
llm-gemini
LLM plugin to access Google's Gemini family of models
Stars: 213
llm-gemini is a plugin that provides API access to Google's Gemini models. It allows users to configure and run various Gemini models for tasks such as generating text, processing images, transcribing audio, and executing code. The plugin supports multi-modal inputs including images, audio, and video, and can output JSON objects. Additionally, it enables chat interactions with the model and supports different embedding models for text processing. Users can also run similarity searches on embedded data. The plugin is designed to work in conjunction with LLM and offers extensive documentation for development and usage.
README:


![]()
API access to Google's Gemini models
Install this plugin in the same environment as LLM.
llm install llm-geminiConfigure the model by setting a key called "gemini" to your API key:
llm keys set gemini<paste key here>
You can also set the API key by assigning it to the environment variable LLM_GEMINI_KEY.
Now run the model using -m gemini-1.5-pro-latest, for example:
llm -m gemini-1.5-pro-latest "A joke about a pelican and a walrus"A pelican walks into a seafood restaurant with a huge fish hanging out of its beak. The walrus, sitting at the bar, eyes it enviously.
"Hey," the walrus says, "That looks delicious! What kind of fish is that?"
The pelican taps its beak thoughtfully. "I believe," it says, "it's a billfish."
Other models are:
gemini-1.5-flash-latest-
gemini-1.5-flash-8b-latest- the least expensive -
gemini-exp-1114- recent experimental #1 -
gemini-exp-1121- recent experimental #2 -
gemini-exp-1206- recent experimental #3 -
gemini-2.0-flash-exp- Gemini 2.0 Flash -
learnlm-1.5-pro-experimental- "an experimental task-specific model that has been trained to align with learning science principles" - more details here. -
gemini-2.0-flash-thinking-exp-1219- experimental "thinking" model from December 2024 -
gemini-2.0-flash-thinking-exp-01-21- experimental "thinking" model from January 2025 -
gemini-2.0-flash- Gemini 2.0 Flash -
gemini-2.0-flash-lite- Gemini 2.0 Flash-Lite -
gemini-2.0-pro-exp-02-05- experimental release of Gemini 2.0 Pro -
gemma-3-27b-it- Gemma 3 27B
Gemini models are multi-modal. You can provide images, audio or video files as input like this:
llm -m gemini-1.5-flash-latest 'extract text' -a image.jpgOr with a URL:
llm -m gemini-1.5-flash-8b-latest 'describe image' \
-a https://static.simonwillison.net/static/2024/pelicans.jpgAudio works too:
llm -m gemini-1.5-pro-latest 'transcribe audio' -a audio.mp3And video:
llm -m gemini-1.5-pro-latest 'describe what happens' -a video.mp4The Gemini prompting guide includes extensive advice on multi-modal prompting.
Use -o json_object 1 to force the output to be JSON:
llm -m gemini-1.5-flash-latest -o json_object 1 \
'3 largest cities in California, list of {"name": "..."}'Outputs:
{"cities": [{"name": "Los Angeles"}, {"name": "San Diego"}, {"name": "San Jose"}]}Gemini models can write and execute code - they can decide to write Python code, execute it in a secure sandbox and use the result as part of their response.
To enable this feature, use -o code_execution 1:
llm -m gemini-1.5-pro-latest -o code_execution 1 \
'use python to calculate (factorial of 13) * 3'Some Gemini models support Grounding with Google Search, where the model can run a Google search and use the results as part of answering a prompt.
Using this feature may incur additional requirements in terms of how you use the results. Consult Google's documentation for more details.
To run a prompt with Google search enabled, use -o google_search 1:
llm -m gemini-1.5-pro-latest -o google_search 1 \
'What happened in Ireland today?'Use llm logs -c --json after running a prompt to see the full JSON response, which includes additional information about grounded results.
To chat interactively with the model, run llm chat:
llm chat -m gemini-1.5-pro-latestThe plugin also adds support for the gemini-embedding-exp-03-07 and text-embedding-004 embedding models.
Run that against a single string like this:
llm embed -m text-embedding-004 -c 'hello world'This returns a JSON array of 768 numbers.
The gemini-embedding-exp-03-07 model is larger, returning 3072 numbers. You can also use variants of it that are truncated down to smaller sizes:
-
gemini-embedding-exp-03-07- 3072 numbers -
gemini-embedding-exp-03-07-2048- 2048 numbers -
gemini-embedding-exp-03-07-1024- 1024 numbers -
gemini-embedding-exp-03-07-512- 512 numbers -
gemini-embedding-exp-03-07-256- 256 numbers -
gemini-embedding-exp-03-07-128- 128 numbers
This command will embed every README.md file in child directories of the current directory and store the results in a SQLite database called embed.db in a collection called readmes:
llm embed-multi readmes -d embed.db -m gemini-embedding-exp-03-07-128 \
--files . '*/README.md'You can then run similarity searches against that collection like this:
llm similar readmes -c 'upload csvs to stuff' -d embed.dbSee the LLM embeddings documentation for further details.
To set up this plugin locally, first checkout the code. Then create a new virtual environment:
cd llm-gemini
python3 -m venv venv
source venv/bin/activateNow install the dependencies and test dependencies:
llm install -e '.[test]'To run the tests:
pytestThis project uses pytest-recording to record Gemini API responses for the tests.
If you add a new test that calls the API you can capture the API response like this:
PYTEST_GEMINI_API_KEY="$(llm keys get gemini)" pytest --record-mode onceYou will need to have stored a valid Gemini API key using this command first:
llm keys set gemini
# Paste key hereFor Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llm-gemini
Similar Open Source Tools
llm-gemini
llm-gemini is a plugin that provides API access to Google's Gemini models. It allows users to configure and run various Gemini models for tasks such as generating text, processing images, transcribing audio, and executing code. The plugin supports multi-modal inputs including images, audio, and video, and can output JSON objects. Additionally, it enables chat interactions with the model and supports different embedding models for text processing. Users can also run similarity searches on embedded data. The plugin is designed to work in conjunction with LLM and offers extensive documentation for development and usage.
yoyak
Yoyak is a small CLI tool powered by LLM for summarizing and translating web pages. It provides shell completion scripts for bash, fish, and zsh. Users can set the model they want to use and summarize web pages with the 'yoyak summary' command. Additionally, translation to other languages is supported using the '-l' option with ISO 639-1 language codes. Yoyak supports various models for summarization and translation tasks.
org-ai
org-ai is a minor mode for Emacs org-mode that provides access to generative AI models, including OpenAI API (ChatGPT, DALL-E, other text models) and Stable Diffusion. Users can use ChatGPT to generate text, have speech input and output interactions with AI, generate images and image variations using Stable Diffusion or DALL-E, and use various commands outside org-mode for prompting using selected text or multiple files. The tool supports syntax highlighting in AI blocks, auto-fill paragraphs on insertion, and offers block options for ChatGPT, DALL-E, and other text models. Users can also generate image variations, use global commands, and benefit from Noweb support for named source blocks.
shell-pilot
Shell-pilot is a simple, lightweight shell script designed to interact with various AI models such as OpenAI, Ollama, Mistral AI, LocalAI, ZhipuAI, Anthropic, Moonshot, and Novita AI from the terminal. It enhances intelligent system management without any dependencies, offering features like setting up a local LLM repository, using official models and APIs, viewing history and session persistence, passing input prompts with pipe/redirector, listing available models, setting request parameters, generating and running commands in the terminal, easy configuration setup, system package version checking, and managing system aliases.

llama.vim
llama.vim is a plugin that provides local LLM-assisted text completion for Vim users. It offers features such as auto-suggest on cursor movement, manual suggestion toggling, suggestion acceptance with Tab and Shift+Tab, control over text generation time, context configuration, ring context with chunks from open and edited files, and performance stats display. The plugin requires a llama.cpp server instance to be running and supports FIM-compatible models. It aims to be simple, lightweight, and provide high-quality and performant local FIM completions even on consumer-grade hardware.

llm-vscode
llm-vscode is an extension designed for all things LLM, utilizing llm-ls as its backend. It offers features such as code completion with 'ghost-text' suggestions, the ability to choose models for code generation via HTTP requests, ensuring prompt size fits within the context window, and code attribution checks. Users can configure the backend, suggestion behavior, keybindings, llm-ls settings, and tokenization options. Additionally, the extension supports testing models like Code Llama 13B, Phind/Phind-CodeLlama-34B-v2, and WizardLM/WizardCoder-Python-34B-V1.0. Development involves cloning llm-ls, building it, and setting up the llm-vscode extension for use.
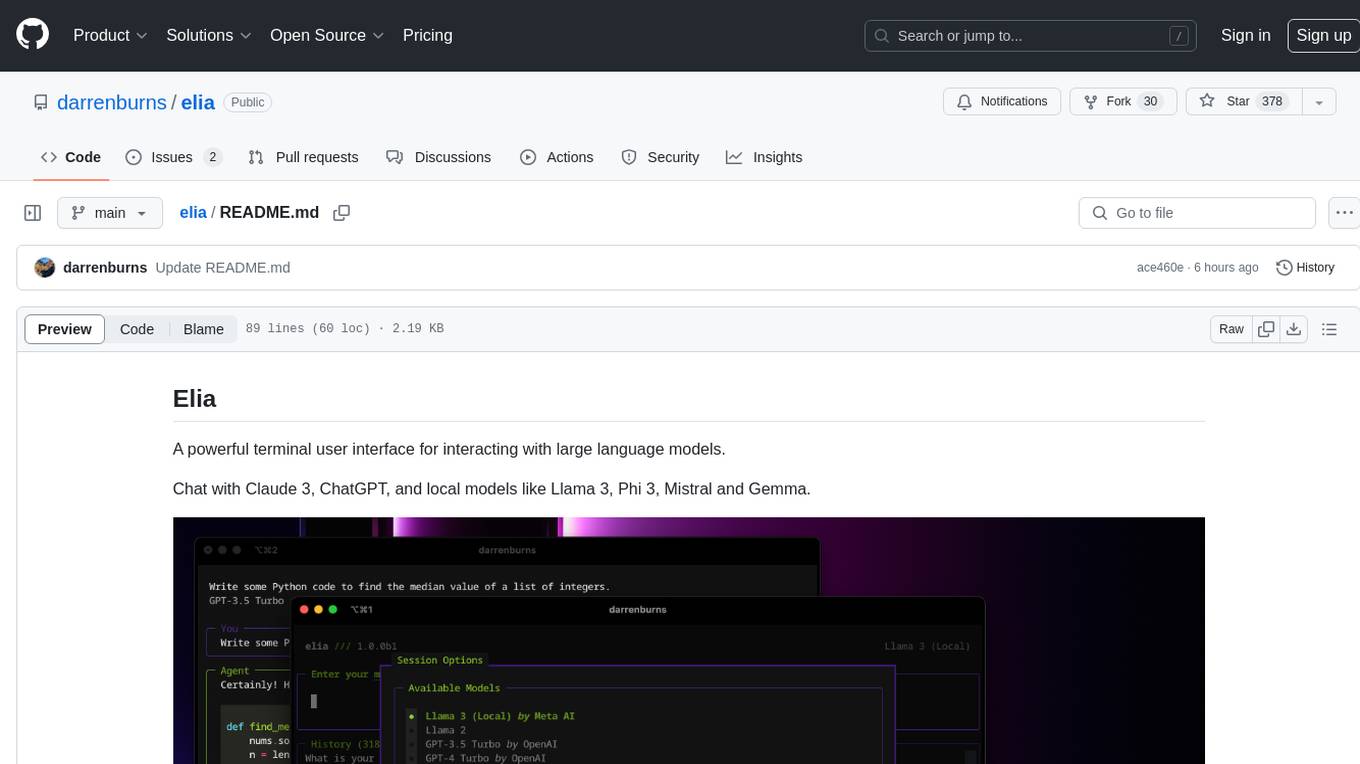
elia
Elia is a powerful terminal user interface designed for interacting with large language models. It allows users to chat with models like Claude 3, ChatGPT, Llama 3, Phi 3, Mistral, and Gemma. Conversations are stored locally in a SQLite database, ensuring privacy. Users can run local models through 'ollama' without data leaving their machine. Elia offers easy installation with pipx and supports various environment variables for different models. It provides a quick start to launch chats and manage local models. Configuration options are available to customize default models, system prompts, and add new models. Users can import conversations from ChatGPT and wipe the database when needed. Elia aims to enhance user experience in interacting with language models through a user-friendly interface.

chatgpt-cli
ChatGPT CLI provides a powerful command-line interface for seamless interaction with ChatGPT models via OpenAI and Azure. It features streaming capabilities, extensive configuration options, and supports various modes like streaming, query, and interactive mode. Users can manage thread-based context, sliding window history, and provide custom context from any source. The CLI also offers model and thread listing, advanced configuration options, and supports GPT-4, GPT-3.5-turbo, and Perplexity's models. Installation is available via Homebrew or direct download, and users can configure settings through default values, a config.yaml file, or environment variables.
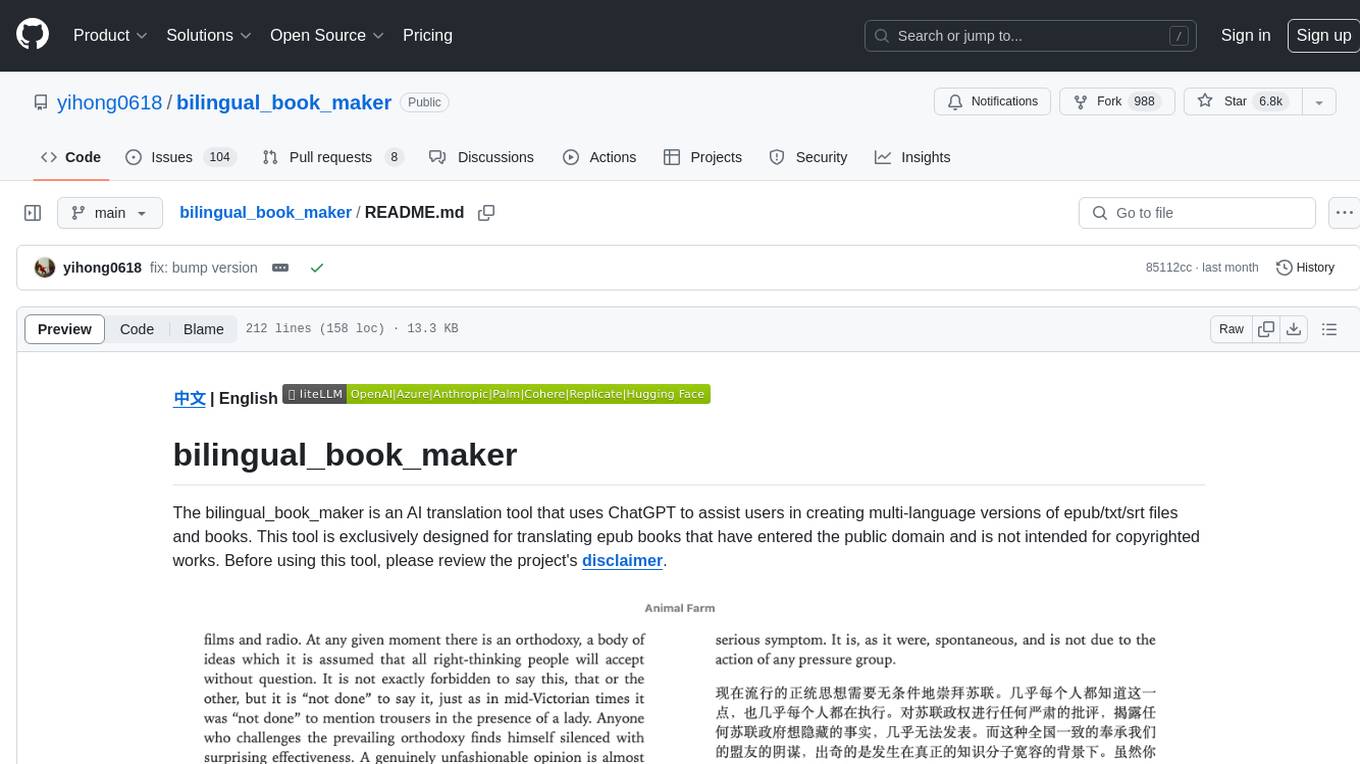
bilingual_book_maker
The bilingual_book_maker is an AI translation tool that uses ChatGPT to assist users in creating multi-language versions of epub/txt/srt files and books. It supports various models like gpt-4, gpt-3.5-turbo, claude-2, palm, llama-2, azure-openai, command-nightly, and gemini. Users need ChatGPT or OpenAI token, epub/txt books, internet access, and Python 3.8+. The tool provides options to specify OpenAI API key, model selection, target language, proxy server, context addition, translation style, and more. It generates bilingual books in epub format after translation. Users can test translations, set batch size, tweak prompts, and use different models like DeepL, Google Gemini, Tencent TranSmart, and more. The tool also supports retranslation, translating specific tags, and e-reader type specification. Docker usage is available for easy setup.
screen-pipe
Screen-pipe is a Rust + WASM tool that allows users to turn their screen into actions using Large Language Models (LLMs). It enables users to record their screen 24/7, extract text from frames, and process text and images for tasks like analyzing sales conversations. The tool is still experimental and aims to simplify the process of recording screens, extracting text, and integrating with various APIs for tasks such as filling CRM data based on screen activities. The project is open-source and welcomes contributions to enhance its functionalities and usability.
aidermacs
Aidermacs is an AI pair programming tool for Emacs that integrates Aider, a powerful open-source AI pair programming tool. It provides top performance on the SWE Bench, support for multi-file edits, real-time file synchronization, and broad language support. Aidermacs delivers an Emacs-centric experience with features like intelligent model selection, flexible terminal backend support, smarter syntax highlighting, enhanced file management, and streamlined transient menus. It thrives on community involvement, encouraging contributions, issue reporting, idea sharing, and documentation improvement.

agenticSeek
AgenticSeek is a voice-enabled AI assistant powered by DeepSeek R1 agents, offering a fully local alternative to cloud-based AI services. It allows users to interact with their filesystem, code in multiple languages, and perform various tasks autonomously. The tool is equipped with memory to remember user preferences and past conversations, and it can divide tasks among multiple agents for efficient execution. AgenticSeek prioritizes privacy by running entirely on the user's hardware without sending data to the cloud.

nano-graphrag
nano-GraphRAG is a simple, easy-to-hack implementation of GraphRAG that provides a smaller, faster, and cleaner version of the official implementation. It is about 800 lines of code, small yet scalable, asynchronous, and fully typed. The tool supports incremental insert, async methods, and various parameters for customization. Users can replace storage components and LLM functions as needed. It also allows for embedding function replacement and comes with pre-defined prompts for entity extraction and community reports. However, some features like covariates and global search implementation differ from the original GraphRAG. Future versions aim to address issues related to data source ID, community description truncation, and add new components.
tiledesk-dashboard
Tiledesk is an open-source live chat platform with integrated chatbots written in Node.js and Express. It is designed to be a multi-channel platform for web, Android, and iOS, and it can be used to increase sales or provide post-sales customer service. Tiledesk's chatbot technology allows for automation of conversations, and it also provides APIs and webhooks for connecting external applications. Additionally, it offers a marketplace for apps and features such as CRM, ticketing, and data export.

python-tgpt
Python-tgpt is a Python package that enables seamless interaction with over 45 free LLM providers without requiring an API key. It also provides image generation capabilities. The name _python-tgpt_ draws inspiration from its parent project tgpt, which operates on Golang. Through this Python adaptation, users can effortlessly engage with a number of free LLMs available, fostering a smoother AI interaction experience.

chat-ui
A chat interface using open source models, eg OpenAssistant or Llama. It is a SvelteKit app and it powers the HuggingChat app on hf.co/chat.
For similar tasks
llm-gemini
llm-gemini is a plugin that provides API access to Google's Gemini models. It allows users to configure and run various Gemini models for tasks such as generating text, processing images, transcribing audio, and executing code. The plugin supports multi-modal inputs including images, audio, and video, and can output JSON objects. Additionally, it enables chat interactions with the model and supports different embedding models for text processing. Users can also run similarity searches on embedded data. The plugin is designed to work in conjunction with LLM and offers extensive documentation for development and usage.

agentscope
AgentScope is a multi-agent platform designed to empower developers to build multi-agent applications with large-scale models. It features three high-level capabilities: Easy-to-Use, High Robustness, and Actor-Based Distribution. AgentScope provides a list of `ModelWrapper` to support both local model services and third-party model APIs, including OpenAI API, DashScope API, Gemini API, and ollama. It also enables developers to rapidly deploy local model services using libraries such as ollama (CPU inference), Flask + Transformers, Flask + ModelScope, FastChat, and vllm. AgentScope supports various services, including Web Search, Data Query, Retrieval, Code Execution, File Operation, and Text Processing. Example applications include Conversation, Game, and Distribution. AgentScope is released under Apache License 2.0 and welcomes contributions.
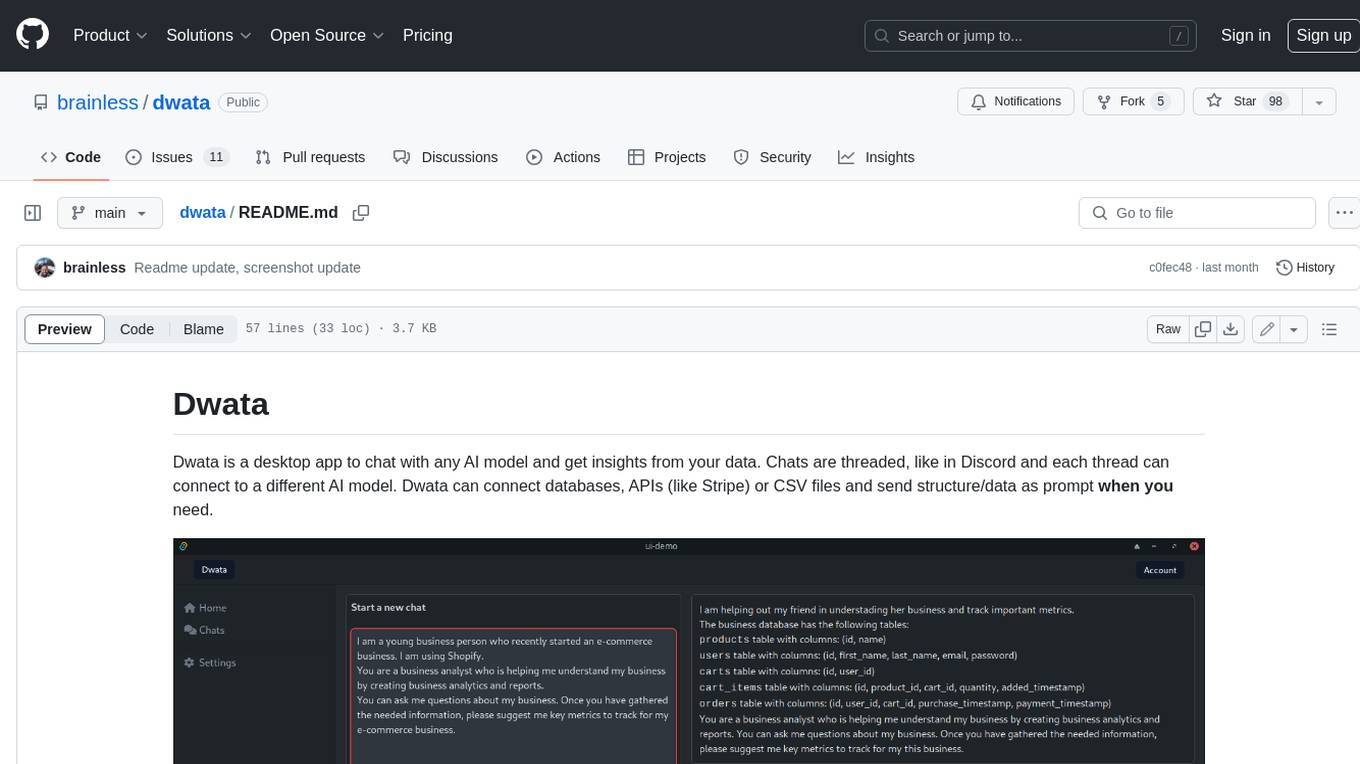
dwata
Dwata is a desktop application that allows users to chat with any AI model and gain insights from their data. Chats are organized into threads, similar to Discord, with each thread connecting to a different AI model. Dwata can connect to databases, APIs (such as Stripe), or CSV files and send structured data as prompts when needed. The AI's response will often include SQL or Python code, which can be used to extract the desired insights. Dwata can validate AI-generated SQL to ensure that the tables and columns referenced are correct and can execute queries against the database from within the application. Python code (typically using Pandas) can also be executed from within Dwata, although this feature is still in development. Dwata supports a range of AI models, including OpenAI's GPT-4, GPT-4 Turbo, and GPT-3.5 Turbo; Groq's LLaMA2-70b and Mixtral-8x7b; Phind's Phind-34B and Phind-70B; Anthropic's Claude; and Ollama's Llama 2, Mistral, and Phi-2 Gemma. Dwata can compare chats from different models, allowing users to see the responses of multiple models to the same prompts. Dwata can connect to various data sources, including databases (PostgreSQL, MySQL, MongoDB), SaaS products (Stripe, Shopify), CSV files/folders, and email (IMAP). The desktop application does not collect any private or business data without the user's explicit consent.
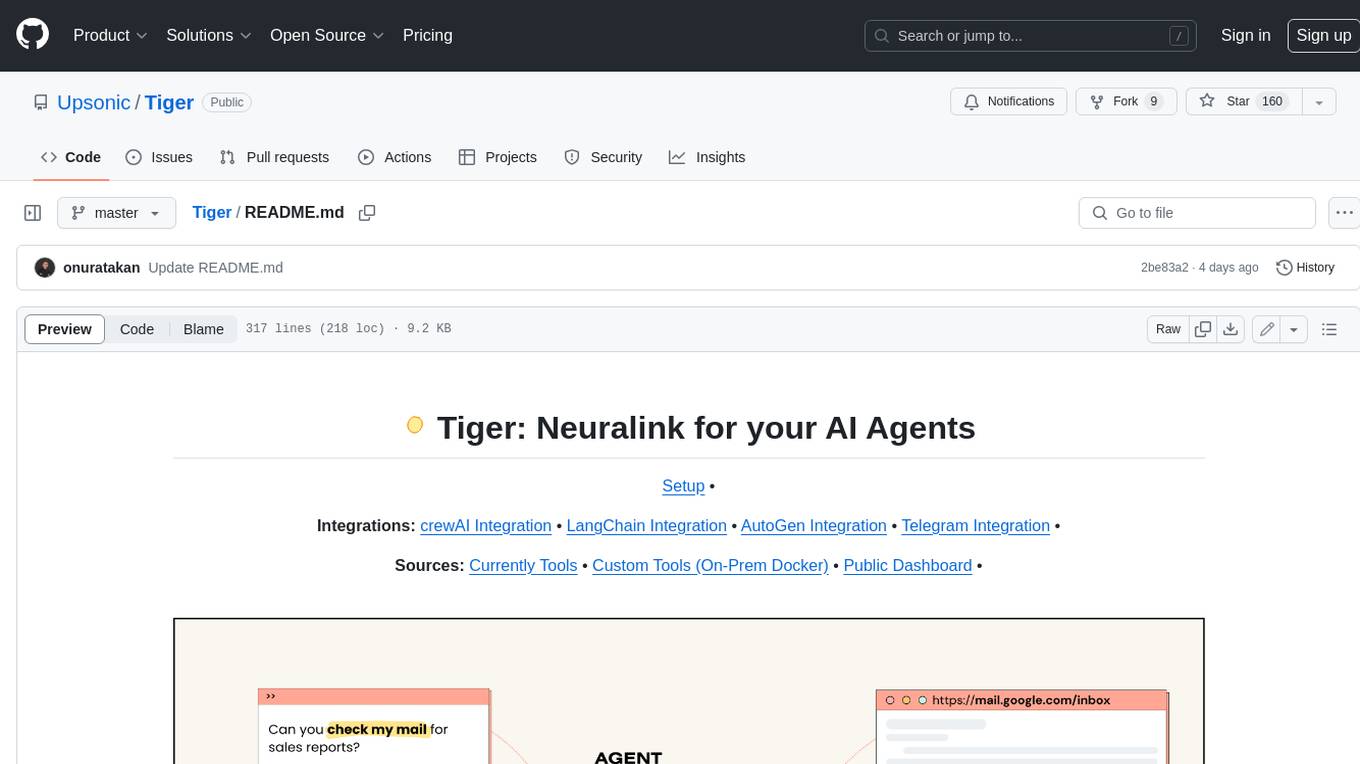
Tiger
Tiger is a community-driven project developing a reusable and integrated tool ecosystem for LLM Agent Revolution. It utilizes Upsonic for isolated tool storage, profiling, and automatic document generation. With Tiger, you can create a customized environment for your agents or leverage the robust and publicly maintained Tiger curated by the community itself.
SWE-agent
SWE-agent is a tool that turns language models (e.g. GPT-4) into software engineering agents capable of fixing bugs and issues in real GitHub repositories. It achieves state-of-the-art performance on the full test set by resolving 12.29% of issues. The tool is built and maintained by researchers from Princeton University. SWE-agent provides a command line tool and a graphical web interface for developers to interact with. It introduces an Agent-Computer Interface (ACI) to facilitate browsing, viewing, editing, and executing code files within repositories. The tool includes features such as a linter for syntax checking, a specialized file viewer, and a full-directory string searching command to enhance the agent's capabilities. SWE-agent aims to improve prompt engineering and ACI design to enhance the performance of language models in software engineering tasks.
NeoGPT
NeoGPT is an AI assistant that transforms your local workspace into a powerhouse of productivity from your CLI. With features like code interpretation, multi-RAG support, vision models, and LLM integration, NeoGPT redefines how you work and create. It supports executing code seamlessly, multiple RAG techniques, vision models, and interacting with various language models. Users can run the CLI to start using NeoGPT and access features like Code Interpreter, building vector database, running Streamlit UI, and changing LLM models. The tool also offers magic commands for chat sessions, such as resetting chat history, saving conversations, exporting settings, and more. Join the NeoGPT community to experience a new era of efficiency and contribute to its evolution.
Phi-3-Vision-MLX
Phi-3-MLX is a versatile AI framework that leverages both the Phi-3-Vision multimodal model and the Phi-3-Mini-128K language model optimized for Apple Silicon using the MLX framework. It provides an easy-to-use interface for a wide range of AI tasks, from advanced text generation to visual question answering and code execution. The project features support for batched generation, flexible agent system, custom toolchains, model quantization, LoRA fine-tuning capabilities, and API integration for extended functionality.
llm-sandbox
LLM Sandbox is a lightweight and portable sandbox environment designed to securely execute large language model (LLM) generated code in a safe and isolated manner using Docker containers. It provides an easy-to-use interface for setting up, managing, and executing code in a controlled Docker environment, simplifying the process of running code generated by LLMs. The tool supports multiple programming languages, offers flexibility with predefined Docker images or custom Dockerfiles, and allows scalability with support for Kubernetes and remote Docker hosts.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.