
cifar10-airbench
94% on CIFAR-10 in 2.67 seconds 💨 96% in 27 seconds
Stars: 147
CIFAR-10 Airbench is a project offering fast and stable training baselines for CIFAR-10 dataset, facilitating machine learning research. It provides easily runnable PyTorch scripts for training neural networks with high accuracy levels. The methods used in this project aim to accelerate research on fundamental properties of deep learning. The project includes GPU-accelerated dataloader for custom experiments and trainings, and can be used for data selection and active learning experiments. The training methods provided are faster than standard ResNet training, offering improved performance for research projects.
README:
A collection of fast and self-contained training scripts for CIFAR-10.
| Script | Mean accuracy | Time | PFLOPs |
|---|---|---|---|
airbench94_compiled.py |
94.01% | 3.09s | 0.36 |
airbench94.py |
94.01% | 3.83s | 0.36 |
airbench95.py |
95.01% | 10.4s | 1.4 |
airbench96.py |
96.03% | 34.7s | 4.9 |
airbench94_muon.py |
94.05% | 2.67s | 0.29 |
airbench96_faster.py |
96.00% | 27.3s | 3.1 |
For a comparison, the standard training used in most studies on CIFAR-10 is much slower:
| Baseline | Mean accuracy | Time | PFLOPs |
|---|---|---|---|
| Standard ResNet-18 training | 96% | 7min | 32.3 |
All timings are on a single NVIDIA A100 GPU.
Note: airbench96 has been improved since the paper from 46s to 35s. In addition, airbench96_faster is an improved (but more complicated) method which uses data filtering by a small proxy model.
And airbench94_muon is an improved method using a variant of the Muon optimizer.
The set of methods used to obtain these training speeds are described in the paper.


To train a neural network with 94% accuracy, run either
git clone https://github.com/KellerJordan/cifar10-airbench.git
cd airbench && python airbench94.py
or
pip install airbench
python -c "import airbench; airbench.warmup94(); airbench.train94()"
Note: airbench94_compiled.py and airbench94.py are equivalent (i.e., yield the same distribution of trained networks), and differ only in that the first uses torch.compile to improve GPU utilization. The former is intended for experiments where many networks are trained at once in order to amortize the one-time compilation cost.
CIFAR-10 is one of the most widely used datasets in machine learning, facilitating thousands of research projects per year. This repo provides fast and stable training baselines for CIFAR-10 in order to help accelerate this research. The trainings are provided as easily runnable dependency-free PyTorch scripts, and can replace classic baselines like training ResNet-20 or ResNet-18.
For writing custom CIFAR-10 experiments or trainings, you may find it useful to use the GPU-accelerated dataloader independently.
import airbench
train_loader = airbench.CifarLoader('/tmp/cifar10', train=True, aug=dict(flip=True, translate=4, cutout=16), batch_size=500)
test_loader = airbench.CifarLoader('/tmp/cifar10', train=False, batch_size=1000)
for epoch in range(200):
for inputs, labels in train_loader:
# outputs = model(inputs)
# loss = F.cross_entropy(outputs, labels)
...
If you wish to modify the data in the loader, it can be done like so:
import airbench
train_loader = airbench.CifarLoader('/tmp/cifar10', train=True, aug=dict(flip=True, translate=4, cutout=16), batch_size=500)
mask = (train_loader.labels < 6) # (this is just an example, the mask can be anything)
train_loader.images = train_loader.images[mask]
train_loader.labels = train_loader.labels[mask]
print(len(train_loader)) # The loader now contains 30,000 images and has batch size 500, so this prints 60.
Airbench can be used as a platform for experiments in data selection and active learning. The following is an example experiment which demonstrates the classic result that low-confidence examples provide more training signal than random examples. It runs in <20 seconds on an A100.
import torch
from airbench import train94, infer, evaluate, CifarLoader
net = train94(label_smoothing=0) # train this network without label smoothing to get a better confidence signal
loader = CifarLoader('cifar10', train=True, batch_size=1000)
logits = infer(net, loader)
conf = logits.log_softmax(1).amax(1) # confidence
train_loader = CifarLoader('cifar10', train=True, batch_size=1024, aug=dict(flip=True, translate=2))
mask = (torch.rand(len(train_loader.labels)) < 0.6)
print('Training on %d images selected randomly' % mask.sum())
train_loader.images = train_loader.images[mask]
train_loader.labels = train_loader.labels[mask]
train94(train_loader, epochs=16) # yields around 93% accuracy
train_loader = CifarLoader('cifar10', train=True, batch_size=1024, aug=dict(flip=True, translate=2))
mask = (conf < conf.float().quantile(0.6))
print('Training on %d images selected based on minimum confidence' % mask.sum())
train_loader.images = train_loader.images[mask]
train_loader.labels = train_loader.labels[mask]
train94(train_loader, epochs=16) # yields around 94% accuracy => low-confidence sampling is better than random.
This project builds on the excellent previous record https://github.com/tysam-code/hlb-CIFAR10 (6.3 A100-seconds to 94%).
Which itself builds on the amazing series https://myrtle.ai/learn/how-to-train-your-resnet/ (26 V100-seconds to 94%, which is >=8 A100-seconds)
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for cifar10-airbench
Similar Open Source Tools
cifar10-airbench
CIFAR-10 Airbench is a project offering fast and stable training baselines for CIFAR-10 dataset, facilitating machine learning research. It provides easily runnable PyTorch scripts for training neural networks with high accuracy levels. The methods used in this project aim to accelerate research on fundamental properties of deep learning. The project includes GPU-accelerated dataloader for custom experiments and trainings, and can be used for data selection and active learning experiments. The training methods provided are faster than standard ResNet training, offering improved performance for research projects.

pytorch-grad-cam
This repository provides advanced AI explainability for PyTorch, offering state-of-the-art methods for Explainable AI in computer vision. It includes a comprehensive collection of Pixel Attribution methods for various tasks like Classification, Object Detection, Semantic Segmentation, and more. The package supports high performance with full batch image support and includes metrics for evaluating and tuning explanations. Users can visualize and interpret model predictions, making it suitable for both production and model development scenarios.

cambrian
Cambrian-1 is a fully open project focused on exploring multimodal Large Language Models (LLMs) with a vision-centric approach. It offers competitive performance across various benchmarks with models at different parameter levels. The project includes training configurations, model weights, instruction tuning data, and evaluation details. Users can interact with Cambrian-1 through a Gradio web interface for inference. The project is inspired by LLaVA and incorporates contributions from Vicuna, LLaMA, and Yi. Cambrian-1 is licensed under Apache 2.0 and utilizes datasets and checkpoints subject to their respective original licenses.

Cherry_LLM
Cherry Data Selection project introduces a self-guided methodology for LLMs to autonomously discern and select cherry samples from open-source datasets, minimizing manual curation and cost for instruction tuning. The project focuses on selecting impactful training samples ('cherry data') to enhance LLM instruction tuning by estimating instruction-following difficulty. The method involves phases like 'Learning from Brief Experience', 'Evaluating Based on Experience', and 'Retraining from Self-Guided Experience' to improve LLM performance.

BetaML.jl
The Beta Machine Learning Toolkit is a package containing various algorithms and utilities for implementing machine learning workflows in multiple languages, including Julia, Python, and R. It offers a range of supervised and unsupervised models, data transformers, and assessment tools. The models are implemented entirely in Julia and are not wrappers for third-party models. Users can easily contribute new models or request implementations. The focus is on user-friendliness rather than computational efficiency, making it suitable for educational and research purposes.

Qwen
Qwen is a series of large language models developed by Alibaba DAMO Academy. It outperforms the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen models outperform the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen-72B achieves better performance than LLaMA2-70B on all tasks and outperforms GPT-3.5 on 7 out of 10 tasks.

moatless-tools
Moatless Tools is a hobby project focused on experimenting with using Large Language Models (LLMs) to edit code in large existing codebases. The project aims to build tools that insert the right context into prompts and handle responses effectively. It utilizes an agentic loop functioning as a finite state machine to transition between states like Search, Identify, PlanToCode, ClarifyChange, and EditCode for code editing tasks.

cladder
CLadder is a repository containing the CLadder dataset for evaluating causal reasoning in language models. The dataset consists of yes/no questions in natural language that require statistical and causal inference to answer. It includes fields such as question_id, given_info, question, answer, reasoning, and metadata like query_type and rung. The dataset also provides prompts for evaluating language models and example questions with associated reasoning steps. Additionally, it offers dataset statistics, data variants, and code setup instructions for using the repository.

DB-GPT-Hub
DB-GPT-Hub is an experimental project leveraging Large Language Models (LLMs) for Text-to-SQL parsing. It includes stages like data collection, preprocessing, model selection, construction, and fine-tuning of model weights. The project aims to enhance Text-to-SQL capabilities, reduce model training costs, and enable developers to contribute to improving Text-to-SQL accuracy. The ultimate goal is to achieve automated question-answering based on databases, allowing users to execute complex database queries using natural language descriptions. The project has successfully integrated multiple large models and established a comprehensive workflow for data processing, SFT model training, prediction output, and evaluation.

Consistency_LLM
Consistency Large Language Models (CLLMs) is a family of efficient parallel decoders that reduce inference latency by efficiently decoding multiple tokens in parallel. The models are trained to perform efficient Jacobi decoding, mapping any randomly initialized token sequence to the same result as auto-regressive decoding in as few steps as possible. CLLMs have shown significant improvements in generation speed on various tasks, achieving up to 3.4 times faster generation. The tool provides a seamless integration with other techniques for efficient Large Language Model (LLM) inference, without the need for draft models or architectural modifications.
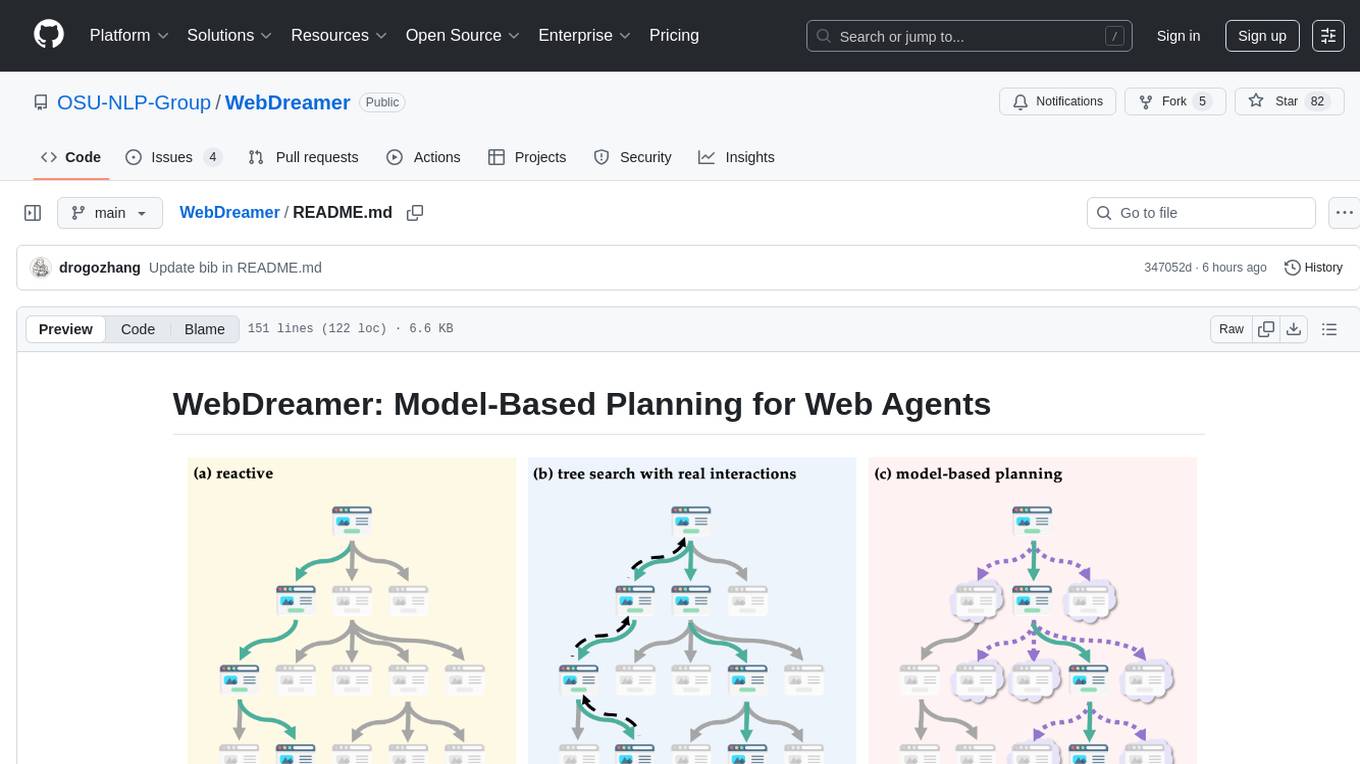
WebDreamer
WebDreamer is a model-based planning tool for web agents that uses large language models (LLMs) as a world model of the internet to predict outcomes of actions on websites. It employs LLM-based simulation for speculative planning on the web, offering greater safety and flexibility compared to traditional tree search methods. The tool provides modules for world model prediction, simulation scoring, and controller actions, enabling users to interact with web pages and achieve specific goals through simulated actions.

edsl
The Expected Parrot Domain-Specific Language (EDSL) package enables users to conduct computational social science and market research with AI. It facilitates designing surveys and experiments, simulating responses using large language models, and performing data labeling and other research tasks. EDSL includes built-in methods for analyzing, visualizing, and sharing research results. It is compatible with Python 3.9 - 3.11 and requires API keys for LLMs stored in a `.env` file.
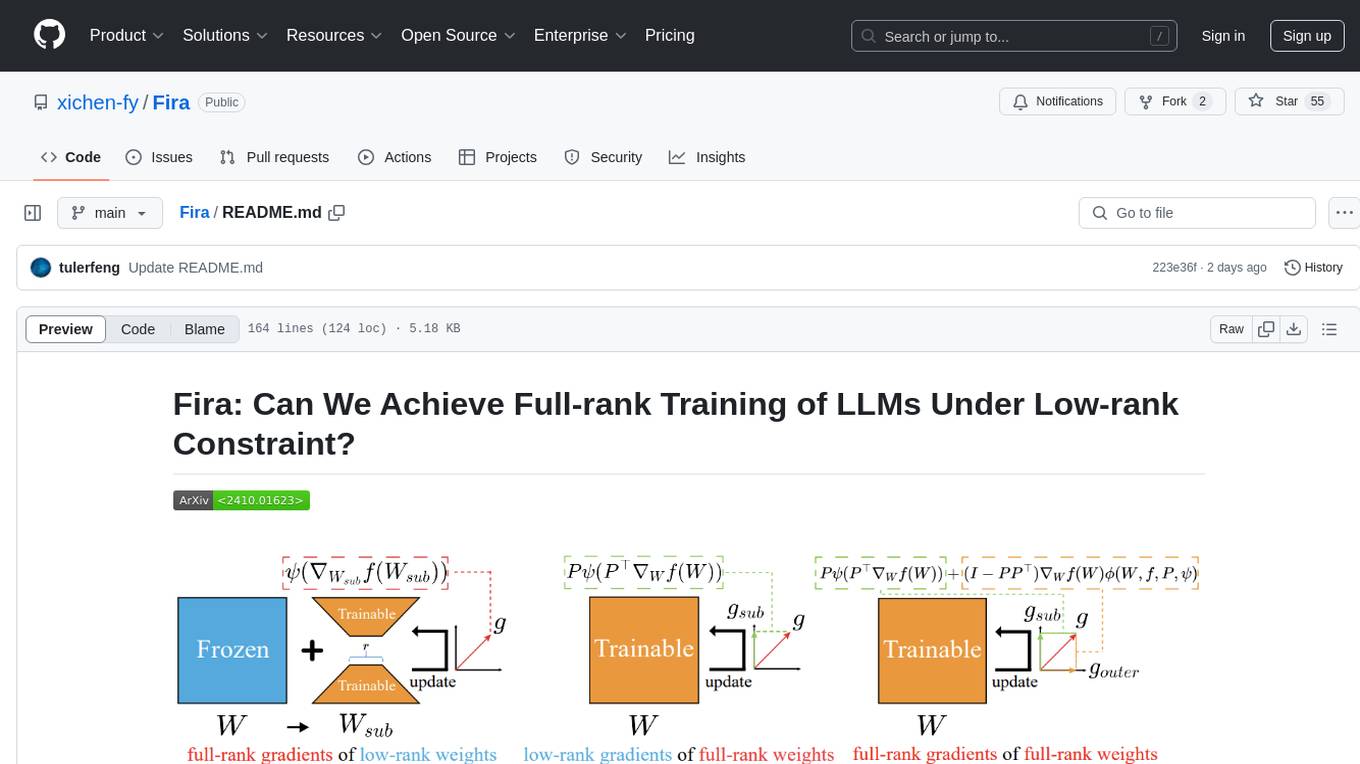
Fira
Fira is a memory-efficient training framework for Large Language Models (LLMs) that enables full-rank training under low-rank constraint. It introduces a method for training with full-rank gradients of full-rank weights, achieved with just two lines of equations. The framework includes pre-training and fine-tuning functionalities, packaged as a Python library for easy use. Fira utilizes Adam optimizer by default and provides options for weight decay. It supports pre-training LLaMA models on the C4 dataset and fine-tuning LLaMA-7B models on commonsense reasoning tasks.

LLM-Pruner
LLM-Pruner is a tool for structural pruning of large language models, allowing task-agnostic compression while retaining multi-task solving ability. It supports automatic structural pruning of various LLMs with minimal human effort. The tool is efficient, requiring only 3 minutes for pruning and 3 hours for post-training. Supported LLMs include Llama-3.1, Llama-3, Llama-2, LLaMA, BLOOM, Vicuna, and Baichuan. Updates include support for new LLMs like GQA and BLOOM, as well as fine-tuning results achieving high accuracy. The tool provides step-by-step instructions for pruning, post-training, and evaluation, along with a Gradio interface for text generation. Limitations include issues with generating repetitive or nonsensical tokens in compressed models and manual operations for certain models.

AQLM
AQLM is the official PyTorch implementation for Extreme Compression of Large Language Models via Additive Quantization. It includes prequantized AQLM models without PV-Tuning and PV-Tuned models for LLaMA, Mistral, and Mixtral families. The repository provides inference examples, model details, and quantization setups. Users can run prequantized models using Google Colab examples, work with different model families, and install the necessary inference library. The repository also offers detailed instructions for quantization, fine-tuning, and model evaluation. AQLM quantization involves calibrating models for compression, and users can improve model accuracy through finetuning. Additionally, the repository includes information on preparing models for inference and contributing guidelines.

AI-Toolbox
AI-Toolbox is a C++ library aimed at representing and solving common AI problems, with a focus on MDPs, POMDPs, and related algorithms. It provides an easy-to-use interface that is extensible to many problems while maintaining readable code. The toolbox includes tutorials for beginners in reinforcement learning and offers Python bindings for seamless integration. It features utilities for combinatorics, polytopes, linear programming, sampling, distributions, statistics, belief updating, data structures, logging, seeding, and more. Additionally, it supports bandit/normal games, single agent MDP/stochastic games, single agent POMDP, and factored/joint multi-agent scenarios.
For similar tasks
cifar10-airbench
CIFAR-10 Airbench is a project offering fast and stable training baselines for CIFAR-10 dataset, facilitating machine learning research. It provides easily runnable PyTorch scripts for training neural networks with high accuracy levels. The methods used in this project aim to accelerate research on fundamental properties of deep learning. The project includes GPU-accelerated dataloader for custom experiments and trainings, and can be used for data selection and active learning experiments. The training methods provided are faster than standard ResNet training, offering improved performance for research projects.

nntrainer
NNtrainer is a software framework for training neural network models on devices with limited resources. It enables on-device fine-tuning of neural networks using user data for personalization. NNtrainer supports various machine learning algorithms and provides examples for tasks such as few-shot learning, ResNet, VGG, and product rating. It is optimized for embedded devices and utilizes CBLAS and CUBLAS for accelerated calculations. NNtrainer is open source and released under the Apache License version 2.0.
uvadlc_notebooks
The UvA Deep Learning Tutorials repository contains a series of Jupyter notebooks designed to help understand theoretical concepts from lectures by providing corresponding implementations. The notebooks cover topics such as optimization techniques, transformers, graph neural networks, and more. They aim to teach details of the PyTorch framework, including PyTorch Lightning, with alternative translations to JAX+Flax. The tutorials are integrated as official tutorials of PyTorch Lightning and are relevant for graded assignments and exams.
Deej-AI
Deej-A.I. is an advanced machine learning project that aims to revolutionize music recommendation systems by using artificial intelligence to analyze and recommend songs based on their content and characteristics. The project involves scraping playlists from Spotify, creating embeddings of songs, training neural networks to analyze spectrograms, and generating recommendations based on similarities in music features. Deej-A.I. offers a unique approach to music curation, focusing on the 'what' rather than the 'how' of DJing, and providing users with personalized and creative music suggestions.
awesome-ai
Awesome AI is a curated list of artificial intelligence resources including courses, tools, apps, and open-source projects. It covers a wide range of topics such as machine learning, deep learning, natural language processing, robotics, conversational interfaces, data science, and more. The repository serves as a comprehensive guide for individuals interested in exploring the field of artificial intelligence and its applications across various domains.
netsaur
Netsaur is a powerful machine learning library for Deno, offering a lightweight and easy-to-use neural network solution. It is blazingly fast and efficient, providing a simple API for creating and training neural networks. Netsaur can run on both CPU and GPU, making it suitable for serverless environments. With Netsaur, users can quickly build and deploy machine learning models for various applications with minimal dependencies. This library is perfect for both beginners and experienced machine learning practitioners.
ai-algorithms
This repository is a work in progress that contains first-principle implementations of groundbreaking AI algorithms using various deep learning frameworks. Each implementation is accompanied by supporting research papers, aiming to provide comprehensive educational resources for understanding and implementing foundational AI algorithms from scratch.
sharpneat
SharpNEAT is a complete implementation of NEAT written in C# and targeting .NET 9. It provides an implementation of an Evolutionary Algorithm (EA) with the specific goal of evolving a population of neural networks towards solving some goal problem task. The framework facilitates research into evolutionary computation and specifically evolution of neural networks, allowing for modular experimentation with genetic coding and evolutionary algorithms.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.