
basdonax-ai-rag
None
Stars: 102
Basdonax AI RAG v1.0 is a repository that contains all the necessary resources to create your own AI-powered secretary using the RAG from Basdonax AI. It leverages open-source models from Meta and Microsoft, namely 'Llama3-7b' and 'Phi3-4b', allowing users to upload documents and make queries. This tool aims to simplify life for individuals by harnessing the power of AI. The installation process involves choosing between different data models based on GPU capabilities, setting up Docker, pulling the desired model, and customizing the assistant prompt file. Once installed, users can access the RAG through a local link and enjoy its functionalities.
README:
Este repositorio contiene todo lo necesario para poder crear tu propia secretaria hecha con Inteligencia Artificial, todo gracias al RAG de Basdonax AI, que utiliza los modelos open source de Meta y de Microsoft: Llama3-7b y Phi3-4b para de esta forma darte la posibilidad de subir tus documentos y hacer consultas a los mismos. Esto fue creado para poder facilitarle la vida a las personas con la IA.
- Docker o Docker desktop: https://www.docker.com/products/docker-desktop/
- (opcional) Tarjeta gráfica RTX
Antes de comenzar con la instalación, tenemos que analizar si tenemos o no una tarjeta gráfica capaz de utilizar Llama3-7b o no. Si tenemos una tarjeta gráfica capaz de utilizar este modelo de datos utilizaremos el archivo docker-compose.yml, si no contamos con esa posibilidad vamos a eliminar el docker-compose.yml y vamos a renombrar el archivo docker-compose_sin_gpu.yml por docker-compose.yml. La diferencia entre un archivo y otro es que el docker-compose_sin_gpu.yml utiliza el LLM Phi3-4b, que es mucho más ligero para correrlo en el procesador de tu PC, mientras que Llama3-7b es mucho más pesado y si bien puede correr en CPU, es más recomendable una gráfica. En el video voy a estar utilizando una RTX 4060 8GB.
Tenemos que tener Docker o Docker Desktop instalado, te recomiendo ver este video para instalar todo: https://www.youtube.com/watch?v=ZyBBv1JmnWQ
Una vez instalado y prendido el Docker Desktop si lo estamos utilizando, vamos a ejecutar en esta misma carpeta:
docker-compose up
La primera vez vamos a tener que esperar a que todo se instale correctamente, va a tardar unos cuantos minutos en ese paso.
Ahora tenemos que instalarnos nuestro modelo LLM, si tenemos una GPU que pueda soportar vamos a ejecutar el comando para traernos Llama3, sino va a ser Phi3 (si queremos utilizar otro modelo, en esta pagina: https://ollama.com/library tenes la lista de todos los modelos open source posibles en esta página, recorda que seguramente vayas a tener que hacer cambios en la prompt si cambias el modelo), ejecutamos:
docker ps
Te va a aparecer algo como esto:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
696d2e45ce7c ui "/bin/sh -c 'streaml…" About a minute ago Up About a minute 0.0.0.0:8080->8080/tcp ui-1
28cf32abee50 ollama/ollama:latest "/bin/ollama serve" About a minute ago Up About a minute 11434/tcp ollama-1
ec09714c3c86 chromadb/chroma:latest "/docker_entrypoint.…" About a minute ago Up About a minute 0.0.0.0:8000->8000/tcp chroma-1
En esta parte tenés que copiar el CONTAINER ID de la imagen llamada ollama/ollama:latest y utilizarla para este comando:
docker exec [CONTAINER ID] ollama pull [nombredelmodelo]
Un ejemplo con Llama3-7b y mi CONTAINER ID
docker exec 28cf32abee50 ollama pull llama3
Un ejemplo con Phi3-4b y mi CONTAINER ID
docker exec 28cf32abee50 ollama pull phi3
Ahora vamos a tener que esperar a que se descargue el modelo, una vez hecho esto solo nos queda modificar la prompt:
Esto se va a hacer a nuestro gusto en el archivo ./app/common/assistant_prompt.py.
Una vez hecho todo lo anterior solo queda un paso: que entremos al siguiente link: http://localhost:8080 para poder utilizar el RAG.
Tenemos que dejarnos en el escritorio el archivo de open_rag.bat si estamos en Windows y si estamos en Mac/Linux el open_rag.sh
Ahora tenemos que abrirlo y modificarlo, tenemos que agregar la ruta donde hicimos/tenemos el docker-compose.yml, por ejemplo mi ruta es:
C:\Users\fcore\OneDrive\Desktop\Basdonax\basdonax-rag>
Entonces en mi caso va a ser así el open_rag.bat (el .sh es lo mismo):
cd C:\Users\fcore\OneDrive\Desktop\Basdonax\basdonax-rag
docker-compose up -d
Ahora mientras que tengamos el Docker/Docker Desktop prendido y mientras que ejecutemos este archivo vamos a poder acceder al RAG en este link: http://localhost:8080
Próximo paso: disfrutar
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for basdonax-ai-rag
Similar Open Source Tools
basdonax-ai-rag
Basdonax AI RAG v1.0 is a repository that contains all the necessary resources to create your own AI-powered secretary using the RAG from Basdonax AI. It leverages open-source models from Meta and Microsoft, namely 'Llama3-7b' and 'Phi3-4b', allowing users to upload documents and make queries. This tool aims to simplify life for individuals by harnessing the power of AI. The installation process involves choosing between different data models based on GPU capabilities, setting up Docker, pulling the desired model, and customizing the assistant prompt file. Once installed, users can access the RAG through a local link and enjoy its functionalities.
AireLibre
AireLibre is a community response to the need for freely, collaboratively, and decentralized air quality information. It includes projects like Red Descentralizada de Aire Libre (ReDAL), Linka, Linka Firmware, LinkaBot, AQmap, and Android/iOS apps. Users can join the network with a sensor communicating with Linka. Materials and tools are needed to build a sensor. The initiative is decentralized and open for community collaboration. Users can extend or add projects to AireLibre. The license allows for creating personal networks. AireLibre is not for professional/industrial/scientific/military use, and the sensors are not calibrated in Switzerland.
switch_AIO_LS_pack
Switch_AIO_LS_pack is a comprehensive package for setting up the SD card of the Nintendo Switch. It includes custom firmware, homebrew applications, payloads, and essential modules to enhance the console experience. The pack also contains the latest firmware and has been prepared using the Ultimate-Switch-Hack-Script project in collaboration with the user nightwolf from Logic-sunrise. It is compatible with all models of the Switch.
Airchains
Airchains is a tool for setting up a local EVM network for testing and development purposes. It provides step-by-step instructions for installing and configuring the necessary components. The tool helps users create their own local EVM network, manage keys, deploy contracts, and interact with the network using RPC. It also guides users on setting up a station for tracking and managing transactions. Airchains is designed to facilitate testing and development activities related to blockchain applications built on the EVM platform.
tafrigh
Tafrigh is a tool for transcribing visual and audio content into text using advanced artificial intelligence techniques provided by OpenAI and wit.ai. It allows direct downloading of content from platforms like YouTube, Facebook, Twitter, and SoundCloud, and provides various output formats such as txt, srt, vtt, csv, tsv, and json. Users can install Tafrigh via pip or by cloning the GitHub repository and using Poetry. The tool supports features like skipping transcription if output exists, specifying playlist items, setting download retries, using different Whisper models, and utilizing wit.ai for transcription. Tafrigh can be used via command line or programmatically, and Docker images are available for easy usage.
VinAI_Translate
VinAI_Translate is a Vietnamese-English Neural Machine Translation System offering state-of-the-art text-to-text translation models for Vietnamese-to-English and English-to-Vietnamese. The system includes pre-trained models with different configurations and parameters, allowing for further fine-tuning. Users can interact with the models through the VinAI Translate system website or the HuggingFace space 'VinAI Translate'. Evaluation scripts are available for assessing the translation quality. The tool can be used in the 'transformers' library for Vietnamese-to-English and English-to-Vietnamese translations, supporting both GPU-based batch translation and CPU-based sequence translation examples.

underthesea
Underthesea is an open-source Vietnamese Natural Language Processing toolkit that provides easy API access to pretrained NLP models for tasks such as word segmentation, part-of-speech tagging, named entity recognition, text classification, and dependency parsing. The toolkit also includes features like Conversational AI Agent for chatting with an AI assistant specialized in Vietnamese NLP. It supports various Python versions and offers tutorials for different NLP tasks like sentence segmentation, text normalization, tagging, classification, sentiment analysis, named entity recognition, language detection, translation, and text-to-speech conversion. Additionally, it provides resources for Vietnamese NLP datasets and upcoming features include Automatic Speech Recognition.
lite_llama
lite_llama is a llama model inference lite framework by triton. It offers accelerated inference for llama3, Qwen2.5, and Llava1.5 models with up to 4x speedup compared to transformers. The framework supports top-p sampling, stream output, GQA, and cuda graph optimizations. It also provides efficient dynamic management for kv cache, operator fusion, and custom operators like rmsnorm, rope, softmax, and element-wise multiplication using triton kernels.
duckduckgo_search
Duckduckgo_search is a Python library that enables AI chat and search functionalities for text, news, images, and videos using the DuckDuckGo.com search engine. It provides various methods for different search types such as text, images, videos, and news. The library also supports search operators, regions, proxy settings, and exception handling. Users can interact with the DuckDuckGo API to retrieve search results based on specific queries and parameters.
AIDailyNews
AIDailyNews is a tool that allows users to deploy their personalized daily news overview using GPT3 and Gemini Pro models. It collects content from RSS feeds every morning at 9 am, analyzes and summarizes it using GPT, and generates a daily report. Users can customize the RSS feeds they want to subscribe to and configure data collection environment variables for Github Action scheduled tasks. The tool supports AI services like GLM, OpenAI, and Google Gemini, allowing users to choose the AI provider, GPT model name, API key, and base URL. It also provides instructions for deploying the tool on Vercel for daily content summaries.
wechat-bot
WeChat Bot is a simple and easy-to-use WeChat robot based on chatgpt and wechaty. It can help you automatically reply to WeChat messages or manage WeChat groups/friends. The tool requires configuration of AI services such as Xunfei, Kimi, or ChatGPT. Users can customize the tool to automatically reply to group or private chat messages based on predefined conditions. The tool supports running in Docker for easy deployment and provides a convenient way to interact with various AI services for WeChat automation.
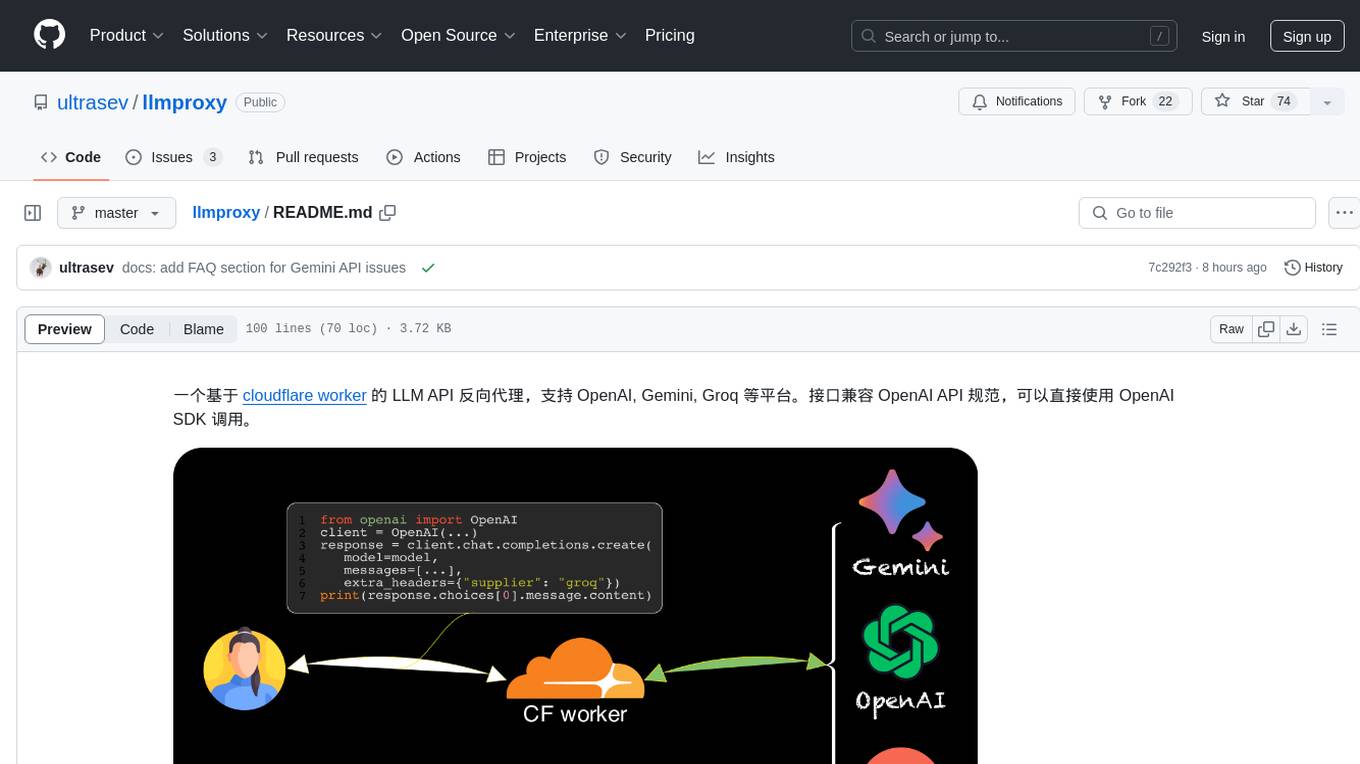
llmproxy
llmproxy is a reverse proxy for LLM API based on Cloudflare Worker, supporting platforms like OpenAI, Gemini, and Groq. The interface is compatible with the OpenAI API specification and can be directly accessed using the OpenAI SDK. It provides a convenient way to interact with various AI platforms through a unified API endpoint, enabling seamless integration and usage in different applications.
botgroup.chat
botgroup.chat is a multi-person AI chat application based on React and Cloudflare Pages for free one-click deployment. It supports multiple AI roles participating in conversations simultaneously, providing an interactive experience similar to group chat. The application features real-time streaming responses, customizable AI roles and personalities, group management functionality, AI role mute function, Markdown format support, mathematical formula display with KaTeX, aesthetically pleasing UI design, and responsive design for mobile devices.

ai-no-jimaku-gumi
AI no jimaku gumi is a command-line utility designed to assist in video translation. It supports translating subtitles using AI models and provides options for different translation and subtitle sources. Users can easily set up the tool by following the installation steps and use it to translate videos to different languages with customizable settings. The tool currently supports DeepL and llm translation backends and SRT subtitle export. It aims to simplify the process of adding subtitles to videos by leveraging AI technology.
HiveChat
HiveChat is an AI chat application designed for small and medium teams. It supports various models such as DeepSeek, Open AI, Claude, and Gemini. The tool allows easy configuration by one administrator for the entire team to use different AI models. It supports features like email or Feishu login, LaTeX and Markdown rendering, DeepSeek mind map display, image understanding, AI agents, cloud data storage, and integration with multiple large model service providers. Users can engage in conversations by logging in, while administrators can configure AI service providers, manage users, and control account registration. The technology stack includes Next.js, Tailwindcss, Auth.js, PostgreSQL, Drizzle ORM, and Ant Design.
sdk
Varg is an AI video generation SDK that extends Vercel's AI SDK with capabilities for video, music, and lipsync. It allows users to generate images, videos, music, and more using familiar patterns and declarative JSX syntax. The SDK supports various models for image and video generation, speech synthesis, music generation, and background removal. Users can create reusable elements for character consistency, handle files from disk, URL, or buffer, and utilize layout helpers, transitions, and caption styles. Varg also offers a visual editor for video workflows with a code editor and node-based interface.
For similar tasks
basdonax-ai-rag
Basdonax AI RAG v1.0 is a repository that contains all the necessary resources to create your own AI-powered secretary using the RAG from Basdonax AI. It leverages open-source models from Meta and Microsoft, namely 'Llama3-7b' and 'Phi3-4b', allowing users to upload documents and make queries. This tool aims to simplify life for individuals by harnessing the power of AI. The installation process involves choosing between different data models based on GPU capabilities, setting up Docker, pulling the desired model, and customizing the assistant prompt file. Once installed, users can access the RAG through a local link and enjoy its functionalities.

TableLLM
TableLLM is a large language model designed for efficient tabular data manipulation tasks in real office scenarios. It can generate code solutions or direct text answers for tasks like insert, delete, update, query, merge, and chart operations on tables embedded in spreadsheets or documents. The model has been fine-tuned based on CodeLlama-7B and 13B, offering two scales: TableLLM-7B and TableLLM-13B. Evaluation results show its performance on benchmarks like WikiSQL, Spider, and self-created table operation benchmark. Users can use TableLLM for code and text generation tasks on tabular data.
awesome-agents
Awesome Agents is a curated list of open source AI agents designed for various tasks such as private interactions with documents, chat implementations, autonomous research, human-behavior simulation, code generation, HR queries, domain-specific research, and more. The agents leverage Large Language Models (LLMs) and other generative AI technologies to provide solutions for complex tasks and projects. The repository includes a diverse range of agents for different use cases, from conversational chatbots to AI coding engines, and from autonomous HR assistants to vision task solvers.
Lumi-AI
Lumi AI is a friendly AI sidekick with a human-like personality that offers features like file upload and analysis, web search, local chat storage, custom instructions, changeable conversational style, enhanced context retention, voice query input, and various tools. The project has been developed with contributions from a team of developers, designers, and testers, and is licensed under Apache 2.0 and MIT licenses.
awesome-rag
Awesome RAG is a curated list of retrieval-augmented generation (RAG) in large language models. It includes papers, surveys, general resources, lectures, talks, tutorials, workshops, tools, and other collections related to retrieval-augmented generation. The repository aims to provide a comprehensive overview of the latest advancements, techniques, and applications in the field of RAG.

ai2-scholarqa-lib
Ai2 Scholar QA is a system for answering scientific queries and literature review by gathering evidence from multiple documents across a corpus and synthesizing an organized report with evidence for each claim. It consists of a retrieval component and a three-step generator pipeline. The retrieval component fetches relevant evidence passages using the Semantic Scholar public API and reranks them. The generator pipeline includes quote extraction, planning and clustering, and summary generation. The system is powered by the ScholarQA class, which includes components like PaperFinder and MultiStepQAPipeline. It requires environment variables for Semantic Scholar API and LLMs, and can be run as local docker containers or embedded into another application as a Python package.
baibot
Baibot is a versatile chatbot framework designed to simplify the process of creating and deploying chatbots. It provides a user-friendly interface for building custom chatbots with various functionalities such as natural language processing, conversation flow management, and integration with external APIs. Baibot is highly customizable and can be easily extended to suit different use cases and industries. With Baibot, developers can quickly create intelligent chatbots that can interact with users in a seamless and engaging manner, enhancing user experience and automating customer support processes.
openclaw
OpenClaw is a personal AI assistant that runs on your own devices, answering you on various channels like WhatsApp, Telegram, Slack, Discord, and more. It can speak and listen on different platforms and render a live Canvas you control. The Gateway serves as the control plane, while the assistant is the main product. It provides a local, fast, and always-on single-user assistant experience. The preferred setup involves running the onboarding wizard in your terminal to guide you through setting up the gateway, workspace, channels, and skills. The tool supports various models and authentication methods, with a focus on security and privacy.
For similar jobs
redbox-copilot
Redbox Copilot is a retrieval augmented generation (RAG) app that uses GenAI to chat with and summarise civil service documents. It increases organisational memory by indexing documents and can summarise reports read months ago, supplement them with current work, and produce a first draft that lets civil servants focus on what they do best. The project uses a microservice architecture with each microservice running in its own container defined by a Dockerfile. Dependencies are managed using Python Poetry. Contributions are welcome, and the project is licensed under the MIT License.
concierge
Concierge is a versatile automation tool designed to streamline repetitive tasks and workflows. It provides a user-friendly interface for creating custom automation scripts without the need for extensive coding knowledge. With Concierge, users can automate various tasks across different platforms and applications, increasing efficiency and productivity. The tool offers a wide range of pre-built automation templates and allows users to customize and schedule their automation processes. Concierge is suitable for individuals and businesses looking to automate routine tasks and improve overall workflow efficiency.
basdonax-ai-rag
Basdonax AI RAG v1.0 is a repository that contains all the necessary resources to create your own AI-powered secretary using the RAG from Basdonax AI. It leverages open-source models from Meta and Microsoft, namely 'Llama3-7b' and 'Phi3-4b', allowing users to upload documents and make queries. This tool aims to simplify life for individuals by harnessing the power of AI. The installation process involves choosing between different data models based on GPU capabilities, setting up Docker, pulling the desired model, and customizing the assistant prompt file. Once installed, users can access the RAG through a local link and enjoy its functionalities.
PerforatedAI
PerforatedAI is a machine learning tool designed to automate the process of analyzing and extracting information from perforated documents. It uses advanced OCR technology to accurately identify and extract data from documents with perforations, such as surveys, questionnaires, and forms. The tool can handle various types of perforations and is capable of processing large volumes of documents quickly and efficiently. PerforatedAI streamlines the data extraction process, saving time and reducing errors associated with manual data entry. It is a valuable tool for businesses and organizations that deal with large amounts of perforated documents on a regular basis.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.
superflows
Superflows is an open-source alternative to OpenAI's Assistant API. It allows developers to easily add an AI assistant to their software products, enabling users to ask questions in natural language and receive answers or have tasks completed by making API calls. Superflows can analyze data, create plots, answer questions based on static knowledge, and even write code. It features a developer dashboard for configuration and testing, stateful streaming API, UI components, and support for multiple LLMs. Superflows can be set up in the cloud or self-hosted, and it provides comprehensive documentation and support.

py-gpt
Py-GPT is a Python library that provides an easy-to-use interface for OpenAI's GPT-3 API. It allows users to interact with the powerful GPT-3 model for various natural language processing tasks. With Py-GPT, developers can quickly integrate GPT-3 capabilities into their applications, enabling them to generate text, answer questions, and more with just a few lines of code.
openssa
OpenSSA is an open-source framework for creating efficient, domain-specific AI agents. It enables the development of Small Specialist Agents (SSAs) that solve complex problems in specific domains. SSAs tackle multi-step problems that require planning and reasoning beyond traditional language models. They apply OODA for deliberative reasoning (OODAR) and iterative, hierarchical task planning (HTP). This "System-2 Intelligence" breaks down complex tasks into manageable steps. SSAs make informed decisions based on domain-specific knowledge. With OpenSSA, users can create agents that process, generate, and reason about information, making them more effective and efficient in solving real-world challenges.