
text-extract-api
Document (PDF, Word, PPTX ...) extraction and parse API using state of the art modern OCRs + Ollama supported models. Anonymize documents. Remove PII. Convert any document or picture to structured JSON or Markdown
Stars: 2068
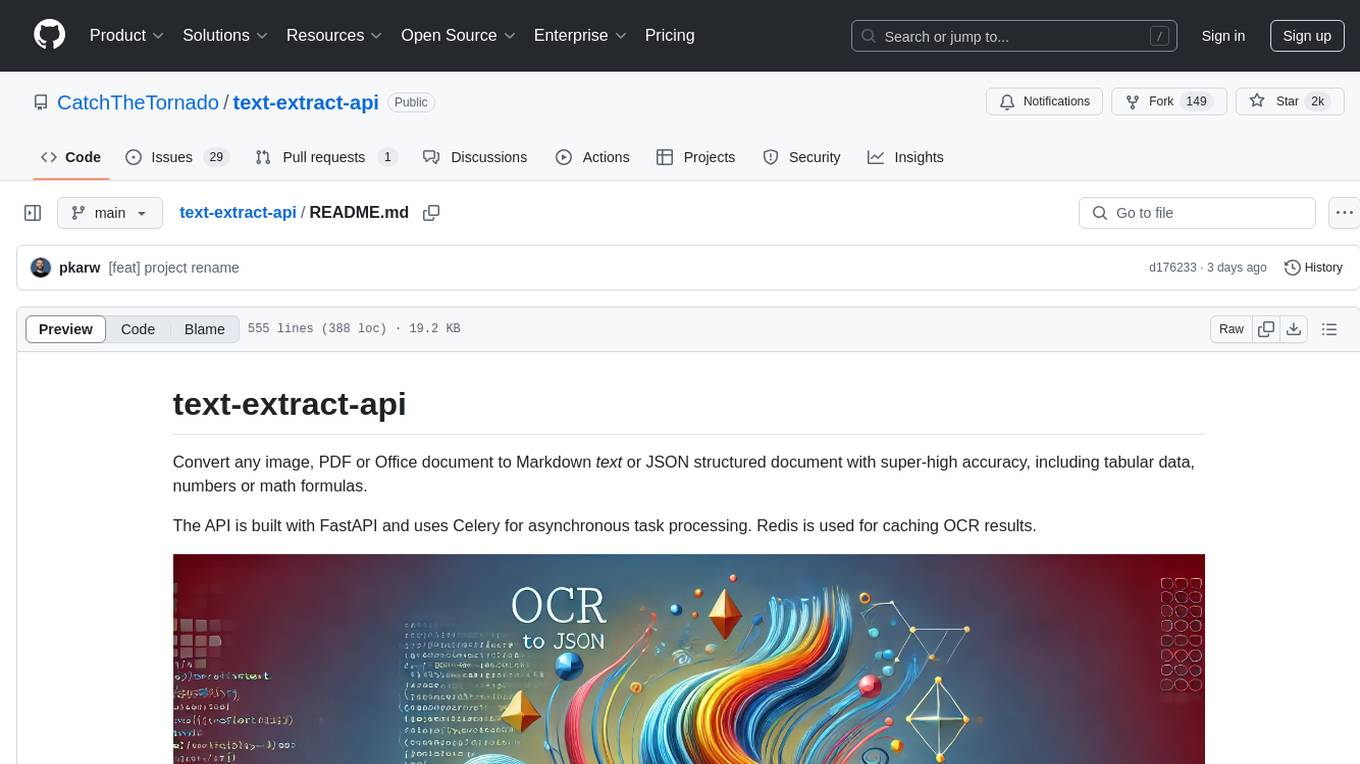
The text-extract-api is a powerful tool that allows users to convert images, PDFs, or Office documents to Markdown text or JSON structured documents with high accuracy. It is built using FastAPI and utilizes Celery for asynchronous task processing, with Redis for caching OCR results. The tool provides features such as PDF/Office to Markdown and JSON conversion, improving OCR results with LLama, removing Personally Identifiable Information from documents, distributed queue processing, caching using Redis, switchable storage strategies, and a CLI tool for task management. Users can run the tool locally or on cloud services, with support for GPU processing. The tool also offers an online demo for testing purposes.
README:
Convert any image, PDF or Office document to Markdown text or JSON structured document with super-high accuracy, including tabular data, numbers or math formulas.
The API is built with FastAPI and uses Celery for asynchronous task processing. Redis is used for caching OCR results.

-
No Cloud/external dependencies all you need: PyTorch based OCR (EasyOCR) + Ollama are shipped and configured via
docker-composeno data is sent outside your dev/server environment, - PDF/Office to Markdown conversion with very high accuracy using different OCR strategies including llama3.2-vision, easyOCR
- PDF/Office to JSON conversion using Ollama supported models (eg. LLama 3.1)
- LLM Improving OCR results LLama is pretty good with fixing spelling and text issues in the OCR text
-
Removing PII This tool can be used for removing Personally Identifiable Information out of document - see
examples - Distributed queue processing using Celery)
- Caching using Redis - the OCR results can be easily cached prior to LLM processing,
- Storage Strategies switchable storage strategies (Google Drive, Local File System ...)
- CLI tool for sending tasks and processing results
Converting MRI report to Markdown + JSON.
python client/cli.py ocr_upload --file examples/example-mri.pdf --prompt_file examples/example-mri-2-json-prompt.txtBefore running the example see getting started

Converting Invoice to JSON and remove PII
python client/cli.py ocr_upload --file examples/example-invoice.pdf --prompt_file examples/example-invoice-remove-pii.txt Before running the example see getting started

You might want to run the app directly on your machine for development purposes OR to use for example Apple GPUs (which are not supported by Docker at the moment).
To have it up and running please execute the following steps:
Download and install Ollama Download and install Docker
To connect to an external Ollama instance, set the environment variable:
OLLAMA_HOST=http://address:port, e.g.:OLLAMA_HOST=http(s)://127.0.0.1:5000If you want to disable the local Ollama model, use env
DISABLE_LOCAL_OLLAMA=1, e.g.DISABLE_LOCAL_OLLAMA=1 make installNote: When local Ollama is disabled, ensure the required model is downloaded on the external instance.
Currently, the
DISABLE_LOCAL_OLLAMAvariable cannot be used to disable Ollama in Docker. As a workaround, remove theollamaservice fromdocker-compose.ymlordocker-compose.gpu.yml.Support for using the variable in Docker environments will be added in a future release.
First, clone the repository and change current directory to it:
git clone https://github.com/CatchTheTornado/text-extract-api.git
cd text-extract-apiBe default application create virtual python env: .venv. You can disable this functionality on local setup by adding DISABLE_VENV=1 before running script:
DISABLE_VENV=1 make install DISABLE_VENV=1 make run Configure environment variables:
cp .env.localhost.example .env.localhostYou might want to just use the defaults - should be fine. After ENV variables are set, just execute:
python3 -m venv .venv
source .venv/bin/activate
pip install -e .
chmod +x run.sh
run.shThis command will install all the dependencies - including Redis (via Docker, so it is not entirely docker free method of running text-extract-api anyways :)
(MAC) - Dependencies
brew update && brew install libmagic poppler pkg-config ghostscript ffmpeg automake autoconf
(Mac) - You need to startup the celery worker
source .venv/bin/activate && celery -A text_extract_api.celery_app worker --loglevel=info --pool=solo
Then you're good to go with running some CLI commands like:
python client/cli.py ocr_upload --file examples/example-mri.pdf --ocr_cache --prompt_file=examples/example-mri-remove-pii.txtTo have multiple tasks running at once - for concurrent processing please run the following command to start single worker process:
celery -A text_extract_api.tasks worker --loglevel=info --pool=solo & # to scale by concurrent processing please run this line as many times as many concurrent processess you want to have runningTo try out the application with our hosted version you can skip the Getting started and try out the CLI tool against our cloud:
Open in the browser: demo.doctractor.com
... or run n the terminal:
python3 -m venv .venv
source .venv/bin/activate
pip install -e .
export OCR_UPLOAD_URL=https://doctractor:[email protected]/ocr/upload
export RESULT_URL=https://doctractor:[email protected]/ocr/result/
python client/cli.py ocr_upload --file examples/example-mri.pdf --ocr_cache --prompt_file=examples/example-mri-remove-pii.txtNote: In the free demo we don't guarantee any processing times. The API is Open so please do not send any secret documents neither any documents containing personal information, If you do - you're doing it on your own risk and responsiblity.

In case of any questions, help requests or just feedback - please join us on Discord!
- Docker
- Docker Compose
git clone https://github.com/CatchTheTornado/text-extract-api.git
cd text-extract-apiYou can use the make install and make run command to setup the Docker environment for text-extract-api. You can find the manual steps required to do so described below.
Create .env file in the root directory and set the necessary environment variables. You can use the .env.example file as a template:
# defaults for docker instances
cp .env.example .envor
# defaults for local run
cp .env.example.localhost .envThen modify the variables inside the file:
#APP_ENV=production # sets the app into prod mode, otherwise dev mode with auto-reload on code changes
REDIS_CACHE_URL=redis://localhost:6379/1
STORAGE_PROFILE_PATH=./storage_profiles
LLAMA_VISION_PROMPT="You are OCR. Convert image to markdown."
# CLI settings
OCR_URL=http://localhost:8000/ocr/upload
OCR_UPLOAD_URL=http://localhost:8000/ocr/upload
OCR_REQUEST_URL=http://localhost:8000/ocr/request
RESULT_URL=http://localhost:8000/ocr/result/
CLEAR_CACHE_URL=http://localhost:8000/ocr/clear_cach
LLM_PULL_API_URL=http://localhost:8000/llm_pull
LLM_GENEREATE_API_URL=http://localhost:8000/llm_generate
CELERY_BROKER_URL=redis://localhost:6379/0
CELERY_RESULT_BACKEND=redis://localhost:6379/0
OLLAMA_HOST=http://localhost:11434
APP_ENV=development # Default to development modeNote: In order to properly save the output files you might need to modify storage_profiles/default.yaml to change the default storage path according to the volumes path defined in the docker-compose.yml
Build and run the Docker containers using Docker Compose:
docker-compose up --build... for GPU support run:
docker-compose -f docker-compose.gpu.yml -p text-extract-api-gpu up --buildNote: While on Mac - Docker does not support Apple GPUs. In this case you might want to run the application natively without the Docker Compose please check how to run it natively with GPU support
This will start the following services:
- FastAPI App: Runs the FastAPI application.
- Celery Worker: Processes asynchronous OCR tasks.
- Redis: Caches OCR results.
- Ollama: Runs the Ollama model.
If the on-prem is too much hassle ask us about the hosted/cloud edition of text-extract-api, we can setup it you, billed just for the usage.
Note: While on Mac, you may need to create a virtual Python environment first:
python3 -m venv .venv
source .venv/bin/activate
# now you've got access to `python` and `pip` within your virutal env.
pip install -e . # install main project requirementsThe project includes a CLI for interacting with the API. To make it work first run:
cd client
pip install -e .You might want to test out different models supported by LLama
python client/cli.py llm_pull --model llama3.1
python client/cli.py llm_pull --model llama3.2-visionThese models are required for most features supported by text-extract-api.
python client/cli.py ocr_upload --file examples/example-mri.pdf --ocr_cacheor alternatively
python client/cli.py ocr_request --file examples/example-mri.pdf --ocr_cacheThe difference is just that the first call uses ocr/upload - multipart form data upload, and the second one is a request to ocr/request sending the file via base64 encoded JSON property - probable a better suit for smaller files.
Important note: To use LLM you must first run the llm_pull to get the specific model required by your requests.
For example you must run:
python client/cli.py llm_pull --model llama3.1
python client/cli.py llm_pull --model llama3.2-visionand only after to run this specific prompt query:
python client/cli.py ocr_upload --file examples/example-mri.pdf --ocr_cache --prompt_file=examples/example-mri-remove-pii.txt --language enNote: The language argument is used for the OCR strategy to load the model weights for the selected language. You can specify multiple languages as a list: en,de,pl etc.
The ocr command can store the results using the storage_profiles:
-
storage_profile: Used to save the result - the
defaultprofile (./storage_profiles/default.yaml) is used by default; if empty file is not saved -
storage_filename: Outputting filename - relative path of the
root_pathset in the storage profile - by default a relative path to/storagefolder; can use placeholders for dynamic formatting:{file_name},{file_extension},{Y},{mm},{dd}- for date formatting,{HH},{MM},{SS}- for time formatting
python client/cli.py ocr_upload --file examples/example-mri.pdf --ocr_cache --prompt_file=examples/example-mri-remove-pii.txt --storage_filename "invoices/{Y}/{file_name}-{Y}-{mm}-{dd}.md"python client/cli.py result --task_id {your_task_id_from_upload_step}python client/cli.py list_files to use specific (in this case google drive) storage profile run:
python client/cli.py list_files --storage_profile gdrivepython client/cli.py load_file --file_name "invoices/2024/example-invoice-2024-10-31-16-33.md"python client/cli.py delete_file --file_name "invoices/2024/example-invoice-2024-10-31-16-33.md" --storage_profile gdriveor for default profile (local file system):
python client/cli.py delete_file --file_name "invoices/2024/example-invoice-2024-10-31-16-33.md" python client/cli.py clear_cachepython llm_generate --prompt "Your prompt here"You might want to use the decdicated API clients to use text-extract-api
There's a dedicated API client for Typescript - text-extract-api-client and the npm package by the same name:
npm install text-extract-api-clientUsage:
import { ApiClient, OcrRequest } from 'text-extract-api-client';
const apiClient = new ApiClient('https://api.doctractor.com/', 'doctractor', 'Aekie2ao');
const formData = new FormData();
formData.append('file', fileInput.files[0]);
formData.append('prompt', 'Convert file to JSON and return only JSON'); // if not provided, no LLM transformation will gonna happen - just the OCR
formData.append('strategy', 'llama_vision');
formData.append('model', 'llama3.1')
formData.append('ocr_cache', 'true');
apiClient.uploadFile(formData).then(response => {
console.log(response);
});- URL: /ocr/upload
- Method: POST
-
Parameters:
- file: PDF, image or Office file to be processed.
-
strategy: OCR strategy to use (
llama_visionoreasyocr). - ocr_cache: Whether to cache the OCR result (true or false).
- prompt: When provided, will be used for Ollama processing the OCR result
- model: When provided along with the prompt - this model will be used for LLM processing
-
storage_profile: Used to save the result - the
defaultprofile (./storage_profiles/default.yaml) is used by default; if empty file is not saved -
storage_filename: Outputting filename - relative path of the
root_pathset in the storage profile - by default a relative path to/storagefolder; can use placeholders for dynamic formatting:{file_name},{file_extension},{Y},{mm},{dd}- for date formatting,{HH},{MM},{SS}- for time formatting -
language: One or many (
enoren,pl,de) language codes for the OCR to load the language weights
Example:
curl -X POST -H "Content-Type: multipart/form-data" -F "file=@examples/example-mri.pdf" -F "strategy=easyocr" -F "ocr_cache=true" -F "prompt=" -F "model=" "http://localhost:8000/ocr/upload" - URL: /ocr/request
- Method: POST
-
Parameters (JSON body):
- file: Base64 encoded PDF file content.
-
strategy: OCR strategy to use (
llama_visionoreasyocr). - ocr_cache: Whether to cache the OCR result (true or false).
- prompt: When provided, will be used for Ollama processing the OCR result.
- model: When provided along with the prompt - this model will be used for LLM processing.
-
storage_profile: Used to save the result - the
defaultprofile (/storage_profiles/default.yaml) is used by default; if empty file is not saved. -
storage_filename: Outputting filename - relative path of the
root_pathset in the storage profile - by default a relative path to/storagefolder; can use placeholders for dynamic formatting:{file_name},{file_extension},{Y},{mm},{dd}- for date formatting,{HH},{MM},{SS}- for time formatting. -
language: One or many (
enoren,pl,de) language codes for the OCR to load the language weights
Example:
curl -X POST "http://localhost:8000/ocr/request" -H "Content-Type: application/json" -d '{
"file": "<base64-encoded-file-content>",
"strategy": "easyocr",
"ocr_cache": true,
"prompt": "",
"model": "llama3.1",
"storage_profile": "default",
"storage_filename": "example.pdf"
}'- URL: /ocr/result/{task_id}
- Method: GET
-
Parameters:
- task_id: Task ID returned by the OCR endpoint.
Example:
curl -X GET "http://localhost:8000/ocr/result/{task_id}"- URL: /ocr/clear_cache
- Method: POST
Example:
curl -X POST "http://localhost:8000/ocr/clear_cache"- URL: /llm/pull
- Method: POST
-
Parameters:
- model: Pull the model you are to use first
Example:
curl -X POST "http://localhost:8000/llm/pull" -H "Content-Type: application/json" -d '{"model": "llama3.1"}'- URL: /llm/generate
- Method: POST
-
Parameters:
- prompt: Prompt for the Ollama model.
- model: Model you like to query
Example:
curl -X POST "http://localhost:8000/llm/generate" -H "Content-Type: application/json" -d '{"prompt": "Your prompt here", "model":"llama3.1"}'- URL: /storage/list
- Method: GET
-
Parameters:
-
storage_profile: Name of the storage profile to use for listing files (default:
default).
-
storage_profile: Name of the storage profile to use for listing files (default:
- URL: /storage/load
- Method: GET
-
Parameters:
- file_name: File name to load from the storage
-
storage_profile: Name of the storage profile to use for listing files (default:
default).
- URL: /storage/delete
- Method: DELETE
-
Parameters:
- file_name: File name to load from the storage
-
storage_profile: Name of the storage profile to use for listing files (default:
default).
The tool can automatically save the results using different storage strategies and storage profiles. Storage profiles are set in the /storage_profiles by a yaml configuration files.
strategy: local_filesystem
settings:
root_path: /storage # The root path where the files will be stored - mount a proper folder in the docker file to match it
subfolder_names_format: "" # eg: by_months/{Y}-{mm}/
create_subfolders: truestrategy: google_drive
settings:
## how to enable GDrive API: https://developers.google.com/drive/api/quickstart/python?hl=pl
service_account_file: /storage/client_secret_269403342997-290pbjjlb06nbof78sjaj7qrqeakp3t0.apps.googleusercontent.com.json
folder_id:Where the service_account_file is a json file with authorization credentials. Please read on how to enable Google Drive API and prepare this authorization file here.
Note: Service Account is different account that the one you're using for Google workspace (files will not be visible in the UI)
strategy: aws_s3
settings:
bucket_name: ${AWS_S3_BUCKET_NAME}
region: ${AWS_REGION}
access_key: ${AWS_ACCESS_KEY_ID}
secret_access_key: ${AWS_SECRET_ACCESS_KEY}-
Access Key Ownership
The access key must belong to an IAM user or role with permissions for S3 operations. -
IAM Policy Example
The IAM policy attached to the user or role must allow the necessary actions. Below is an example of a policy granting access to an S3 bucket:{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject", "s3:ListBucket", "s3:DeleteObject" ], "Resource": [ "arn:aws:s3:::your-bucket-name", "arn:aws:s3:::your-bucket-name/*" ] } ] }
Next, populate the appropriate .env file (e.g., .env, .env.localhost) with the required AWS credentials:
AWS_ACCESS_KEY_ID=your-access-key-id
AWS_SECRET_ACCESS_KEY=your-secret-access-key
AWS_REGION=your-region
AWS_S3_BUCKET_NAME=your-bucket-nameThis project is licensed under the MIT License. See the LICENSE file for details.
In case of any questions please contact us at: [email protected]
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for text-extract-api
Similar Open Source Tools
text-extract-api
The text-extract-api is a powerful tool that allows users to convert images, PDFs, or Office documents to Markdown text or JSON structured documents with high accuracy. It is built using FastAPI and utilizes Celery for asynchronous task processing, with Redis for caching OCR results. The tool provides features such as PDF/Office to Markdown and JSON conversion, improving OCR results with LLama, removing Personally Identifiable Information from documents, distributed queue processing, caching using Redis, switchable storage strategies, and a CLI tool for task management. Users can run the tool locally or on cloud services, with support for GPU processing. The tool also offers an online demo for testing purposes.
openai-edge-tts
This project provides a local, OpenAI-compatible text-to-speech (TTS) API using `edge-tts`. It emulates the OpenAI TTS endpoint (`/v1/audio/speech`), enabling users to generate speech from text with various voice options and playback speeds, just like the OpenAI API. `edge-tts` uses Microsoft Edge's online text-to-speech service, making it completely free. The project supports multiple audio formats, adjustable playback speed, and voice selection options, providing a flexible and customizable TTS solution for users.
forge
Forge is a powerful open-source tool for building modern web applications. It provides a simple and intuitive interface for developers to quickly scaffold and deploy projects. With Forge, you can easily create custom components, manage dependencies, and streamline your development workflow. Whether you are a beginner or an experienced developer, Forge offers a flexible and efficient solution for your web development needs.

pentagi
PentAGI is an innovative tool for automated security testing that leverages cutting-edge artificial intelligence technologies. It is designed for information security professionals, researchers, and enthusiasts who need a powerful and flexible solution for conducting penetration tests. The tool provides secure and isolated operations in a sandboxed Docker environment, fully autonomous AI-powered agent for penetration testing steps, a suite of 20+ professional security tools, smart memory system for storing research results, web intelligence for gathering information, integration with external search systems, team delegation system, comprehensive monitoring and reporting, modern interface, API integration, persistent storage, scalable architecture, self-hosted solution, flexible authentication, and quick deployment through Docker Compose.

airbadge
Airbadge is a Stripe addon for Auth.js that simplifies the process of creating a SaaS site by integrating payment, authentication, gating, self-service account management, webhook handling, trials & free plans, session data, and more. It allows users to launch a SaaS app without writing any authentication or payment code. The project is open source and free to use with optional paid features under the BSL License.

roast
Roast is a convention-oriented framework for creating structured AI workflows maintained by the Augmented Engineering team at Shopify. It provides a structured, declarative approach to building AI workflows with convention over configuration, built-in tools for file operations, search, and AI interactions, Ruby integration for custom steps, shared context between steps, step customization with AI models and parameters, session replay, parallel execution, function caching, and extensive instrumentation for monitoring workflow execution, AI calls, and tool usage.
aider-desk
AiderDesk is a desktop application that enhances coding workflow by leveraging AI capabilities. It offers an intuitive GUI, project management, IDE integration, MCP support, settings management, cost tracking, structured messages, visual file management, model switching, code diff viewer, one-click reverts, and easy sharing. Users can install it by downloading the latest release and running the executable. AiderDesk also supports Python version detection and auto update disabling. It includes features like multiple project management, context file management, model switching, chat mode selection, question answering, cost tracking, MCP server integration, and MCP support for external tools and context. Development setup involves cloning the repository, installing dependencies, running in development mode, and building executables for different platforms. Contributions from the community are welcome following specific guidelines.

LEANN
LEANN is an innovative vector database that democratizes personal AI, transforming your laptop into a powerful RAG system that can index and search through millions of documents using 97% less storage than traditional solutions without accuracy loss. It achieves this through graph-based selective recomputation and high-degree preserving pruning, computing embeddings on-demand instead of storing them all. LEANN allows semantic search of file system, emails, browser history, chat history, codebase, or external knowledge bases on your laptop with zero cloud costs and complete privacy. It is a drop-in semantic search MCP service fully compatible with Claude Code, enabling intelligent retrieval without changing your workflow.
TermNet
TermNet is an AI-powered terminal assistant that connects a Large Language Model (LLM) with shell command execution, browser search, and dynamically loaded tools. It streams responses in real-time, executes tools one at a time, and maintains conversational memory across steps. The project features terminal integration for safe shell command execution, dynamic tool loading without code changes, browser automation powered by Playwright, WebSocket architecture for real-time communication, a memory system to track planning and actions, streaming LLM output integration, a safety layer to block dangerous commands, dual interface options, a notification system, and scratchpad memory for persistent note-taking. The architecture includes a multi-server setup with servers for WebSocket, browser automation, notifications, and web UI. The project structure consists of core backend files, various tools like web browsing and notification management, and servers for browser automation and notifications. Installation requires Python 3.9+, Ollama, and Chromium, with setup steps provided in the README. The tool can be used via the launcher for managing components or directly by starting individual servers. Additional tools can be added by registering them in `toolregistry.json` and implementing them in Python modules. Safety notes highlight the blocking of dangerous commands, allowed risky commands with warnings, and the importance of monitoring tool execution and setting appropriate timeouts.
Groqqle
Groqqle 2.1 is a revolutionary, free AI web search and API that instantly returns ORIGINAL content derived from source articles, websites, videos, and even foreign language sources, for ANY target market of ANY reading comprehension level! It combines the power of large language models with advanced web and news search capabilities, offering a user-friendly web interface, a robust API, and now a powerful Groqqle_web_tool for seamless integration into your projects. Developers can instantly incorporate Groqqle into their applications, providing a powerful tool for content generation, research, and analysis across various domains and languages.
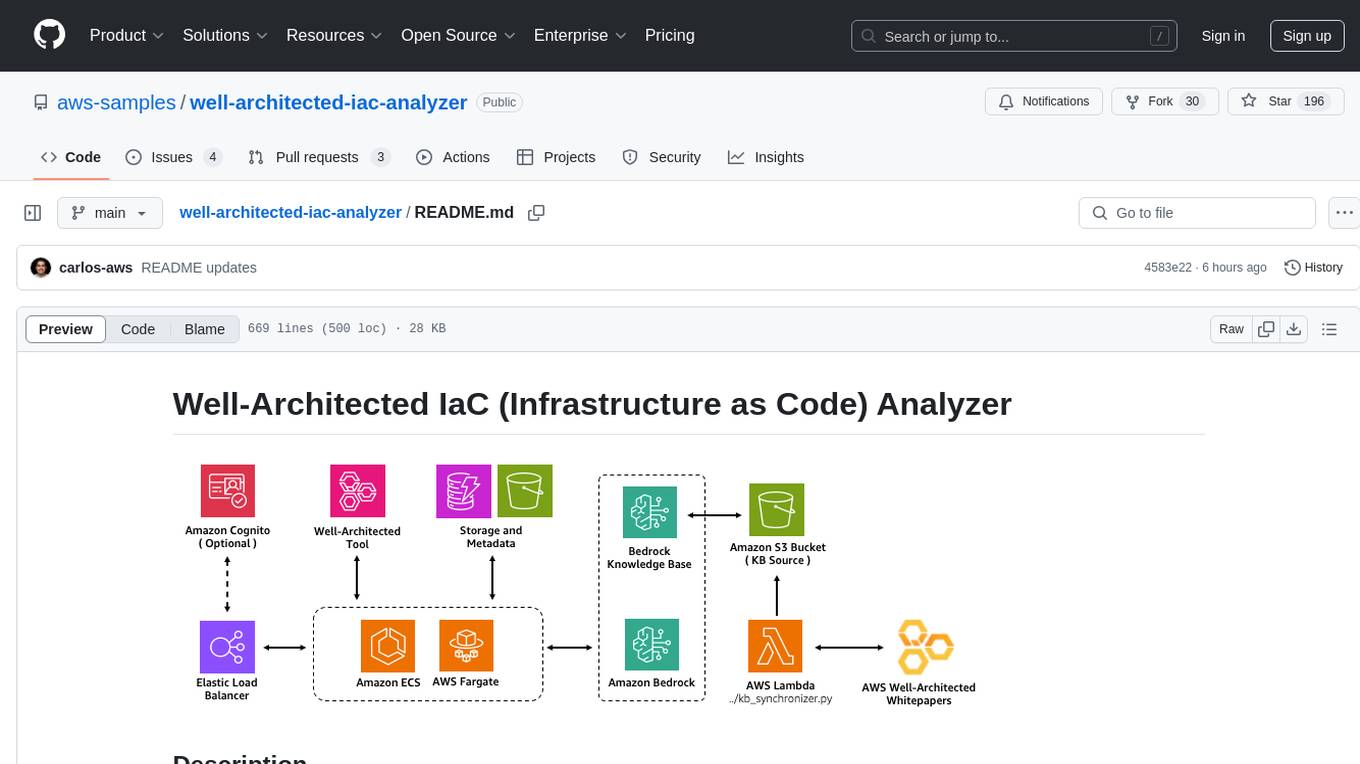
well-architected-iac-analyzer
Well-Architected Infrastructure as Code (IaC) Analyzer is a project demonstrating how generative AI can evaluate infrastructure code for alignment with best practices. It features a modern web application allowing users to upload IaC documents, complete IaC projects, or architecture diagrams for assessment. The tool provides insights into infrastructure code alignment with AWS best practices, offers suggestions for improving cloud architecture designs, and can generate IaC templates from architecture diagrams. Users can analyze CloudFormation, Terraform, or AWS CDK templates, architecture diagrams in PNG or JPEG format, and complete IaC projects with supporting documents. Real-time analysis against Well-Architected best practices, integration with AWS Well-Architected Tool, and export of analysis results and recommendations are included.
docs-mcp-server
The docs-mcp-server repository contains the server-side code for the documentation management system. It provides functionalities for managing, storing, and retrieving documentation files. Users can upload, update, and delete documents through the server. The server also supports user authentication and authorization to ensure secure access to the documentation system. Additionally, the server includes APIs for integrating with other systems and tools, making it a versatile solution for managing documentation in various projects and organizations.
supergateway
Supergateway is a tool that allows running MCP stdio-based servers over SSE (Server-Sent Events) with one command. It is useful for remote access, debugging, or connecting to SSE-based clients when your MCP server only speaks stdio. The tool supports running in SSE to Stdio mode as well, where it connects to a remote SSE server and exposes a local stdio interface for downstream clients. Supergateway can be used with ngrok to share local MCP servers with remote clients and can also be run in a Docker containerized deployment. It is designed with modularity in mind, ensuring compatibility and ease of use for AI tools exchanging data.

comp
Comp AI is an open-source compliance automation platform designed to assist companies in achieving compliance with standards like SOC 2, ISO 27001, and GDPR. It transforms compliance into an engineering problem solved through code, automating evidence collection, policy management, and control implementation while maintaining data and infrastructure control.

orbit
ORBIT (Open Retrieval-Based Inference Toolkit) is a middleware platform that provides a unified API for AI inference. It acts as a central gateway, allowing you to connect various local and remote AI models with your private data sources like SQL databases, vector stores, and local files. ORBIT uses a flexible adapter architecture to connect your data to AI models, creating specialized 'agents' for specific tasks. It supports scenarios like Knowledge Base Q&A and Chat with Your SQL Database, enabling users to interact with AI models seamlessly. The tool offers a RESTful API for programmatic access and includes features like authentication, API key management, system prompts, health monitoring, and file management. ORBIT is designed to streamline AI inference tasks and facilitate interactions between users and AI models.
mcp-ui
mcp-ui is a collection of SDKs that bring interactive web components to the Model Context Protocol (MCP). It allows servers to define reusable UI snippets, render them securely in the client, and react to their actions in the MCP host environment. The SDKs include @mcp-ui/server (TypeScript) for generating UI resources on the server, @mcp-ui/client (TypeScript) for rendering UI components on the client, and mcp_ui_server (Ruby) for generating UI resources in a Ruby environment. The project is an experimental community playground for MCP UI ideas, with rapid iteration and enhancements.
For similar tasks
text-extract-api
The text-extract-api is a powerful tool that allows users to convert images, PDFs, or Office documents to Markdown text or JSON structured documents with high accuracy. It is built using FastAPI and utilizes Celery for asynchronous task processing, with Redis for caching OCR results. The tool provides features such as PDF/Office to Markdown and JSON conversion, improving OCR results with LLama, removing Personally Identifiable Information from documents, distributed queue processing, caching using Redis, switchable storage strategies, and a CLI tool for task management. Users can run the tool locally or on cloud services, with support for GPU processing. The tool also offers an online demo for testing purposes.
For similar jobs

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

daily-poetry-image
Daily Chinese ancient poetry and AI-generated images powered by Bing DALL-E-3. GitHub Action triggers the process automatically. Poetry is provided by Today's Poem API. The website is built with Astro.

exif-photo-blog
EXIF Photo Blog is a full-stack photo blog application built with Next.js, Vercel, and Postgres. It features built-in authentication, photo upload with EXIF extraction, photo organization by tag, infinite scroll, light/dark mode, automatic OG image generation, a CMD-K menu with photo search, experimental support for AI-generated descriptions, and support for Fujifilm simulations. The application is easy to deploy to Vercel with just a few clicks and can be customized with a variety of environment variables.

SillyTavern
SillyTavern is a user interface you can install on your computer (and Android phones) that allows you to interact with text generation AIs and chat/roleplay with characters you or the community create. SillyTavern is a fork of TavernAI 1.2.8 which is under more active development and has added many major features. At this point, they can be thought of as completely independent programs.

Twitter-Insight-LLM
This project enables you to fetch liked tweets from Twitter (using Selenium), save it to JSON and Excel files, and perform initial data analysis and image captions. This is part of the initial steps for a larger personal project involving Large Language Models (LLMs).

AISuperDomain
Aila Desktop Application is a powerful tool that integrates multiple leading AI models into a single desktop application. It allows users to interact with various AI models simultaneously, providing diverse responses and insights to their inquiries. With its user-friendly interface and customizable features, Aila empowers users to engage with AI seamlessly and efficiently. Whether you're a researcher, student, or professional, Aila can enhance your AI interactions and streamline your workflow.

ChatGPT-On-CS
This project is an intelligent dialogue customer service tool based on a large model, which supports access to platforms such as WeChat, Qianniu, Bilibili, Douyin Enterprise, Douyin, Doudian, Weibo chat, Xiaohongshu professional account operation, Xiaohongshu, Zhihu, etc. You can choose GPT3.5/GPT4.0/ Lazy Treasure Box (more platforms will be supported in the future), which can process text, voice and pictures, and access external resources such as operating systems and the Internet through plug-ins, and support enterprise AI applications customized based on their own knowledge base.

obs-localvocal
LocalVocal is a live-streaming AI assistant plugin for OBS that allows you to transcribe audio speech into text and perform various language processing functions on the text using AI / LLMs (Large Language Models). It's privacy-first, with all data staying on your machine, and requires no GPU, cloud costs, network, or downtime.