Best AI tools for< Deploy Model >
20 - AI tool Sites

Mystic.ai
Mystic.ai is an AI tool designed to deploy and scale Machine Learning models with ease. It offers a fully managed Kubernetes platform that runs in your own cloud, allowing users to deploy ML models in their own Azure/AWS/GCP account or in a shared GPU cluster. Mystic.ai provides cost optimizations, fast inference, simpler developer experience, and performance optimizations to ensure high-performance AI model serving. With features like pay-as-you-go API, cloud integration with AWS/Azure/GCP, and a beautiful dashboard, Mystic.ai simplifies the deployment and management of ML models for data scientists and AI engineers.

PoplarML
PoplarML is a platform that enables the deployment of production-ready, scalable ML systems with minimal engineering effort. It offers one-click deploys, real-time inference, and framework agnostic support. With PoplarML, users can seamlessly deploy ML models using a CLI tool to a fleet of GPUs and invoke their models through a REST API endpoint. The platform supports Tensorflow, Pytorch, and JAX models.
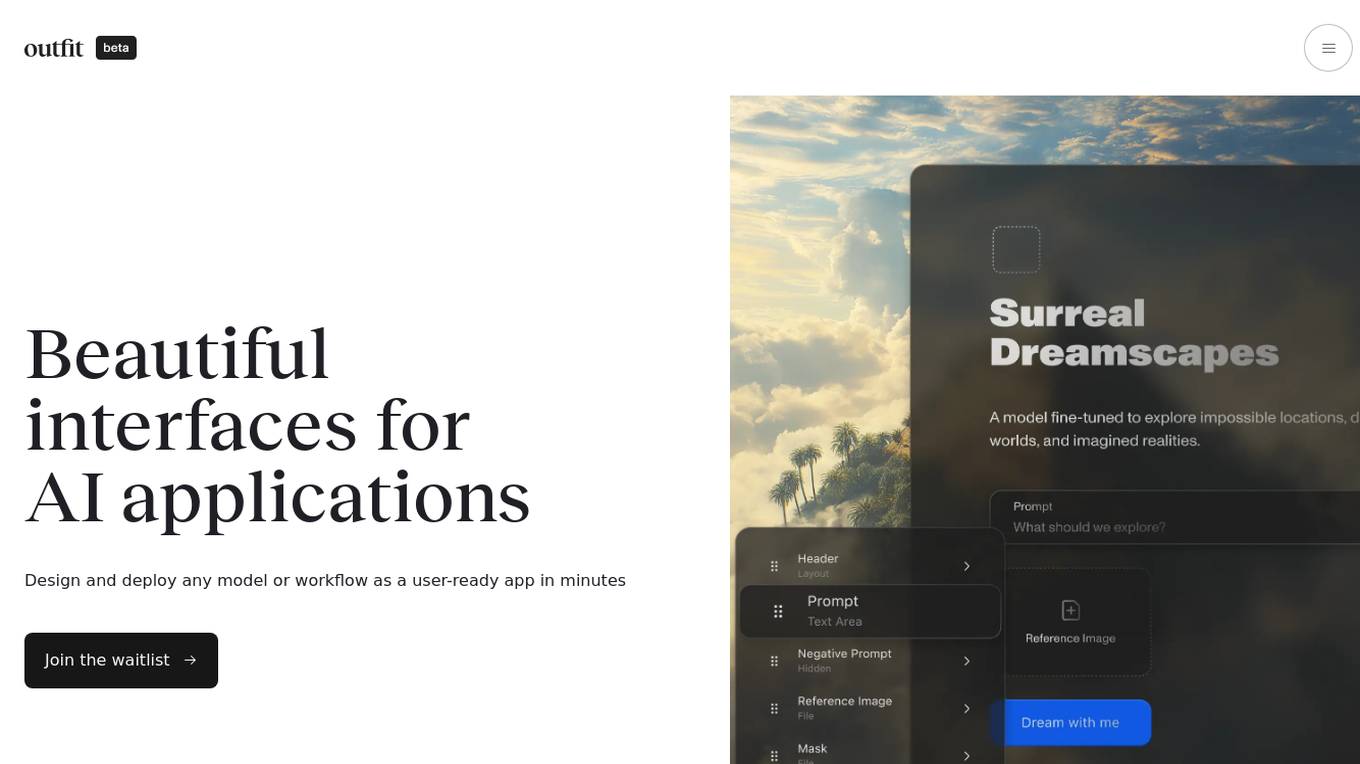
Outfit AI
Outfit AI is an AI tool that enables users to design and deploy AI models or workflows as user-ready applications in minutes. It allows users to create custom user interfaces for their AI-powered apps by dropping in an API key from Replicate or Hugging Face. With Outfit AI, users can have creative control over the design of their apps, build complex workflows without any code, and optimize prompts for better performance. The tool aims to help users launch their models faster, save time, and enhance their AI applications with a built-in product copilot.
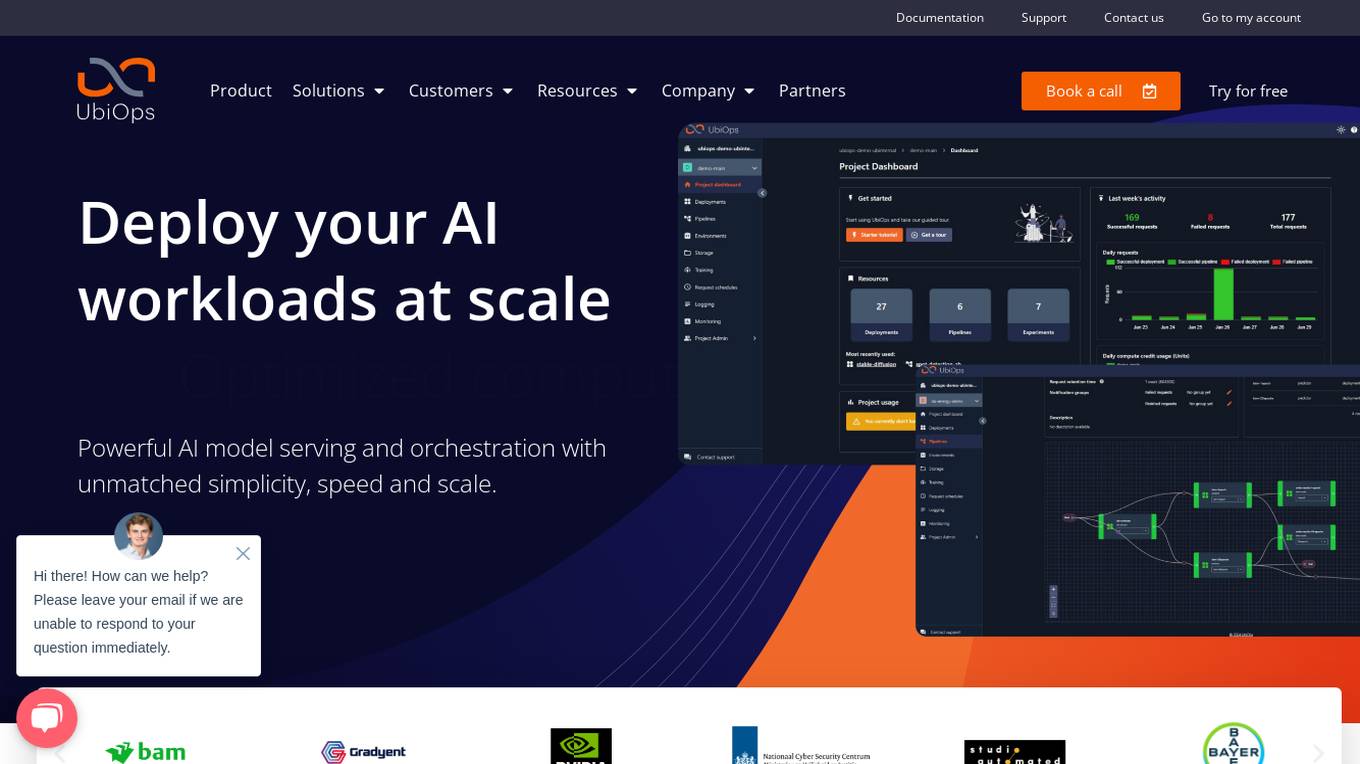
UbiOps
UbiOps is an AI infrastructure platform that helps teams quickly run their AI & ML workloads as reliable and secure microservices. It offers powerful AI model serving and orchestration with unmatched simplicity, speed, and scale. UbiOps allows users to deploy models and functions in minutes, manage AI workloads from a single control plane, integrate easily with tools like PyTorch and TensorFlow, and ensure security and compliance by design. The platform supports hybrid and multi-cloud workload orchestration, rapid adaptive scaling, and modular applications with unique workflow management system.
Baseten
Baseten is a machine learning infrastructure that provides a unified platform for data scientists and engineers to build, train, and deploy machine learning models. It offers a range of features to simplify the ML lifecycle, including data preparation, model training, and deployment. Baseten also provides a marketplace of pre-built models and components that can be used to accelerate the development of ML applications.

Wallaroo.AI
Wallaroo.AI is an AI inference platform that offers production-grade AI inference microservices optimized on OpenVINO for cloud and Edge AI application deployments on CPUs and GPUs. It provides hassle-free AI inferencing for any model, any hardware, anywhere, with ultrafast turnkey inference microservices. The platform enables users to deploy, manage, observe, and scale AI models effortlessly, reducing deployment costs and time-to-value significantly.
Groq
Groq is a fast AI inference tool that offers GroqCloud™ Platform and GroqRack™ Cluster for developers to build and deploy AI models with ultra-low-latency inference. It provides instant intelligence for openly-available models like Llama 3.1 and is known for its speed and compatibility with other AI providers. Groq powers leading openly-available AI models and has gained recognition in the AI chip industry. The tool has received significant funding and valuation, positioning itself as a strong challenger to established players like Nvidia.
Domino Data Lab
Domino Data Lab is an enterprise AI platform that enables users to build, deploy, and manage AI models across any environment. It fosters collaboration, establishes best practices, and ensures governance while reducing costs. The platform provides access to a broad ecosystem of open source and commercial tools, and infrastructure, allowing users to accelerate and scale AI impact. Domino serves as a central hub for AI operations and knowledge, offering integrated workflows, automation, and hybrid multicloud capabilities. It helps users optimize compute utilization, enforce compliance, and centralize knowledge across teams.
Arcee AI
Arcee AI is a platform that offers a cost-effective, secure, end-to-end solution for building and deploying Small Language Models (SLMs). It allows users to merge and train custom language models by leveraging open source models and their own data. The platform is known for its Model Merging technique, which combines the power of pre-trained Large Language Models (LLMs) with user-specific data to create high-performing models across various industries.
Unsloth
Unsloth is an AI tool designed to make finetuning large language models like Llama-3, Mistral, Phi-3, and Gemma 2x faster, use 70% less memory, and with no degradation in accuracy. The tool provides documentation to help users navigate through training their custom models, covering essentials such as installing and updating Unsloth, creating datasets, running, and deploying models. Users can also integrate third-party tools and utilize platforms like Google Colab.
Together AI
Together AI is an AI Acceleration Cloud platform that offers fast inference, fine-tuning, and training services. It provides self-service NVIDIA GPUs, model deployment on custom hardware, AI chat app, code execution sandbox, and tools to find the right model for specific use cases. The platform also includes a model library with open-source models, documentation for developers, and resources for advancing open-source AI. Together AI enables users to leverage pre-trained models, fine-tune them, or build custom models from scratch, catering to various generative AI needs.
FuriosaAI
FuriosaAI is an AI application that offers Hardware RNGD for LLM and Multimodality, as well as WARBOY for Computer Vision. It provides a comprehensive developer experience through the Furiosa SDK, Model Zoo, and Dev Support. The application focuses on efficient AI inference, high-performance LLM and multimodal deployment capabilities, and sustainable mass adoption of AI. FuriosaAI features the Tensor Contraction Processor architecture, software for streamlined LLM deployment, and a robust ecosystem support. It aims to deliver powerful and efficient deep learning acceleration while ensuring future-proof programmability and efficiency.

SuperAnnotate
SuperAnnotate is an AI data platform that simplifies and accelerates model-building by unifying the AI pipeline. It enables users to create, curate, and evaluate datasets efficiently, leading to the development of better models faster. The platform offers features like connecting any data source, building customizable UIs, creating high-quality datasets, evaluating models, and deploying models seamlessly. SuperAnnotate ensures global security and privacy measures for data protection.
Striveworks
Striveworks is an AI application that offers a Machine Learning Operations Platform designed to help organizations build, deploy, maintain, monitor, and audit machine learning models efficiently. It provides features such as rapid model deployment, data and model auditability, low-code interface, flexible deployment options, and operationalizing AI data science with real returns. Striveworks aims to accelerate the ML lifecycle, save time and money in model creation, and enable non-experts to leverage AI for data-driven decisions.
Qualcomm AI Hub
Qualcomm AI Hub is a platform that allows users to run AI models on Snapdragon® 8 Elite devices. It provides a collaborative ecosystem for model makers, cloud providers, runtime, and SDK partners to deploy on-device AI solutions quickly and efficiently. Users can bring their own models, optimize for deployment, and access a variety of AI services and resources. The platform caters to various industries such as mobile, automotive, and IoT, offering a range of models and services for edge computing.
ClearML
ClearML is an open-source, end-to-end platform for continuous machine learning (ML). It provides a unified platform for data management, experiment tracking, model training, deployment, and monitoring. ClearML is designed to make it easy for teams to collaborate on ML projects and to ensure that models are deployed and maintained in a reliable and scalable way.
JFrog ML
JFrog ML is an AI platform designed to streamline AI development from prototype to production. It offers a unified MLOps platform to build, train, deploy, and manage AI workflows at scale. With features like Feature Store, LLMOps, and model monitoring, JFrog ML empowers AI teams to collaborate efficiently and optimize AI & ML models in production.
Comet ML
Comet ML is a machine learning platform that integrates with your existing infrastructure and tools so you can manage, visualize, and optimize models—from training runs to production monitoring.
ConsoleX
ConsoleX is an advanced AI tool that offers a wide range of functionalities to unlock infinite possibilities in the field of artificial intelligence. It provides users with a powerful platform to develop, test, and deploy AI models with ease. With cutting-edge features and intuitive interface, ConsoleX is designed to cater to the needs of both beginners and experts in the AI domain. Whether you are a data scientist, researcher, or developer, ConsoleX empowers you to explore the full potential of AI technology and drive innovation in your projects.
Comet ML
Comet ML is a machine learning platform that integrates with your existing infrastructure and tools so you can manage, visualize, and optimize models—from training runs to production monitoring.
8 - Open Source AI Tools

vllm
vLLM is a fast and easy-to-use library for LLM inference and serving. It is designed to be efficient, flexible, and easy to use. vLLM can be used to serve a variety of LLM models, including Hugging Face models. It supports a variety of decoding algorithms, including parallel sampling, beam search, and more. vLLM also supports tensor parallelism for distributed inference and streaming outputs. It is open-source and available on GitHub.

bce-qianfan-sdk
The Qianfan SDK provides best practices for large model toolchains, allowing AI workflows and AI-native applications to access the Qianfan large model platform elegantly and conveniently. The core capabilities of the SDK include three parts: large model reasoning, large model training, and general and extension: * `Large model reasoning`: Implements interface encapsulation for reasoning of Yuyan (ERNIE-Bot) series, open source large models, etc., supporting dialogue, completion, Embedding, etc. * `Large model training`: Based on platform capabilities, it supports end-to-end large model training process, including training data, fine-tuning/pre-training, and model services. * `General and extension`: General capabilities include common AI development tools such as Prompt/Debug/Client. The extension capability is based on the characteristics of Qianfan to adapt to common middleware frameworks.

dstack
Dstack is an open-source orchestration engine for running AI workloads in any cloud. It supports a wide range of cloud providers (such as AWS, GCP, Azure, Lambda, TensorDock, Vast.ai, CUDO, RunPod, etc.) as well as on-premises infrastructure. With Dstack, you can easily set up and manage dev environments, tasks, services, and pools for your AI workloads.

tiny-llm-zh
Tiny LLM zh is a project aimed at building a small-parameter Chinese language large model for quick entry into learning large model-related knowledge. The project implements a two-stage training process for large models and subsequent human alignment, including tokenization, pre-training, instruction fine-tuning, human alignment, evaluation, and deployment. It is deployed on ModeScope Tiny LLM website and features open access to all data and code, including pre-training data and tokenizer. The project trains a tokenizer using 10GB of Chinese encyclopedia text to build a Tiny LLM vocabulary. It supports training with Transformers deepspeed, multiple machine and card support, and Zero optimization techniques. The project has three main branches: llama2_torch, main tiny_llm, and tiny_llm_moe, each with specific modifications and features.
examples
Cerebrium's official examples repository provides practical, ready-to-use examples for building Machine Learning / AI applications on the platform. The repository contains self-contained projects demonstrating specific use cases with detailed instructions on deployment. Examples cover a wide range of categories such as getting started, advanced concepts, endpoints, integrations, large language models, voice, image & video, migrations, application demos, batching, and Python apps.
HuaTuoAI
HuaTuoAI is an artificial intelligence image classification system specifically designed for traditional Chinese medicine. It utilizes deep learning techniques, such as Convolutional Neural Networks (CNN), to accurately classify Chinese herbs and ingredients based on input images. The project aims to unlock the secrets of plants, depict the unknown realm of Chinese medicine using technology and intelligence, and perpetuate ancient cultural heritage.

vector-inference
This repository provides an easy-to-use solution for running inference servers on Slurm-managed computing clusters using vLLM. All scripts in this repository run natively on the Vector Institute cluster environment. Users can deploy models as Slurm jobs, check server status and performance metrics, and shut down models. The repository also supports launching custom models with specific configurations. Additionally, users can send inference requests and set up an SSH tunnel to run inference from a local device.

mini-sglang
Mini-SGLang is a lightweight yet high-performance inference framework for Large Language Models. With a compact codebase of ~5,000 lines of Python, it serves as both a capable inference engine and a transparent reference for researchers and developers. It achieves state-of-the-art throughput and latency with advanced optimizations such as Radix Cache, Chunked Prefill, Overlap Scheduling, Tensor Parallelism, and Optimized Kernels integrating FlashAttention and FlashInfer for maximum efficiency. Mini-SGLang is designed to demystify the complexities of modern LLM serving systems, providing a clean, modular, and fully type-annotated codebase that is easy to understand and modify.
20 - OpenAI Gpts



Instructor GCP ML
Formador para la certificación de ML Engineer en GCP, con respuestas y explicaciones detalladas.

HuggingFace Helper
A witty yet succinct guide for HuggingFace, offering technical assistance on using the platform - based on their Learning Hub

TensorFlow Oracle
I'm an expert in TensorFlow, providing detailed, accurate guidance for all skill levels.
ML Engineer GPT
I'm a Python and PyTorch expert with knowledge of ML infrastructure requirements ready to help you build and scale your ML projects.



![[latest] FastAPI GPT Screenshot](/screenshots_gpts/g-BhYCAfVXk.jpg)
[latest] FastAPI GPT
Up-to-date FastAPI coding assistant with knowledge of the latest version. Part of the [latest] GPTs family.
GPT Designer
A creative aide for designing new GPT models, skilled in ideation and prompting.