
linghe
A high-performance kernel library for LLM training
Stars: 60
A library of high-performance kernels for LLM training, linghe is designed for MoE training with FP8 quantization. It provides fused quantization kernels, memory-efficiency kernels, and implementation-optimized kernels. The repo benchmarks on H800 with specific configurations and offers examples in tests. Users can refer to the API for more details.
README:

A library of high-performance kernels for LLM training.
- Support more shapes and various GPU archs.
- Release our fp8 training kernels beyond blockwise quantization.
- [2025/07] We implement multiple kernels for FP8 training with
Megatron-LMblockwise quantization.
Our repo, linghe, is designed for LLM training, especially for MoE training with FP8 quantizaiton. It provides 3 main categories of kernels:
- Fused quantization kernels: fuse quantization with previous layer, e.g., RMS norm and Silu.
- Memory-efficiency kernels: fuse multiple IO-itensive operations, e.g., ROPE with qk-norm.
- Implementation-optimized kernels: use efficient triton implementation, e.g., routing map padding instead of activation padding.
We benchmark on H800 with batch size 8192, hidden size 2048, num experts 256, activation experts 8.
| kernel | baseline(us) | linghe(us) | speedup |
|---|---|---|---|
| RMSNorm+Quantization(forward) | 159.3 us | 72.4 us | 2.2 |
| Split+qk-norm+rope+transpose(forward) | 472 us | 59.1 us | 7.99 |
| Split+qk-norm+rope+transpose(backward) | 645 us | 107.5 us | 6.0 |
| Fp32 router gemm(forward) | 242.3 us | 61.6 us | 3.931 |
| Fp32 router gemm(backward) | 232.7 us | 78.1 us | 2.979 |
| Permute with padded indices | 388 us | 229.4 us | 1.69 |
| Unpermute with padding indices | 988.6 us | 806.9 us | 1.23 |
| Batch Silu+quantization(forward) | 6241.7 us | 1181.7 us | 5.28 |
| Batch Silu+quantization(backward) | 7147.7 us | 2317.9 us | 3.08 |
| Silu+quantization(forward) | 144.9 us | 58.2 us | 2.48 |
| Silu+quantization(backward) | 163.4 us | 74.2 us | 2.2 |
| fused linear gate(forward) | 160.4 us | 46.9 us | 3.42 |
| fused linear gate(backward) | 572.9 us | 81.1 us | 7.06 |
| Cross entropy(forward) | 2780.8 us | 818.2 us | 3.4 |
| Cross entropy(backward) | 7086.3 us | 1781.0 us | 3.98 |
| batch grad norm | 1733.7 us | 1413.7 us | 1.23 |
| Batch count zero | 4997.9 us | 746.8 us | 6.69 |
Other benchmark results can be obtained by running scripts in tests and benchmark folders.
Examples can be found in tests.
Please refer to API
[TBD]
@misc{zhao2025linghe,
title={Linghe: Enabling Efficient Trillion-Scale LLM Training via Optimized Kernels},
author={Yao Zhao and Chen Liang and Jingyu Hu and Zixuan Cheng and Longfei Li}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for linghe
Similar Open Source Tools
linghe
A library of high-performance kernels for LLM training, linghe is designed for MoE training with FP8 quantization. It provides fused quantization kernels, memory-efficiency kernels, and implementation-optimized kernels. The repo benchmarks on H800 with specific configurations and offers examples in tests. Users can refer to the API for more details.

nntrainer
NNtrainer is a software framework for training neural network models on devices with limited resources. It enables on-device fine-tuning of neural networks using user data for personalization. NNtrainer supports various machine learning algorithms and provides examples for tasks such as few-shot learning, ResNet, VGG, and product rating. It is optimized for embedded devices and utilizes CBLAS and CUBLAS for accelerated calculations. NNtrainer is open source and released under the Apache License version 2.0.
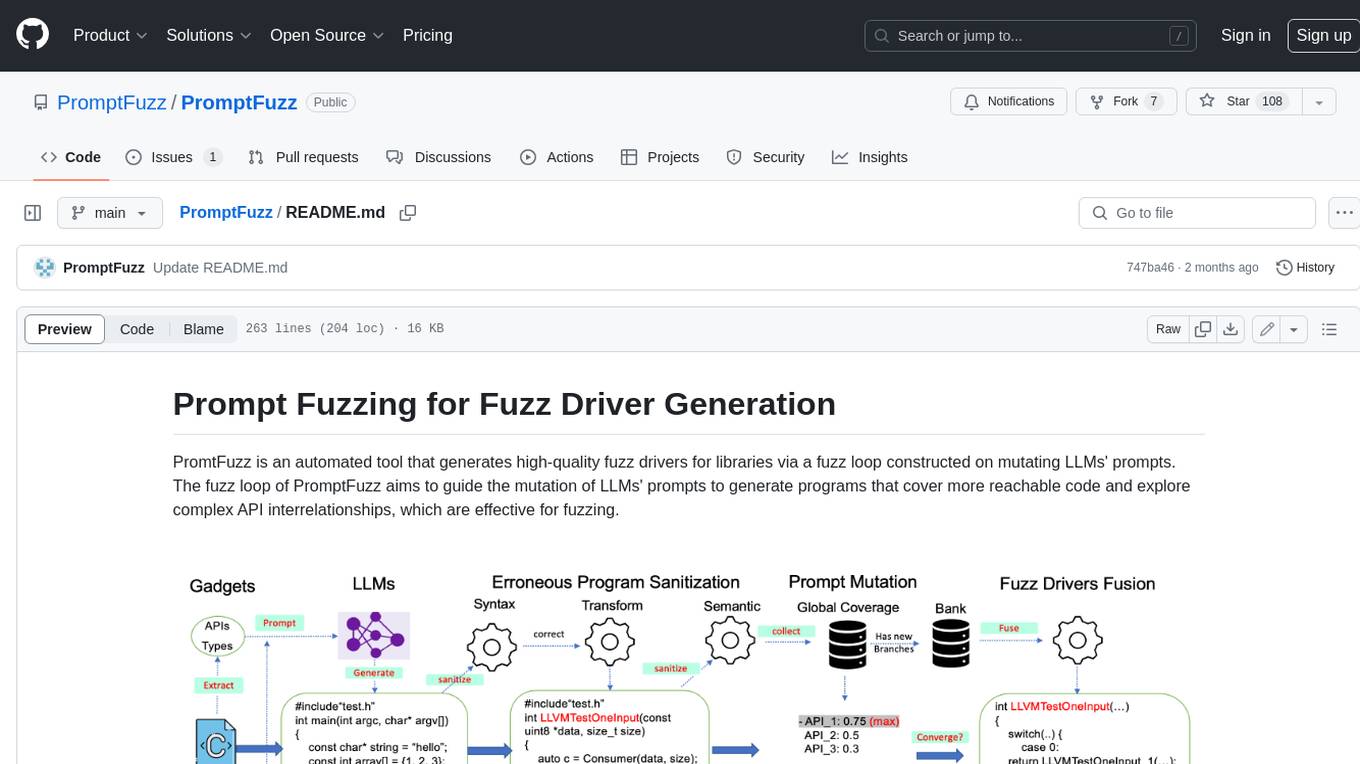
PromptFuzz
**Description:** PromptFuzz is an automated tool that generates high-quality fuzz drivers for libraries via a fuzz loop constructed on mutating LLMs' prompts. The fuzz loop of PromptFuzz aims to guide the mutation of LLMs' prompts to generate programs that cover more reachable code and explore complex API interrelationships, which are effective for fuzzing. **Features:** * **Multiply LLM support** : Supports the general LLMs: Codex, Inocder, ChatGPT, and GPT4 (Currently tested on ChatGPT). * **Context-based Prompt** : Construct LLM prompts with the automatically extracted library context. * **Powerful Sanitization** : The program's syntax, semantics, behavior, and coverage are thoroughly analyzed to sanitize the problematic programs. * **Prioritized Mutation** : Prioritizes mutating the library API combinations within LLM's prompts to explore complex interrelationships, guided by code coverage. * **Fuzz Driver Exploitation** : Infers API constraints using statistics and extends fixed API arguments to receive random bytes from fuzzers. * **Fuzz engine integration** : Integrates with grey-box fuzz engine: LibFuzzer. **Benefits:** * **High branch coverage:** The fuzz drivers generated by PromptFuzz achieved a branch coverage of 40.12% on the tested libraries, which is 1.61x greater than _OSS-Fuzz_ and 1.67x greater than _Hopper_. * **Bug detection:** PromptFuzz detected 33 valid security bugs from 49 unique crashes. * **Wide range of bugs:** The fuzz drivers generated by PromptFuzz can detect a wide range of bugs, most of which are security bugs. * **Unique bugs:** PromptFuzz detects uniquely interesting bugs that other fuzzers may miss. **Usage:** 1. Build the library using the provided build scripts. 2. Export the LLM API KEY if using ChatGPT or GPT4. 3. Generate fuzz drivers using the `fuzzer` command. 4. Run the fuzz drivers using the `harness` command. 5. Deduplicate and analyze the reported crashes. **Future Works:** * **Custom LLMs suport:** Support custom LLMs. * **Close-source libraries:** Apply PromptFuzz to close-source libraries by fine tuning LLMs on private code corpus. * **Performance** : Reduce the huge time cost required in erroneous program elimination.

YuLan-Mini
YuLan-Mini is a lightweight language model with 2.4 billion parameters that achieves performance comparable to industry-leading models despite being pre-trained on only 1.08T tokens. It excels in mathematics and code domains. The repository provides pre-training resources, including data pipeline, optimization methods, and annealing approaches. Users can pre-train their own language models, perform learning rate annealing, fine-tune the model, research training dynamics, and synthesize data. The team behind YuLan-Mini is AI Box at Renmin University of China. The code is released under the MIT License with future updates on model weights usage policies. Users are advised on potential safety concerns and ethical use of the model.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

CogVLM2
CogVLM2 is a new generation of open source models that offer significant improvements in benchmarks such as TextVQA and DocVQA. It supports 8K content length, image resolution up to 1344 * 1344, and both Chinese and English languages. The project provides basic calling methods, fine-tuning examples, and OpenAI API format calling examples to help developers quickly get started with the model.
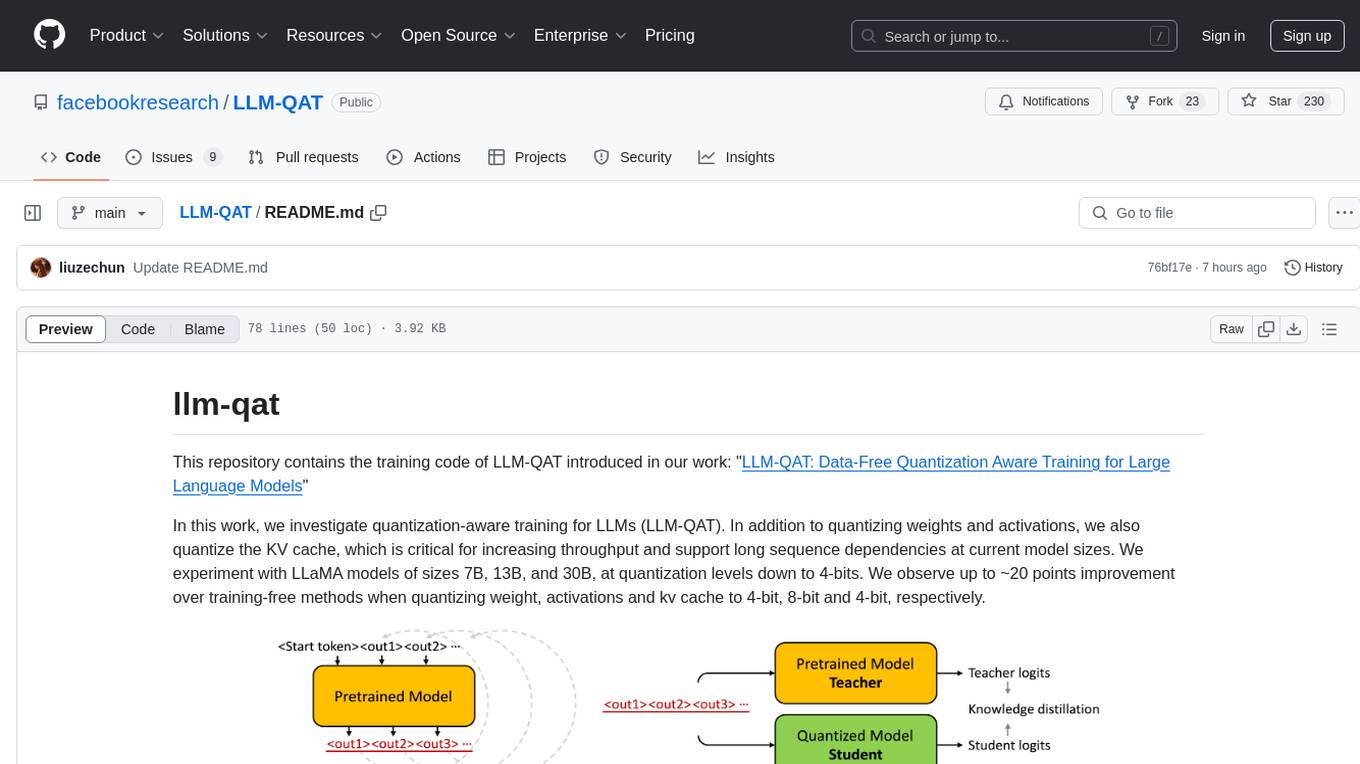
LLM-QAT
This repository contains the training code of LLM-QAT for large language models. The work investigates quantization-aware training for LLMs, including quantizing weights, activations, and the KV cache. Experiments were conducted on LLaMA models of sizes 7B, 13B, and 30B, at quantization levels down to 4-bits. Significant improvements were observed when quantizing weight, activations, and kv cache to 4-bit, 8-bit, and 4-bit, respectively.

llm-compression-intelligence
This repository presents the findings of the paper "Compression Represents Intelligence Linearly". The study reveals a strong linear correlation between the intelligence of LLMs, as measured by benchmark scores, and their ability to compress external text corpora. Compression efficiency, derived from raw text corpora, serves as a reliable evaluation metric that is linearly associated with model capabilities. The repository includes the compression corpora used in the paper, code for computing compression efficiency, and data collection and processing pipelines.
BizFinBench
BizFinBench is a benchmark tool designed for evaluating large language models (LLMs) in logic-heavy and precision-critical domains such as finance. It comprises over 100,000 bilingual financial questions rooted in real-world business scenarios. The tool covers five dimensions: numerical calculation, reasoning, information extraction, prediction recognition, and knowledge-based question answering, mapped to nine fine-grained categories. BizFinBench aims to assess the capacity of LLMs in real-world financial scenarios and provides insights into their strengths and limitations.

awesome-mobile-llm
Awesome Mobile LLMs is a curated list of Large Language Models (LLMs) and related studies focused on mobile and embedded hardware. The repository includes information on various LLM models, deployment frameworks, benchmarking efforts, applications, multimodal LLMs, surveys on efficient LLMs, training LLMs on device, mobile-related use-cases, industry announcements, and related repositories. It aims to be a valuable resource for researchers, engineers, and practitioners interested in mobile LLMs.
ZhiLight
ZhiLight is a highly optimized large language model (LLM) inference engine developed by Zhihu and ModelBest Inc. It accelerates the inference of models like Llama and its variants, especially on PCIe-based GPUs. ZhiLight offers significant performance advantages compared to mainstream open-source inference engines. It supports various features such as custom defined tensor and unified global memory management, optimized fused kernels, support for dynamic batch, flash attention prefill, prefix cache, and different quantization techniques like INT8, SmoothQuant, FP8, AWQ, and GPTQ. ZhiLight is compatible with OpenAI interface and provides high performance on mainstream NVIDIA GPUs with different model sizes and precisions.

Awesome-LLM-Constrained-Decoding
Awesome-LLM-Constrained-Decoding is a curated list of papers, code, and resources related to constrained decoding of Large Language Models (LLMs). The repository aims to facilitate reliable, controllable, and efficient generation with LLMs by providing a comprehensive collection of materials in this domain.
COLD-Attack
COLD-Attack is a framework designed for controllable jailbreaks on large language models (LLMs). It formulates the controllable attack generation problem and utilizes the Energy-based Constrained Decoding with Langevin Dynamics (COLD) algorithm to automate the search of adversarial LLM attacks with control over fluency, stealthiness, sentiment, and left-right-coherence. The framework includes steps for energy function formulation, Langevin dynamics sampling, and decoding process to generate discrete text attacks. It offers diverse jailbreak scenarios such as fluent suffix attacks, paraphrase attacks, and attacks with left-right-coherence.
rubra
Rubra is a collection of open-weight large language models enhanced with tool-calling capability. It allows users to call user-defined external tools in a deterministic manner while reasoning and chatting, making it ideal for agentic use cases. The models are further post-trained to teach instruct-tuned models new skills and mitigate catastrophic forgetting. Rubra extends popular inferencing projects for easy use, enabling users to run the models easily.

goodai-ltm-benchmark
This repository contains code and data for replicating experiments on Long-Term Memory (LTM) abilities of conversational agents. It includes a benchmark for testing agents' memory performance over long conversations, evaluating tasks requiring dynamic memory upkeep and information integration. The repository supports various models, datasets, and configurations for benchmarking and reporting results.

Prompt-Engineering-Holy-Grail
The Prompt Engineering Holy Grail repository is a curated resource for prompt engineering enthusiasts, providing essential resources, tools, templates, and best practices to support learning and working in prompt engineering. It covers a wide range of topics related to prompt engineering, from beginner fundamentals to advanced techniques, and includes sections on learning resources, online courses, books, prompt generation tools, prompt management platforms, prompt testing and experimentation, prompt crafting libraries, prompt libraries and datasets, prompt engineering communities, freelance and job opportunities, contributing guidelines, code of conduct, support for the project, and contact information.
For similar tasks
linghe
A library of high-performance kernels for LLM training, linghe is designed for MoE training with FP8 quantization. It provides fused quantization kernels, memory-efficiency kernels, and implementation-optimized kernels. The repo benchmarks on H800 with specific configurations and offers examples in tests. Users can refer to the API for more details.

BentoML
BentoML is an open-source model serving library for building performant and scalable AI applications with Python. It comes with everything you need for serving optimization, model packaging, and production deployment.

Qwen-TensorRT-LLM
Qwen-TensorRT-LLM is a project developed for the NVIDIA TensorRT Hackathon 2023, focusing on accelerating inference for the Qwen-7B-Chat model using TRT-LLM. The project offers various functionalities such as FP16/BF16 support, INT8 and INT4 quantization options, Tensor Parallel for multi-GPU parallelism, web demo setup with gradio, Triton API deployment for maximum throughput/concurrency, fastapi integration for openai requests, CLI interaction, and langchain support. It supports models like qwen2, qwen, and qwen-vl for both base and chat models. The project also provides tutorials on Bilibili and blogs for adapting Qwen models in NVIDIA TensorRT-LLM, along with hardware requirements and quick start guides for different model types and quantization methods.
CodeFuse-ModelCache
Codefuse-ModelCache is a semantic cache for large language models (LLMs) that aims to optimize services by introducing a caching mechanism. It helps reduce the cost of inference deployment, improve model performance and efficiency, and provide scalable services for large models. The project caches pre-generated model results to reduce response time for similar requests and enhance user experience. It integrates various embedding frameworks and local storage options, offering functionalities like cache-writing, cache-querying, and cache-clearing through RESTful API. The tool supports multi-tenancy, system commands, and multi-turn dialogue, with features for data isolation, database management, and model loading schemes. Future developments include data isolation based on hyperparameters, enhanced system prompt partitioning storage, and more versatile embedding models and similarity evaluation algorithms.
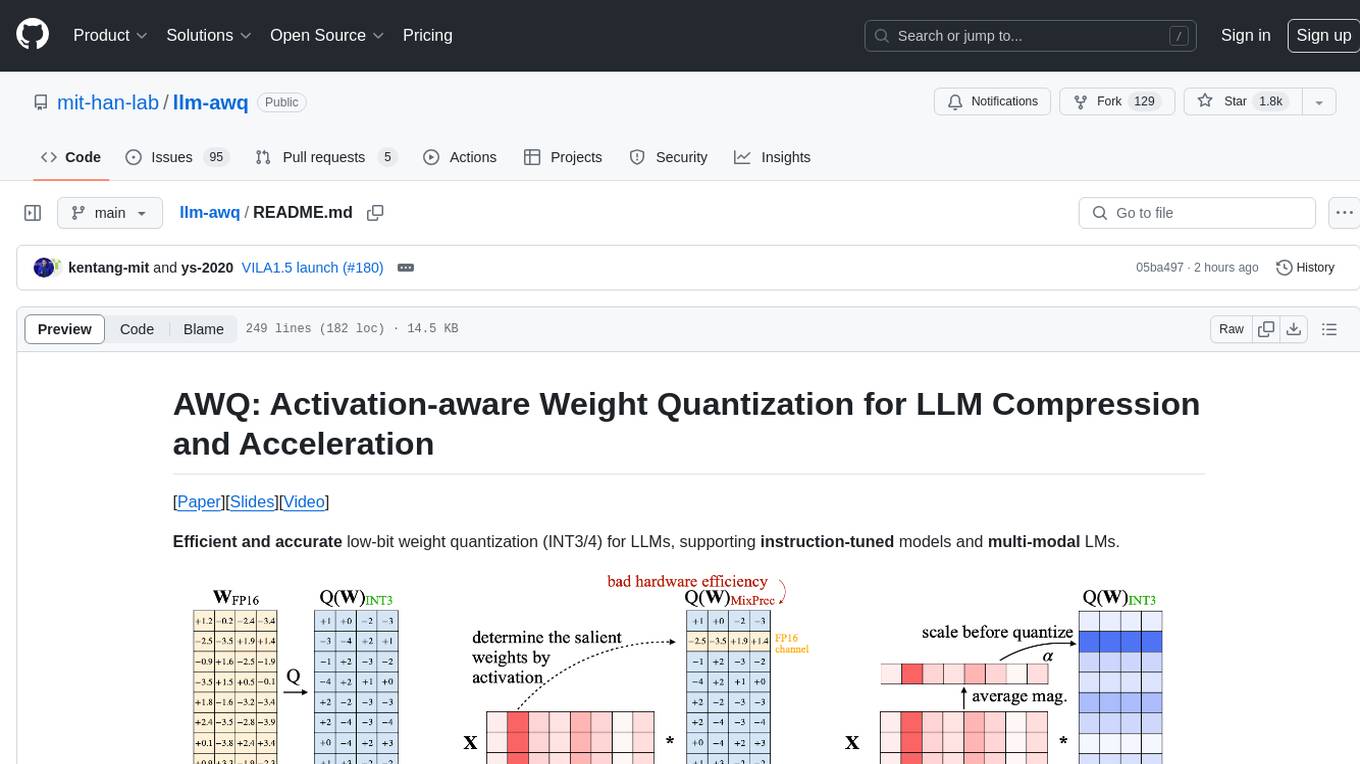
llm-awq
AWQ (Activation-aware Weight Quantization) is a tool designed for efficient and accurate low-bit weight quantization (INT3/4) for Large Language Models (LLMs). It supports instruction-tuned models and multi-modal LMs, providing features such as AWQ search for accurate quantization, pre-computed AWQ model zoo for various LLMs, memory-efficient 4-bit linear in PyTorch, and efficient CUDA kernel implementation for fast inference. The tool enables users to run large models on resource-constrained edge platforms, delivering more efficient responses with LLM/VLM chatbots through 4-bit inference.

LazyLLM
LazyLLM is a low-code development tool for building complex AI applications with multiple agents. It assists developers in building AI applications at a low cost and continuously optimizing their performance. The tool provides a convenient workflow for application development and offers standard processes and tools for various stages of application development. Users can quickly prototype applications with LazyLLM, analyze bad cases with scenario task data, and iteratively optimize key components to enhance the overall application performance. LazyLLM aims to simplify the AI application development process and provide flexibility for both beginners and experts to create high-quality applications.
ktransformers
KTransformers is a flexible Python-centric framework designed to enhance the user's experience with advanced kernel optimizations and placement/parallelism strategies for Transformers. It provides a Transformers-compatible interface, RESTful APIs compliant with OpenAI and Ollama, and a simplified ChatGPT-like web UI. The framework aims to serve as a platform for experimenting with innovative LLM inference optimizations, focusing on local deployments constrained by limited resources and supporting heterogeneous computing opportunities like GPU/CPU offloading of quantized models.
LLM-QAT
This repository contains the training code of LLM-QAT for large language models. The work investigates quantization-aware training for LLMs, including quantizing weights, activations, and the KV cache. Experiments were conducted on LLaMA models of sizes 7B, 13B, and 30B, at quantization levels down to 4-bits. Significant improvements were observed when quantizing weight, activations, and kv cache to 4-bit, 8-bit, and 4-bit, respectively.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.