
Customer-Service-Conversational-Insights-with-Azure-OpenAI-Services
A solution accelerator built on top of Microsoft Fabric, Azure OpenAI Service, and Azure AI Speech that enables customers with large amounts of conversational data to use generative AI to surface key phrases alongside operational metrics, unlocking valuable insights for targeted business impact.
Stars: 191
This solution accelerator is built on Azure Cognitive Search Service and Azure OpenAI Service to synthesize post-contact center transcripts for intelligent contact center scenarios. It converts raw transcripts into customer call summaries to extract insights around product and service performance. Key features include conversation summarization, key phrase extraction, speech-to-text transcription, sensitive information extraction, sentiment analysis, and opinion mining. The tool enables data professionals to quickly analyze call logs for improvement in contact center operations.
README:
MENU: USER STORY | SIMPLE DEPLOY | SUPPORTING DOCUMENTATION | CUSTOMER TRUTH

This solution accelerator enables customers with large amounts of conversational data to use generative AI to surface key phrases alongside operational metrics. This enables users to discover valuable insights for targeted business impact.
Version history: An updated version of the Conversation Knowledge Mining solution accelerator was published on 08/15/2024. If you deployed the accelerator prior to that date, please see “Version history” in the Supporting documentation section.
- Data processing: Microsoft Fabric processes both audio and conversation files at scale, leveraging its benefits for efficient and scalable data handling
- Summarization and key phrase extraction: Azure OpenAI is used to summarize long conversations into concise paragraphs and extract relevant key phrases
- Speech transcription and diarization: Azure Speech is used to transcribe audio files, including speaker diarization for post-call analytics. Diarization is the process of recognizing and separating individual speakers into mono-channel audio data
- Analytics dashboard: Power BI is used to visualize the correlation between operational metrics and AI-generated conversational data

A contact center manager reviews contact center performance to ensure resources are being used efficiently. To identify areas for improvement, they need to understand the correlation between conversational and operational data.
The contact center manager uses their dashboard to identify how LLM-generated conversational analytics and insights are impacting operations to make an informed decision about how to improve their center’s performance.
Company personnel (employees, executives) looking to gain conversational insights in correlation with operational Contact Center metrics would leverage this accelerator to find what they need quickly.
- Conversation analysis: Generative AI analyzes call transcripts, summarizes content, identifies and aggregates key phrases for data visualization
- Automated customer satisfaction: Generative AI determines the post-call satisfaction rating of a customer’s experience with their agent
- Operational clarity: Relevant metrics such as call volume, handling time, and call resolution are pulled from the same call logs for operational data visualization
- Unified data: Unstructured (call transcripts) and structured (operational metrics) data are both analyzed and visualized within the same application
- Targeted decision enablement: Enable agents and managers to achieve glanceable insight recognition, corollary information analysis, and accelerated decision making
-
Azure Speech Service
-
Azure OpenAI
-
Microsoft Fabric Capacity
-
The user deploying the template must have permission to create resources and resource groups.


-
Deploy Azure resources
Click the following deployment button to create the required resources for this accelerator directly in your Azure Subscription.-
Most fields will have a default name set already. You will need to update the following Azure OpenAI settings:
-
Region - the region where the resources will be created in
-
Solution Prefix - provide a 6 alphanumeric value that will be used to prefix resources
-
Location - location of resources, by default it will use the resource group's location
-
-
-
Create Fabric workspace
- Navigate to (Fabric Workspace)
- Click on Workspaces from left Navigation
- Click on + New Workspace
- Provide Name of Workspace
- Provide Description of Workspace (optional)
- Click Apply
- Open Workspace
- Retrieve Workspace ID from URL, refer to documentation additional assistance (here)
-
Deploy Fabric resources and artifacts
- Navigate to (Azure Portal)
- Click on Azure Cloud Shell in the top right of navigation Menu (add image)
- Run the run the following commands:
-
az login***Follow instructions in Azure Cloud Shell for login instructions rm -rf ./Customer-Service-Conversational-Insights-with-Azure-OpenAI-Servicesgit clone https://github.com/microsoft/Customer-Service-Conversational-Insights-with-Azure-OpenAI-Servicescd ./Customer-Service-Conversational-Insights-with-Azure-OpenAI-Services/Deployment/scripts/fabric_scripts-
sh ./run_fabric_items_scripts.sh keyvault_param workspaceid_param solutionprefix_param- keyvault_param - the name of the keyvault that was created in Step 1
- workspaceid_param - the workspaceid created in Step 2
- solutionprefix_param - prefix used to append to lakehouse upon creation
-
- Get Fabric Lakehouse connection details:
- Once deployment is complete, navigate to Fabric Workspace
- Find Lakehouse in workspace (ex.lakehouse_solutionprefix_param)
- Click on the
...next to the SQL Analytics Endpoint - Click on
Copy SQL connection string - Click Copy button in popup window.
- Wait 10-15 minutes to allow the data pipelines to finish processing then proceed to next step.
-
Open Power BI report
- Download the .pbix file from the Reports folder.
- Open Power BI report in Power BI Dashboard
- Click on
Transform Datamenu option from the Task Bar - Click
Data source settings - Click
Change Source... - Input the Server link (from Fabric Workspace)
- Input Database name (the lakehouse name from Fabric Workspace)
- Click
OK - Click
Edit Permissions - If not signed in, sign in your credentials and proceed to click OK
- Click
Close - Report should refresh with new connection.
-
Publish Power BI
- Click
Publish(from PBI report in Power BI Desktop application) - Select Fabric Workspace
- Click
Select - After publish is complete, navigate to Fabric Workspace
- Click
...next to the Semantic model for Power BI report - Click on
Settings - Click on
Edit credentials(under Data source credentials) - Select
OAuth2for the Authentication method - Select option for
Privacy level setting for this data source - Click
Sign in - Navigate back to Fabric workspace and click on Power BI report
- Click
-
Schedule Post-Processing Notebook
It is essential to update dates daily as they advance based on the current day at the time of deployment. Since the Power BI report relies on the current date, we highly recommend scheduling or running the 03_post_processing notebook daily in the workspace. Please note that this process modifies the original date of the processed data. If you do not wish to run this, do not execute the 03_post_processing notebook.To schedule the notebook, follow these steps:
- Navigate to the Workspace
- Click on the "..." next to the 03_post_processing notebook
- Select "Schedule"
- Configure the schedule settings (we recommend running the notebook at least daily)
Currently, audio files are not processed during deployment. To manually process audio files, follow these steps:
- Open the
pipeline_notebook - Comment out cell 2 (only if there are zero files in the
conversation_inputdata folder waiting for JSON processing) - Uncomment cells 3 and 4
- Run
pipeline_notebook
All files JSON and WAV files can be uploaded in the corresponding Lakehouse in the data/Files folder:
-
Conversation (JSON files): Upload JSON files in the conversation_input folder.
-
Audio (WAV files): Upload Audio files in the audio_input folder.
- To process additional files, manually execute the pipeline_notebook after uploading new files.
- The OpenAI prompt can be modified within the Fabric notebooks.
If you'd like to customize the accelerator, here are some ways you might do that:
- Modify the Power BI report to use a custom logo
- Ingest your own JSON conversation files by uploading them into the
conversation_inputlakehouse folder and run the data pipeline - Ingest your own audio conversation files by uploading them into the
audio_inputlakehouse folder and run the data pipeline
- Microsoft Fabric documentation - Microsoft Fabric | Microsoft Learn
- Azure OpenAI Service - Documentation, quickstarts, API reference - Azure AI services | Microsoft Learn
- Speech service documentation - Tutorials, API Reference - Azure AI services - Azure AI services | Microsoft Learn
An updated version of the Conversation Knowledge Mining (CKM) solution accelerator was published on 08/15/2024. If you deployed the accelerator prior to that date, please note that CKM v2 cannot be deployed over CKM v1. Please also note that the CKM v2 .json conversation file format has been revised to include additional metadata, therefore CKM v1 files are no longer compatible. For resources related to CKM v1, please visit our archive (link-to-archive).
Customer stories coming soon.
To the extent that the Software includes components or code used in or derived from Microsoft products or services, including without limitation Microsoft Azure Services (collectively, “Microsoft Products and Services”), you must also comply with the Product Terms applicable to such Microsoft Products and Services. You acknowledge and agree that the license governing the Software does not grant you a license or other right to use Microsoft Products and Services. Nothing in the license or this ReadMe file will serve to supersede, amend, terminate or modify any terms in the Product Terms for any Microsoft Products and Services.
You must also comply with all domestic and international export laws and regulations that apply to the Software, which include restrictions on destinations, end users, and end use. For further information on export restrictions, visit https://aka.ms/exporting.
You acknowledge that the Software and Microsoft Products and Services (1) are not designed, intended or made available as a medical device(s), and (2) are not designed or intended to be a substitute for professional medical advice, diagnosis, treatment, or judgment and should not be used to replace or as a substitute for professional medical advice, diagnosis, treatment, or judgment. Customer is solely responsible for displaying and/or obtaining appropriate consents, warnings, disclaimers, and acknowledgements to end users of Customer’s implementation of the Online Services.
You acknowledge the Software is not subject to SOC 1 and SOC 2 compliance audits. No Microsoft technology, nor any of its component technologies, including the Software, is intended or made available as a substitute for the professional advice, opinion, or judgement of a certified financial services professional. Do not use the Software to replace, substitute, or provide professional financial advice or judgment.
BY ACCESSING OR USING THE SOFTWARE, YOU ACKNOWLEDGE THAT THE SOFTWARE IS NOT DESIGNED OR INTENDED TO SUPPORT ANY USE IN WHICH A SERVICE INTERRUPTION, DEFECT, ERROR, OR OTHER FAILURE OF THE SOFTWARE COULD RESULT IN THE DEATH OR SERIOUS BODILY INJURY OF ANY PERSON OR IN PHYSICAL OR ENVIRONMENTAL DAMAGE (COLLECTIVELY, “HIGH-RISK USE”), AND THAT YOU WILL ENSURE THAT, IN THE EVENT OF ANY INTERRUPTION, DEFECT, ERROR, OR OTHER FAILURE OF THE SOFTWARE, THE SAFETY OF PEOPLE, PROPERTY, AND THE ENVIRONMENT ARE NOT REDUCED BELOW A LEVEL THAT IS REASONABLY, APPROPRIATE, AND LEGAL, WHETHER IN GENERAL OR IN A SPECIFIC INDUSTRY. BY ACCESSING THE SOFTWARE, YOU FURTHER ACKNOWLEDGE THAT YOUR HIGH-RISK USE OF THE SOFTWARE IS AT YOUR OWN RISK.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Customer-Service-Conversational-Insights-with-Azure-OpenAI-Services
Similar Open Source Tools
Customer-Service-Conversational-Insights-with-Azure-OpenAI-Services
This solution accelerator is built on Azure Cognitive Search Service and Azure OpenAI Service to synthesize post-contact center transcripts for intelligent contact center scenarios. It converts raw transcripts into customer call summaries to extract insights around product and service performance. Key features include conversation summarization, key phrase extraction, speech-to-text transcription, sensitive information extraction, sentiment analysis, and opinion mining. The tool enables data professionals to quickly analyze call logs for improvement in contact center operations.
Conversation-Knowledge-Mining-Solution-Accelerator
The Conversation Knowledge Mining Solution Accelerator enables customers to leverage intelligence to uncover insights, relationships, and patterns from conversational data. It empowers users to gain valuable knowledge and drive targeted business impact by utilizing Azure AI Foundry, Azure OpenAI, Microsoft Fabric, and Azure Search for topic modeling, key phrase extraction, speech-to-text transcription, and interactive chat experiences.

azure-search-openai-demo
This sample demonstrates a few approaches for creating ChatGPT-like experiences over your own data using the Retrieval Augmented Generation pattern. It uses Azure OpenAI Service to access a GPT model (gpt-35-turbo), and Azure AI Search for data indexing and retrieval. The repo includes sample data so it's ready to try end to end. In this sample application we use a fictitious company called Contoso Electronics, and the experience allows its employees to ask questions about the benefits, internal policies, as well as job descriptions and roles.

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

AntSK
AntSK is an AI knowledge base/agent built with .Net8+Blazor+SemanticKernel. It features a semantic kernel for accurate natural language processing, a memory kernel for continuous learning and knowledge storage, a knowledge base for importing and querying knowledge from various document formats, a text-to-image generator integrated with StableDiffusion, GPTs generation for creating personalized GPT models, API interfaces for integrating AntSK into other applications, an open API plugin system for extending functionality, a .Net plugin system for integrating business functions, real-time information retrieval from the internet, model management for adapting and managing different models from different vendors, support for domestic models and databases for operation in a trusted environment, and planned model fine-tuning based on llamafactory.

dataherald
Dataherald is a natural language-to-SQL engine built for enterprise-level question answering over structured data. It allows you to set up an API from your database that can answer questions in plain English. You can use Dataherald to: * Allow business users to get insights from the data warehouse without going through a data analyst * Enable Q+A from your production DBs inside your SaaS application * Create a ChatGPT plug-in from your proprietary data
LLM-Minutes-of-Meeting
LLM-Minutes-of-Meeting is a project showcasing NLP & LLM's capability to summarize long meetings and automate the task of delegating Minutes of Meeting(MoM) emails. It converts audio/video files to text, generates editable MoM, and aims to develop a real-time python web-application for meeting automation. The tool features keyword highlighting, topic tagging, export in various formats, user-friendly interface, and uses Celery for asynchronous processing. It is designed for corporate meetings, educational institutions, legal and medical fields, accessibility, and event coverage.

morphik-core
Morphik is an AI-native toolset designed to help developers integrate context into their AI applications by providing tools to store, represent, and search unstructured data. It offers features such as multimodal search, fast metadata extraction, and integrations with existing tools. Morphik aims to address the challenges of traditional AI approaches that struggle with visually rich documents and provide a more comprehensive solution for understanding and processing complex data.

super-agent-party
A 3D AI desktop companion with endless possibilities! This repository provides a platform for enhancing the LLM API without code modification, supporting seamless integration of various functionalities such as knowledge bases, real-time networking, multimodal capabilities, automation, and deep thinking control. It offers one-click deployment to multiple terminals, ecological tool interconnection, standardized interface opening, and compatibility across all platforms. Users can deploy the tool on Windows, macOS, Linux, or Docker, and access features like intelligent agent deployment, VRM desktop pets, Tavern character cards, QQ bot deployment, and developer-friendly interfaces. The tool supports multi-service providers, extensive tool integration, and ComfyUI workflows. Hardware requirements are minimal, making it suitable for various deployment scenarios.

PulsarRPA
PulsarRPA is a high-performance, distributed, open-source Robotic Process Automation (RPA) framework designed to handle large-scale RPA tasks with ease. It provides a comprehensive solution for browser automation, web content understanding, and data extraction. PulsarRPA addresses challenges of browser automation and accurate web data extraction from complex and evolving websites. It incorporates innovative technologies like browser rendering, RPA, intelligent scraping, advanced DOM parsing, and distributed architecture to ensure efficient, accurate, and scalable web data extraction. The tool is open-source, customizable, and supports cutting-edge information extraction technology, making it a preferred solution for large-scale web data extraction.

HuggingFists
HuggingFists is a low-code data flow tool that enables convenient use of LLM and HuggingFace models. It provides functionalities similar to Langchain, allowing users to design, debug, and manage data processing workflows, create and schedule workflow jobs, manage resources environment, and handle various data artifact resources. The tool also offers account management for users, allowing centralized management of data source accounts and API accounts. Users can access Hugging Face models through the Inference API or locally deployed models, as well as datasets on Hugging Face. HuggingFists supports breakpoint debugging, branch selection, function calls, workflow variables, and more to assist users in developing complex data processing workflows.

aiid
The Artificial Intelligence Incident Database (AIID) is a collection of incidents involving the development and use of artificial intelligence (AI). The database is designed to help researchers, policymakers, and the public understand the potential risks and benefits of AI, and to inform the development of policies and practices to mitigate the risks and promote the benefits of AI. The AIID is a collaborative project involving researchers from the University of California, Berkeley, the University of Washington, and the University of Toronto.
cymbal-air-toolbox-demo
Cymbal Air Toolbox Demo is a project that provides a production-quality reference implementation for building Agentic applications using Agents and Retrieval Augmented Generation (RAG) to query and interact with data stored in Google Cloud Databases. The demo showcases a customer service assistant for a fictional airline, Cymbal Air, assisting travelers with flight management and providing information about San Francisco International Airport (SFO). It utilizes techniques like Retrieval Augmented Generation (RAG) and Agent-based Orchestration to enhance responses and handle a wide variety of queries. The architecture includes components like the user-facing application, MCP Toolbox middleware server, and a database, offering advantages such as better security, scalability, and recall for agents.
doc2plan
doc2plan is a browser-based application that helps users create personalized learning plans by extracting content from documents. It features a Creator for manual or AI-assisted plan construction and a Viewer for interactive plan navigation. Users can extract chapters, key topics, generate quizzes, and track progress. The application includes AI-driven content extraction, quiz generation, progress tracking, plan import/export, assistant management, customizable settings, viewer chat with text-to-speech and speech-to-text support, and integration with various Retrieval-Augmented Generation (RAG) models. It aims to simplify the creation of comprehensive learning modules tailored to individual needs.
intelligence-toolkit
The Intelligence Toolkit is a suite of interactive workflows designed to help domain experts make sense of real-world data by identifying patterns, themes, relationships, and risks within complex datasets. It utilizes generative AI (GPT models) to create reports on findings of interest. The toolkit supports analysis of case, entity, and text data, providing various interactive workflows for different intelligence tasks. Users are expected to evaluate the quality of data insights and AI interpretations before taking action. The system is designed for moderate-sized datasets and responsible use of personal case data. It uses the GPT-4 model from OpenAI or Azure OpenAI APIs for generating reports and insights.
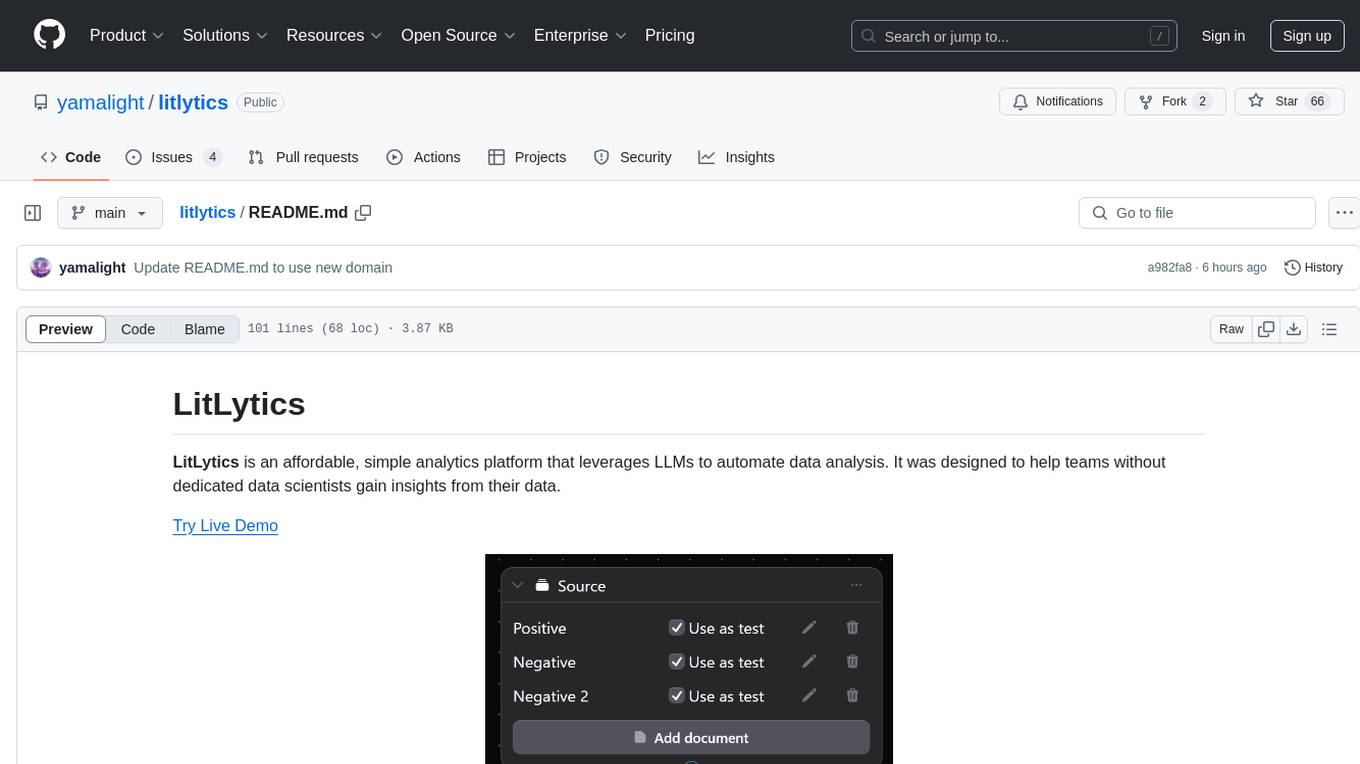
litlytics
LitLytics is an affordable analytics platform leveraging LLMs for automated data analysis. It simplifies analytics for teams without data scientists, generates custom pipelines, and allows customization. Cost-efficient with low data processing costs. Scalable and flexible, works with CSV, PDF, and plain text data formats.
For similar tasks
Customer-Service-Conversational-Insights-with-Azure-OpenAI-Services
This solution accelerator is built on Azure Cognitive Search Service and Azure OpenAI Service to synthesize post-contact center transcripts for intelligent contact center scenarios. It converts raw transcripts into customer call summaries to extract insights around product and service performance. Key features include conversation summarization, key phrase extraction, speech-to-text transcription, sensitive information extraction, sentiment analysis, and opinion mining. The tool enables data professionals to quickly analyze call logs for improvement in contact center operations.

nlp-llms-resources
The 'nlp-llms-resources' repository is a comprehensive resource list for Natural Language Processing (NLP) and Large Language Models (LLMs). It covers a wide range of topics including traditional NLP datasets, data acquisition, libraries for NLP, neural networks, sentiment analysis, optical character recognition, information extraction, semantics, topic modeling, multilingual NLP, domain-specific LLMs, vector databases, ethics, costing, books, courses, surveys, aggregators, newsletters, papers, conferences, and societies. The repository provides valuable information and resources for individuals interested in NLP and LLMs.

adata
AData is a free and open-source A-share database that focuses on transaction-related data. It provides comprehensive data on stocks, including basic information, market data, and sentiment analysis. AData is designed to be easy to use and integrate with other applications, making it a valuable tool for quantitative trading and AI training.

PIXIU
PIXIU is a project designed to support the development, fine-tuning, and evaluation of Large Language Models (LLMs) in the financial domain. It includes components like FinBen, a Financial Language Understanding and Prediction Evaluation Benchmark, FIT, a Financial Instruction Dataset, and FinMA, a Financial Large Language Model. The project provides open resources, multi-task and multi-modal financial data, and diverse financial tasks for training and evaluation. It aims to encourage open research and transparency in the financial NLP field.

hezar
Hezar is an all-in-one AI library designed specifically for the Persian community. It brings together various AI models and tools, making it easy to use AI with just a few lines of code. The library seamlessly integrates with Hugging Face Hub, offering a developer-friendly interface and task-based model interface. In addition to models, Hezar provides tools like word embeddings, tokenizers, feature extractors, and more. It also includes supplementary ML tools for deployment, benchmarking, and optimization.

text-embeddings-inference
Text Embeddings Inference (TEI) is a toolkit for deploying and serving open source text embeddings and sequence classification models. TEI enables high-performance extraction for popular models like FlagEmbedding, Ember, GTE, and E5. It implements features such as no model graph compilation step, Metal support for local execution on Macs, small docker images with fast boot times, token-based dynamic batching, optimized transformers code for inference using Flash Attention, Candle, and cuBLASLt, Safetensors weight loading, and production-ready features like distributed tracing with Open Telemetry and Prometheus metrics.

CodeProject.AI-Server
CodeProject.AI Server is a standalone, self-hosted, fast, free, and open-source Artificial Intelligence microserver designed for any platform and language. It can be installed locally without the need for off-device or out-of-network data transfer, providing an easy-to-use solution for developers interested in AI programming. The server includes a HTTP REST API server, backend analysis services, and the source code, enabling users to perform various AI tasks locally without relying on external services or cloud computing. Current capabilities include object detection, face detection, scene recognition, sentiment analysis, and more, with ongoing feature expansions planned. The project aims to promote AI development, simplify AI implementation, focus on core use-cases, and leverage the expertise of the developer community.

spark-nlp
Spark NLP is a state-of-the-art Natural Language Processing library built on top of Apache Spark. It provides simple, performant, and accurate NLP annotations for machine learning pipelines that scale easily in a distributed environment. Spark NLP comes with 36000+ pretrained pipelines and models in more than 200+ languages. It offers tasks such as Tokenization, Word Segmentation, Part-of-Speech Tagging, Named Entity Recognition, Dependency Parsing, Spell Checking, Text Classification, Sentiment Analysis, Token Classification, Machine Translation, Summarization, Question Answering, Table Question Answering, Text Generation, Image Classification, Image to Text (captioning), Automatic Speech Recognition, Zero-Shot Learning, and many more NLP tasks. Spark NLP is the only open-source NLP library in production that offers state-of-the-art transformers such as BERT, CamemBERT, ALBERT, ELECTRA, XLNet, DistilBERT, RoBERTa, DeBERTa, XLM-RoBERTa, Longformer, ELMO, Universal Sentence Encoder, Llama-2, M2M100, BART, Instructor, E5, Google T5, MarianMT, OpenAI GPT2, Vision Transformers (ViT), OpenAI Whisper, and many more not only to Python and R, but also to JVM ecosystem (Java, Scala, and Kotlin) at scale by extending Apache Spark natively.
For similar jobs

llmops-promptflow-template
LLMOps with Prompt flow is a template and guidance for building LLM-infused apps using Prompt flow. It provides centralized code hosting, lifecycle management, variant and hyperparameter experimentation, A/B deployment, many-to-many dataset/flow relationships, multiple deployment targets, comprehensive reporting, BYOF capabilities, configuration-based development, local prompt experimentation and evaluation, endpoint testing, and optional Human-in-loop validation. The tool is customizable to suit various application needs.

azure-search-vector-samples
This repository provides code samples in Python, C#, REST, and JavaScript for vector support in Azure AI Search. It includes demos for various languages showcasing vectorization of data, creating indexes, and querying vector data. Additionally, it offers tools like Azure AI Search Lab for experimenting with AI-enabled search scenarios in Azure and templates for deploying custom chat-with-your-data solutions. The repository also features documentation on vector search, hybrid search, creating and querying vector indexes, and REST API references for Azure AI Search and Azure OpenAI Service.

geti-sdk
The Intel® Geti™ SDK is a python package that enables teams to rapidly develop AI models by easing the complexities of model development and enhancing collaboration between teams. It provides tools to interact with an Intel® Geti™ server via the REST API, allowing for project creation, downloading, uploading, deploying for local inference with OpenVINO, setting project and model configuration, launching and monitoring training jobs, and media upload and prediction. The SDK also includes tutorial-style Jupyter notebooks demonstrating its usage.

booster
Booster is a powerful inference accelerator designed for scaling large language models within production environments or for experimental purposes. It is built with performance and scaling in mind, supporting various CPUs and GPUs, including Nvidia CUDA, Apple Metal, and OpenCL cards. The tool can split large models across multiple GPUs, offering fast inference on machines with beefy GPUs. It supports both regular FP16/FP32 models and quantised versions, along with popular LLM architectures. Additionally, Booster features proprietary Janus Sampling for code generation and non-English languages.

xFasterTransformer
xFasterTransformer is an optimized solution for Large Language Models (LLMs) on the X86 platform, providing high performance and scalability for inference on mainstream LLM models. It offers C++ and Python APIs for easy integration, along with example codes and benchmark scripts. Users can prepare models in a different format, convert them, and use the APIs for tasks like encoding input prompts, generating token ids, and serving inference requests. The tool supports various data types and models, and can run in single or multi-rank modes using MPI. A web demo based on Gradio is available for popular LLM models like ChatGLM and Llama2. Benchmark scripts help evaluate model inference performance quickly, and MLServer enables serving with REST and gRPC interfaces.

amazon-transcribe-live-call-analytics
The Amazon Transcribe Live Call Analytics (LCA) with Agent Assist Sample Solution is designed to help contact centers assess and optimize caller experiences in real time. It leverages Amazon machine learning services like Amazon Transcribe, Amazon Comprehend, and Amazon SageMaker to transcribe and extract insights from contact center audio. The solution provides real-time supervisor and agent assist features, integrates with existing contact centers, and offers a scalable, cost-effective approach to improve customer interactions. The end-to-end architecture includes features like live call transcription, call summarization, AI-powered agent assistance, and real-time analytics. The solution is event-driven, ensuring low latency and seamless processing flow from ingested speech to live webpage updates.

ai-lab-recipes
This repository contains recipes for building and running containerized AI and LLM applications with Podman. It provides model servers that serve machine-learning models via an API, allowing developers to quickly prototype new AI applications locally. The recipes include components like model servers and AI applications for tasks such as chat, summarization, object detection, etc. Images for sample applications and models are available in `quay.io`, and bootable containers for AI training on Linux OS are enabled.

XLearning
XLearning is a scheduling platform for big data and artificial intelligence, supporting various machine learning and deep learning frameworks. It runs on Hadoop Yarn and integrates frameworks like TensorFlow, MXNet, Caffe, Theano, PyTorch, Keras, XGBoost. XLearning offers scalability, compatibility, multiple deep learning framework support, unified data management based on HDFS, visualization display, and compatibility with code at native frameworks. It provides functions for data input/output strategies, container management, TensorBoard service, and resource usage metrics display. XLearning requires JDK >= 1.7 and Maven >= 3.3 for compilation, and deployment on CentOS 7.2 with Java >= 1.7 and Hadoop 2.6, 2.7, 2.8.