
CyteType
Multi-agent LLM driven cell type annotation for single-cell RNA-Seq data
Stars: 103
CyteType is a tool for automated cell type annotation in single-cell RNA sequencing (scRNA-seq) data. It utilizes a multi-agent AI architecture to provide transparent, evidence-based annotations with Cell Ontology mapping. The tool integrates with Scanpy and Seurat workflows, aiming to streamline the time-consuming process of cell type annotation in single-cell analysis by offering consistent, reproducible annotations with a full evidence trail for every decision.
README:
![]()


CyteType performs automated cell type annotation in single-cell RNA sequencing (scRNA-seq) data. It uses a multi-agent AI architecture to deliver transparent, evidence-based annotations with Cell Ontology mapping.
Integrates with Scanpy and Seurat workflows.
Preprint published: Nov. 7, 2025: bioRxiv link - Dive into benchmarking results
Cell type annotation is one of the most time-consuming steps in single-cell analysis. It typically requires weeks of expert curation, and the results often vary between annotators. When annotations do get done, the reasoning is rarely documented; this makes it difficult to reproduce or audit later.
CyteType addresses this with a novel agentic architecture: specialized AI agents collaborate on marker gene analysis, literature evidence retrieval, and ontology mapping. The result is consistent, reproducible annotations with a full evidence trail for every decision.
| Feature | Description |
|---|---|
| Cell Ontology Integration | Automatic CL ID assignment for standardized terminology and cross-study comparison |
| Confidence Scores | Numeric certainty values (0–1) for cell type, subtype, and activation state — useful for flagging ambiguous clusters |
| Linked Literature | Each annotation includes supporting publications and condition-specific references — see exactly why a call was made |
| Annotation QC via Match Scores | Compare CyteType results against your existing annotations to quickly identify discrepancies and validate previous work |
| Embedded Chat Interface | Explore results interactively; chat is connected to your expression data for on-the-fly queries |
Also included: interactive HTML reports, Scanpy/Seurat compatibility (R wrapper via CyteTypeR), and no API keys required out of the box.
pip install cytetypeimport scanpy as sc
from cytetype import CyteType
# Assumes preprocessed AnnData with clusters and marker genes
group_key = 'clusters'
annotator = CyteType(
adata,
group_key=group_key,
rank_key='rank_genes_' + group_key,
n_top_genes=100
)
adata = annotator.run(study_context="Human PBMC from healthy donor")
sc.pl.umap(adata, color='cytetype_annotation_clusters')Note: No API keys required for default configuration. See custom LLM configuration for advanced options.
run()now handles artifact packaging and upload automatically (vars.h5+obs.duckdb) before annotation. Generated artifact files are kept on disk by default; usecleanup_artifacts=Trueto remove them after run completion/failure.
Using R/Seurat? → CyteTypeR
| Resource | Description |
|---|---|
| Configuration | LLM settings, parameters, and customization |
| Output Columns | Understanding annotation results and metadata |
| Troubleshooting | Common issues and solutions |
| Development | Contributing and local setup |
| Discord | Community support |
Each analysis generates an HTML report documenting annotation decisions, reviewer comments and an embedded chat interface for further exploration.
Validated across PBMC, bone marrow, tumor microenvironment, and cross-species datasets. CyteType's agentic architecture consistently outperforms existing annotation methods:
| Comparison | Improvement |
|---|---|
| vs GPTCellType | +388% |
| vs CellTypist | +268% |
| vs SingleR | +101% |
Browse CyteType results on atlas scale datasets
If you use CyteType in your research, please cite our preprint:
Ahuja G, Antill A, Su Y, Dall'Olio GM, Basnayake S, Karlsson G, Dhapola P. Multi-agent AI enables evidence-based cell annotation in single-cell transcriptomics. bioRxiv 2025. doi: 10.1101/2025.11.06.686964
@article{cytetype2025,
title={Multi-agent AI enables evidence-based cell annotation in single-cell transcriptomics},
author={Gautam Ahuja, Alex Antill, Yi Su, Giovanni Marco Dall'Olio, Sukhitha Basnayake, Göran Karlsson, Parashar Dhapola},
journal={bioRxiv},
year={2025},
doi={10.1101/2025.11.06.686964},
url={https://www.biorxiv.org/content/10.1101/2025.11.06.686964v1}
}CyteType is free for academic and non-commercial research under CC BY-NC-SA 4.0.
For commercial licensing, contact [email protected].
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for CyteType
Similar Open Source Tools
CyteType
CyteType is a tool for automated cell type annotation in single-cell RNA sequencing (scRNA-seq) data. It utilizes a multi-agent AI architecture to provide transparent, evidence-based annotations with Cell Ontology mapping. The tool integrates with Scanpy and Seurat workflows, aiming to streamline the time-consuming process of cell type annotation in single-cell analysis by offering consistent, reproducible annotations with a full evidence trail for every decision.

EvoAgentX
EvoAgentX is an open-source framework for building, evaluating, and evolving LLM-based agents or agentic workflows in an automated, modular, and goal-driven manner. It enables developers and researchers to move beyond static prompt chaining or manual workflow orchestration by introducing a self-evolving agent ecosystem. The framework includes features such as agent workflow autoconstruction, built-in evaluation, self-evolution engine, plug-and-play compatibility, comprehensive built-in tools, memory module support, and human-in-the-loop interactions.
Evaluator
NeMo Evaluator SDK is an open-source platform for robust, reproducible, and scalable evaluation of Large Language Models. It enables running hundreds of benchmarks across popular evaluation harnesses against any OpenAI-compatible model API. The platform ensures auditable and trustworthy results by executing evaluations in open-source Docker containers. NeMo Evaluator SDK is built on four core principles: Reproducibility by Default, Scale Anywhere, State-of-the-Art Benchmarking, and Extensible and Customizable.

X-AnyLabeling
X-AnyLabeling is a robust annotation tool that seamlessly incorporates an AI inference engine alongside an array of sophisticated features. Tailored for practical applications, it is committed to delivering comprehensive, industrial-grade solutions for image data engineers. This tool excels in swiftly and automatically executing annotations across diverse and intricate tasks.
awesome-slash
Automate the entire development workflow beyond coding. awesome-slash provides production-ready skills, agents, and commands for managing tasks, branches, reviews, CI, and deployments. It automates the entire workflow, including task exploration, planning, implementation, review, and shipping. The tool includes 11 plugins, 40 agents, 26 skills, and 26k lines of lib code, with 3,357 tests and support for 3 platforms. It works with Claude Code, OpenCode, and Codex CLI, offering specialized capabilities through skills and agents.
EnvScaler
EnvScaler is an automated, scalable framework that creates tool-interactive environments for training LLM agents. It consists of SkelBuilder for environment description mining and quality inspection, ScenGenerator for synthesizing multiple environment scenarios, and modules for supervised fine-tuning and reinforcement learning. The tool provides data, models, and evaluation guides for users to build, generate scenarios, collect training data, train models, and evaluate performance. Users can interact with environments, build environments from scratch, and improve LLMs' task-solving abilities in complex environments.

rhesis
Rhesis is a comprehensive test management platform designed for Gen AI teams, offering tools to create, manage, and execute test cases for generative AI applications. It ensures the robustness, reliability, and compliance of AI systems through features like test set management, automated test generation, edge case discovery, compliance validation, integration capabilities, and performance tracking. The platform is open source, emphasizing community-driven development, transparency, extensible architecture, and democratizing AI safety. It includes components such as backend services, frontend applications, SDK for developers, worker services, chatbot applications, and Polyphemus for uncensored LLM service. Rhesis enables users to address challenges unique to testing generative AI applications, such as non-deterministic outputs, hallucinations, edge cases, ethical concerns, and compliance requirements.
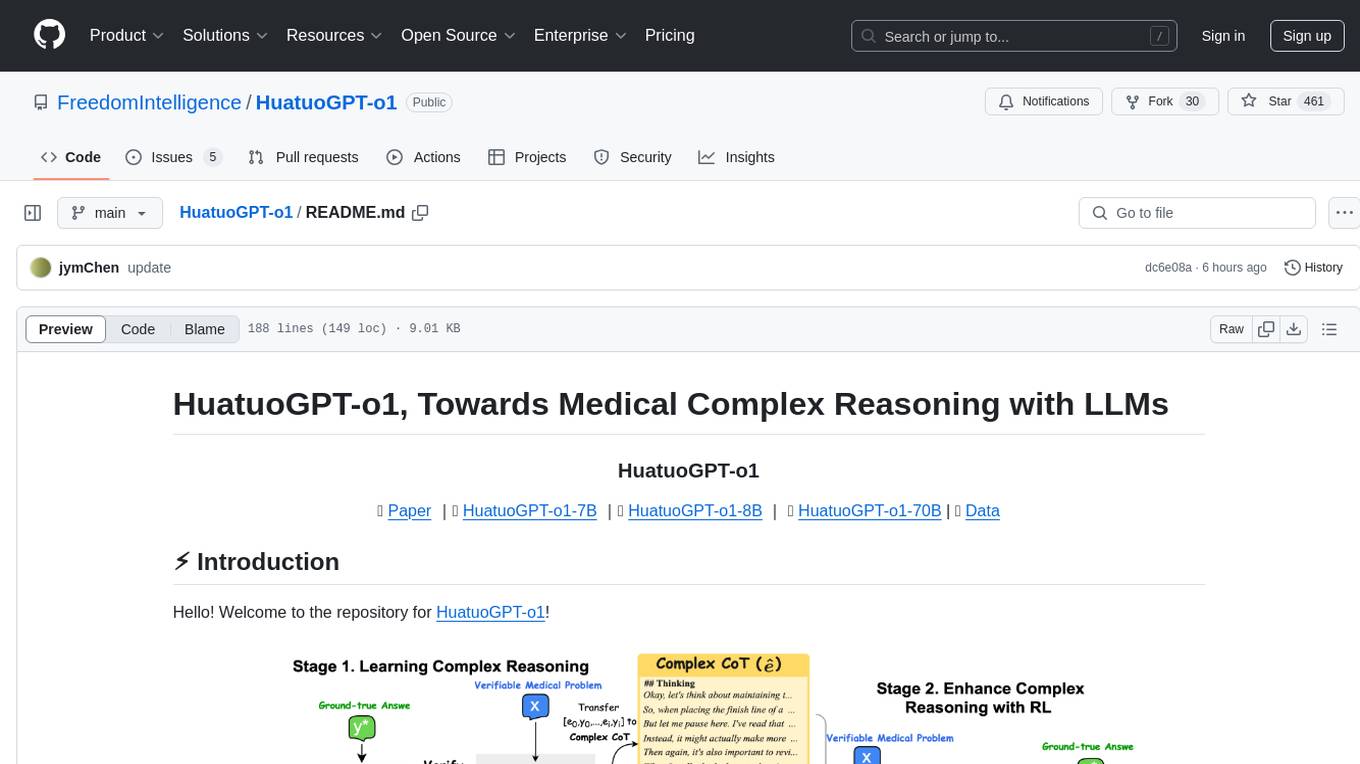
HuatuoGPT-o1
HuatuoGPT-o1 is a medical language model designed for advanced medical reasoning. It can identify mistakes, explore alternative strategies, and refine answers. The model leverages verifiable medical problems and a specialized medical verifier to guide complex reasoning trajectories and enhance reasoning through reinforcement learning. The repository provides access to models, data, and code for HuatuoGPT-o1, allowing users to deploy the model for medical reasoning tasks.
superagentx
SuperAgentX is a lightweight open-source AI framework designed for multi-agent applications with Artificial General Intelligence (AGI) capabilities. It offers goal-oriented multi-agents with retry mechanisms, easy deployment through WebSocket, RESTful API, and IO console interfaces, streamlined architecture with no major dependencies, contextual memory using SQL + Vector databases, flexible LLM configuration supporting various Gen AI models, and extendable handlers for integration with diverse APIs and data sources. It aims to accelerate the development of AGI by providing a powerful platform for building autonomous AI agents capable of executing complex tasks with minimal human intervention.
SciCode
SciCode is a challenging benchmark designed to evaluate the capabilities of language models (LMs) in generating code for solving realistic scientific research problems. It contains 338 subproblems decomposed from 80 challenging main problems across 16 subdomains from 6 domains. The benchmark offers optional descriptions specifying useful scientific background information and scientist-annotated gold-standard solutions and test cases for evaluation. SciCode demonstrates a realistic workflow of identifying critical science concepts and facts and transforming them into computation and simulation code, aiming to help showcase LLMs' progress towards assisting scientists and contribute to the future building and evaluation of scientific AI.
MemMachine
MemMachine is an open-source long-term memory layer designed for AI agents and LLM-powered applications. It enables AI to learn, store, and recall information from past sessions, transforming stateless chatbots into personalized, context-aware assistants. With capabilities like episodic memory, profile memory, working memory, and agent memory persistence, MemMachine offers a developer-friendly API, flexible storage options, and seamless integration with various AI frameworks. It is suitable for developers, researchers, and teams needing persistent, cross-session memory for their LLM applications.

BitBLAS
BitBLAS is a library for mixed-precision BLAS operations on GPUs, for example, the $W_{wdtype}A_{adtype}$ mixed-precision matrix multiplication where $C_{cdtype}[M, N] = A_{adtype}[M, K] \times W_{wdtype}[N, K]$. BitBLAS aims to support efficient mixed-precision DNN model deployment, especially the $W_{wdtype}A_{adtype}$ quantization in large language models (LLMs), for example, the $W_{UINT4}A_{FP16}$ in GPTQ, the $W_{INT2}A_{FP16}$ in BitDistiller, the $W_{INT2}A_{INT8}$ in BitNet-b1.58. BitBLAS is based on techniques from our accepted submission at OSDI'24.
unoplat-code-confluence
Unoplat-CodeConfluence is a universal code context engine that aims to extract, understand, and provide precise code context across repositories tied through domains. It combines deterministic code grammar with state-of-the-art LLM pipelines to achieve human-like understanding of codebases in minutes. The tool offers smart summarization, graph-based embedding, enhanced onboarding, graph-based intelligence, deep dependency insights, and seamless integration with existing development tools and workflows. It provides a precise context API for knowledge engine and AI coding assistants, enabling reliable code understanding through bottom-up code summarization, graph-based querying, and deep package and dependency analysis.

indexify
Indexify is an open-source engine for building fast data pipelines for unstructured data (video, audio, images, and documents) using reusable extractors for embedding, transformation, and feature extraction. LLM Applications can query transformed content friendly to LLMs by semantic search and SQL queries. Indexify keeps vector databases and structured databases (PostgreSQL) updated by automatically invoking the pipelines as new data is ingested into the system from external data sources. **Why use Indexify** * Makes Unstructured Data **Queryable** with **SQL** and **Semantic Search** * **Real-Time** Extraction Engine to keep indexes **automatically** updated as new data is ingested. * Create **Extraction Graph** to describe **data transformation** and extraction of **embedding** and **structured extraction**. * **Incremental Extraction** and **Selective Deletion** when content is deleted or updated. * **Extractor SDK** allows adding new extraction capabilities, and many readily available extractors for **PDF**, **Image**, and **Video** indexing and extraction. * Works with **any LLM Framework** including **Langchain**, **DSPy**, etc. * Runs on your laptop during **prototyping** and also scales to **1000s of machines** on the cloud. * Works with many **Blob Stores**, **Vector Stores**, and **Structured Databases** * We have even **Open Sourced Automation** to deploy to Kubernetes in production.
MarkLLM
MarkLLM is an open-source toolkit designed for watermarking technologies within large language models (LLMs). It simplifies access, understanding, and assessment of watermarking technologies, supporting various algorithms, visualization tools, and evaluation modules. The toolkit aids researchers and the community in ensuring the authenticity and origin of machine-generated text.

semantic-router
The Semantic Router is an intelligent routing tool that utilizes a Mixture-of-Models (MoM) approach to direct OpenAI API requests to the most suitable models based on semantic understanding. It enhances inference accuracy by selecting models tailored to different types of tasks. The tool also automatically selects relevant tools based on the prompt to improve tool selection accuracy. Additionally, it includes features for enterprise security such as PII detection and prompt guard to protect user privacy and prevent misbehavior. The tool implements similarity caching to reduce latency. The comprehensive documentation covers setup instructions, architecture guides, and API references.
For similar tasks
ceLLama
ceLLama is a streamlined automation pipeline for cell type annotations using large-language models (LLMs). It operates locally to ensure privacy, provides comprehensive analysis by considering negative genes, offers efficient processing speed, and generates customized reports. Ideal for quick and preliminary cell type checks.
CyteType
CyteType is a tool for automated cell type annotation in single-cell RNA sequencing (scRNA-seq) data. It utilizes a multi-agent AI architecture to provide transparent, evidence-based annotations with Cell Ontology mapping. The tool integrates with Scanpy and Seurat workflows, aiming to streamline the time-consuming process of cell type annotation in single-cell analysis by offering consistent, reproducible annotations with a full evidence trail for every decision.
For similar jobs

NoLabs
NoLabs is an open-source biolab that provides easy access to state-of-the-art models for bio research. It supports various tasks, including drug discovery, protein analysis, and small molecule design. NoLabs aims to accelerate bio research by making inference models accessible to everyone.
OpenCRISPR
OpenCRISPR is a set of free and open gene editing systems designed by Profluent Bio. The OpenCRISPR-1 protein maintains the prototypical architecture of a Type II Cas9 nuclease but is hundreds of mutations away from SpCas9 or any other known natural CRISPR-associated protein. You can view OpenCRISPR-1 as a drop-in replacement for many protocols that need a cas9-like protein with an NGG PAM and you can even use it with canonical SpCas9 gRNAs. OpenCRISPR-1 can be fused in a deactivated or nickase format for next generation gene editing techniques like base, prime, or epigenome editing.
ersilia
The Ersilia Model Hub is a unified platform of pre-trained AI/ML models dedicated to infectious and neglected disease research. It offers an open-source, low-code solution that provides seamless access to AI/ML models for drug discovery. Models housed in the hub come from two sources: published models from literature (with due third-party acknowledgment) and custom models developed by the Ersilia team or contributors.

ontogpt
OntoGPT is a Python package for extracting structured information from text using large language models, instruction prompts, and ontology-based grounding. It provides a command line interface and a minimal web app for easy usage. The tool has been evaluated on test data and is used in related projects like TALISMAN for gene set analysis. OntoGPT enables users to extract information from text by specifying relevant terms and provides the extracted objects as output.

bia-bob
BIA `bob` is a Jupyter-based assistant for interacting with data using large language models to generate Python code. It can utilize OpenAI's chatGPT, Google's Gemini, Helmholtz' blablador, and Ollama. Users need respective accounts to access these services. Bob can assist in code generation, bug fixing, code documentation, GPU-acceleration, and offers a no-code custom Jupyter Kernel. It provides example notebooks for various tasks like bio-image analysis, model selection, and bug fixing. Installation is recommended via conda/mamba environment. Custom endpoints like blablador and ollama can be used. Google Cloud AI API integration is also supported. The tool is extensible for Python libraries to enhance Bob's functionality.

Scientific-LLM-Survey
Scientific Large Language Models (Sci-LLMs) is a repository that collects papers on scientific large language models, focusing on biology and chemistry domains. It includes textual, molecular, protein, and genomic languages, as well as multimodal language. The repository covers various large language models for tasks such as molecule property prediction, interaction prediction, protein sequence representation, protein sequence generation/design, DNA-protein interaction prediction, and RNA prediction. It also provides datasets and benchmarks for evaluating these models. The repository aims to facilitate research and development in the field of scientific language modeling.
polaris
Polaris establishes a novel, industry‑certified standard to foster the development of impactful methods in AI-based drug discovery. This library is a Python client to interact with the Polaris Hub. It allows you to download Polaris datasets and benchmarks, evaluate a custom method against a Polaris benchmark, and create and upload new datasets and benchmarks.
awesome-AI4MolConformation-MD
The 'awesome-AI4MolConformation-MD' repository focuses on protein conformations and molecular dynamics using generative artificial intelligence and deep learning. It provides resources, reviews, datasets, packages, and tools related to AI-driven molecular dynamics simulations. The repository covers a wide range of topics such as neural networks potentials, force fields, AI engines/frameworks, trajectory analysis, visualization tools, and various AI-based models for protein conformational sampling. It serves as a comprehensive guide for researchers and practitioners interested in leveraging AI for studying molecular structures and dynamics.