
claude-scholar
Personal AI CLI configuration for academic research & software development. Supports Claude Code, OpenCode, and Codex CLI — covering the full research lifecycle from ideation to publication.
Stars: 812
Claude Scholar is a personal configuration system for Claude Code CLI, designed for academic research and software development. It covers the full research lifecycle from ideation to publication, offering rich skills, commands, agents, and hooks optimized for various tasks. The tool supports features like research ideation, ML project development, experiment analysis, paper writing, self-review, submission and rebuttal, post-acceptance processing, and more. It also includes supporting workflows for automated enforcement, knowledge extraction, skill evolution, and offers a structured file structure for easy navigation and usage.
README:



Personal Claude Code / Codex CLI / OpenCode configuration for academic research and software development — covering the full research lifecycle from ideation to publication.
- 2026-02-26: Zotero MCP Web API mode — remote access, import papers via DOI/arXiv ID/URL, collection management, item updates, safe deletion; config guides for Claude Code, Codex CLI, OpenCode
-
2026-02-25: Codex CLI support — added
codexbranch supporting OpenAI Codex CLI with config.toml, 40 skills, 14 agents, and sandbox security -
2026-02-23: Added
setup.shinstaller — safe merge into existing~/.claude, auto-backupsettings.json, smart hooks/mcpServers/plugins merge -
2026-02-21: OpenCode support — Claude Scholar now supports OpenCode as an alternative CLI; switch to the
opencodebranch for OpenCode-compatible configuration
View older changelog
-
2026-02-20: Bilingual config — translated
CLAUDE.mdto English for international readability; addedCLAUDE.zh-CN.mdas Chinese backup; Chinese users can switch withcp CLAUDE.zh-CN.md CLAUDE.md -
2026-02-15: Zotero MCP integration — added
/zotero-reviewand/zotero-notescommands, updatedresearch-ideationskill with Zotero integration guide, enhancedliterature-revieweragent with Zotero MCP support for automated paper import, collection management, full-text reading, and citation export -
2026-02-14: Hooks optimization — restructured
security-guardto two-tier system (Block + Confirm),skill-forced-evalnow groups skills into 6 categories with silent scan mode,session-startlimits display to top 5,session-summaryadds 30-day log auto-cleanup,stop-summaryshows separate added/modified/deleted counts; removed deprecated shell scripts (lib/common.sh, lib/platform.sh) - 2026-02-11: Major update — added 10 new skills (research-ideation, results-analysis, citation-verification, review-response, paper-self-review, post-acceptance, daily-coding, frontend-design, ui-ux-pro-max, web-design-reviewer), 7 new agents, 8 research workflow commands, 2 new rules (security, experiment-reproducibility); restructured CLAUDE.md; 89 files changed
- 2026-01-26: Rewrote all Hooks to cross-platform Node.js; completely rewrote README; expanded ML paper writing knowledge base; merged PR #1 (cross-platform support)
- 2026-01-25: Project open-sourced, v1.0.0 released with 25 skills (architecture-design, bug-detective, git-workflow, kaggle-learner, scientific-writing, etc.), 2 agents (paper-miner, kaggle-miner), 30+ commands (including SuperClaude suite), 5 Shell Hooks, and 2 rules (coding-style, agents)
Claude Scholar is a personal configuration system for Claude Code CLI, providing rich skills, commands, agents, and hooks optimized for:
- Academic Research - Complete research lifecycle: idea generation → experimentation → results analysis → paper writing → review response → conference preparation
- Software Development - Git workflows, code review, test-driven development, ML project architecture
- Plugin Development - Skill, Command, Agent, Hook development guides with quality assessment
- Project Management - Planning documents, code standards, automated workflows with cross-platform hooks
| Topic | Description |
|---|---|
| 🚀 Quick Start | Get up and running in minutes |
| 📚 Core Workflows | Paper writing, code organization, skill evolution |
| 🛠️ What's Included | Skills, commands, agents overview |
| 📖 Installation Guide | Full, minimal, or selective setup |
| 📦 MCP Setup | Zotero MCP for research workflows |
| 🔧 Project Rules | Coding style and agent orchestration |
Complete academic research lifecycle - 7 stages from idea to publication.
End-to-end research startup from idea generation to literature management:
Tools: research-ideation skill + literature-reviewer agent + Zotero MCP
Process:
- 5W1H Brainstorming: What, Why, Who, When, Where, How → structured thinking framework
-
Literature Search & Import: WebSearch finds papers → extract DOIs → auto-import to Zotero via
add_items_by_doi→ classify into themed sub-collections (Core Papers, Methods, Applications, Baselines, To-Read) -
PDF & Full-Text:
find_and_attach_pdfsbatch-attaches open-access PDFs →get_item_fulltextreads full paper content for deep analysis (fallback: abstract + domain knowledge) - Gap Analysis: 5 types (Literature, Methodological, Application, Interdisciplinary, Temporal) → identify 2-3 concrete research opportunities
- Research Question: SMART principles → formulate specific, measurable questions
- Method Selection & Planning: Evaluate method applicability → timeline, milestones, risk assessment
Zotero Collection Structure:
📁 Research-{Topic}-{YYYY-MM}
├── 📁 Core Papers
├── 📁 Methods
├── 📁 Applications
├── 📁 Baselines
└── 📁 To-Read
Output: literature-review.md + research-proposal.md + references.bib (exported from Zotero) + organized Zotero collection with PDFs
Commands:
-
/research-init "topic"→ full workflow: create Zotero collection → search & import papers → full-text analysis → gap analysis → generate review & proposal -
/zotero-review "collection"→ analyze an existing Zotero collection → generate literature review with comparison matrix -
/zotero-notes "collection"→ batch read papers → generate structured reading notes (summary/detailed/comparison formats)
Maintainable ML project structure for experiment code:
Tools: architecture-design skill + code-reviewer agent + git-workflow skill
Process:
-
Structure: Factory & Registry patterns → config-driven models (only
cfgparameter) → enforced byrules/coding-style.md -
Code Style: 200-400 line files → type hints required →
@dataclass(frozen=True)for configs → max 3-level nesting -
Debug (
bug-detective): Error pattern matching for Python/Bash/JS → stack trace analysis → anti-pattern identification -
Git: Conventional Commits (
feat/scope: message) → branch strategy (master/develop/feature) → merge with--no-ff
Commands: /plan, /commit, /code-review, /tdd
Statistical analysis and visualization of experimental results:
Tools: results-analysis skill + data-analyst agent
Process:
- Data Processing: Automated cleaning and preprocessing of experiment logs
- Statistical Testing: t-test, ANOVA, Wilcoxon signed-rank → validate significance
- Visualization: matplotlib/seaborn integration → publication-ready figures (line plots, bar charts, heatmaps)
- Ablation Studies: Systematic component analysis → understand contribution of each part
Command: /analyze-results <experiment_dir> → generates analysis report with figures and statistics
Systematic paper writing from template to final draft:
Tools: ml-paper-writing skill + paper-miner agent + latex-conference-template-organizer skill
Process:
- Template Preparation: Download conference .zip → extract main files → remove sample content → clean Overleaf-ready structure
-
Citation Verification (
citation-verification): Multi-layer validation (Format → API → Information → Content) → prevents hallucinations - Systematic Writing: Narrative framing → 5-sentence abstract formula → section-by-section drafting with feedback cycles
-
Anti-AI Processing (
writing-anti-ai): Remove inflated symbolism, promotional language, vague attributions → add human voice and rhythm → bilingual support (EN/CN)
Venues: NeurIPS, ICML, ICLR, ACL, AAAI, COLM, Nature, Science, Cell, PNAS
Quality assurance before submission:
Tools: paper-self-review skill
Process:
- Structure Check: Logical flow, section balance, narrative coherence
- Logic Validation: Argument soundness, claim-evidence alignment, assumption clarity
- Citation Audit: Reference accuracy, proper attribution, citation completeness
- Figure Quality: Visual clarity, caption completeness, color accessibility
- Writing Polish: Grammar, clarity, conciseness, academic tone
- Compliance: Page limits, formatting requirements, ethical disclosures
6-item checklist → systematic quality assessment
Paper submission and review response:
Tools: review-response skill + rebuttal-writer agent
Submission Process:
- Pre-submission: Conference-specific checklists (NeurIPS 16-item, ICML Broader Impact, ICLR LLM disclosure)
- Format Check: Page limits, anonymization, supplementary materials
- Final Review: Proofread, check references, verify figures
Rebuttal Process:
- Review Analysis: Parse and classify comments (Major/Minor/Typo/Misunderstanding)
- Response Strategy: Accept/Defend/Clarify/Experiment → tailored approach per comment type
- Rebuttal Writing: Structured response with evidence and reasoning
- Tone Management: Professional, respectful, evidence-based language
Command: /rebuttal <review_file> → generates complete rebuttal document with experiment plan
Conference preparation and research promotion:
Tools: post-acceptance skill
Process:
- Presentation: Slide creation guidance (15/20/30 min formats) → visual design principles → storytelling structure
- Poster: Academic poster templates (A0/A1 sizes) → layout optimization → visual hierarchy
- Promotion: Social media content (Twitter/X, LinkedIn) → blog posts → press releases → research summaries
Commands: /presentation, /poster, /promote → automated content generation
Coverage: 90% of academic research lifecycle (from idea to publication)
These workflows run in the background to enhance the primary workflows.
Cross-platform hooks (Node.js) automate workflow enforcement:
Session Start → Skill Evaluation → Session End → Session Stop
-
skill-forced-eval (
skill-forced-eval.js): Before EVERY user prompt → groups all available skills (local + plugins) into 6 categories → silent scan mode, only outputs matched skills → requires activation before implementation → ensures no relevant skill is missed -
session-start (
session-start.js): Session begins → displays Git status, pending todos, available commands (top 5 with fold count), package manager → shows project context at a glance -
session-summary (
session-summary.js): Session ends → generates comprehensive work log → summarizes all changes made → provides smart recommendations for next steps → auto-cleans logs older than 30 days -
stop-summary (
stop-summary.js): Session stops → quick status check with separate added/modified/deleted counts → groups temp files by folder (top 3 per folder) → shows actionable cleanup suggestions -
security-guard (
security-guard.js): Two-tier security system — Block tier: immediately rejects catastrophic commands (rm -rf /, dd, mkfs, system dirs); Confirm tier: injects systemMessage forcing model to ask user before executing dangerous-but-legitimate operations (git push --force, git reset --hard, chmod 777, SQL DROP/DELETE/TRUNCATE, sensitive file writes)
Cross-platform: All hooks use Node.js (not shell scripts) ensuring Windows/macOS/Linux compatibility.
Two specialized mining agents continuously extract knowledge to improve skills:
-
paper-miner (agent): Analyze research papers (PDF/DOCX/arXiv links) → extracts writing patterns, structure insights, venue requirements, rebuttal strategies → updates
ml-paper-writing/references/knowledge/with categorized entries (structure.md, writing-techniques.md, submission-guides.md, review-response.md) -
kaggle-miner (agent): Study winning Kaggle competition solutions → extract competition briefs, front-runner detailed technical analysis, code templates, best practices → update the
kaggle-learnerskill's knowledge base (references/knowledge/[domain]/directories, categorized by NLP/CV/Time Series/Tabular/Multimodal)
Knowledge feedback loop: Each paper or solution analyzed enriches the knowledge base, creating a self-improving system that evolves with your research.
3-step continuous improvement cycle for maintaining and improving skills:
skill-development → skill-quality-reviewer → skill-improver
-
Develop (
skill-development): Create skills with proper YAML frontmatter → clear descriptions with trigger phrases → progressive disclosure (lean SKILL.md, details inreferences/) -
Review (
skill-quality-reviewer): 4-dimension quality assessment → Description Quality (25%), Content Organization (30%), Writing Style (20%), Structural Integrity (25%) → generates improvement plan with prioritized fixes -
Improve (
skill-improver): Merges suggested changes → updates documentation → iterates on feedback → reads improvement plans and applies changes automatically
View file structure
claude-scholar/
├── hooks/ # Cross-platform JavaScript hooks (automated enforcement)
│ ├── hook-common.js # Shared utilities (git diff, change analysis)
│ ├── session-start.js # Session begin - Git status, todos, top 5 commands
│ ├── skill-forced-eval.js # Silent scan, 6-category skill grouping
│ ├── session-summary.js # Session end - work log, 30-day log auto-cleanup
│ ├── stop-summary.js # Session stop - added/modified/deleted counts, grouped temp files
│ └── security-guard.js # Two-tier security: Block (catastrophic) + Confirm (dangerous)
│
├── skills/ # 32 specialized skills (domain knowledge + workflows)
│ ├── ml-paper-writing/ # Full paper writing: NeurIPS, ICML, ICLR, ACL, AAAI, COLM
│ │ └── references/
│ │ └── knowledge/ # Extracted patterns from successful papers
│ │ ├── structure.md # Paper organization patterns
│ │ ├── writing-techniques.md # Sentence templates, transitions
│ │ ├── submission-guides.md # Venue requirements (page limits, etc.)
│ │ └── review-response.md # Rebuttal strategies
│ │
│ ├── research-ideation/ # Research startup: 5W1H, literature review, gap analysis
│ │ └── references/
│ │ ├── 5w1h-framework.md # Systematic thinking tool
│ │ ├── gap-analysis-guide.md # 5 types of research gaps
│ │ ├── literature-search-strategies.md
│ │ ├── research-question-formulation.md
│ │ ├── method-selection-guide.md
│ │ └── research-planning.md
│ │
│ ├── results-analysis/ # Experiment analysis: statistics, visualization, ablation
│ │ └── references/
│ │ ├── statistical-methods.md # t-test, ANOVA, Wilcoxon
│ │ ├── visualization-best-practices.md # matplotlib/seaborn
│ │ ├── results-writing-guide.md # Writing results sections
│ │ └── common-pitfalls.md # Common analysis mistakes
│ │
│ ├── review-response/ # Systematic rebuttal writing
│ │ └── references/
│ │ ├── review-classification.md # Major/Minor/Typo/Misunderstanding
│ │ ├── response-strategies.md # Accept/Defend/Clarify/Experiment
│ │ ├── rebuttal-templates.md # Structured response templates
│ │ └── tone-guidelines.md # Professional language
│ │
│ ├── paper-self-review/ # 6-item quality checklist
│ ├── post-acceptance/ # Conference preparation
│ │ └── references/
│ │ ├── presentation-templates/ # Slide creation (15/20/30 min)
│ │ ├── poster-templates/ # Academic poster design
│ │ ├── promotion-examples/ # Social media content
│ │ └── design-guidelines.md # Visual design principles
│ │
│ ├── citation-verification/ # Multi-layer citation validation
│ ├── writing-anti-ai/ # Remove AI patterns: symbolism, promotional language
│ │ └── references/
│ │ ├── patterns-english.md # English AI patterns to remove
│ │ └── patterns-chinese.md # Chinese AI patterns to remove
│ │
│ ├── architecture-design/ # ML project patterns: Factory, Registry, Config-driven
│ ├── git-workflow/ # Git discipline: Conventional Commits, branching
│ ├── bug-detective/ # Debugging: Python, Bash, JS/TS error patterns
│ ├── code-review-excellence/ # Code review: security, performance, maintainability
│ ├── skill-development/ # Skill creation: YAML, progressive disclosure
│ ├── skill-quality-reviewer/ # Skill assessment: 4-dimension scoring
│ ├── skill-improver/ # Skill evolution: merge improvements
│ ├── kaggle-learner/ # Learn from Kaggle winning solutions
│ ├── doc-coauthoring/ # Document collaboration workflow
│ ├── latex-conference-template-organizer # Template cleanup for Overleaf
│ └── ... (10+ more skills)
│
├── commands/ # 50+ slash commands (quick workflow execution)
│ ├── research-init.md # Launch research startup workflow
│ ├── zotero-review.md # Read Zotero papers, generate literature review
│ ├── zotero-notes.md # Batch read Zotero papers, generate reading notes
│ ├── analyze-results.md # Analyze experiment results
│ ├── rebuttal.md # Generate systematic rebuttal document
│ ├── presentation.md # Create conference presentation outline
│ ├── poster.md # Generate academic poster design plan
│ ├── promote.md # Generate promotion content
│ ├── plan.md # Implementation planning with agent delegation
│ ├── commit.md # Conventional Commits: feat/fix/docs/refactor
│ ├── code-review.md # Quality and security review workflow
│ ├── tdd.md # Test-driven development: Red-Green-Refactor
│ ├── build-fix.md # Fix build errors automatically
│ ├── verify.md # Run verification loops
│ ├── checkpoint.md # Save verification state
│ ├── refactor-clean.md # Remove dead code
│ ├── learn.md # Extract patterns from code
│ ├── update-github.md # Commit and push to GitHub
│ ├── update-readme.md # Update README documentation
│ ├── update-memory.md # Check and update CLAUDE.md memory
│ ├── create_project.md # Create new project from template
│ ├── setup-pm.md # Configure package manager (uv/pnpm)
│ └── sc/ # SuperClaude command suite (30 commands)
│ ├── sc-agent.md # Agent management
│ ├── sc-estimate.md # Development time estimation
│ ├── sc-improve.md # Code improvement
│ └── ...
│
├── agents/ # 14 specialized agents (focused task delegation)
│ ├── literature-reviewer.md # Literature search and trend analysis
│ ├── data-analyst.md # Automated data analysis and visualization
│ ├── rebuttal-writer.md # Systematic rebuttal writing
│ ├── paper-miner.md # Extract paper knowledge: structure, techniques
│ ├── architect.md # System design: architecture decisions
│ ├── code-reviewer.md # Review code: quality, security, best practices
│ ├── tdd-guide.md # Guide TDD: test-first development
│ ├── kaggle-miner.md # Extract engineering practices from Kaggle
│ ├── build-error-resolver.md # Fix build errors: analyze and resolve
│ ├── refactor-cleaner.md # Remove dead code: detect and cleanup
│ ├── bug-analyzer.md # Deep code execution flow analysis and root cause investigation
│ ├── dev-planner.md # Implementation planning and task breakdown
│ ├── ui-sketcher.md # UI blueprint design and interaction specs
│ └── story-generator.md # User story and requirement generation
│
├── rules/ # Global guidelines (always-follow constraints)
│ ├── coding-style.md # ML project standards: file size, immutability, types
│ ├── agents.md # Agent orchestration: when to delegate, parallel execution
│ ├── security.md # Secrets management, sensitive file protection
│ └── experiment-reproducibility.md # Random seeds, config recording, checkpoints
│
├── CLAUDE.md # Global configuration: project overview, preferences, rules
│
└── README.md # This file - overview, installation, features
Web Design:
-
frontend-design- Create distinctive, production-grade frontend interfaces -
ui-ux-pro-max- UI/UX design intelligence (50+ styles, 97 palettes, 9 stacks) -
web-design-reviewer- Visual inspection and design issue fixing
Writing & Academic:
-
ml-paper-writing- Full paper writing guidance for top conferences/journals -
writing-anti-ai- Remove AI writing patterns (bilingual support) -
doc-coauthoring- Structured document collaboration workflow -
latex-conference-template-organizer- LaTeX template management -
daily-paper-generator- Automated daily paper generation for research tracking
Research Workflow:
-
research-ideation- Research startup: 5W1H brainstorming, literature review, gap analysis -
results-analysis- Experiment analysis: statistical testing, visualization, ablation studies -
review-response- Systematic rebuttal writing with tone management -
paper-self-review- 6-item quality checklist for paper self-assessment -
post-acceptance- Conference preparation: presentations, posters, promotion -
citation-verification- Multi-layer citation validation to prevent hallucinations
Development:
-
daily-coding- Daily coding checklist (minimal, auto-triggered) -
git-workflow- Git best practices (Conventional Commits, branching) -
code-review-excellence- Code review guidelines -
bug-detective- Debugging for Python, Bash, JS/TS -
architecture-design- ML project design patterns -
verification-loop- Testing and validation
Plugin Development:
-
skill-development- Skill creation guide -
skill-improver- Skill improvement tools -
skill-quality-reviewer- Quality assessment -
command-development- Slash command creation -
agent-identifier- Agent configuration -
hook-development- Hook development guide -
mcp-integration- MCP server integration
Utilities:
-
uv-package-manager- Modern Python package management -
planning-with-files- Markdown-based planning -
webapp-testing- Local web application testing -
kaggle-learner- Learn from Kaggle solutions
Research Commands:
| Command | Purpose |
|---|---|
/research-init |
Launch research startup workflow (5W1H, literature review, gap analysis) |
/zotero-review |
Read papers from Zotero collection, generate structured literature review |
/zotero-notes |
Batch read Zotero papers, generate structured reading notes |
/analyze-results |
Analyze experiment results (statistics, visualization, ablation) |
/rebuttal |
Generate systematic rebuttal document from review comments |
/presentation |
Create conference presentation outline |
/poster |
Generate academic poster design plan |
/promote |
Generate promotion content (Twitter, LinkedIn, blog) |
Development Commands:
| Command | Purpose |
|---|---|
/plan |
Create implementation plans |
/commit |
Commit with Conventional Commits |
/update-github |
Commit and push to GitHub |
/update-readme |
Update README documentation |
/update-memory |
Check and update CLAUDE.md memory |
/code-review |
Perform code review |
/tdd |
Test-driven development workflow |
/build-fix |
Fix build errors |
/verify |
Verify changes |
/checkpoint |
Create checkpoints |
/refactor-clean |
Refactor and cleanup |
/learn |
Extract reusable patterns |
/create_project |
Create new project from template |
/setup-pm |
Configure package manager (uv/pnpm) |
/sc |
SuperClaude command suite (30 commands) |
Research Agents:
- literature-reviewer - Literature search, classification, and trend analysis
- data-analyst - Automated data analysis and visualization
- rebuttal-writer - Systematic rebuttal writing with tone optimization
- paper-miner - Extract paper writing knowledge from successful publications
Development Agents:
- architect - System architecture design
- build-error-resolver - Fix build errors
- code-reviewer - Review code quality
- refactor-cleaner - Remove dead code
- tdd-guide - Guide TDD workflow
- kaggle-miner - Extract Kaggle engineering practices
- bug-analyzer - Deep code execution flow analysis and root cause investigation
- dev-planner - Implementation planning and task breakdown
Design & Content Agents:
- ui-sketcher - UI blueprint design and interaction specs
- story-generator - User story and requirement generation
Choose the installation method that fits your needs:
git clone https://github.com/Galaxy-Dawn/claude-scholar.git /tmp/claude-scholar
bash /tmp/claude-scholar/scripts/setup.sh
The script merges skills/commands/agents/rules/hooks into your existing ~/.claude, and adds hooks/mcpServers/enabledPlugins to your settings.json (auto-backup to settings.json.bak). Your env and permissions are untouched.
Includes: All 32 skills, 50+ commands, 14 agents, 5 hooks, and project rules.
Core hooks and essential skills only (faster load, less complexity):
# Clone repository
git clone https://github.com/Galaxy-Dawn/claude-scholar.git /tmp/claude-scholar
# Copy only hooks and core skills
mkdir -p ~/.claude/hooks ~/.claude/skills
cp /tmp/claude-scholar/hooks/*.js ~/.claude/hooks/
cp -r /tmp/claude-scholar/skills/ml-paper-writing ~/.claude/skills/
cp -r /tmp/claude-scholar/skills/research-ideation ~/.claude/skills/
cp -r /tmp/claude-scholar/skills/results-analysis ~/.claude/skills/
cp -r /tmp/claude-scholar/skills/review-response ~/.claude/skills/
cp -r /tmp/claude-scholar/skills/writing-anti-ai ~/.claude/skills/
cp -r /tmp/claude-scholar/skills/git-workflow ~/.claude/skills/
cp -r /tmp/claude-scholar/skills/bug-detective ~/.claude/skills/
# Cleanup
rm -rf /tmp/claude-scholar
Post-install: Merge hooks config into your settings.json — see settings.json.template for the required hooks entries.
Includes: 5 hooks, 7 core skills (complete research workflow + essential development).
Pick and choose specific components:
# Clone repository
git clone https://github.com/Galaxy-Dawn/claude-scholar.git /tmp/claude-scholar
cd /tmp/claude-scholar
# Copy what you need, for example:
# - Hooks only
cp hooks/*.js ~/.claude/hooks/
# - Specific skills
cp -r skills/latex-conference-template-organizer ~/.claude/skills/
cp -r skills/architecture-design ~/.claude/skills/
# - Specific agents
cp agents/paper-miner.md ~/.claude/agents/
# - Project rules
cp rules/coding-style.md ~/.claude/rules/
cp rules/agents.md ~/.claude/rules/
Post-install: Merge hooks config into your settings.json — see settings.json.template.
Recommended for: Advanced users who want custom configurations.
- Claude Code CLI
- Git
- Node.js (required for hooks)
- uv, Python (for Python development)
- Zotero (for Zotero MCP features)
For Zotero-integrated research workflows, install the MCP server:
# Install from Galaxy-Dawn fork (Web API mode)
uv tool install git+https://github.com/Galaxy-Dawn/zotero-mcp.git
Then add to your ~/.claude/settings.json:
{
"mcpServers": {
"zotero": {
"command": "zotero-mcp",
"args": ["serve"],
"env": {
"ZOTERO_API_KEY": "your-api-key",
"ZOTERO_LIBRARY_ID": "your-library-id",
"ZOTERO_LIBRARY_TYPE": "user",
"UNPAYWALL_EMAIL": "[email protected]",
"UNSAFE_OPERATIONS": "all"
}
}
}
}
See MCP_SETUP.md for detailed setup guide and troubleshooting.
After installation, the hooks provide automated workflow assistance:
-
Every prompt triggers
skill-forced-eval→ ensures applicable skills are considered -
Session starts with
session-start→ displays project context -
Sessions end with
session-summary→ generates work log with recommendations -
Session stops with
stop-summary→ provides status check
Enforced by rules/coding-style.md:
- File Size: 200-400 lines maximum
-
Immutability: Use
@dataclass(frozen=True)for configs - Type Hints: Required for all functions
- Patterns: Factory & Registry for all modules
-
Config-Driven: Models accept only
cfgparameter
Defined in rules/agents.md:
- Available agent types and purposes
- Parallel task execution
- Multi-perspective analysis
Defined in rules/security.md:
- Secrets management (environment variables,
.envfiles) - Sensitive file protection (never commit tokens, keys, credentials)
- Pre-commit security checks via hooks
Defined in rules/experiment-reproducibility.md:
- Random seed management for reproducibility
- Configuration recording (Hydra auto-save)
- Environment recording and checkpoint management
This is a personal configuration, but you're welcome to:
- Fork and adapt for your own research
- Submit issues for bugs
- Suggest improvements via issues
MIT License
Built with Claude Code CLI and enhanced by the open-source community.
This project is inspired by and builds upon excellent work from the community:
- everything-claude-code - Comprehensive resource for Claude Code CLI
- AI-research-SKILLs - Research-focused skills and configurations
These projects provided valuable insights and foundations for the research-oriented features in Claude Scholar.
For data science, AI research, and academic writing.
Repository: https://github.com/Galaxy-Dawn/claude-scholar
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for claude-scholar
Similar Open Source Tools
claude-scholar
Claude Scholar is a personal configuration system for Claude Code CLI, designed for academic research and software development. It covers the full research lifecycle from ideation to publication, offering rich skills, commands, agents, and hooks optimized for various tasks. The tool supports features like research ideation, ML project development, experiment analysis, paper writing, self-review, submission and rebuttal, post-acceptance processing, and more. It also includes supporting workflows for automated enforcement, knowledge extraction, skill evolution, and offers a structured file structure for easy navigation and usage.
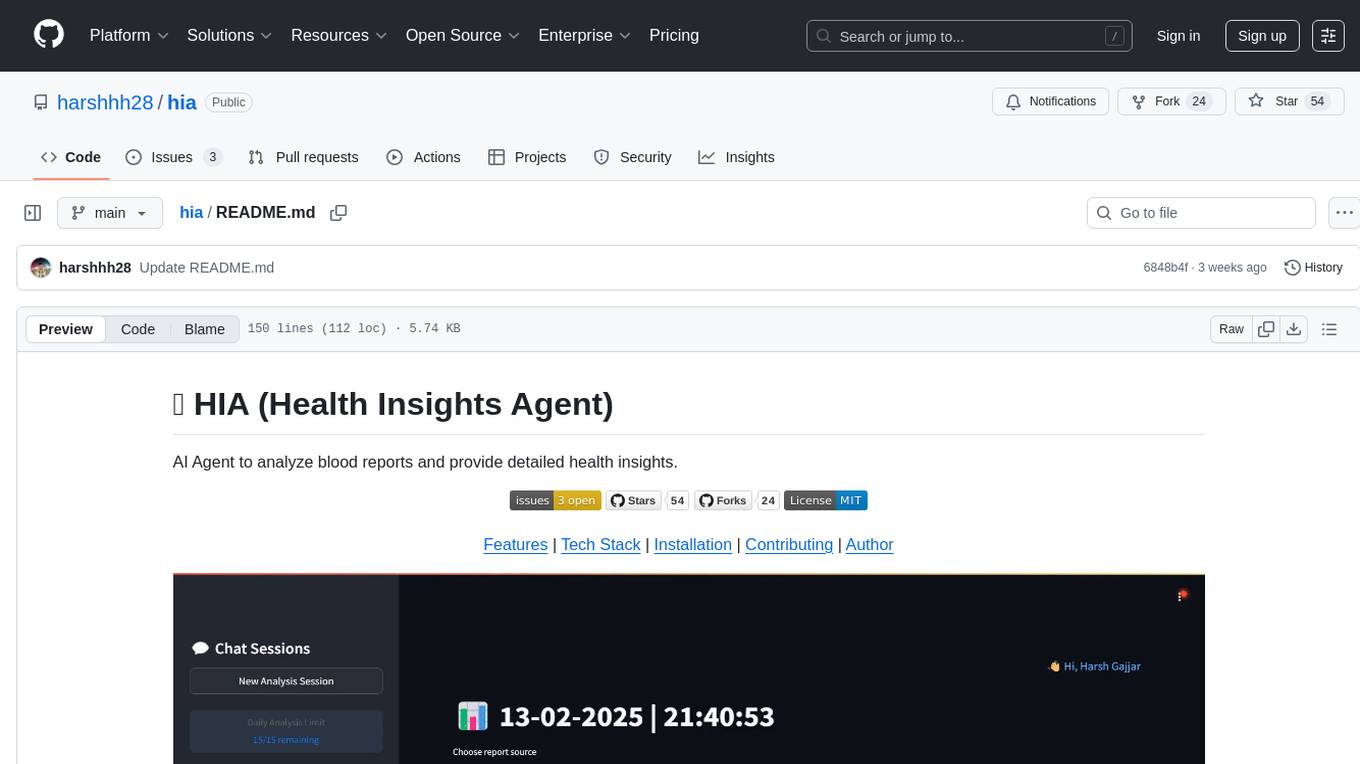
hia
HIA (Health Insights Agent) is an AI agent designed to analyze blood reports and provide personalized health insights. It features an intelligent agent-based architecture with multi-model cascade system, in-context learning, PDF upload and text extraction, secure user authentication, session history tracking, and a modern UI. The tech stack includes Streamlit for frontend, Groq for AI integration, Supabase for database, PDFPlumber for PDF processing, and Supabase Auth for authentication. The project structure includes components for authentication, UI, configuration, services, agents, and utilities. Contributions are welcome, and the project is licensed under MIT.
claude-code-ultimate-guide
The Claude Code Ultimate Guide is an exhaustive documentation resource that takes users from beginner to power user in using Claude Code. It includes production-ready templates, workflow guides, a quiz, and a cheatsheet for daily use. The guide covers educational depth, methodologies, and practical examples to help users understand concepts and workflows. It also provides interactive onboarding, a repository structure overview, and learning paths for different user levels. The guide is regularly updated and offers a unique 257-question quiz for comprehensive assessment. Users can also find information on agent teams coverage, methodologies, annotated templates, resource evaluations, and learning paths for different roles like junior developer, senior developer, power user, and product manager/devops/designer.
claude-code-mastery
Claude Code Mastery is a comprehensive tool for maximizing Claude Code, offering a production-ready project template with 16 slash commands, deterministic hook enforcement, MongoDB wrapper, live AI monitoring, and three-layer security. It provides a security gatekeeper, project scaffolding blueprint, MCP server integration, workflow automation through custom commands, and emphasizes the importance of single-purpose chats to avoid performance degradation.
llm4s
LLM4S provides a simple, robust, and scalable framework for building Large Language Models (LLM) applications in Scala. It aims to leverage Scala's type safety, functional programming, JVM ecosystem, concurrency, and performance advantages to create reliable and maintainable AI-powered applications. The framework supports multi-provider integration, execution environments, error handling, Model Context Protocol (MCP) support, agent frameworks, multimodal generation, and Retrieval-Augmented Generation (RAG) workflows. It also offers observability features like detailed trace logging, monitoring, and analytics for debugging and performance insights.

agent-skills
Agent Skills is a secure, validated skill registry for professional AI coding agents. It provides a library of verified, tested, and safe capabilities to extend various AI agents with confidence. The tool addresses security concerns in marketplace skills by offering 100% open-source code, static analysis for credential theft prevention, immutable integrity to prevent supply chain attacks, and human curation to ensure safety boundaries. Users can install skills through an interactive wizard, choose from a variety of supported AI coding agents, and benefit from a growing catalog of featured skills for development, cloud, automation, design, and security tasks.
LLM-TradeBot
LLM-TradeBot is an Intelligent Multi-Agent Quantitative Trading Bot based on the Adversarial Decision Framework (ADF). It achieves high win rates and low drawdown in automated futures trading through market regime detection, price position awareness, dynamic score calibration, and multi-layer physical auditing. The bot prioritizes judging 'IF we should trade' before deciding 'HOW to trade' and offers features like multi-agent collaboration, agent configuration, agent chatroom, AUTO1 symbol selection, multi-LLM support, multi-account trading, async concurrency, CLI headless mode, test/live mode toggle, safety mechanisms, and full-link auditing. The system architecture includes a multi-agent architecture with various agents responsible for different tasks, a four-layer strategy filter, and detailed data flow diagrams. The bot also supports backtesting, full-link data auditing, and safety warnings for users.
specweave
SpecWeave is a spec-driven Skill Fabric for AI coding agents that allows programming AI in English. It provides first-class support for Claude Code and offers reusable logic for controlling AI behavior. With over 100 skills out of the box, SpecWeave eliminates the need to learn Claude Code docs and handles various aspects of feature development. The tool enables users to describe what they want, and SpecWeave autonomously executes tasks, including writing code, running tests, and syncing to GitHub/JIRA. It supports solo developers, agent teams working in parallel, and brownfield projects, offering file-based coordination, autonomous teams, and enterprise-ready features. SpecWeave also integrates LSP Code Intelligence for semantic understanding of codebases and allows for extensible skills without forking.
Automodel
Automodel is a Python library for automating the process of building and evaluating machine learning models. It provides a set of tools and utilities to streamline the model development workflow, from data preprocessing to model selection and evaluation. With Automodel, users can easily experiment with different algorithms, hyperparameters, and feature engineering techniques to find the best model for their dataset. The library is designed to be user-friendly and customizable, allowing users to define their own pipelines and workflows. Automodel is suitable for data scientists, machine learning engineers, and anyone looking to quickly build and test machine learning models without the need for manual intervention.
smart-ralph
Smart Ralph is a Claude Code plugin designed for spec-driven development. It helps users turn vague feature ideas into structured specs and executes them task-by-task. The tool operates within a self-contained execution loop without external dependencies, providing a seamless workflow for feature development. Named after the Ralph agentic loop pattern, Smart Ralph simplifies the development process by focusing on the next task at hand, akin to the simplicity of the Springfield student, Ralph.
botserver
General Bots is a self-hosted AI automation platform and LLM conversational platform focused on convention over configuration and code-less approaches. It serves as the core API server handling LLM orchestration, business logic, database operations, and multi-channel communication. The platform offers features like multi-vendor LLM API, MCP + LLM Tools Generation, Semantic Caching, Web Automation Engine, Enterprise Data Connectors, and Git-like Version Control. It enforces a ZERO TOLERANCE POLICY for code quality and security, with strict guidelines for error handling, performance optimization, and code patterns. The project structure includes modules for core functionalities like Rhai BASIC interpreter, security, shared types, tasks, auto task system, file operations, learning system, and LLM assistance.
stylekit
StyleKit is a comprehensive design system toolkit that helps both humans and AI generate consistent, high-quality UI code. It provides structured style specifications, design tokens, component recipes, prompt templates, and export tools — everything needed to go from 'I want a glassmorphism SaaS dashboard' to production-ready frontend code. With 90+ visual styles, 20+ page templates, 25+ UI components, and AI-powered tools like Prompt Builder, Smart Recommender, Style Linter, Style Analyzer, and Style Blender, StyleKit offers a platform with GitHub OAuth, ratings & comments, style submissions, instant community availability, favorites, bilingual support, PWA, and dark/light mode themes.
PAI
PAI is an open-source personal AI infrastructure designed to orchestrate personal and professional lives. It provides a scaffolding framework with real-world examples for life management, professional tasks, and personal goals. The core mission is to augment humans with AI capabilities to thrive in a world full of AI. PAI features UFC Context Architecture for persistent memory, specialized digital assistants for various tasks, an integrated tool ecosystem with MCP Servers, voice system, browser automation, and API integrations. The philosophy of PAI focuses on augmenting human capability rather than replacing it. The tool is MIT licensed and encourages contributions from the open-source community.
gigachad-grc
A comprehensive, modular, containerized Governance, Risk, and Compliance (GRC) platform built with modern technologies. Manage your entire security program from compliance tracking to risk management, third-party assessments, and external audits. The platform includes specialized modules for Compliance, Data Management, Risk Management, Third-Party Risk Management, Trust, Audit, Tools, AI & Automation, and Administration. It offers features like controls management, frameworks assessment, policies lifecycle management, vendor risk management, security questionnaires, knowledge base, audit management, awareness training, phishing simulations, AI-powered risk scoring, and MCP server integration. The tech stack includes Node.js, TypeScript, React, PostgreSQL, Keycloak, Traefik, Redis, and RustFS for storage.
multi-agent-ralph-loop
Multi-agent RALPH (Reinforcement Learning with Probabilistic Hierarchies) Loop is a framework for multi-agent reinforcement learning research. It provides a flexible and extensible platform for developing and testing multi-agent reinforcement learning algorithms. The framework supports various environments, including grid-world environments, and allows users to easily define custom environments. Multi-agent RALPH Loop is designed to facilitate research in the field of multi-agent reinforcement learning by providing a set of tools and utilities for experimenting with different algorithms and scenarios.
cc-sdd
The cc-sdd repository provides a tool for AI-Driven Development Life Cycle with Spec-Driven Development workflows for Claude Code and Gemini CLI. It includes powerful slash commands, Project Memory for AI learning, structured AI-DLC workflow, Spec-Driven Development methodology, and Kiro IDE compatibility. Ideal for feature development, code reviews, technical planning, and maintaining development standards. The tool supports multiple coding agents, offers an AI-DLC workflow with quality gates, and allows for advanced options like language and OS selection, preview changes, safe updates, and custom specs directory. It integrates AI-Driven Development Life Cycle, Project Memory, Spec-Driven Development, supports cross-platform usage, multi-language support, and safe updates with backup options.
For similar tasks

llm-compression-intelligence
This repository presents the findings of the paper "Compression Represents Intelligence Linearly". The study reveals a strong linear correlation between the intelligence of LLMs, as measured by benchmark scores, and their ability to compress external text corpora. Compression efficiency, derived from raw text corpora, serves as a reliable evaluation metric that is linearly associated with model capabilities. The repository includes the compression corpora used in the paper, code for computing compression efficiency, and data collection and processing pipelines.

edsl
The Expected Parrot Domain-Specific Language (EDSL) package enables users to conduct computational social science and market research with AI. It facilitates designing surveys and experiments, simulating responses using large language models, and performing data labeling and other research tasks. EDSL includes built-in methods for analyzing, visualizing, and sharing research results. It is compatible with Python 3.9 - 3.11 and requires API keys for LLMs stored in a `.env` file.

fast-stable-diffusion
Fast-stable-diffusion is a project that offers notebooks for RunPod, Paperspace, and Colab Pro adaptations with AUTOMATIC1111 Webui and Dreambooth. It provides tools for running and implementing Dreambooth, a stable diffusion project. The project includes implementations by XavierXiao and is sponsored by Runpod, Paperspace, and Colab Pro.

RobustVLM
This repository contains code for the paper 'Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models'. It focuses on fine-tuning CLIP in an unsupervised manner to enhance its robustness against visual adversarial attacks. By replacing the vision encoder of large vision-language models with the fine-tuned CLIP models, it achieves state-of-the-art adversarial robustness on various vision-language tasks. The repository provides adversarially fine-tuned ViT-L/14 CLIP models and offers insights into zero-shot classification settings and clean accuracy improvements.

TempCompass
TempCompass is a benchmark designed to evaluate the temporal perception ability of Video LLMs. It encompasses a diverse set of temporal aspects and task formats to comprehensively assess the capability of Video LLMs in understanding videos. The benchmark includes conflicting videos to prevent models from relying on single-frame bias and language priors. Users can clone the repository, install required packages, prepare data, run inference using examples like Video-LLaVA and Gemini, and evaluate the performance of their models across different tasks such as Multi-Choice QA, Yes/No QA, Caption Matching, and Caption Generation.

LLM-LieDetector
This repository contains code for reproducing experiments on lie detection in black-box LLMs by asking unrelated questions. It includes Q/A datasets, prompts, and fine-tuning datasets for generating lies with language models. The lie detectors rely on asking binary 'elicitation questions' to diagnose whether the model has lied. The code covers generating lies from language models, training and testing lie detectors, and generalization experiments. It requires access to GPUs and OpenAI API calls for running experiments with open-source models. Results are stored in the repository for reproducibility.

bigcodebench
BigCodeBench is an easy-to-use benchmark for code generation with practical and challenging programming tasks. It aims to evaluate the true programming capabilities of large language models (LLMs) in a more realistic setting. The benchmark is designed for HumanEval-like function-level code generation tasks, but with much more complex instructions and diverse function calls. BigCodeBench focuses on the evaluation of LLM4Code with diverse function calls and complex instructions, providing precise evaluation & ranking and pre-generated samples to accelerate code intelligence research. It inherits the design of the EvalPlus framework but differs in terms of execution environment and test evaluation.
rag
RAG with txtai is a Retrieval Augmented Generation (RAG) Streamlit application that helps generate factually correct content by limiting the context in which a Large Language Model (LLM) can generate answers. It supports two categories of RAG: Vector RAG, where context is supplied via a vector search query, and Graph RAG, where context is supplied via a graph path traversal query. The application allows users to run queries, add data to the index, and configure various parameters to control its behavior.
For similar jobs

Perplexica
Perplexica is an open-source AI-powered search engine that utilizes advanced machine learning algorithms to provide clear answers with sources cited. It offers various modes like Copilot Mode, Normal Mode, and Focus Modes for specific types of questions. Perplexica ensures up-to-date information by using SearxNG metasearch engine. It also features image and video search capabilities and upcoming features include finalizing Copilot Mode and adding Discover and History Saving features.

KULLM
KULLM (구름) is a Korean Large Language Model developed by Korea University NLP & AI Lab and HIAI Research Institute. It is based on the upstage/SOLAR-10.7B-v1.0 model and has been fine-tuned for instruction. The model has been trained on 8×A100 GPUs and is capable of generating responses in Korean language. KULLM exhibits hallucination and repetition phenomena due to its decoding strategy. Users should be cautious as the model may produce inaccurate or harmful results. Performance may vary in benchmarks without a fixed system prompt.

MMMU
MMMU is a benchmark designed to evaluate multimodal models on college-level subject knowledge tasks, covering 30 subjects and 183 subfields with 11.5K questions. It focuses on advanced perception and reasoning with domain-specific knowledge, challenging models to perform tasks akin to those faced by experts. The evaluation of various models highlights substantial challenges, with room for improvement to stimulate the community towards expert artificial general intelligence (AGI).

1filellm
1filellm is a command-line data aggregation tool designed for LLM ingestion. It aggregates and preprocesses data from various sources into a single text file, facilitating the creation of information-dense prompts for large language models. The tool supports automatic source type detection, handling of multiple file formats, web crawling functionality, integration with Sci-Hub for research paper downloads, text preprocessing, and token count reporting. Users can input local files, directories, GitHub repositories, pull requests, issues, ArXiv papers, YouTube transcripts, web pages, Sci-Hub papers via DOI or PMID. The tool provides uncompressed and compressed text outputs, with the uncompressed text automatically copied to the clipboard for easy pasting into LLMs.

gpt-researcher
GPT Researcher is an autonomous agent designed for comprehensive online research on a variety of tasks. It can produce detailed, factual, and unbiased research reports with customization options. The tool addresses issues of speed, determinism, and reliability by leveraging parallelized agent work. The main idea involves running 'planner' and 'execution' agents to generate research questions, seek related information, and create research reports. GPT Researcher optimizes costs and completes tasks in around 3 minutes. Features include generating long research reports, aggregating web sources, an easy-to-use web interface, scraping web sources, and exporting reports to various formats.

ChatTTS
ChatTTS is a generative speech model optimized for dialogue scenarios, providing natural and expressive speech synthesis with fine-grained control over prosodic features. It supports multiple speakers and surpasses most open-source TTS models in terms of prosody. The model is trained with 100,000+ hours of Chinese and English audio data, and the open-source version on HuggingFace is a 40,000-hour pre-trained model without SFT. The roadmap includes open-sourcing additional features like VQ encoder, multi-emotion control, and streaming audio generation. The tool is intended for academic and research use only, with precautions taken to limit potential misuse.

HebTTS
HebTTS is a language modeling approach to diacritic-free Hebrew text-to-speech (TTS) system. It addresses the challenge of accurately mapping text to speech in Hebrew by proposing a language model that operates on discrete speech representations and is conditioned on a word-piece tokenizer. The system is optimized using weakly supervised recordings and outperforms diacritic-based Hebrew TTS systems in terms of content preservation and naturalness of generated speech.

do-research-in-AI
This repository is a collection of research lectures and experience sharing posts from frontline researchers in the field of AI. It aims to help individuals upgrade their research skills and knowledge through insightful talks and experiences shared by experts. The content covers various topics such as evaluating research papers, choosing research directions, research methodologies, and tips for writing high-quality scientific papers. The repository also includes discussions on academic career paths, research ethics, and the emotional aspects of research work. Overall, it serves as a valuable resource for individuals interested in advancing their research capabilities in the field of AI.