
roam-extension-live-ai-assistant
Powerful AI Assistant in Roam Research
Stars: 55
Live AI is an AI Assistant tailor-made for Roam, providing access to the latest LLMs directly in Roam blocks. Users can interact with AI to extend their thinking, explore their graph, and chat with structured responses. The tool leverages Roam's features to write prompts, query graph parts, and chat with content. Users can dictate, translate, transform, and enrich content easily. Live AI supports various tasks like audio and video analysis, PDF reading, image generation, and web search. The tool offers features like Chat panel, Live AI context menu, and Ask Your Graph agent for versatile usage. Users can control privacy levels, compare AI models, create custom prompts, and apply styles for response formatting. Security concerns are addressed by allowing users to control data sent to LLMs.
README:
AI Assistant tailor-made for Roam: the power of all the latest LLMs instantly accessible in Roam. Interact with your favorite AI directly in Roam blocks, making the most of Roam’s interface to truly extend your thinking rather than just read answers! Or discover a new way to explore your graph in the agentic Chat interface. No usage limits, pay only for what you use (probably just a few dozen cents per month) or rely on free local models through Ollama or OpenAI compatible servers.
Leverage Roam's features to write simple or structured prompts, query specific parts of your graph (your latest DNPs over a given period, sidebar content, linked references, images, .pdf, etc.) and chat with this content or get directly structured responses, which can include tables, images, queries, Mermaid diagrams, code... Dictate, translate, transform, enrich or create structured content very easily thanks to a large set of built-in prompts or your own custom prompts relying on any defined and living context!
Ask your entire graph any question with Ask Your Graph agent or unlock the full power of advanced Roam queries using simple natural language queries with query agents, explore, filter and chat with the results!
If you want to encourage me to develop further and enhance Live AI extension, you can buy me a coffee ☕ here or sponsor me on Github. Thanks in advance for your support! 🙏
For any question or suggestion, DM me on X/Twitter and follow me to be informed of updates and new extensions : @fbgallet, or on Bluesky: @fbgallet.bsky.social
Please report any issue here.
- Drag & drop block(s) to Chat panel to add them to the context
- New models support: Gemini 3 Pro and Nano banana Pro, Claude Opus 4.5
- Audio and Video analysis with Gemini models
- Audio file transcription with OpenAI or Gemini
- Pdf, image, audio, video and web search supported in Chat panel
(See complete changelog here)
- GETTING STARTED
- Model-Specific Features (Voice, Web search, Image, PDF)
- Going further to get better answers
- Agents (Query agents, Ask Your Graph and Live Outliner)
- Security concerns
- Detailed documentation and advanced uses
- Get an API key
- Your first prompt
- Live AI context menu
- The basics of AI requests
- Chat with your AI Assistant
- Apply built-in prompts to existing content
- Providing rich context
- About the cost
Choose the AI models provider(s) that will provide you with an API key to use their services at will and copy your API key in the extension settings.
OpenAI and Anthropic currently provide the most tested models for Live AI, but many other options are available. For paid models, you will be billed for each request based on the number of tokens used, which in practice is very much cheaper than existing subscriptions, and without the specific limitations of these subscriptions (you don't need any subscription to use Live AI, do not confuse the paid use of the API with, for example, ChatGPT Plus). Be aware that OpenAI API key is required for specific features: voice transcription, text-to-speech and Image generation (now also supported by Google API). Web Search or PDF reading can be achieved both with specific OpenAI or Anthropic models.
Obtaining an API key is a simple operation, accessible to any user. Follow the instructions provided here if you do not already have API keys and see here current API pricing.
🆕 You can simply click on the Chat icon in the left sidebar to start an ephemeral conversation right away in the new Chat panel! Just write your request and press Enter!
See the demo .gif in the introduction section. N.B.: in this demo the Live AI buttons are in the top bar instead of left sidebar (you can switch in the extension settings)
Since v.22, it's the easiest entry point to Live AI. You can set hotkeys via Roam command palette (Cmd+p) for Live AI: Open Chat panel command to open it still quicker!
[!TIP] When opening the Chat panel, you can click on buttons to have help about the Chat, or Live AI in general, or get tips. You can even be guided by the Chat Agent to discover all the new features! Verify that 'Get help' tool is enabled, and just ask questions. The agent will rely on this help file and other Live AI detailed help file support you in learning how to use this extension!
You want still a smoother experience without breaking your flow in Roam ? Simply write some prompt in any block (or press the microphone button and provide vocal instructions) and click on the "Ask AI" button (⚡️ lightning bolt icon). That's all ! It will send your prompt to the default model and almost instantly insert the response in the children blocks of your prompt.
[!TIP] For request to AI models directly from your notes, the KEY PRINCIPLE is simple:
The prompt is the focused or selected block(s)
[!IMPORTANT] The context menu is the main entry point to Live AI, from where all features are accessible, including Chat panel, Tokens counter Query agents... Read the following instructions carrefuly:
This simple process - write and get instant response in Roam blocks - can be still more efficient with keyboard only, using Live AI Context menu, a rich context menu with a search box to access any Live AI command and context definition very quicky.
To open Live AI context menu, you can either:
- run
Live AI: Context menucommand from the Command Palette, using the hotkeys. Default hotkeys areCmd + Ctrl + a, which you can modify as you wish (recommanded way, very efficient) - right-click on the "Ask AI" button (⚡️ lightning bolt icon),
-
Cmd/Ctrl + right-clickanywhere on the page where right-clicking does not have a specific function in Roam (you can customize the key to press while right clicking in the settings).
Once the context menu is open, the first selected command is Focused block as prompt if a block is focused. Select this command to send your prompt to the default model.
[!TIP] ⚡️ In practice, the process to send some prompt to your AI assistant is almost instant:
- write your prompt and let the focus in the corresponding block
- trigger hotkeys (
Cmd + Ctrl+ aby default) to open the Live AI context menu- press
Enterto run the first command: 'Focused block as prompt' or press down arrow to select the next command 'Focused block & all children as prompt' to include all the descendants of the focused block in the prompt
[!NOTE] This first command, used to send your own prompts to an AI model, will automatically adjust to the selection state: focus, blocks selection, text selection, entire page or zoom view if neither focus nor selection.
You can also write a quick prompt directly in the search bar of the context menu and run the command "Use this custom prompt". The AI generated response will be inserted as last block of the current page/view.
The following 5 ingredients will be part of your requests (the last 3 are optional):
- PROMPT: your instructions to the AI model, available either in the currently focused block (and its children in option) or in a selection of blocks (using native Roam blocks selection), or only the selected text in a block. It can include images for models supporting image recognition (most of them) or .pdf files (only OpenAI and Anthropic models). Note that block references and block or page embed will be resolved and remplaced by the corresponding block content, unless they are inserted in inline code. Live AI provide also a large set of built-in prompts and you can create custom prompts templates for prompts you use regularly.
-
MODEL: the AI model (LLM) that will generate a response according to your instructions. In Live AI context menu, the submenu of
Focused block as promptcommand show the list of available models (for other commands, you have to right click on them to show this model submenu). Click on a model to use it for your current prompt. Right click on a model to set it as default model. You can also change the default model in the extension settings. - CONTEXT: the data your instructions might refer to (e.g., an article to summarize or use as inspiration). Live AI lets you leverage Roam powerful graph structure by using content from different parts of the interface as context, like the sidebar, linked references, current page (or zoom), mentioned pages, previous daily notes, and so on. If no prompt is provided (neither focused nor selected block) the context content will directly be used as prompt. See below for more details.
-
OUTPUT TARGET: the AI model response will be inserted directly in your graph (unless from the Chat panel, where you can insert responses or whole chat in your graph on demand). By default, it will be inserted as a block or hierarchy of blocks as direct child of the focused block, or as next sibling block of the top block of a selection of blocks. If a prompt is sent without block focused or selected (if the whole zoom view is used, or a custom prompt), the response will be inserted as last block of the current view or daily note. By default, a (customizable) header in the form of
AI Assistant (model):will be inserted as parent block of the response. You can ask for a response without header by choosingnew w/o(new block without header) in the target dropdown on the right of the context menu search box.Replacewill insert the response directly into the selected blocks, what can be very useful to complete some template but you will loose a part or your whole prompt.Appendmaintains your prompt and add the response in the same block (in case of short response).Chatwill open the chat panel and display the response of the LLM. Most of the time,automode is the better solution, adapted to the existing built-in prompts. - STYLE: the output format of the AI model response. You can provide details on how the answer should be written as well as how it will be inserted into Roam, for example, whether it should be broken down into more or less blocks (by default, Live AI supports most Roam-specific formatting like bold or highlighted text, headings, and Katex...). Live AI provide a few predefined styles and you can create your own custom styles. See below for more details.
The Chat panel is now the easiest way to have ephemeral or deep conversations with your AI assistant and allow easily to switch from Chat interface to Roam blocks by saving current conversation in Roam blocks on demand, or continue any existing conversation. A saved conversation is just a block including #liveai/chat: direct children blocks are the conversation turns.
But you can also easily continue any conversation with an AI Assistant inline in Roam blocks (or switch at any moment to chat interface):
- click on the conversation icon on the right of the last AI response block (if generated recently) or simply insert a block as next sibling of an AI response block (the one that contains it's role description, provided in settings, by default:
AI Assistant (<model>):). It is not necessary to insert your role (such as "Me:") but more convenient in terms of readability. - write or dictate your prompt (it can include children blocks),
- click on the button to continue the conversation, or run the usual AI generation command, or click on "Continue the conversation" command in Live AI context menu (all previous sibling blocks and their children will be taken into account).
- click +
Alton the button to continue conversation will insert suggestions. Only the selected one will be used as prompt.
- click +
- you can easily switch model during the conversation, just
right-clickon the conversation icon and choose another model - You can even ask one AI to respond to another and follow the conversation between two AIs:
right-clickon the conversation icon at the level of the last AI's response to choose the model that will respond.
Often, you will ask your assistant to process information already available in your graph, such as translating or summarizing a set of blocks. You could write instructions and copy the blocks to process to use them as a big prompt, but to make the most common tasks easier, Live AI offers a set of built-in prompts (around fifty) designed to be effective, rigorous, and tailored to Roam's specific constraints. You simply need, either:
- to select (by multi-block selection) the content to process,
- open the Live AI context menu and choose a command to apply the corresponding built-in prompt
- eventually use a specific model (not the default one) by right-clicking on the command: a list of available models will appear in a submenu
[!TIP] ⚡️ In practice, all you need is a hotkey and a few letters to quickly find a command. For example, to translate a block into French, you just need to press 'cmd + Ctrl + a', type 'fre' in the search bar of the context menu and press Enter! It's almost instant !
The KEY PRINCIPLE for built-in or custom prompt is:
The focused or selected block(s) is the content to which the instructions are applied
You can also add specific instructions to built-in prompts simply by clicking the + button on the left of the prompt search box !
You can view the exact content of each of these prompts here.
You can easily add context to your prompt, that is, a large set of data from your graph that will serve either as resources or as data to be processed, depending on the nature of your prompt and whether you have selected a set of blocks to process or not. In the first case, the context will be added to the system prompt and not as content to be processed. In the second case, the context will be inserted into the user prompt, to be processed directly.
To define the context, you can either check the corresponding box in the context menu or press the corresponding modifier keys to catch all the content of the following elements (at different children depths depending on the element type and settings):
-
Page (click +
Alt): the current page or zoom where the focus block or selected blocks are inserted, or by default, the main page zoom (at the center of the display) -
LinkedRefs (click +
Ctrl): the linked references of the current page -
Sidebar (click +
Shift): all the content of the sidebar -
DNPs (click +
Ctrl): a defined range of previous Daily notes (relative to the currently opened or focused DNP, but NOT including today or current day, unless triggered from a not-DNP) - [[page]] mentions: the content and linked references of the mentioned pages (as [[page]], #tag or atttribute::)
- Pdf: if .pdf documents are present in your notes, as file or as web url, they can be processed by the AI model (OpenAI or Anthropic models)
[!TIP] If a context is defined (or if you have selected multiple blocks as prompt) the uids (or block reference identifier) of all the corresponding blocks will be provided to the LLM, so it can refer to one of them if needed. Thanks to this, you can easily ask your LLMs to mention or cite relevant block uids or block references as sources (they will understand these terms). This is the default behavior but you can disable this feature if you feel that the uids are being handled improperly by your LLMs or are unnecessarily weighing down your prompts (more tokens)
See more details on context definition and inline context here
The cost of each request depends on the amount of information sent and generated, measured in tokens: one token in English is roughly 0.75 words. The cost of tokens for the input data (your prompt + context + style instructions) is on average 4 to 5 times lower than the cost for the text generated by the model.
To give you an idea, a request based on about 10 pages of text (4000 words) that generates 1 page of response (400 words) will cost around $0.0026 with OpenAI’s default model (gpt-4.1-mini). Making such a (large) request 10 times a day for a month would cost about $0.78.
You can track the cost of each request and the total per model for the current and past months by clicking the $ button at the top of Live AI context menu popup. Learn more about models and providers pricing here.
You need either an account on OpenAI to benefit from Whisper (or gpt-4o-transcribe models) transcriptions, or a Groq one since you can define Groq as default provider for the audio transcription model and user the powerful whisper-large-v3 model. Estimated cost is $0.006/minute.
-
the transcribed text will be inserted by default at the bottom of the current page (or page view) or appended to the current focused block (so exactly where you want, you have just to place the cursor anywhere just before clicking the button or running the transcription command).
-
by default, the language should be automatically detected, but you can specify it for better results, using the ISO 639-1 codes
-
You can specify a list of words to be spelled in a specific way (e.g. proper nouns, acronyms, technical terms, etc.), see the Whisper prompt option in the settings.
-
if you have not entered any OpenAI API Key or Groq API Key, or if you disable Whisper, the free Web Speech API will be used to transcribe audio (
⚠️ not available in Electron Desktop app and Firefox or Arc browser) -
Direct translation of vocal recording:
A large number of source languages are supported, but the target language is currently limited to English. This limitation can be easily overcome through post-processing using a generative AI, as it only requires asking it to translate into almost any language.
You can easily transcribe entire audio recordings (meetings, interviews, lectures, etc.): when a block contains audio, an "Audio transcription" command appears in the context menu. It transcribes audio using Gemini (if current model includes "gemini") or OpenAI/Groq Whisper (using default Voice transcription model defined in settings), then formats the output into proper paragraphs. Add custom instructions in the prompt field to customize transcription and eventually name speakers.
Supported audio formats:
-
{{[[audio]]: url}}- Roam audio embed format - Direct audio file URLs - Supports .mp3, .wav, .aiff, .aac, .ogg, .flac, .m4a extensions
You can analyze audio files directly in your prompts by including audio URLs or using Roam's audio embed format. Simply insert an audio file in your prompt or context and the AI will transcribe and/or analyze its content (if the audio is in the context, you have to use "audio" keyword in your prompt to activate audio analysis). So you can extract specific information from audio content, analyze audio within a specific time range, generate summaries or insights...
Audio segment analysis:
You can analyze specific segments of audio files by adding time markers in your prompt (using start: or from: and/or end: or to:, and s or m:ss time format):
-
start: 1:30orstart: 90- Start analysis at 1 minute 30 seconds (or 90 seconds) -
end: 5:00orend: 300- End analysis at 5 minutes - Example: "Transcribe this audio start: 2:00 end: 4:30"
- If no time markers are specified, the entire audio file will be analyzed
Important notes:
- If you don't provide specific instructions, the AI will provide a transcription by default
- You can combine audio analysis with other AI capabilities (e.g., summarization, translation, Q&A)
You can have any selection read aloud (the focus block, part of the selected text in that block, or a set of selected blocks). You just need an active OpenAI key (since the gpt-4o-mini-tts model will be used) and run the Text To Speech command from Live AI context menu. Press Escape to stop the reading. It can take a few seconds for processing data before speaking. Estimated cost is $0.015/minute.
In the extension settings, you can change the voice and provide instructions to control aspects of speech, including: Accent, Emotional range, Intonation, Impressions, Speed of speech, Tone, Whispering...
You can analyze videos directly in your prompts by including video URLs or using Roam's video embed format. Simply insert a video in your prompt or context and the AI will analyze its content (if the video is in the context, you have to use "video" keyword in your prompt to activate video analysis)
Supported video formats:
-
{{[[video]]: url}}- Standard Roam video embed -
{{[[youtube]]: url}}- YouTube-specific embed - Direct YouTube URLs - The AI will detect and analyze YouTube URLs automatically
Video clipping support:
You can analyze specific segments of videos by adding time markers in your prompt (using start: or from: and/or end: or to:, and s or m:ss time format):
-
start: 1:30orstart: 90- Start analysis at 1 minute 30 seconds (or 90 seconds) -
end: 5:00orend: 300- End analysis at 5 minutes - Example: "Summarize this video start:2:00 end:4:30"
Important notes:
- Videos must be public and allow AI analysis (some YouTube videos may be restricted)
- For large video files (>20MB), they will be uploaded via Google's Files API
- Smaller videos are processed inline for faster analysis
- All videos are processed at low resolution to optimize costs
You can generate images directly embedded in Roam using a prompt (written in a block, or a block selection, optionally including a context) with the Image generation command. This feature requires an OpenAI API key (and your organization's authentication (identity verification)) or Google API key. Google Gemini 3 'Nano banana Pro' is currently the most suitable model for edition and text insertion in images and is set as default image generation model in settings.
See best practices for Google Gemini image models 'nano banana' here (don't care about the code on this page, all is handled by Live AI)
In the built-in prompts menu, choose among three levels of image quality (except for gemini-2.5-flash-image, always 1K): low, medium or high (equivalent to 1K, 2K or 4K for Nano banana pro). The low level is usually enough, the image generates faster (about fifteen seconds for a simple prompt) and costs much less (see the pricing doc for details).
In you prompt, you can provide:
- Image format: if you want a square (1024x1024), portrait (1024*1536), or landscape format (1536x1024), or a transparent background (or the model will choose by itself). For Google models, you can specify ratio directly in your prompt (e.g.: 1:1, 2:3, 4:3, 16:9, etc.)
- Image in prompt: the image generation can rely on existing images (as inspiration or source to edit). Simply insert one or multiple images in your prompt (by selecting the corresponding blocks or putting them in the choosen context). Be aware that each input image will add input tokens cost.
-
Image edition: Gemini Nano banana models allow direct image edition without any mask: just insert the image to edit in your prompt or context and ask for modifications. Multi-turn image editing is supported: in the Chat panel, you can refine images through multiple conversational edits (once an image has been generated in the chat, all following message can only be used for image edition and no other purpose); in Roam blocks, create a child block under an existing image and use the
Image generationcommand to iteratively edit the image. The chat maintains context across edits and model attribution is automatically added below each generated image. Google Imagen-4 models doesn't support edit. For OpenAPI models you can target the image edition to a specific part of an image by attaching a copy of the initial image with a transparent area (alpha channel) to indicate where the requested change should be made without altering the rest. The image used as a mask will only be recognized as such if you add the keywordmaskin the markdown link to the image, e.g.:
OpenAI, Anthropic and Google models supporting images as input support also .pdf files in your prompt or in the context. You can insert them both as simple web url or as {{[[pdf]]: ...}} component specific to Roam (including the firebase url where your pdf is stored).
In Chat panel, you can insert a pdf in the prompt or in the context and chat with its content! If your pdf is in the context, you have to explicitly mention "pdf" keyword in your first prompt to allow the agent to extract .pdf from the context.
You have to know that for each page, text and an image of the page will be sent as input to the LLM: the total tokens count will be greater than for simple text input, even if there is no image in your .pdf.
The knowledge base used for the LLM responses can be the web itself if you use Web search command (or OpenAI gpt-5-search-api, gpt-4o-search or gpt-4o-mini-search models with basic prompt completion command) . It's useful if you're looking for information that requires recent data or practical questions, for example, organizing a trip.
The models don't just summarize different relevant content found on the internet. You can use a rich prompt that requests all types of advanced and structured content processing that the LLM will gather.
You can set the default model to use for Web search either in extension settings or by right-clicking on the choosen model in the submenu of Web search command.
[!WARNING]
⚠️ To collect its data and prepare its response, the model will browse several sites: the input tokens used will be much higher than your prompt, leading to additional costs. Additionally, providers charge a fee per 1,000 queries: $10 for Anthropic, and between $25 and $50 for OpenAI, depending on the context size and model.
Anthropic models can even fetch specific web page if you insert the url in your prompt (if allowed by the web domain).
The most important thing is the precision of your prompt, which is why it can be helpful to create personalized or style-specific prompt templates to reuse instructions proven effective through experience. However, different LLMs respond very differently to instructions and vary in how sensitive they are to certain types of directions, so it can be very useful to compare their responses.
You can easily compare AI models responses: right click on 'Generate a response again' button ⟳ appearing on the right of the AI response and choose another model. The new response will be inserted just above the first one.
You can improve the response: click + Alt on 'Generate a response again' button ⟳ and the previous result will be taken into account to be improved.
You can even add feedback on the errors or shortcomings of the previous result: place the focus in the block with your correction instructions before clicking the retry button.
Create your custom prompts simply by inserting #liveai/prompt in some block. The content of this block will be used as title of your custom prompt and all its children will be used as a structured prompt (block references will be resolved). They will appear in the "custom prompts" section of the context menu.
In the title block of your custom prompt, you can define an inline context, see the syntax here.
Live AI Skills, inspired by Anthropic Agent Skills, provide a new way to rely on predefined and rich set of instructions and resources, see detailed documentation here. It's only available in the Chat agent.
A style describes the way the generative AIs will write in all their responses, regardless of the specific prompt used (but some built-in prompts, like translation or correction, are incompatible with a style, it won't apply). A set of built-in styles are offered:
- Concise: for shorter responses, often limited to a few sentences
- Conversational: the AI will adopt a more oral style and encourage continuing the conversation, in a similar way to ChatGPT
- No bullet points: responses will ideally take the form of one (or a few) paragraph, to avoid the multiplication of bullet points (which is suitable for Roam but not always desirable)
- Atomic: on the other hand, will emphasize the tendency of generative AIs to break down their responses into bullet points, with simple content in each block
- Quiz: instead of providing a direct answer, the LLM will offer multiple-choice responses to exercise your judgment, and if you can't identify the correct answer, it will give hints
- Socratic: responses in the style of the famous philosopher Socrates (in the dialogues written by Plato). Socrates, not claiming to know the truth about the subject being asked, raises questions himself to encourage thinking, particularly about the meaning of key concepts, involved values, implicit beliefs, etc.
You can read the detailed system prompts defining each built-in style here.
You can add your own custom style, using #liveai/style tag. See here for detailed documentation.
Currently, 3 complementary AI Agents can help users to find precise information in their Roam Graph through natural language queries. The first two do not send any data from your graph to the LLM, they simply interpret the user's request to transform it into native Roam database queries. In contrast, "Ask your graph" agent can have access to the data extracted by the queries to answer your question or proceed with the required processing (depending on privacy mode you choose).
- Natural language query: transform the user request in a properly formatted Roam query. It supports period range and semantic variations, see details here. Very reliable.
-
Natural language :q Datomic query: transform the user request in a Datalog Datomic query using the native
:qquery syntax, supporting more complexes and structured queries than the previous one. See details here.
Ask anything to your entire graph, the agent will find the most relevant data to answer your request. Then you can interact and chat with the results to get the best insights! And when no block is focused, "Ask Linked References of current page" command allow to chat with linked references!
Ask Your Graph is an agent with tools to search for nodes that meet the conditions you provide in natural language. Simply write your natural language query in any block and run Ask Your Graph agent from the Context menu or command panels. Or enable the corresponding tool in the Chat panel and the chat agent will recognize if your prompt is a graph query or not by itself!
The conditions in a query to Ask your graph can be:
- text or exact "quotes",
- page references,
- regex patterns,
- attributes and their values.
- time intervals,
- specific pages only, or DNP only/excluded,
Conditions can be combined logically in natural language or using symbols (+ for AND, | for OR, - for NOT). They can also be combined sequentially (Do this, then that...): it's often better to combine multiple simple queries than an complex query. You can also ask for a limited number of result and for random results!
[!TIP] Stick to simple logic so as not to narrow down the search too much from start. You can add filters later in the full results view, select manually most relevant results or let an LLM do this for you as a next step.
The nodes matching these conditions can be:
- blocks and their children (default search: block + direct children), up to 3 levels deep, with optional conditions for both the parent and at least one child,
- pages based on their title or Daily notes based on a time range,
- blocks matching all conditions (specify "in same block" in your query),
- pages based on their full content,
- pages containing at least one block matching all conditions.
Examples of request:
blocks mentioning [[meeting]] and financeblocks mentioning [[meeting]] and #important, and John in one of its children2 random pages where attribute 'status' is #pendingWhat are the main topics of my [[meeting]] since one month ?
For each condition, different variations can be tested to broaden the search:
- fuzzy search or syntactic variation using the
*symbol after a word (or by explicit request), - semantic variations with
~after a mode (synonyms, related terms, broader terms, or a custom variation defined in your prompt).
These variations can be included in the initial query or applied after the first round of results via a menu. By default, if no results are found, the agent will first try fuzzy search, then semantic variations until at least one result is found. In settings, you can also force "always fuzzy", "always synonyms" or "always all semantic variations".
Examples of request:
-
[[meeting]] about finance~ since one week(will search for finance and a list of synonyms) -
All pages with design* in the title(fuzzy search on 'design') -
Pages with some color~ in the title (custom semantic variation: list most common colors)(LLM generated list of common colors as search terms)
-
Once your query returns results (by default inserted in your graph in Private mode, limited to 20, or selected and commented in Balanced/Full modes), you can view, filter, and sort them in the full results view.
-
From there, you can chat directly with the results or with a selected subset of results. In its responses, the agent will reference the concerned results. You can instantly connect what the agent says with the related blocks just by hovering over them!
-
-
A new button on top-right of linked references allow to ""Ask Linked References of current page" (or if no block is focused, clicking on Ask Your Graph icon or running the corresponding command from the context menu): it opens linked references in the full view results (reproducing the current filters), allowing to filter/select some of them and chat with them!
-
You can also take an existing query or :q query (without dedicated rules or variables) as the base for new searches. Ask Your Graph will understand it, reproduce its results, and open new filtering and precision search possibilities.
-
Each user query can be saved for further exploration and the 3 most recents queries remain available. Each query can also be combined with other queries or completed by specific pages or blocks. Run "Open results view" command to load and chat with saved queries.
There are three privacy levels letting you decide what data may become accessible to the LLM when running Ask Your Graph from a Roam block:
- in "Private" mode, the LLM will never access block content, only their uid and page titles.
- in "Balanced" mode (and by default in the chat interface), the LLM receives block content only at the response synthesis stage; all intermediate steps rely only on uids and page titles.
- in "Full" mode, the agent may use the content and hierarchy of blocks and pages whenever needed for its search. Results can be more precise, but processing will take longer.
In Chat panel, by principle, all blocks and pages loaded in the context will be read (at least partially) by the LLM. If you want to prevent any distant LLM to acccess block or page content, disable tools allowing to load pages or blocks and don't add context to the chat.
Ask Your Graph offers many search options, from the simplest to the most complex. Just phrase your request in natural language (or use voice transcription!), the agent does the rest! But if you want to make the most of the agent’s capabilities, check out the detailed documentation: See details here.
This is another way of using AI, an alternative to the "Chat" format. It involves an Agent that autonomously chooses to modify an outline, that is, a set of blocks located under a given parent block, based on user requests. Instead of generating a series of content one after another as in a chat, the Live Outliner Agent modifies, adds, or removes specific blocks in the outline, while maintaining the same structure. In other words, the generation is inserted into a pre-existing structure (similar to a template) and acts only surgically, modifying only the necessary elements, which reduces the number of output tokens. It's a powerful and innovative feature, still experimental 🧪. See details here.
Sending personal data to a LLMs is not trivial and should always be done with caution. The only completely safe method is to use local models (accessible via Ollama in Live AI), but the most powerful ones require very powerful computers and are generally slower than online models. It's therefore useful to be able to clearly identify which data from your graph will be sent to the LLMs.
With Live AI, you generally have control over what you decide to send or not to the LLMs, except in the case of the Ask your graph agent. Here's what's sent to the LLM based on the type of command used:
- when using the generative AI from a prompt, only the prompt (a block or the blocks selected by the user + the content of block refs without their children) is sent.
- when using
Continue the conversationcommand: all previous sibling blocks and all their children are sent.Selected blocks as promptcommand checks if the previous sibling blocks contain a specific header for an AI response, if so, it behaves the same asContinue the conversation. In other words, to ensure that previous sibling blocks are not sent to the API by mistake, it's enough to start any new request as the first child of a new block. - when using a context, by default (customizable in the extension settings):
- the current page sends all the content of the current zoom,
- linked references send 3 levels of blocks (that means, 2 levels of children),
- [[pages]] links send corresponding page content and its linked references on 3 levels
- DNPs send 3 levels of blocks from the last 7 days (relative)
- You can also set tags to exclude blocks (and their children) from context
- regarding agents:
-
NL query,NL: q Datomic query, andAsk Your Graphin private mode only send the natural language query, no graph content is sent to the LLM API ! -
Ask your graphin chat or ballanced or full modes, on the other hand, sends to an LLM the results of queries (blocks that match the conditions + their direct parent + and all children up to 3 levels for pre-selected blocks). During the agentic processing of the user request, the user has no control over what is sent to the LLM, since the data captured depends on how the agent interprets the user's initial query. In the chat with results interface, the user can choose which result has to be sent to the LLM. -
Live Outliner Agentonly sends the content of the active Live Outline.
-
- Generative AI
- Built-in prompts
- Context definition and inline context
- Custom prompts
- Custom styles
- Using SmartBlocks commands
- AI Agents
- LLM Providers
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for roam-extension-live-ai-assistant
Similar Open Source Tools
roam-extension-live-ai-assistant
Live AI is an AI Assistant tailor-made for Roam, providing access to the latest LLMs directly in Roam blocks. Users can interact with AI to extend their thinking, explore their graph, and chat with structured responses. The tool leverages Roam's features to write prompts, query graph parts, and chat with content. Users can dictate, translate, transform, and enrich content easily. Live AI supports various tasks like audio and video analysis, PDF reading, image generation, and web search. The tool offers features like Chat panel, Live AI context menu, and Ask Your Graph agent for versatile usage. Users can control privacy levels, compare AI models, create custom prompts, and apply styles for response formatting. Security concerns are addressed by allowing users to control data sent to LLMs.
feedgen
FeedGen is an open-source tool that uses Google Cloud's state-of-the-art Large Language Models (LLMs) to improve product titles, generate more comprehensive descriptions, and fill missing attributes in product feeds. It helps merchants and advertisers surface and fix quality issues in their feeds using Generative AI in a simple and configurable way. The tool relies on GCP's Vertex AI API to provide both zero-shot and few-shot inference capabilities on GCP's foundational LLMs. With few-shot prompting, users can customize the model's responses towards their own data, achieving higher quality and more consistent output. FeedGen is an Apps Script based application that runs as an HTML sidebar in Google Sheets, allowing users to optimize their feeds with ease.

brokk
Brokk is a code assistant designed to understand code semantically, allowing LLMs to work effectively on large codebases. It offers features like agentic search, summarizing related classes, parsing stack traces, adding source for usages, and autonomously fixing errors. Users can interact with Brokk through different panels and commands, enabling them to manipulate context, ask questions, search codebase, run shell commands, and more. Brokk helps with tasks like debugging regressions, exploring codebase, AI-powered refactoring, and working with dependencies. It is particularly useful for making complex, multi-file edits with o1pro.

AIlice
AIlice is a fully autonomous, general-purpose AI agent that aims to create a standalone artificial intelligence assistant, similar to JARVIS, based on the open-source LLM. AIlice achieves this goal by building a "text computer" that uses a Large Language Model (LLM) as its core processor. Currently, AIlice demonstrates proficiency in a range of tasks, including thematic research, coding, system management, literature reviews, and complex hybrid tasks that go beyond these basic capabilities. AIlice has reached near-perfect performance in everyday tasks using GPT-4 and is making strides towards practical application with the latest open-source models. We will ultimately achieve self-evolution of AI agents. That is, AI agents will autonomously build their own feature expansions and new types of agents, unleashing LLM's knowledge and reasoning capabilities into the real world seamlessly.

noScribe
noScribe is an AI-based software designed for automated audio transcription, specifically tailored for transcribing interviews for qualitative social research or journalistic purposes. It is a free and open-source tool that runs locally on the user's computer, ensuring data privacy. The software can differentiate between speakers and supports transcription in 99 languages. It includes a user-friendly editor for reviewing and correcting transcripts. Developed by Kai Dröge, a PhD in sociology with a background in computer science, noScribe aims to streamline the transcription process and enhance the efficiency of qualitative analysis.
vigenair
ViGenAiR is a tool that harnesses the power of Generative AI models on Google Cloud Platform to automatically transform long-form Video Ads into shorter variants, targeting different audiences. It generates video, image, and text assets for Demand Gen and YouTube video campaigns. Users can steer the model towards generating desired videos, conduct A/B testing, and benefit from various creative features. The tool offers benefits like diverse inventory, compelling video ads, creative excellence, user control, and performance insights. ViGenAiR works by analyzing video content, splitting it into coherent segments, and generating variants following Google's best practices for effective ads.
blurt
Blurt is a Gnome shell extension that enables accurate speech-to-text input in Linux. It is based on the command line utility NoteWhispers and supports Gnome shell version 48. Users can transcribe speech using a local whisper.cpp installation or a whisper.cpp server. The extension allows for easy setup, start/stop of speech-to-text input with key bindings or icon click, and provides visual indicators during operation. It offers convenience by enabling speech input into any window that allows text input, with the transcribed text sent to the clipboard for easy pasting.

lovelaice
Lovelaice is an AI-powered assistant for your terminal and editor. It can run bash commands, search the Internet, answer general and technical questions, complete text files, chat casually, execute code in various languages, and more. Lovelaice is configurable with API keys and LLM models, and can be used for a wide range of tasks requiring bash commands or coding assistance. It is designed to be versatile, interactive, and helpful for daily tasks and projects.

wdoc
wdoc is a powerful Retrieval-Augmented Generation (RAG) system designed to summarize, search, and query documents across various file types. It aims to handle large volumes of diverse document types, making it ideal for researchers, students, and professionals dealing with extensive information sources. wdoc uses LangChain to process and analyze documents, supporting tens of thousands of documents simultaneously. The system includes features like high recall and specificity, support for various Language Model Models (LLMs), advanced RAG capabilities, advanced document summaries, and support for multiple tasks. It offers markdown-formatted answers and summaries, customizable embeddings, extensive documentation, scriptability, and runtime type checking. wdoc is suitable for power users seeking document querying capabilities and AI-powered document summaries.

ChainForge
ChainForge is a visual programming environment for battle-testing prompts to LLMs. It is geared towards early-stage, quick-and-dirty exploration of prompts, chat responses, and response quality that goes beyond ad-hoc chatting with individual LLMs. With ChainForge, you can: * Query multiple LLMs at once to test prompt ideas and variations quickly and effectively. * Compare response quality across prompt permutations, across models, and across model settings to choose the best prompt and model for your use case. * Setup evaluation metrics (scoring function) and immediately visualize results across prompts, prompt parameters, models, and model settings. * Hold multiple conversations at once across template parameters and chat models. Template not just prompts, but follow-up chat messages, and inspect and evaluate outputs at each turn of a chat conversation. ChainForge comes with a number of example evaluation flows to give you a sense of what's possible, including 188 example flows generated from benchmarks in OpenAI evals. This is an open beta of Chainforge. We support model providers OpenAI, HuggingFace, Anthropic, Google PaLM2, Azure OpenAI endpoints, and Dalai-hosted models Alpaca and Llama. You can change the exact model and individual model settings. Visualization nodes support numeric and boolean evaluation metrics. ChainForge is built on ReactFlow and Flask.

WilmerAI
WilmerAI is a middleware system designed to process prompts before sending them to Large Language Models (LLMs). It categorizes prompts, routes them to appropriate workflows, and generates manageable prompts for local models. It acts as an intermediary between the user interface and LLM APIs, supporting multiple backend LLMs simultaneously. WilmerAI provides API endpoints compatible with OpenAI API, supports prompt templates, and offers flexible connections to various LLM APIs. The project is under heavy development and may contain bugs or incomplete code.
Generative-AI-Pharmacist
Generative AI Pharmacist is a project showcasing the use of generative AI tools to create an animated avatar named Macy, who delivers medication counseling in a realistic and professional manner. The project utilizes tools like Midjourney for image generation, ChatGPT for text generation, ElevenLabs for text-to-speech conversion, and D-ID for creating a photorealistic talking avatar video. The demo video featuring Macy discussing commonly-prescribed medications demonstrates the potential of generative AI in healthcare communication.
obsidian-Smart2Brain
Your Smart Second Brain is a free and open-source Obsidian plugin that serves as your personal assistant, powered by large language models like ChatGPT or Llama2. It can directly access and process your notes, eliminating the need for manual prompt editing, and it can operate completely offline, ensuring your data remains private and secure.
ChatGPT-Telegram-Bot
The ChatGPT Telegram Bot is a powerful Telegram bot that utilizes various GPT models, including GPT3.5, GPT4, GPT4 Turbo, GPT4 Vision, DALL·E 3, Groq Mixtral-8x7b/LLaMA2-70b, and Claude2.1/Claude3 opus/sonnet API. It enables users to engage in efficient conversations and information searches on Telegram. The bot supports multiple AI models, online search with DuckDuckGo and Google, user-friendly interface, efficient message processing, document interaction, Markdown rendering, and convenient deployment options like Zeabur, Replit, and Docker. Users can set environment variables for configuration and deployment. The bot also provides Q&A functionality, supports model switching, and can be deployed in group chats with whitelisting. The project is open source under GPLv3 license.

ai-rag-chat-evaluator
This repository contains scripts and tools for evaluating a chat app that uses the RAG architecture. It provides parameters to assess the quality and style of answers generated by the chat app, including system prompt, search parameters, and GPT model parameters. The tools facilitate running evaluations, with examples of evaluations on a sample chat app. The repo also offers guidance on cost estimation, setting up the project, deploying a GPT-4 model, generating ground truth data, running evaluations, and measuring the app's ability to say 'I don't know'. Users can customize evaluations, view results, and compare runs using provided tools.
sorcery
Sorcery is a SillyTavern extension that allows AI characters to interact with the real world by executing user-defined scripts at specific events in the chat. It is easy to use and does not require a specially trained function calling model. Sorcery can be used to control smart home appliances, interact with virtual characters, and perform various tasks in the chat environment. It works by injecting instructions into the system prompt and intercepting markers to run associated scripts, providing a seamless user experience.
For similar tasks

RVC_CLI
**RVC_CLI: Retrieval-based Voice Conversion Command Line Interface** This command-line interface (CLI) provides a comprehensive set of tools for voice conversion, enabling you to modify the pitch, timbre, and other characteristics of audio recordings. It leverages advanced machine learning models to achieve realistic and high-quality voice conversions. **Key Features:** * **Inference:** Convert the pitch and timbre of audio in real-time or process audio files in batch mode. * **TTS Inference:** Synthesize speech from text using a variety of voices and apply voice conversion techniques. * **Training:** Train custom voice conversion models to meet specific requirements. * **Model Management:** Extract, blend, and analyze models to fine-tune and optimize performance. * **Audio Analysis:** Inspect audio files to gain insights into their characteristics. * **API:** Integrate the CLI's functionality into your own applications or workflows. **Applications:** The RVC_CLI finds applications in various domains, including: * **Music Production:** Create unique vocal effects, harmonies, and backing vocals. * **Voiceovers:** Generate voiceovers with different accents, emotions, and styles. * **Audio Editing:** Enhance or modify audio recordings for podcasts, audiobooks, and other content. * **Research and Development:** Explore and advance the field of voice conversion technology. **For Jobs:** * Audio Engineer * Music Producer * Voiceover Artist * Audio Editor * Machine Learning Engineer **AI Keywords:** * Voice Conversion * Pitch Shifting * Timbre Modification * Machine Learning * Audio Processing **For Tasks:** * Convert Pitch * Change Timbre * Synthesize Speech * Train Model * Analyze Audio
audioseal
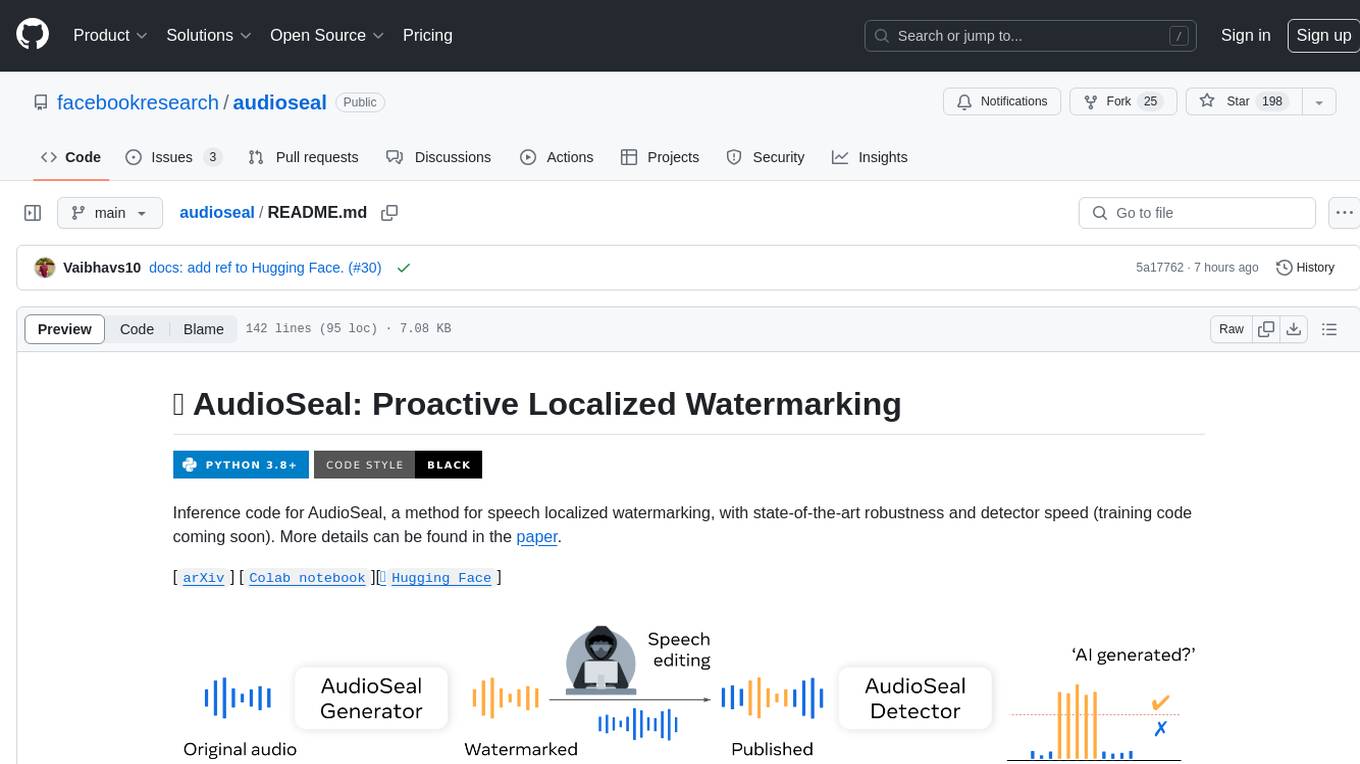
AudioSeal is a method for speech localized watermarking, designed with state-of-the-art robustness and detector speed. It jointly trains a generator to embed a watermark in audio and a detector to detect watermarked fragments in longer audios, even in the presence of editing. The tool achieves top-notch detection performance at the sample level, generates minimal alteration of signal quality, and is robust to various audio editing types. With a fast, single-pass detector, AudioSeal surpasses existing models in speed, making it ideal for large-scale and real-time applications.
SLAM-LLM
SLAM-LLM is a deep learning toolkit designed for researchers and developers to train custom multimodal large language models (MLLM) focusing on speech, language, audio, and music processing. It provides detailed recipes for training and high-performance checkpoints for inference. The toolkit supports tasks such as automatic speech recognition (ASR), text-to-speech (TTS), visual speech recognition (VSR), automated audio captioning (AAC), spatial audio understanding, and music caption (MC). SLAM-LLM features easy extension to new models and tasks, mixed precision training for faster training with less GPU memory, multi-GPU training with data and model parallelism, and flexible configuration based on Hydra and dataclass.
freegenius
FreeGenius AI is an ambitious project offering a comprehensive suite of AI solutions that mirror the capabilities of LetMeDoIt AI. It is designed to engage in intuitive conversations, execute codes, provide up-to-date information, and perform various tasks. The tool is free, customizable, and provides access to real-time data and device information. It aims to support offline and online backends, open-source large language models, and optional API keys. Users can use FreeGenius AI for tasks like generating tweets, analyzing audio, searching financial data, checking weather, and creating maps.

RVC_CLI
RVC_CLI is a command line interface tool for retrieval-based voice conversion. It provides functionalities for installation, getting started, inference, training, UVR, additional features, and API integration. Users can perform tasks like single inference, batch inference, TTS inference, preprocess dataset, extract features, start training, generate index file, model extract, model information, model blender, launch TensorBoard, download models, audio analyzer, and prerequisites download. The tool is built on various projects like ContentVec, HIFIGAN, audio-slicer, python-audio-separator, RMVPE, FCPE, VITS, So-Vits-SVC, Harmonify, and others.

towhee
Towhee is a cutting-edge framework designed to streamline the processing of unstructured data through the use of Large Language Model (LLM) based pipeline orchestration. It can extract insights from diverse data types like text, images, audio, and video files using generative AI and deep learning models. Towhee offers rich operators, prebuilt ETL pipelines, and a high-performance backend for efficient data processing. With a Pythonic API, users can build custom data processing pipelines easily. Towhee is suitable for tasks like sentence embedding, image embedding, video deduplication, question answering with documents, and cross-modal retrieval based on CLIP.
chatwise-releases
ChatWise is an offline tool that supports various AI models such as OpenAI, Anthropic, Google AI, Groq, and Ollama. It is multi-modal, allowing text-to-speech powered by OpenAI and ElevenLabs. The tool supports text files, PDFs, audio, and images across different models. ChatWise is currently available for macOS (Apple Silicon & Intel) with Windows support coming soon.
AudioMuse-AI
AudioMuse-AI is a deep learning-based tool for audio analysis and music generation. It provides a user-friendly interface for processing audio data and generating music compositions. The tool utilizes state-of-the-art machine learning algorithms to analyze audio signals and extract meaningful features for music generation. With AudioMuse-AI, users can explore the possibilities of AI in music creation and experiment with different styles and genres. Whether you are a music enthusiast, a researcher, or a developer, AudioMuse-AI offers a versatile platform for audio analysis and music generation.
For similar jobs

Perplexica
Perplexica is an open-source AI-powered search engine that utilizes advanced machine learning algorithms to provide clear answers with sources cited. It offers various modes like Copilot Mode, Normal Mode, and Focus Modes for specific types of questions. Perplexica ensures up-to-date information by using SearxNG metasearch engine. It also features image and video search capabilities and upcoming features include finalizing Copilot Mode and adding Discover and History Saving features.

KULLM
KULLM (구름) is a Korean Large Language Model developed by Korea University NLP & AI Lab and HIAI Research Institute. It is based on the upstage/SOLAR-10.7B-v1.0 model and has been fine-tuned for instruction. The model has been trained on 8×A100 GPUs and is capable of generating responses in Korean language. KULLM exhibits hallucination and repetition phenomena due to its decoding strategy. Users should be cautious as the model may produce inaccurate or harmful results. Performance may vary in benchmarks without a fixed system prompt.

MMMU
MMMU is a benchmark designed to evaluate multimodal models on college-level subject knowledge tasks, covering 30 subjects and 183 subfields with 11.5K questions. It focuses on advanced perception and reasoning with domain-specific knowledge, challenging models to perform tasks akin to those faced by experts. The evaluation of various models highlights substantial challenges, with room for improvement to stimulate the community towards expert artificial general intelligence (AGI).

1filellm
1filellm is a command-line data aggregation tool designed for LLM ingestion. It aggregates and preprocesses data from various sources into a single text file, facilitating the creation of information-dense prompts for large language models. The tool supports automatic source type detection, handling of multiple file formats, web crawling functionality, integration with Sci-Hub for research paper downloads, text preprocessing, and token count reporting. Users can input local files, directories, GitHub repositories, pull requests, issues, ArXiv papers, YouTube transcripts, web pages, Sci-Hub papers via DOI or PMID. The tool provides uncompressed and compressed text outputs, with the uncompressed text automatically copied to the clipboard for easy pasting into LLMs.

gpt-researcher
GPT Researcher is an autonomous agent designed for comprehensive online research on a variety of tasks. It can produce detailed, factual, and unbiased research reports with customization options. The tool addresses issues of speed, determinism, and reliability by leveraging parallelized agent work. The main idea involves running 'planner' and 'execution' agents to generate research questions, seek related information, and create research reports. GPT Researcher optimizes costs and completes tasks in around 3 minutes. Features include generating long research reports, aggregating web sources, an easy-to-use web interface, scraping web sources, and exporting reports to various formats.

ChatTTS
ChatTTS is a generative speech model optimized for dialogue scenarios, providing natural and expressive speech synthesis with fine-grained control over prosodic features. It supports multiple speakers and surpasses most open-source TTS models in terms of prosody. The model is trained with 100,000+ hours of Chinese and English audio data, and the open-source version on HuggingFace is a 40,000-hour pre-trained model without SFT. The roadmap includes open-sourcing additional features like VQ encoder, multi-emotion control, and streaming audio generation. The tool is intended for academic and research use only, with precautions taken to limit potential misuse.

HebTTS
HebTTS is a language modeling approach to diacritic-free Hebrew text-to-speech (TTS) system. It addresses the challenge of accurately mapping text to speech in Hebrew by proposing a language model that operates on discrete speech representations and is conditioned on a word-piece tokenizer. The system is optimized using weakly supervised recordings and outperforms diacritic-based Hebrew TTS systems in terms of content preservation and naturalness of generated speech.

do-research-in-AI
This repository is a collection of research lectures and experience sharing posts from frontline researchers in the field of AI. It aims to help individuals upgrade their research skills and knowledge through insightful talks and experiences shared by experts. The content covers various topics such as evaluating research papers, choosing research directions, research methodologies, and tips for writing high-quality scientific papers. The repository also includes discussions on academic career paths, research ethics, and the emotional aspects of research work. Overall, it serves as a valuable resource for individuals interested in advancing their research capabilities in the field of AI.