
LLM-as-a-Judge
None
Stars: 79
LLM-as-a-Judge is a repository that includes papers discussed in a survey paper titled 'A Survey on LLM-as-a-Judge'. The repository covers various aspects of using Large Language Models (LLMs) as judges for tasks such as evaluation, reasoning, and decision-making. It provides insights into evaluation pipelines, improvement strategies, and specific tasks related to LLMs. The papers included in the repository explore different methodologies, applications, and future research directions for leveraging LLMs as evaluators in various domains.
README:

🌻 Homepage • 📖 Paper List • 📊 Meta-eval • 🌟 Arxiv • 🔗 Talk
This repo include the papers discussed in our survey paper A Survey on LLM-as-a-Judge
Feel free to cite if you find our survey is useful for your research:
@article{gu2024surveyllmasajudge,
title = {A Survey on LLM-as-a-Judge},
author = {Jiawei Gu and Xuhui Jiang and Zhichao Shi and Hexiang Tan and Xuehao Zhai and Chengjin Xu and Wei Li and Yinghan Shen and Shengjie Ma and Honghao Liu and Yuanzhuo Wang and Jian Guo},
year = {2024},
journal = {arXiv preprint arXiv: 2411.15594}
}
🔥 [2025-01-28] We added analysis on LLM-as-a-Judge and o1-like Reasoning Enhancement, as well as meta-evaluation results on o1-mini, Gemini-2.0-Flash-Thinking-1219, and DeepSeek-R1!
🌟 [2025-01-16] We shared and discussed the methodologies, applications (Finance, RAG, and Synthetic Data), and future research directions of LLM-as-a-Judge at BAAI Talk! 🤗 [Replay] [Methodology] [RAG & Synthetic Data]
🚀 [2024-11-23] We released A Survey on LLM-as-a-Judge, exploring LLMs as reliable, scalable evaluators and outlining key challenges and future directions!



- Reference
- Overview of LLM-as-a-Judge
- Evaluation Pipelines of LLM-as-a-Judge
- Improvement Strategies for LLM-as-a-Judge
- Table of Content
-
Paper List
- 1 What is LLM-as-a-Judge?
- 2 How to use LLM-as-a-Judge?
- 3 How to improve LLM-as-a-Judge?
-
A Multi-Aspect Framework for Counter Narrative Evaluation using Large Language Models
NAACL2024Jaylen Jones, Lingbo Mo, Eric Fosler-Lussier, and Huan Sun. [Paper]
-
Generative judge for evaluating alignment.
ArXiv preprint2023Junlong Li, Shichao Sun, Weizhe Yuan, Run-Ze Fan, Hai Zhao, and Pengfei Liu. [Paper]
-
Judgelm: Fine-tuned large language models are scalable judges.
ArXiv preprint2023Lianghui Zhu, Xinggang Wang, and Xinlong Wang. [Paper]
-
Large Language Models are Better Reasoners with Self-Verification.
EMNLP findings2023Yixuan Weng, Minjun Zhu, Fei Xia, Bin Li, Shizhu He, Shengping Liu, Bin Sun, Kang Liu, and Jun Zhao. [Paper]
-
Benchmarking Foundation Models with Language-Model-as-an-Examiner.
NeurIPS2023Yushi Bai, Jiahao Ying, Yixin Cao, Xin Lv, Yuze He, Xiaozhi Wang, Jifan Yu, Kaisheng Zeng, Yijia Xiao, Haozhe Lyu, Jiayin Zhang, Juanzi Li, and Lei Hou. [Paper]
-
Human-like summarization evaluation with chatgpt.
ArXiv preprint2023Mingqi Gao, Jie Ruan, Renliang Sun, Xunjian Yin, Shiping Yang, and Xiaojun Wan. [Paper]
-
Reflexion: language agents with verbal reinforcement learning.
NeurIPS2023Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. [Paper]
-
MacGyver: Are Large Language Models Creative Problem Solvers?
NAACL2024Yufei Tian, Abhilasha Ravichander, Lianhui Qin, Ronan Le Bras, Raja Marjieh, Nanyun Peng, Yejin Choi, Thomas Griffiths, and Faeze Brahman. [Paper]
-
Think-on-graph: Deep and responsible reasoning of large language model with knowledge graph.
ArXiv preprint2023Jiashuo Sun, Chengjin Xu, Lumingyuan Tang, Saizhuo Wang, Chen Lin, Yeyun Gong, Heung-Yeung Shum, and Jian Guo. [Paper]
-
Large Language Models are Effective Text Rankers with Pairwise Ranking Prompting.
NAACL findings2024Zhen Qin, Rolf Jagerman, Kai Hui, Honglei Zhuang, Junru Wu, Le Yan, Jiaming Shen, Tianqi Liu, Jialu Liu, Donald Metzler, Xuanhui Wang, and Michael Bendersky. [Papaer]
-
**Aligning with human judgement: The role of pairwise preference in large language model evaluators. **
COLM2024Yinhong Liu, Han Zhou, Zhijiang Guo, Ehsan Shareghi, Ivan Vulic, Anna Korhonen, and Nigel Collier. [Paper]
-
LLM Comparative Assessment: Zero-shot NLG Evaluation through Pairwise Comparisons using Large Language Models.
EACL2024Adian Liusie, Potsawee Manakul, and Mark Gales. [Paper]
-
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena.
NeurIPS2023Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. [Paper]
-
Rrhf: Rank responses to align language models with human feedback without tears.
ArXiv preprint2023Zheng Yuan, Hongyi Yuan, Chuanqi Tan, Wei Wang, Songfang Huang, and Fei Huang. [Paper]
-
PandaLM: An Automatic Evaluation Benchmark for LLM Instruction Tuning Optimization.
ArXiv preprint2023Yidong Wang, Zhuohao Yu, Zhengran Zeng, Linyi Yang, Cunxiang Wang, Hao Chen, Chaoya Jiang, Rui Xie, Jindong Wang, Xing Xie, et al. 2023. [Paper]
-
Human-like summarization evaluation with chatgpt.
ArXiv preprint2023Mingqi Gao, Jie Ruan, Renliang Sun, Xunjian Yin, Shiping Yang, and Xiaojun Wan. [Paper]
-
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena.
NeurIPS2023Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. [Paper]
-
AlpacaEval: An Automatic Evaluator of Instruction-following Models.
2023Xuechen Li, Tianyi Zhang, Yann Dubois, Rohan Taori, Ishaan Gulrajani, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. [Code]
-
PandaLM: An Automatic Evaluation Benchmark for LLM Instruction Tuning Optimization.
ArXiv preprint2023Yidong Wang, Zhuohao Yu, Zhengran Zeng, Linyi Yang, Cunxiang Wang, Hao Chen, Chaoya Jiang, Rui Xie, Jindong Wang, Xing Xie, et al. 2023. [Paper]
-
Judgelm: Fine-tuned large language models are scalable judges.
ArXiv preprint2023Lianghui Zhu, Xinggang Wang, and Xinlong Wang. [Paper]
-
Generative judge for evaluating alignment.
ArXiv preprint2023Junlong Li, Shichao Sun, Weizhe Yuan, Run-Ze Fan, Hai Zhao, and Pengfei Liu. [Paper]
-
Prometheus: Inducing Fine-grained Evaluation Capability in Language Models.
ArXiv preprint2023Seungone Kim, Jamin Shin, Yejin Cho, Joel Jang, Shayne Longpre, Hwaran Lee, Sangdoo Yun, Seongjin Shin, Sungdong Kim, James Thorne, et al. [Paper]
-
xFinder: Robust and Pinpoint Answer Extraction for Large Language Models.
ArXiv preprint2024Qingchen Yu, Zifan Zheng, Shichao Song, Zhiyu Li, Feiyu Xiong, Bo Tang, and Ding Chen. [Paper]
-
MacGyver: Are Large Language Models Creative Problem Solvers?
NAACL2024Yufei Tian, Abhilasha Ravichander, Lianhui Qin, Ronan Le Bras, Raja Marjieh, Nanyun Peng, Yejin Choi, Thomas Griffiths, and Faeze Brahman. [Paper]
-
Guiding LLMs the right way: fast, non-invasive constrained generation.
ICML2024Luca Beurer-Kellner, Marc Fischer, and Martin Vechev. [Paper]
-
XGrammar: Flexible and Efficient Structured Generation Engine for Large Language Models.
ArXiv preprint2024Yixin Dong, Charlie F. Ruan, Yaxing Cai, Ruihang Lai, Ziyi Xu, Yilong Zhao, and Tianqi Chen. [Paper]
-
SGLang: Efficient Execution of Structured Language Model Programs.
NeurIPS2025Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. [Paper]
-
Reasoning with Language Model is Planning with World Model.
EMNLP2023Shibo Hao, Yi Gu, Haodi Ma, Joshua Hong, Zhen Wang, Daisy Wang, and Zhiting Hu. [Paper]
-
Speculative rag: Enhancing retrieval augmented generation through drafting.
ArXiv preprint2024Zilong Wang, Zifeng Wang, Long Le, Huaixiu Steven Zheng, Swaroop Mishra, Vincent Perot, Yuwei Zhang, Anush Mattapalli, Ankur Taly, Jingbo Shang, et al. [Paper]
-
**Agent-as-a-Judge: Evaluate Agents with Agents. **
ArXiv preprint2024Mingchen Zhuge, Changsheng Zhao, Dylan Ashley, Wenyi Wang, Dmitrii Khizbullin, Yunyang Xiong, Zechun Liu, Ernie Chang, Raghuraman Krishnamoorthi, Yuandong Tian, et al. [Paper]
-
Reasoning with Language Model is Planning with World Model.
EMNLP2023Shibo Hao, Yi Gu, Haodi Ma, Joshua Hong, Zhen Wang, Daisy Wang, and Zhiting Hu. [Paper]
-
AlpacaFarm: A Simulation Framework for Methods that Learn from Human Feedback.
NeurIPS2023Yann Dubois, Chen Xuechen Li, Rohan Taori, Tianyi Zhang, Ishaan Gulrajani, Jimmy Ba, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. [Paper]
-
Large language models are not fair evaluators.
ACL2024Peiyi Wang, Lei Li, Liang Chen, Dawei Zhu, Binghuai Lin, Yunbo Cao, Qi Liu, Tianyu Liu, and Zhifang Sui. [Paper]
-
Wider and deeper llm networks are fairer llm evaluators.
ArXiv preprint2023Xinghua Zhang, Bowen Yu, Haiyang Yu, Yangyu Lv, Tingwen Liu, Fei Huang, Hongbo Xu, and Yongbin Li. [Paper]
-
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena.
NeurIPS2023Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. [Paper]
-
**SelFee: Iterative Self-Revising LLM Empowered by Self-Feedback Generation. **
Blog2023Seonghyeon Ye, Yongrae Jo, Doyoung Kim, Sungdong Kim, Hyeonbin Hwang, and Minjoon Seo. [Blog]
-
Shepherd: A Critic for Language Model Generation.
ArXiv preprint2023Tianlu Wang, Ping Yu, Xiaoqing Ellen Tan, Sean O’Brien, Ramakanth Pasunuru, Jane Dwivedi-Yu, Olga Golovneva, Luke Zettlemoyer, Maryam Fazel-Zarandi, and Asli Celikyilmaz. [Paper]
-
PandaLM: An Automatic Evaluation Benchmark for LLM Instruction Tuning Optimization.
ArXiv preprint2023Yidong Wang, Zhuohao Yu, Zhengran Zeng, Linyi Yang, Cunxiang Wang, Hao Chen, Chaoya Jiang, Rui Xie, Jindong Wang, Xing Xie, et al. 2023. [Paper]
-
RAFT: Reward rAnked FineTuning for Generative Foundation Model Alignment.
ArXiv preprint2023Hanze Dong, Wei Xiong, Deepanshu Goyal, Rui Pan, Shizhe Diao, Jipeng Zhang, Kashun Shum, and Tong Zhang. [Paper]
-
Rrhf: Rank responses to align language models with human feedback without tears.
ArXiv preprint2023Zheng Yuan, Hongyi Yuan, Chuanqi Tan, Wei Wang, Songfang Huang, and Fei Huang. [Paper]
-
Stanford Alpaca: An Instruction-following LLaMA model.
2023Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. [Code]
-
Languages are rewards: Hindsight finetuning using human feedback.
ArXiv preprint2023Hao Liu, Carmelo Sferrazza, and Pieter Abbeel. [Paper]
-
The Wisdom of Hindsight Makes Language Models Better Instruction Followers.
PMLR2023Tianjun Zhang, Fangchen Liu, Justin Wong, Pieter Abbeel, and Joseph E. Gonzalez. [Paper]
-
**Principle-Driven Self-Alignment of Language Models from Scratch with Minimal Human Supervision. **
NeurIPS2023Zhiqing Sun, Yikang Shen, Qinhong Zhou, Hongxin Zhang, Zhenfang Chen, David D. Cox, Yiming Yang, and Chuang Gan. [Paper]
-
Wizardmath: Empowering mathematical reasoning for large language models via
**reinforced evol-instruct. **
ArXiv preprint2023Haipeng Luo, Qingfeng Sun, Can Xu, Pu Zhao, Jianguang Lou, Chongyang Tao, Xiubo Geng, Qingwei Lin, Shifeng Chen, and Dongmei Zhang. [Paper]
-
Self-taught evaluators.
ArXiv preprint2024Tianlu Wang, Ilia Kulikov, Olga Golovneva, Ping Yu, Weizhe Yuan, Jane Dwivedi-Yu, Richard Yuanzhe Pang, Maryam Fazel-Zarandi, Jason Weston, and Xian Li. [Paper]
-
Holistic analysis of hallucination in gpt-4v (ision): Bias and interference challenges.
ArXiv preprint2023Chenhang Cui, Yiyang Zhou, Xinyu Yang, Shirley Wu, Linjun Zhang, James Zou, and Huaxiu Yao. [Paper]
-
Evaluating Object Hallucination in Large Vision-Language Models.
EMNLP2023Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen. [Paper]
-
Evaluation and analysis of hallucination in large vision-language models.
ArXiv preprint2023Junyang Wang, Yiyang Zhou, Guohai Xu, Pengcheng Shi, Chenlin Zhao, Haiyang Xu, Qinghao Ye, Ming Yan, Ji Zhang, Jihua Zhu, et al. [Paper]
-
Aligning large multimodal models with factually augmented rlhf.
ArXiv preprint2023Zhiqing Sun, Sheng Shen, Shengcao Cao, Haotian Liu, Chunyuan Li, Yikang Shen, Chuang Gan, Liang-Yan Gui, Yu-Xiong Wang, Yiming Yang, et al. [Paper]
-
MLLM-as-a-Judge: Assessing Multimodal LLM-as-a-Judge with Vision-Language Benchmark.
ICML2024Dongping Chen, Ruoxi Chen, Shilin Zhang, Yaochen Wang, Yinuo Liu, Huichi Zhou, Qihui Zhang, Yao Wan, Pan Zhou, and Lichao Sun. [Paper]
-
**Agent-as-a-Judge: Evaluate Agents with Agents. **
ArXiv preprint2024Mingchen Zhuge, Changsheng Zhao, Dylan Ashley, Wenyi Wang, Dmitrii Khizbullin, Yunyang Xiong, Zechun Liu, Ernie Chang, Raghuraman Krishnamoorthi, Yuandong Tian, et al. [Paper]
-
Reasoning with Language Model is Planning with World Model.
EMNLP2023Shibo Hao, Yi Gu, Haodi Ma, Joshua Hong, Zhen Wang, Daisy Wang, and Zhiting Hu. [Paper]
-
Reflexion: language agents with verbal reinforcement learning.
NeurIPS2023Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. [Paper]
-
Towards Reasoning in Large Language Models: A Survey.
ACL findings2023Jie Huang and Kevin Chen-Chuan Chang. [Paper]
-
Let’s verify step by step.
ICLR2023Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. [Paper]
-
FActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation.
EMNLP2023Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. [Paper]
-
SALAD-Bench: A Hierarchical and Comprehensive Safety Benchmark for Large Language Models.
ACL findings2024Lijun Li, Bowen Dong, Ruohui Wang, Xuhao Hu, Wangmeng Zuo, Dahua Lin, Yu Qiao, and Jing Shao. [Paper]
-
GPTScore: Evaluate as You Desire.
NAACL2024Jinlan Fu, See-Kiong Ng, Zhengbao Jiang, and Pengfei Liu. [Paper]
-
G-Eval: NLG Evaluation using Gpt-4 with Better Human Alignment.
EMNLP2023Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. [Paper]
-
DHP Benchmark: Are LLMs Good NLG Evaluators?
ArXiv preprint2024Yicheng Wang, Jiayi Yuan, Yu-Neng Chuang, Zhuoer Wang, Yingchi Liu, Mark Cusick, Param Kulkarni, Zhengping Ji, Yasser Ibrahim, and Xia Hu. [Paper]
-
SocREval: Large Language Models with the Socratic Method for Reference-free Reasoning Evaluation.
NAACL findings2024Hangfeng He, Hongming Zhang, and Dan Roth. [Paper]
-
Branch-Solve-Merge Improves Large Language Model Evaluation and Generation.
NAACL2024Swarnadeep Saha, Omer Levy, Asli Celikyilmaz, Mohit Bansal, Jason Weston, and Xian Li. [Paper]
-
HD-Eval: Aligning Large Language Model Evaluators Through Hierarchical Criteria Decomposition.
ACL2024Yuxuan Liu, Tianchi Yang, Shaohan Huang, Zihan Zhang, Haizhen Huang, Furu Wei, Weiwei Deng, Feng Sun, and Qi Zhang. [Paper]
-
Are LLM-based Evaluators Confusing NLG Quality Criteria?
ACL2024Xinyu Hu, Mingqi Gao, Sen Hu, Yang Zhang, Yicheng Chen, Teng Xu, and Xiaojun Wan. [Paper]
-
Large language models are not fair evaluators.
ACL2024Peiyi Wang, Lei Li, Liang Chen, Dawei Zhu, Binghuai Lin, Yunbo Cao, Qi Liu, Tianyu Liu, and Zhifang Sui. [Paper]
-
Generative judge for evaluating alignment.
ArXiv preprint2023Junlong Li, Shichao Sun, Weizhe Yuan, Run-Ze Fan, Hai Zhao, and Pengfei Liu. [Paper]
-
Judgelm: Fine-tuned large language models are scalable judges.
ArXiv preprint2023Lianghui Zhu, Xinggang Wang, and Xinlong Wang. [Paper]
-
PandaLM: An Automatic Evaluation Benchmark for LLM Instruction Tuning Optimization.
ArXiv preprint2023Yidong Wang, Zhuohao Yu, Zhengran Zeng, Linyi Yang, Cunxiang Wang, Hao Chen, Chaoya Jiang, Rui Xie, Jindong Wang, Xing Xie, et al. 2023. [Paper]
-
**Aligning with human judgement: The role of pairwise preference in large language model evaluators. **
COLM2024Yinhong Liu, Han Zhou, Zhijiang Guo, Ehsan Shareghi, Ivan Vulic, Anna Korhonen, and Nigel Collier. [Paper]
-
G-Eval: NLG Evaluation using Gpt-4 with Better Human Alignment.
EMNLP2023Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. [Paper]
-
DHP Benchmark: Are LLMs Good NLG Evaluators?
ArXiv preprint2024Yicheng Wang, Jiayi Yuan, Yu-Neng Chuang, Zhuoer Wang, Yingchi Liu, Mark Cusick, Param Kulkarni, Zhengping Ji, Yasser Ibrahim, and Xia Hu. [Paper]
-
LLM-Eval: Unified Multi-Dimensional Automatic Evaluation for Open-Domain Conversations with Large Language Models.
NLP4ConvAI2023Yen-Ting Lin and Yun-Nung Chen. [Paper]
-
CLAIR: Evaluating Image Captions with Large Language Models.
EMNLP2023David Chan, Suzanne Petryk, Joseph Gonzalez, Trevor Darrell, and John Canny. [Paper]
-
FLEUR: An Explainable Reference-Free Evaluation Metric for Image Captioning Using a Large Multimodal Model.
ACL2024Yebin Lee, Imseong Park, and Myungjoo Kang. [Paper]
-
PandaLM: An Automatic Evaluation Benchmark for LLM Instruction Tuning Optimization.
ArXiv preprint2023Yidong Wang, Zhuohao Yu, Zhengran Zeng, Linyi Yang, Cunxiang Wang, Hao Chen, Chaoya Jiang, Rui Xie, Jindong Wang, Xing Xie, et al. 2023. [Paper]
-
SALAD-Bench: A Hierarchical and Comprehensive Safety Benchmark for Large Language Models.
ACL findings2024Lijun Li, Bowen Dong, Ruohui Wang, Xuhao Hu, Wangmeng Zuo, Dahua Lin, Yu Qiao, and Jing Shao. [Paper]
-
Offsetbias: Leveraging debiased data for tuning evaluators.
ArXiv preprint2024Junsoo Park, Seungyeon Jwa, Meiying Ren, Daeyoung Kim, and Sanghyuk Choi. [Papaer]
-
Judgelm: Fine-tuned large language models are scalable judges.
ArXiv preprint2023Lianghui Zhu, Xinggang Wang, and Xinlong Wang. [Paper]
-
CritiqueLLM: Towards an Informative Critique Generation Model for Evaluation of Large Language Model Generation.
ACL2024Pei Ke, Bosi Wen, Andrew Feng, Xiao Liu, Xuanyu Lei, Jiale Cheng, Shengyuan Wang, Aohan Zeng, Yuxiao Dong, Hongning Wang, et al. [Paper]
-
INSTRUCTSCORE: Towards Explainable Text Generation Evaluation with Automatic Feedback.
EMNLP2023Wenda Xu, Danqing Wang, Liangming Pan, Zhenqiao Song, Markus Freitag, William Wang, and Lei Li. [Paper]
-
Jade: A linguistics-based safety evaluation platform for llm.
ArXiv preprint2023Mi Zhang, Xudong Pan, and Min Yang. [Paper]
-
Evaluation Metrics in the Era of GPT-4: Reliably Evaluating Large Language Models on Sequence to Sequence Tasks.
EMNLP2023Andrea Sottana, Bin Liang, Kai Zou, and Zheng Yuan. [Paper]
-
On the humanity of conversational ai: Evaluating the psychological portrayal of llms.
ICLR2023Jen-tse Huang, Wenxuan Wang, Eric John Li, Man Ho Lam, Shujie Ren, Youliang Yuan, Wenxiang Jiao, Zhaopeng Tu, and Michael Lyu. [Paper]
-
Generative judge for evaluating alignment.
ArXiv preprint2023Junlong Li, Shichao Sun, Weizhe Yuan, Run-Ze Fan, Hai Zhao, and Pengfei Liu. [Paper]
-
Goal-Oriented Prompt Attack and Safety Evaluation for LLMs.
ArXiv preprint2023Chengyuan Liu, Fubang Zhao, Lizhi Qing, Yangyang Kang, Changlong Sun, Kun Kuang, and Fei Wu. [Paper]
-
Benchmarking Foundation Models with Language-Model-as-an-Examiner.
NeurIPS2023Yushi Bai, Jiahao Ying, Yixin Cao, Xin Lv, Yuze He, Xiaozhi Wang, Jifan Yu, Kaisheng Zeng, Yijia Xiao, Haozhe Lyu, Jiayin Zhang, Juanzi Li, and Lei Hou. [Paper]
-
FLEUR: An Explainable Reference-Free Evaluation Metric for Image Captioning Using a Large Multimodal Model.
ACL2024Yebin Lee, Imseong Park, and Myungjoo Kang. [Paper]
-
G-Eval: NLG Evaluation using Gpt-4 with Better Human Alignment.
EMNLP2023Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. [Paper]
-
DHP Benchmark: Are LLMs Good NLG Evaluators?
ArXiv preprint2024Yicheng Wang, Jiayi Yuan, Yu-Neng Chuang, Zhuoer Wang, Yingchi Liu, Mark Cusick, Param Kulkarni, Zhengping Ji, Yasser Ibrahim, and Xia Hu. [Paper]
-
TrueTeacher: Learning Factual Consistency Evaluation with Large Language Models.
EMNLP2023Zorik Gekhman, Jonathan Herzig, Roee Aharoni, Chen Elkind, and Idan Szpektor. [Paper]
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LLM-as-a-Judge
Similar Open Source Tools
LLM-as-a-Judge
LLM-as-a-Judge is a repository that includes papers discussed in a survey paper titled 'A Survey on LLM-as-a-Judge'. The repository covers various aspects of using Large Language Models (LLMs) as judges for tasks such as evaluation, reasoning, and decision-making. It provides insights into evaluation pipelines, improvement strategies, and specific tasks related to LLMs. The papers included in the repository explore different methodologies, applications, and future research directions for leveraging LLMs as evaluators in various domains.
awesome-llm-role-playing-with-persona
Awesome-llm-role-playing-with-persona is a curated list of resources for large language models for role-playing with assigned personas. It includes papers and resources related to persona-based dialogue systems, personalized response generation, psychology of LLMs, biases in LLMs, and more. The repository aims to provide a comprehensive collection of research papers and tools for exploring role-playing abilities of large language models in various contexts.
Prompt4ReasoningPapers
Prompt4ReasoningPapers is a repository dedicated to reasoning with language model prompting. It provides a comprehensive survey of cutting-edge research on reasoning abilities with language models. The repository includes papers, methods, analysis, resources, and tools related to reasoning tasks. It aims to support various real-world applications such as medical diagnosis, negotiation, etc.

Awesome-LLM-Reasoning
**Curated collection of papers and resources on how to unlock the reasoning ability of LLMs and MLLMs.** **Description in less than 400 words, no line breaks and quotation marks.** Large Language Models (LLMs) have revolutionized the NLP landscape, showing improved performance and sample efficiency over smaller models. However, increasing model size alone has not proved sufficient for high performance on challenging reasoning tasks, such as solving arithmetic or commonsense problems. This curated collection of papers and resources presents the latest advancements in unlocking the reasoning abilities of LLMs and Multimodal LLMs (MLLMs). It covers various techniques, benchmarks, and applications, providing a comprehensive overview of the field. **5 jobs suitable for this tool, in lowercase letters.** - content writer - researcher - data analyst - software engineer - product manager **Keywords of the tool, in lowercase letters.** - llm - reasoning - multimodal - chain-of-thought - prompt engineering **5 specific tasks user can use this tool to do, in less than 3 words, Verb + noun form, in daily spoken language.** - write a story - answer a question - translate a language - generate code - summarize a document

Awesome-LLM-Preference-Learning
The repository 'Awesome-LLM-Preference-Learning' is the official repository of a survey paper titled 'Towards a Unified View of Preference Learning for Large Language Models: A Survey'. It contains a curated list of papers related to preference learning for Large Language Models (LLMs). The repository covers various aspects of preference learning, including on-policy and off-policy methods, feedback mechanisms, reward models, algorithms, evaluation techniques, and more. The papers included in the repository explore different approaches to aligning LLMs with human preferences, improving mathematical reasoning in LLMs, enhancing code generation, and optimizing language model performance.
LLMAgentPapers
LLM Agents Papers is a repository containing must-read papers on Large Language Model Agents. It covers a wide range of topics related to language model agents, including interactive natural language processing, large language model-based autonomous agents, personality traits in large language models, memory enhancements, planning capabilities, tool use, multi-agent communication, and more. The repository also provides resources such as benchmarks, types of tools, and a tool list for building and evaluating language model agents. Contributors are encouraged to add important works to the repository.
Awesome-LLM-Reasoning-Openai-o1-Survey
The repository 'Awesome LLM Reasoning Openai-o1 Survey' provides a collection of survey papers and related works on OpenAI o1, focusing on topics such as LLM reasoning, self-play reinforcement learning, complex logic reasoning, and scaling law. It includes papers from various institutions and researchers, showcasing advancements in reasoning bootstrapping, reasoning scaling law, self-play learning, step-wise and process-based optimization, and applications beyond math. The repository serves as a valuable resource for researchers interested in exploring the intersection of language models and reasoning techniques.

Awesome-LLM-RAG
This repository, Awesome-LLM-RAG, aims to record advanced papers on Retrieval Augmented Generation (RAG) in Large Language Models (LLMs). It serves as a resource hub for researchers interested in promoting their work related to LLM RAG by updating paper information through pull requests. The repository covers various topics such as workshops, tutorials, papers, surveys, benchmarks, retrieval-enhanced LLMs, RAG instruction tuning, RAG in-context learning, RAG embeddings, RAG simulators, RAG search, RAG long-text and memory, RAG evaluation, RAG optimization, and RAG applications.
LLM4DB
LLM4DB is a repository focused on the intersection of Large Language Models (LLMs) and Database technologies. It covers various aspects such as data processing, data analysis, database optimization, and data management for LLMs. The repository includes research papers, tools, and techniques related to leveraging LLMs for tasks like data cleaning, entity matching, schema matching, data discovery, NL2SQL, data exploration, data visualization, knob tuning, query optimization, and database diagnosis.

LLM4DB
LLM4DB is a repository focused on the intersection of Large Language Models (LLM) and Database technologies. It covers various aspects such as data processing, data analysis, database optimization, and data management for LLM. The repository includes works on data cleaning, entity matching, schema matching, data discovery, NL2SQL, data exploration, data visualization, configuration tuning, query optimization, and anomaly diagnosis using LLMs. It aims to provide insights and advancements in leveraging LLMs for improving data processing, analysis, and database management tasks.

awesome-generative-information-retrieval
This repository contains a curated list of resources on generative information retrieval, including research papers, datasets, tools, and applications. Generative information retrieval is a subfield of information retrieval that uses generative models to generate new documents or passages of text that are relevant to a given query. This can be useful for a variety of tasks, such as question answering, summarization, and document generation. The resources in this repository are intended to help researchers and practitioners stay up-to-date on the latest advances in generative information retrieval.

Awesome-Audio-LLM
Awesome-Audio-LLM is a repository dedicated to various models and methods related to audio and language processing. It includes a wide range of research papers and models developed by different institutions and authors. The repository covers topics such as bridging audio and language, speech emotion recognition, voice assistants, and more. It serves as a comprehensive resource for those interested in the intersection of audio and language processing.
Awesome-Multimodal-LLM-for-Code
This repository contains papers, methods, benchmarks, and evaluations for code generation under multimodal scenarios. It covers UI code generation, scientific code generation, slide code generation, visually rich programming, logo generation, program repair, UML code generation, and general benchmarks.
For similar tasks

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

promptfoo
Promptfoo is a tool for testing and evaluating LLM output quality. With promptfoo, you can build reliable prompts, models, and RAGs with benchmarks specific to your use-case, speed up evaluations with caching, concurrency, and live reloading, score outputs automatically by defining metrics, use as a CLI, library, or in CI/CD, and use OpenAI, Anthropic, Azure, Google, HuggingFace, open-source models like Llama, or integrate custom API providers for any LLM API.

vespa
Vespa is a platform that performs operations such as selecting a subset of data in a large corpus, evaluating machine-learned models over the selected data, organizing and aggregating it, and returning it, typically in less than 100 milliseconds, all while the data corpus is continuously changing. It has been in development for many years and is used on a number of large internet services and apps which serve hundreds of thousands of queries from Vespa per second.

python-aiplatform
The Vertex AI SDK for Python is a library that provides a convenient way to use the Vertex AI API. It offers a high-level interface for creating and managing Vertex AI resources, such as datasets, models, and endpoints. The SDK also provides support for training and deploying custom models, as well as using AutoML models. With the Vertex AI SDK for Python, you can quickly and easily build and deploy machine learning models on Vertex AI.

ScandEval
ScandEval is a framework for evaluating pretrained language models on mono- or multilingual language tasks. It provides a unified interface for benchmarking models on a variety of tasks, including sentiment analysis, question answering, and machine translation. ScandEval is designed to be easy to use and extensible, making it a valuable tool for researchers and practitioners alike.

opencompass
OpenCompass is a one-stop platform for large model evaluation, aiming to provide a fair, open, and reproducible benchmark for large model evaluation. Its main features include: * Comprehensive support for models and datasets: Pre-support for 20+ HuggingFace and API models, a model evaluation scheme of 70+ datasets with about 400,000 questions, comprehensively evaluating the capabilities of the models in five dimensions. * Efficient distributed evaluation: One line command to implement task division and distributed evaluation, completing the full evaluation of billion-scale models in just a few hours. * Diversified evaluation paradigms: Support for zero-shot, few-shot, and chain-of-thought evaluations, combined with standard or dialogue-type prompt templates, to easily stimulate the maximum performance of various models. * Modular design with high extensibility: Want to add new models or datasets, customize an advanced task division strategy, or even support a new cluster management system? Everything about OpenCompass can be easily expanded! * Experiment management and reporting mechanism: Use config files to fully record each experiment, and support real-time reporting of results.

flower
Flower is a framework for building federated learning systems. It is designed to be customizable, extensible, framework-agnostic, and understandable. Flower can be used with any machine learning framework, for example, PyTorch, TensorFlow, Hugging Face Transformers, PyTorch Lightning, scikit-learn, JAX, TFLite, MONAI, fastai, MLX, XGBoost, Pandas for federated analytics, or even raw NumPy for users who enjoy computing gradients by hand.
thinc
Thinc is a lightweight deep learning library that offers an elegant, type-checked, functional-programming API for composing models, with support for layers defined in other frameworks such as PyTorch, TensorFlow and MXNet. You can use Thinc as an interface layer, a standalone toolkit or a flexible way to develop new models.
For similar jobs

asreview
The ASReview project implements active learning for systematic reviews, utilizing AI-aided pipelines to assist in finding relevant texts for search tasks. It accelerates the screening of textual data with minimal human input, saving time and increasing output quality. The software offers three modes: Oracle for interactive screening, Exploration for teaching purposes, and Simulation for evaluating active learning models. ASReview LAB is designed to support decision-making in any discipline or industry by improving efficiency and transparency in screening large amounts of textual data.
NewEraAI-Papers
The NewEraAI-Papers repository provides links to collections of influential and interesting research papers from top AI conferences, along with open-source code to promote reproducibility and provide detailed implementation insights beyond the scope of the article. Users can stay up to date with the latest advances in AI research by exploring this repository. Contributions to improve the completeness of the list are welcomed, and users can create pull requests, open issues, or contact the repository owner via email to enhance the repository further.
cltk
The Classical Language Toolkit (CLTK) is a Python library that provides natural language processing (NLP) capabilities for pre-modern languages. It offers a modular processing pipeline with pre-configured defaults and supports almost 20 languages. Users can install the latest version using pip and access detailed documentation on the official website. The toolkit is designed to meet the unique needs of researchers working with historical languages, filling a void in the NLP landscape that often neglects non-spoken languages and different research goals.
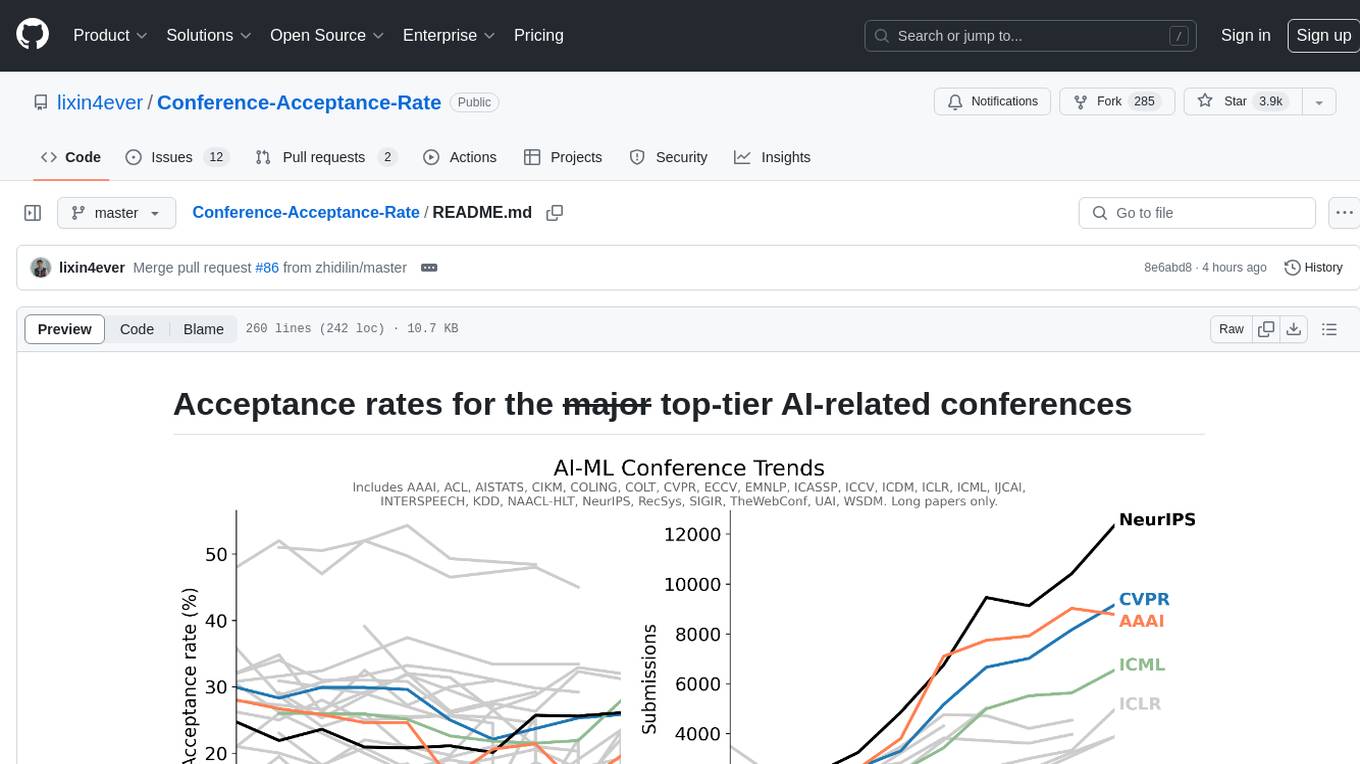
Conference-Acceptance-Rate
The 'Conference-Acceptance-Rate' repository provides acceptance rates for top-tier AI-related conferences in the fields of Natural Language Processing, Computational Linguistics, Computer Vision, Pattern Recognition, Machine Learning, Learning Theory, Artificial Intelligence, Data Mining, Information Retrieval, Speech Processing, and Signal Processing. The data includes acceptance rates for long papers and short papers over several years for each conference, allowing researchers to track trends and make informed decisions about where to submit their work.
pdftochat
PDFToChat is a tool that allows users to chat with their PDF documents in seconds. It is powered by Together AI and Pinecone, utilizing a tech stack including Next.js, Mixtral, M2 Bert, LangChain.js, MongoDB Atlas, Bytescale, Vercel, Clerk, and Tailwind CSS. Users can deploy the tool to Vercel or any other host by setting up Together.ai, MongoDB Atlas database, Bytescale, Clerk, and Vercel. The tool enables users to interact with PDFs through chat, with future tasks including adding features like trash icon for deleting PDFs, exploring different embedding models, implementing auto scrolling, improving replies, benchmarking accuracy, researching chunking and retrieval best practices, adding demo video, upgrading to Next.js 14, adding analytics, customizing tailwind prose, saving chats in postgres DB, compressing large PDFs, implementing custom uploader, session tracking, error handling, and support for images in PDFs.

tods-arxiv-daily-paper
This repository provides a tool for fetching and summarizing daily papers from the arXiv repository. It allows users to stay updated with the latest research in various fields by automatically retrieving and summarizing papers on a daily basis. The tool simplifies the process of accessing and digesting academic papers, making it easier for researchers and enthusiasts to keep track of new developments in their areas of interest.
Awesome-LLM-Strawberry
Awesome LLM Strawberry is a collection of research papers and blogs related to OpenAI Strawberry(o1) and Reasoning. The repository is continuously updated to track the frontier of LLM Reasoning.
Call-for-Reviewers
The `Call-for-Reviewers` repository aims to collect the latest 'call for reviewers' links from various top CS/ML/AI conferences/journals. It provides an opportunity for individuals in the computer/ machine learning/ artificial intelligence fields to gain review experience for applying for NIW/H1B/EB1 or enhancing their CV. The repository helps users stay updated with the latest research trends and engage with the academic community.