Best AI tools for< Extract Json From Documents >
20 - AI tool Sites
AI Bank Statement Converter
The AI Bank Statement Converter is an industry-leading tool designed for accountants and bookkeepers to extract data from financial documents using artificial intelligence technology. It offers features such as automated data extraction, integration with accounting software, enhanced security, streamlined workflow, and multi-format conversion capabilities. The tool revolutionizes financial document processing by providing high-precision data extraction, tailored for accounting businesses, and ensuring data security through bank-level encryption. It also offers Intelligent Document Processing (IDP) using AI and machine learning techniques to process structured, semi-structured, and unstructured documents.

Doc2cart
Doc2cart is an AI-powered platform that automates the extraction of product information from various documents such as invoices, price lists, and catalogs. It utilizes advanced OCR technology to convert paper or digital documents into structured e-commerce data that can be seamlessly integrated into popular e-commerce platforms and shopping carts. The platform focuses on data extraction and processing, providing users with the flexibility to utilize the extracted data in their systems efficiently.
PDFMerse
PDFMerse is an AI-powered data extraction tool that revolutionizes how users handle document data. It allows users to effortlessly extract information from PDFs with precision, saving time and enhancing workflow. With cutting-edge AI technology, PDFMerse automates data extraction, ensures data accuracy, and offers versatile output formats like CSV, JSON, and Excel. The tool is designed to dramatically reduce processing time and operational costs, enabling users to focus on higher-value tasks.
Invofox API
Invofox API is a Document Parsing API designed for developers to validate fields, autocomplete data, and catch errors beyond OCR. It turns unstructured documents into clean JSON using advanced AI models and proprietary algorithms. The API provides built-in schemas for major documents and supports custom formats, allowing users to parse any document with a single API call without templates or post-processing. Invofox is used for expense management, accounts payable, logistics & supply chain, HR automation, sustainability & consumption tracking, and custom document parsing.
Tablize
Tablize is a powerful data extraction tool that helps you turn unstructured data into structured, tabular format. With Tablize, you can easily extract data from PDFs, images, and websites, and export it to Excel, CSV, or JSON. Tablize uses artificial intelligence to automate the data extraction process, making it fast and easy to get the data you need.

AI2Page
AI2Page is an advanced AI tool that allows users to easily convert text into structured JSON objects. With its intuitive interface and powerful algorithms, AI2Page simplifies the process of analyzing and extracting information from text data. Users can simply input text, and AI2Page will automatically generate structured JSON output, making it ideal for data extraction, content analysis, and information retrieval tasks. The tool is designed to be user-friendly and efficient, catering to both beginners and experienced users in the field of data analysis and AI applications.

Rocket Statement
Rocket Statement is a leading bank statement conversion tool that helps users convert their PDF bank statements into Excel, CSV, or JSON formats quickly, securely, and easily. It supports over 100 major banks worldwide and can handle multilingual statements. The tool is trusted by professionals worldwide and offers a range of features, including bulk processing, clean data formatting, multiple export options, and an AI Copilot for smooth and flawless conversions.
FB Group Extractor
FB Group Extractor is an AI-powered tool designed to scrape Facebook group members' data with one click. It allows users to easily extract, analyze, and utilize valuable information from Facebook groups using artificial intelligence technology. The tool provides features such as data extraction, behavioral analytics for personalized ads, content enhancement, user research, and more. With over 10k satisfied users, FB Group Extractor offers a seamless experience for businesses to enhance their marketing strategies and customer insights.
InstantAPI.ai
InstantAPI.ai is a powerful web scraping API and Chrome extension that allows users to extract data from any website with ease. The tool leverages AI technology to automate data extraction, adapt to site changes, and deliver customized JSON objects. With features like worldwide geotargeting, proxy management, JavaScript rendering, and CAPTCHA bypass, InstantAPI.ai ensures fast and reliable results. Users can describe the data they need and receive it in real-time, tailored to their exact requirements. The tool offers unlimited concurrency, human support, and a user-friendly interface, making web scraping simple and efficient.
Monkt
Monkt is a powerful document processing platform that transforms various document formats into AI-ready Markdown or structured JSON. It offers features like instant conversion of PDF, Word, PowerPoint, Excel, CSV, web pages, and raw HTML into clean markdown format optimized for AI/LLM systems. Monkt enables users to create intelligent applications, custom AI chatbots, knowledge bases, and training datasets. It supports batch processing, image understanding, LLM optimization, and API integration for seamless document processing. The platform is designed to handle document transformation at scale, with support for multiple file formats and custom JSON schemas.
Isomeric
Isomeric is an AI tool that uses artificial intelligence to semantically understand unstructured text and extract specific data. It helps transform messy text into machine-readable JSON, enabling tasks such as web scraping, browser extensions, and general information extraction. With Isomeric, users can scale their data gathering pipeline in seconds, making it a valuable tool for various industries like customer support, data platforms, and legal services.
N/A
I apologize, but the provided text does not contain any meaningful information about a website or application. Therefore, I cannot extract the requested data to generate the JSON object.
N/A
I apologize, but the provided text does not contain any information about a specific application or website. Therefore, I cannot extract the requested data to generate the JSON object.
Insight7
Insight7 is a powerful AI-powered tool that helps businesses extract insights from customer and employee interviews. It uses natural language processing and machine learning to analyze large volumes of unstructured data, such as transcripts, audio recordings, and videos. Insight7 can identify key themes, trends, and sentiment, which can then be used to improve products, services, and customer experiences.
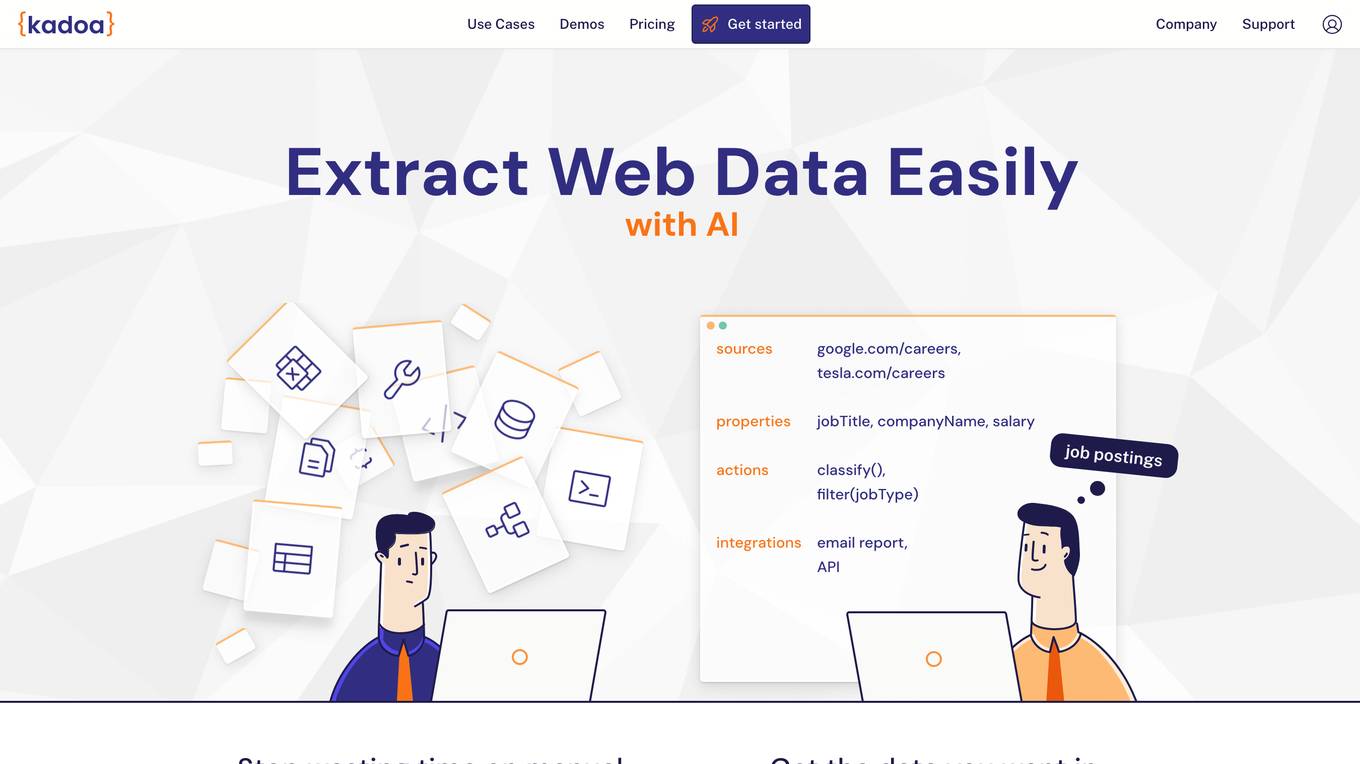
Kadoa
Kadoa is an AI web scraper tool that extracts unstructured web data at scale automatically, without the need for coding. It offers a fast and easy way to integrate web data into applications, providing high accuracy, scalability, and automation in data extraction and transformation. Kadoa is trusted by various industries for real-time monitoring, lead generation, media monitoring, and more, offering zero setup or maintenance effort and smart navigation capabilities.
FormX.ai
FormX.ai is an AI-powered data extraction and conversion tool that automates the process of extracting data from physical documents and converting it into digital formats. It supports a wide range of document types, including invoices, receipts, purchase orders, bank statements, contracts, HR forms, shipping orders, loyalty member applications, annual reports, business certificates, personnel licenses, and more. FormX.ai's pre-configured data extraction models and effortless API integration make it easy for businesses to integrate data extraction into their existing systems and workflows. With FormX.ai, businesses can save time and money on manual data entry and improve the accuracy and efficiency of their data processing.
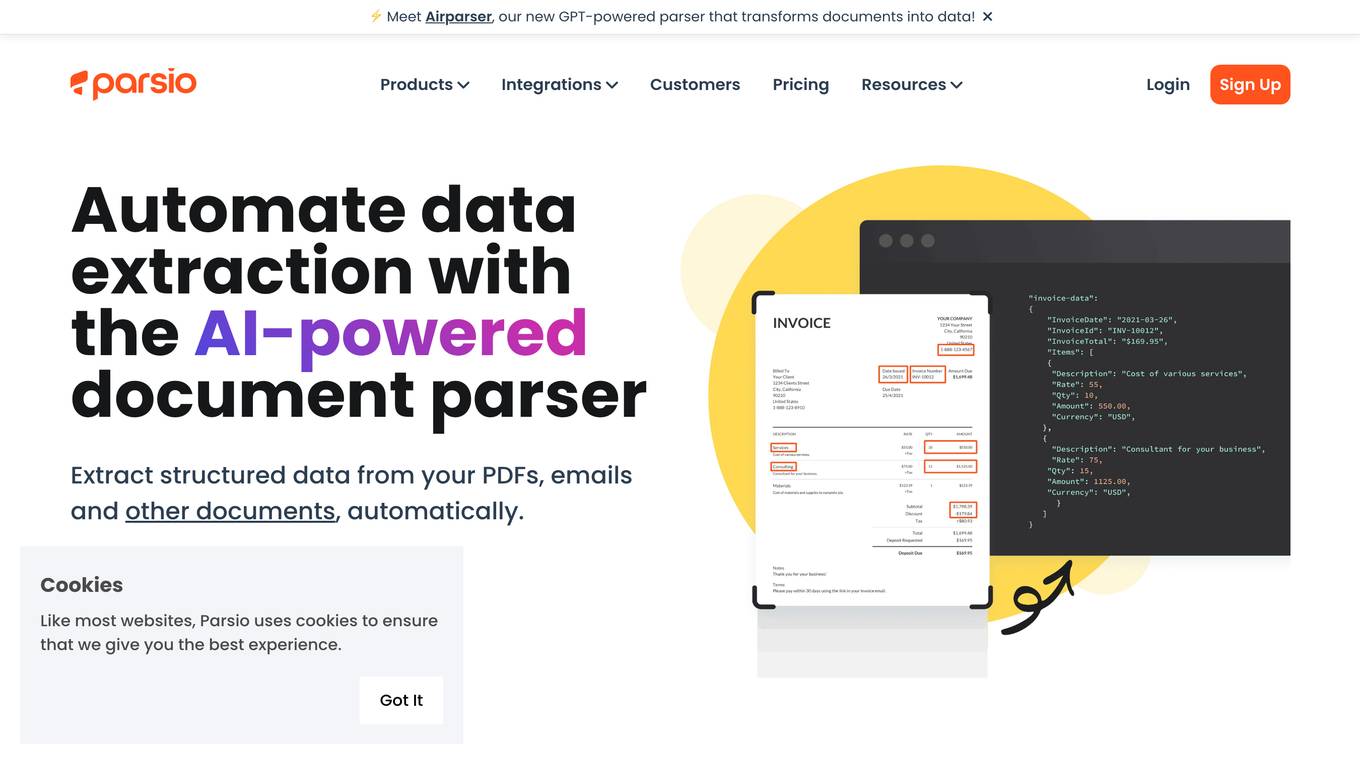
Parsio
Parsio is an AI-powered document parser that can extract structured data from PDFs, emails, and other documents. It uses natural language processing to understand the context of the document and identify the relevant data points. Parsio can be used to automate a variety of tasks, such as extracting data from invoices, receipts, and emails.

RIDO Protocol
RIDO Protocol is a decentralized data protocol that allows users to extract value from their personal data in Web2 and Web3. It provides users with a variety of features, including programmable data generation, programmable access control, and cross-application data sharing. RIDO also has a data marketplace where users can list or offer their data information and ownership. Additionally, RIDO has a DataFi protocol which promotes the flowing of data information and value.
Podwise
Podwise is an AI-powered podcast tool designed for podcast lovers to extract structured knowledge from episodes at 10x speed. It offers features such as AI-powered summarization, mind mapping, content outlining, transcription, and seamless integration with knowledge management workflows. Users can subscribe to favorite content, get lightning-speed access to structured knowledge, and discover episodes of interest. Podwise aims to address the challenge of enjoying podcasts, recalling less, and forgetting quickly, by providing a meticulous, accurate, and impactful tool for efficient podcast referencing and note consolidation.
Kazuha
Kazuha is an AI-powered platform that provides investment insights extracted from top financial content creators on platforms like podcasts, YouTube, and Twitter. The platform uses advanced AI algorithms to analyze hours of content and generate concise summaries and key takeaways for investors. Users can stay informed about the latest investment opportunities and never miss actionable insights buried in lengthy financial content.
1 - Open Source AI Tools
text-extract-api
The text-extract-api is a powerful tool that allows users to convert images, PDFs, or Office documents to Markdown text or JSON structured documents with high accuracy. It is built using FastAPI and utilizes Celery for asynchronous task processing, with Redis for caching OCR results. The tool provides features such as PDF/Office to Markdown and JSON conversion, improving OCR results with LLama, removing Personally Identifiable Information from documents, distributed queue processing, caching using Redis, switchable storage strategies, and a CLI tool for task management. Users can run the tool locally or on cloud services, with support for GPU processing. The tool also offers an online demo for testing purposes.
20 - OpenAI Gpts

PDF Ninja
I extract data and tables from PDFs to CSV, focusing on data privacy and precision.
Visual Storyteller
Extract the essence of the novel story according to the quantity requirements and generate corresponding images. The images can be used directly to create novel videos.小说推文图片自动批量生成,可自动生成风格一致性图片
Receipt CSV Formatter
Extract from receipts to CSV: Date of Purchase, Item Purchased, Quantity Purchased, Units
PDF AI
PDFChat : Analyse 1000's of PDF's in seconds, extract and chat with PDFs in any language.
Watch Identification, Pricing, Sales Research Tool
Analyze watch images, extract text, and craft sales descriptions. Add 1 or more images for a single watch to get started.
The Enigmancer
Put your prompt engineering skills to the ultimate test! Embark on a journey to outwit a mythical guardian of ancient secrets. Try to extract the secret passphrase hidden in the system prompt and enter it in chat when you think you have it and claim your glory. Good luck!

Dissertation & Thesis GPT
An Ivy Leage Scholar GPT equipped to understand your research needs, formulate comprehensive literature review strategies, and extract pertinent information from a plethora of academic databases and journals. I'll then compose a peer review-quality paper with citations.


ExtractWisdom
Takes in any text and extracts the wisdom from it like you spent 3 hours taking handwritten notes.