
markpdfdown
A high-quality PDF to Markdown tool based on large language model visual recognition. 一款基于大模型视觉识别的高质量PDF转Markdown工具
Stars: 661
MarkPDFDown is a powerful tool that leverages multimodal large language models to transcribe PDF files into Markdown format. It simplifies the process of converting PDF documents into clean, editable Markdown text by accurately extracting text, preserving formatting, and handling complex document structures including tables, formulas, and diagrams.
README:
English | 中文




A powerful tool that leverages multimodal large language models to transcribe PDF files into Markdown format.

MarkPDFDown is designed to simplify the process of converting PDF documents into clean, editable Markdown text. By utilizing advanced multimodal AI models, it can accurately extract text, preserve formatting, and handle complex document structures including tables, formulas, and diagrams.
- PDF to Markdown Conversion: Transform any PDF document into well-formatted Markdown
- Image to Markdown Conversion: Transform image into well-formatted Markdown
- Multimodal Understanding: Leverages AI to comprehend document structure and content
- Format Preservation: Maintains headings, lists, tables, and other formatting elements
- Customizable Model: Configure the model to suit your needs

conda create -n markpdfdown python=3.9
conda activate markpdfdown
# Clone the repository
git clone https://github.com/MarkPDFdown/markpdfdown.git
cd markpdfdown
# Install dependencies
pip install -r requirements.txt
# Set up your OpenAI API key
export OPENAI_API_KEY=<your-api-key>
# Optionally, set up your OpenAI API base
export OPENAI_API_BASE=<your-api-base>
# Optionally, set up your OpenAI API model
export OPENAI_DEFAULT_MODEL=<your-model>
# pdf to markdown
python main.py < tests/input.pdf > output.md
# image to markdown
python main.py < input_image.png > output.mdpython main.py page_start page_end < tests/input.pdf > output.mddocker run -i -e OPENAI_API_KEY=<your-api-key> -e OPENAI_API_BASE=<your-api-base> -e OPENAI_DEFAULT_MODEL=<your-model> jorbenzhu/markpdfdown < input.pdf > output.md- Python 3.9+
- Dependencies listed in
requirements.txt - Access to the specified multimodal AI model
Contributions are welcome! Please feel free to submit a Pull Request.
- Fork the repository
- Create your feature branch (
git checkout -b feature/amazing-feature) - Commit your changes (
git commit -m 'feat: Add some amazing feature') - Push to the branch (
git push origin feature/amazing-feature) - Open a Pull Request
This project is licensed under the Apache License 2.0. See the LICENSE file for details.
- Thanks to the developers of the multimodal AI models that power this tool
- Inspired by the need for better PDF to Markdown conversion tools
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for markpdfdown
Similar Open Source Tools
markpdfdown
MarkPDFDown is a powerful tool that leverages multimodal large language models to transcribe PDF files into Markdown format. It simplifies the process of converting PDF documents into clean, editable Markdown text by accurately extracting text, preserving formatting, and handling complex document structures including tables, formulas, and diagrams.
markpdfdown
MarkPDFDown is a powerful tool that leverages multimodal large language models to transcribe PDF files into Markdown format. It simplifies the process of converting PDF documents into clean, editable Markdown text by accurately extracting text, preserving formatting, and handling complex document structures including tables, formulas, and diagrams.
chunkr
Chunkr is an open-source document intelligence API that provides a production-ready service for document layout analysis, OCR, and semantic chunking. It allows users to convert PDFs, PPTs, Word docs, and images into RAG/LLM-ready chunks. The API offers features such as layout analysis, OCR with bounding boxes, structured HTML and markdown output, and VLM processing controls. Users can interact with Chunkr through a Python SDK, enabling them to upload documents, process them, and export results in various formats. The tool also supports self-hosted deployment options using Docker Compose or Kubernetes, with configurations for different AI models like OpenAI, Google AI Studio, and OpenRouter. Chunkr is dual-licensed under the GNU Affero General Public License v3.0 (AGPL-3.0) and a commercial license, providing flexibility for different usage scenarios.

MegaParse
MegaParse is a powerful and versatile parser designed to handle various types of documents such as text, PDFs, Powerpoint presentations, and Word documents with no information loss. It is fast, efficient, and open source, supporting a wide range of file formats. MegaParse ensures compatibility with tables, table of contents, headers, footers, and images, making it a comprehensive solution for document parsing.

easy-dataset
Easy Dataset is a specialized application designed to streamline the creation of fine-tuning datasets for Large Language Models (LLMs). It offers an intuitive interface for uploading domain-specific files, intelligently splitting content, generating questions, and producing high-quality training data for model fine-tuning. With Easy Dataset, users can transform domain knowledge into structured datasets compatible with all OpenAI-format compatible LLM APIs, making the fine-tuning process accessible and efficient.

mmore
MMORE is an open-source, end-to-end pipeline for ingesting, processing, indexing, and retrieving knowledge from various file types such as PDFs, Office docs, images, audio, video, and web pages. It standardizes content into a unified multimodal format, supports distributed CPU/GPU processing, and offers hybrid dense+sparse retrieval with an integrated RAG service through CLI and APIs.
FileScopeMCP
FileScopeMCP is a TypeScript-based tool for ranking files in a codebase by importance, tracking dependencies, and providing summaries. It analyzes code structure, generates importance scores, maps bidirectional dependencies, visualizes file relationships, and allows adding custom summaries. The tool supports multiple languages, persistent storage, and offers tools for file tree management, file analysis, file summaries, diagram generation, and file watching. It is built with TypeScript/Node.js, implements the Model Context Protocol, uses Mermaid.js for diagram generation, and stores data in JSON format. FileScopeMCP aims to enhance code understanding and visualization for developers.

code2prompt
Code2Prompt is a powerful command-line tool that generates comprehensive prompts from codebases, designed to streamline interactions between developers and Large Language Models (LLMs) for code analysis, documentation, and improvement tasks. It bridges the gap between codebases and LLMs by converting projects into AI-friendly prompts, enabling users to leverage AI for various software development tasks. The tool offers features like holistic codebase representation, intelligent source tree generation, customizable prompt templates, smart token management, Gitignore integration, flexible file handling, clipboard-ready output, multiple output options, and enhanced code readability.
any-parser
AnyParser provides an API to accurately extract unstructured data (e.g., PDFs, images, charts) into a structured format. Users can set up their API key, run synchronous and asynchronous extractions, and perform batch extraction. The tool is useful for extracting text, numbers, and symbols from various sources like PDFs and images. It offers flexibility in processing data and provides immediate results for synchronous extraction while allowing users to fetch results later for asynchronous and batch extraction. AnyParser is designed to simplify data extraction tasks and enhance data processing efficiency.
llm_aided_ocr
The LLM-Aided OCR Project is an advanced system that enhances Optical Character Recognition (OCR) output by leveraging natural language processing techniques and large language models. It offers features like PDF to image conversion, OCR using Tesseract, error correction using LLMs, smart text chunking, markdown formatting, duplicate content removal, quality assessment, support for local and cloud-based LLMs, asynchronous processing, detailed logging, and GPU acceleration. The project provides detailed technical overview, text processing pipeline, LLM integration, token management, quality assessment, logging, configuration, and customization. It requires Python 3.12+, Tesseract OCR engine, PDF2Image library, PyTesseract, and optional OpenAI or Anthropic API support for cloud-based LLMs. The installation process involves setting up the project, installing dependencies, and configuring environment variables. Users can place a PDF file in the project directory, update input file path, and run the script to generate post-processed text. The project optimizes processing with concurrent processing, context preservation, and adaptive token management. Configuration settings include choosing between local or API-based LLMs, selecting API provider, specifying models, and setting context size for local LLMs. Output files include raw OCR output and LLM-corrected text. Limitations include performance dependency on LLM quality and time-consuming processing for large documents.
youtube_summarizer
YouTube AI Summarizer is a modern Next.js-based tool for AI-powered YouTube video summarization. It allows users to generate concise summaries of YouTube videos using various AI models, with support for multiple languages and summary styles. The application features flexible API key requirements, multilingual support, flexible summary modes, a smart history system, modern UI/UX design, and more. Users can easily input a YouTube URL, select language, summary type, and AI model, and generate summaries with real-time progress tracking. The tool offers a clean, well-structured summary view, history dashboard, and detailed history view for past summaries. It also provides configuration options for API keys and database setup, along with technical highlights, performance improvements, and a modern tech stack.
glimpse
Glimpse is a blazingly fast tool for peeking at codebases, offering features like fast parallel file processing, tree-view of codebase structure, source code content viewing, token counting with multiple backends, configurable defaults, clipboard support, customizable file type detection, .gitignore respect, web content processing with Markdown conversion, Git repository support, and URL traversal with configurable depth. It supports token counting using Tiktoken or HuggingFace tokenizer backends, helping estimate context window usage for large language models. Glimpse can process local directories, multiple files, Git repositories, web pages, and convert content to Markdown. It offers various options for customization and configuration, including file type inclusions/exclusions, token counting settings, URL processing settings, and default exclude patterns. Glimpse is suitable for developers and data scientists looking to analyze codebases, estimate token counts, and process web content efficiently.
panda-etl
PandaETL is an open-source, no-code ETL tool designed to extract and parse data from various document types including PDFs, emails, websites, audio files, and more. With an intuitive interface and powerful backend, PandaETL simplifies the process of data extraction and transformation, making it accessible to users without programming skills.

llama-cpp-agent
The llama-cpp-agent framework is a tool designed for easy interaction with Large Language Models (LLMs). Allowing users to chat with LLM models, execute structured function calls and get structured output (objects). It provides a simple yet robust interface and supports llama-cpp-python and OpenAI endpoints with GBNF grammar support (like the llama-cpp-python server) and the llama.cpp backend server. It works by generating a formal GGML-BNF grammar of the user defined structures and functions, which is then used by llama.cpp to generate text valid to that grammar. In contrast to most GBNF grammar generators it also supports nested objects, dictionaries, enums and lists of them.
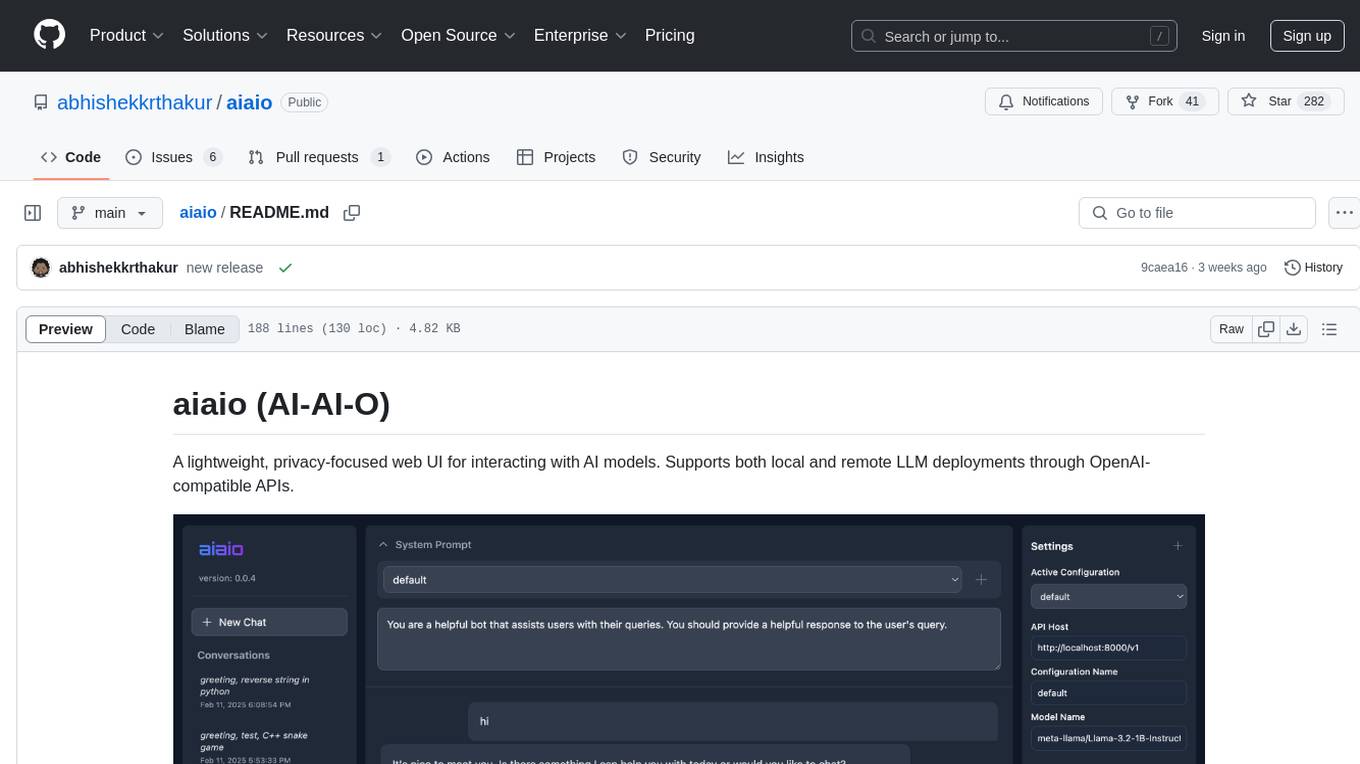
aiaio
aiaio (AI-AI-O) is a lightweight, privacy-focused web UI for interacting with AI models. It supports both local and remote LLM deployments through OpenAI-compatible APIs. The tool provides features such as dark/light mode support, local SQLite database for conversation storage, file upload and processing, configurable model parameters through UI, privacy-focused design, responsive design for mobile/desktop, syntax highlighting for code blocks, real-time conversation updates, automatic conversation summarization, customizable system prompts, WebSocket support for real-time updates, Docker support for deployment, multiple API endpoint support, and multiple system prompt support. Users can configure model parameters and API settings through the UI, handle file uploads, manage conversations, and use keyboard shortcuts for efficient interaction. The tool uses SQLite for storage with tables for conversations, messages, attachments, and settings. Contributions to the project are welcome under the Apache License 2.0.
ai-context
AI Context is a CLI tool that generates AI-friendly markdown files from GitHub repos, local code, YouTube videos, or webpages. It supports processing local directories, GitHub repositories, YouTube transcripts, and webpages, converting them to markdown format. The tool simplifies interactions with LLMs like ChatGPT and Claude by providing a text-first context creation approach. It offers features for installation, usage, and acknowledgments, with options to process single paths, URLs, or lists of paths concurrently.
For similar tasks

vision-parse
Vision Parse is a tool that leverages Vision Language Models to parse PDF documents into beautifully formatted markdown content. It offers smart content extraction, content formatting, multi-LLM support, PDF document support, and local model hosting using Ollama. Users can easily convert PDFs to markdown with high precision and preserve document hierarchy and styling. The tool supports multiple Vision LLM providers like OpenAI, LLama, and Gemini for accuracy and speed, making document processing efficient and effortless.
markpdfdown
MarkPDFDown is a powerful tool that leverages multimodal large language models to transcribe PDF files into Markdown format. It simplifies the process of converting PDF documents into clean, editable Markdown text by accurately extracting text, preserving formatting, and handling complex document structures including tables, formulas, and diagrams.
MegaParse
MegaParse is a powerful and versatile parser designed to handle various types of documents such as text, PDFs, Powerpoint presentations, and Word documents with no information loss. It is fast, efficient, and open source, supporting a wide range of file formats. MegaParse ensures compatibility with tables, table of contents, headers, footers, and images, making it a comprehensive solution for document parsing.
NekoImageGallery
NekoImageGallery is an online AI image search engine that utilizes the Clip model and Qdrant vector database. It supports keyword search and similar image search. The tool generates 768-dimensional vectors for each image using the Clip model, supports OCR text search using PaddleOCR, and efficiently searches vectors using the Qdrant vector database. Users can deploy the tool locally or via Docker, with options for metadata storage using Qdrant database or local file storage. The tool provides API documentation through FastAPI's built-in Swagger UI and can be used for tasks like image search, text extraction, and vector search.
gemini_multipdf_chat
Gemini PDF Chatbot is a Streamlit-based application that allows users to chat with a conversational AI model trained on PDF documents. The chatbot extracts information from uploaded PDF files and answers user questions based on the provided context. It features PDF upload, text extraction, conversational AI using the Gemini model, and a chat interface. Users can deploy the application locally or to the cloud, and the project structure includes main application script, environment variable file, requirements, and documentation. Dependencies include PyPDF2, langchain, Streamlit, google.generativeai, and dotenv.
screen-pipe
Screen-pipe is a Rust + WASM tool that allows users to turn their screen into actions using Large Language Models (LLMs). It enables users to record their screen 24/7, extract text from frames, and process text and images for tasks like analyzing sales conversations. The tool is still experimental and aims to simplify the process of recording screens, extracting text, and integrating with various APIs for tasks such as filling CRM data based on screen activities. The project is open-source and welcomes contributions to enhance its functionalities and usability.
whisper
Whisper is an open-source library by Open AI that converts/extracts text from audio. It is a cross-platform tool that supports real-time transcription of various types of audio/video without manual conversion to WAV format. The library is designed to run on Linux and Android platforms, with plans for expansion to other platforms. Whisper utilizes three frameworks to function: DART for CLI execution, Flutter for mobile app integration, and web/WASM for web application deployment. The tool aims to provide a flexible and easy-to-use solution for transcription tasks across different programs and platforms.
swift-ocr-llm-powered-pdf-to-markdown
Swift OCR is a powerful tool for extracting text from PDF files using OpenAI's GPT-4 Turbo with Vision model. It offers flexible input options, advanced OCR processing, performance optimizations, structured output, robust error handling, and scalable architecture. The tool ensures accurate text extraction, resilience against failures, and efficient handling of multiple requests.
For similar jobs

asreview
The ASReview project implements active learning for systematic reviews, utilizing AI-aided pipelines to assist in finding relevant texts for search tasks. It accelerates the screening of textual data with minimal human input, saving time and increasing output quality. The software offers three modes: Oracle for interactive screening, Exploration for teaching purposes, and Simulation for evaluating active learning models. ASReview LAB is designed to support decision-making in any discipline or industry by improving efficiency and transparency in screening large amounts of textual data.
NewEraAI-Papers
The NewEraAI-Papers repository provides links to collections of influential and interesting research papers from top AI conferences, along with open-source code to promote reproducibility and provide detailed implementation insights beyond the scope of the article. Users can stay up to date with the latest advances in AI research by exploring this repository. Contributions to improve the completeness of the list are welcomed, and users can create pull requests, open issues, or contact the repository owner via email to enhance the repository further.
cltk
The Classical Language Toolkit (CLTK) is a Python library that provides natural language processing (NLP) capabilities for pre-modern languages. It offers a modular processing pipeline with pre-configured defaults and supports almost 20 languages. Users can install the latest version using pip and access detailed documentation on the official website. The toolkit is designed to meet the unique needs of researchers working with historical languages, filling a void in the NLP landscape that often neglects non-spoken languages and different research goals.
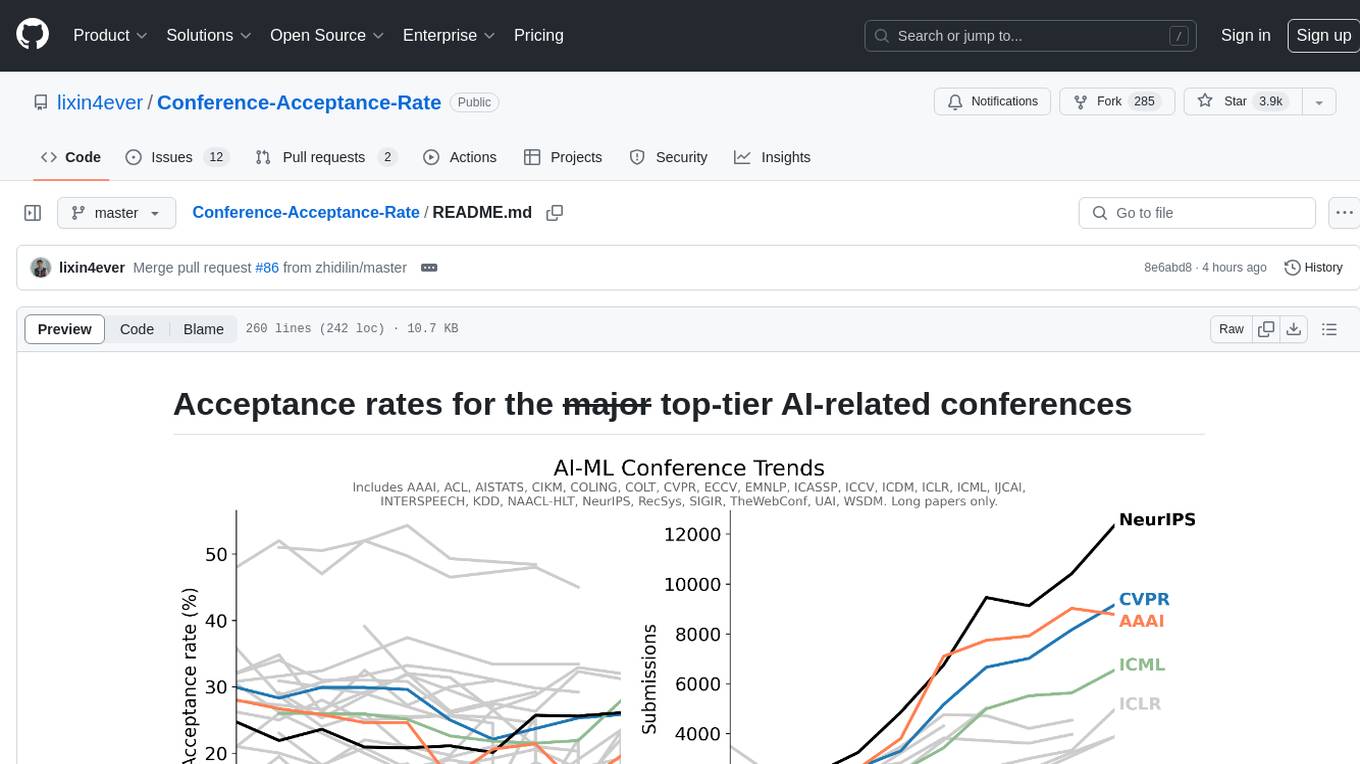
Conference-Acceptance-Rate
The 'Conference-Acceptance-Rate' repository provides acceptance rates for top-tier AI-related conferences in the fields of Natural Language Processing, Computational Linguistics, Computer Vision, Pattern Recognition, Machine Learning, Learning Theory, Artificial Intelligence, Data Mining, Information Retrieval, Speech Processing, and Signal Processing. The data includes acceptance rates for long papers and short papers over several years for each conference, allowing researchers to track trends and make informed decisions about where to submit their work.
pdftochat
PDFToChat is a tool that allows users to chat with their PDF documents in seconds. It is powered by Together AI and Pinecone, utilizing a tech stack including Next.js, Mixtral, M2 Bert, LangChain.js, MongoDB Atlas, Bytescale, Vercel, Clerk, and Tailwind CSS. Users can deploy the tool to Vercel or any other host by setting up Together.ai, MongoDB Atlas database, Bytescale, Clerk, and Vercel. The tool enables users to interact with PDFs through chat, with future tasks including adding features like trash icon for deleting PDFs, exploring different embedding models, implementing auto scrolling, improving replies, benchmarking accuracy, researching chunking and retrieval best practices, adding demo video, upgrading to Next.js 14, adding analytics, customizing tailwind prose, saving chats in postgres DB, compressing large PDFs, implementing custom uploader, session tracking, error handling, and support for images in PDFs.

tods-arxiv-daily-paper
This repository provides a tool for fetching and summarizing daily papers from the arXiv repository. It allows users to stay updated with the latest research in various fields by automatically retrieving and summarizing papers on a daily basis. The tool simplifies the process of accessing and digesting academic papers, making it easier for researchers and enthusiasts to keep track of new developments in their areas of interest.
Awesome-LLM-Strawberry
Awesome LLM Strawberry is a collection of research papers and blogs related to OpenAI Strawberry(o1) and Reasoning. The repository is continuously updated to track the frontier of LLM Reasoning.
Call-for-Reviewers
The `Call-for-Reviewers` repository aims to collect the latest 'call for reviewers' links from various top CS/ML/AI conferences/journals. It provides an opportunity for individuals in the computer/ machine learning/ artificial intelligence fields to gain review experience for applying for NIW/H1B/EB1 or enhancing their CV. The repository helps users stay updated with the latest research trends and engage with the academic community.