as animating custom characters or using characters as models for clothing. The tool includes built-in checks to prevent unethical applications, such as working on inappropriate media. Users are expected to use the tool responsibly and adhere to local laws, especially when using real faces for deepfake content. The tool supports both CPU and GPU acceleration for faster processing and provides a user-friendly GUI for swapping faces in images or videos.

AutoAgent
AutoAgent is a fully-automated and zero-code framework that enables users to create and deploy LLM agents through natural language alone. It is a top performer on the GAIA Benchmark, equipped with a native self-managing vector database, and allows for easy creation of tools, agents, and workflows without any coding. AutoAgent seamlessly integrates with a wide range of LLMs and supports both function-calling and ReAct interaction modes. It is designed to be dynamic, extensible, customized, and lightweight, serving as a personal AI assistant.

booster
Booster is a powerful inference accelerator designed for scaling large language models within production environments or for experimental purposes. It is built with performance and scaling in mind, supporting various CPUs and GPUs, including Nvidia CUDA, Apple Metal, and OpenCL cards. The tool can split large models across multiple GPUs, offering fast inference on machines with beefy GPUs. It supports both regular FP16/FP32 models and quantised versions, along with popular LLM architectures. Additionally, Booster features proprietary Janus Sampling for code generation and non-English languages.

tts-generation-webui
TTS Generation WebUI is a comprehensive tool that provides a user-friendly interface for text-to-speech and voice cloning tasks. It integrates various AI models such as Bark, MusicGen, AudioGen, Tortoise, RVC, Vocos, Demucs, SeamlessM4T, and MAGNeT. The tool offers one-click installers, Google Colab demo, videos for guidance, and extra voices for Bark. Users can generate audio outputs, manage models, caches, and system space for AI projects. The project is open-source and emphasizes ethical and responsible use of AI technology.
effective_llm_alignment
This is a super customizable, concise, user-friendly, and efficient toolkit for training and aligning LLMs. It provides support for various methods such as SFT, Distillation, DPO, ORPO, CPO, SimPO, SMPO, Non-pair Reward Modeling, Special prompts basket format, Rejection Sampling, Scoring using RM, Effective FAISS Map-Reduce Deduplication, LLM scoring using RM, NER, CLIP, Classification, and STS. The toolkit offers key libraries like PyTorch, Transformers, TRL, Accelerate, FSDP, DeepSpeed, and tools for result logging with wandb or clearml. It allows mixing datasets, generation and logging in wandb/clearml, vLLM batched generation, and aligns models using the SMPO method.
For similar tasks
miner-release
Heurist Miner is a tool that allows users to contribute their GPU for AI inference tasks on the Heurist network. It supports dual mining capabilities for image generation models and Large Language Models, offers flexible setup on Windows or Linux with multiple GPUs, ensures secure rewards through a dual-wallet system, and is fully open source. Users can earn rewards by hosting AI models and supporting applications in the Heurist ecosystem.
Stake-auto-bot
Stake-auto-bot is a tool designed for automated staking in the cryptocurrency space. It allows users to set up automated processes for staking their digital assets, providing a convenient way to earn rewards and secure networks. The tool simplifies the staking process by automating the necessary steps, such as selecting validators, delegating tokens, and monitoring rewards. With Stake-auto-bot, users can optimize their staking strategies and maximize their returns with minimal effort.

airflow
Apache Airflow (or simply Airflow) is a platform to programmatically author, schedule, and monitor workflows. When workflows are defined as code, they become more maintainable, versionable, testable, and collaborative. Use Airflow to author workflows as directed acyclic graphs (DAGs) of tasks. The Airflow scheduler executes your tasks on an array of workers while following the specified dependencies. Rich command line utilities make performing complex surgeries on DAGs a snap. The rich user interface makes it easy to visualize pipelines running in production, monitor progress, and troubleshoot issues when needed.

tt-metal
TT-NN is a python & C++ Neural Network OP library. It provides a low-level programming model, TT-Metalium, enabling kernel development for Tenstorrent hardware.
Forza-Mods-AIO
Forza Mods AIO is a free and open-source tool that enhances the gaming experience in Forza Horizon 4 and 5. It offers a range of time-saving and quality-of-life features, making gameplay more enjoyable and efficient. The tool is designed to streamline various aspects of the game, improving user satisfaction and overall enjoyment.
openssa
OpenSSA is an open-source framework for creating efficient, domain-specific AI agents. It enables the development of Small Specialist Agents (SSAs) that solve complex problems in specific domains. SSAs tackle multi-step problems that require planning and reasoning beyond traditional language models. They apply OODA for deliberative reasoning (OODAR) and iterative, hierarchical task planning (HTP). This "System-2 Intelligence" breaks down complex tasks into manageable steps. SSAs make informed decisions based on domain-specific knowledge. With OpenSSA, users can create agents that process, generate, and reason about information, making them more effective and efficient in solving real-world challenges.

pezzo
Pezzo is a fully cloud-native and open-source LLMOps platform that allows users to observe and monitor AI operations, troubleshoot issues, save costs and latency, collaborate, manage prompts, and deliver AI changes instantly. It supports various clients for prompt management, observability, and caching. Users can run the full Pezzo stack locally using Docker Compose, with prerequisites including Node.js 18+, Docker, and a GraphQL Language Feature Support VSCode Extension. Contributions are welcome, and the source code is available under the Apache 2.0 License.

llm_qlora
LLM_QLoRA is a repository for fine-tuning Large Language Models (LLMs) using QLoRA methodology. It provides scripts for training LLMs on custom datasets, pushing models to HuggingFace Hub, and performing inference. Additionally, it includes models trained on HuggingFace Hub, a blog post detailing the QLoRA fine-tuning process, and instructions for converting and quantizing models. The repository also addresses troubleshooting issues related to Python versions and dependencies.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.