
llm-in-sandbox
LLM-in-Sandbox Elicits General Agentic Intelligence
Stars: 185
LLM-in-Sandbox is a project that aims to unlock general agentic intelligence by placing a large language model (LLM) inside a code sandbox with basic computer capabilities. This approach allows the LLM to outperform standalone models across various domains such as chemistry, physics, math, biomedicine, long-context understanding, and instruction-following without additional training. The project leverages reinforcement learning (RL) to further enhance performance, with benefits including consistent improvements in non-code domains, using the file system as long-term memory for up to 8× token savings, Docker isolation for security, and compatibility with various LLM providers like OpenAI, Anthropic, vLLM, and SGLang.
README:
🌐 Project Page • 📄 Paper • 🤗 Huggingface • 📦 Model and Data • 🎬 Youtube Video • 💻 LLM-in-Sandbox-RL
As vibe coding becomes common and 🦞 OpenClaw draws widespread attention, we present the first systematic study showing that placing an LLM inside a code sandbox with basic computer capabilities lets it significantly outperform standalone LLMs across chemistry, physics, math, biomedicine, long-context understanding, and instruction-following with no extra training. RL further amplifies the gains.
- 📈 Consistent improvements across diverse non-code domains
- 🧠 File system as long-term memory, up to 8× token savings
- 🐳 Docker isolation for security (vs. unrestricted setups like 🦞 OpenClaw)
- 🔌 Works with OpenAI, Anthropic, vLLM, SGLang, etc.
Feel free to open an issue if you have any questions or run into any problems. We'd be happy to help!

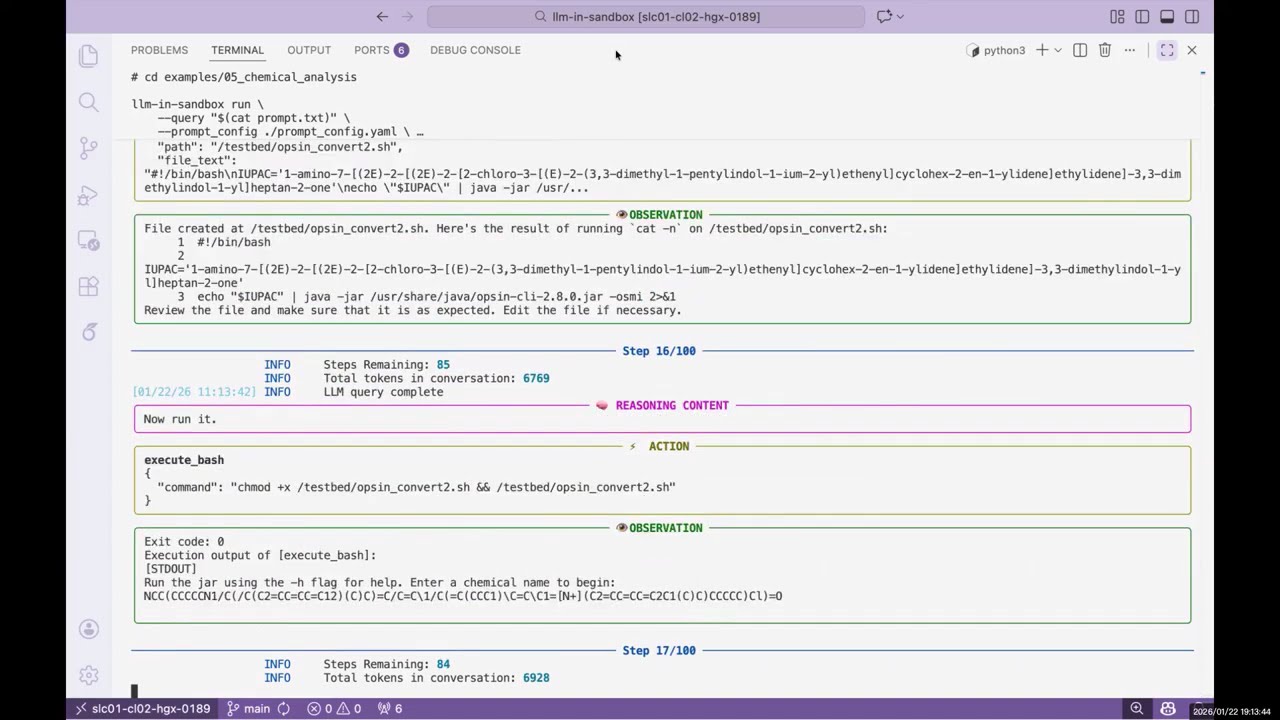
- [2026-02-12] Released code, data, and wandb log for LLM-in-Sandbox Reinforcement Learning at LLM-in-Sandbox-RL.
- [2026-02-11] v0.2.0: Added benchmark module for reproducing paper results, evaluating any LLM, and adding your own tasks.
Requirements: Python 3.10+, Docker
pip install llm-in-sandboxOr install from source:
git clone https://github.com/llm-in-sandbox/llm-in-sandbox.git
cd llm-in-sandbox
pip install -e .Docker Image
The default Docker image (cdx123/llm-in-sandbox:v0.1) will be automatically pulled when you first run the agent. The first run may take a minute to download the image (~400MB), but subsequent runs will start instantly.
LLM-in-Sandbox works with various LLM providers including OpenAI, Anthropic, and self-hosted servers (vLLM, SGLang, etc.).
llm-in-sandbox run \
--query "write a hello world in python" \
--llm_name "openai/gpt-5" \
--llm_base_url "http://your-api-server/v1" \
--api_key "your-api-key"Using local vLLM server for Qwen3-Coder-30B-A3B-Instruct
1. Start vLLM server:
vllm serve Qwen/Qwen3-Coder-30B-A3B-Instruct \
--served-model-name qwen3_coder \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder \
--tensor-parallel-size 8 \
--enable-prefix-caching2. Run agent (in a new terminal once server is ready):
llm-in-sandbox run \
--query "write a hello world in python" \
--llm_name qwen3_coder \
--llm_base_url "http://localhost:8000/v1" \
--temperature 0.7Using local SGLang server for DeepSeek-V3.2-Thinking
1. Start sgLang server:
python3 -m sglang.launch_server \
--model-path "deepseek-ai/DeepSeek-V3.2" \
--served-model-name "DeepSeek-V3.2" \
--trust-remote-code \
--tp-size 8 \
--tool-call-parser deepseekv32 \
--reasoning-parser deepseek-v3 \
--host 0.0.0.0 \
--port 56782. Run agent (in a new terminal once server is ready):
llm-in-sandbox run \
--query "write a hello world in python" \
--llm_name DeepSeek-V3.2 \
--llm_base_url "http://0.0.0.0:5678/v1" \
--extra_body '{"chat_template_kwargs": {"thinking": True}}'| Parameter | Description | Default |
|---|---|---|
--query |
Task for the agent | required |
--llm_name |
Model name | required |
--llm_base_url |
API endpoint URL | from LLM_BASE_URL env var |
--api_key |
API key (not needed for local server) | from OPENAI_API_KEY env var |
--input_dir |
Input files folder to mount (Optional) | None |
--output_dir |
Output folder for results | ./output |
--docker_image |
Docker image to use | cdx123/llm-in-sandbox:v0.1 |
--prompt_config |
Path to prompt template | ./config/general.yaml |
--temperature |
Sampling temperature | 1.0 |
--max_steps |
Max conversation turns | 100 |
--extra_body |
Extra JSON body for LLM API calls | None |
Run llm-in-sandbox run --help for all available parameters.
Each run creates a timestamped folder:
output/2026-01-16_14-30-00/
├── files/
│ ├── answer.txt # Final answer
│ └── hello_world.py # Output file
└── trajectory.json # Execution history
We provide examples across diverse non-coding domains: scientific reasoning, long-context understanding, instruction following, travel planning, video production, music composition, poster design, and more.
👉 See examples/README.md for the full list.
Reproduce our paper results, evaluate any LLM in the sandbox, or add your own tasks.
👉 See llm_in_sandbox/benchmark/README.md
Feel free to open an issue if you have any questions or run into any problems, we’d be happy to help! You can also reach us directly at [email protected] and [email protected].
We learned the design and reused code from R2E-Gym. Thanks for the great work!
If you find our work helpful, please cite us:
@article{cheng2026llm,
title={Llm-in-sandbox elicits general agentic intelligence},
author={Cheng, Daixuan and Huang, Shaohan and Gu, Yuxian and Song, Huatong and Chen, Guoxin and Dong, Li and Zhao, Wayne Xin and Wen, Ji-Rong and Wei, Furu},
journal={arXiv preprint arXiv:2601.16206},
year={2026}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llm-in-sandbox
Similar Open Source Tools
llm-in-sandbox
LLM-in-Sandbox is a project that aims to unlock general agentic intelligence by placing a large language model (LLM) inside a code sandbox with basic computer capabilities. This approach allows the LLM to outperform standalone models across various domains such as chemistry, physics, math, biomedicine, long-context understanding, and instruction-following without additional training. The project leverages reinforcement learning (RL) to further enhance performance, with benefits including consistent improvements in non-code domains, using the file system as long-term memory for up to 8× token savings, Docker isolation for security, and compatibility with various LLM providers like OpenAI, Anthropic, vLLM, and SGLang.
ai-coders-context
The @ai-coders/context repository provides the Ultimate MCP for AI Agent Orchestration, Context Engineering, and Spec-Driven Development. It simplifies context engineering for AI by offering a universal process called PREVC, which consists of Planning, Review, Execution, Validation, and Confirmation steps. The tool aims to address the problem of context fragmentation by introducing a single `.context/` directory that works universally across different tools. It enables users to create structured documentation, generate agent playbooks, manage workflows, provide on-demand expertise, and sync across various AI tools. The tool follows a structured, spec-driven development approach to improve AI output quality and ensure reproducible results across projects.
green-bit-llm
Green-Bit-LLM is a Python toolkit designed for fine-tuning, inferencing, and evaluating GreenBitAI's low-bit Language Models (LLMs). It utilizes the Bitorch Engine for efficient operations on low-bit LLMs, enabling high-performance inference on various GPUs and supporting full-parameter fine-tuning using quantized LLMs. The toolkit also provides evaluation tools to validate model performance on benchmark datasets. Green-Bit-LLM is compatible with AutoGPTQ series of 4-bit quantization and compression models.
pr-pilot
PR Pilot is an AI-powered tool designed to assist users in their daily workflow by delegating routine work to AI with confidence and predictability. It integrates seamlessly with popular development tools and allows users to interact with it through a Command-Line Interface, Python SDK, REST API, and Smart Workflows. Users can automate tasks such as generating PR titles and descriptions, summarizing and posting issues, and formatting README files. The tool aims to save time and enhance productivity by providing AI-powered solutions for common development tasks.

skyvern
Skyvern automates browser-based workflows using LLMs and computer vision. It provides a simple API endpoint to fully automate manual workflows, replacing brittle or unreliable automation solutions. Traditional approaches to browser automations required writing custom scripts for websites, often relying on DOM parsing and XPath-based interactions which would break whenever the website layouts changed. Instead of only relying on code-defined XPath interactions, Skyvern adds computer vision and LLMs to the mix to parse items in the viewport in real-time, create a plan for interaction and interact with them. This approach gives us a few advantages: 1. Skyvern can operate on websites it’s never seen before, as it’s able to map visual elements to actions necessary to complete a workflow, without any customized code 2. Skyvern is resistant to website layout changes, as there are no pre-determined XPaths or other selectors our system is looking for while trying to navigate 3. Skyvern leverages LLMs to reason through interactions to ensure we can cover complex situations. Examples include: 1. If you wanted to get an auto insurance quote from Geico, the answer to a common question “Were you eligible to drive at 18?” could be inferred from the driver receiving their license at age 16 2. If you were doing competitor analysis, it’s understanding that an Arnold Palmer 22 oz can at 7/11 is almost definitely the same product as a 23 oz can at Gopuff (even though the sizes are slightly different, which could be a rounding error!) Want to see examples of Skyvern in action? Jump to #real-world-examples-of- skyvern

OSA
OSA (Open-Source-Advisor) is a tool designed to improve the quality of scientific open source projects by automating the generation of README files, documentation, CI/CD scripts, and providing advice and recommendations for repositories. It supports various LLMs accessible via API, local servers, or osa_bot hosted on ITMO servers. OSA is currently under development with features like README file generation, documentation generation, automatic implementation of changes, LLM integration, and GitHub Action Workflow generation. It requires Python 3.10 or higher and tokens for GitHub/GitLab/Gitverse and LLM API key. Users can install OSA using PyPi or build from source, and run it using CLI commands or Docker containers.

LongLoRA
LongLoRA is a tool for efficient fine-tuning of long-context large language models. It includes LongAlpaca data with long QA data collected and short QA sampled, models from 7B to 70B with context length from 8k to 100k, and support for GPTNeoX models. The tool supports supervised fine-tuning, context extension, and improved LoRA fine-tuning. It provides pre-trained weights, fine-tuning instructions, evaluation methods, local and online demos, streaming inference, and data generation via Pdf2text. LongLoRA is licensed under Apache License 2.0, while data and weights are under CC-BY-NC 4.0 License for research use only.

agentscope
AgentScope is a multi-agent platform designed to empower developers to build multi-agent applications with large-scale models. It features three high-level capabilities: Easy-to-Use, High Robustness, and Actor-Based Distribution. AgentScope provides a list of `ModelWrapper` to support both local model services and third-party model APIs, including OpenAI API, DashScope API, Gemini API, and ollama. It also enables developers to rapidly deploy local model services using libraries such as ollama (CPU inference), Flask + Transformers, Flask + ModelScope, FastChat, and vllm. AgentScope supports various services, including Web Search, Data Query, Retrieval, Code Execution, File Operation, and Text Processing. Example applications include Conversation, Game, and Distribution. AgentScope is released under Apache License 2.0 and welcomes contributions.
Online-RLHF
This repository, Online RLHF, focuses on aligning large language models (LLMs) through online iterative Reinforcement Learning from Human Feedback (RLHF). It aims to bridge the gap in existing open-source RLHF projects by providing a detailed recipe for online iterative RLHF. The workflow presented here has shown to outperform offline counterparts in recent LLM literature, achieving comparable or better results than LLaMA3-8B-instruct using only open-source data. The repository includes model releases for SFT, Reward model, and RLHF model, along with installation instructions for both inference and training environments. Users can follow step-by-step guidance for supervised fine-tuning, reward modeling, data generation, data annotation, and training, ultimately enabling iterative training to run automatically.
memorix
Memorix is a cross-agent memory bridge tool designed to prevent AI assistants from forgetting important information during chats or when switching between different agents. It allows users to store and retrieve architecture decisions, bug fixes, technical explanations, code changes, insights, design choices, and more across various agents seamlessly. With Memorix, users can avoid re-explaining concepts, prevent context loss when switching agents, collaborate effectively, sync workspaces, generate project skills, and utilize a knowledge graph for intelligent retrieval. The tool offers 24 MCP tools for smart memory management, cross-agent workspace sync, a knowledge graph compatible with MCP Official Memory Server, various observation types, a visual dashboard, auto-memory hooks, and optional vector search for semantic similarity. Memorix ensures project isolation, local data storage, and zero cross-contamination, making it a valuable tool for enhancing productivity and knowledge retention in AI-driven workflows.
paperbanana
PaperBanana is an automated academic illustration tool designed for AI scientists. It implements an agentic framework for generating publication-quality academic diagrams and statistical plots from text descriptions. The tool utilizes a two-phase multi-agent pipeline with iterative refinement, Gemini-based VLM planning, and image generation. It offers a CLI, Python API, and MCP server for IDE integration, along with Claude Code skills for generating diagrams, plots, and evaluating diagrams. PaperBanana is not affiliated with or endorsed by the original authors or Google Research, and it may differ from the original system described in the paper.
agents
AI agent tooling for data engineering workflows. Includes an MCP server for Airflow, a CLI tool for interacting with Airflow from your terminal, and skills that extend AI coding agents with specialized capabilities for working with Airflow and data warehouses. Works with Claude Code, Cursor, and other agentic coding tools. The tool provides a comprehensive set of features for data discovery & analysis, data lineage, DAG development, dbt integration, migration, and more. It also offers user journeys for data analysis flow and DAG development flow. The Airflow CLI tool allows users to interact with Airflow directly from the terminal. The tool supports various databases like Snowflake, PostgreSQL, Google BigQuery, and more, with auto-detected SQLAlchemy databases. Skills are invoked automatically based on user queries or can be invoked directly using specific commands.

optillm
optillm is an OpenAI API compatible optimizing inference proxy implementing state-of-the-art techniques to enhance accuracy and performance of LLMs, focusing on reasoning over coding, logical, and mathematical queries. By leveraging additional compute at inference time, it surpasses frontier models across diverse tasks.
rank_llm
RankLLM is a suite of prompt-decoders compatible with open source LLMs like Vicuna and Zephyr. It allows users to create custom ranking models for various NLP tasks, such as document reranking, question answering, and summarization. The tool offers a variety of features, including the ability to fine-tune models on custom datasets, use different retrieval methods, and control the context size and variable passages. RankLLM is easy to use and can be integrated into existing NLP pipelines.

OpenResearcher
OpenResearcher is a fully open agentic large language model designed for long-horizon deep research scenarios. It achieves an impressive 54.8% accuracy on BrowseComp-Plus, surpassing performance of GPT-4.1, Claude-Opus-4, Gemini-2.5-Pro, DeepSeek-R1, and Tongyi-DeepResearch. The tool is fully open-source, providing the training and evaluation recipe—including data, model, training methodology, and evaluation framework for everyone to progress deep research. It offers features like a fully open-source recipe, highly scalable and low-cost generation of deep research trajectories, and remarkable performance on deep research benchmarks.

evalverse
Evalverse is an open-source project designed to support Large Language Model (LLM) evaluation needs. It provides a standardized and user-friendly solution for processing and managing LLM evaluations, catering to AI research engineers and scientists. Evalverse supports various evaluation methods, insightful reports, and no-code evaluation processes. Users can access unified evaluation with submodules, request evaluations without code via Slack bot, and obtain comprehensive reports with scores, rankings, and visuals. The tool allows for easy comparison of scores across different models and swift addition of new evaluation tools.
For similar tasks
llm-in-sandbox
LLM-in-Sandbox is a project that aims to unlock general agentic intelligence by placing a large language model (LLM) inside a code sandbox with basic computer capabilities. This approach allows the LLM to outperform standalone models across various domains such as chemistry, physics, math, biomedicine, long-context understanding, and instruction-following without additional training. The project leverages reinforcement learning (RL) to further enhance performance, with benefits including consistent improvements in non-code domains, using the file system as long-term memory for up to 8× token savings, Docker isolation for security, and compatibility with various LLM providers like OpenAI, Anthropic, vLLM, and SGLang.
MiniCPM
MiniCPM is a series of open-source large models on the client side jointly developed by Face Intelligence and Tsinghua University Natural Language Processing Laboratory. The main language model MiniCPM-2B has only 2.4 billion (2.4B) non-word embedding parameters, with a total of 2.7B parameters. - After SFT, MiniCPM-2B performs similarly to Mistral-7B on public comprehensive evaluation sets (better in Chinese, mathematics, and code capabilities), and outperforms models such as Llama2-13B, MPT-30B, and Falcon-40B overall. - After DPO, MiniCPM-2B also surpasses many representative open-source large models such as Llama2-70B-Chat, Vicuna-33B, Mistral-7B-Instruct-v0.1, and Zephyr-7B-alpha on the current evaluation set MTBench, which is closest to the user experience. - Based on MiniCPM-2B, a multi-modal large model MiniCPM-V 2.0 on the client side is constructed, which achieves the best performance of models below 7B in multiple test benchmarks, and surpasses larger parameter scale models such as Qwen-VL-Chat 9.6B, CogVLM-Chat 17.4B, and Yi-VL 34B on the OpenCompass leaderboard. MiniCPM-V 2.0 also demonstrates leading OCR capabilities, approaching Gemini Pro in scene text recognition capabilities. - After Int4 quantization, MiniCPM can be deployed and inferred on mobile phones, with a streaming output speed slightly higher than human speech speed. MiniCPM-V also directly runs through the deployment of multi-modal large models on mobile phones. - A single 1080/2080 can efficiently fine-tune parameters, and a single 3090/4090 can fully fine-tune parameters. A single machine can continuously train MiniCPM, and the secondary development cost is relatively low.

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.

suno-api
Suno AI API is an open-source project that allows developers to integrate the music generation capabilities of Suno.ai into their own applications. The API provides a simple and convenient way to generate music, lyrics, and other audio content using Suno.ai's powerful AI models. With Suno AI API, developers can easily add music generation functionality to their apps, websites, and other projects.

openvino-plugins-ai-audacity
OpenVINO™ AI Plugins for Audacity* are a set of AI-enabled effects, generators, and analyzers for Audacity®. These AI features run 100% locally on your PC -- no internet connection necessary! OpenVINO™ is used to run AI models on supported accelerators found on the user's system such as CPU, GPU, and NPU. * **Music Separation**: Separate a mono or stereo track into individual stems -- Drums, Bass, Vocals, & Other Instruments. * **Noise Suppression**: Removes background noise from an audio sample. * **Music Generation & Continuation**: Uses MusicGen LLM to generate snippets of music, or to generate a continuation of an existing snippet of music. * **Whisper Transcription**: Uses whisper.cpp to generate a label track containing the transcription or translation for a given selection of spoken audio or vocals.
SunoApi
SunoAPI is an unofficial client for Suno AI, built on Python and Streamlit. It supports functions like generating music and obtaining music information. Users can set up multiple account information to be saved for use. The tool also features built-in maintenance and activation functions for tokens, eliminating concerns about token expiration. It supports multiple languages and allows users to upload pictures for generating songs based on image content analysis.
awesome-generative-ai
Awesome Generative AI is a curated list of modern Generative Artificial Intelligence projects and services. Generative AI technology creates original content like images, sounds, and texts using machine learning algorithms trained on large data sets. It can produce unique and realistic outputs such as photorealistic images, digital art, music, and writing. The repo covers a wide range of applications in art, entertainment, marketing, academia, and computer science.

ai-audio-datasets
AI Audio Datasets List (AI-ADL) is a comprehensive collection of datasets consisting of speech, music, and sound effects, used for Generative AI, AIGC, AI model training, and audio applications. It includes datasets for speech recognition, speech synthesis, music information retrieval, music generation, audio processing, sound synthesis, and more. The repository provides a curated list of diverse datasets suitable for various AI audio tasks.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.