
browser-use
🌐 Make websites accessible for AI agents. Automate tasks online with ease.
Stars: 78042

Browser Use is a tool designed to make websites accessible for AI agents. It provides an easy way to connect AI agents with the browser, enabling users to perform tasks such as extracting vision and HTML elements, managing multiple tabs, and executing custom actions. The tool supports various language models and allows users to parallelize multiple agents for efficient processing. With features like self-correction and the ability to register custom actions, Browser Use offers a versatile solution for interacting with web content using AI technology.
README:







🌤️ Want to skip the setup? Use our cloud for faster, scalable, stealth-enabled browser automation!
- Direct your favorite coding agent (Cursor, Claude Code, etc) to Agents.md
- Prompt away!
1. Create environment with uv (Python>=3.11):
uv init2. Install Browser-Use package:
# We ship every day - use the latest version!
uv add browser-use
uv sync3. Get your API key from Browser Use Cloud and add it to your .env file (new signups get $10 free credits):
# .env
BROWSER_USE_API_KEY=your-key
4. Install Chromium browser:
uvx browser-use install5. Run your first agent:
from browser_use import Agent, Browser, ChatBrowserUse
import asyncio
async def example():
browser = Browser(
# use_cloud=True, # Uncomment to use a stealth browser on Browser Use Cloud
)
llm = ChatBrowserUse()
agent = Agent(
task="Find the number of stars of the browser-use repo",
llm=llm,
browser=browser,
)
history = await agent.run()
return history
if __name__ == "__main__":
history = asyncio.run(example())Check out the library docs and the cloud docs for more!
We handle agents, browsers, persistence, auth, cookies, and LLMs. The agent runs right next to the browser for minimal latency.
from browser_use import Browser, sandbox, ChatBrowserUse
from browser_use.agent.service import Agent
import asyncio
@sandbox()
async def my_task(browser: Browser):
agent = Agent(task="Find the top HN post", browser=browser, llm=ChatBrowserUse())
await agent.run()
# Just call it like any async function
asyncio.run(my_task())See Going to Production for more details.
Want to get started even faster? Generate a ready-to-run template:
uvx browser-use init --template defaultThis creates a browser_use_default.py file with a working example. Available templates:
-
default- Minimal setup to get started quickly -
advanced- All configuration options with detailed comments -
tools- Examples of custom tools and extending the agent
You can also specify a custom output path:
uvx browser-use init --template default --output my_agent.pyFast, persistent browser automation from the command line:
browser-use open https://example.com # Navigate to URL
browser-use state # See clickable elements
browser-use click 5 # Click element by index
browser-use type "Hello" # Type text
browser-use screenshot page.png # Take screenshot
browser-use close # Close browserThe CLI keeps the browser running between commands for fast iteration. See CLI docs for all commands.
For Claude Code, install the skill to enable AI-assisted browser automation:
mkdir -p ~/.claude/skills/browser-use
curl -o ~/.claude/skills/browser-use/SKILL.md \
https://raw.githubusercontent.com/browser-use/browser-use/main/skills/browser-use/SKILL.mdhttps://github.com/user-attachments/assets/a6813fa7-4a7c-40a6-b4aa-382bf88b1850
https://github.com/user-attachments/assets/ac34f75c-057a-43ef-ad06-5b2c9d42bf06
💡See more examples here ↗ and give us a star!
Integrations, hosting, custom tools, MCP, and more on our Docs ↗
What's the best model to use?
We optimized ChatBrowserUse() specifically for browser automation tasks. On avg it completes tasks 3-5x faster than other models with SOTA accuracy.
Pricing (per 1M tokens):
- Input tokens: $0.20
- Cached input tokens: $0.02
- Output tokens: $2.00
For other LLM providers, see our supported models documentation.
Can I use custom tools with the agent?
Yes! You can add custom tools to extend the agent's capabilities:
from browser_use import Tools
tools = Tools()
@tools.action(description='Description of what this tool does.')
def custom_tool(param: str) -> str:
return f"Result: {param}"
agent = Agent(
task="Your task",
llm=llm,
browser=browser,
tools=tools,
)Can I use this for free?
Yes! Browser-Use is open source and free to use. You only need to choose an LLM provider (like OpenAI, Google, ChatBrowserUse, or run local models with Ollama).
How do I handle authentication?
Check out our authentication examples:
- Using real browser profiles - Reuse your existing Chrome profile with saved logins
- If you want to use temporary accounts with inbox, choose AgentMail
- To sync your auth profile with the remote browser, run
curl -fsSL https://browser-use.com/profile.sh | BROWSER_USE_API_KEY=XXXX sh(replace XXXX with your API key)
These examples show how to maintain sessions and handle authentication seamlessly.
How do I solve CAPTCHAs?
For CAPTCHA handling, you need better browser fingerprinting and proxies. Use Browser Use Cloud which provides stealth browsers designed to avoid detection and CAPTCHA challenges.
How do I go into production?
Chrome can consume a lot of memory, and running many agents in parallel can be tricky to manage.
For production use cases, use our Browser Use Cloud API which handles:
- Scalable browser infrastructure
- Memory management
- Proxy rotation
- Stealth browser fingerprinting
- High-performance parallel execution
Tell your computer what to do, and it gets it done.


For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for browser-use
Similar Open Source Tools
browser-use
Browser Use is a tool designed to make websites accessible for AI agents. It provides an easy way to connect AI agents with the browser, enabling users to perform tasks such as extracting vision and HTML elements, managing multiple tabs, and executing custom actions. The tool supports various language models and allows users to parallelize multiple agents for efficient processing. With features like self-correction and the ability to register custom actions, Browser Use offers a versatile solution for interacting with web content using AI technology.
better-chatbot
Better Chatbot is an open-source AI chatbot designed for individuals and teams, inspired by various AI models. It integrates major LLMs, offers powerful tools like MCP protocol and data visualization, supports automation with custom agents and visual workflows, enables collaboration by sharing configurations, provides a voice assistant feature, and ensures an intuitive user experience. The platform is built with Vercel AI SDK and Next.js, combining leading AI services into one platform for enhanced chatbot capabilities.
VibeSurf
VibeSurf is an open-source AI agentic browser that combines workflow automation with intelligent AI agents, offering faster, cheaper, and smarter browser automation. It allows users to create revolutionary browser workflows, run multiple AI agents in parallel, perform intelligent AI automation tasks, maintain privacy with local LLM support, and seamlessly integrate as a Chrome extension. Users can save on token costs, achieve efficiency gains, and enjoy deterministic workflows for consistent and accurate results. VibeSurf also provides a Docker image for easy deployment and offers pre-built workflow templates for common tasks.
Free-GPT4-WEB-API
FreeGPT4-WEB-API is a Python server that allows you to have a self-hosted GPT-4 Unlimited and Free WEB API, via the latest Bing's AI. It uses Flask and GPT4Free libraries. GPT4Free provides an interface to the Bing's GPT-4. The server can be configured by editing the `FreeGPT4_Server.py` file. You can change the server's port, host, and other settings. The only cookie needed for the Bing model is `_U`.

DevoxxGenieIDEAPlugin
Devoxx Genie is a Java-based IntelliJ IDEA plugin that integrates with local and cloud-based LLM providers to aid in reviewing, testing, and explaining project code. It supports features like code highlighting, chat conversations, and adding files/code snippets to context. Users can modify REST endpoints and LLM parameters in settings, including support for cloud-based LLMs. The plugin requires IntelliJ version 2023.3.4 and JDK 17. Building and publishing the plugin is done using Gradle tasks. Users can select an LLM provider, choose code, and use commands like review, explain, or generate unit tests for code analysis.
Scrapling
Scrapling is a high-performance, intelligent web scraping library for Python that automatically adapts to website changes while significantly outperforming popular alternatives. For both beginners and experts, Scrapling provides powerful features while maintaining simplicity. It offers features like fast and stealthy HTTP requests, adaptive scraping with smart element tracking and flexible selection, high performance with lightning-fast speed and memory efficiency, and developer-friendly navigation API and rich text processing. It also includes advanced parsing features like smart navigation, content-based selection, handling structural changes, and finding similar elements. Scrapling is designed to handle anti-bot protections and website changes effectively, making it a versatile tool for web scraping tasks.
pyspur
PySpur is a graph-based editor designed for LLM (Large Language Models) workflows. It offers modular building blocks, node-level debugging, and performance evaluation. The tool is easy to hack, supports JSON configs for workflow graphs, and is lightweight with minimal dependencies. Users can quickly set up PySpur by cloning the repository, creating a .env file, starting docker services, and accessing the portal. PySpur can also work with local models served using Ollama, with steps provided for configuration. The roadmap includes features like canvas, async/batch execution, support for Ollama, new nodes, pipeline optimization, templates, code compilation, multimodal support, and more.

bytebot
Bytebot is an open-source AI desktop agent that provides a virtual employee with its own computer to complete tasks for users. It can use various applications, download and organize files, log into websites, process documents, and perform complex multi-step workflows. By giving AI access to a complete desktop environment, Bytebot unlocks capabilities not possible with browser-only agents or API integrations, enabling complete task autonomy, document processing, and usage of real applications.
hyper-mcp
hyper-mcp is a fast and secure MCP server that extends its capabilities through WebAssembly plugins. It makes it easy to add AI capabilities to applications by allowing users to write plugins in any language that compiles to WebAssembly, distribute them via standard OCI registries, and run them anywhere from cloud to edge. The tool is built with a security-first mindset, offering sandboxed plugins, memory-safe execution, secure plugin distribution, and fine-grained access control for host functions. Users can deploy hyper-mcp anywhere, benefit from cross-platform compatibility, and prevent tool name collisions with the support tool name prefix feature.
actionbook
Actionbook is a browser action engine designed for AI agents, providing up-to-date action manuals and DOM structure to enable instant website operations without guesswork. It offers faster execution, token savings, resilient automation, and universal compatibility, making it ideal for building reliable browser agents. Actionbook integrates seamlessly with AI coding assistants and offers three integration methods: CLI, MCP Server, and JavaScript SDK. The tool is well-documented and actively developed in a monorepo setup using pnpm workspaces and Turborepo.
infinite-image-browsing
Infinite Image Browsing (IIB) is a versatile tool that offers excellent performance in displaying images, supports image search and favorite functionalities, allows viewing images/videos with various features like full-screen preview and sending to other tabs, provides multiple usage methods including extension installation, standalone Python usage, and desktop application, supports TikTok-style view, walk mode for automatic loading of folders, preview based on file tree structure, image comparison, topic/tag analysis, smart file organization, multilingual support, privacy and security features, packaging/batch download, keyboard shortcuts, and AI integration. The tool also offers natural language categorization and search capabilities, with API endpoints for embedding, clustering, and prompt retrieval. It supports caching and incremental updates for efficient processing and offers various configuration options through environment variables.
farfalle
Farfalle is an open-source AI-powered search engine that allows users to run their own local LLM or utilize the cloud. It provides a tech stack including Next.js for frontend, FastAPI for backend, Tavily for search API, Logfire for logging, and Redis for rate limiting. Users can get started by setting up prerequisites like Docker and Ollama, and obtaining API keys for Tavily, OpenAI, and Groq. The tool supports models like llama3, mistral, and gemma. Users can clone the repository, set environment variables, run containers using Docker Compose, and deploy the backend and frontend using services like Render and Vercel.
gaia-ui
A collection of production-ready UI components designed specifically for building AI assistants and chatbots. These components are battle-tested in production at GAIA, designed to handle edge cases and real-world scenarios, accessible, responsive, and performant. The library focuses on quality over quantity, offering components that solve real problems better than existing alternatives. Users can easily add components to their projects using the provided commands, and the library is actively being developed and refined for better compatibility and smaller bundle sizes.
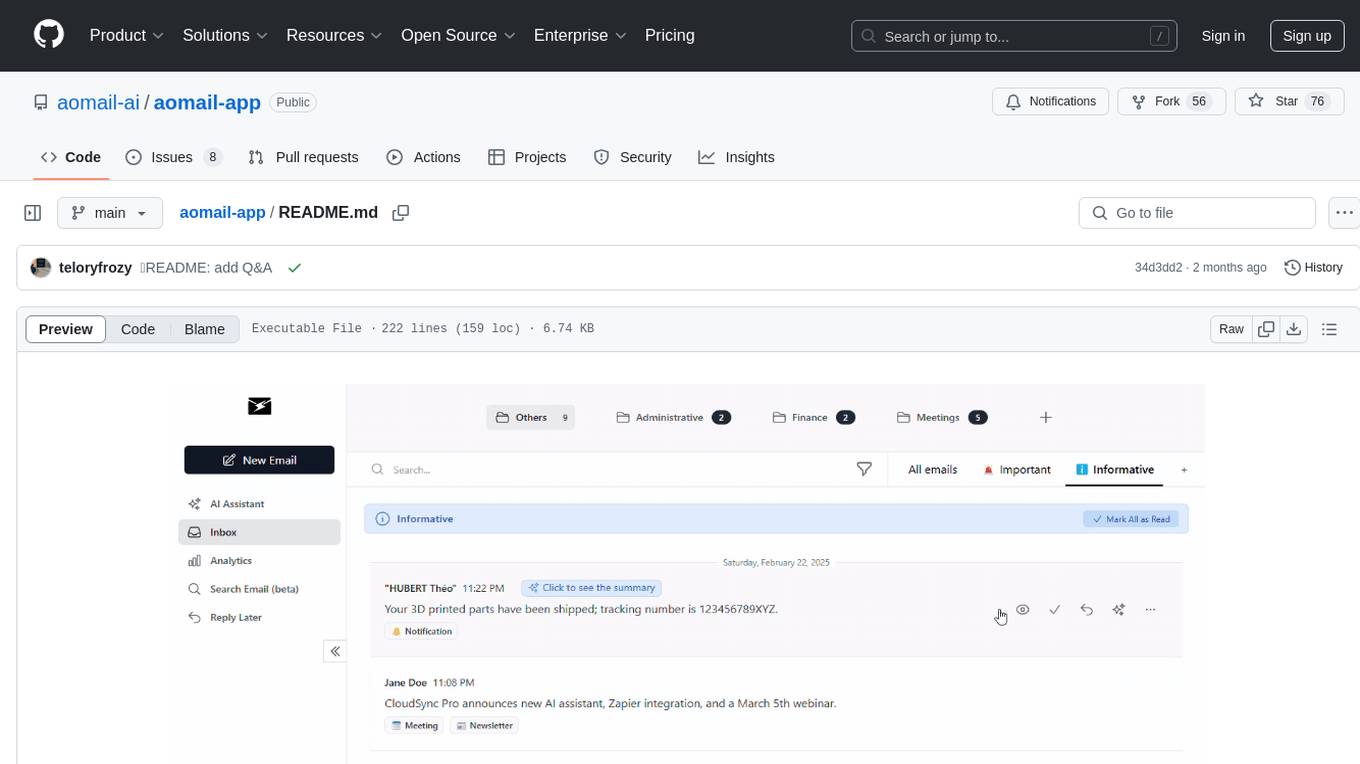
aomail-app
Aomail is an intelligent, open-source email management platform with AI capabilities. It offers email provider integration, AI-powered tools for smart categorization and assistance, analytics and management features. Users can self-host for complete control. Coming soon features include AI custom rules, platform integration with Discord & Slack, and support for various AI providers. The tool is designed to revolutionize email management by providing advanced AI features and analytics.
tingly-box
Tingly Box is a tool that helps in deciding which model to call, compressing context, and routing requests efficiently. It offers secure, reliable, and customizable functional extensions. With features like unified API, smart routing, context compression, auto API translation, blazing fast performance, flexible authentication, visual control panel, and client-side usage stats, Tingly Box provides a comprehensive solution for managing AI models and tokens. It supports integration with various IDEs, CLI tools, SDKs, and AI applications, making it versatile and easy to use. The tool also allows seamless integration with OAuth providers like Claude Code, enabling users to utilize existing quotas in OpenAI-compatible tools. Tingly Box aims to simplify AI model management and usage by providing a single endpoint for multiple providers with minimal configuration, promoting seamless integration with SDKs and CLI tools.
Devon
Devon is an open-source pair programmer tool designed to facilitate collaborative coding sessions. It provides features such as multi-file editing, codebase exploration, test writing, bug fixing, and architecture exploration. The tool supports Anthropic, OpenAI, and Groq APIs, with plans to add more models in the future. Devon is community-driven, with ongoing development goals including multi-model support, plugin system for tool builders, self-hostable Electron app, and setting SOTA on SWE-bench Lite. Users can contribute to the project by developing core functionality, conducting research on agent performance, providing feedback, and testing the tool.
For similar tasks

skyvern
Skyvern automates browser-based workflows using LLMs and computer vision. It provides a simple API endpoint to fully automate manual workflows, replacing brittle or unreliable automation solutions. Traditional approaches to browser automations required writing custom scripts for websites, often relying on DOM parsing and XPath-based interactions which would break whenever the website layouts changed. Instead of only relying on code-defined XPath interactions, Skyvern adds computer vision and LLMs to the mix to parse items in the viewport in real-time, create a plan for interaction and interact with them. This approach gives us a few advantages: 1. Skyvern can operate on websites it’s never seen before, as it’s able to map visual elements to actions necessary to complete a workflow, without any customized code 2. Skyvern is resistant to website layout changes, as there are no pre-determined XPaths or other selectors our system is looking for while trying to navigate 3. Skyvern leverages LLMs to reason through interactions to ensure we can cover complex situations. Examples include: 1. If you wanted to get an auto insurance quote from Geico, the answer to a common question “Were you eligible to drive at 18?” could be inferred from the driver receiving their license at age 16 2. If you were doing competitor analysis, it’s understanding that an Arnold Palmer 22 oz can at 7/11 is almost definitely the same product as a 23 oz can at Gopuff (even though the sizes are slightly different, which could be a rounding error!) Want to see examples of Skyvern in action? Jump to #real-world-examples-of- skyvern

airbyte-connectors
This repository contains Airbyte connectors used in Faros and Faros Community Edition platforms as well as Airbyte Connector Development Kit (CDK) for JavaScript/TypeScript.

open-parse
Open Parse is a Python library for visually discerning document layouts and chunking them effectively. It is designed to fill the gap in open-source libraries for handling complex documents. Unlike text splitting, which converts a file to raw text and slices it up, Open Parse visually analyzes documents for superior LLM input. It also supports basic markdown for parsing headings, bold, and italics, and has high-precision table support, extracting tables into clean Markdown formats with accuracy that surpasses traditional tools. Open Parse is extensible, allowing users to easily implement their own post-processing steps. It is also intuitive, with great editor support and completion everywhere, making it easy to use and learn.

unstract
Unstract is a no-code platform that enables users to launch APIs and ETL pipelines to structure unstructured documents. With Unstract, users can go beyond co-pilots by enabling machine-to-machine automation. Unstract's Prompt Studio provides a simple, no-code approach to creating prompts for LLMs, vector databases, embedding models, and text extractors. Users can then configure Prompt Studio projects as API deployments or ETL pipelines to automate critical business processes that involve complex documents. Unstract supports a wide range of LLM providers, vector databases, embeddings, text extractors, ETL sources, and ETL destinations, providing users with the flexibility to choose the best tools for their needs.

Dot
Dot is a standalone, open-source application designed for seamless interaction with documents and files using local LLMs and Retrieval Augmented Generation (RAG). It is inspired by solutions like Nvidia's Chat with RTX, providing a user-friendly interface for those without a programming background. Pre-packaged with Mistral 7B, Dot ensures accessibility and simplicity right out of the box. Dot allows you to load multiple documents into an LLM and interact with them in a fully local environment. Supported document types include PDF, DOCX, PPTX, XLSX, and Markdown. Users can also engage with Big Dot for inquiries not directly related to their documents, similar to interacting with ChatGPT. Built with Electron JS, Dot encapsulates a comprehensive Python environment that includes all necessary libraries. The application leverages libraries such as FAISS for creating local vector stores, Langchain, llama.cpp & Huggingface for setting up conversation chains, and additional tools for document management and interaction.

instructor
Instructor is a Python library that makes it a breeze to work with structured outputs from large language models (LLMs). Built on top of Pydantic, it provides a simple, transparent, and user-friendly API to manage validation, retries, and streaming responses. Get ready to supercharge your LLM workflows!

sparrow
Sparrow is an innovative open-source solution for efficient data extraction and processing from various documents and images. It seamlessly handles forms, invoices, receipts, and other unstructured data sources. Sparrow stands out with its modular architecture, offering independent services and pipelines all optimized for robust performance. One of the critical functionalities of Sparrow - pluggable architecture. You can easily integrate and run data extraction pipelines using tools and frameworks like LlamaIndex, Haystack, or Unstructured. Sparrow enables local LLM data extraction pipelines through Ollama or Apple MLX. With Sparrow solution you get API, which helps to process and transform your data into structured output, ready to be integrated with custom workflows. Sparrow Agents - with Sparrow you can build independent LLM agents, and use API to invoke them from your system. **List of available agents:** * **llamaindex** - RAG pipeline with LlamaIndex for PDF processing * **vllamaindex** - RAG pipeline with LLamaIndex multimodal for image processing * **vprocessor** - RAG pipeline with OCR and LlamaIndex for image processing * **haystack** - RAG pipeline with Haystack for PDF processing * **fcall** - Function call pipeline * **unstructured-light** - RAG pipeline with Unstructured and LangChain, supports PDF and image processing * **unstructured** - RAG pipeline with Weaviate vector DB query, Unstructured and LangChain, supports PDF and image processing * **instructor** - RAG pipeline with Unstructured and Instructor libraries, supports PDF and image processing. Works great for JSON response generation

Open-DocLLM
Open-DocLLM is an open-source project that addresses data extraction and processing challenges using OCR and LLM technologies. It consists of two main layers: OCR for reading document content and LLM for extracting specific content in a structured manner. The project offers a larger context window size compared to JP Morgan's DocLLM and integrates tools like Tesseract OCR and Mistral for efficient data analysis. Users can run the models on-premises using LLM studio or Ollama, and the project includes a FastAPI app for testing purposes.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.