
ParseHub
支持 AI 总结的社交媒体聚合解析器 Social Media Aggregation Analyzer Supported by AI Summarization
Stars: 55
ParseHub is a social media aggregation analyzer supported by AI summarization. It supports various platforms such as Twitter, Instagram, Weibo, Bilibili, and more for analyzing videos and text content. Users can utilize ParseHub to summarize content using the 'whisper-1' model and access a Telegram bot developed based on the project. The tool provides functionalities for parsing and summarizing social media content, making it a valuable resource for extracting insights and information from diverse social media platforms.
README:
支持AI总结的社交媒体聚合解析器
Social Media Aggregation Analyzer Supported by AI Summarization
视频总结使用
whisper-1模型
基于该项目开发的 Tg Bot:
@ParsehuBot | https://github.com/z-mio/parse_hub_bot
支持的平台:
Twitter 视频|图文
Instagram 视频|图文
微博 视频|图文
贴吧 视频|图文
小红书 视频|图文
Youtube 视频|音乐
Facebook 视频
Bilibili 视频|动态
抖音|TikTok 视频|图文
微信公众号 图文
最右 视频|图文
酷安 视频|图文
皮皮虾 视频|图文
快手 视频
Threads 视频|图文
......
pip install parsehub
[!IMPORTANT]
注意
Linux用户在导入skia-python包时可能会遇到以下报错
libGL.so.1: cannot open shared object file: No such file or directoryWindows用户在缺少Microsoft Visual C++ Runtime时可能会遇到以下报错
ImportError: DLL load failed while importing skia: The specified module could not be found.ubuntu用户
# Ubuntu 22 安装 apt install libgl1-mesa-glx # Ubuntu 24 安装 apt install libgl1 libglx-mesa0ArchLinux用户
pacman -S libglcentos用户
yum install mesa-libGL -yWindows用户
from parsehub import ParseHub
from parsehub.config import ParseConfig, DownloadConfig
import asyncio
async def main():
ph = ParseHub(config=ParseConfig())
result = await ph.parse('https://twitter.com/aobuta_anime/status/1827284717848424696')
print(result)
sr = await result.summary(download_config=DownloadConfig())
print(sr.content)
if __name__ == '__main__':
asyncio.run(main())| 名称 | 描述 | 默认值 |
|---|---|---|
PROVIDER |
模型提供商, 支持: openai
|
openai |
API_KEY |
API Key | |
BASE_URL |
API 端点 | https://api.openai.com/v1 |
MODEL |
AI总结使用的模型 | gpt-4o-mini |
PROMPT |
AI总结提示词 | Use "Simplified Chinese" to summarize the key points of articles and video subtitles. Summarize it in one sentence at the beginning and then write out n key points. |
TRANSCRIPTIONS_PROVIDER |
语音转文本模型提供商 支持: openai,azure,fast_whisper
|
|
TRANSCRIPTIONS_BASE_URL |
语音转文本 API端点 | |
TRANSCRIPTIONS_API_KEY |
语音转文本 API密钥 |
- 为什么需要登录?
- 部分平台的内容有限制,需要登录才能查看。
通过 Cookie 登录:
from parsehub.config import ParseConfig
pc = ParseConfig(cookie="从浏览器中获取的cookie")目前支持的平台:
twitterinstagramkuaishoubilibiliyoutube
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ParseHub
Similar Open Source Tools
ParseHub
ParseHub is a social media aggregation analyzer supported by AI summarization. It supports various platforms such as Twitter, Instagram, Weibo, Bilibili, and more for analyzing videos and text content. Users can utilize ParseHub to summarize content using the 'whisper-1' model and access a Telegram bot developed based on the project. The tool provides functionalities for parsing and summarizing social media content, making it a valuable resource for extracting insights and information from diverse social media platforms.
parse_hub_bot
ParseHubBot is a Telegram aggregation analysis Bot that supports AI summary and inline mode. It currently supports various platforms like Douyin, Bilibili, YouTube, TikTok, Twitter, Baidu Tieba, Facebook, Weibo, Instagram, etc. Users can deploy the bot by modifying environment variables and platform configurations. Deployment can be done using Docker or by running the bot directly. The bot can be started by running a script in the project root directory. Users can interact with the bot by sending share links or using the command '/jx' for regular use, and by mentioning the bot username followed by a link for inline use.
kubectl-mcp-server
Control your entire Kubernetes infrastructure through natural language conversations with AI. Talk to your clusters like you talk to a DevOps expert. Debug crashed pods, optimize costs, deploy applications, audit security, manage Helm charts, and visualize dashboards—all through natural language. The tool provides 253 powerful tools, 8 workflow prompts, 8 data resources, and works with all major AI assistants. It offers AI-powered diagnostics, built-in cost optimization, enterprise-ready features, zero learning curve, universal compatibility, visual insights, and production-grade deployment options. From debugging crashed pods to optimizing cluster costs, kubectl-mcp-server is your AI-powered DevOps companion.
fittencode.nvim
Fitten Code AI Programming Assistant for Neovim provides fast completion using AI, asynchronous I/O, and support for various actions like document code, edit code, explain code, find bugs, generate unit test, implement features, optimize code, refactor code, start chat, and more. It offers features like accepting suggestions with Tab, accepting line with Ctrl + Down, accepting word with Ctrl + Right, undoing accepted text, automatic scrolling, and multiple HTTP/REST backends. It can run as a coc.nvim source or nvim-cmp source.
code-cli
Autohand Code CLI is an autonomous coding agent in CLI form that uses the ReAct pattern to understand, plan, and execute code changes. It is designed for seamless coding experience without context switching or copy-pasting. The tool is fast, intuitive, and extensible with modular skills. It can be used to automate coding tasks, enforce code quality, and speed up development. Autohand can be integrated into team workflows and CI/CD pipelines to enhance productivity and efficiency.
snapai
SnapAI is a tool that leverages AI-powered image generation models to create professional app icons for React Native & Expo developers. It offers lightning-fast icon generation, iOS optimized icons, privacy-first approach with local API key storage, multiple sizes and HD quality icons. The tool is developer-friendly with a simple CLI for easy integration into CI/CD pipelines.
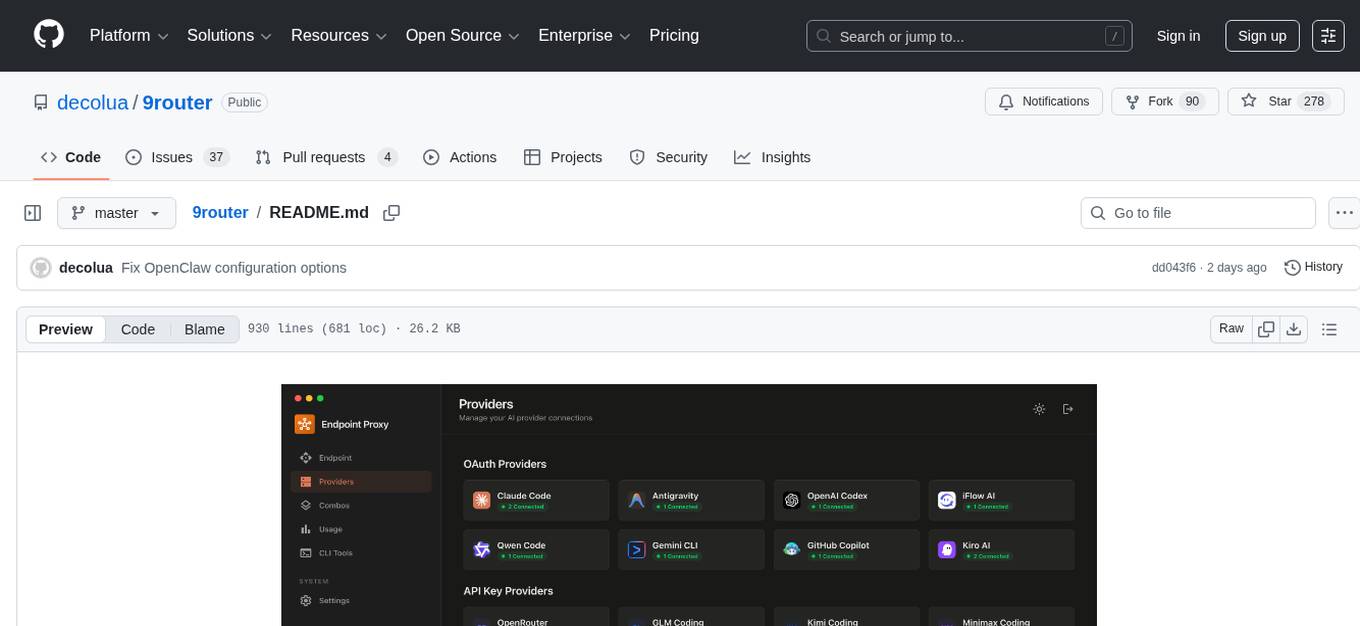
9router
9Router is a free AI router tool designed to help developers maximize their AI subscriptions, auto-route to free and cheap AI models with smart fallback, and avoid hitting limits and wasting money. It offers features like real-time quota tracking, format translation between OpenAI, Claude, and Gemini, multi-account support, auto token refresh, custom model combinations, request logging, cloud sync, usage analytics, and flexible deployment options. The tool supports various providers like Claude Code, Codex, Gemini CLI, GitHub Copilot, GLM, MiniMax, iFlow, Qwen, and Kiro, and allows users to create combos for different scenarios. Users can connect to the tool via CLI tools like Cursor, Claude Code, Codex, OpenClaw, and Cline, and deploy it on VPS, Docker, or Cloudflare Workers.

onnxruntime-server
ONNX Runtime Server is a server that provides TCP and HTTP/HTTPS REST APIs for ONNX inference. It aims to offer simple, high-performance ML inference and a good developer experience. Users can provide inference APIs for ONNX models without writing additional code by placing the models in the directory structure. Each session can choose between CPU or CUDA, analyze input/output, and provide Swagger API documentation for easy testing. Ready-to-run Docker images are available, making it convenient to deploy the server.
google_workspace_mcp
The Google Workspace MCP Server is a production-ready server that integrates major Google Workspace services with AI assistants. It supports single-user and multi-user authentication via OAuth 2.1, making it a powerful backend for custom applications. Built with FastMCP for optimal performance, it features advanced authentication handling, service caching, and streamlined development patterns. The server provides full natural language control over Google Calendar, Drive, Gmail, Docs, Sheets, Slides, Forms, Tasks, and Chat through all MCP clients, AI assistants, and developer tools. It supports free Google accounts and Google Workspace plans with expanded app options like Chat & Spaces. The server also offers private cloud instance options.
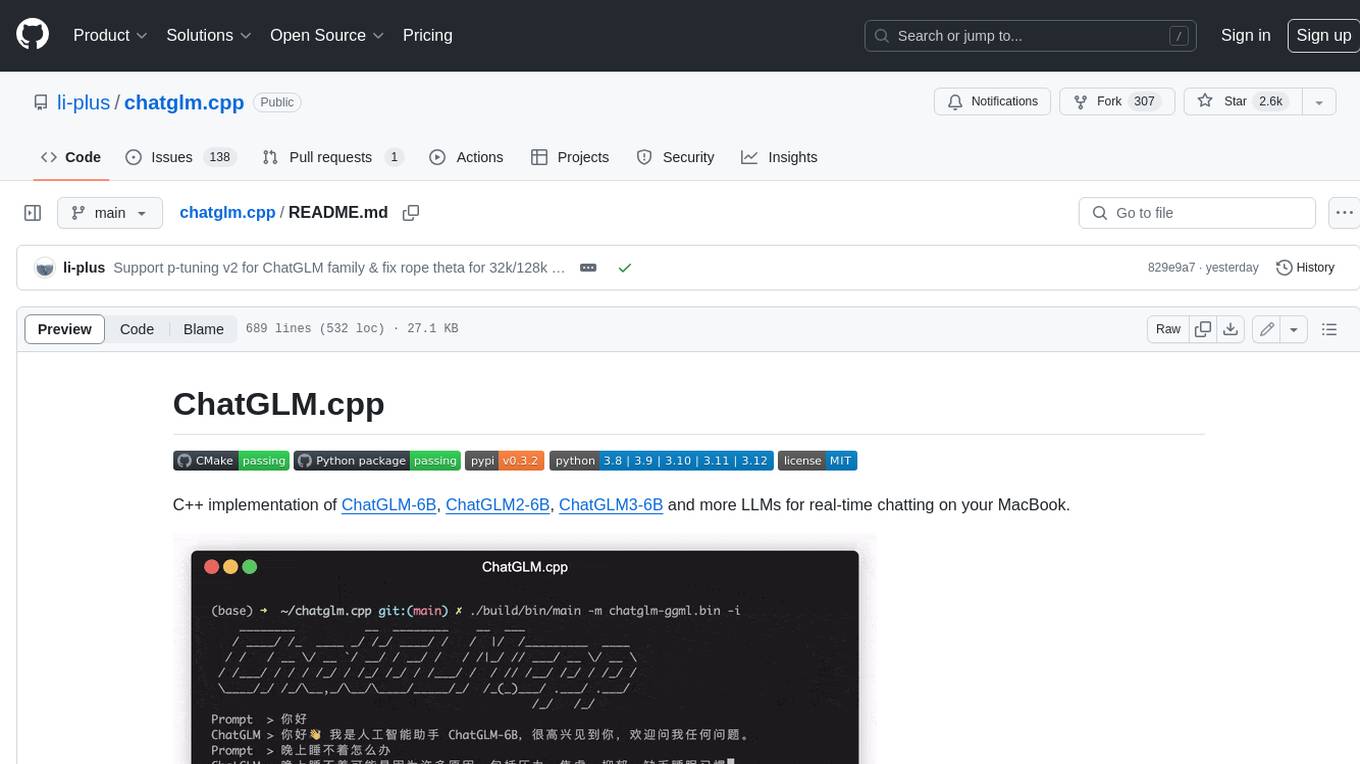
chatglm.cpp
ChatGLM.cpp is a C++ implementation of ChatGLM-6B, ChatGLM2-6B, ChatGLM3-6B and more LLMs for real-time chatting on your MacBook. It is based on ggml, working in the same way as llama.cpp. ChatGLM.cpp features accelerated memory-efficient CPU inference with int4/int8 quantization, optimized KV cache and parallel computing. It also supports P-Tuning v2 and LoRA finetuned models, streaming generation with typewriter effect, Python binding, web demo, api servers and more possibilities.
worker-vllm
The worker-vLLM repository provides a serverless endpoint for deploying OpenAI-compatible vLLM models with blazing-fast performance. It supports deploying various model architectures, such as Aquila, Baichuan, BLOOM, ChatGLM, Command-R, DBRX, DeciLM, Falcon, Gemma, GPT-2, GPT BigCode, GPT-J, GPT-NeoX, InternLM, Jais, LLaMA, MiniCPM, Mistral, Mixtral, MPT, OLMo, OPT, Orion, Phi, Phi-3, Qwen, Qwen2, Qwen2MoE, StableLM, Starcoder2, Xverse, and Yi. Users can deploy models using pre-built Docker images or build custom images with specified arguments. The repository also supports OpenAI compatibility for chat completions, completions, and models, with customizable input parameters. Users can modify their OpenAI codebase to use the deployed vLLM worker and access a list of available models for deployment.

llm.nvim
llm.nvim is a universal plugin for a large language model (LLM) designed to enable users to interact with LLM within neovim. Users can customize various LLMs such as gpt, glm, kimi, and local LLM. The plugin provides tools for optimizing code, comparing code, translating text, and more. It also supports integration with free models from Cloudflare, Github models, siliconflow, and others. Users can customize tools, chat with LLM, quickly translate text, and explain code snippets. The plugin offers a flexible window interface for easy interaction and customization.
atlas-mcp-server
ATLAS (Adaptive Task & Logic Automation System) is a high-performance Model Context Protocol server designed for LLMs to manage complex task hierarchies. Built with TypeScript, it features ACID-compliant storage, efficient task tracking, and intelligent template management. ATLAS provides LLM Agents task management through a clean, flexible tool interface. The server implements the Model Context Protocol (MCP) for standardized communication between LLMs and external systems, offering hierarchical task organization, task state management, smart templates, enterprise features, and performance optimization.
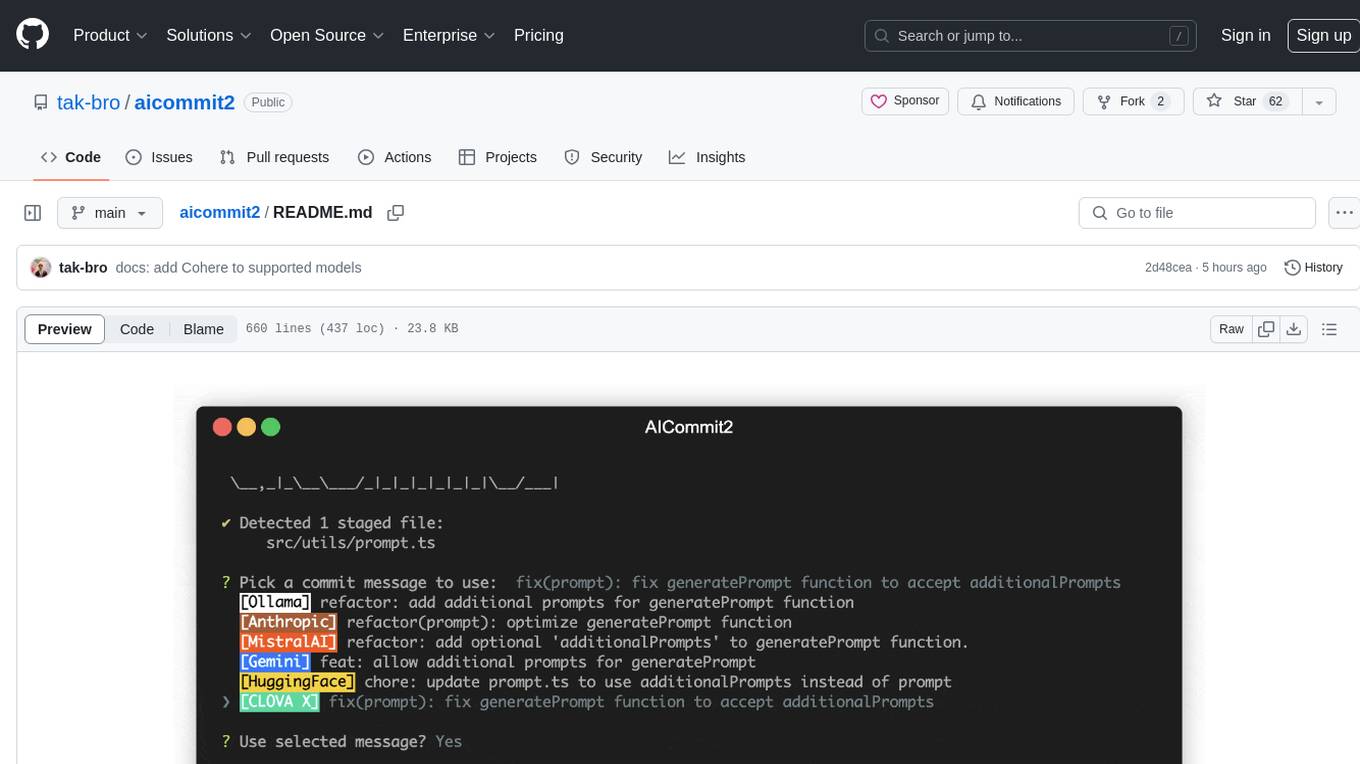
aicommit2
AICommit2 is a Reactive CLI tool that streamlines interactions with various AI providers such as OpenAI, Anthropic Claude, Gemini, Mistral AI, Cohere, and unofficial providers like Huggingface and Clova X. Users can request multiple AI simultaneously to generate git commit messages without waiting for all AI responses. The tool runs 'git diff' to grab code changes, sends them to configured AI, and returns the AI-generated commit message. Users can set API keys or Cookies for different providers and configure options like locale, generate number of messages, commit type, proxy, timeout, max-length, and more. AICommit2 can be used both locally with Ollama and remotely with supported providers, offering flexibility and efficiency in generating commit messages.
moonpalace
MoonPalace is a debugging tool for API provided by Moonshot AI. It supports all platforms (Mac, Windows, Linux) and is simple to use by replacing 'base_url' with 'http://localhost:9988'. It captures complete requests, including 'accident scenes' during network errors, and allows quick retrieval and viewing of request information using 'request_id' and 'chatcmpl_id'. It also enables one-click export of BadCase structured reporting data to help improve Kimi model capabilities. MoonPalace is recommended for use as an API 'supplier' during code writing and debugging stages to quickly identify and locate various issues related to API calls and code writing processes, and to export request details for submission to Moonshot AI to improve Kimi model.
ruler
Ruler is a tool designed to centralize AI coding assistant instructions, providing a single source of truth for managing instructions across multiple AI coding tools. It helps in avoiding inconsistent guidance, duplicated effort, context drift, onboarding friction, and complex project structures by automatically distributing instructions to the right configuration files. With support for nested rule loading, Ruler can handle complex project structures with context-specific instructions for different components. It offers features like centralised rule management, nested rule loading, automatic distribution, targeted agent configuration, MCP server propagation, .gitignore automation, and a simple CLI for easy configuration management.
For similar tasks

Awesome-LLMs-for-Video-Understanding
Awesome-LLMs-for-Video-Understanding is a repository dedicated to exploring Video Understanding with Large Language Models. It provides a comprehensive survey of the field, covering models, pretraining, instruction tuning, and hybrid methods. The repository also includes information on tasks, datasets, and benchmarks related to video understanding. Contributors are encouraged to add new papers, projects, and materials to enhance the repository.
Video-MME
Video-MME is the first-ever comprehensive evaluation benchmark of Multi-modal Large Language Models (MLLMs) in Video Analysis. It assesses the capabilities of MLLMs in processing video data, covering a wide range of visual domains, temporal durations, and data modalities. The dataset comprises 900 videos with 256 hours and 2,700 human-annotated question-answer pairs. It distinguishes itself through features like duration variety, diversity in video types, breadth in data modalities, and quality in annotations.

ControlLLM
ControlLLM is a framework that empowers large language models to leverage multi-modal tools for solving complex real-world tasks. It addresses challenges like ambiguous user prompts, inaccurate tool selection, and inefficient tool scheduling by utilizing a task decomposer, a Thoughts-on-Graph paradigm, and an execution engine with a rich toolbox. The framework excels in tasks involving image, audio, and video processing, showcasing superior accuracy, efficiency, and versatility compared to existing methods.

gen-cv
This repository is a rich resource offering examples of synthetic image generation, manipulation, and reasoning using Azure Machine Learning, Computer Vision, OpenAI, and open-source frameworks like Stable Diffusion. It provides practical insights into image processing applications, including content generation, video analysis, avatar creation, and image manipulation with various tools and APIs.

outspeed
Outspeed is a PyTorch-inspired SDK for building real-time AI applications on voice and video input. It offers low-latency processing of streaming audio and video, an intuitive API familiar to PyTorch users, flexible integration of custom AI models, and tools for data preprocessing and model deployment. Ideal for developing voice assistants, video analytics, and other real-time AI applications processing audio-visual data.
starter-applets
This repository contains the source code for Google AI Studio's starter apps — a collection of small apps that demonstrate how Gemini can be used to create interactive experiences. These apps are built to run inside AI Studio, but the versions included here can run standalone using the Gemini API. The apps cover spatial understanding, video analysis, and map exploration, showcasing Gemini's capabilities in these areas. Developers can use these starter applets to kickstart their projects and learn how to leverage Gemini for spatial reasoning and interactive experiences.

TRACE
TRACE is a temporal grounding video model that utilizes causal event modeling to capture videos' inherent structure. It presents a task-interleaved video LLM model tailored for sequential encoding/decoding of timestamps, salient scores, and textual captions. The project includes various model checkpoints for different stages and fine-tuning on specific datasets. It provides evaluation codes for different tasks like VTG, MVBench, and VideoMME. The repository also offers annotation files and links to raw videos preparation projects. Users can train the model on different tasks and evaluate the performance based on metrics like CIDER, METEOR, SODA_c, F1, mAP, Hit@1, etc. TRACE has been enhanced with trace-retrieval and trace-uni models, showing improved performance on dense video captioning and general video understanding tasks.
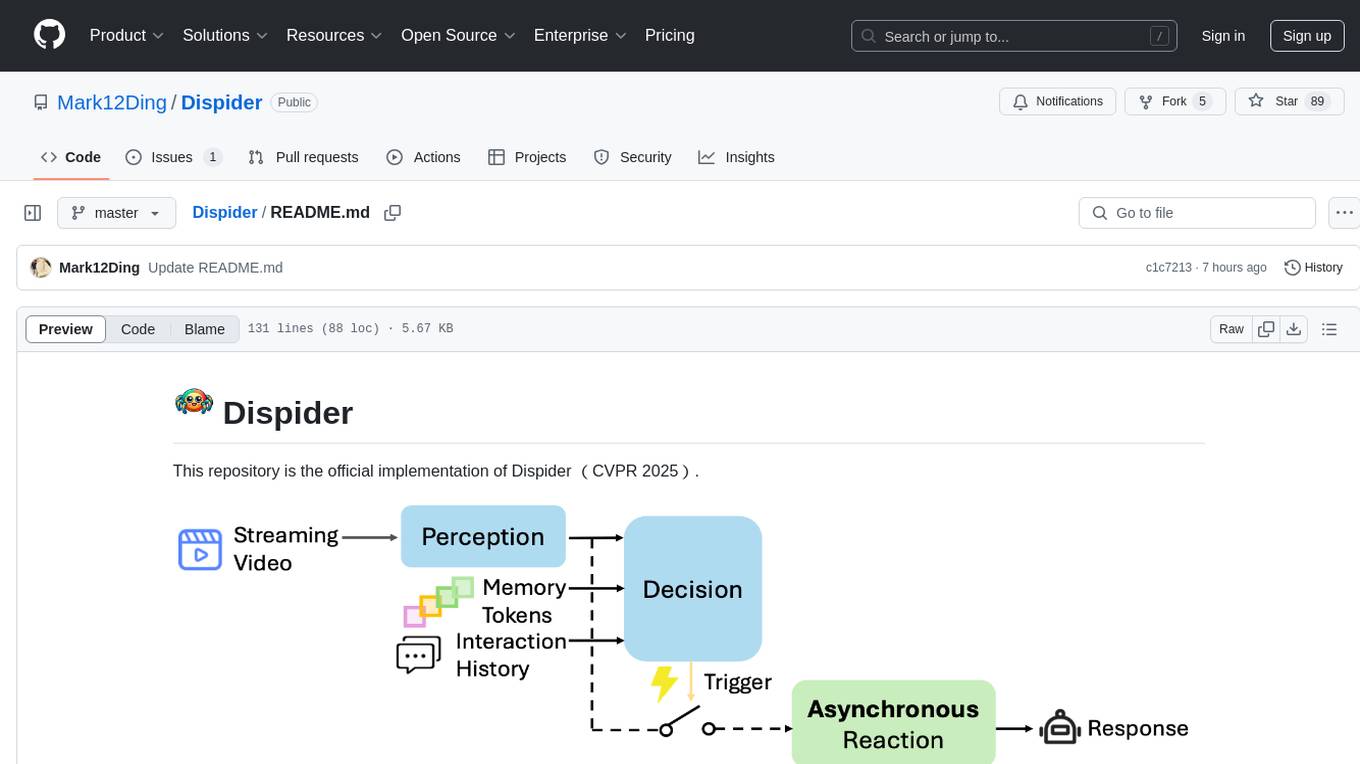
Dispider
Dispider is an implementation enabling real-time interactions with streaming videos, providing continuous feedback in live scenarios. It separates perception, decision-making, and reaction into asynchronous modules, ensuring timely interactions. Dispider outperforms VideoLLM-online on benchmarks like StreamingBench and excels in temporal reasoning. The tool requires CUDA 11.8 and specific library versions for optimal performance.
For similar jobs

book
Podwise is an AI knowledge management app designed specifically for podcast listeners. With the Podwise platform, you only need to follow your favorite podcasts, such as "Hardcore Hackers". When a program is released, Podwise will use AI to transcribe, extract, summarize, and analyze the podcast content, helping you to break down the hard-core podcast knowledge. At the same time, it is connected to platforms such as Notion, Obsidian, Logseq, and Readwise, embedded in your knowledge management workflow, and integrated with content from other channels including news, newsletters, and blogs, helping you to improve your second brain 🧠.

extractor
Extractor is an AI-powered data extraction library for Laravel that leverages OpenAI's capabilities to effortlessly extract structured data from various sources, including images, PDFs, and emails. It features a convenient wrapper around OpenAI Chat and Completion endpoints, supports multiple input formats, includes a flexible Field Extractor for arbitrary data extraction, and integrates with Textract for OCR functionality. Extractor utilizes JSON Mode from the latest GPT-3.5 and GPT-4 models, providing accurate and efficient data extraction.

Scrapegraph-ai
ScrapeGraphAI is a Python library that uses Large Language Models (LLMs) and direct graph logic to create web scraping pipelines for websites, documents, and XML files. It allows users to extract specific information from web pages by providing a prompt describing the desired data. ScrapeGraphAI supports various LLMs, including Ollama, OpenAI, Gemini, and Docker, enabling users to choose the most suitable model for their needs. The library provides a user-friendly interface through its `SmartScraper` class, which simplifies the process of building and executing scraping pipelines. ScrapeGraphAI is open-source and available on GitHub, with extensive documentation and examples to guide users. It is particularly useful for researchers and data scientists who need to extract structured data from web pages for analysis and exploration.

databerry
Chaindesk is a no-code platform that allows users to easily set up a semantic search system for personal data without technical knowledge. It supports loading data from various sources such as raw text, web pages, files (Word, Excel, PowerPoint, PDF, Markdown, Plain Text), and upcoming support for web sites, Notion, and Airtable. The platform offers a user-friendly interface for managing datastores, querying data via a secure API endpoint, and auto-generating ChatGPT Plugins for each datastore. Chaindesk utilizes a Vector Database (Qdrant), Openai's text-embedding-ada-002 for embeddings, and has a chunk size of 1024 tokens. The technology stack includes Next.js, Joy UI, LangchainJS, PostgreSQL, Prisma, and Qdrant, inspired by the ChatGPT Retrieval Plugin.

auto-news
Auto-News is an automatic news aggregator tool that utilizes Large Language Models (LLM) to pull information from various sources such as Tweets, RSS feeds, YouTube videos, web articles, Reddit, and journal notes. The tool aims to help users efficiently read and filter content based on personal interests, providing a unified reading experience and organizing information effectively. It features feed aggregation with summarization, transcript generation for videos and articles, noise reduction, task organization, and deep dive topic exploration. The tool supports multiple LLM backends, offers weekly top-k aggregations, and can be deployed on Linux/MacOS using docker-compose or Kubernetes.

SemanticFinder
SemanticFinder is a frontend-only live semantic search tool that calculates embeddings and cosine similarity client-side using transformers.js and SOTA embedding models from Huggingface. It allows users to search through large texts like books with pre-indexed examples, customize search parameters, and offers data privacy by keeping input text in the browser. The tool can be used for basic search tasks, analyzing texts for recurring themes, and has potential integrations with various applications like wikis, chat apps, and personal history search. It also provides options for building browser extensions and future ideas for further enhancements and integrations.

1filellm
1filellm is a command-line data aggregation tool designed for LLM ingestion. It aggregates and preprocesses data from various sources into a single text file, facilitating the creation of information-dense prompts for large language models. The tool supports automatic source type detection, handling of multiple file formats, web crawling functionality, integration with Sci-Hub for research paper downloads, text preprocessing, and token count reporting. Users can input local files, directories, GitHub repositories, pull requests, issues, ArXiv papers, YouTube transcripts, web pages, Sci-Hub papers via DOI or PMID. The tool provides uncompressed and compressed text outputs, with the uncompressed text automatically copied to the clipboard for easy pasting into LLMs.

Agently-Daily-News-Collector
Agently Daily News Collector is an open-source project showcasing a workflow powered by the Agent ly AI application development framework. It allows users to generate news collections on various topics by inputting the field topic. The AI agents automatically perform the necessary tasks to generate a high-quality news collection saved in a markdown file. Users can edit settings in the YAML file, install Python and required packages, input their topic idea, and wait for the news collection to be generated. The process involves tasks like outlining, searching, summarizing, and preparing column data. The project dependencies include Agently AI Development Framework, duckduckgo-search, BeautifulSoup4, and PyYAM.