
tafrigh
تفريغ النصوص وإنشاء ملفات SRT و VTT باستخدام نماذج Whisper وتقنية wit.ai.
Stars: 92
Tafrigh is a tool for transcribing visual and audio content into text using advanced artificial intelligence techniques provided by OpenAI and wit.ai. It allows direct downloading of content from platforms like YouTube, Facebook, Twitter, and SoundCloud, and provides various output formats such as txt, srt, vtt, csv, tsv, and json. Users can install Tafrigh via pip or by cloning the GitHub repository and using Poetry. The tool supports features like skipping transcription if output exists, specifying playlist items, setting download retries, using different Whisper models, and utilizing wit.ai for transcription. Tafrigh can be used via command line or programmatically, and Docker images are available for easy usage.
README:




![]()
تفريغ المواد المرئية أو المسموعة إلى نصوص.
يمكنك الاطلاع على أمثلة تم تفريغها باستخدام تفريغ من هنا.
- تفريغ المواد المرئية والمسموعة إلى نصوص باستخدام أحدث تقنيات الذكاء الاصطناعي المقدمة من شركة OpenAI
- إمكانية تفريغ المواد باستخدام تقنيات wit.ai المقدمة من شركة Facebook
- تنزيل المواد بشكل مباشر من YouTube و Facebook و Twitter و SoundCloud وغيرها
- توفير صيَغ مخرجات مختلفة كـ
txtوsrtوvttوcsvوtsvوjson
- يُفضّل وجود معالج رسوميات قوي في حاسبك في حال استخدام نماذج Whisper
- تثبيت لغة Python بإصدار 3.10 أو أعلى على حاسبك
- تثبيت برمجية FFmpeg على حاسبك
- تثبيت برمجية yt-dlp على حاسبك
يمكنك تثبيت تفريغ من خلال pip باستخدام الأمر: pip install tafrigh[wit,whisper]
يمكنك تحديد الاعتماديات التي تريد تثبيتها حسب نوع التقنية التي تريد استخدامها من خلال كتابة wit أو whisper بين قوسين مربعين كما هو موضّح في الأمر السابق.
- قم بتنزيل هذا المستودع من خلال الضغط على Code ثم Download ZIP أو من خلال تنفيذ الأمر التالي:
git clone [email protected]:ieasybooks/tafrigh.git - قم بفك ضغط الملف إذا قمت بتنزيله بصيغة ZIP وتوجّه إلى مجلد المشروع
- قم بتنفيذ الأمر التالي لتثبيت تفريغ:
poetry install
أضف -E wit أو -E whisper لتحديد الاعتماديات المراد تثبيتها.
-
المدخلات
- الروابط أو مسارات الملفات: يجب تمرير الروابط أو مسارات الملفات للمواد المُراد تفريغها بعد اسم أداة تفريغ بشكل مباشر. على سبيل المثال:
tafrigh "https://yout..." "https://yout..." "C:\Users\ieasybooks\leactue.wav" - تخطي عملية التفريغ في حال وجود المخرجات مسبقًا: يمكن تمرير الاختيار
--skip_if_output_existلتخطي عملية التفريغ إذا كانت المخرجات المطلوبة موجودة بالفعل في مجلد الإخراج المحدد - المواد المُراد تفريفها من قائمة التشغيل: يمكن تحديد نطاق معين من المواد ليتم تفريغه من قائمة التشغيل من خلال الاختيار
--playlist_itemsمن خلال تمرير قيمة على صيغة"[START]:[STOP][:STEP]". على سبيل المثال، عند تمرير2:5سيتم تنزيل المواد من2إلى5من قائمة التشغيل. هذا الاختيار يُؤثّر على كل قوائم التشغيل التي يتم تمريرها كمدخلات لتفريغ - عدد مرات محاولة إعادة تحميل المواد: قد يفشل تحميل بعض المواد عند تحميل قائمة تشغيل كاملة باستخدام مكتبة
yt-dlp، يمكن من خلال الاختيار--download_retriesتحديد عدد مرات محاولة إعادة التحميل في حال فشل تحميل إحدى المواد. القيمة الافتراضية هي3
- الروابط أو مسارات الملفات: يجب تمرير الروابط أو مسارات الملفات للمواد المُراد تفريغها بعد اسم أداة تفريغ بشكل مباشر. على سبيل المثال:
-
خيارات تقنية Whisper
-
النموذج: يمكنك تحديد النموذج من خلال الاختيار
--model_name_or_path. النماذج المتوفرة:-
tiny.en(لغة انجليزية فقط) -
tiny(الأقل دقة) -
base.en(لغة انجليزية فقط) base-
small.en(لغة انجليزية فقط) -
small(الاختيار الإفتراضي) -
medium.en(لغة انجليزية فقط) mediumlarge-v1large-v2large-v3-
large(الأعلى دقة) - اسم نموذج Whisper موجود على HuggingFace Hub
- مسار نموذج Whisper تم تنزيله مسبقًا
- مسار نموذج Whisper تم تحويله باستخدام أداة
ct2-transformers-converterلاستخدام المكتبة السريعةfaster-whisper
-
-
المهمة: يمكنك تحديد المهمة من خلال الاختيار
--task. المهمات المتوفرة:-
transcribe: تحويل الصوت إلى نص (الاختيار الإفتراضي) -
translation: ترجمة الصوت إلى نص باللغة الانجليزية
-
- اللغة: يمكنك تحديد لغة الصوت من خلال الاختيار
--language. على سبيل المثال، لتحديد اللغة العربية قم بتمريرar. إذا لم يتم تحديد اللغة، سيتم التعرف عليها تلقائيا - استخدام نسخة أسرع من نماذج Whisper: من خلال تمرير الاختيار
--use_faster_whisperسيتم استخدام النسخة الأسرع من نماذج Whisper - حجم نطاق البحث: يمكنك تحسين النتائج باستخدام اختيار
--beam_sizeوالذي يسمح لك بإجبار النموذج على البحث في نطاق أوسع من الكلمات أثناء إنشاء النص. القيمة الإفتراضية هي5 -
طريقة ضغط النموذج: يمكنك تحديد الطريقة التي تم بها ضغط النموذج أثناء تحويله باستخدام أداة
ct2-transformers-converterمن خلال تمرير الاختيار--ct2_compute_type. الطرق المتوفرة:-
default(الاختيار الإفتراضي) int8int8_float16int16float16
-
-
النموذج: يمكنك تحديد النموذج من خلال الاختيار
-
خيارات تقنية Wit
- مفاتيح wit.ai: يمكنك استخدام تقنيات wit.ai لتفريغ المواد إلى نصوص من خلال تمرير المفتاح أو المفاتيح الخاصة بك للاختيار
--wit_client_access_tokens. إذا تم تمرير هذا الاختيار، سيتم استخدام wit.ai لتفريغ المواد إلى نصوص. غير ذلك، سيتم استخدام نماذج Whisper - تحديد أقصى مدة للتقطيع: يمكنك تحديد أقصى مدة للتقطيع والتي ستؤثر على طول الجمل في ملفات SRT و VTT من خلال تمرير الاختيار
--max_cutting_duration. القيمة الافتراضية هي15
- مفاتيح wit.ai: يمكنك استخدام تقنيات wit.ai لتفريغ المواد إلى نصوص من خلال تمرير المفتاح أو المفاتيح الخاصة بك للاختيار
-
المخرجات
- ضغط الأجزاء: يمكنك استخدام الاختيار
--min_words_per_segmentللتحكم في أقل عدد من الكلمات التي يمكن أن تكون داخل جزء واحد من أجزاء التفريغ. القيمة الإفتراضية هي1، يمكنك تمرير0لتعطيل هذه الخاصية - يمكنك تمرير الاختيار
--save_files_before_compactلحفظ الملفات الأصلية قبل أن يتم دمج أجزائها بناء على اختيار--min_words_per_segment - يمكنك حفظ مخرجات مكتبة
yt-dlpبصيغةjsonمن خلال تمرير الاختيار--save_yt_dlp_responses - إخراج عينة من الأجزاء بعد الدمج: يمكنك تمرير قيمة للاختيار
--output_sampleللحصول على عينة عشوائية من جميع الأجزاء التي تم تفريغها من كل المواد بعد دمجها بناء على اختيار--min_words_per_segment. القيمة الافتراضية هي0، أي أنه لن يتم إخراج أي عينات -
صيغة المخرجات: يمكنك تحديد صيغة المخرجات من خلال الاختيار
--output_formats. الصيغ المتوفرة:txtsrtvttcsvtsvjson-
all(الاختيار الإفتراضي) -
none(لن يتم إنشاء ملف في حال تمرير هذه الصيغة)
- مجلد المخرجات: يمكنك تحديد مجلد الاخراج من خلال الاختيار
--output_dir. بشكل تلقائي سيكون المجلد الحالي هو مجلد الاخراج إذا لم يتم تحديده
- ضغط الأجزاء: يمكنك استخدام الاختيار
➜ tafrigh --help
usage: tafrigh [-h] [--version] [--skip_if_output_exist | --no-skip_if_output_exist] [--playlist_items PLAYLIST_ITEMS]
[--download_retries DOWNLOAD_RETRIES] [--verbose | --no-verbose] [-m MODEL_NAME_OR_PATH] [-t {transcribe,translate}]
[-l {af,am,ar,as,az,ba,be,bg,bn,bo,br,bs,ca,cs,cy,da,de,el,en,es,et,eu,fa,fi,fo,fr,gl,gu,ha,haw,he,hi,hr,ht,hu,hy,id,is,it,ja,jw,ka,kk,km,kn,ko,la,lb,ln,lo,lt,lv,mg,mi,mk,ml,mn,mr,ms,mt,my,ne,nl,nn,no,oc,pa,pl,ps,pt,ro,ru,sa,sd,si,sk,sl,sn,so,sq,sr,su,sv,sw,ta,te,tg,th,tk,tl,tr,tt,uk,ur,uz,vi,yi,yo,zh}]
[--use_faster_whisper | --no-use_faster_whisper] [--beam_size BEAM_SIZE]
[--ct2_compute_type {default,int8,int8_float16,int16,float16}]
[-w WIT_CLIENT_ACCESS_TOKENS [WIT_CLIENT_ACCESS_TOKENS ...]] [--max_cutting_duration [1-17]]
[--min_words_per_segment MIN_WORDS_PER_SEGMENT] [--save_files_before_compact | --no-save_files_before_compact]
[--save_yt_dlp_responses | --no-save_yt_dlp_responses] [--output_sample OUTPUT_SAMPLE]
[-f {all,txt,srt,vtt,csv,tsv,json,none} [{all,txt,srt,vtt,csv,tsv,json,none} ...]] [-o OUTPUT_DIR]
urls_or_paths [urls_or_paths ...]
options:
-h, --help show this help message and exit
--version show program's version number and exit
Input:
urls_or_paths Video/Playlist URLs or local folder/file(s) to transcribe.
--skip_if_output_exist, --no-skip_if_output_exist
Whether to skip generating the output if the output file already exists.
--playlist_items PLAYLIST_ITEMS
Comma separated playlist_index of the items to download. You can specify a range using "[START]:[STOP][:STEP]".
--download_retries DOWNLOAD_RETRIES
Number of retries for yt-dlp downloads that fail.
--verbose, --no-verbose
Whether to print out the progress and debug messages.
Whisper:
-m MODEL_NAME_OR_PATH, --model_name_or_path MODEL_NAME_OR_PATH
Name or path of the Whisper model to use.
-t {transcribe,translate}, --task {transcribe,translate}
Whether to perform X->X speech recognition ('transcribe') or X->English translation ('translate').
-l {af,am,ar,as,az,ba,be,bg,bn,bo,br,bs,ca,cs,cy,da,de,el,en,es,et,eu,fa,fi,fo,fr,gl,gu,ha,haw,he,hi,hr,ht,hu,hy,id,is,it,ja,jw,ka,kk,km,kn,ko,la,lb,ln,lo,lt,lv,mg,mi,mk,ml,mn,mr,ms,mt,my,ne,nl,nn,no,oc,pa,pl,ps,pt,ro,ru,sa,sd,si,sk,sl,sn,so,sq,sr,su,sv,sw,ta,te,tg,th,tk,tl,tr,tt,uk,ur,uz,vi,yi,yo,zh}, --language {af,am,ar,as,az,ba,be,bg,bn,bo,br,bs,ca,cs,cy,da,de,el,en,es,et,eu,fa,fi,fo,fr,gl,gu,ha,haw,he,hi,hr,ht,hu,hy,id,is,it,ja,jw,ka,kk,km,kn,ko,la,lb,ln,lo,lt,lv,mg,mi,mk,ml,mn,mr,ms,mt,my,ne,nl,nn,no,oc,pa,pl,ps,pt,ro,ru,sa,sd,si,sk,sl,sn,so,sq,sr,su,sv,sw,ta,te,tg,th,tk,tl,tr,tt,uk,ur,uz,vi,yi,yo,zh}
Language spoken in the audio, skip to perform language detection.
--use_faster_whisper, --no-use_faster_whisper
Whether to use Faster Whisper implementation.
--beam_size BEAM_SIZE
Number of beams in beam search, only applicable when temperature is zero.
--ct2_compute_type {default,int8,int8_float16,int16,float16}
Quantization type applied while converting the model to CTranslate2 format.
Wit:
-w WIT_CLIENT_ACCESS_TOKENS [WIT_CLIENT_ACCESS_TOKENS ...], --wit_client_access_tokens WIT_CLIENT_ACCESS_TOKENS [WIT_CLIENT_ACCESS_TOKENS ...]
List of wit.ai client access tokens. If provided, wit.ai APIs will be used to do the transcription, otherwise
whisper will be used.
--max_cutting_duration [1-17]
The maximum allowed cutting duration. It should be between 1 and 17.
Output:
--min_words_per_segment MIN_WORDS_PER_SEGMENT
The minimum number of words should appear in each transcript segment. Any segment have words count less than
this threshold will be merged with the next one. Pass 0 to disable this behavior.
--save_files_before_compact, --no-save_files_before_compact
Saves the output files before applying the compact logic that is based on --min_words_per_segment.
--save_yt_dlp_responses, --no-save_yt_dlp_responses
Whether to save the yt-dlp library JSON responses or not.
--output_sample OUTPUT_SAMPLE
Samples random compacted segments from the output and generates a CSV file contains the sampled data. Pass 0 to
disable this behavior.
-f {all,txt,srt,vtt,csv,tsv,json,none} [{all,txt,srt,vtt,csv,tsv,json,none} ...], --output_formats {all,txt,srt,vtt,csv,tsv,json,none} [{all,txt,srt,vtt,csv,tsv,json,none} ...]
Format of the output file; if not specified, all available formats will be produced.
-o OUTPUT_DIR, --output_dir OUTPUT_DIR
Directory to save the outputs.
tafrigh "https://youtu.be/dDzxYcEJbgo" \
--model_name_or_path small \
--task transcribe \
--language ar \
--output_dir . \
--output_formats txt srttafrigh "https://youtube.com/playlist?list=PLyS-PHSxRDxsLnVsPrIwnsHMO5KgLz7T5" \
--model_name_or_path small \
--task transcribe \
--language ar \
--output_dir . \
--output_formats txt srttafrigh "https://youtu.be/4h5P7jXvW98" "https://youtu.be/jpfndVSROpw" \
--model_name_or_path small \
--task transcribe \
--language ar \
--output_dir . \
--output_formats txt srtيمكنك استخدام مكتبة faster_whisper التي توفّر سرعة أكبر في تفريغ المواد من خلال تمرير الاختيار --use_faster_whisper كالتالي:
tafrigh "https://youtu.be/3K5Jh_-UYeA" \
--model_name_or_path large \
--task transcribe \
--language ar \
--use_faster_whisper \
--output_dir . \
--output_formats txt srttafrigh "https://youtu.be/dDzxYcEJbgo" \
--wit_client_access_tokens XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX \
--output_dir . \
--output_formats txt srt \
--min_words_per_segment 10 \
--max_cutting_duration 10tafrigh "https://youtube.com/playlist?list=PLyS-PHSxRDxsLnVsPrIwnsHMO5KgLz7T5" \
--wit_client_access_tokens XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX \
--output_dir . \
--output_formats txt srt \
--min_words_per_segment 10 \
--max_cutting_duration 10tafrigh "https://youtu.be/4h5P7jXvW98" "https://youtu.be/jpfndVSROpw" \
--wit_client_access_tokens XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX \
--output_dir . \
--output_formats txt srt \
--min_words_per_segment 10 \
--max_cutting_duration 10يمكنك استخدام تفريغ من خلال الشيفرة البرمجية كالتالي:
from tafrigh import farrigh, Config
if __name__ == '__main__':
config = Config(
input=Config.Input(
urls_or_paths=['https://youtu.be/qFsUwp5iomU'],
skip_if_output_exist=False,
playlist_items='',
download_retries=3,
verbose=False,
),
whisper=Config.Whisper(
model_name_or_path='tiny',
task='transcribe',
language='ar',
use_faster_whisper=True,
beam_size=5,
ct2_compute_type='default',
),
wit=Config.Wit(
wit_client_access_tokens=[],
max_cutting_duration=10,
),
output=Config.Output(
min_words_per_segment=10,
save_files_before_compact=False,
save_yt_dlp_responses=False,
output_sample=0,
output_formats=['txt', 'srt'],
output_dir='.',
),
)
for progress in farrigh(config):
print(progress)دالة "فَرِّغْ" farrigh هي عبارة عن مُوَلِّدْ (Generator) يقوم بتوليد الحالة الحالية للتفريغ وأين وصلت العملية. إذا لم تكن بحاجة إلى تتبع هذا الأمر، يمكنك الاستغناء عن حلقة الدوران من خلال استخدام deque كالتالي:
from collections import deque
from tafrigh import farrigh, Config
if __name__ == '__main__':
config = Config(...)
deque(farrigh(config), maxlen=0)إذا كان لديك Docker على حاسبك، فالطريقة الأسهل لاستخدام تفريغ هي من خلاله. الأمر التالي يقوم بتنزيل Docker image الخاصة بتفريغ وتفريغ مقطع من YouTube باستخدام تقنيات wit.ai وإخراج النتائج في المجلد الحالي:
docker run -it --rm -v "$PWD:/tafrigh" ghcr.io/ieasybooks/tafrigh \
"https://www.youtube.com/watch?v=qFsUwp5iomU" \
--wit_client_access_tokens XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX \
-f txt srtيمكنك تمرير أي خيار من خيارات مكتبة تفريغ المُوضّحة في الأعلى.
يوجد أكثر من Docker image يمكنك استخدامها لتفريغ حسب الاعتماديات التي تريد استخدامها:
-
ghcr.io/ieasybooks/tafrigh: تحتوي على اعتماديات تقنيات wit.ai ونماذج Whisper معا -
ghcr.io/ieasybooks/tafrigh-whisper: تحتوي على اعتماديات نماذج Whisper فقط -
ghcr.io/ieasybooks/tafrigh-wit: تحتوي على اعتماديات تقنيات wit.ai فقط
من السلبيات أن نماذج Whisper لن تستطيع استخدام معالج الرسوميات الخاص بحاسبك في حال استخدامك لها من خلال Docker، وهذا أمر نعمل على حله في المستقبل.
تم الاعتماد بشكل كبير على مستودع yt-whisper لإنجاز تفريغ بشكل أسرع.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for tafrigh
Similar Open Source Tools
tafrigh
Tafrigh is a tool for transcribing visual and audio content into text using advanced artificial intelligence techniques provided by OpenAI and wit.ai. It allows direct downloading of content from platforms like YouTube, Facebook, Twitter, and SoundCloud, and provides various output formats such as txt, srt, vtt, csv, tsv, and json. Users can install Tafrigh via pip or by cloning the GitHub repository and using Poetry. The tool supports features like skipping transcription if output exists, specifying playlist items, setting download retries, using different Whisper models, and utilizing wit.ai for transcription. Tafrigh can be used via command line or programmatically, and Docker images are available for easy usage.
cntext
cntext is a text analysis package that provides semantic distance and semantic projection based on word embedding models. Additionally, cntext offers traditional methods such as word count statistics, readability, document similarity, sentiment analysis, etc. It includes modules for text statistics, sentiment analysis, dictionary construction, similarity calculations, and text-to-mind cognitive analysis.
mlp-mixer-pytorch
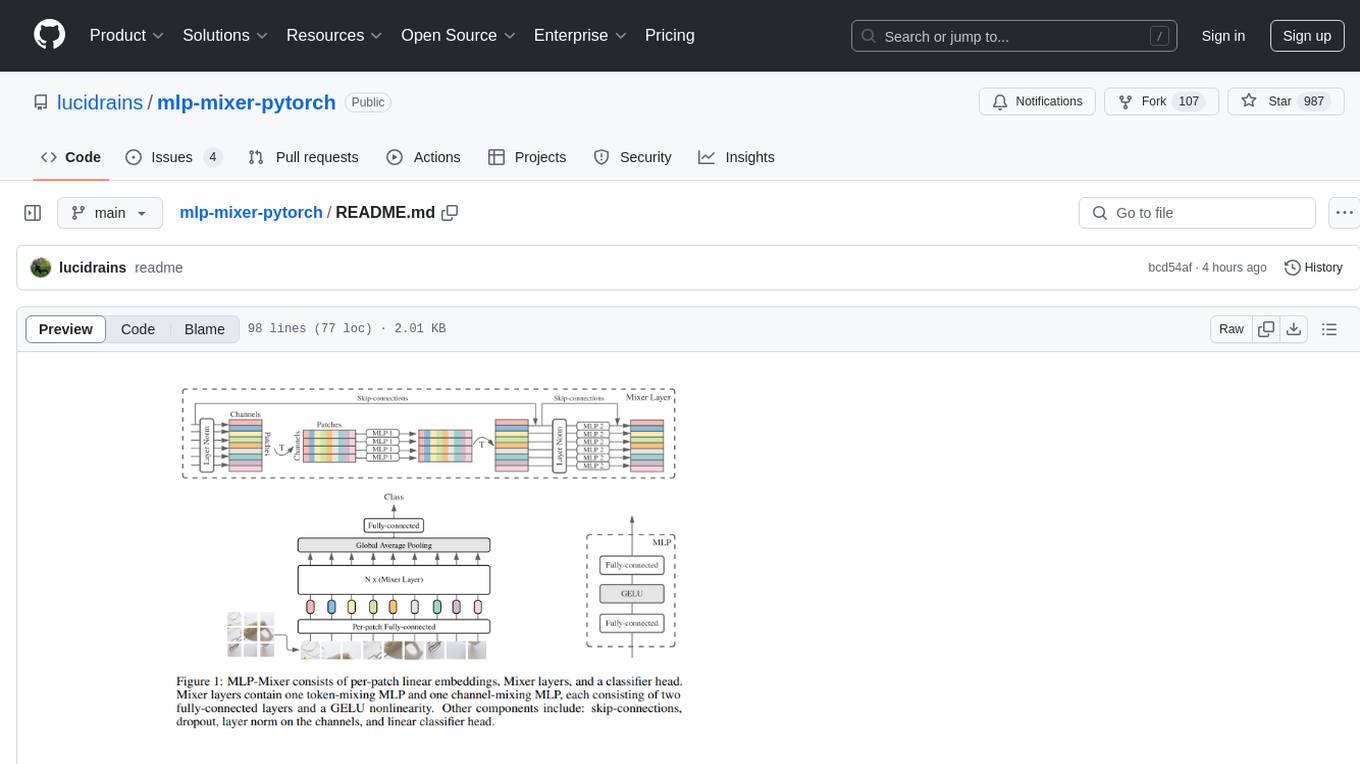
MLP Mixer - Pytorch is an all-MLP solution for vision tasks, developed by Google AI, implemented in Pytorch. It provides an architecture that does not require convolutions or attention mechanisms, offering an alternative approach for image and video processing. The tool is designed to handle tasks related to image classification and video recognition, utilizing multi-layer perceptrons (MLPs) for feature extraction and classification. Users can easily install the tool using pip and integrate it into their Pytorch projects to experiment with MLP-based vision models.

lagent
Lagent is a lightweight open-source framework that allows users to efficiently build large language model(LLM)-based agents. It also provides some typical tools to augment LLM. The overview of our framework is shown below:
prajna
Prajna is an open-source programming language specifically developed for building more modular, automated, and intelligent artificial intelligence infrastructure. It aims to cater to various stages of AI research, training, and deployment by providing easy access to CPU, GPU, and various TPUs for AI computing. Prajna features just-in-time compilation, GPU/heterogeneous programming support, tensor computing, syntax improvements, and user-friendly interactions through main functions, Repl, and Jupyter, making it suitable for algorithm development and deployment in various scenarios.
open-lx01
Open-LX01 is a project aimed at turning the Xiao Ai Mini smart speaker into a fully self-controlled device. The project involves steps such as gaining control, flashing custom firmware, and achieving autonomous control. It includes analysis of main services, reverse engineering methods, cross-compilation environment setup, customization of programs on the speaker, and setting up a web server. The project also covers topics like using custom ASR and TTS, developing a wake-up program, and creating a UI for various configurations. Additionally, it explores topics like gdb-server setup, open-mico-aivs-lab, and open-mipns-sai integration using Porcupine or Kaldi.
Webscout
Webscout is an all-in-one Python toolkit for web search, AI interaction, digital utilities, and more. It provides access to diverse search engines, cutting-edge AI models, temporary communication tools, media utilities, developer helpers, and powerful CLI interfaces through a unified library. With features like comprehensive search leveraging Google and DuckDuckGo, AI powerhouse for accessing various AI models, YouTube toolkit for video and transcript management, GitAPI for GitHub data extraction, Tempmail & Temp Number for privacy, Text-to-Speech conversion, GGUF conversion & quantization, SwiftCLI for CLI interfaces, LitPrinter for styled console output, LitLogger for logging, LitAgent for user agent generation, Text-to-Image generation, Scout for web parsing and crawling, Awesome Prompts for specialized tasks, Weather Toolkit, and AI Search Providers.
ai
The Vercel AI SDK is a library for building AI-powered streaming text and chat UIs. It provides React, Svelte, Vue, and Solid helpers for streaming text responses and building chat and completion UIs. The SDK also includes a React Server Components API for streaming Generative UI and first-class support for various AI providers such as OpenAI, Anthropic, Mistral, Perplexity, AWS Bedrock, Azure, Google Gemini, Hugging Face, Fireworks, Cohere, LangChain, Replicate, Ollama, and more. Additionally, it offers Node.js, Serverless, and Edge Runtime support, as well as lifecycle callbacks for saving completed streaming responses to a database in the same request.
xsai
xsAI is an extra-small AI SDK designed for Browser, Node.js, Deno, Bun, or Edge Runtime. It provides a series of utils to help users utilize OpenAI or OpenAI-compatible APIs. The SDK is lightweight and efficient, using a variety of methods to minimize its size. It is runtime-agnostic, working seamlessly across different environments without depending on Node.js Built-in Modules. Users can easily install specific utils like generateText or streamText, and leverage tools like weather to perform tasks such as getting the weather in a location.

Janus
Janus is a series of unified multimodal understanding and generation models, including Janus-Pro, Janus, and JanusFlow. Janus-Pro is an advanced version that improves both multimodal understanding and visual generation significantly. Janus decouples visual encoding for unified multimodal understanding and generation, surpassing previous models. JanusFlow harmonizes autoregression and rectified flow for unified multimodal understanding and generation, achieving comparable or superior performance to specialized models. The models are available for download and usage, supporting a broad range of research in academic and commercial communities.
Webscout
WebScout is a versatile tool that allows users to search for anything using Google, DuckDuckGo, and phind.com. It contains AI models, can transcribe YouTube videos, generate temporary email and phone numbers, has TTS support, webai (terminal GPT and open interpreter), and offline LLMs. It also supports features like weather forecasting, YT video downloading, temp mail and number generation, text-to-speech, advanced web searches, and more.
sdk
Varg is an AI video generation SDK that extends Vercel's AI SDK with capabilities for video, music, and lipsync. It allows users to generate images, videos, music, and more using familiar patterns and declarative JSX syntax. The SDK supports various models for image and video generation, speech synthesis, music generation, and background removal. Users can create reusable elements for character consistency, handle files from disk, URL, or buffer, and utilize layout helpers, transitions, and caption styles. Varg also offers a visual editor for video workflows with a code editor and node-based interface.

HiveChat
HiveChat is an AI chat application designed for small and medium teams. It supports various models such as DeepSeek, Open AI, Claude, and Gemini. The tool allows easy configuration by one administrator for the entire team to use different AI models. It supports features like email or Feishu login, LaTeX and Markdown rendering, DeepSeek mind map display, image understanding, AI agents, cloud data storage, and integration with multiple large model service providers. Users can engage in conversations by logging in, while administrators can configure AI service providers, manage users, and control account registration. The technology stack includes Next.js, Tailwindcss, Auth.js, PostgreSQL, Drizzle ORM, and Ant Design.
chrome-ai
Chrome AI is a Vercel AI provider for Chrome's built-in model (Gemini Nano). It allows users to create language models using Chrome's AI capabilities. The tool is under development and may contain errors and frequent changes. Users can install the ChromeAI provider module and use it to generate text, stream text, and generate objects. To enable AI in Chrome, users need to have Chrome version 127 or greater and turn on specific flags. The tool is designed for developers and researchers interested in experimenting with Chrome's built-in AI features.
BetterOCR
BetterOCR is a tool that enhances text detection by combining multiple OCR engines with LLM (Language Model). It aims to improve OCR results, especially for languages with limited training data or noisy outputs. The tool combines results from EasyOCR, Tesseract, and Pororo engines, along with LLM support from OpenAI. Users can provide custom context for better accuracy, view performance examples by language, and upcoming features include box detection, improved interface, and async support. The package is under rapid development and contributions are welcomed.
For similar tasks
tafrigh
Tafrigh is a tool for transcribing visual and audio content into text using advanced artificial intelligence techniques provided by OpenAI and wit.ai. It allows direct downloading of content from platforms like YouTube, Facebook, Twitter, and SoundCloud, and provides various output formats such as txt, srt, vtt, csv, tsv, and json. Users can install Tafrigh via pip or by cloning the GitHub repository and using Poetry. The tool supports features like skipping transcription if output exists, specifying playlist items, setting download retries, using different Whisper models, and utilizing wit.ai for transcription. Tafrigh can be used via command line or programmatically, and Docker images are available for easy usage.
z-ai-sdk-python
Z.ai Open Platform Python SDK is the official Python SDK for Z.ai's large model open interface, providing developers with easy access to Z.ai's open APIs. The SDK offers core features like chat completions, embeddings, video generation, audio processing, assistant API, and advanced tools. It supports various functionalities such as speech transcription, text-to-video generation, image understanding, and structured conversation handling. Developers can customize client behavior, configure API keys, and handle errors efficiently. The SDK is designed to simplify AI interactions and enhance AI capabilities for developers.
XLICON-V2-MD
XLICON-V2-MD is a versatile Multi-Device WhatsApp bot developed by Salman Ahamed. It offers a wide range of features, making it an advanced and user-friendly bot for various purposes. The bot supports multi-device operation, AI photo enhancement, downloader commands, hidden NSFW commands, logo generation, anime exploration, economic activities, games, and audio/video editing. Users can deploy the bot on platforms like Heroku, Replit, Codespace, Okteto, Railway, Mongenius, Coolify, and Render. The bot is maintained by Salman Ahamed and Abraham Dwamena, with contributions from various developers and testers. Misusing the bot may result in a ban from WhatsApp, so users are advised to use it at their own risk.
Aidoku
Aidoku is a free and open source manga reading application for iOS and iPadOS. It offers features like ad-free experience, robust WASM source system, online reading through external sources, iCloud sync support, downloads, and tracker support. Users can access the latest ipa from the releases page and join TestFlight via the Aidoku Discord for detailed installation instructions. The project is open to contributions, with planned features and fixes. Translation efforts are welcomed through Weblate for crowd-sourced translations.
Topu-ai
TOPU Md is a simple WhatsApp user bot created by Topu Tech. It offers various features such as multi-device support, AI photo enhancement, downloader commands, hidden NSFW commands, logo commands, anime commands, economy menu, various games, and audio/video editor commands. Users can fork the repo, get a session ID by pairing code, and deploy on Heroku. The bot requires Node version 18.x or higher for optimal performance. Contributions to TOPU-MD are welcome, and the tool is safe for use on WhatsApp and Heroku. The tool is licensed under the MIT License and is designed to enhance the WhatsApp experience with diverse features.
aiograpi
aiograpi is an asynchronous Instagram API wrapper for Python that allows users to interact with various Instagram functionalities such as retrieving public data of users, posts, stories, followers, and following users, managing proxy servers and challenge resolver, login by different methods, managing messages and threads, downloading and uploading various types of content, working with insights, likes, comments, and more. It is designed for testing or research purposes rather than production business use.
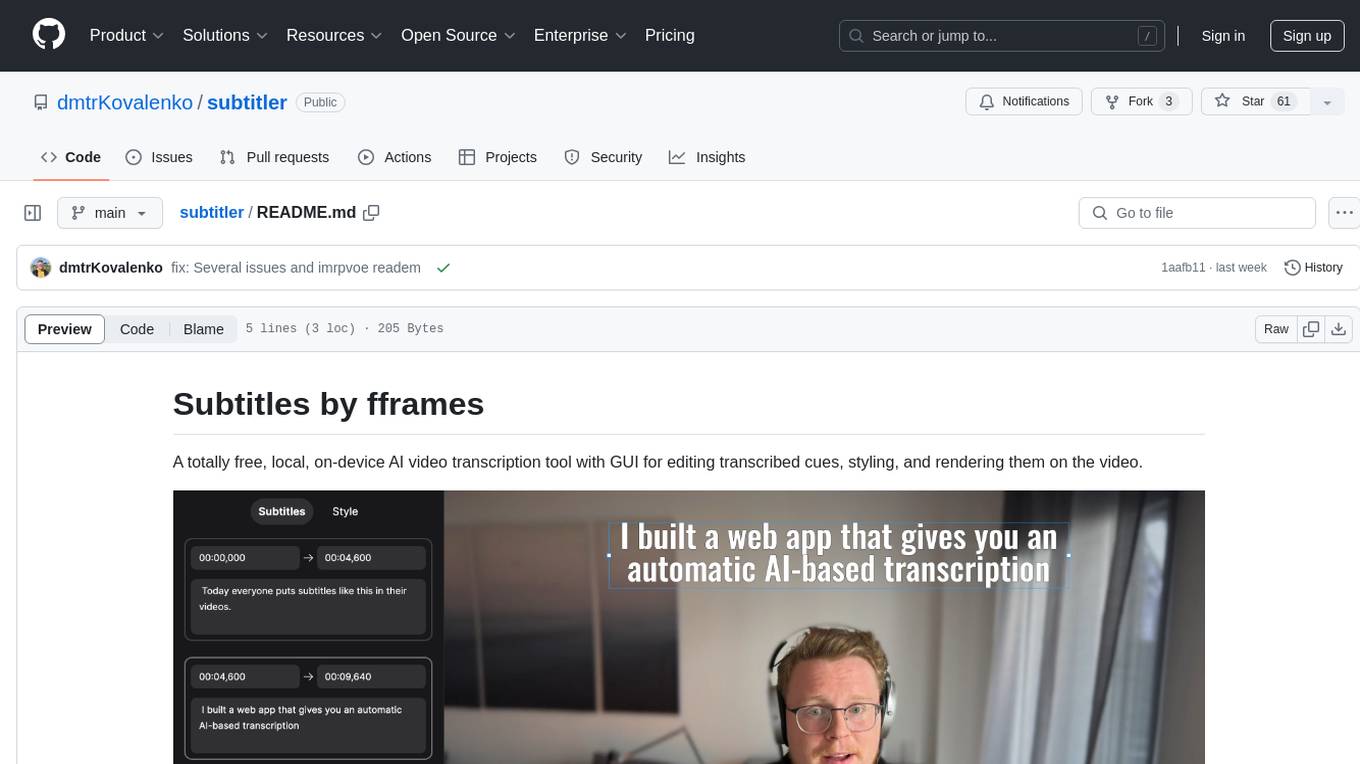
subtitler
Subtitles by fframes is a free, local, on-device AI video transcription tool with a user-friendly GUI. It allows users to transcribe video content, edit transcribed cues, style the subtitles, and render them directly onto the video. The tool provides a convenient way to create accurate subtitles for videos without the need for an internet connection.
Webscout
WebScout is a versatile tool that allows users to search for anything using Google, DuckDuckGo, and phind.com. It contains AI models, can transcribe YouTube videos, generate temporary email and phone numbers, has TTS support, webai (terminal GPT and open interpreter), and offline LLMs. It also supports features like weather forecasting, YT video downloading, temp mail and number generation, text-to-speech, advanced web searches, and more.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.