
AudioMuse-AI
AudioMuse-AI is an Open Source Dockerized environment that brings automatic playlist generation to Jellyfin, Navidrome, LMS, Lyrion and Emby. Using powerful tools like Librosa and ONNX, it performs sonic analysis on your audio files locally, allowing you to curate the perfect playlist for any mood or occasion without relying on external APIs.
Stars: 1248
AudioMuse-AI is a deep learning-based tool for audio analysis and music generation. It provides a user-friendly interface for processing audio data and generating music compositions. The tool utilizes state-of-the-art machine learning algorithms to analyze audio signals and extract meaningful features for music generation. With AudioMuse-AI, users can explore the possibilities of AI in music creation and experiment with different styles and genres. Whether you are a music enthusiast, a researcher, or a developer, AudioMuse-AI offers a versatile platform for audio analysis and music generation.
README:



AudioMuse-AI is an open-source, Dockerized environment that brings automatic playlist generation to your self-hosted music library. Using tools such as Librosa and ONNX, it performs sonic analysis on your audio files locally, allowing you to curate playlists for any mood or occasion without relying on external APIs.
Deploy it easily on your local machine with Docker Compose or Podman, or scale it in a Kubernetes cluster (supports AMD64 and ARM64). It integrates with the main music servers' APIs such as Jellyfin, Navidrome, LMS, Lyrion, and Emby. More integrations may be added in the future.
AudioMuse-AI lets you explore your music library in innovative ways, just start with an initial analysis, and you’ll unlock features like:
- Clustering: Automatically groups sonically similar songs, creating genre-defying playlists based on the music's actual sound.
- Instant Playlists: Simply tell the AI what you want to hear—like "high-tempo, low-energy music" and it will instantly generate a playlist for you.
- Music Map: Discover your music collection visually with a vibrant, genre-based 2D map.
- Playlist from Similar Songs: Pick a track you love, and AudioMuse-AI will find all the songs in your library that share its sonic signature, creating a new discovery playlist.
- Song Paths: Create a seamless listening journey between two songs. AudioMuse-AI finds the perfect tracks to bridge the sonic gap.
- Sonic Fingerprint: Generates playlists based on your listening habits, finding tracks similar to what you've been playing most often.
- Song Alchemy: Mix your ideal vibe, mark tracks as "ADD" or "SUBTRACT" to get a curated playlist and a 2D preview. Export the final selection directly to your media server.
- Text Search: search your song with simple text that can contains mood, instruments and genre like calm piano songs.
More information like ARCHITECTURE, ALGORITHM DESCRIPTION, DEPLOYMENT STRATEGY, FAQ, GPU DEPLOYMENT, HARDWARE REQUIREMENTS and CONFIGURATION PARAMETERS can be found in the docs folder.
The full list or AudioMuse-AI related repository are:
- AudioMuse-AI: the core application, it run Flask and Worker containers to actually run all the feature;
- AudioMuse-AI Helm Chart: helm chart for easy installation on Kubernetes;
- AudioMuse-AI Plugin for Jellyfin: Jellyfin Plugin;
- AudioMuse-AI Plugin for Navidrome: Navidrome Plugin;
- AudioMuse-AI MusicServer: Open Subosnic like Music Sever with integrated sonic functionality.
And now just some NEWS:
- Version 0.8.0 finaly out of BETA and with new CLAP model that enable the search of song by text that contains genre, instruments and moods.
Important: Despite the similar name, this project (AudioMuse-AI) is an independent, community-driven effort. It has no official connection to the website audiomuse.ai.
We are not affiliated with, endorsed by, or sponsored by the owners of audiomuse.ai.
- Quick Start Deployment
- Hardware Requirements
- Docker Image Tagging Strategy
- Key Technologies
- How To Contribute
- Star History
Get AudioMuse-AI running in minutes with Docker Compose.
If you need more deployment example take a look at DEPLOYMENT page.
For a full list of configuration parameter take a look at PARAMETERS page.
For the architecture design of AudioMuse-AI, take a look to the ARCHITECTURE page.
Prerequisites:
- Docker and Docker Compose installed
- A running media server (Jellyfin, Navidrome, Lyrion, or Emby)
- See Hardware Requirements
Steps:
-
Create your environment file:
cp deployment/.env.example deployment/.env
-
Edit
.envwith your media server credentials:For Jellyfin:
MEDIASERVER_TYPE=jellyfin JELLYFIN_URL=http://your-jellyfin-server:8096 JELLYFIN_USER_ID=your-user-id JELLYFIN_TOKEN=your-api-token
For Navidrome:
MEDIASERVER_TYPE=navidrome NAVIDROME_URL=http://your-navidrome-server:4533 NAVIDROME_USER=your-username NAVIDROME_PASSWORD=your-password
For Lyrion:
MEDIASERVER_TYPE=lyrion LYRION_URL=http://your-lyrion-server:9000
For Emby:
MEDIASERVER_TYPE=emby EMBY_URL=http://your-emby-server:8096 EMBY_USER_ID=your-user-id EMBY_TOKEN=your-api-token
-
Start the services:
docker compose -f deployment/docker-compose.yaml up -d
Remember to get the correct version for your Music Server.
docker-compose.yaml is for Jellyfin. You also have docker-compose-navidrome.yaml, docker-compose-lyrion.yaml, dokcer-compose-emby.yaml
Other example are for advanced deployment.
-
Access the application: Open your browser at
http://localhost:8000 -
Run your first analysis:
- Navigate to "Analysis and Clustering" page
- Click "Start Analysis" to scan your library
- Wait for completion, then explore features like clustering and music map
Stopping the services:
docker compose -f deployment/docker-compose.yaml downAudioMuse-AI has been tested on:
- Intel: HP Mini PC with Intel i5-6500, 16 GB RAM and NVMe SSD
- ARM: Raspberry Pi 5, 8 GB RAM and NVMe SSD / Mac Mini M4 16GB / Amphere based VM with 4core 8GB ram
Suggested requirements:
- CPU: 4-core Intel with AVX2 support (usually produced in 2015 or later) or ARM
- 8 GB RAM
- NVME SSD storage
You can check the Tested Hardware and Configuration notes to see which hardware has already been validated.
For more information about the GPU deployment requirements have a look to the GPU page.
Our GitHub Actions workflow automatically builds and publishes Docker images with the following tags:
-
:latestStable build from the main branch. Recommended for most users. -
:develDevelopment build from the devel branch. May be unstable — for testing and development only. -
:vX.Y.Z(e.g.:v1.0.0,:v0.1.4-alpha) Immutable images built from Git release tags. Ideal for reproducible or pinned deployments. -
-noavx2variants Experimental images for CPUs without AVX2 support, using legacy dependencies. Not recommended unless required for compatibility. -
-nvidiavariants Images that support the use of GPU for both Analysis and Clustering. Not recommended for old GPU.
AudioMuse AI is built upon a robust stack of open-source technologies:
- Flask: Provides the lightweight web interface for user interaction and API endpoints.
- Redis Queue (RQ): A simple Python library for queueing jobs and processing them in the background with Redis.
- Supervisord: Supervisor is a client/server system that allows its users to monitor and control a number of processes on UNIX-like operating systems.
- Essentia-tensorflow An open-source library for audio analysis, feature extraction, and music information retrieval. (used only until version v0.5.0-beta)
- MusicNN Tensorflow Audio Models from Essentia Leverages pre-trained MusicNN models for feature extraction and prediction. More details and models.
- Librosa Library for audio analysis, feature extraction, and music information retrieval. (used from version v0.6.0-beta)
- CLAP (Contrastive Language-Audio Pretraining) Neural network for audio-text matching, enabling natural language music search and text-based playlist generation.
- ONNX Open Neural Network Exchange format and ONNX Runtime for fast, portable, cross-platform model inference. (Used from v0.7.0-beta, replaces TensorFlow)
- Tensorflow Platform developed by Google for building, training, and deploying machine learning and deep learning models. (Used only in versions before v0.7.0-beta)
- scikit-learn Utilized for machine learning algorithms:
- voyager Approximate Nearest Neighbors used for the /similarity interface. Used from v0.6.3-beta
- PostgreSQL: A powerful, open-source relational database used for persisting:
- Ollama Enables self-hosting of various open-source Large Language Models (LLMs) for tasks like intelligent playlist naming.
- Docker / OCI-compatible Containers – The entire application is packaged as a container, ensuring consistent and portable deployment across environments.
Contributions, issues, and feature requests are welcome!
For more details on how to contribute please follow the Contributing Guidelines
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for AudioMuse-AI
Similar Open Source Tools
AudioMuse-AI
AudioMuse-AI is a deep learning-based tool for audio analysis and music generation. It provides a user-friendly interface for processing audio data and generating music compositions. The tool utilizes state-of-the-art machine learning algorithms to analyze audio signals and extract meaningful features for music generation. With AudioMuse-AI, users can explore the possibilities of AI in music creation and experiment with different styles and genres. Whether you are a music enthusiast, a researcher, or a developer, AudioMuse-AI offers a versatile platform for audio analysis and music generation.

easydiffusion
Easy Diffusion 3.0 is a user-friendly tool for installing and using Stable Diffusion on your computer. It offers hassle-free installation, clutter-free UI, task queue, intelligent model detection, live preview, image modifiers, multiple prompts file, saving generated images, UI themes, searchable models dropdown, and supports various image generation tasks like 'Text to Image', 'Image to Image', and 'InPainting'. The tool also provides advanced features such as custom models, merge models, custom VAE models, multi-GPU support, auto-updater, developer console, and more. It is designed for both new users and advanced users looking for powerful AI image generation capabilities.
pocketpal-ai
PocketPal AI is a versatile virtual assistant tool designed to streamline daily tasks and enhance productivity. It leverages artificial intelligence technology to provide personalized assistance in managing schedules, organizing information, setting reminders, and more. With its intuitive interface and smart features, PocketPal AI aims to simplify users' lives by automating routine activities and offering proactive suggestions for optimal time management and task prioritization.
refact
This repository contains Refact WebUI for fine-tuning and self-hosting of code models, which can be used inside Refact plugins for code completion and chat. Users can fine-tune open-source code models, self-host them, download and upload Lloras, use models for code completion and chat inside Refact plugins, shard models, host multiple small models on one GPU, and connect GPT-models for chat using OpenAI and Anthropic keys. The repository provides a Docker container for running the self-hosted server and supports various models for completion, chat, and fine-tuning. Refact is free for individuals and small teams under the BSD-3-Clause license, with custom installation options available for GPU support. The community and support include contributing guidelines, GitHub issues for bugs, a community forum, Discord for chatting, and Twitter for product news and updates.

AIOStreams
AIOStreams is a versatile tool that combines streams from various addons into one platform, offering extensive customization options. Users can change result formats, filter results by various criteria, remove duplicates, prioritize services, sort results, specify size limits, and more. The tool scrapes results from selected addons, applies user configurations, and presents the results in a unified manner. It simplifies the process of finding and accessing desired content from multiple sources, enhancing user experience and efficiency.
WritingTools
Writing Tools is an Apple Intelligence-inspired application for Windows, Linux, and macOS that supercharges your writing with an AI LLM. It allows users to instantly proofread, optimize text, and summarize content from webpages, YouTube videos, documents, etc. The tool is privacy-focused, open-source, and supports multiple languages. It offers powerful features like grammar correction, content summarization, and LLM chat mode, making it a versatile writing assistant for various tasks.
SAM
SAM is a native macOS AI assistant built with Swift and SwiftUI, designed for non-developers who want powerful tools in their everyday life. It provides real assistance, smart memory, voice control, image generation, and custom AI model training. SAM keeps your data on your Mac, supports multiple AI providers, and offers features for documents, creativity, writing, organization, learning, and more. It is privacy-focused, user-friendly, and accessible from various devices. SAM stands out with its privacy-first approach, intelligent memory, task execution capabilities, powerful tools, image generation features, custom AI model training, and flexible AI provider support.

deepnote
Deepnote is a data notebook tool designed for the AI era, used by over 500,000 data professionals at companies like Estée Lauder, SoundCloud, Statsig, and Gusto. It offers a human-readable format, block-based architecture, reactive notebook execution, and effortless conversion between .ipynb and .deepnote formats. Deepnote extends Jupyter with features like native AI agent, Git integration, cloud compute, and native database & API connections. The repository contains reusable packages and libraries for Deepnote's notebook, runtime, and collaboration features.
Linguflex
Linguflex is a project that aims to simulate engaging, authentic, human-like interaction with AI personalities. It offers voice-based conversation with custom characters, alongside an array of practical features such as controlling smart home devices, playing music, searching the internet, fetching emails, displaying current weather information and news, assisting in scheduling, and searching or generating images.
whispering-ui
Whispering Tiger UI is a Native-UI tool designed to control the Whispering Tiger application, a free and Open-Source tool that can listen/watch to audio streams or in-game images on your machine and provide transcription or translation to a web browser using Websockets or over OSC. It features a Native-UI for Windows, easy access to all Whispering Tiger features including transcription, translation, text-to-speech, and in-game image recognition. The tool supports loopback audio device, configuration saving/loading, plugin support for additional features, and auto-update functionality. Users can create profiles, configure audio devices, select A.I. devices for speech-to-text, and install/manage plugins for extended functionality.

ai-flow
AI Flow is an open-source, user-friendly UI application that empowers you to seamlessly connect multiple AI models together, specifically leveraging the capabilities of multiples AI APIs such as OpenAI, StabilityAI and Replicate. In a nutshell, AI Flow provides a visual platform for crafting and managing AI-driven workflows, thereby facilitating diverse and dynamic AI interactions.
obsidian-llmsider
LLMSider is an AI assistant plugin for Obsidian that offers flexible multi-model support, deep workflow integration, privacy-first design, and a professional tool ecosystem. It provides comprehensive AI capabilities for personal knowledge management, from intelligent writing assistance to complex task automation, making AI a capable assistant for thinking and creating while ensuring data privacy.

CushyStudio
CushyStudio is a generative AI platform designed for creatives of any level to effortlessly create stunning images, videos, and 3D models. It offers CushyApps, a collection of visual tools tailored for different artistic tasks, and CushyKit, an extensive toolkit for custom apps development and task automation. Users can dive into the AI revolution, unleash their creativity, share projects, and connect with a vibrant community. The platform aims to simplify the AI art creation process and provide a user-friendly environment for designing interfaces, adding custom logic, and accessing various tools.
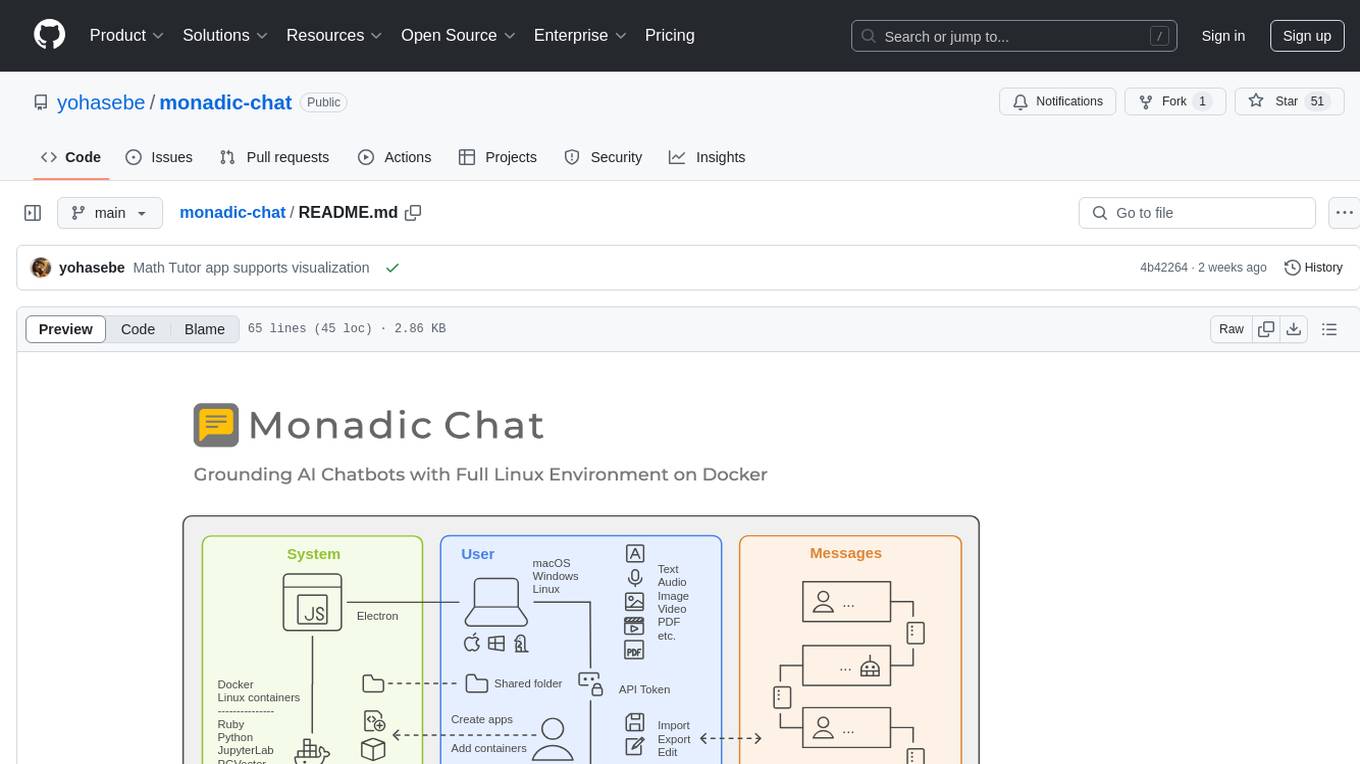
monadic-chat
Monadic Chat is a locally hosted web application designed to create and utilize intelligent chatbots. It provides a Linux environment on Docker to GPT and other LLMs, enabling the execution of advanced tasks that require external tools. The tool supports voice interaction, image and video recognition and generation, and AI-to-AI chat, making it useful for using AI and developing various applications. It is available for Mac, Windows, and Linux (Debian/Ubuntu) with easy-to-use installers.

TaskingAI
TaskingAI brings Firebase's simplicity to **AI-native app development**. The platform enables the creation of GPTs-like multi-tenant applications using a wide range of LLMs from various providers. It features distinct, modular functions such as Inference, Retrieval, Assistant, and Tool, seamlessly integrated to enhance the development process. TaskingAI’s cohesive design ensures an efficient, intelligent, and user-friendly experience in AI application development.
RWKV_APP
RWKV App is an experimental application that enables users to run Large Language Models (LLMs) offline on their edge devices. It offers a privacy-first, on-device LLM experience for everyday devices. Users can engage in multi-turn conversations, text-to-speech, visual understanding, and more, all without requiring an internet connection. The app supports switching between different models, running locally without internet, and exploring various AI tasks such as chat, speech generation, and visual understanding. It is built using Flutter and Dart FFI for cross-platform compatibility and efficient communication with the C++ inference engine. The roadmap includes integrating features into the RWKV Chat app, supporting more model weights, hardware, operating systems, and devices.
For similar tasks

RVC_CLI
**RVC_CLI: Retrieval-based Voice Conversion Command Line Interface** This command-line interface (CLI) provides a comprehensive set of tools for voice conversion, enabling you to modify the pitch, timbre, and other characteristics of audio recordings. It leverages advanced machine learning models to achieve realistic and high-quality voice conversions. **Key Features:** * **Inference:** Convert the pitch and timbre of audio in real-time or process audio files in batch mode. * **TTS Inference:** Synthesize speech from text using a variety of voices and apply voice conversion techniques. * **Training:** Train custom voice conversion models to meet specific requirements. * **Model Management:** Extract, blend, and analyze models to fine-tune and optimize performance. * **Audio Analysis:** Inspect audio files to gain insights into their characteristics. * **API:** Integrate the CLI's functionality into your own applications or workflows. **Applications:** The RVC_CLI finds applications in various domains, including: * **Music Production:** Create unique vocal effects, harmonies, and backing vocals. * **Voiceovers:** Generate voiceovers with different accents, emotions, and styles. * **Audio Editing:** Enhance or modify audio recordings for podcasts, audiobooks, and other content. * **Research and Development:** Explore and advance the field of voice conversion technology. **For Jobs:** * Audio Engineer * Music Producer * Voiceover Artist * Audio Editor * Machine Learning Engineer **AI Keywords:** * Voice Conversion * Pitch Shifting * Timbre Modification * Machine Learning * Audio Processing **For Tasks:** * Convert Pitch * Change Timbre * Synthesize Speech * Train Model * Analyze Audio
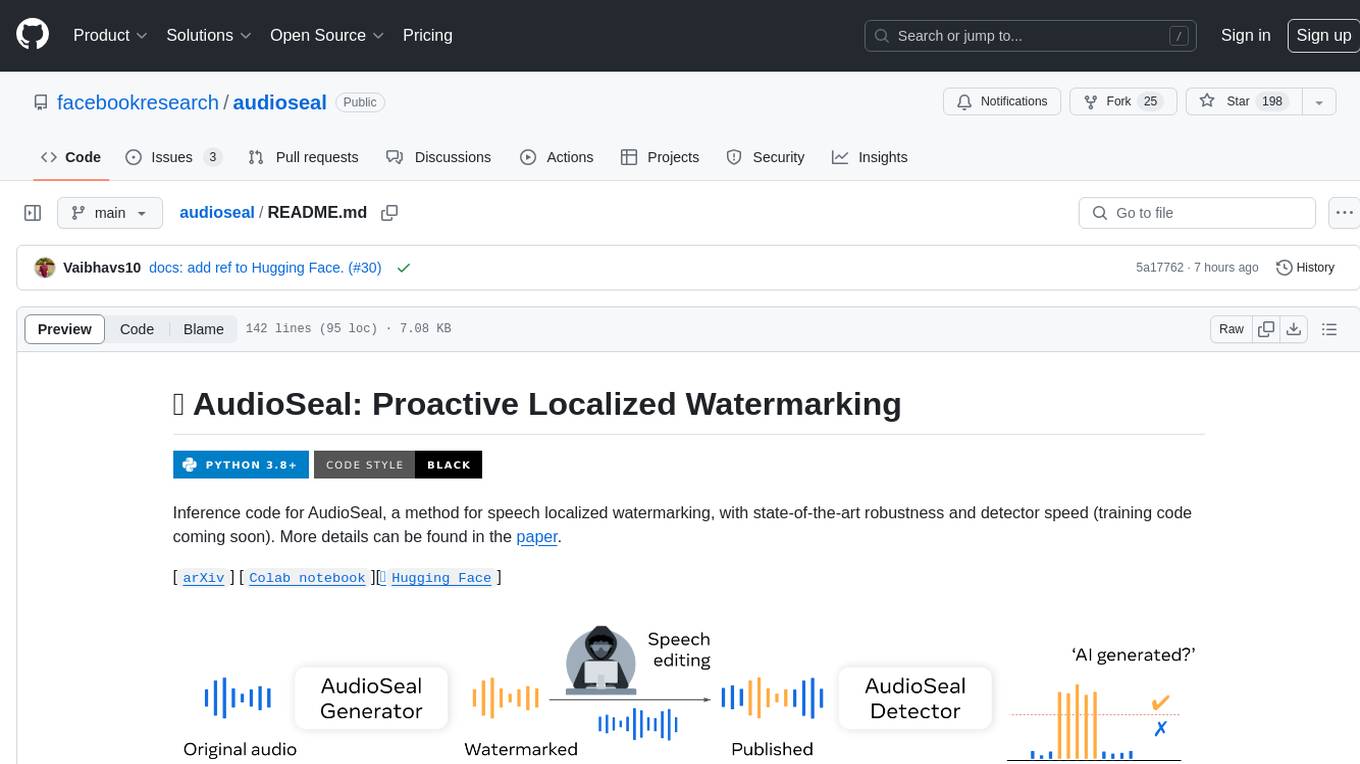
audioseal
AudioSeal is a method for speech localized watermarking, designed with state-of-the-art robustness and detector speed. It jointly trains a generator to embed a watermark in audio and a detector to detect watermarked fragments in longer audios, even in the presence of editing. The tool achieves top-notch detection performance at the sample level, generates minimal alteration of signal quality, and is robust to various audio editing types. With a fast, single-pass detector, AudioSeal surpasses existing models in speed, making it ideal for large-scale and real-time applications.
SLAM-LLM
SLAM-LLM is a deep learning toolkit designed for researchers and developers to train custom multimodal large language models (MLLM) focusing on speech, language, audio, and music processing. It provides detailed recipes for training and high-performance checkpoints for inference. The toolkit supports tasks such as automatic speech recognition (ASR), text-to-speech (TTS), visual speech recognition (VSR), automated audio captioning (AAC), spatial audio understanding, and music caption (MC). SLAM-LLM features easy extension to new models and tasks, mixed precision training for faster training with less GPU memory, multi-GPU training with data and model parallelism, and flexible configuration based on Hydra and dataclass.
freegenius
FreeGenius AI is an ambitious project offering a comprehensive suite of AI solutions that mirror the capabilities of LetMeDoIt AI. It is designed to engage in intuitive conversations, execute codes, provide up-to-date information, and perform various tasks. The tool is free, customizable, and provides access to real-time data and device information. It aims to support offline and online backends, open-source large language models, and optional API keys. Users can use FreeGenius AI for tasks like generating tweets, analyzing audio, searching financial data, checking weather, and creating maps.

RVC_CLI
RVC_CLI is a command line interface tool for retrieval-based voice conversion. It provides functionalities for installation, getting started, inference, training, UVR, additional features, and API integration. Users can perform tasks like single inference, batch inference, TTS inference, preprocess dataset, extract features, start training, generate index file, model extract, model information, model blender, launch TensorBoard, download models, audio analyzer, and prerequisites download. The tool is built on various projects like ContentVec, HIFIGAN, audio-slicer, python-audio-separator, RMVPE, FCPE, VITS, So-Vits-SVC, Harmonify, and others.

towhee
Towhee is a cutting-edge framework designed to streamline the processing of unstructured data through the use of Large Language Model (LLM) based pipeline orchestration. It can extract insights from diverse data types like text, images, audio, and video files using generative AI and deep learning models. Towhee offers rich operators, prebuilt ETL pipelines, and a high-performance backend for efficient data processing. With a Pythonic API, users can build custom data processing pipelines easily. Towhee is suitable for tasks like sentence embedding, image embedding, video deduplication, question answering with documents, and cross-modal retrieval based on CLIP.
chatwise-releases
ChatWise is an offline tool that supports various AI models such as OpenAI, Anthropic, Google AI, Groq, and Ollama. It is multi-modal, allowing text-to-speech powered by OpenAI and ElevenLabs. The tool supports text files, PDFs, audio, and images across different models. ChatWise is currently available for macOS (Apple Silicon & Intel) with Windows support coming soon.
AudioMuse-AI
AudioMuse-AI is a deep learning-based tool for audio analysis and music generation. It provides a user-friendly interface for processing audio data and generating music compositions. The tool utilizes state-of-the-art machine learning algorithms to analyze audio signals and extract meaningful features for music generation. With AudioMuse-AI, users can explore the possibilities of AI in music creation and experiment with different styles and genres. Whether you are a music enthusiast, a researcher, or a developer, AudioMuse-AI offers a versatile platform for audio analysis and music generation.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.