
model_baseline
Testing baseline LLMs performance across various models
Stars: 232
This repository contains code for testing model baselines on ARC-AGI tasks. Users can test model baselines on ARC-AGI-1 and ARC-AGI-2 tasks, run single tasks, run tasks with concurrency, score submissions, and view historical results. Contributors can add more model adapters to the `src/adapters` folder. The repository also provides CLI usage for validation, uploading model outputs, bulk uploading, and Hugging Face integration for model submissions. Contributors can test new providers using the `test_providers.sh` script before submitting pull requests.
README:
This repo contains code for testing model baselines on ARC-AGI. The input data is a folder containing individual files for ARC-AGI tasks.
git clone https://github.com/arcprizeorg/model_baseline.git
git submodule update --init
pip install -r requirements.txt
The task format for ARC-AGI-1 and ARC-AGI-2 are identical. You can point this testing hardness towards ARC-AGI-2 via the --data_dir parameter. When running with concurrency, ensure you're using the correct <task_list>.txt found in data/task_lists/ for the set you're testing.
To test a single task, run:
python3 -m main --data_dir data/arc-agi/data/evaluation --config claude_sonnet--task_id 0a1d4ef5 --print_logs
Use the optional parameters to save and print the submission:
python3 -m main --data_dir data/arc-agi/data/evaluation --config claude_sonnet --task_id {} --save_submission_dir submissions/claude_sonnet_20241022 --print_logs
This will write one <id>.json file per task.
Testing multiple tasks in a single run can be slow. You can use the your parallel technique of choice to speed this up.
For example with the parallel command:
brew install parallel
parallel --jobs 20 --progress python3 -m main --data_dir data/arc-agi/data/evaluation --config claude_sonnet --task_id {} --save_submission_dir submissions/claude_sonnet_20241022 --print_logs :::: ./data/task_lists/public_evaluation_v1.txt
Note: In order to use parllel you'll need a list of task ids. generate_tasks_list.py helps with this. Public data task ids are already supplied.
python3 -m src.utils.generate_tasks_list --task_dir data/arc-agi/data/training --output_file data/task_lists/public_training
You can score your submissions by pointing the scoring script at your submissions directory:
python3 -m src.scoring.scoring --task_dir data/arc-agi/data/evaluation --submission_dir submissions/claude_sonnet_20241022 --print_logs --results_dir results/claude_sonnet_20241022
Note: You'll also need to tell the script which task set to score.
Results are stored in the results folder. You can view historical results for models here.
This repo is welcome to contributions!
Specifically, we would love help adding more model adapters to the src/adapters folder.
More will get added by the ARC-AGI team, but we'll also gladly accept contributions from the community.
For more information visit the ARC Prize.
Validate model outputs against task sets:
# Basic validation
python cli/main.py validate data/arc-agi/data/evaluation submissions/open_ai_o1_high_20241217
# Validate another model's outputs
python cli/main.py validate data/arc-agi/data/evaluation submissions/claude_sonnet_20241022Upload a single model's outputs to a task set repository:
# Basic upload (private repository)
python cli/main.py upload submissions/open_ai_o1_high_20241217 --task-set public_eval_v1
# Upload to a different organization
python cli/main.py upload submissions/claude_sonnet_20241022 --task-set public_eval_v1 --org your-org-name
# Create a public repository
python cli/main.py upload submissions/deepseek_v3 --task-set public_eval_v1 --publicUpload multiple model outputs at once:
# Upload all models in submissions directory (private repository)
python cli/main.py bulk-upload submissions/ --task-set public_eval_v1
# Upload to a different organization
python cli/main.py bulk-upload submissions/ --task-set public_eval_v1 --org your-org-name
# Create a public repository
python cli/main.py bulk-upload submissions/ --task-set public_eval_v1 --publicNotes:
- All uploads create private repositories by default
- Use
--publicflag to create public repositories - Files are uploaded to subdirectories matching model names
- Default organization is "arcprize"
Before uploading, you'll need to authenticate with Hugging Face:
- Get your access token from https://huggingface.co/settings/tokens
- Set up authentication using either method:
# Option 1: Environment variable export HUGGING_FACE_HUB_TOKEN=your_token_here # Option 2: CLI login huggingface-cli login
The upload process organizes submissions by task sets. Each task set (e.g., public_eval_v1) becomes a separate dataset repository on Hugging Face, with model submissions organized in subdirectories.
Structure:
task_set_name/
├── model_name_1/
│ ├── result1.json
│ ├── result2.json
├── model_name_2/
│ ├── result1.json
│ └── result2.json
To upload model outputs:
python cli/main.py upload submissions/model_name --task-set task_set_name [--org organization] [--public]For example:
python cli/main.py upload submissions/open_ai_o1_high_20241217 --task-set public_eval_v1To upload multiple model outputs at once:
python cli/main.py bulk-upload submissions/ --task-set task_set_name [--org organization] [--public]For contributors implementing new providers, we provide a streamlined way to validate your implementation using the test_providers.sh script. This script helps ensure your provider implementation works correctly with the ARC-AGI tasks before submitting a pull request.
# Run all provider tests
./test_providers.sh
# The script will test multiple provider/model combinations in parallel
# Each test will:
# 1. Run a specific task for each provider/model
# 2. Save the output
# 3. Report success/failureThe tests ensure that:
- The provider can successfully connect to its API
- The model can process ARC-AGI tasks
- The output matches the expected format
- The provider correctly handles token usage and costs
You can test the same model with different configurations by using the --config parameter:
# Test a model with a specific configuration
python3 -m main --data_dir data/arc-agi/data/evaluation --config claude_sonnet --task_id sample_task_id --print_logsThe test_providers.sh script includes examples of testing the same model with different configurations, such as:
-
openai o1 0b17323b high_temp- Testing o1 with high temperature -
openai o1 0b17323b low_temp- Testing o1 with low temperature
New models are defined in src/models.yml. Each model requires:
models:
- name: "model_config_name" # A unique identifier for this model configuration
model_name: "actual-model-name" # The actual model name used by the provider's API
provider: "provider-name"
max_tokens: 4024 # or appropriate limit
temperature: 0.0 # optional
pricing:
date: "YYYY-MM-DD"
input: 0.00 # Cost per 1M input tokens
output: 0.00 # Cost per 1M output tokensIn models.yml, you can create multiple configurations for the same underlying model by defining separate entries with different name values but the same model_name:
models:
# Configuration for short responses
- name: "o1_short_response"
model_name: "o1"
provider: "openai"
max_completion_tokens: 1024 # Shorter response limit
pricing:
date: "2025-02-23"
input: 15.00
output: 60.00
# Configuration for long responses
- name: "o1_long_response"
model_name: "o1"
provider: "openai"
max_completion_tokens: 4024 # Longer response limit
pricing:
date: "2025-02-23"
input: 15.00
output: 60.00When running the model, you specify the configuration name as the model parameter:
# Run with short response configuration
python3 -m main --config o1_short_response --task_id sample_task_id
# Run with long response configuration
python3 -m main --config o1_long_response --task_id sample_task_idYou can add any model-specific parameters supported by the provider's API:
models:
- name: "gemini_pro"
model_name: "gemini-1.5-pro"
provider: "gemini"
max_output_tokens: 4024 # Provider-specific parameter
temperature: 0.0
pricing:
date: "2025-02-23"
input: 1.25
output: 5.00Note how different providers may use different parameter names (e.g., max_tokens, max_completion_tokens, or max_output_tokens) depending on their API requirements.
When running batch tests with multiple configurations:
# Test with short response configuration
parallel --jobs 20 python3 -m main --data_dir data/arc-agi/data/evaluation --config o1_long_response --task_id {} --save_submission_dir submissions/o1_short :::: ./data/task_lists/public_evaluation_v1.txt
# Test with long response configuration
parallel --jobs 20 python3 -m main --data_dir data/arc-agi/data/evaluation --config o1_long_response --task_id {} --save_submission_dir submissions/o1_long :::: ./data/task_lists/public_evaluation_v1.txtAfter running tests with different configurations, you can compare their performance:
# Score short response configuration
python3 -m src.scoring.scoring --task_dir data/arc-agi/data/evaluation --submission_dir submissions/o1_short --print_logs --results_dir results/o1_short
# Score long response configuration
python3 -m src.scoring.scoring --task_dir data/arc-agi/data/evaluation --submission_dir submissions/o1_long --print_logs --results_dir results/o1_longThis allows you to systematically evaluate how different parameter settings affect model performance on ARC-AGI tasks.
-
Create a new file in
src/adapters/(e.g.,my_provider.py) -
Implement the
ProviderAdapterclass:from .provider import ProviderAdapter class MyProviderAdapter(ProviderAdapter): def init_client(self): # Initialize API client pass def make_prediction(self, prompt: str) -> Attempt: # Make prediction and return standardized Attempt object pass def chat_completion(self, messages: str) -> str: # Handle chat completion pass
-
Key requirements:
- Handle authentication (typically via environment variables)
- Implement proper error handling
- Convert provider-specific responses to standardized formats
- Track and report token usage and costs
- Add test cases to
test_providers.sh - Test with sample tasks:
python3 -m main --data_dir data/arc-agi/data/evaluation --provider new_provider --model new_model --task_id sample_task_id --print_logs
Remember to:
- Follow the existing patterns in other provider implementations
- Maintain consistent error handling
- Document any provider-specific requirements or limitations
- Update tests to cover the new provider
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for model_baseline
Similar Open Source Tools
model_baseline
This repository contains code for testing model baselines on ARC-AGI tasks. Users can test model baselines on ARC-AGI-1 and ARC-AGI-2 tasks, run single tasks, run tasks with concurrency, score submissions, and view historical results. Contributors can add more model adapters to the `src/adapters` folder. The repository also provides CLI usage for validation, uploading model outputs, bulk uploading, and Hugging Face integration for model submissions. Contributors can test new providers using the `test_providers.sh` script before submitting pull requests.

pentagi
PentAGI is an innovative tool for automated security testing that leverages cutting-edge artificial intelligence technologies. It is designed for information security professionals, researchers, and enthusiasts who need a powerful and flexible solution for conducting penetration tests. The tool provides secure and isolated operations in a sandboxed Docker environment, fully autonomous AI-powered agent for penetration testing steps, a suite of 20+ professional security tools, smart memory system for storing research results, web intelligence for gathering information, integration with external search systems, team delegation system, comprehensive monitoring and reporting, modern interface, API integration, persistent storage, scalable architecture, self-hosted solution, flexible authentication, and quick deployment through Docker Compose.
svelte-bench
SvelteBench is an LLM benchmark tool for evaluating Svelte components generated by large language models. It supports multiple LLM providers such as OpenAI, Anthropic, Google, and OpenRouter. Users can run predefined test suites to verify the functionality of the generated components. The tool allows configuration of API keys for different providers and offers debug mode for faster development. Users can provide a context file to improve component generation. Benchmark results are saved in JSON format for analysis and visualization.
forge
Forge is a powerful open-source tool for building modern web applications. It provides a simple and intuitive interface for developers to quickly scaffold and deploy projects. With Forge, you can easily create custom components, manage dependencies, and streamline your development workflow. Whether you are a beginner or an experienced developer, Forge offers a flexible and efficient solution for your web development needs.
askrepo
askrepo is a tool that reads the content of Git-managed text files in a specified directory, sends it to the Google Gemini API, and provides answers to questions based on a specified prompt. It acts as a question-answering tool for source code by using a Google AI model to analyze and provide answers based on the provided source code files. The tool leverages modules for file processing, interaction with the Google AI API, and orchestrating the entire process of extracting information from source code files.
action_mcp
Action MCP is a powerful tool for managing and automating your cloud infrastructure. It provides a user-friendly interface to easily create, update, and delete resources on popular cloud platforms. With Action MCP, you can streamline your deployment process, reduce manual errors, and improve overall efficiency. The tool supports various cloud providers and offers a wide range of features to meet your infrastructure management needs. Whether you are a developer, system administrator, or DevOps engineer, Action MCP can help you simplify and optimize your cloud operations.

paxml
Pax is a framework to configure and run machine learning experiments on top of Jax.
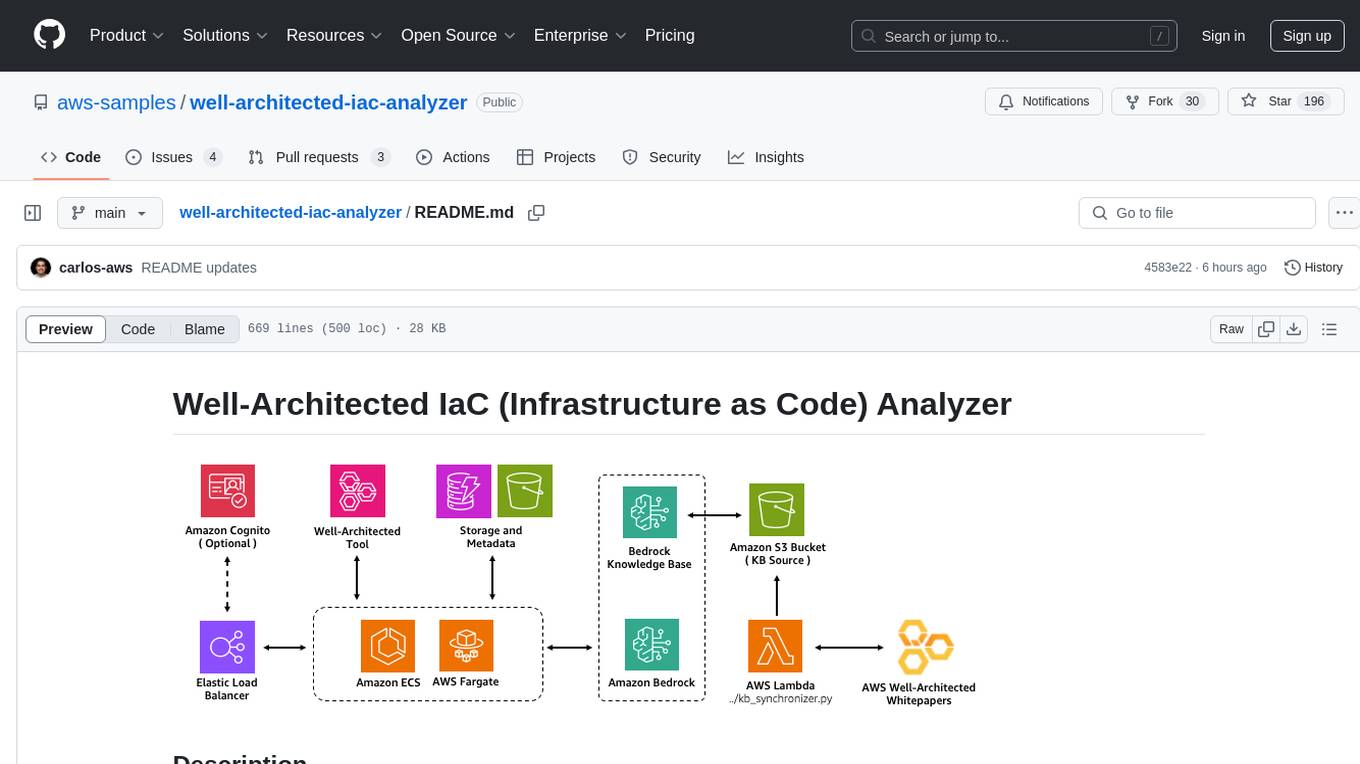
well-architected-iac-analyzer
Well-Architected Infrastructure as Code (IaC) Analyzer is a project demonstrating how generative AI can evaluate infrastructure code for alignment with best practices. It features a modern web application allowing users to upload IaC documents, complete IaC projects, or architecture diagrams for assessment. The tool provides insights into infrastructure code alignment with AWS best practices, offers suggestions for improving cloud architecture designs, and can generate IaC templates from architecture diagrams. Users can analyze CloudFormation, Terraform, or AWS CDK templates, architecture diagrams in PNG or JPEG format, and complete IaC projects with supporting documents. Real-time analysis against Well-Architected best practices, integration with AWS Well-Architected Tool, and export of analysis results and recommendations are included.
clickclickclick
ClickClickClick is a framework designed to enable autonomous Android and computer use using various LLM models, both locally and remotely. It supports tasks such as drafting emails, opening browsers, and starting games, with current support for local models via Ollama, Gemini, and GPT 4o. The tool is highly experimental and evolving, with the best results achieved using specific model combinations. Users need prerequisites like `adb` installation and USB debugging enabled on Android phones. The tool can be installed via cloning the repository, setting up a virtual environment, and installing dependencies. It can be used as a CLI tool or script, allowing users to configure planner and finder models for different tasks. Additionally, it can be used as an API to execute tasks based on provided prompts, platform, and models.
xGitGuard
xGitGuard is an AI-based system developed by Comcast Cybersecurity Research and Development team to detect secrets (e.g., API tokens, usernames, passwords) exposed on GitHub repositories. It uses advanced Natural Language Processing to detect secrets at scale and with appropriate velocity. The tool provides workflows for detecting credentials and keys/tokens in both enterprise and public GitHub accounts. Users can set up search patterns, configure API access, run detections with or without ML filters, and train ML models for improved detection accuracy. xGitGuard also supports custom keyword scans for targeted organizations or repositories. The tool is licensed under Apache 2.0.

LLM-Finetuning-Toolkit
LLM Finetuning toolkit is a config-based CLI tool for launching a series of LLM fine-tuning experiments on your data and gathering their results. It allows users to control all elements of a typical experimentation pipeline - prompts, open-source LLMs, optimization strategy, and LLM testing - through a single YAML configuration file. The toolkit supports basic, intermediate, and advanced usage scenarios, enabling users to run custom experiments, conduct ablation studies, and automate fine-tuning workflows. It provides features for data ingestion, model definition, training, inference, quality assurance, and artifact outputs, making it a comprehensive tool for fine-tuning large language models.
lightspeed-service
OpenShift LightSpeed (OLS) is an AI powered assistant that runs on OpenShift and provides answers to product questions using backend LLM services. It supports various LLM providers such as OpenAI, Azure OpenAI, OpenShift AI, RHEL AI, and Watsonx. Users can configure the service, manage API keys securely, and deploy it locally or on OpenShift. The project structure includes REST API handlers, configuration loader, LLM providers registry, and more. Additional tools include generating OpenAPI schema, requirements.txt file, and uploading artifacts to an S3 bucket. The project is open source under the Apache 2.0 License.
cursor-tools
cursor-tools is a CLI tool designed to enhance AI agents with advanced skills, such as web search, repository context, documentation generation, GitHub integration, Xcode tools, and browser automation. It provides features like Perplexity for web search, Gemini 2.0 for codebase context, and Stagehand for browser operations. The tool requires API keys for Perplexity AI and Google Gemini, and supports global installation for system-wide access. It offers various commands for different tasks and integrates with Cursor Composer for AI agent usage.
aicommits
AI Commits is a CLI tool that automates the process of writing git commit messages using AI technology. It allows users to generate commit messages based on their code changes, eliminating the need to manually write commit messages. The tool supports various AI providers such as TogetherAI, OpenAI, OpenRouter, Ollama, and LM Studio, as well as custom OpenAI-compatible endpoints. Users can configure the tool to select the AI provider, set API keys, and choose from available AI models. AI Commits can be used in CLI mode to generate commit messages for staged changes or integrated with Git via the prepare-commit-msg hook. Additionally, users can customize the commit message format, generate multiple recommendations, and manage configurations using environment variables or command-line options. The tool aims to streamline the git commit process by leveraging AI technology to provide meaningful and context-aware commit messages.

llama.vim
llama.vim is a plugin that provides local LLM-assisted text completion for Vim users. It offers features such as auto-suggest on cursor movement, manual suggestion toggling, suggestion acceptance with Tab and Shift+Tab, control over text generation time, context configuration, ring context with chunks from open and edited files, and performance stats display. The plugin requires a llama.cpp server instance to be running and supports FIM-compatible models. It aims to be simple, lightweight, and provide high-quality and performant local FIM completions even on consumer-grade hardware.
trickPrompt-engine
This repository contains a vulnerability mining engine based on GPT technology. The engine is designed to identify logic vulnerabilities in code by utilizing task-driven prompts. It does not require prior knowledge or fine-tuning and focuses on prompt design rather than model design. The tool is effective in real-world projects and should not be used for academic vulnerability testing. It supports scanning projects in various languages, with current support for Solidity. The engine is configured through prompts and environment settings, enabling users to scan for vulnerabilities in their codebase. Future updates aim to optimize code structure, add more language support, and enhance usability through command line mode. The tool has received a significant audit bounty of $50,000+ as of May 2024.
For similar tasks
model_baseline
This repository contains code for testing model baselines on ARC-AGI tasks. Users can test model baselines on ARC-AGI-1 and ARC-AGI-2 tasks, run single tasks, run tasks with concurrency, score submissions, and view historical results. Contributors can add more model adapters to the `src/adapters` folder. The repository also provides CLI usage for validation, uploading model outputs, bulk uploading, and Hugging Face integration for model submissions. Contributors can test new providers using the `test_providers.sh` script before submitting pull requests.
empirical
Empirical is a tool that allows you to test different LLMs, prompts, and other model configurations across all the scenarios that matter for your application. With Empirical, you can run your test datasets locally against off-the-shelf models, test your own custom models and RAG applications, view, compare, and analyze outputs on a web UI, score your outputs with scoring functions, and run tests on CI/CD.
truss
Truss is a tool that simplifies the process of serving AI/ML models in production. It provides a consistent and easy-to-use interface for packaging, testing, and deploying models, regardless of the framework they were created with. Truss also includes a live reload server for fast feedback during development, and a batteries-included model serving environment that eliminates the need for Docker and Kubernetes configuration.

LLMinator
LLMinator is a Gradio-based tool with an integrated chatbot designed to locally run and test Language Model Models (LLMs) directly from HuggingFace. It provides an easy-to-use interface made with Gradio, LangChain, and Torch, offering features such as context-aware streaming chatbot, inbuilt code syntax highlighting, loading any LLM repo from HuggingFace, support for both CPU and CUDA modes, enabling LLM inference with llama.cpp, and model conversion capabilities.

onnxruntime-server
ONNX Runtime Server is a server that provides TCP and HTTP/HTTPS REST APIs for ONNX inference. It aims to offer simple, high-performance ML inference and a good developer experience. Users can provide inference APIs for ONNX models without writing additional code by placing the models in the directory structure. Each session can choose between CPU or CUDA, analyze input/output, and provide Swagger API documentation for easy testing. Ready-to-run Docker images are available, making it convenient to deploy the server.

llm-vscode
llm-vscode is an extension designed for all things LLM, utilizing llm-ls as its backend. It offers features such as code completion with 'ghost-text' suggestions, the ability to choose models for code generation via HTTP requests, ensuring prompt size fits within the context window, and code attribution checks. Users can configure the backend, suggestion behavior, keybindings, llm-ls settings, and tokenization options. Additionally, the extension supports testing models like Code Llama 13B, Phind/Phind-CodeLlama-34B-v2, and WizardLM/WizardCoder-Python-34B-V1.0. Development involves cloning llm-ls, building it, and setting up the llm-vscode extension for use.

mistral-inference
Mistral Inference repository contains minimal code to run 7B, 8x7B, and 8x22B models. It provides model download links, installation instructions, and usage guidelines for running models via CLI or Python. The repository also includes information on guardrailing, model platforms, deployment, and references. Users can interact with models through commands like mistral-demo, mistral-chat, and mistral-common. Mistral AI models support function calling and chat interactions for tasks like testing models, chatting with models, and using Codestral as a coding assistant. The repository offers detailed documentation and links to blogs for further information.

llm-on-ray
LLM-on-Ray is a comprehensive solution for building, customizing, and deploying Large Language Models (LLMs). It simplifies complex processes into manageable steps by leveraging the power of Ray for distributed computing. The tool supports pretraining, finetuning, and serving LLMs across various hardware setups, incorporating industry and Intel optimizations for performance. It offers modular workflows with intuitive configurations, robust fault tolerance, and scalability. Additionally, it provides an Interactive Web UI for enhanced usability, including a chatbot application for testing and refining models.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.