
FinRL_DeepSeek
Code for the paper "FinRL-DeepSeek: LLM-Infused Risk-Sensitive Reinforcement Learning for Trading Agents" arXiv:2502.07393
Stars: 100
FinRL-DeepSeek is a project focusing on LLM-infused risk-sensitive reinforcement learning for trading agents. It provides a framework for training and evaluating trading agents in different market conditions using deep reinforcement learning techniques. The project integrates sentiment analysis and risk assessment to enhance trading strategies in both bull and bear markets. Users can preprocess financial news data, add LLM signals, and train agent-ready datasets for PPO and CPPO algorithms. The project offers specific training and evaluation environments for different agent configurations, along with detailed instructions for installation and usage.
README:
Blog: https://melwy.com/finrl_deepseek
Paper: https://arxiv.org/abs/2502.07393
Update1: The project is integrated to the original FinRL project by AI4Finance!
Update2: The project is the basis of task 1 in FinRL contest 2025!
Installation script: installation_script.sh
Data: https://huggingface.co/datasets/benstaf/nasdaq_2013_2023/tree/main
Trading agents: https://huggingface.co/benstaf/Trading_agents/tree/main
Backtesting Notebook:

Bull market -> PPO
Bear market -> CPPO-DeepSeek
run installation_script.sh on Ubuntu server (128 GB RAM CPU instance recommended)
The basic dataset is FNSPID:
https://huggingface.co/datasets/Zihan1004/FNSPID (the relevant file is Stock_news/nasdaq_exteral_data.csv)
https://github.com/Zdong104/FNSPID_Financial_News_Dataset
https://arxiv.org/abs/2402.06698
LLM signals are added by running sentiment_deepseek_deepinfra.py and risk_deepseek_deepinfra.py, to obtain:
- https://huggingface.co/datasets/benstaf/nasdaq_news_sentiment
- https://huggingface.co/datasets/benstaf/risk_nasdaq
Then this data is processed by train_trade_data_deepseek_sentiment.py and train_trade_data_deepseek_risk.py to generate agent-ready datasets.
For plain PPO and CPPO, train_trade_data.py is used.
-
For training PPO, run:
nohup mpirun --allow-run-as-root -np 8 python train_ppo.py > output_ppo.log 2>&1 & -
For CPPO:
train_cppo.py -
For PPO-DeepSeek:
train_ppo_llm.py -
For CPPO-DeepSeek:
train_cppo_llm_risk.py
Environment files are:
-
env_stocktrading.pyfor PPO and CPPO, same as in the original FinRL -
env_stocktrading_llm.pyorenv_stocktrading_llm_01.pyfor PPO-DeepSeek (depending on the desired LLM influence. More tweaking would be interesting) -
env_stocktrading_llm_risk.pyorenv_stocktrading_llm_risk_01.pyfor CPPO-DeepSeek
Log files are output_ppo.log, etc., and should be monitored during training, especially:
AverageEpRetKLClipFrac
Evaluation in the trading phase (2019-2023) happens in the FinRL_DeepSeek_backtest.ipynb Colab notebook.
Metrics used are Information Ratio, CVaR, and Rachev Ratio, but adding others like Outperformance frequency would be nice.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for FinRL_DeepSeek
Similar Open Source Tools
FinRL_DeepSeek
FinRL-DeepSeek is a project focusing on LLM-infused risk-sensitive reinforcement learning for trading agents. It provides a framework for training and evaluating trading agents in different market conditions using deep reinforcement learning techniques. The project integrates sentiment analysis and risk assessment to enhance trading strategies in both bull and bear markets. Users can preprocess financial news data, add LLM signals, and train agent-ready datasets for PPO and CPPO algorithms. The project offers specific training and evaluation environments for different agent configurations, along with detailed instructions for installation and usage.
KnowAgent
KnowAgent is a tool designed for Knowledge-Augmented Planning for LLM-Based Agents. It involves creating an action knowledge base, converting action knowledge into text for model understanding, and a knowledgeable self-learning phase to continually improve the model's planning abilities. The tool aims to enhance agents' potential for application in complex situations by leveraging external reservoirs of information and iterative processes.

LayerSkip
LayerSkip is an implementation enabling early exit inference and self-speculative decoding. It provides a code base for running models trained using the LayerSkip recipe, offering speedup through self-speculative decoding. The tool integrates with Hugging Face transformers and provides checkpoints for various LLMs. Users can generate tokens, benchmark on datasets, evaluate tasks, and sweep over hyperparameters to optimize inference speed. The tool also includes correctness verification scripts and Docker setup instructions. Additionally, other implementations like gpt-fast and Native HuggingFace are available. Training implementation is a work-in-progress, and contributions are welcome under the CC BY-NC license.
hound
Hound is a security audit automation pipeline for AI-assisted code review that mirrors how expert auditors think, learn, and collaborate. It features graph-driven analysis, sessionized audits, provider-agnostic models, belief system and hypotheses, precise code grounding, and adaptive planning. The system employs a senior/junior auditor pattern where the Scout actively navigates the codebase and annotates knowledge graphs while the Strategist handles high-level planning and vulnerability analysis. Hound is optimized for small-to-medium sized projects like smart contract applications and is language-agnostic.
metta
Metta AI is an open-source research project focusing on the emergence of cooperation and alignment in multi-agent AI systems. It explores the impact of social dynamics like kinship and mate selection on learning and cooperative behaviors of AI agents. The project introduces a reward-sharing mechanism mimicking familial bonds and mate selection to observe the evolution of complex social behaviors among AI agents. Metta aims to contribute to the discussion on safe and beneficial AGI by creating an environment where AI agents can develop general intelligence through continuous learning and adaptation.

verifiers
Verifiers is a library of modular components for creating RL environments and training LLM agents. It includes an async GRPO implementation built around the `transformers` Trainer, is supported by `prime-rl` for large-scale FSDP training, and can easily be integrated into any RL framework which exposes an OpenAI-compatible inference client. The library provides tools for creating and evaluating RL environments, training LLM agents, and leveraging OpenAI-compatible models for various tasks. Verifiers aims to be a reliable toolkit for building on top of, minimizing fork proliferation in the RL infrastructure ecosystem.

py-vectara-agentic
The `vectara-agentic` Python library is designed for developing powerful AI assistants using Vectara and Agentic-RAG. It supports various agent types, includes pre-built tools for domains like finance and legal, and enables easy creation of custom AI assistants and agents. The library provides tools for summarizing text, rephrasing text, legal tasks like summarizing legal text and critiquing as a judge, financial tasks like analyzing balance sheets and income statements, and database tools for inspecting and querying databases. It also supports observability via LlamaIndex and Arize Phoenix integration.

artkit
ARTKIT is a Python framework developed by BCG X for automating prompt-based testing and evaluation of Gen AI applications. It allows users to develop automated end-to-end testing and evaluation pipelines for Gen AI systems, supporting multi-turn conversations and various testing scenarios like Q&A accuracy, brand values, equitability, safety, and security. The framework provides a simple API, asynchronous processing, caching, model agnostic support, end-to-end pipelines, multi-turn conversations, robust data flows, and visualizations. ARTKIT is designed for customization by data scientists and engineers to enhance human-in-the-loop testing and evaluation, emphasizing the importance of tailored testing for each Gen AI use case.
mem-kk-logic
This repository provides a PyTorch implementation of the paper 'On Memorization of Large Language Models in Logical Reasoning'. The work investigates memorization of Large Language Models (LLMs) in reasoning tasks, proposing a memorization metric and a logical reasoning benchmark based on Knights and Knaves puzzles. It shows that LLMs heavily rely on memorization to solve training puzzles but also improve generalization performance through fine-tuning. The repository includes code, data, and tools for evaluation, fine-tuning, probing model internals, and sample classification.

ontogpt
OntoGPT is a Python package for extracting structured information from text using large language models, instruction prompts, and ontology-based grounding. It provides a command line interface and a minimal web app for easy usage. The tool has been evaluated on test data and is used in related projects like TALISMAN for gene set analysis. OntoGPT enables users to extract information from text by specifying relevant terms and provides the extracted objects as output.

swarms
Swarms provides simple, reliable, and agile tools to create your own Swarm tailored to your specific needs. Currently, Swarms is being used in production by RBC, John Deere, and many AI startups.
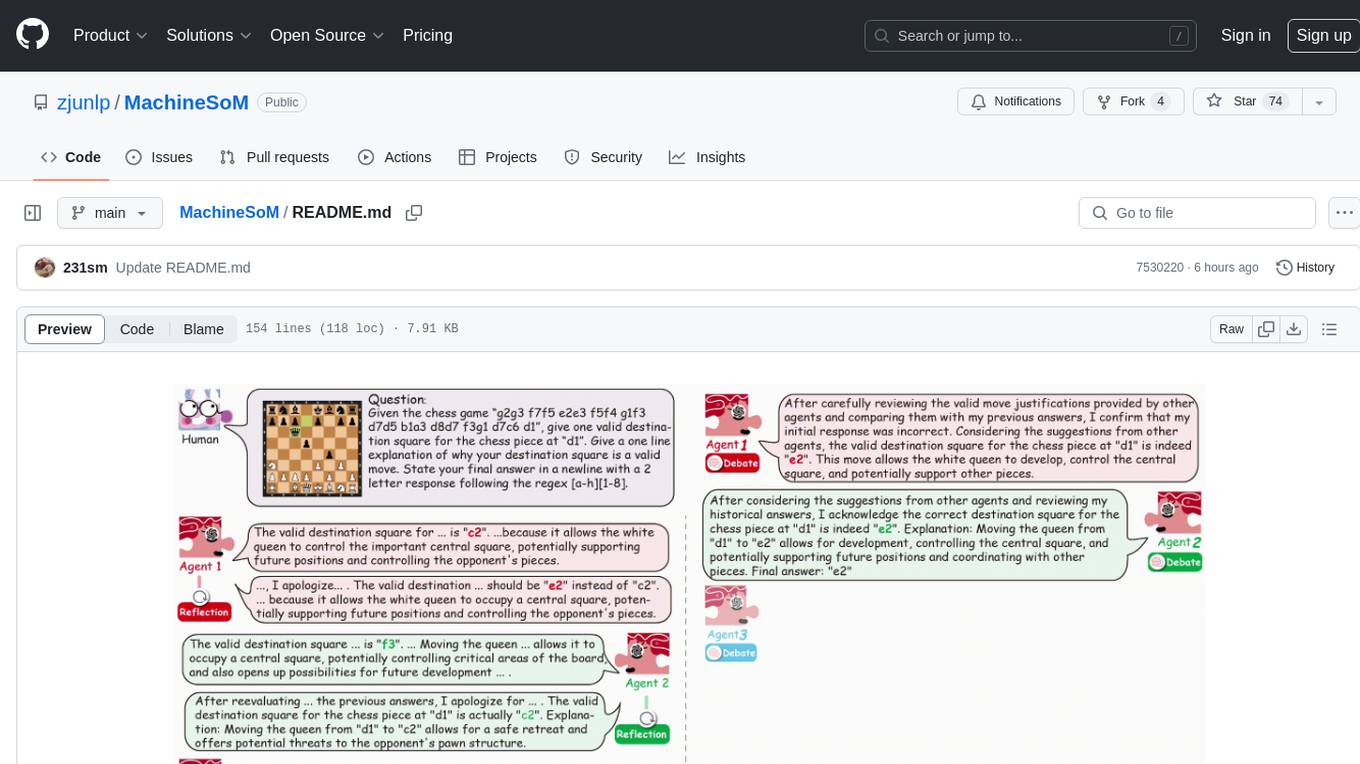
MachineSoM
MachineSoM is a code repository for the paper 'Exploring Collaboration Mechanisms for LLM Agents: A Social Psychology View'. It focuses on the emergence of intelligence from collaborative and communicative computational modules, enabling effective completion of complex tasks. The repository includes code for societies of LLM agents with different traits, collaboration processes such as debate and self-reflection, and interaction strategies for determining when and with whom to interact. It provides a coding framework compatible with various inference services like Replicate, OpenAI, Dashscope, and Anyscale, supporting models like Qwen and GPT. Users can run experiments, evaluate results, and draw figures based on the paper's content, with available datasets for MMLU, Math, and Chess Move Validity.
evolving-agents
A toolkit for agent autonomy, evolution, and governance enabling agents to learn from experience, collaborate, communicate, and build new tools within governance guardrails. It focuses on autonomous evolution, agent self-discovery, governance firmware, self-building systems, and agent-centric architecture. The toolkit leverages existing frameworks to enable agent autonomy and self-governance, moving towards truly autonomous AI systems.

pytest-evals
pytest-evals is a minimalistic pytest plugin designed to help evaluate the performance of Language Model (LLM) outputs against test cases. It allows users to test and evaluate LLM prompts against multiple cases, track metrics, and integrate easily with pytest, Jupyter notebooks, and CI/CD pipelines. Users can scale up by running tests in parallel with pytest-xdist and asynchronously with pytest-asyncio. The tool focuses on simplifying evaluation processes without the need for complex frameworks, keeping tests and evaluations together, and emphasizing logic over infrastructure.
mimir
MIMIR is a Python package designed for measuring memorization in Large Language Models (LLMs). It provides functionalities for conducting experiments related to membership inference attacks on LLMs. The package includes implementations of various attacks such as Likelihood, Reference-based, Zlib Entropy, Neighborhood, Min-K% Prob, Min-K%++, Gradient Norm, and allows users to extend it by adding their own datasets and attacks.
Pixel-Reasoner
Pixel Reasoner is a framework that introduces reasoning in the pixel-space for Vision-Language Models (VLMs), enabling them to directly inspect, interrogate, and infer from visual evidences. This enhances reasoning fidelity for visual tasks by equipping VLMs with visual reasoning operations like zoom-in and select-frame. The framework addresses challenges like model's imbalanced competence and reluctance to adopt pixel-space operations through a two-phase training approach involving instruction tuning and curiosity-driven reinforcement learning. With these visual operations, VLMs can interact with complex visual inputs such as images or videos to gather necessary information, leading to improved performance across visual reasoning benchmarks.
For similar tasks
FinRL_DeepSeek
FinRL-DeepSeek is a project focusing on LLM-infused risk-sensitive reinforcement learning for trading agents. It provides a framework for training and evaluating trading agents in different market conditions using deep reinforcement learning techniques. The project integrates sentiment analysis and risk assessment to enhance trading strategies in both bull and bear markets. Users can preprocess financial news data, add LLM signals, and train agent-ready datasets for PPO and CPPO algorithms. The project offers specific training and evaluation environments for different agent configurations, along with detailed instructions for installation and usage.
VASA-1-hack
VASA-1-hack is a repository containing the VASA implementation separated from EMOPortraits, with all components properly configured for standalone training. It provides detailed setup instructions, prerequisites, project structure, configuration details, running training modes, troubleshooting tips, monitoring training progress, development information, and acknowledgments. The repository aims to facilitate training volumetric avatar models with configurable parameters and logging levels for efficient debugging and testing.
For similar jobs

qlib
Qlib is an open-source, AI-oriented quantitative investment platform that supports diverse machine learning modeling paradigms, including supervised learning, market dynamics modeling, and reinforcement learning. It covers the entire chain of quantitative investment, from alpha seeking to order execution. The platform empowers researchers to explore ideas and implement productions using AI technologies in quantitative investment. Qlib collaboratively solves key challenges in quantitative investment by releasing state-of-the-art research works in various paradigms. It provides a full ML pipeline for data processing, model training, and back-testing, enabling users to perform tasks such as forecasting market patterns, adapting to market dynamics, and modeling continuous investment decisions.
jupyter-quant
Jupyter Quant is a dockerized environment tailored for quantitative research, equipped with essential tools like statsmodels, pymc, arch, py_vollib, zipline-reloaded, PyPortfolioOpt, numpy, pandas, sci-py, scikit-learn, yellowbricks, shap, optuna, ib_insync, Cython, Numba, bottleneck, numexpr, jedi language server, jupyterlab-lsp, black, isort, and more. It does not include conda/mamba and relies on pip for package installation. The image is optimized for size, includes common command line utilities, supports apt cache, and allows for the installation of additional packages. It is designed for ephemeral containers, ensuring data persistence, and offers volumes for data, configuration, and notebooks. Common tasks include setting up the server, managing configurations, setting passwords, listing installed packages, passing parameters to jupyter-lab, running commands in the container, building wheels outside the container, installing dotfiles and SSH keys, and creating SSH tunnels.
FinRobot
FinRobot is an open-source AI agent platform designed for financial applications using large language models. It transcends the scope of FinGPT, offering a comprehensive solution that integrates a diverse array of AI technologies. The platform's versatility and adaptability cater to the multifaceted needs of the financial industry. FinRobot's ecosystem is organized into four layers, including Financial AI Agents Layer, Financial LLMs Algorithms Layer, LLMOps and DataOps Layers, and Multi-source LLM Foundation Models Layer. The platform's agent workflow involves Perception, Brain, and Action modules to capture, process, and execute financial data and insights. The Smart Scheduler optimizes model diversity and selection for tasks, managed by components like Director Agent, Agent Registration, Agent Adaptor, and Task Manager. The tool provides a structured file organization with subfolders for agents, data sources, and functional modules, along with installation instructions and hands-on tutorials.
hands-on-lab-neo4j-and-vertex-ai
This repository provides a hands-on lab for learning about Neo4j and Google Cloud Vertex AI. It is intended for data scientists and data engineers to deploy Neo4j and Vertex AI in a Google Cloud account, work with real-world datasets, apply generative AI, build a chatbot over a knowledge graph, and use vector search and index functionality for semantic search. The lab focuses on analyzing quarterly filings of asset managers with $100m+ assets under management, exploring relationships using Neo4j Browser and Cypher query language, and discussing potential applications in capital markets such as algorithmic trading and securities master data management.
jupyter-quant
Jupyter Quant is a dockerized environment tailored for quantitative research, equipped with essential tools like statsmodels, pymc, arch, py_vollib, zipline-reloaded, PyPortfolioOpt, numpy, pandas, sci-py, scikit-learn, yellowbricks, shap, optuna, and more. It provides Interactive Broker connectivity via ib_async and includes major Python packages for statistical and time series analysis. The image is optimized for size, includes jedi language server, jupyterlab-lsp, and common command line utilities. Users can install new packages with sudo, leverage apt cache, and bring their own dot files and SSH keys. The tool is designed for ephemeral containers, ensuring data persistence and flexibility for quantitative analysis tasks.
Qbot
Qbot is an AI-oriented automated quantitative investment platform that supports diverse machine learning modeling paradigms, including supervised learning, market dynamics modeling, and reinforcement learning. It provides a full closed-loop process from data acquisition, strategy development, backtesting, simulation trading to live trading. The platform emphasizes AI strategies such as machine learning, reinforcement learning, and deep learning, combined with multi-factor models to enhance returns. Users with some Python knowledge and trading experience can easily utilize the platform to address trading pain points and gaps in the market.
FinMem-LLM-StockTrading
This repository contains the Python source code for FINMEM, a Performance-Enhanced Large Language Model Trading Agent with Layered Memory and Character Design. It introduces FinMem, a novel LLM-based agent framework devised for financial decision-making, encompassing three core modules: Profiling, Memory with layered processing, and Decision-making. FinMem's memory module aligns closely with the cognitive structure of human traders, offering robust interpretability and real-time tuning. The framework enables the agent to self-evolve its professional knowledge, react agilely to new investment cues, and continuously refine trading decisions in the volatile financial environment. It presents a cutting-edge LLM agent framework for automated trading, boosting cumulative investment returns.
LLMs-in-Finance
This repository focuses on the application of Large Language Models (LLMs) in the field of finance. It provides insights and knowledge about how LLMs can be utilized in various scenarios within the finance industry, particularly in generating AI agents. The repository aims to explore the potential of LLMs to enhance financial processes and decision-making through the use of advanced natural language processing techniques.