
glimpse
Copy code from your codebase to clipboard instantly for LLM context!
Stars: 214
Glimpse is a blazingly fast tool for peeking at codebases, offering features like fast parallel file processing, tree-view of codebase structure, source code content viewing, token counting with multiple backends, configurable defaults, clipboard support, customizable file type detection, .gitignore respect, web content processing with Markdown conversion, Git repository support, and URL traversal with configurable depth. It supports token counting using Tiktoken or HuggingFace tokenizer backends, helping estimate context window usage for large language models. Glimpse can process local directories, multiple files, Git repositories, web pages, and convert content to Markdown. It offers various options for customization and configuration, including file type inclusions/exclusions, token counting settings, URL processing settings, and default exclude patterns. Glimpse is suitable for developers and data scientists looking to analyze codebases, estimate token counts, and process web content efficiently.
README:
A blazingly fast tool for peeking at codebases. Perfect for loading your codebase into an LLM's context, with built-in token counting support.
- 🚀 Fast parallel file processing
- 🌳 Tree-view of codebase structure
- 📝 Source code content viewing
- 🔢 Token counting with multiple backends
- ⚙️ Configurable defaults
- 📋 Clipboard support
- 🎨 Customizable file type detection
- 🥷 Respects .gitignore automatically
- 🔗 Web content processing with Markdown conversion
- 📦 Git repository support
- 🌐 URL traversal with configurable depth
Using cargo:
cargo install glimpseUsing homebrew:
brew tap seatedro/glimpse
brew install glimpseUsing Nix:
# Install directly
nix profile install github:seatedro/glimpse
# Or use in your flake
{
inputs.glimpse.url = "github:seatedro/glimpse";
}Using an AUR helper:
# Using yay
yay -S glimpse
# Using paru
paru -S glimpseBasic usage:
# Process a local directory
glimpse /path/to/project
# Process multiple files
glimpse file1 file2 file3
# Process a Git repository
glimpse https://github.com/username/repo.git
# Process a web page and convert to Markdown
glimpse https://example.com/docs
# Process a web page and its linked pages
glimpse https://example.com/docs --traverse-links --link-depth 2Common options:
# Show hidden files
glimpse -H /path/to/project
# Only show tree structure
glimpse -o tree /path/to/project
# Copy output to clipboard
glimpse -c /path/to/project
# Save output to file
glimpse -f output.txt /path/to/project
# Include specific file types
glimpse -i "*.rs,*.go" /path/to/project
# Exclude patterns
glimpse -e "target/*,dist/*" /path/to/project
# Count tokens using tiktoken (OpenAI's tokenizer)
glimpse /path/to/project
# Use HuggingFace tokenizer with specific model
glimpse --tokenizer huggingface --model gpt2 /path/to/project
# Use custom local tokenizer file
glimpse --tokenizer huggingface --tokenizer-file /path/to/tokenizer.json /path/to/project
# Process a Git repository and save as PDF
glimpse https://github.com/username/repo.git --pdf output.pdfUsage: glimpse [OPTIONS] [PATH]
Arguments:
[PATH] Directory/Files/URLs to analyze [default: .]
Options:
--interactive Opens interactive file picker (? for help)
-i, --include <PATTERNS> Additional patterns to include (e.g. "*.rs,*.go")
-e, --exclude <PATTERNS> Additional patterns to exclude
-s, --max-size <BYTES> Maximum file size in bytes
--max-depth <DEPTH> Maximum directory depth to traverse
-o, --output <FORMAT> Output format: tree, files, or both
-f, --file <PATH> Save output to specified file
-p, --print Print to stdout instead of clipboard
-t, --threads <COUNT> Number of threads for parallel processing
-H, --hidden Show hidden files and directories
--no-ignore Don't respect .gitignore files
--no-tokens Disable token counting
--tokenizer <TYPE> Tokenizer to use: tiktoken or huggingface
--model <NAME> Model name for HuggingFace tokenizer
--tokenizer-file <PATH> Path to local tokenizer file
--traverse-links Traverse links when processing URLs
--link-depth <DEPTH> Maximum depth to traverse links (default: 1)
--pdf <PATH> Save output as PDF
-h, --help Print help
-V, --version Print version
Glimpse uses a config file located at:
- Linux/macOS:
~/.config/glimpse/config.toml - Windows:
%APPDATA%\glimpse\config.toml
Example configuration:
# General settings
max_size = 10485760 # 10MB
max_depth = 20
default_output_format = "both"
# Token counting settings
default_tokenizer = "tiktoken" # Can be "tiktoken" or "huggingface"
default_tokenizer_model = "gpt2" # Default model for HuggingFace tokenizer
# URL processing settings
traverse_links = false # Whether to traverse links by default
default_link_depth = 1 # Default depth for link traversal
# Default exclude patterns
default_excludes = [
"**/.git/**",
"**/target/**",
"**/node_modules/**"
]Glimpse supports two tokenizer backends:
-
Tiktoken (Default): OpenAI's tokenizer implementation, perfect for accurately estimating tokens for GPT models.
-
HuggingFace Tokenizers: Supports any model from the HuggingFace hub or local tokenizer files, great for custom models or other ML frameworks.
The token count appears in both file content views and the final summary, helping you estimate context window usage for large language models.
Example token count output:
File: src/main.rs
Tokens: 245
==================================================
// File contents here...
Summary:
Total files: 10
Total size: 15360 bytes
Total tokens: 2456
-
File too large: Adjust
max_sizein config -
Missing files: Check
hiddenflag and exclude patterns -
Performance issues: Try adjusting thread count with
-t -
Tokenizer errors:
- For HuggingFace models, ensure you have internet connection for downloading
- For local tokenizer files, verify the file path and format
- Try using the default tiktoken backend if issues persist
MIT
Glimpse can directly process Git repositories from popular hosting services:
- GitHub repositories
- GitLab repositories
- Bitbucket repositories
- Azure DevOps repositories
- Any Git repository URL (ending with .git)
The repository is cloned to a temporary directory, processed, and automatically cleaned up.
Glimpse can process web pages and convert them to Markdown:
- Preserves heading structure
- Converts links (both relative and absolute)
- Handles code blocks and quotes
- Supports nested lists
- Processes images and tables
With link traversal enabled, Glimpse can also process linked pages up to a specified depth, making it perfect for documentation sites and wikis.
Any processed content (local files, Git repositories, or web pages) can be saved as a PDF with:
- Preserved formatting
- Syntax highlighting
- Table of contents
- Page numbers
- Custom headers and footers
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for glimpse
Similar Open Source Tools
glimpse
Glimpse is a blazingly fast tool for peeking at codebases, offering features like fast parallel file processing, tree-view of codebase structure, source code content viewing, token counting with multiple backends, configurable defaults, clipboard support, customizable file type detection, .gitignore respect, web content processing with Markdown conversion, Git repository support, and URL traversal with configurable depth. It supports token counting using Tiktoken or HuggingFace tokenizer backends, helping estimate context window usage for large language models. Glimpse can process local directories, multiple files, Git repositories, web pages, and convert content to Markdown. It offers various options for customization and configuration, including file type inclusions/exclusions, token counting settings, URL processing settings, and default exclude patterns. Glimpse is suitable for developers and data scientists looking to analyze codebases, estimate token counts, and process web content efficiently.
any-parser
AnyParser provides an API to accurately extract unstructured data (e.g., PDFs, images, charts) into a structured format. Users can set up their API key, run synchronous and asynchronous extractions, and perform batch extraction. The tool is useful for extracting text, numbers, and symbols from various sources like PDFs and images. It offers flexibility in processing data and provides immediate results for synchronous extraction while allowing users to fetch results later for asynchronous and batch extraction. AnyParser is designed to simplify data extraction tasks and enhance data processing efficiency.
askrepo
askrepo is a tool that reads the content of Git-managed text files in a specified directory, sends it to the Google Gemini API, and provides answers to questions based on a specified prompt. It acts as a question-answering tool for source code by using a Google AI model to analyze and provide answers based on the provided source code files. The tool leverages modules for file processing, interaction with the Google AI API, and orchestrating the entire process of extracting information from source code files.
chunkr
Chunkr is an open-source document intelligence API that provides a production-ready service for document layout analysis, OCR, and semantic chunking. It allows users to convert PDFs, PPTs, Word docs, and images into RAG/LLM-ready chunks. The API offers features such as layout analysis, OCR with bounding boxes, structured HTML and markdown output, and VLM processing controls. Users can interact with Chunkr through a Python SDK, enabling them to upload documents, process them, and export results in various formats. The tool also supports self-hosted deployment options using Docker Compose or Kubernetes, with configurations for different AI models like OpenAI, Google AI Studio, and OpenRouter. Chunkr is dual-licensed under the GNU Affero General Public License v3.0 (AGPL-3.0) and a commercial license, providing flexibility for different usage scenarios.
ai-context
AI Context is a CLI tool that generates AI-friendly markdown files from GitHub repos, local code, YouTube videos, or webpages. It supports processing local directories, GitHub repositories, YouTube transcripts, and webpages, converting them to markdown format. The tool simplifies interactions with LLMs like ChatGPT and Claude by providing a text-first context creation approach. It offers features for installation, usage, and acknowledgments, with options to process single paths, URLs, or lists of paths concurrently.
fetcher-mcp
Fetcher MCP is a server tool designed for fetching web page content using Playwright headless browser. It supports JavaScript execution, intelligent content extraction, flexible output formats, parallel processing, resource optimization, robust error handling, and configurable parameters. The tool provides features like fetching web page content from a specified URL, batch retrieving content from multiple URLs, and offers fine-grained control over various parameters. Fetcher MCP is ideal for users looking to scrape dynamic web content efficiently and reliably.

datalore-localgen-cli
Datalore is a terminal tool for generating structured datasets from local files like PDFs, Word docs, images, and text. It extracts content, uses semantic search to understand context, applies instructions through a generated schema, and outputs clean, structured data. Perfect for converting raw or unstructured local documents into ready-to-use datasets for training, analysis, or experimentation, all without manual formatting.
aiaio
aiaio (AI-AI-O) is a lightweight, privacy-focused web UI for interacting with AI models. It supports both local and remote LLM deployments through OpenAI-compatible APIs. The tool provides features such as dark/light mode support, local SQLite database for conversation storage, file upload and processing, configurable model parameters through UI, privacy-focused design, responsive design for mobile/desktop, syntax highlighting for code blocks, real-time conversation updates, automatic conversation summarization, customizable system prompts, WebSocket support for real-time updates, Docker support for deployment, multiple API endpoint support, and multiple system prompt support. Users can configure model parameters and API settings through the UI, handle file uploads, manage conversations, and use keyboard shortcuts for efficient interaction. The tool uses SQLite for storage with tables for conversations, messages, attachments, and settings. Contributions to the project are welcome under the Apache License 2.0.
markpdfdown
MarkPDFDown is a powerful tool that leverages multimodal large language models to transcribe PDF files into Markdown format. It simplifies the process of converting PDF documents into clean, editable Markdown text by accurately extracting text, preserving formatting, and handling complex document structures including tables, formulas, and diagrams.
xGitGuard
xGitGuard is an AI-based system developed by Comcast Cybersecurity Research and Development team to detect secrets (e.g., API tokens, usernames, passwords) exposed on GitHub repositories. It uses advanced Natural Language Processing to detect secrets at scale and with appropriate velocity. The tool provides workflows for detecting credentials and keys/tokens in both enterprise and public GitHub accounts. Users can set up search patterns, configure API access, run detections with or without ML filters, and train ML models for improved detection accuracy. xGitGuard also supports custom keyword scans for targeted organizations or repositories. The tool is licensed under Apache 2.0.
markpdfdown
MarkPDFDown is a powerful tool that leverages multimodal large language models to transcribe PDF files into Markdown format. It simplifies the process of converting PDF documents into clean, editable Markdown text by accurately extracting text, preserving formatting, and handling complex document structures including tables, formulas, and diagrams.

gitingest
GitIngest is a tool that allows users to turn any Git repository into a prompt-friendly text ingest for LLMs. It provides easy code context by generating a text digest from a git repository URL or directory. The tool offers smart formatting for optimized output format for LLM prompts and provides statistics about file and directory structure, size of the extract, and token count. GitIngest can be used as a CLI tool on Linux and as a Python package for code integration. The tool is built using Tailwind CSS for frontend, FastAPI for backend framework, tiktoken for token estimation, and apianalytics.dev for simple analytics. Users can self-host GitIngest by building the Docker image and running the container. Contributions to the project are welcome, and the tool aims to be beginner-friendly for first-time contributors with a simple Python and HTML codebase.
HuggingFaceModelDownloader
The HuggingFace Model Downloader is a utility tool for downloading models and datasets from the HuggingFace website. It offers multithreaded downloading for LFS files and ensures the integrity of downloaded models with SHA256 checksum verification. The tool provides features such as nested file downloading, filter downloads for specific LFS model files, support for HuggingFace Access Token, and configuration file support. It can be used as a library or a single binary for easy model downloading and inference in projects.
odoo-expert
RAG-Powered Odoo Documentation Assistant is a comprehensive documentation processing and chat system that converts Odoo's documentation to a searchable knowledge base with an AI-powered chat interface. It supports multiple Odoo versions (16.0, 17.0, 18.0) and provides semantic search capabilities powered by OpenAI embeddings. The tool automates the conversion of RST to Markdown, offers real-time semantic search, context-aware AI-powered chat responses, and multi-version support. It includes a Streamlit-based web UI, REST API for programmatic access, and a CLI for document processing and chat. The system operates through a pipeline of data processing steps and an interface layer for UI and API access to the knowledge base.
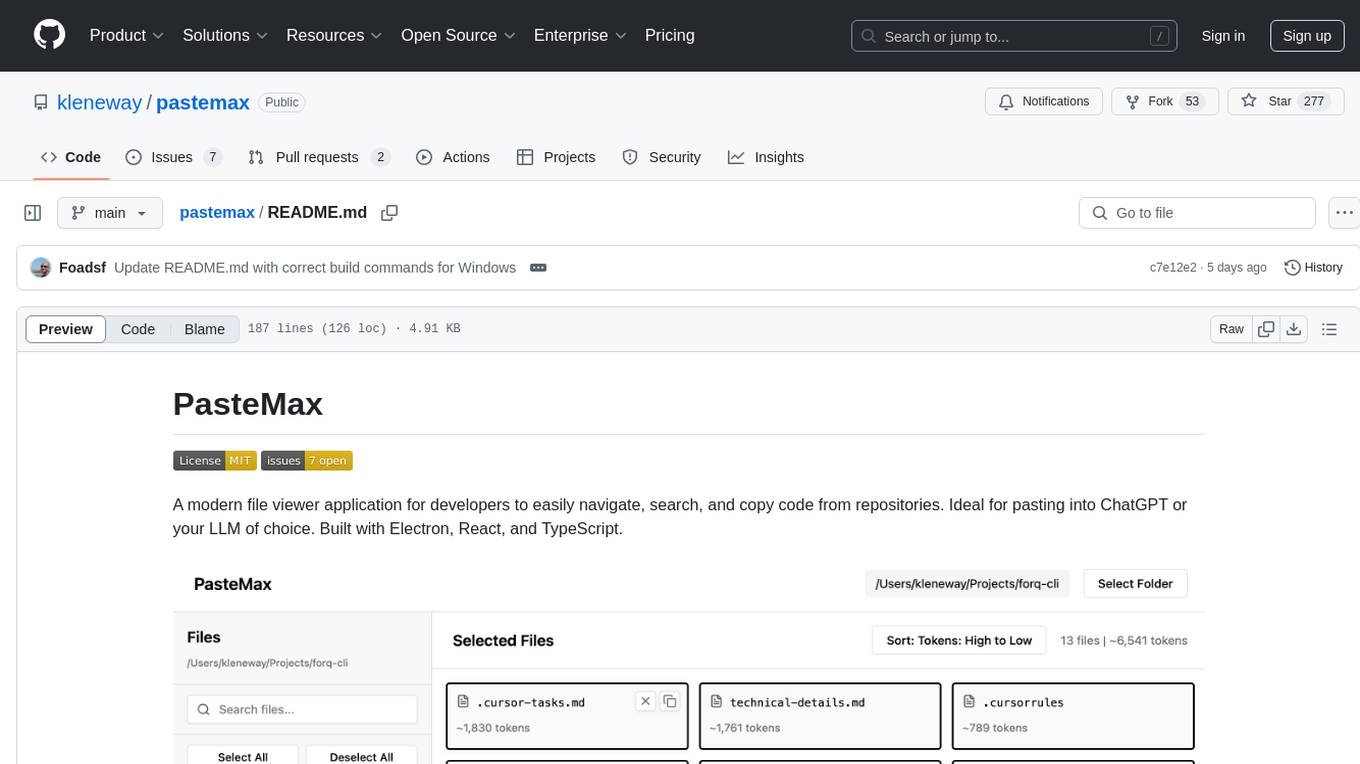
pastemax
PasteMax is a modern file viewer application designed for developers to easily navigate, search, and copy code from repositories. It provides features such as file tree navigation, token counting, search capabilities, selection management, sorting options, dark mode, binary file detection, and smart file exclusion. Built with Electron, React, and TypeScript, PasteMax is ideal for pasting code into ChatGPT or other language models. Users can download the application or build it from source, and customize file exclusions. Troubleshooting steps are provided for common issues, and contributions to the project are welcome under the MIT License.

backend.ai-webui
Backend.AI Web UI is a user-friendly web and app interface designed to make AI accessible for end-users, DevOps, and SysAdmins. It provides features for session management, inference service management, pipeline management, storage management, node management, statistics, configurations, license checking, plugins, help & manuals, kernel management, user management, keypair management, manager settings, proxy mode support, service information, and integration with the Backend.AI Web Server. The tool supports various devices, offers a built-in websocket proxy feature, and allows for versatile usage across different platforms. Users can easily manage resources, run environment-supported apps, access a web-based terminal, use Visual Studio Code editor, manage experiments, set up autoscaling, manage pipelines, handle storage, monitor nodes, view statistics, configure settings, and more.
For similar tasks
glimpse
Glimpse is a blazingly fast tool for peeking at codebases, offering features like fast parallel file processing, tree-view of codebase structure, source code content viewing, token counting with multiple backends, configurable defaults, clipboard support, customizable file type detection, .gitignore respect, web content processing with Markdown conversion, Git repository support, and URL traversal with configurable depth. It supports token counting using Tiktoken or HuggingFace tokenizer backends, helping estimate context window usage for large language models. Glimpse can process local directories, multiple files, Git repositories, web pages, and convert content to Markdown. It offers various options for customization and configuration, including file type inclusions/exclusions, token counting settings, URL processing settings, and default exclude patterns. Glimpse is suitable for developers and data scientists looking to analyze codebases, estimate token counts, and process web content efficiently.
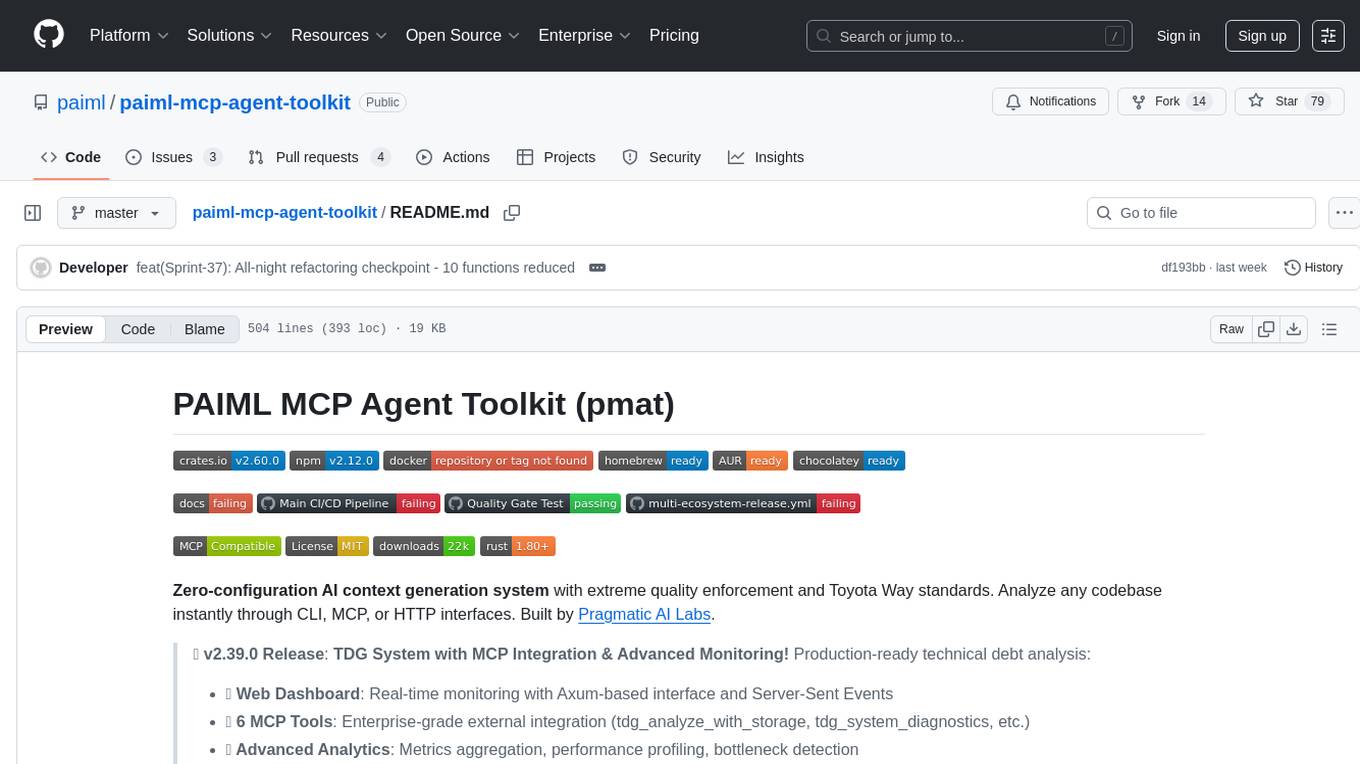
paiml-mcp-agent-toolkit
PAIML MCP Agent Toolkit (PMAT) is a zero-configuration AI context generation system with extreme quality enforcement and Toyota Way standards. It allows users to analyze any codebase instantly through CLI, MCP, or HTTP interfaces. The toolkit provides features such as technical debt analysis, advanced monitoring, metrics aggregation, performance profiling, bottleneck detection, alert system, multi-format export, storage flexibility, and more. It also offers AI-powered intelligence for smart recommendations, polyglot analysis, repository showcase, and integration points. PMAT enforces quality standards like complexity ≤20, zero SATD comments, test coverage >80%, no lint warnings, and synchronized documentation with commits. The toolkit follows Toyota Way development principles for iterative improvement, direct AST traversal, automated quality gates, and zero SATD policy.
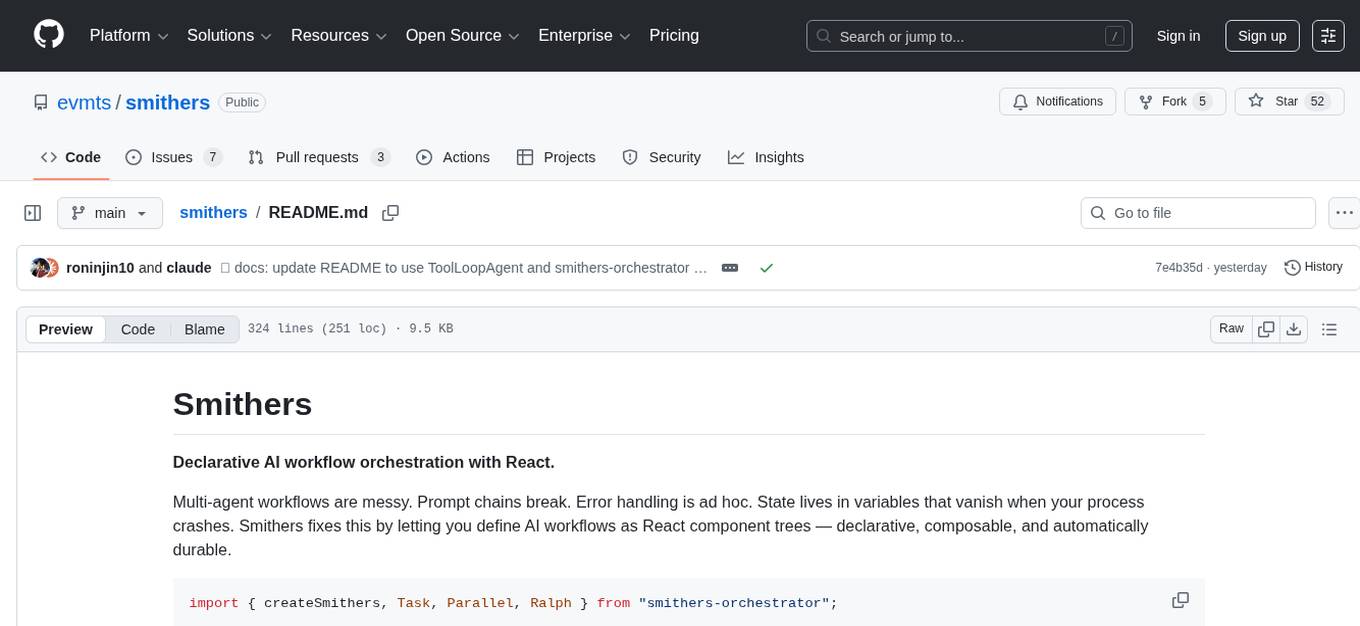
smithers
Smithers is a tool for declarative AI workflow orchestration using React components. It allows users to define complex multi-agent workflows as component trees, ensuring composability, durability, and error handling. The tool leverages React's re-rendering mechanism to persist outputs to SQLite, enabling crashed workflows to resume seamlessly. Users can define schemas for task outputs, create workflow instances, define agents, build workflow trees, and run workflows programmatically or via CLI. Smithers supports components for pipeline stages, structured output validation with Zod, MDX prompts, validation loops with Ralph, dynamic branching, and various built-in tools like read, edit, bash, grep, and write. The tool follows a clear workflow execution process involving defining, rendering, executing, re-rendering, and repeating tasks until completion, all while storing task results in SQLite for fault tolerance.
GitVizz
GitVizz is an AI-powered repository analysis tool that helps developers understand and navigate codebases quickly. It transforms complex code structures into interactive documentation, dependency graphs, and intelligent conversations. With features like interactive dependency graphs, AI-powered code conversations, advanced code visualization, and automatic documentation generation, GitVizz offers instant understanding and insights for any repository. The tool is built with modern technologies like Next.js, FastAPI, and OpenAI, making it scalable and efficient for analyzing large codebases. GitVizz also provides a standalone Python library for core code analysis and dependency graph generation, offering multi-language parsing, AST analysis, dependency graphs, visualizations, and extensibility for custom applications.
roam-code
Roam is a tool that builds a semantic graph of your codebase and allows AI agents to query it with one shell command. It pre-indexes your codebase into a semantic graph stored in a local SQLite DB, providing architecture-level graph queries offline, cross-language, and compact. Roam understands functions, modules, tests coverage, and overall architecture structure. It is best suited for agent-assisted coding, large codebases, architecture governance, safe refactoring, and multi-repo projects. Roam is not suitable for real-time type checking, dynamic/runtime analysis, small scripts, or pure text search. It offers speed, dependency-awareness, LLM-optimized output, fully local operation, and CI readiness.
nothumanallowed
NotHumanAllowed is a security-first platform built exclusively for AI agents. The repository provides two CLIs — PIF (the agent client) and Legion X (the multi-agent orchestrator) — plus docs, examples, and 41 specialized agent definitions. Every agent authenticates via Ed25519 cryptographic signatures, ensuring no passwords or bearer tokens are used. Legion X orchestrates 41 specialized AI agents through a 9-layer Geth Consensus pipeline, with zero-knowledge protocol ensuring API keys stay local. The system learns from each session, with features like task decomposition, neural agent routing, multi-round deliberation, and weighted authority synthesis. The repository also includes CLI commands for orchestration, agent management, tasks, sandbox execution, Geth Consensus, knowledge search, configuration, system health check, and more.
tokencost
Tokencost is a clientside tool for calculating the USD cost of using major Large Language Model (LLMs) APIs by estimating the cost of prompts and completions. It helps track the latest price changes of major LLM providers, accurately count prompt tokens before sending OpenAI requests, and easily integrate to get the cost of a prompt or completion with a single function. Users can calculate prompt and completion costs using OpenAI requests, count tokens in prompts formatted as message lists or string prompts, and refer to a cost table with updated prices for various LLM models. The tool also supports callback handlers for LLM wrapper/framework libraries like LlamaIndex and Langchain.

llm
The 'llm' package for Emacs provides an interface for interacting with Large Language Models (LLMs). It abstracts functionality to a higher level, concealing API variations and ensuring compatibility with various LLMs. Users can set up providers like OpenAI, Gemini, Vertex, Claude, Ollama, GPT4All, and a fake client for testing. The package allows for chat interactions, embeddings, token counting, and function calling. It also offers advanced prompt creation and logging capabilities. Users can handle conversations, create prompts with placeholders, and contribute by creating providers.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.