
tt-xla
Repo for AI Compiler team. The intended purpose of this repo is for implementation of a PJRT device.
Stars: 51

TT-XLA is a repository that enables running PyTorch and JAX models on Tenstorrent's AI hardware. It serves as a backend integration between the JAX ecosystem and Tenstorrent's ML accelerators using the PJRT (Portable JAX Runtime) interface. It supports ingestion of PyTorch models through PyTorch/XLA and JAX models via jit compile, providing a StableHLO (SHLO) graph to TT-MLIR compiler.
README:
![]()
TT-XLA leverages a PJRT interface to integrate JAX (and in the future other frameworks), TT-MLIR and Tenstorrent hardware. It supports ingestion of PyTorch models through PyTorch/XLA and JAX models via jit compile, providing a StableHLO (SHLO) graph to TT-MLIR compiler.
The TT-XLA repository is primarily used to enable running PyTorch and JAX models on Tenstorrent's AI hardware. It's a backend integration between the JAX ecosystem and Tenstorrent's ML accelerators using the PJRT (Portable JAX Runtime) interface.
-
- TT-XLA is the primary frontend for running PyTorch and JAX models. It leverages a PJRT interface to integrate JAX (and in the future other frameworks), TT-MLIR, and Tenstorrent hardware. It supports ingestion of JAX models via jit compile, providing StableHLO (SHLO) graph to TT-MLIR compiler. TT-XLA can be used for single and multi-chip projects.
- See the TT-XLA docs pages for an overview and getting started guide.
-
- A TVM based graph compiler designed to optimize and transform computational graphs for deep learning models. Supports ingestion of ONNX, TensorFlow, PaddlePaddle and similar ML frameworks via TVM (TT-TVM). It also supports ingestion of PyTorch, however it is recommended that you use TT-XLA. TT-Forge-FE does not support multi-chip configurations; it is for single-chip projects only.
- See the TT-Forge-FE docs pages for an overview and getting started guide.
-
TT-Torch - (deprecated)
- A MLIR-native, open-source, PyTorch 2.X and torch-mlir based front-end. It provides stableHLO (SHLO) graphs to TT-MLIR. Supports ingestion of PyTorch models via PT2.X compile and ONNX models via torch-mlir (ONNX->SHLO)
- See the TT-Torch docs pages for an overview and getting started guide.
- TT-XLA - (single and multi-chip) For use with PyTorch, JAX, and TensorFlow
- TT-Forge-FE - (single chip only) For use with ONNX and PaddlePaddle, it also runs PyTorch, however it is recommended to use TT-XLA for PyTorch
- TT-MLIR - Open source compiler framework for compiling and optimizing machine learning models for Tenstorrent hardware
- TT-Metal - Low-level programming model, enabling kernel development for Tenstorrent hardware
- TT-TVM - A compiler stack for deep learning systems designed to close the gap between the productivity-focused deep learning frameworks, and the performance and efficiency-focused hardware backends
- TT-Torch - (Deprecated) Previously for use with PyTorch. It is recommended that you use TT-XLA for PyTorch.
This repo is a part of Tenstorrent’s bounty program. If you are interested in helping to improve tt-forge, please make sure to read the Tenstorrent Bounty Program Terms and Conditions before heading to the issues tab. Look for the issues that are tagged with both “bounty” and difficulty level!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for tt-xla
Similar Open Source Tools
tt-xla
TT-XLA is a repository that enables running PyTorch and JAX models on Tenstorrent's AI hardware. It serves as a backend integration between the JAX ecosystem and Tenstorrent's ML accelerators using the PJRT (Portable JAX Runtime) interface. It supports ingestion of PyTorch models through PyTorch/XLA and JAX models via jit compile, providing a StableHLO (SHLO) graph to TT-MLIR compiler.

kalavai-client
Kalavai is an open-source platform that transforms everyday devices into an AI supercomputer by aggregating resources from multiple machines. It facilitates matchmaking of resources for large AI projects, making AI hardware accessible and affordable. Users can create local and public pools, connect with the community's resources, and share computing power. The platform aims to be a management layer for research groups and organizations, enabling users to unlock the power of existing hardware without needing a devops team. Kalavai CLI tool helps manage both versions of the platform.
uccl
UCCL is a command-line utility tool designed to simplify the process of converting Unix-style file paths to Windows-style file paths and vice versa. It provides a convenient way for developers and system administrators to handle file path conversions without the need for manual adjustments. With UCCL, users can easily convert file paths between different operating systems, making it a valuable tool for cross-platform development and file management tasks.

gpt4all
GPT4All is an ecosystem to run powerful and customized large language models that work locally on consumer grade CPUs and any GPU. Note that your CPU needs to support AVX or AVX2 instructions. Learn more in the documentation. A GPT4All model is a 3GB - 8GB file that you can download and plug into the GPT4All open-source ecosystem software. Nomic AI supports and maintains this software ecosystem to enforce quality and security alongside spearheading the effort to allow any person or enterprise to easily train and deploy their own on-edge large language models.
AITemplate
AITemplate (AIT) is a Python framework that transforms deep neural networks into CUDA (NVIDIA GPU) / HIP (AMD GPU) C++ code for lightning-fast inference serving. It offers high performance close to roofline fp16 TensorCore (NVIDIA GPU) / MatrixCore (AMD GPU) performance on major models. AITemplate is unified, open, and flexible, supporting a comprehensive range of fusions for both GPU platforms. It provides excellent backward capability, horizontal fusion, vertical fusion, memory fusion, and works with or without PyTorch. FX2AIT is a tool that converts PyTorch models into AIT for fast inference serving, offering easy conversion and expanded support for models with unsupported operators.
rig
Rig is a Rust library designed for building scalable, modular, and user-friendly applications powered by large language models (LLMs). It provides full support for LLM completion and embedding workflows, offers simple yet powerful abstractions for LLM providers like OpenAI and Cohere, as well as vector stores such as MongoDB and in-memory storage. With Rig, users can easily integrate LLMs into their applications with minimal boilerplate code.

only_train_once
Only Train Once (OTO) is an automatic, architecture-agnostic DNN training and compression framework that allows users to train a general DNN from scratch or a pretrained checkpoint to achieve high performance and slimmer architecture simultaneously in a one-shot manner without fine-tuning. The framework includes features for automatic structured pruning and erasing operators, as well as hybrid structured sparse optimizers for efficient model compression. OTO provides tools for pruning zero-invariant group partitioning, constructing pruned models, and visualizing pruning and erasing dependency graphs. It supports the HESSO optimizer and offers a sanity check for compliance testing on various DNNs. The repository also includes publications, installation instructions, quick start guides, and a roadmap for future enhancements and collaborations.
Genesis
Genesis is a physics platform designed for general purpose Robotics/Embodied AI/Physical AI applications. It includes a universal physics engine, a lightweight, ultra-fast, pythonic, and user-friendly robotics simulation platform, a powerful and fast photo-realistic rendering system, and a generative data engine that transforms user-prompted natural language description into various modalities of data. It aims to lower the barrier to using physics simulations, unify state-of-the-art physics solvers, and minimize human effort in collecting and generating data for robotics and other domains.
PocketFlow
Pocket Flow is a 100-line minimalist LLM framework designed for (Multi-)Agents, Task Decomposition, RAG, etc. It aims to be the framework used by LLMs, focusing on stripping away low-level implementation details and emphasizing high-level programming paradigms. Pocket Flow serves as a learning resource and provides a core abstraction of a nested directed graph for breaking down tasks into multiple steps.

swiftide
Swiftide is a fast, streaming indexing and query library tailored for Retrieval Augmented Generation (RAG) in AI applications. It is built in Rust, utilizing parallel, asynchronous streams for blazingly fast performance. With Swiftide, users can easily build AI applications from idea to production in just a few lines of code. The tool addresses frustrations around performance, stability, and ease of use encountered while working with Python-based tooling. It offers features like fast streaming indexing pipeline, experimental query pipeline, integrations with various platforms, loaders, transformers, chunkers, embedders, and more. Swiftide aims to provide a platform for data indexing and querying to advance the development of automated Large Language Model (LLM) applications.

clearml
ClearML is a suite of tools designed to streamline the machine learning workflow. It includes an experiment manager, MLOps/LLMOps, data management, and model serving capabilities. ClearML is open-source and offers a free tier hosting option. It supports various ML/DL frameworks and integrates with Jupyter Notebook and PyCharm. ClearML provides extensive logging capabilities, including source control info, execution environment, hyper-parameters, and experiment outputs. It also offers automation features, such as remote job execution and pipeline creation. ClearML is designed to be easy to integrate, requiring only two lines of code to add to existing scripts. It aims to improve collaboration, visibility, and data transparency within ML teams.

AgentCPM
AgentCPM is a series of open-source LLM agents jointly developed by THUNLP, Renmin University of China, ModelBest, and the OpenBMB community. It addresses challenges faced by agents in real-world applications such as limited long-horizon capability, autonomy, and generalization. The team focuses on building deep research capabilities for agents, releasing AgentCPM-Explore, a deep-search LLM agent, and AgentCPM-Report, a deep-research LLM agent. AgentCPM-Explore is the first open-source agent model with 4B parameters to appear on widely used long-horizon agent benchmarks. AgentCPM-Report is built on the 8B-parameter base model MiniCPM4.1, autonomously generating long-form reports with extreme performance and minimal footprint, designed for high-privacy scenarios with offline and agile local deployment.

lerobot
LeRobot is a state-of-the-art AI library for real-world robotics in PyTorch. It aims to provide models, datasets, and tools to lower the barrier to entry to robotics, focusing on imitation learning and reinforcement learning. LeRobot offers pretrained models, datasets with human-collected demonstrations, and simulation environments. It plans to support real-world robotics on affordable and capable robots. The library hosts pretrained models and datasets on the Hugging Face community page.

LightLLM
LightLLM is a lightweight library for linear and logistic regression models. It provides a simple and efficient way to train and deploy machine learning models for regression tasks. The library is designed to be easy to use and integrate into existing projects, making it suitable for both beginners and experienced data scientists. With LightLLM, users can quickly build and evaluate regression models using a variety of algorithms and hyperparameters. The library also supports feature engineering and model interpretation, allowing users to gain insights from their data and make informed decisions based on the model predictions.
agentgateway
Agentgateway is an open source data plane optimized for agentic AI connectivity within or across any agent framework or environment. It provides drop-in security, observability, and governance for agent-to-agent and agent-to-tool communication, supporting leading interoperable protocols like Agent2Agent (A2A) and Model Context Protocol (MCP). Highly performant, security-first, multi-tenant, dynamic, and supporting legacy API transformation, agentgateway is designed to handle any scale and run anywhere with any agent framework.

opencompass
OpenCompass is a one-stop platform for large model evaluation, aiming to provide a fair, open, and reproducible benchmark for large model evaluation. Its main features include: * Comprehensive support for models and datasets: Pre-support for 20+ HuggingFace and API models, a model evaluation scheme of 70+ datasets with about 400,000 questions, comprehensively evaluating the capabilities of the models in five dimensions. * Efficient distributed evaluation: One line command to implement task division and distributed evaluation, completing the full evaluation of billion-scale models in just a few hours. * Diversified evaluation paradigms: Support for zero-shot, few-shot, and chain-of-thought evaluations, combined with standard or dialogue-type prompt templates, to easily stimulate the maximum performance of various models. * Modular design with high extensibility: Want to add new models or datasets, customize an advanced task division strategy, or even support a new cluster management system? Everything about OpenCompass can be easily expanded! * Experiment management and reporting mechanism: Use config files to fully record each experiment, and support real-time reporting of results.
For similar tasks

byteir
The ByteIR Project is a ByteDance model compilation solution. ByteIR includes compiler, runtime, and frontends, and provides an end-to-end model compilation solution. Although all ByteIR components (compiler/runtime/frontends) are together to provide an end-to-end solution, and all under the same umbrella of this repository, each component technically can perform independently. The name, ByteIR, comes from a legacy purpose internally. The ByteIR project is NOT an IR spec definition project. Instead, in most scenarios, ByteIR directly uses several upstream MLIR dialects and Google Mhlo. Most of ByteIR compiler passes are compatible with the selected upstream MLIR dialects and Google Mhlo.
zml
ZML is a high-performance AI inference stack built for production, using Zig language, MLIR, and Bazel. It allows users to create exciting AI projects, run pre-packaged models like MNIST, TinyLlama, OpenLLama, and Meta Llama, and compile models for accelerator runtimes. Users can also run tests, explore examples, and contribute to the project. ZML is licensed under the Apache 2.0 license.
edgeai
Embedded inference of Deep Learning models is quite challenging due to high compute requirements. TI’s Edge AI software product helps optimize and accelerate inference on TI’s embedded devices. It supports heterogeneous execution of DNNs across cortex-A based MPUs, TI’s latest generation C7x DSP, and DNN accelerator (MMA). The solution simplifies the product life cycle of DNN development and deployment by providing a rich set of tools and optimized libraries.
sdnext
SD.Next is an Image Diffusion implementation with advanced features. It offers multiple UI options, diffusion models, and built-in controls for text, image, batch, and video processing. The tool is multiplatform, supporting Windows, Linux, MacOS, nVidia, AMD, IntelArc/IPEX, DirectML, OpenVINO, ONNX+Olive, and ZLUDA. It provides optimized processing with the latest torch developments, including model compile, quantize, and compress functionalities. SD.Next also features Interrogate/Captioning with various models, queue management, automatic updates, and mobile compatibility.
mirage
Mirage Persistent Kernel (MPK) is a compiler and runtime system that automatically transforms LLM inference into a single megakernel—a fused GPU kernel that performs all necessary computation and communication within a single kernel launch. This end-to-end GPU fusion approach reduces LLM inference latency by 1.2× to 6.7×, all while requiring minimal developer effort.
tt-xla
TT-XLA is a repository that enables running PyTorch and JAX models on Tenstorrent's AI hardware. It serves as a backend integration between the JAX ecosystem and Tenstorrent's ML accelerators using the PJRT (Portable JAX Runtime) interface. It supports ingestion of PyTorch models through PyTorch/XLA and JAX models via jit compile, providing a StableHLO (SHLO) graph to TT-MLIR compiler.
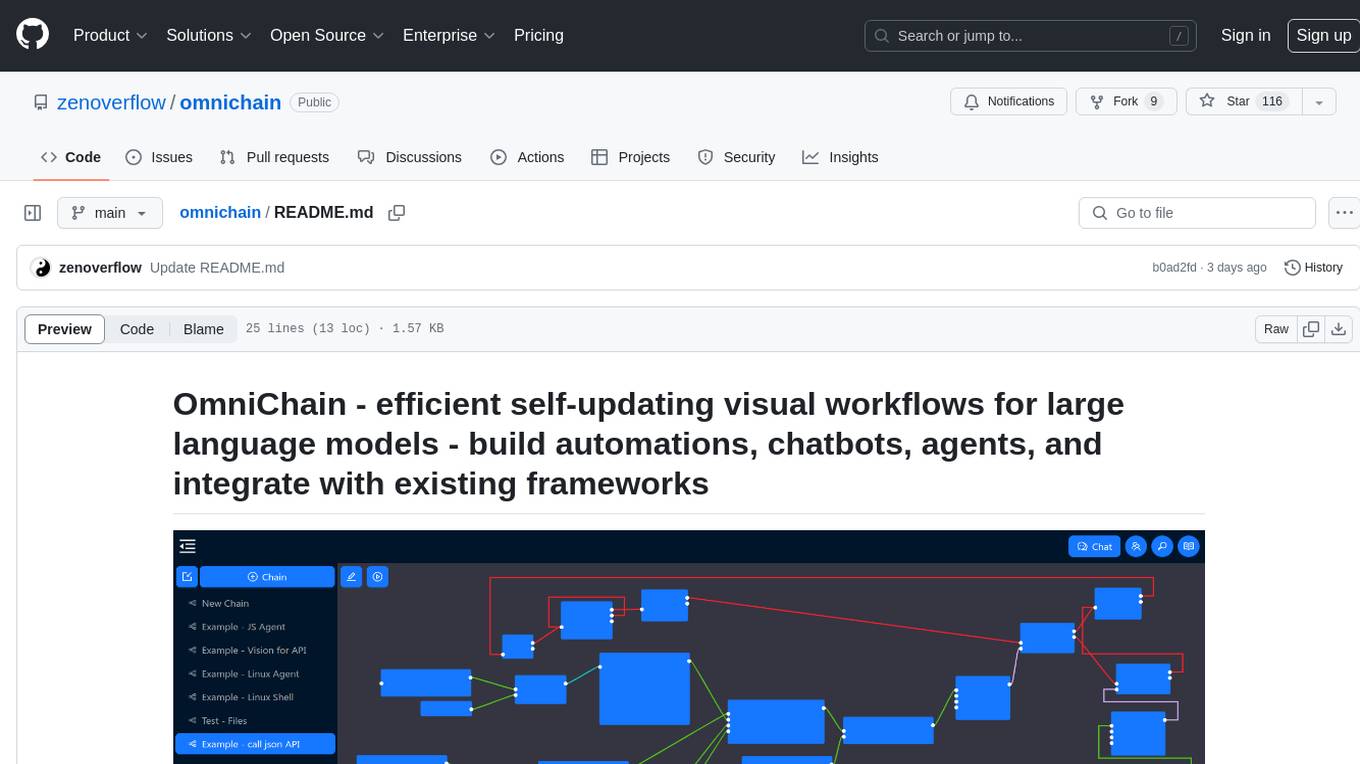
omnichain
OmniChain is a tool for building efficient self-updating visual workflows using AI language models, enabling users to automate tasks, create chatbots, agents, and integrate with existing frameworks. It allows users to create custom workflows guided by logic processes, store and recall information, and make decisions based on that information. The tool enables users to create tireless robot employees that operate 24/7, access the underlying operating system, generate and run NodeJS code snippets, and create custom agents and logic chains. OmniChain is self-hosted, open-source, and available for commercial use under the MIT license, with no coding skills required.
GOLEM
GOLEM is an open-source AI framework focused on optimization and learning of structured graph-based models using meta-heuristic methods. It emphasizes the potential of meta-heuristics in complex problem spaces where gradient-based methods are not suitable, and the importance of structured models in various problem domains. The framework offers features like structured model optimization, metaheuristic methods, multi-objective optimization, constrained optimization, extensibility, interpretability, and reproducibility. It can be applied to optimization problems represented as directed graphs with defined fitness functions. GOLEM has applications in areas like AutoML, Bayesian network structure search, differential equation discovery, geometric design, and neural architecture search. The project structure includes packages for core functionalities, adapters, graph representation, optimizers, genetic algorithms, utilities, serialization, visualization, examples, and testing. Contributions are welcome, and the project is supported by ITMO University's Research Center Strong Artificial Intelligence in Industry.
For similar jobs
turnkeyml
TurnkeyML is a tools framework that integrates models, toolchains, and hardware backends to simplify the evaluation and actuation of deep learning models. It supports use cases like exporting ONNX files, performance validation, functional coverage measurement, stress testing, and model insights analysis. The framework consists of analysis, build, runtime, reporting tools, and a models corpus, seamlessly integrated to provide comprehensive functionality with simple commands. Extensible through plugins, it offers support for various export and optimization tools and AI runtimes. The project is actively seeking collaborators and is licensed under Apache 2.0.
libedgetpu
This repository contains the source code for the userspace level runtime driver for Coral devices. The software is distributed in binary form at coral.ai/software. Users can build the library using Docker + Bazel, Bazel, or Makefile methods. It supports building on Linux, macOS, and Windows. The library is used to enable the Edge TPU runtime, which may heat up during operation. Google does not accept responsibility for any loss or damage if the device is operated outside the recommended ambient temperature range.

FlagPerf
FlagPerf is an integrated AI hardware evaluation engine jointly built by the Institute of Intelligence and AI hardware manufacturers. It aims to establish an industry-oriented metric system to evaluate the actual capabilities of AI hardware under software stack combinations (model + framework + compiler). FlagPerf features a multidimensional evaluation metric system that goes beyond just measuring 'whether the chip can support specific model training.' It covers various scenarios and tasks, including computer vision, natural language processing, speech, multimodal, with support for multiple training frameworks and inference engines to connect AI hardware with software ecosystems. It also supports various testing environments to comprehensively assess the performance of domestic AI chips in different scenarios.
tt-xla
TT-XLA is a repository that enables running PyTorch and JAX models on Tenstorrent's AI hardware. It serves as a backend integration between the JAX ecosystem and Tenstorrent's ML accelerators using the PJRT (Portable JAX Runtime) interface. It supports ingestion of PyTorch models through PyTorch/XLA and JAX models via jit compile, providing a StableHLO (SHLO) graph to TT-MLIR compiler.

Qwen-TensorRT-LLM
Qwen-TensorRT-LLM is a project developed for the NVIDIA TensorRT Hackathon 2023, focusing on accelerating inference for the Qwen-7B-Chat model using TRT-LLM. The project offers various functionalities such as FP16/BF16 support, INT8 and INT4 quantization options, Tensor Parallel for multi-GPU parallelism, web demo setup with gradio, Triton API deployment for maximum throughput/concurrency, fastapi integration for openai requests, CLI interaction, and langchain support. It supports models like qwen2, qwen, and qwen-vl for both base and chat models. The project also provides tutorials on Bilibili and blogs for adapting Qwen models in NVIDIA TensorRT-LLM, along with hardware requirements and quick start guides for different model types and quantization methods.

dl_model_infer
This project is a c++ version of the AI reasoning library that supports the reasoning of tensorrt models. It provides accelerated deployment cases of deep learning CV popular models and supports dynamic-batch image processing, inference, decode, and NMS. The project has been updated with various models and provides tutorials for model exports. It also includes a producer-consumer inference model for specific tasks. The project directory includes implementations for model inference applications, backend reasoning classes, post-processing, pre-processing, and target detection and tracking. Speed tests have been conducted on various models, and onnx downloads are available for different models.

joliGEN
JoliGEN is an integrated framework for training custom generative AI image-to-image models. It implements GAN, Diffusion, and Consistency models for various image translation tasks, including domain and style adaptation with conservation of semantics. The tool is designed for real-world applications such as Controlled Image Generation, Augmented Reality, Dataset Smart Augmentation, and Synthetic to Real transforms. JoliGEN allows for fast and stable training with a REST API server for simplified deployment. It offers a wide range of options and parameters with detailed documentation available for models, dataset formats, and data augmentation.

ai-edge-torch
AI Edge Torch is a Python library that supports converting PyTorch models into a .tflite format for on-device applications on Android, iOS, and IoT devices. It offers broad CPU coverage with initial GPU and NPU support, closely integrating with PyTorch and providing good coverage of Core ATen operators. The library includes a PyTorch converter for model conversion and a Generative API for authoring mobile-optimized PyTorch Transformer models, enabling easy deployment of Large Language Models (LLMs) on mobile devices.