
top_secret
Filter sensitive information from free text before sending it to external services or APIs, such as chatbots and LLMs.
Stars: 249
Top Secret is a Ruby gem designed to filter sensitive information from free text before sending it to external services or APIs, such as chatbots and LLMs. It provides default filters for credit cards, emails, phone numbers, social security numbers, people's names, and locations, with the ability to add custom filters. Users can configure the tool to handle sensitive information redaction, scan for sensitive data, batch process messages, and restore filtered text from external services. Top Secret uses Regex and NER filters to detect and redact sensitive information, allowing users to override default filters, disable specific filters, and add custom filters globally. The tool is suitable for applications requiring data privacy and security measures.
README:
![]()
Filter sensitive information from free text before sending it to external services or APIs, such as chatbots and LLMs.
By default it filters the following:
- Credit cards
- Emails
- Phone numbers
- Social security numbers
- People's names
- Locations
However, you can add your own custom filters.
Install the gem and add to the application's Gemfile by executing:
bundle add top_secretIf bundler is not being used to manage dependencies, install the gem by executing:
gem install top_secret[!IMPORTANT] Top Secret depends on MITIE Ruby, which depends on MITIE.
You'll need to download and extract ner_model.dat first.
[!TIP] Due to its large size, you'll likely want to avoid committing ner_model.dat into version control.
You'll need to ensure the file exists in deployed environments. See relevant discussion for details.
Alternatively, you can disable NER filtering entirely by setting
model_pathtonilif you only need regex-based filters (credit cards, emails, phone numbers, SSNs). This improves performance and eliminates the model file dependency.
By default, Top Secret assumes the file will live at the root of your project, but this can be configured.
TopSecret.configure do |config|
config.model_path = "path/to/ner_model.dat"
endTop Secret ships with a set of filters to detect and redact the most common types of sensitive information.
You can override, disable, or add to this list as needed.
By default, the following filters are enabled
credit_card_filter
Matches common credit card formats
result = TopSecret::Text.filter("My card number is 4242-4242-4242-4242")
result.output
# => "My card number is [CREDIT_CARD_1]"email_filter
Matches email addresses
result = TopSecret::Text.filter("Email me at [email protected]")
result.output
# => "Email me at [EMAIL_1]"phone_number_filter
Matches phone numbers
result = TopSecret::Text.filter("Call me at 555-555-5555")
result.output
# => "Call me at [PHONE_NUMBER_1]"ssn_filter
Matches U.S. Social Security numbers
result = TopSecret::Text.filter("My SSN is 123-45-6789")
result.output
# => "My SSN is [SSN_1]"people_filter
Detects names of people (NER-based)
result = TopSecret::Text.filter("Ralph is joining the meeting")
result.output
# => "[PERSON_1] is joining the meeting"location_filter
Detects location names (NER-based)
result = TopSecret::Text.filter("Let's meet in Boston")
result.output
# => "Let's meet in [LOCATION_1]"TopSecret::Text.filter("Ralph can be reached at [email protected]")This will return
<TopSecret::Text::Result
@input="Ralph can be reached at [email protected]",
@mapping={:EMAIL_1=>"[email protected]", :PERSON_1=>"Ralph"},
@output="[PERSON_1] can be reached at [EMAIL_1]"
>View the original text
result.input
# => "Ralph can be reached at [email protected]"View the filtered text
result.output
# => "[PERSON_1] can be reached at [EMAIL_1]"View the mapping
result.mapping
# => {:EMAIL_1=>"[email protected]", :PERSON_1=>"Ralph"}Check if sensitive information was found
result.sensitive?
# => true
result.safe?
# => falseUse TopSecret::Text.scan to detect sensitive information without redacting the text. This is useful when you only need to check if sensitive data exists or get a mapping of what was found:
TopSecret::Text.scan("Ralph can be reached at [email protected]")This will return
<TopSecret::Text::ScanResult
@mapping={:EMAIL_1=>"[email protected]", :PERSON_1=>"Ralph"}
>Check if sensitive information was found
result.sensitive?
# => true
result.safe?
# => falseView the mapping of found sensitive information
result.mapping
# => {:EMAIL_1=>"[email protected]", :PERSON_1=>"Ralph"}The scan method accepts the same filter options as filter:
# Override default filters
email_filter = TopSecret::Filters::Regex.new(
label: "EMAIL_ADDRESS",
regex: /\w+\[at\]\w+\.\w+/
)
result = TopSecret::Text.scan("Contact user[at]example.com", email_filter:)
result.mapping
# => {:EMAIL_ADDRESS_1=>"user[at]example.com"}
# Disable specific filters
result = TopSecret::Text.scan("Ralph works in Boston", people_filter: nil)
result.mapping
# => {:LOCATION_1=>"Boston"}
# Add custom filters
ip_filter = TopSecret::Filters::Regex.new(
label: "IP_ADDRESS",
regex: /\b\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\b/
)
result = TopSecret::Text.scan("Server IP is 192.168.1.1", custom_filters: [ip_filter])
result.mapping
# => {:IP_ADDRESS_1=>"192.168.1.1"}When processing multiple messages, use filter_all to ensure consistent redaction labels across all messages:
messages = [
"Contact [email protected] for details",
"Email [email protected] again if needed",
"Also CC [email protected] on the thread"
]
result = TopSecret::Text.filter_all(messages)This will return
<TopSecret::Text::BatchResult
@mapping={:EMAIL_1=>"[email protected]", :EMAIL_2=>"[email protected]"},
@items=[
<TopSecret::Text::Result @input="Contact [email protected] for details", @output="Contact [EMAIL_1] for details", @mapping={:EMAIL_1=>"[email protected]"}>,
<TopSecret::Text::Result @input="Email [email protected] again if needed", @output="Email [EMAIL_1] again if needed", @mapping={:EMAIL_1=>"[email protected]"}>,
<TopSecret::Text::Result @input="Also CC [email protected] on the thread", @output="Also CC [EMAIL_2] on the thread", @mapping={:EMAIL_2=>"[email protected]"}>
]
>Access the global mapping
result.mapping
# => {:EMAIL_1=>"[email protected]", :EMAIL_2=>"[email protected]"}Access individual items
result.items[0].input
# => "Contact [email protected] for details"
result.items[0].output
# => "Contact [EMAIL_1] for details"
result.items[0].mapping
# => {:EMAIL_1=>"[email protected]"}
result.items[0].sensitive?
# => true
result.items[0].safe?
# => falseThe key benefit is that identical values receive the same labels across all messages - notice how [email protected] becomes [EMAIL_1] in both the first and second messages.
Each item also maintains its own mapping containing only the sensitive information found in that specific message, while the batch result provides a global mapping of all sensitive information across all messages.
When external services (like LLMs) return responses containing filter placeholders, use TopSecret::FilteredText.restore to substitute them back with original values:
# Filter messages before sending to LLM
messages = ["Contact [email protected] for details"]
batch_result = TopSecret::Text.filter_all(messages)
# Send filtered text to LLM: "Contact [EMAIL_1] for details"
# LLM responds with: "I'll email [EMAIL_1] about this request"
llm_response = "I'll email [EMAIL_1] about this request"
# Restore the original values
restore_result = TopSecret::FilteredText.restore(llm_response, mapping: batch_result.mapping)This will return
<TopSecret::FilteredText::Result
@output="I'll email [email protected] about this request",
@restored=["[EMAIL_1]"],
@unrestored=[]
>Access the restored text
restore_result.output
# => "I'll email [email protected] about this request"Track which placeholders were restored
restore_result.restored
# => ["[EMAIL_1]"]
restore_result.unrestored
# => []The restoration process tracks both successful and failed placeholder substitutions, allowing you to handle cases where the LLM response contains placeholders not found in your mapping.
When sending filtered information to LLMs, they'll likely need to be instructed on how to handle those filters. Otherwise, we risk them not being returned in the response, which would break the restoration process.
Here's a recommended approach:
instructions = <<~TEXT
I'm going to send filtered information to you in the form of free text.
If you need to refer to the filtered information in a response, just reference it by the filter.
TEXTComplete example:
require "openai"
require "top_secret"
openai = OpenAI::Client.new(
api_key: Rails.application.credentials.openai.api_key!
)
original_messages = [
"Ralph lives in Boston.",
"You can reach them at [email protected] or 877-976-2687"
]
# Filter all messages
result = TopSecret::Text.filter_all(original_messages)
filtered_messages = result.items.map(&:output)
user_messages = filtered_messages.map { {role: "user", content: it} }
# Instruct LLM how to handle filtered messages
instructions = <<~TEXT
I'm going to send filtered information to you in the form of free text.
If you need to refer to the filtered information in a response, just reference it by the filter.
TEXT
messages = [
{role: "system", content: instructions},
*user_messages
]
chat_completion = openai.chat.completions.create(messages:, model: :"gpt-5")
response = chat_completion.choices.last.message.content
# Restore the response from the mapping
mapping = result.mapping
restored_response = TopSecret::FilteredText.restore(response, mapping:).output
puts(restored_response)When overriding or disabling a default filter, you must map to the correct key.
[!IMPORTANT] Invalid filter keys will raise an
ArgumentError. Only the following keys are valid:credit_card_filter,email_filter,phone_number_filter,ssn_filter,people_filter,location_filter
regex_filter = TopSecret::Filters::Regex.new(label: "EMAIL_ADDRESS", regex: /\b\w+\[at\]\w+\.\w+\b/)
ner_filter = TopSecret::Filters::NER.new(label: "NAME", tag: :person, min_confidence_score: 0.25)
TopSecret::Text.filter("Ralph can be reached at ralph[at]thoughtbot.com",
email_filter: regex_filter,
people_filter: ner_filter
)This will return
<TopSecret::Text::Result
@input="Ralph can be reached at ralph[at]thoughtbot.com",
@mapping={:EMAIL_ADDRESS_1=>"ralph[at]thoughtbot.com", :NAME_1=>"Ralph", :NAME_2=>"ralph["},
@output="[NAME_1] can be reached at [EMAIL_ADDRESS_1]"
>TopSecret::Text.filter("Ralph can be reached at [email protected]",
email_filter: nil,
people_filter: nil
)This will return
<TopSecret::Text::Result
@input="Ralph can be reached at [email protected]",
@mapping={},
@output="Ralph can be reached at [email protected]"
># This will raise ArgumentError: Unknown key: :invalid_filter. Valid keys are: ...
TopSecret::Text.filter("some text", invalid_filter: some_filter)Adding new Regex filters
ip_address_filter = TopSecret::Filters::Regex.new(
label: "IP_ADDRESS",
regex: /\b\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\b/
)
TopSecret::Text.filter("Ralph's IP address is 192.168.1.1",
custom_filters: [ip_address_filter]
)This will return
<TopSecret::Text::Result
@input="Ralph's IP address is 192.168.1.1",
@mapping={:PERSON_1=>"Ralph", :IP_ADDRESS_1=>"192.168.1.1"},
@output="[PERSON_1]'s IP address is [IP_ADDRESS_1]"
>Adding new NER filters
Since MITIE Ruby has an API for training a model, you're free to add new NER filters.
language_filter = TopSecret::Filters::NER.new(
label: "LANGUAGE",
tag: :language,
min_confidence_score: 0.75
)
TopSecret::Text.filter("Ralph's favorite programming language is Ruby.",
custom_filters: [language_filter]
)This will return
<TopSecret::Text::Result
@input="Ralph's favorite programming language is Ruby.",
@mapping={:PERSON_1=>"Ralph", :LANGUAGE_1=>"Ruby"},
@output="[PERSON_1]'s favorite programming language is [LANGUAGE_1]"
>Top Secret uses two types of filters to detect and redact sensitive information:
Regex filters use regular expressions to find patterns in text.
They are useful for structured data like credit card numbers, emails, or IP addresses.
regex_filter = TopSecret::Filters::Regex.new(
label: "IP_ADDRESS",
regex: /\b\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\b/
)
result = TopSecret::Text.filter("Server IP: 192.168.1.1",
custom_filters: [regex_filter]
)
result.output
# => "Server IP: [IP_ADDRESS_1]"NER (Named Entity Recognition) filters use the MITIE library to detect entities like people, locations, and other categories based on trained language models.
They are ideal for free-form text where patterns are less predictable.
ner_filter = TopSecret::Filters::NER.new(
label: "PERSON",
tag: :person,
min_confidence_score: 0.25
)
result = TopSecret::Text.filter("Ralph and Ruby work at thoughtbot.",
people_filter: ner_filter
)
result.output
# => "[PERSON_1] and [PERSON_2] work at thoughtbot."NER filters match based on the tag you specify (:person, :location, etc.) and only include matches with a confidence score above min_confidence_score.
By default, Top Secret only ships with NER filters for two entity types:
:person:location
If you need other tags you can train your own MITIE model and add custom NER filters:
TopSecret.configure do |config|
config.model_path = "path/to/ner_model.dat"
endFor improved performance or when the MITIE model file cannot be deployed, you can disable NER-based filtering entirely. This will disable people and location detection but retain all regex-based filters (credit cards, emails, phone numbers, SSNs):
TopSecret.configure do |config|
config.model_path = nil
endThis is useful in environments where:
- The model file cannot be deployed due to size constraints
- You only need regex-based filtering
- You want to optimize for performance over NER capabilities
TopSecret.configure do |config|
config.min_confidence_score = 0.75
endTopSecret.configure do |config|
config.email_filter = TopSecret::Filters::Regex.new(
label: "EMAIL_ADDRESS",
regex: /\b\w+\[at\]\w+\.\w+\b/
)
endTopSecret.configure do |config|
config.email_filter = nil
endip_address_filter = TopSecret::Filters::Regex.new(
label: "IP_ADDRESS",
regex: /\b\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\b/
)
TopSecret.configure do |config|
config.custom_filters << ip_address_filter
endAfter checking out the repo, run bin/setup to install dependencies. Then, run rake spec to run the tests. You can also run bin/console for an interactive prompt that will allow you to experiment.
[!IMPORTANT] Top Secret depends on MITIE Ruby, which depends on MITIE.
You'll need to download and extract ner_model.dat first, and place it in the root of this project.
Run bin/benchmark to test performance and catch regressions:
bin/benchmark # CI-optimized benchmark with pass/fail thresholds[!NOTE] When adding new public methods to the API, ensure they are included in the benchmark script to catch performance regressions.
To install this gem onto your local machine, run bundle exec rake install. To release a new version, update the version number in version.rb, and then run bundle exec rake release, which will create a git tag for the version, push git commits and the created tag, and push the .gem file to rubygems.org.
Bug reports and pull requests are welcome on GitHub at https://github.com/thoughtbot/top_secret.
Please create a new discussion if you want to share ideas for new features.
This project is intended to be a safe, welcoming space for collaboration, and contributors are expected to adhere to the code of conduct.
Open source templates are Copyright (c) thoughtbot, inc. It contains free software that may be redistributed under the terms specified in the LICENSE file.
Everyone interacting in the TopSecret project's codebases, issue trackers, chat rooms and mailing lists is expected to follow the code of conduct.
This repo is maintained and funded by thoughtbot, inc. The names and logos for thoughtbot are trademarks of thoughtbot, inc.
We love open source software! See our other projects. We are available for hire.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for top_secret
Similar Open Source Tools
top_secret
Top Secret is a Ruby gem designed to filter sensitive information from free text before sending it to external services or APIs, such as chatbots and LLMs. It provides default filters for credit cards, emails, phone numbers, social security numbers, people's names, and locations, with the ability to add custom filters. Users can configure the tool to handle sensitive information redaction, scan for sensitive data, batch process messages, and restore filtered text from external services. Top Secret uses Regex and NER filters to detect and redact sensitive information, allowing users to override default filters, disable specific filters, and add custom filters globally. The tool is suitable for applications requiring data privacy and security measures.

langchainrb
Langchain.rb is a Ruby library that makes it easy to build LLM-powered applications. It provides a unified interface to a variety of LLMs, vector search databases, and other tools, making it easy to build and deploy RAG (Retrieval Augmented Generation) systems and assistants. Langchain.rb is open source and available under the MIT License.
aiavatarkit
AIAvatarKit is a tool for building AI-based conversational avatars quickly. It supports various platforms like VRChat and cluster, along with real-world devices. The tool is extensible, allowing unlimited capabilities based on user needs. It requires VOICEVOX API, Google or Azure Speech Services API keys, and Python 3.10. Users can start conversations out of the box and enjoy seamless interactions with the avatars.

instructor
Instructor is a popular Python library for managing structured outputs from large language models (LLMs). It offers a user-friendly API for validation, retries, and streaming responses. With support for various LLM providers and multiple languages, Instructor simplifies working with LLM outputs. The library includes features like response models, retry management, validation, streaming support, and flexible backends. It also provides hooks for logging and monitoring LLM interactions, and supports integration with Anthropic, Cohere, Gemini, Litellm, and Google AI models. Instructor facilitates tasks such as extracting user data from natural language, creating fine-tuned models, managing uploaded files, and monitoring usage of OpenAI models.

python-tgpt
Python-tgpt is a Python package that enables seamless interaction with over 45 free LLM providers without requiring an API key. It also provides image generation capabilities. The name _python-tgpt_ draws inspiration from its parent project tgpt, which operates on Golang. Through this Python adaptation, users can effortlessly engage with a number of free LLMs available, fostering a smoother AI interaction experience.

swarmzero
SwarmZero SDK is a library that simplifies the creation and execution of AI Agents and Swarms of Agents. It supports various LLM Providers such as OpenAI, Azure OpenAI, Anthropic, MistralAI, Gemini, Nebius, and Ollama. Users can easily install the library using pip or poetry, set up the environment and configuration, create and run Agents, collaborate with Swarms, add tools for complex tasks, and utilize retriever tools for semantic information retrieval. Sample prompts are provided to help users explore the capabilities of the agents and swarms. The SDK also includes detailed examples and documentation for reference.
gitleaks
Gitleaks is a tool for detecting secrets like passwords, API keys, and tokens in git repos, files, and whatever else you wanna throw at it via stdin. It can be installed using Homebrew, Docker, or Go, and is available in binary form for many popular platforms and OS types. Gitleaks can be implemented as a pre-commit hook directly in your repo or as a GitHub action. It offers scanning modes for git repositories, directories, and stdin, and allows creating baselines for ignoring old findings. Gitleaks also provides configuration options for custom secret detection rules and supports features like decoding encoded text and generating reports in various formats.
ruby_llm-monitoring
RubyLLM::Monitoring is a tool designed to monitor the LLM (Live-Link Monitoring) usage within a Rails application. It provides a dashboard to display metrics such as Throughput, Cost, Response Time, and Error Rate. Users can customize the displayed metrics and add their own custom metrics. The tool also supports setting up alerts based on predefined conditions, such as monitoring cost and errors. Authentication and authorization are left to the user, allowing for flexibility in securing the monitoring dashboard. Overall, RubyLLM::Monitoring aims to provide a comprehensive solution for monitoring and analyzing the performance of a Rails application.
shell-pilot
Shell-pilot is a simple, lightweight shell script designed to interact with various AI models such as OpenAI, Ollama, Mistral AI, LocalAI, ZhipuAI, Anthropic, Moonshot, and Novita AI from the terminal. It enhances intelligent system management without any dependencies, offering features like setting up a local LLM repository, using official models and APIs, viewing history and session persistence, passing input prompts with pipe/redirector, listing available models, setting request parameters, generating and running commands in the terminal, easy configuration setup, system package version checking, and managing system aliases.

instructor
Instructor is a Python library that makes it a breeze to work with structured outputs from large language models (LLMs). Built on top of Pydantic, it provides a simple, transparent, and user-friendly API to manage validation, retries, and streaming responses. Get ready to supercharge your LLM workflows!
langchain-decorators
LangChain Decorators is a layer on top of LangChain that provides syntactic sugar for writing custom langchain prompts and chains. It offers a more pythonic way of writing code, multiline prompts without breaking code flow, IDE support for hinting and type checking, leveraging LangChain ecosystem, support for optional parameters, and sharing parameters between prompts. It simplifies streaming, automatic LLM selection, defining custom settings, debugging, and passing memory, callback, stop, etc. It also provides functions provider, dynamic function schemas, binding prompts to objects, defining custom settings, and debugging options. The project aims to enhance the LangChain library by making it easier to use and more efficient for writing custom prompts and chains.

ruby-openai
Use the OpenAI API with Ruby! 🤖🩵 Stream text with GPT-4, transcribe and translate audio with Whisper, or create images with DALL·E... Hire me | 🎮 Ruby AI Builders Discord | 🐦 Twitter | 🧠 Anthropic Gem | 🚂 Midjourney Gem ## Table of Contents * Ruby OpenAI * Table of Contents * Installation * Bundler * Gem install * Usage * Quickstart * With Config * Custom timeout or base URI * Extra Headers per Client * Logging * Errors * Faraday middleware * Azure * Ollama * Counting Tokens * Models * Examples * Chat * Streaming Chat * Vision * JSON Mode * Functions * Edits * Embeddings * Batches * Files * Finetunes * Assistants * Threads and Messages * Runs * Runs involving function tools * Image Generation * DALL·E 2 * DALL·E 3 * Image Edit * Image Variations * Moderations * Whisper * Translate * Transcribe * Speech * Errors * Development * Release * Contributing * License * Code of Conduct

llm-rag-workshop
The LLM RAG Workshop repository provides a workshop on using Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG) to generate and understand text in a human-like manner. It includes instructions on setting up the environment, indexing Zoomcamp FAQ documents, creating a Q&A system, and using OpenAI for generation based on retrieved information. The repository focuses on enhancing language model responses with retrieved information from external sources, such as document databases or search engines, to improve factual accuracy and relevance of generated text.

Lumos
Lumos is a Chrome extension powered by a local LLM co-pilot for browsing the web. It allows users to summarize long threads, news articles, and technical documentation. Users can ask questions about reviews and product pages. The tool requires a local Ollama server for LLM inference and embedding database. Lumos supports multimodal models and file attachments for processing text and image content. It also provides options to customize models, hosts, and content parsers. The extension can be easily accessed through keyboard shortcuts and offers tools for automatic invocation based on prompts.

magentic
Easily integrate Large Language Models into your Python code. Simply use the `@prompt` and `@chatprompt` decorators to create functions that return structured output from the LLM. Mix LLM queries and function calling with regular Python code to create complex logic.
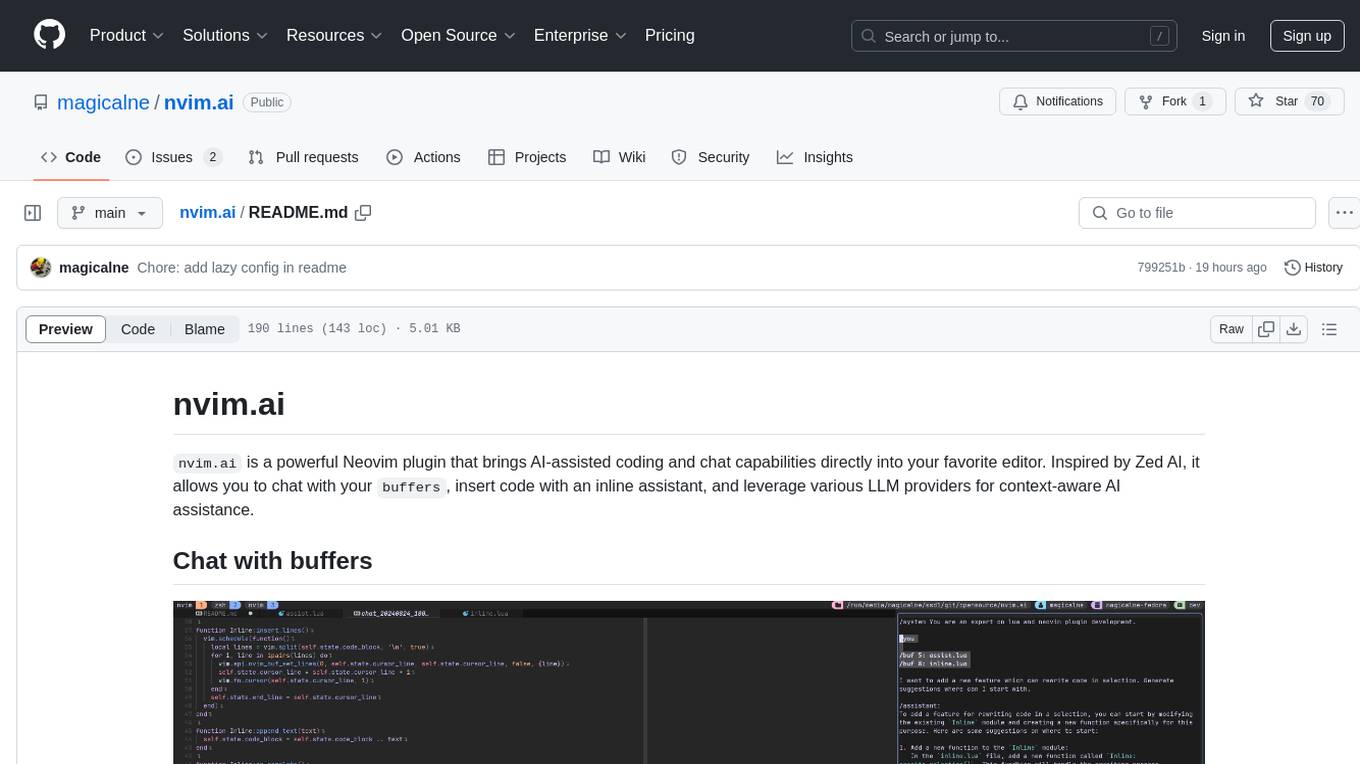
nvim.ai
nvim.ai is a powerful Neovim plugin that enables AI-assisted coding and chat capabilities within the editor. Users can chat with buffers, insert code with an inline assistant, and utilize various LLM providers for context-aware AI assistance. The plugin supports features like interacting with AI about code and documents, receiving relevant help based on current work, code insertion, code rewriting (Work in Progress), and integration with multiple LLM providers. Users can configure the plugin, add API keys to dotfiles, and integrate with nvim-cmp for command autocompletion. Keymaps are available for chat and inline assist functionalities. The chat dialog allows parsing content with keywords and supports roles like /system, /you, and /assistant. Context-aware assistance can be accessed through inline assist by inserting code blocks anywhere in the file.
For similar tasks
top_secret
Top Secret is a Ruby gem designed to filter sensitive information from free text before sending it to external services or APIs, such as chatbots and LLMs. It provides default filters for credit cards, emails, phone numbers, social security numbers, people's names, and locations, with the ability to add custom filters. Users can configure the tool to handle sensitive information redaction, scan for sensitive data, batch process messages, and restore filtered text from external services. Top Secret uses Regex and NER filters to detect and redact sensitive information, allowing users to override default filters, disable specific filters, and add custom filters globally. The tool is suitable for applications requiring data privacy and security measures.
For similar jobs

ciso-assistant-community
CISO Assistant is a tool that helps organizations manage their cybersecurity posture and compliance. It provides a centralized platform for managing security controls, threats, and risks. CISO Assistant also includes a library of pre-built frameworks and tools to help organizations quickly and easily implement best practices.
llm-course
The llm-course repository is a collection of resources and materials for a course on Legal and Legislative Drafting. It includes lecture notes, assignments, readings, and other educational materials to help students understand the principles and practices of drafting legal documents. The course covers topics such as statutory interpretation, legal drafting techniques, and the role of legislation in the legal system. Whether you are a law student, legal professional, or someone interested in understanding the intricacies of legal language, this repository provides valuable insights and resources to enhance your knowledge and skills in legal drafting.
non-ai-licenses
This repository provides templates for software and digital work licenses that restrict usage in AI training datasets or AI technologies. It includes various license styles such as Apache, BSD, MIT, UPL, ISC, CC0, and MPL-2.0.
sec-parser
The `sec-parser` project simplifies extracting meaningful information from SEC EDGAR HTML documents by organizing them into semantic elements and a tree structure. It helps in parsing SEC filings for financial and regulatory analysis, analytics and data science, AI and machine learning, causal AI, and large language models. The tool is especially beneficial for AI, ML, and LLM applications by streamlining data pre-processing and feature extraction.
docq
Docq is a private and secure GenAI tool designed to extract knowledge from business documents, enabling users to find answers independently. It allows data to stay within organizational boundaries, supports self-hosting with various cloud vendors, and offers multi-model and multi-modal capabilities. Docq is extensible, open-source (AGPLv3), and provides commercial licensing options. The tool aims to be a turnkey solution for organizations to adopt AI innovation safely, with plans for future features like more data ingestion options and model fine-tuning.
AwesomeResponsibleAI
Awesome Responsible AI is a curated list of academic research, books, code of ethics, courses, data sets, frameworks, institutes, newsletters, principles, podcasts, reports, tools, regulations, and standards related to Responsible, Trustworthy, and Human-Centered AI. It covers various concepts such as Responsible AI, Trustworthy AI, Human-Centered AI, Responsible AI frameworks, AI Governance, and more. The repository provides a comprehensive collection of resources for individuals interested in ethical, transparent, and accountable AI development and deployment.
verifywise
VerifyWise is an open-source AI governance platform designed to help businesses harness the power of AI safely and responsibly. The platform ensures compliance and robust AI management without compromising on security. It offers additional products like MaskWise for data redaction, EvalWise for AI model evaluation, and FlagWise for security threat monitoring. VerifyWise simplifies AI governance for organizations, aiding in risk management, regulatory compliance, and promoting responsible AI practices. It features options for on-premises or private cloud hosting, open-source with AGPLv3 license, AI-generated answers for compliance audits, source code transparency, Docker deployment, user registration, role-based access control, and various AI governance tools like risk management, bias & fairness checks, evidence center, AI trust center, and more.
sec-edgar-mcp
SEC EDGAR MCP is an open-source Model Context Protocol (MCP) server that connects AI models to the rich dataset of SEC EDGAR filings. It provides tools for accessing SEC filing data, leveraging the EdgarTools Python library for fetching data from official SEC sources and performing direct XBRL parsing for financial precision. The server acts as a middleman between an AI client and the SEC's EDGAR backend, offering tools for company lookup, financial statements, insider transactions, and more. Responses are deterministic, maintain exact precision, and include clickable SEC URLs for verification.