
flutter_gemma
The Flutter plugin allows running the Gemma AI model locally on a device from a Flutter application.
Stars: 243
Flutter Gemma is a family of lightweight, state-of-the art open models that bring the power of Google's Gemma language models directly to Flutter applications. It allows for local execution on user devices, supports both iOS and Android platforms, and offers LoRA support for tailored AI behavior. The tool provides a simple interface for integrating Gemma models into Flutter projects, enabling advanced AI capabilities without relying on external servers. Users can easily download pre-trained Gemma models, fine-tune them for specific use cases, and customize behavior using LoRA weights. The tool supports model and LoRA weight management, model initialization, response generation, and chat scenarios, with considerations for model size, LoRA weights, and production app deployment.
README:
# Flutter Gemma
The plugin supports not only Gemma, but also other models. Here's the full list of supported models: Gemma 2B & Gemma 7B, Gemma-2 2B, Gemma-3 1B, Gemma 3 270M, Gemma 3 Nano 2B, Gemma 3 Nano 4B, TinyLlama 1.1B, Hammer 2.1 0.5B, Llama 3.2 1B, Phi-2, Phi-3 , Phi-4, DeepSeek, Qwen2.5-1.5B-Instruct, Falcon-RW-1B, StableLM-3B.
*Note: Currently, the flutter_gemma plugin supports Gemma-3, Gemma 3 270M, Gemma 3 Nano (with multimodal vision support), TinyLlama, Hammer 2.1, Llama 3.2, Phi-4, DeepSeek and Qwen2.5.
Gemma is a family of lightweight, state-of-the art open models built from the same research and technology used to create the Gemini models

Bring the power of Google's lightweight Gemma language models directly to your Flutter applications. With Flutter Gemma, you can seamlessly incorporate advanced AI capabilities into your iOS and Android apps, all without relying on external servers.
There is an example of using:

- Local Execution: Run Gemma models directly on user devices for enhanced privacy and offline functionality.
- Platform Support: Compatible with iOS, Android, and Web platforms.
- 🖼️ Multimodal Support: Text + Image input with Gemma 3 Nano vision models (NEW!)
- 🛠️ Function Calling: Enable your models to call external functions and integrate with other services (supported by select models)
- 🧠 Thinking Mode: View the reasoning process of DeepSeek models with blocks (NEW!)
- 🛑 Stop Generation: Cancel text generation mid-process on Android devices (NEW!)
- ⚙️ Backend Switching: Choose between CPU and GPU backends for each model individually in the example app (NEW!)
- 🔍 Advanced Model Filtering: Filter models by features (Multimodal, Function Calls, Thinking) with expandable UI (NEW!)
- 📊 Model Sorting: Sort models alphabetically, by size, or use default order in the example app (NEW!)
- LoRA Support: Efficient fine-tuning and integration of LoRA (Low-Rank Adaptation) weights for tailored AI behavior.
- 📥 Enhanced Downloads: Smart retry logic and ETag handling for reliable model downloads from HuggingFace CDN
- 🔧 Download Reliability: Automatic resume/restart logic for interrupted downloads with exponential backoff
- 🔧 Model Replace Policy: Configurable model replacement system (keep/replace) with automatic model switching
- 📊 Text Embeddings: Generate vector embeddings from text using EmbeddingGemma and Gecko models (NEW!)
- 🔧 Unified Model Management: Single system for managing both inference and embedding models with automatic validation
Flutter Gemma supports two types of model files:
-
.taskfiles: MediaPipe-optimized format with built-in chat templates -
.bin/.tflitefiles: Standard format requiring manual chat template formatting
The plugin automatically detects the file type and applies appropriate formatting.
The example app offers a curated list of models, each suited for different tasks. Here's a breakdown of the models available and their capabilities:
| Model Family | Best For | Function Calling | Thinking Mode | Vision | Languages | Size |
|---|---|---|---|---|---|---|
| Gemma 3 Nano | On-device multimodal chat and image analysis. | ✅ | ❌ | ✅ | Multilingual | 3-6GB |
| DeepSeek R1 | High-performance reasoning and code generation. | ✅ | ✅ | ❌ | Multilingual | 1.7GB |
| Qwen 2.5 | Strong multilingual chat and instruction following. | ✅ | ❌ | ❌ | Multilingual | 1.6GB |
| Hammer 2.1 | Lightweight action model for tool usage. | ✅ | ❌ | ❌ | Multilingual | 0.5GB |
| Gemma 3 1B | Balanced and efficient text generation. | ✅ | ❌ | ❌ | Multilingual | 0.5GB |
| Gemma 3 270M | Ideal for fine-tuning (LoRA) for specific tasks | ❌ | ❌ | ❌ | Multilingual | 0.3GB |
| TinyLlama 1.1B | Extremely compact, general-purpose chat. | ❌ | ❌ | ❌ | English-focused | 1.2GB |
| Llama 3.2 1B | Efficient instruction following | ❌ | ❌ | ❌ | Multilingual | 1.1GB |
-
Add
flutter_gemmato yourpubspec.yaml:dependencies: flutter_gemma: latest_version
-
Run
flutter pub getto install.
- Download Model and optionally LoRA Weights: Obtain a pre-trained Gemma model (recommended: 2b or 2b-it) from Kaggle
- For multimodal support, download Gemma 3 Nano models that support vision input
- Optionally, fine-tune a model for your specific use case
- If you have LoRA weights, you can use them to customize the model's behavior without retraining the entire model.
- There is an article that described all approaches
- Platform specific setup:
iOS
-
Set minimum iOS version in
Podfile:
platform :ios, '16.0' # Required for MediaPipe GenAI-
Enable file sharing in
Info.plist:
<key>UIFileSharingEnabled</key>
<true/>-
Add network access description in
Info.plist(for development):
<key>NSLocalNetworkUsageDescription</key>
<string>This app requires local network access for model inference services.</string>-
Enable performance optimization in
Info.plist(optional):
<key>CADisableMinimumFrameDurationOnPhone</key>
<true/>-
Add memory entitlements in
Runner.entitlements(for large models):
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>com.apple.developer.kernel.extended-virtual-addressing</key>
<true/>
<key>com.apple.developer.kernel.increased-memory-limit</key>
<true/>
<key>com.apple.developer.kernel.increased-debugging-memory-limit</key>
<true/>
</dict>
</plist>-
Change the linking type of pods to static in
Podfile:
use_frameworks! :linkage => :staticAndroid
- If you want to use a GPU to work with the model, you need to add OpenGL support in the manifest.xml. If you plan to use only the CPU, you can skip this step.
Add to 'AndroidManifest.xml' above tag </application>
<uses-native-library
android:name="libOpenCL.so"
android:required="false"/>
<uses-native-library android:name="libOpenCL-car.so" android:required="false"/>
<uses-native-library android:name="libOpenCL-pixel.so" android:required="false"/>Web
-
Web currently works only GPU backend models, CPU backend models are not supported by MediaPipe yet
-
Multimodal support (images) is in development for web platform
-
Add dependencies to
index.htmlfile in web folder
<script type="module">
import { FilesetResolver, LlmInference } from 'https://cdn.jsdelivr.net/npm/@mediapipe/tasks-genai';
window.FilesetResolver = FilesetResolver;
window.LlmInference = LlmInference;
</script>The new API splits functionality into two parts:
- ModelFileManager: Manages model and LoRA weights file handling.
- InferenceModel: Handles model initialization and response generation.
The updated API splits the functionality into two main parts:
- Import and access the plugin:
import 'package:flutter_gemma/flutter_gemma.dart';
final gemma = FlutterGemmaPlugin.instance;- Managing Model Files with ModelFileManager
final modelManager = gemma.modelManager;Place the model in the assets or upload it to a network drive, such as Firebase.
ATTENTION!! You do not need to load the model every time the application starts; it is stored in the system files and only needs to be done once. Please carefully review the example application. You should use loadAssetModel and loadNetworkModel methods only when you need to upload the model to device
1.Loading Models from assets (available only in debug mode):
Don't forget to add your model to pubspec.yaml
- Loading from assets (loraUrl is optional)
await modelManager.installModelFromAsset('model.bin', loraPath: 'lora_weights.bin');- Loading from assets with Progress Status (loraUrl is optional)
modelManager.installModelFromAssetWithProgress('model.bin', loraPath: 'lora_weights.bin').listen(
(progress) {
print('Loading progress: $progress%');
},
onDone: () {
print('Model loading complete.');
},
onError: (error) {
print('Error loading model: $error');
},
);2.Loading Models from network:
-
For web usage, you will also need to enable CORS (Cross-Origin Resource Sharing) for your network resource. To enable CORS in Firebase, you can follow the guide in the Firebase documentation: Setting up CORS
- Loading from the network (loraUrl is optional).
await modelManager.downloadModelFromNetwork('https://example.com/model.bin', loraUrl: 'https://example.com/lora_weights.bin');- Loading from the network with Progress Status (loraUrl is optional)
modelManager.downloadModelFromNetworkWithProgress('https://example.com/model.bin', loraUrl: 'https://example.com/lora_weights.bin').listen(
(progress) {
print('Loading progress: $progress%');
},
onDone: () {
print('Model loading complete.');
},
onError: (error) {
print('Error loading model: $error');
},
);- Loading LoRA Weights
- Loading LoRA weight from the network.
await modelManager.downloadLoraWeightsFromNetwork('https://example.com/lora_weights.bin');- Loading LoRA weight from assets.
await modelManager.installLoraWeightsFromAsset('lora_weights.bin');- Model Management You can set model and weights paths manually
await modelManager.setModelPath('model.bin');
await modelManager.setLoraWeightsPath('lora_weights.bin');Model Replace Policy (NEW!)
Configure how the plugin handles switching between different models:
// Set policy to keep all models (default behavior)
await modelManager.setReplacePolicy(ModelReplacePolicy.keep);
// Set policy to replace old models (saves storage space)
await modelManager.setReplacePolicy(ModelReplacePolicy.replace);
// Check current policy
final currentPolicy = modelManager.replacePolicy;Automatic Model Management (NEW!)
Use ensureModelReady() for seamless model switching that handles all scenarios automatically:
// Handles all cases:
// - Same model already loaded: does nothing
// - Different model with KEEP policy: loads new model, keeps old one
// - Different model with REPLACE policy: deletes old model, loads new one
// - Corrupted/invalid model: re-downloads automatically
await modelManager.ensureModelReady(
'gemma-3n-E4B-it-int4.task',
'https://huggingface.co/google/gemma-3n-E4B-it-litert-preview/resolve/main/gemma-3n-E4B-it-int4.task'
);You can delete the model and weights from the device. Deleting the model or LoRA weights will automatically close and clean up the inference. This ensures that there are no lingering resources or memory leaks when switching models or updating files.
await modelManager.deleteModel();
await modelManager.deleteLoraWeights();5.Initialize:
Before performing any inference, you need to create a model instance. This ensures that your application is ready to handle requests efficiently.
Text-Only Models:
final inferenceModel = await FlutterGemmaPlugin.instance.createModel(
modelType: ModelType.gemmaIt, // Required, model type to create
preferredBackend: PreferredBackend.gpu, // Optional, backend type, default is PreferredBackend.gpu
maxTokens: 512, // Optional, default is 1024
loraRanks: [4, 8], // Optional, LoRA rank configuration for fine-tuned models
);🖼️ Multimodal Models (NEW!):
final inferenceModel = await FlutterGemmaPlugin.instance.createModel(
modelType: ModelType.gemmaIt, // Required, model type to create
preferredBackend: PreferredBackend.gpu, // Optional, backend type
maxTokens: 4096, // Recommended for multimodal models
supportImage: true, // Enable image support
maxNumImages: 1, // Optional, maximum number of images per message
loraRanks: [4, 8], // Optional, LoRA rank configuration for fine-tuned models
);6.Using Sessions for Single Inferences:
If you need to generate individual responses without maintaining a conversation history, use sessions. Sessions allow precise control over inference and must be properly closed to avoid memory leaks.
- Text-Only Session:
final session = await inferenceModel.createSession(
temperature: 1.0, // Optional, default: 0.8
randomSeed: 1, // Optional, default: 1
topK: 1, // Optional, default: 1
// topP: 0.9, // Optional nucleus sampling parameter
// loraPath: 'path/to/lora.bin', // Optional LoRA weights path
// enableVisionModality: true, // Enable vision for multimodal models
);
await session.addQueryChunk(Message.text(text: 'Tell me something interesting', isUser: true));
String response = await session.getResponse();
print(response);
await session.close(); // Always close the session when done- 🖼️ Multimodal Session (NEW!):
import 'dart:typed_data'; // For Uint8List
final session = await inferenceModel.createSession(
enableVisionModality: true, // Enable image processing
);
// Text + Image message
final imageBytes = await loadImageBytes(); // Your image loading method
await session.addQueryChunk(Message.withImage(
text: 'What do you see in this image?',
imageBytes: imageBytes,
isUser: true,
));
// Note: session.getResponse() returns String directly
String response = await session.getResponse();
print(response);
await session.close();- Asynchronous Response Generation:
final session = await inferenceModel.createSession();
await session.addQueryChunk(Message.text(text: 'Tell me something interesting', isUser: true));
// Note: session.getResponseAsync() returns Stream<String>
session.getResponseAsync().listen((String token) {
print(token);
}, onDone: () {
print('Stream closed');
}, onError: (error) {
print('Error: $error');
});
await session.close(); // Always close the session when done7.Chat Scenario with Automatic Session Management
For chat-based applications, you can create a chat instance. Unlike sessions, the chat instance manages the conversation context and refreshes sessions when necessary.
Text-Only Chat:
final chat = await inferenceModel.createChat(
temperature: 0.8, // Controls response randomness, default: 0.8
randomSeed: 1, // Ensures reproducibility, default: 1
topK: 1, // Limits vocabulary scope, default: 1
// topP: 0.9, // Optional nucleus sampling parameter
// tokenBuffer: 256, // Token buffer size, default: 256
// loraPath: 'path/to/lora.bin', // Optional LoRA weights path
// supportImage: false, // Enable image support, default: false
// tools: [], // List of available tools, default: []
// supportsFunctionCalls: false, // Enable function calling, default: false
// isThinking: false, // Enable thinking mode, default: false
// modelType: ModelType.gemmaIt, // Model type, default: ModelType.gemmaIt
);🖼️ Multimodal Chat (NEW!):
final chat = await inferenceModel.createChat(
temperature: 0.8, // Controls response randomness
randomSeed: 1, // Ensures reproducibility
topK: 1, // Limits vocabulary scope
supportImage: true, // Enable image support in chat
// tokenBuffer: 256, // Token buffer size for context management
);🧠 Thinking Mode Chat (DeepSeek Models):
final chat = await inferenceModel.createChat(
temperature: 0.8,
randomSeed: 1,
topK: 1,
isThinking: true, // Enable thinking mode for DeepSeek models
modelType: ModelType.deepSeek, // Specify DeepSeek model type
// supportsFunctionCalls: true, // Enable function calling for DeepSeek models
);- Synchronous Chat:
await chat.addQueryChunk(Message.text(text: 'User: Hello, who are you?', isUser: true));
ModelResponse response = await chat.generateChatResponse();
if (response is TextResponse) {
print(response.token);
}
await chat.addQueryChunk(Message.text(text: 'User: Are you sure?', isUser: true));
ModelResponse response2 = await chat.generateChatResponse();
if (response2 is TextResponse) {
print(response2.token);
}- 🖼️ Multimodal Chat Example:
// Add text message
await chat.addQueryChunk(Message.text(text: 'Hello!', isUser: true));
ModelResponse response1 = await chat.generateChatResponse();
if (response1 is TextResponse) {
print(response1.token);
}
// Add image message
final imageBytes = await loadImageBytes();
await chat.addQueryChunk(Message.withImage(
text: 'Can you analyze this image?',
imageBytes: imageBytes,
isUser: true,
));
ModelResponse response2 = await chat.generateChatResponse();
if (response2 is TextResponse) {
print(response2.token);
}
// Add image-only message
await chat.addQueryChunk(Message.imageOnly(imageBytes: imageBytes, isUser: true));
ModelResponse response3 = await chat.generateChatResponse();
if (response3 is TextResponse) {
print(response3.token);
}- Asynchronous Chat (Streaming):
await chat.addQueryChunk(Message.text(text: 'User: Hello, who are you?', isUser: true));
chat.generateChatResponseAsync().listen((ModelResponse response) {
if (response is TextResponse) {
print(response.token);
} else if (response is FunctionCallResponse) {
print('Function call: ${response.name}');
} else if (response is ThinkingResponse) {
print('Thinking: ${response.content}');
}
}, onDone: () {
print('Chat stream closed');
}, onError: (error) {
print('Chat error: $error');
});- 🛠️ Function Calling
Enable your models to call external functions and integrate with other services. Note: Function calling is only supported by specific models - see the Model Support section below.
Step 1: Define Tools
Tools define the functions your model can call:
final List<Tool> _tools = [
const Tool(
name: 'change_background_color',
description: "Changes the background color of the app. The color should be a standard web color name like 'red', 'blue', 'green', 'yellow', 'purple', or 'orange'.",
parameters: {
'type': 'object',
'properties': {
'color': {
'type': 'string',
'description': 'The color name',
},
},
'required': ['color'],
},
),
const Tool(
name: 'show_alert',
description: 'Shows an alert dialog with a custom message and title.',
parameters: {
'type': 'object',
'properties': {
'title': {
'type': 'string',
'description': 'The title of the alert dialog',
},
'message': {
'type': 'string',
'description': 'The message content of the alert dialog',
},
},
'required': ['title', 'message'],
},
),
];Step 2: Create Chat with Tools
final chat = await inferenceModel.createChat(
temperature: 0.8,
randomSeed: 1,
topK: 1,
tools: _tools, // Pass your tools
supportsFunctionCalls: true, // Enable function calling (required for tools)
// tokenBuffer: 256, // Adjust if needed for function calling
);Step 3: Handle Different Response Types
The model can now return two types of responses:
// Add user message
await chat.addQueryChunk(Message.text(text: 'Change the background to blue', isUser: true));
// Handle async responses
chat.generateChatResponseAsync().listen((response) {
if (response is TextResponse) {
// Regular text token from the model
print('Text: ${response.token}');
// Update your UI with the text
} else if (response is FunctionCallResponse) {
// Model wants to call a function
print('Function Call: ${response.name}(${response.args})');
_handleFunctionCall(response);
}
});Step 4: Execute Function and Send Response Back
Future<void> _handleFunctionCall(FunctionCallResponse functionCall) async {
// Execute the requested function
Map<String, dynamic> toolResponse;
switch (functionCall.name) {
case 'change_background_color':
final color = functionCall.args['color'] as String?;
// Your implementation here
toolResponse = {'status': 'success', 'message': 'Color changed to $color'};
break;
case 'show_alert':
final title = functionCall.args['title'] as String?;
final message = functionCall.args['message'] as String?;
// Show alert dialog
toolResponse = {'status': 'success', 'message': 'Alert shown'};
break;
default:
toolResponse = {'error': 'Unknown function: ${functionCall.name}'};
}
// Send the tool response back to the model
final toolMessage = Message.toolResponse(
toolName: functionCall.name,
response: toolResponse,
);
await chat.addQueryChunk(toolMessage);
// The model will then generate a final response explaining what it did
final finalResponse = await chat.generateChatResponse();
if (finalResponse is TextResponse) {
print('Model: ${finalResponse.token}');
}
}Function Calling Best Practices:
- Use descriptive function names and clear descriptions
- Specify required vs optional parameters
- Always handle function execution errors gracefully
- Send meaningful responses back to the model
- The model will only call functions when explicitly requested by the user
- 🧠 Thinking Mode (DeepSeek Models)
DeepSeek models support "thinking mode" where you can see the model's reasoning process before it generates the final response. This provides transparency into how the model approaches problems.
Enable Thinking Mode:
final chat = await inferenceModel.createChat(
temperature: 0.8,
randomSeed: 1,
topK: 1,
isThinking: true, // Enable thinking mode
modelType: ModelType.deepSeek, // Required for DeepSeek models
supportsFunctionCalls: true, // DeepSeek also supports function calls
tools: _tools, // Optional: add tools for function calling
// tokenBuffer: 256, // Token buffer for context management
);Handle Thinking Responses:
chat.generateChatResponseAsync().listen((response) {
if (response is ThinkingResponse) {
// Model's reasoning process
print('Model is thinking: ${response.content}');
// Show thinking bubble in UI
_showThinkingBubble(response.content);
} else if (response is TextResponse) {
// Final response after thinking
print('Final answer: ${response.token}');
_updateFinalResponse(response.token);
} else if (response is FunctionCallResponse) {
// DeepSeek can also call functions while thinking
print('Function call: ${response.name}');
_handleFunctionCall(response);
}
});Thinking Mode Features:
- ✅ Transparent Reasoning: See how the model thinks through problems
- ✅ Interactive UI: Show/hide thinking bubbles with expandable content
- ✅ Streaming Support: Thinking content streams in real-time
- ✅ Function Integration: Models can think before calling functions
- ✅ DeepSeek Optimized: Designed specifically for DeepSeek model architecture
Example Thinking Flow:
-
User asks: "Change the background to blue and explain why blue is calming"
-
Model thinks: "I need to change the color first, then explain the psychology"
-
Model calls:
change_background_color(color: 'blue') -
Model explains: "Blue is calming because it's associated with sky and ocean..."
-
📊 Text Embedding Models (NEW!)
Generate vector embeddings from text using specialized embedding models. These models convert text into numerical vectors that can be used for semantic similarity, search, and RAG applications.
Supported Embedding Models:
- EmbeddingGemma models (256, 512, 1024, 2048 dimensions)
- Gecko 256 (256 dimensions)
Download Embedding Models:
// Create embedding model specification
final embeddingSpec = MobileModelManager.createEmbeddingSpec(
name: 'EmbeddingGemma 1024',
modelUrl: 'https://huggingface.co/litert-community/embeddinggemma-300m/resolve/main/embeddinggemma-300M_seq1024_mixed-precision.tflite',
tokenizerUrl: 'https://huggingface.co/litert-community/embeddinggemma-300m/resolve/main/sentencepiece.model',
);
// Download with progress tracking
final mobileManager = FlutterGemmaPlugin.instance.modelManager as MobileModelManager;
mobileManager.downloadModelWithProgress(embeddingSpec, token: 'your_hf_token').listen(
(progress) => print('Download progress: ${progress.overallProgress}%'),
onError: (error) => print('Download error: $error'),
onDone: () => print('Download completed'),
);Generate Text Embeddings:
// Create embedding model instance with downloaded files
final embeddingModel = await FlutterGemmaPlugin.instance.createEmbeddingModel(
modelPath: '/path/to/embeddinggemma-300M_seq1024_mixed-precision.tflite',
tokenizerPath: '/path/to/sentencepiece.model',
preferredBackend: PreferredBackend.gpu, // Optional: use GPU acceleration
);
// Generate embedding for single text
final embedding = await embeddingModel.generateEmbedding('Hello, world!');
print('Embedding vector: ${embedding.take(5)}...'); // Show first 5 dimensions
print('Embedding dimension: ${embedding.length}');
// Generate embeddings for multiple texts
final embeddings = await embeddingModel.generateEmbeddings([
'Hello, world!',
'How are you?',
'Flutter is awesome!'
]);
print('Generated ${embeddings.length} embeddings');
// Get embedding model dimension
final dimension = await embeddingModel.getDimension();
print('Model dimension: $dimension');
// Calculate cosine similarity between embeddings
double cosineSimilarity(List<double> a, List<double> b) {
double dotProduct = 0.0;
double normA = 0.0;
double normB = 0.0;
for (int i = 0; i < a.length; i++) {
dotProduct += a[i] * b[i];
normA += a[i] * a[i];
normB += b[i] * b[i];
}
return dotProduct / (math.sqrt(normA) * math.sqrt(normB));
}
final similarity = cosineSimilarity(embeddings[0], embeddings[1]);
print('Similarity: $similarity');
// Close model when done
await embeddingModel.close();Important Notes:
- EmbeddingGemma models require HuggingFace authentication token for gated repositories
- Embedding models use the same unified download and management system as inference models
- Each embedding model consists of both model file (.tflite) and tokenizer file (.model)
- Different dimension options allow trade-offs between accuracy and performance
- Checking Token Usage You can check the token size of a prompt before inference. The accumulated context should not exceed maxTokens to ensure smooth operation.
int tokenCount = await session.sizeInTokens('Your prompt text here');
print('Prompt size in tokens: $tokenCount');- Closing the Model
When you no longer need to perform any further inferences, call the close method to release resources:
await inferenceModel.close();If you need to use the inference again later, remember to call createModel again before generating responses.
The plugin now supports different types of messages:
// Text only
final textMessage = Message.text(text: "Hello!", isUser: true);
// Text + Image
final multimodalMessage = Message.withImage(
text: "What's in this image?",
imageBytes: imageBytes,
isUser: true,
);
// Image only
final imageMessage = Message.imageOnly(imageBytes: imageBytes, isUser: true);
// Tool response (for function calling)
final toolMessage = Message.toolResponse(
toolName: 'change_background_color',
response: {'status': 'success', 'color': 'blue'},
);
// System information message
final systemMessage = Message.systemInfo(text: "Function completed successfully");
// Thinking content (for DeepSeek models)
final thinkingMessage = Message.thinking(text: "Let me analyze this problem...");
// Check if message contains image
if (message.hasImage) {
print('This message contains an image');
}
// Create a copy of message
final copiedMessage = message.copyWith(text: "Updated text");The model can return different types of responses depending on capabilities:
// Handle different response types
chat.generateChatResponseAsync().listen((response) {
if (response is TextResponse) {
// Regular text token from the model
print('Text token: ${response.token}');
// Use response.token to update your UI incrementally
} else if (response is FunctionCallResponse) {
// Model wants to call a function (Gemma 3 Nano, DeepSeek, Qwen2.5)
print('Function: ${response.name}');
print('Arguments: ${response.args}');
// Execute the function and send response back
_handleFunctionCall(response);
} else if (response is ThinkingResponse) {
// Model's reasoning process (DeepSeek models only)
print('Thinking: ${response.content}');
// Show thinking process in UI
_showThinkingBubble(response.content);
}
});Response Types:
-
TextResponse: Contains a text token (response.token) for regular model output -
FunctionCallResponse: Contains function name (response.name) and arguments (response.args) when the model wants to call a function -
ThinkingResponse: Contains the model's reasoning process (response.content) for DeepSeek models with thinking mode enabled
- Gemma 2B & Gemma 7B
- Gemma-2 2B
- Gemma-3 1B
- Gemma 3 270M - Ultra-compact model
- TinyLlama 1.1B - Lightweight chat model
- Hammer 2.1 0.5B - Action model with function calling
- Llama 3.2 1B - Instruction-tuned model
- Phi-4
- DeepSeek
- Phi-2, Phi-3, Falcon-RW-1B, StableLM-3B
- Gemma 3 Nano E2B - 1.5B parameters with vision support
- Gemma 3 Nano E4B - 1.5B parameters with vision support
- EmbeddingGemma 256 - 300M parameters, 256 dimensions (179MB)
- EmbeddingGemma 512 - 300M parameters, 512 dimensions (179MB)
- EmbeddingGemma 1024 - 300M parameters, 1024 dimensions (183MB)
- EmbeddingGemma 2048 - 300M parameters, 2048 dimensions (196MB)
- Gecko 256 - 110M parameters, 256 dimensions (114MB)
Function calling is currently supported by the following models:
- Gemma 3 Nano models (E2B, E4B) - Full function calling support
- Hammer 2.1 0.5B - Action model with strong function calling capabilities
- DeepSeek models - Function calling + thinking mode support
- Qwen models - Full function calling support
- Gemma 3 1B models - Text generation only
- Gemma 3 270M - Text generation only
- TinyLlama 1.1B - Text generation only
- Llama 3.2 1B - Text generation only
- Phi models - Text generation only
Important Notes:
- When using unsupported models with tools, the plugin will log a warning and ignore the tools
- Models will work normally for text generation even if function calling is not supported
- Check the
supportsFunctionCallsproperty in your model configuration
| Feature | Android | iOS | Web |
|---|---|---|---|
| Text Generation | ✅ | ✅ | ✅ |
| Image Input | ✅ | ✅ | |
| Function Calling | ✅ | ✅ | ✅ |
| GPU Acceleration | ✅ | ✅ | ✅ |
| Streaming Responses | ✅ | ✅ | ✅ |
| LoRA Support | ✅ | ✅ | ✅ |
- ✅ = Fully supported
⚠️ = In development
The full and complete example you can find in example folder
- Model Size: Larger models (such as 7b and 7b-it) might be too resource-intensive for on-device inference.
- Function Calling Support: Gemma 3 Nano and DeepSeek models support function calling. Other models will ignore tools and show a warning.
-
Thinking Mode: Only DeepSeek models support thinking mode. Enable with
isThinking: trueandmodelType: ModelType.deepSeek. - Multimodal Models: Gemma 3 Nano models with vision support require more memory and are recommended for devices with 8GB+ RAM.
-
iOS Memory Requirements: Large models require memory entitlements in
Runner.entitlementsand minimum iOS 16.0. - LoRA Weights: They provide efficient customization without the need for full model retraining.
- Development vs. Production: For production apps, do not embed the model or LoRA weights within your assets. Instead, load them once and store them securely on the device or via a network drive.
- Web Models: Currently, Web support is available only for GPU backend models. Multimodal support is in development.
-
Image Formats: The plugin automatically handles common image formats (JPEG, PNG, etc.) when using
Message.withImage().
Multimodal Issues:
- Ensure you're using a multimodal model (Gemma 3 Nano E2B/E4B)
- Set
supportImage: truewhen creating model and chat - Check device memory - multimodal models require more RAM
Performance:
- Use GPU backend for better performance with multimodal models
- Consider using CPU backend for text-only models on lower-end devices
Memory Issues:
-
iOS: Ensure
Runner.entitlementscontains memory entitlements (see iOS setup) - iOS: Set minimum platform to iOS 16.0 in Podfile
- Reduce
maxTokensif experiencing memory issues - Use smaller models (1B-2B parameters) for devices with <6GB RAM
- Close sessions and models when not needed
- Monitor token usage with
sizeInTokens()
iOS Build Issues:
- Ensure minimum iOS version is set to 16.0 in Podfile
- Use static linking:
use_frameworks! :linkage => :static - Clean and reinstall pods:
cd ios && pod install --repo-update - Check that all required entitlements are in
Runner.entitlements
For advanced users who need to manually process model responses, the ModelThinkingFilter class provides utilities for cleaning model outputs:
import 'package:flutter_gemma/core/extensions.dart';
// Clean response based on model type
String cleanedResponse = ModelThinkingFilter.cleanResponse(
rawResponse,
ModelType.deepSeek
);
// The filter automatically removes model-specific tokens like:
// - <end_of_turn> tags (Gemma models)
// - Special DeepSeek tokens
// - Extra whitespace and formattingThis is automatically handled by the chat API, but can be useful for custom inference implementations.
✅ 📊 Text Embeddings - Generate vector embeddings with EmbeddingGemma and Gecko models for semantic search applications
✅ 🔧 Unified Model Management - Single system for managing both inference and embedding models with automatic validation
✅ 🛠️ Advanced Function Calling - Enable your models to call external functions and integrate with other services (Gemma 3 Nano, Hammer 2.1, DeepSeek, and Qwen2.5 models)
✅ 🧠 Thinking Mode - View the reasoning process of DeepSeek models with interactive thinking bubbles
✅ 💬 Enhanced Response Types - New TextResponse, FunctionCallResponse, and ThinkingResponse types for better handling
✅ 🖼️ Multimodal Support - Text + Image input with Gemma 3 Nano models
✅ 📨 Enhanced Message API - Support for different message types including tool responses
✅ ⚙️ Backend Switching - Choose between CPU and GPU backends individually for each model in the example app
✅ 🔍 Advanced Model Filtering - Filter models by features (Multimodal, Function Calls, Thinking) with expandable UI
✅ 📊 Model Sorting - Sort models alphabetically, by size, or use default order
✅ 🚀 New Models - Added Gemma 3 270M, TinyLlama 1.1B, Hammer 2.1 0.5B, and Llama 3.2 1B support
✅ 🌐 Cross-Platform - Works on Android, iOS, and Web (text-only)
✅ 💾 Memory Optimization - Better resource management for multimodal models
Coming Soon:
- Full Multimodal Web Support
- On-Device RAG Pipelines
- Desktop Support (macOS, Windows, Linux)
- Audio & Video Input
- Audio Output (Text-to-Speech)
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for flutter_gemma
Similar Open Source Tools
flutter_gemma
Flutter Gemma is a family of lightweight, state-of-the art open models that bring the power of Google's Gemma language models directly to Flutter applications. It allows for local execution on user devices, supports both iOS and Android platforms, and offers LoRA support for tailored AI behavior. The tool provides a simple interface for integrating Gemma models into Flutter projects, enabling advanced AI capabilities without relying on external servers. Users can easily download pre-trained Gemma models, fine-tune them for specific use cases, and customize behavior using LoRA weights. The tool supports model and LoRA weight management, model initialization, response generation, and chat scenarios, with considerations for model size, LoRA weights, and production app deployment.
aio-pika
Aio-pika is a wrapper around aiormq for asyncio and humans. It provides a completely asynchronous API, object-oriented API, transparent auto-reconnects with complete state recovery, Python 3.7+ compatibility, transparent publisher confirms support, transactions support, and complete type-hints coverage.
pixeltable
Pixeltable is a Python library designed for ML Engineers and Data Scientists to focus on exploration, modeling, and app development without the need to handle data plumbing. It provides a declarative interface for working with text, images, embeddings, and video, enabling users to store, transform, index, and iterate on data within a single table interface. Pixeltable is persistent, acting as a database unlike in-memory Python libraries such as Pandas. It offers features like data storage and versioning, combined data and model lineage, indexing, orchestration of multimodal workloads, incremental updates, and automatic production-ready code generation. The tool emphasizes transparency, reproducibility, cost-saving through incremental data changes, and seamless integration with existing Python code and libraries.
dive
Dive is an AI toolkit for Go that enables the creation of specialized teams of AI agents and seamless integration with leading LLMs. It offers a CLI and APIs for easy integration, with features like creating specialized agents, hierarchical agent systems, declarative configuration, multiple LLM support, extended reasoning, model context protocol, advanced model settings, tools for agent capabilities, tool annotations, streaming, CLI functionalities, thread management, confirmation system, deep research, and semantic diff. Dive also provides semantic diff analysis, unified interface for LLM providers, tool system with annotations, custom tool creation, and support for various verified models. The toolkit is designed for developers to build AI-powered applications with rich agent capabilities and tool integrations.
polyfire-js
Polyfire is an all-in-one managed backend for AI apps that allows users to build AI apps directly from the frontend, eliminating the need for a separate backend. It simplifies the process by providing most backend services in just a few lines of code. With Polyfire, users can easily create chatbots, transcribe audio files to text, generate simple text, create a long-term memory, and generate images with Dall-E. The tool also offers starter guides and tutorials to help users get started quickly and efficiently.

acte
Acte is a framework designed to build GUI-like tools for AI Agents. It aims to address the issues of cognitive load and freedom degrees when interacting with multiple APIs in complex scenarios. By providing a graphical user interface (GUI) for Agents, Acte helps reduce cognitive load and constraints interaction, similar to how humans interact with computers through GUIs. The tool offers APIs for starting new sessions, executing actions, and displaying screens, accessible via HTTP requests or the SessionManager class.
rust-genai
genai is a multi-AI providers library for Rust that aims to provide a common and ergonomic single API to various generative AI providers such as OpenAI, Anthropic, Cohere, Ollama, and Gemini. It focuses on standardizing chat completion APIs across major AI services, prioritizing ergonomics and commonality. The library initially focuses on text chat APIs and plans to expand to support images, function calling, and more in the future versions. Version 0.1.x will have breaking changes in patches, while version 0.2.x will follow semver more strictly. genai does not provide a full representation of a given AI provider but aims to simplify the differences at a lower layer for ease of use.
BrowserAI
BrowserAI is a tool that allows users to run large language models (LLMs) directly in the browser, providing a simple, fast, and open-source solution. It prioritizes privacy by processing data locally, is cost-effective with no server costs, works offline after initial download, and offers WebGPU acceleration for high performance. It is developer-friendly with a simple API, supports multiple engines, and comes with pre-configured models for easy use. Ideal for web developers, companies needing privacy-conscious AI solutions, researchers experimenting with browser-based AI, and hobbyists exploring AI without infrastructure overhead.
aiotdlib
aiotdlib is a Python asyncio Telegram client based on TDLib. It provides automatic generation of types and functions from tl schema, validation, good IDE type hinting, and high-level API methods for simpler work with tdlib. The package includes prebuilt TDLib binaries for macOS (arm64) and Debian Bullseye (amd64). Users can use their own binary by passing `library_path` argument to `Client` class constructor. Compatibility with other versions of the library is not guaranteed. The tool requires Python 3.9+ and users need to get their `api_id` and `api_hash` from Telegram docs for installation and usage.

probe
Probe is an AI-friendly, fully local, semantic code search tool designed to power the next generation of AI coding assistants. It combines the speed of ripgrep with the code-aware parsing of tree-sitter to deliver precise results with complete code blocks, making it perfect for large codebases and AI-driven development workflows. Probe supports various features like AI-friendly code extraction, fully local operation without external APIs, fast scanning of large codebases, accurate code structure parsing, re-rankers and NLP methods for better search results, multi-language support, interactive AI chat mode, and flexibility to run as a CLI tool, MCP server, or interactive AI chat.
mcp-ui
mcp-ui is a collection of SDKs that bring interactive web components to the Model Context Protocol (MCP). It allows servers to define reusable UI snippets, render them securely in the client, and react to their actions in the MCP host environment. The SDKs include @mcp-ui/server (TypeScript) for generating UI resources on the server, @mcp-ui/client (TypeScript) for rendering UI components on the client, and mcp_ui_server (Ruby) for generating UI resources in a Ruby environment. The project is an experimental community playground for MCP UI ideas, with rapid iteration and enhancements.
Scrapling
Scrapling is a high-performance, intelligent web scraping library for Python that automatically adapts to website changes while significantly outperforming popular alternatives. For both beginners and experts, Scrapling provides powerful features while maintaining simplicity. It offers features like fast and stealthy HTTP requests, adaptive scraping with smart element tracking and flexible selection, high performance with lightning-fast speed and memory efficiency, and developer-friendly navigation API and rich text processing. It also includes advanced parsing features like smart navigation, content-based selection, handling structural changes, and finding similar elements. Scrapling is designed to handle anti-bot protections and website changes effectively, making it a versatile tool for web scraping tasks.
node-sdk
The ChatBotKit Node SDK is a JavaScript-based platform for building conversational AI bots and agents. It offers easy setup, serverless compatibility, modern framework support, customizability, and multi-platform deployment. With capabilities like multi-modal and multi-language support, conversation management, chat history review, custom datasets, and various integrations, this SDK enables users to create advanced chatbots for websites, mobile apps, and messaging platforms.
mem0
Mem0 is a tool that provides a smart, self-improving memory layer for Large Language Models, enabling personalized AI experiences across applications. It offers persistent memory for users, sessions, and agents, self-improving personalization, a simple API for easy integration, and cross-platform consistency. Users can store memories, retrieve memories, search for related memories, update memories, get the history of a memory, and delete memories using Mem0. It is designed to enhance AI experiences by enabling long-term memory storage and retrieval.
BrowserAI
BrowserAI is a production-ready tool that allows users to run AI models directly in the browser, offering simplicity, speed, privacy, and open-source capabilities. It provides WebGPU acceleration for fast inference, zero server costs, offline capability, and developer-friendly features. Perfect for web developers, companies seeking privacy-conscious AI solutions, researchers experimenting with browser-based AI, and hobbyists exploring AI without infrastructure overhead. The tool supports various AI tasks like text generation, speech recognition, and text-to-speech, with pre-configured popular models ready to use. It offers a simple SDK with multiple engine support and seamless switching between MLC and Transformers engines.
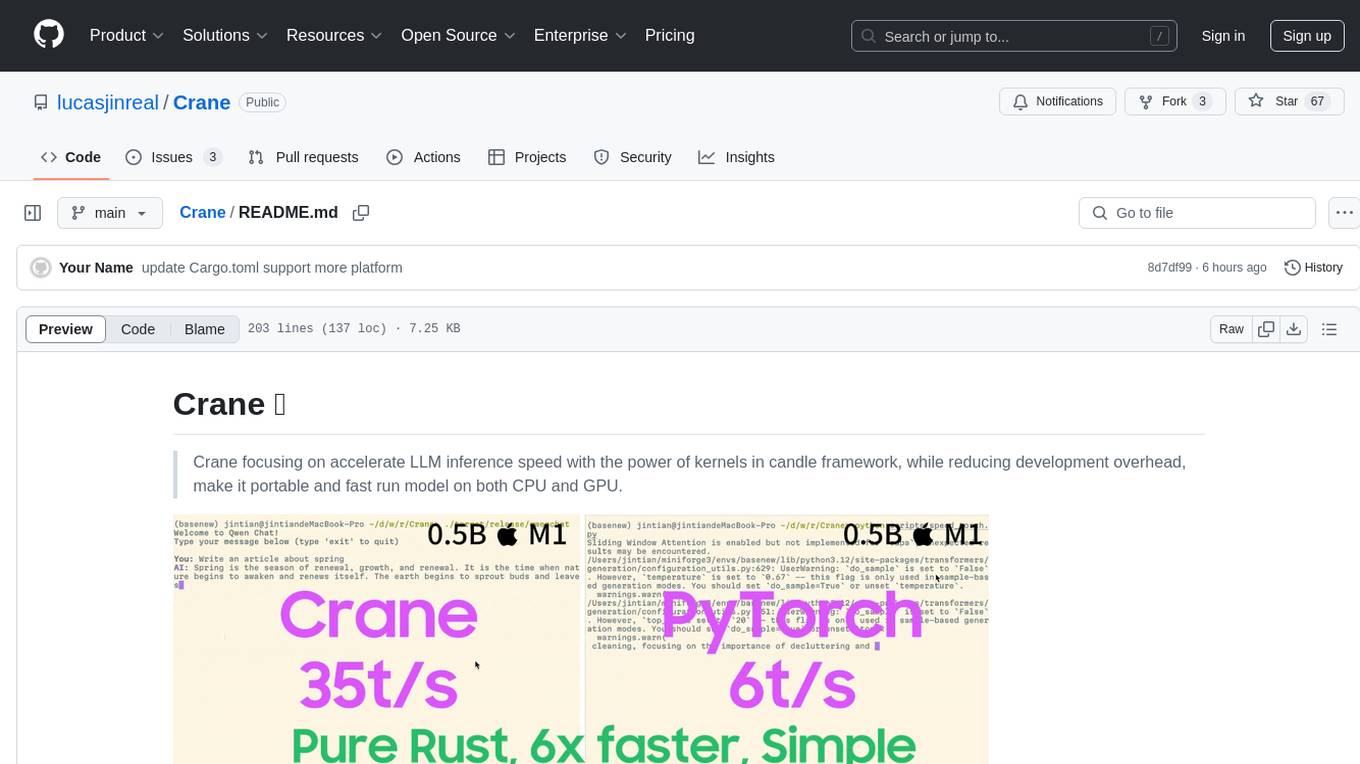
Crane
Crane is a high-performance inference framework leveraging Rust's Candle for maximum speed on CPU/GPU. It focuses on accelerating LLM inference speed with optimized kernels, reducing development overhead, and ensuring portability for running models on both CPU and GPU. Supported models include TTS systems like Spark-TTS and Orpheus-TTS, foundation models like Qwen2.5 series and basic LLMs, and multimodal models like Namo-R1 and Qwen2.5-VL. Key advantages of Crane include blazing-fast inference outperforming native PyTorch, Rust-powered to eliminate C++ complexity, Apple Silicon optimized for GPU acceleration via Metal, and hardware agnostic with a unified codebase for CPU/CUDA/Metal execution. Crane simplifies deployment with the ability to add new models with less than 100 lines of code in most cases.
For similar tasks

LeanCopilot
Lean Copilot is a tool that enables the use of large language models (LLMs) in Lean for proof automation. It provides features such as suggesting tactics/premises, searching for proofs, and running inference of LLMs. Users can utilize built-in models from LeanDojo or bring their own models to run locally or on the cloud. The tool supports platforms like Linux, macOS, and Windows WSL, with optional CUDA and cuDNN for GPU acceleration. Advanced users can customize behavior using Tactic APIs and Model APIs. Lean Copilot also allows users to bring their own models through ExternalGenerator or ExternalEncoder. The tool comes with caveats such as occasional crashes and issues with premise selection and proof search. Users can get in touch through GitHub Discussions for questions, bug reports, feature requests, and suggestions. The tool is designed to enhance theorem proving in Lean using LLMs.
langflow
Langflow is an open-source Python-powered visual framework designed for building multi-agent and RAG applications. It is fully customizable, language model agnostic, and vector store agnostic. Users can easily create flows by dragging components onto the canvas, connect them, and export the flow as a JSON file. Langflow also provides a command-line interface (CLI) for easy management and configuration, allowing users to customize the behavior of Langflow for development or specialized deployment scenarios. The tool can be deployed on various platforms such as Google Cloud Platform, Railway, and Render. Contributors are welcome to enhance the project on GitHub by following the contributing guidelines.
TypeGPT
TypeGPT is a Python application that enables users to interact with ChatGPT or Google Gemini from any text field in their operating system using keyboard shortcuts. It provides global accessibility, keyboard shortcuts for communication, and clipboard integration for larger text inputs. Users need to have Python 3.x installed along with specific packages and API keys from OpenAI for ChatGPT access. The tool allows users to run the program normally or in the background, manage processes, and stop the program. Users can use keyboard shortcuts like `/ask`, `/see`, `/stop`, `/chatgpt`, `/gemini`, `/check`, and `Shift + Cmd + Enter` to interact with the application in any text field. Customization options are available by modifying files like `keys.txt` and `system_prompt.txt`. Contributions are welcome, and future plans include adding support for other APIs and a user-friendly GUI.
HookPHP
HookPHP is an open-source project that provides a PHP extension for hooking into various aspects of PHP applications. It allows developers to easily extend and customize the behavior of their PHP applications by providing hooks at key points in the execution flow. With HookPHP, developers can efficiently add custom functionality, modify existing behavior, and enhance the overall performance of their PHP applications. The project is licensed under the MIT license, making it accessible for developers to use and contribute to.
flutter_gemma
Flutter Gemma is a family of lightweight, state-of-the art open models that bring the power of Google's Gemma language models directly to Flutter applications. It allows for local execution on user devices, supports both iOS and Android platforms, and offers LoRA support for tailored AI behavior. The tool provides a simple interface for integrating Gemma models into Flutter projects, enabling advanced AI capabilities without relying on external servers. Users can easily download pre-trained Gemma models, fine-tune them for specific use cases, and customize behavior using LoRA weights. The tool supports model and LoRA weight management, model initialization, response generation, and chat scenarios, with considerations for model size, LoRA weights, and production app deployment.
tiledesk-chatbot
Tiledesk Chatbot Engine is a Node.js-based framework for creating and managing interactive chatbots. It is designed to work seamlessly with the Tiledesk Design Studio, allowing easy design and customization of chatbot behavior. The engine is scalable, performant, and encourages collaboration and innovation through its open-source nature under the MIT license.
claude-code-settings
A repository collecting best practices for Claude Code settings and customization. It provides configuration files for customizing Claude Code's behavior and building an efficient development environment. The repository includes custom agents and skills for specific domains, interactive development workflow features, efficient development rules, and team workflow with Codex MCP. Users can leverage the provided configuration files and tools to enhance their development process and improve code quality.
semantic-router
Semantic Router is a superfast decision-making layer for your LLMs and agents. Rather than waiting for slow LLM generations to make tool-use decisions, we use the magic of semantic vector space to make those decisions — _routing_ our requests using _semantic_ meaning.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.