
dbt-llm-agent
RAG based LLM chatbot for dbt projects
Stars: 76
dbt-llm-agent is an LLM-powered agent designed for interacting with dbt projects. It offers features such as question answering, documentation generation, agentic model interpretation, Postgres integration with pgvector, dbt model selection, question tracking, and upcoming Slack integration. The agent utilizes dbt project parsing, PostgreSQL with pgvector, model selection syntax, large language models like GPT-4, and question tracking to provide its functionalities. Users can set up the agent by checking Python version, cloning the repository, installing dependencies, setting up PostgreSQL with pgvector, configuring environment variables, and initializing the database schema. The agent can be initialized in Cloud Mode, Local Mode, or Source Code Mode to load project metadata. Once set up, users can work with model documentation, ask questions, provide feedback, list models, get detailed model information, and contribute to the project.
README:
An LLM-powered agent for interacting with dbt projects.
BETA NOTICE: This project is currently in beta. The most valuable features at this stage are model interpretation and question answering. A Slack integration is coming soon!
- Question Answering: Ask questions about your dbt project in natural language
- Documentation Generation: Automatically generate documentation for missing models
- Agentic Model Interpretation: Intelligently interpret models using a step-by-step approach that verifies interpretations against upstream models
- Postgres with pgvector: Store model embeddings in Postgres using pgvector (supports Supabase)
- dbt Model Selection: Use dbt's model selection syntax to specify which models to work with
- Question Tracking: Track questions, answers, and feedback for continuous improvement
- Coming Soon: Slack Integration: Ask questions and receive answers directly in Slack
The agent uses a combination of:
- dbt Project Parsing: Extract information from your dbt project including models, sources, and documentation
- PostgreSQL with pgvector: Store both structured metadata and vector embeddings for semantic search
- Model Selection: Selectively parse and embed models using dbt's selection syntax
- LLM Integration: Use large language models (like GPT-4) to generate responses and documentation
- Question Tracking: Store a history of questions, answers, and user feedback
-
Check Python Version: This project requires Python 3.10 or higher. You can check your Python version with:
python --version # or python3 --versionIf you need to upgrade or install Python 3.10+, visit python.org/downloads.
-
Clone the repository:
git clone https://github.com/pragunbhutani/dbt-llm-agent.git cd dbt-llm-agent -
Install dependencies: This project uses Poetry for dependency management.
# Install Poetry if you don't have it curl -sSL https://install.python-poetry.org | python3 - # Install dependencies poetry install
-
Set up PostgreSQL: You need a PostgreSQL database (version 11+) with the
pgvectorextension enabled. This database will store model metadata, embeddings, and question history.- Install PostgreSQL if you haven't already.
- Install
pgvector. Follow the instructions at https://github.com/pgvector/pgvector. - Create a database for the agent (e.g.,
dbt_llm_agent).
Quick setup commands for local PostgreSQL:
# Create database createdb dbt_llm_agent # Enable pgvector extension (run this in psql) psql -d dbt_llm_agent -c 'CREATE EXTENSION IF NOT EXISTS vector;'
-
Configure environment variables: Copy the example environment file and fill in your details:
cp .env.example .env
Edit the
.envfile with your:OPENAI_API_KEY-
POSTGRES_URI(database connection string) - dbt Cloud credentials (
DBT_CLOUD_...) if usinginit cloud. -
DBT_PROJECT_PATHif usinginit localorinit sourceand not providing the path as an argument.
-
Initialize the database schema: Run the following command. This creates the necessary tables and enables the
pgvectorextension if needed.poetry run dbt-llm-agent init-db
To use the agent, you first need to load your dbt project's metadata into the database. Use the init command:
poetry run dbt-llm-agent init <mode> [options]There are three modes available:
Fetches the manifest.json from the latest successful run in your dbt Cloud account. This provides the richest metadata, including compiled SQL.
-
Command:
poetry run dbt-llm-agent init cloud -
Prerequisites:
- dbt Cloud account with successful job runs that generate artifacts.
- Environment variables set in
.env:DBT_CLOUD_URLDBT_CLOUD_ACCOUNT_ID-
DBT_CLOUD_API_KEY(User Token or Service Token)
-
Example:
# Ensure DBT_CLOUD_URL, DBT_CLOUD_ACCOUNT_ID, DBT_CLOUD_API_KEY are in .env poetry run dbt-llm-agent init cloud
Runs dbt compile on your local dbt project and parses the generated manifest.json from the target/ directory. Also provides rich metadata including compiled SQL.
-
Command:
poetry run dbt-llm-agent init local --project-path /path/to/your/dbt/project -
Prerequisites:
- dbt project configured locally (
dbt_project.yml,profiles.ymletc.). - Ability to run
dbt compilesuccessfully in the project directory. - The dbt project path can be provided via the
--project-pathargument or theDBT_PROJECT_PATHenvironment variable.
- dbt project configured locally (
-
Example:
# Using argument poetry run dbt-llm-agent init local --project-path /Users/me/code/my_dbt_project # Using environment variable (set DBT_PROJECT_PATH in .env) poetry run dbt-llm-agent init local
Parses your dbt project directly from the source .sql and .yml files. This mode does not capture compiled SQL or reliably determine data types.
-
Command:
poetry run dbt-llm-agent init source /path/to/your/dbt/project -
Prerequisites:
- Access to the dbt project source code.
- The dbt project path can be provided via the argument or the
DBT_PROJECT_PATHenvironment variable.
-
Example:
# Using argument poetry run dbt-llm-agent init source /Users/me/code/my_dbt_project # Using environment variable poetry run dbt-llm-agent init source
Note: The init command replaces the older parse command for loading project metadata.
You only need to run init once initially, or again if your dbt project structure changes significantly. Use the --force flag with init to overwrite existing models in the database.
Once you've completed the setup and initialization, you've got the basics sorted! Now you can start using the agent's main features:
There are two main paths depending on whether your models already have documentation:
Generate vector embeddings for semantic search to enable question answering:
# Embed all models
poetry run dbt-llm-agent embed --select "*"
# Or embed specific models or tags
poetry run dbt-llm-agent embed --select "+tag:marts"
poetry run dbt-llm-agent embed --select "my_model"First, use the LLM to interpret and generate descriptions for models and columns:
# Interpret a specific model and save the results
poetry run dbt-llm-agent interpret --select "fct_orders" --save
# Interpret all models in the staging layer, save, and embed
poetry run dbt-llm-agent interpret --select "tag:staging" --save --embedThe --save flag stores the interpretations in the database, and --embed automatically generates embeddings after interpretation.
Now that your models are embedded, you can ask questions about your dbt project:
poetry run dbt-llm-agent ask "What models are tagged as finance?"
poetry run dbt-llm-agent ask "Show me the columns in the customers model"
poetry run dbt-llm-agent ask "Explain the fct_orders model"
poetry run dbt-llm-agent ask "How is discount_amount calculated in the orders model?"Help improve the agent by providing feedback on answers:
# List previous questions
poetry run dbt-llm-agent questions
# Provide positive feedback
poetry run dbt-llm-agent feedback 1 --useful
# Provide negative feedback with explanation
poetry run dbt-llm-agent feedback 2 --not-useful --text "Use this_other_model instead"
# Just provide text feedback without marking useful/not useful
poetry run dbt-llm-agent feedback 3 --text "This answer is correct but too verbose."This feedback helps the agent improve its answers over time.
# List all models in your project
poetry run dbt-llm-agent list
# Get detailed information about a specific model
poetry run dbt-llm-agent model-details my_model_nameContributions are welcome! Please follow standard fork-and-pull-request workflow.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for dbt-llm-agent
Similar Open Source Tools
dbt-llm-agent
dbt-llm-agent is an LLM-powered agent designed for interacting with dbt projects. It offers features such as question answering, documentation generation, agentic model interpretation, Postgres integration with pgvector, dbt model selection, question tracking, and upcoming Slack integration. The agent utilizes dbt project parsing, PostgreSQL with pgvector, model selection syntax, large language models like GPT-4, and question tracking to provide its functionalities. Users can set up the agent by checking Python version, cloning the repository, installing dependencies, setting up PostgreSQL with pgvector, configuring environment variables, and initializing the database schema. The agent can be initialized in Cloud Mode, Local Mode, or Source Code Mode to load project metadata. Once set up, users can work with model documentation, ask questions, provide feedback, list models, get detailed model information, and contribute to the project.
hound
Hound is a security audit automation pipeline for AI-assisted code review that mirrors how expert auditors think, learn, and collaborate. It features graph-driven analysis, sessionized audits, provider-agnostic models, belief system and hypotheses, precise code grounding, and adaptive planning. The system employs a senior/junior auditor pattern where the Scout actively navigates the codebase and annotates knowledge graphs while the Strategist handles high-level planning and vulnerability analysis. Hound is optimized for small-to-medium sized projects like smart contract applications and is language-agnostic.
RA.Aid
RA.Aid is an AI software development agent powered by `aider` and advanced reasoning models like `o1`. It combines `aider`'s code editing capabilities with LangChain's agent-based task execution framework to provide an intelligent assistant for research, planning, and implementation of multi-step development tasks. It handles complex programming tasks by breaking them down into manageable steps, running shell commands automatically, and leveraging expert reasoning models like OpenAI's o1. RA.Aid is designed for everyday software development, offering features such as multi-step task planning, automated command execution, and the ability to handle complex programming tasks beyond single-shot code edits.
model-compose
model-compose is an open-source, declarative workflow orchestrator inspired by docker-compose. It lets you define and run AI model pipelines using simple YAML files. Effortlessly connect external AI services or run local AI models within powerful, composable workflows. Features include declarative design, multi-workflow support, modular components, flexible I/O routing, streaming mode support, and more. It supports running workflows locally or serving them remotely, Docker deployment, environment variable support, and provides a CLI interface for managing AI workflows.

agenticSeek
AgenticSeek is a voice-enabled AI assistant powered by DeepSeek R1 agents, offering a fully local alternative to cloud-based AI services. It allows users to interact with their filesystem, code in multiple languages, and perform various tasks autonomously. The tool is equipped with memory to remember user preferences and past conversations, and it can divide tasks among multiple agents for efficient execution. AgenticSeek prioritizes privacy by running entirely on the user's hardware without sending data to the cloud.
BuildCLI
BuildCLI is a command-line interface (CLI) tool designed for managing and automating common tasks in Java project development. It simplifies the development process by allowing users to create, compile, manage dependencies, run projects, generate documentation, manage configuration profiles, dockerize projects, integrate CI/CD tools, and generate structured changelogs. The tool aims to enhance productivity and streamline Java project management by providing a range of functionalities accessible directly from the terminal.

rclip
rclip is a command-line photo search tool powered by the OpenAI's CLIP neural network. It allows users to search for images using text queries, similar image search, and combining multiple queries. The tool extracts features from photos to enable searching and indexing, with options for previewing results in supported terminals or custom viewers. Users can install rclip on Linux, macOS, and Windows using different installation methods. The repository follows the Conventional Commits standard and welcomes contributions from the community.
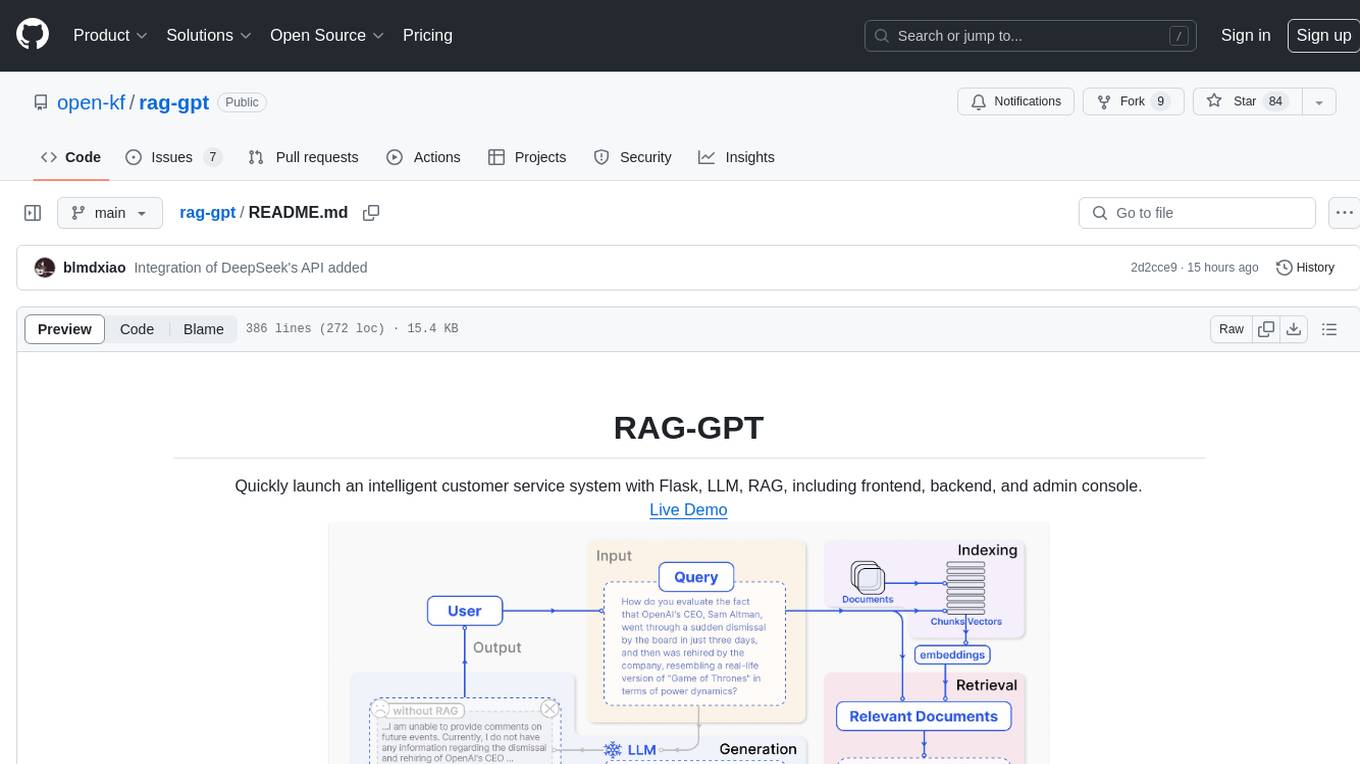
rag-gpt
RAG-GPT is a tool that allows users to quickly launch an intelligent customer service system with Flask, LLM, and RAG. It includes frontend, backend, and admin console components. The tool supports cloud-based and local LLMs, enables deployment of conversational service robots in minutes, integrates diverse knowledge bases, offers flexible configuration options, and features an attractive user interface.
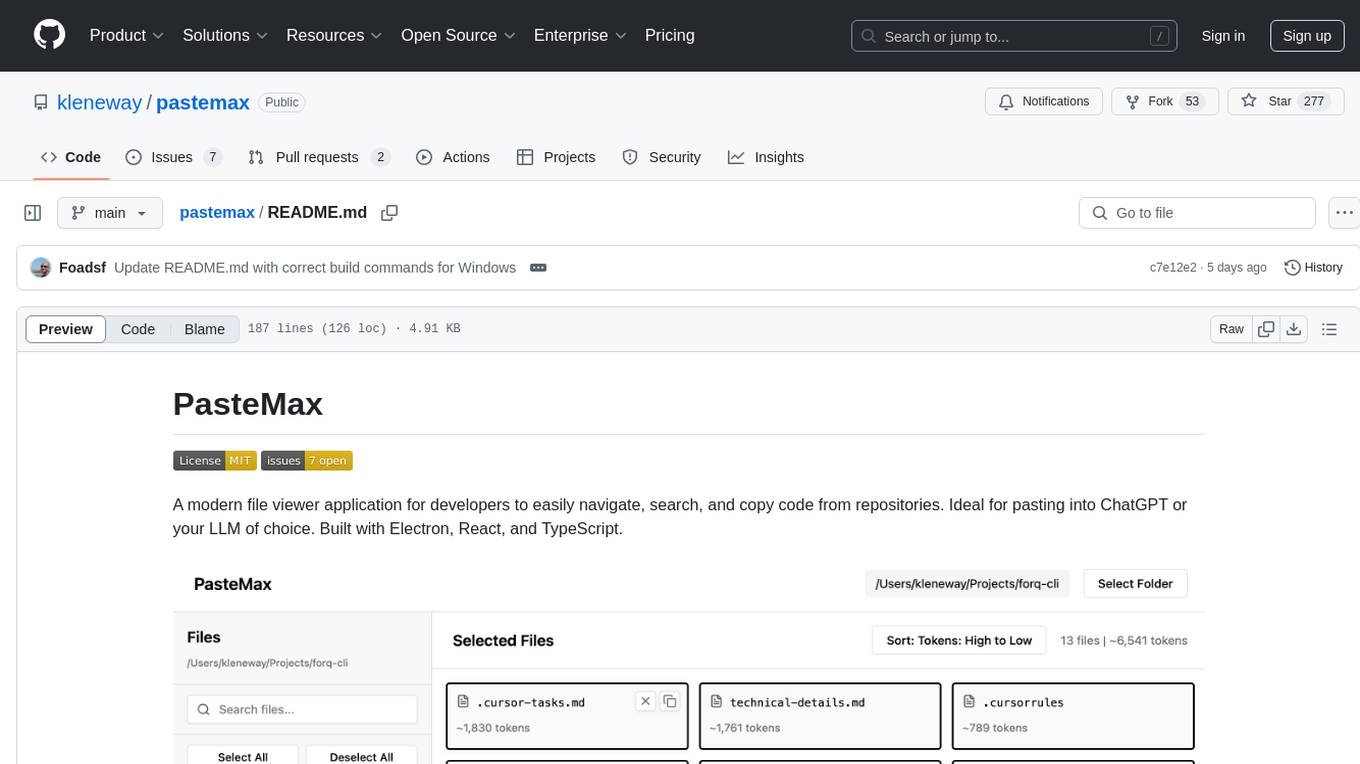
pastemax
PasteMax is a modern file viewer application designed for developers to easily navigate, search, and copy code from repositories. It provides features such as file tree navigation, token counting, search capabilities, selection management, sorting options, dark mode, binary file detection, and smart file exclusion. Built with Electron, React, and TypeScript, PasteMax is ideal for pasting code into ChatGPT or other language models. Users can download the application or build it from source, and customize file exclusions. Troubleshooting steps are provided for common issues, and contributions to the project are welcome under the MIT License.
backend.ai
Backend.AI is a streamlined, container-based computing cluster platform that hosts popular computing/ML frameworks and diverse programming languages, with pluggable heterogeneous accelerator support including CUDA GPU, ROCm GPU, TPU, IPU and other NPUs. It allocates and isolates the underlying computing resources for multi-tenant computation sessions on-demand or in batches with customizable job schedulers with its own orchestrator. All its functions are exposed as REST/GraphQL/WebSocket APIs.

LLMBox
LLMBox is a comprehensive library designed for implementing Large Language Models (LLMs) with a focus on a unified training pipeline and comprehensive model evaluation. It serves as a one-stop solution for training and utilizing LLMs, offering flexibility and efficiency in both training and utilization stages. The library supports diverse training strategies, comprehensive datasets, tokenizer vocabulary merging, data construction strategies, parameter efficient fine-tuning, and efficient training methods. For utilization, LLMBox provides comprehensive evaluation on various datasets, in-context learning strategies, chain-of-thought evaluation, evaluation methods, prefix caching for faster inference, support for specific LLM models like vLLM and Flash Attention, and quantization options. The tool is suitable for researchers and developers working with LLMs for natural language processing tasks.
llm-functions
LLM Functions is a project that enables the enhancement of large language models (LLMs) with custom tools and agents developed in bash, javascript, and python. Users can create tools for their LLM to execute system commands, access web APIs, or perform other complex tasks triggered by natural language prompts. The project provides a framework for building tools and agents, with tools being functions written in the user's preferred language and automatically generating JSON declarations based on comments. Agents combine prompts, function callings, and knowledge (RAG) to create conversational AI agents. The project is designed to be user-friendly and allows users to easily extend the capabilities of their language models.
cursor-tools
cursor-tools is a CLI tool designed to enhance AI agents with advanced skills, such as web search, repository context, documentation generation, GitHub integration, Xcode tools, and browser automation. It provides features like Perplexity for web search, Gemini 2.0 for codebase context, and Stagehand for browser operations. The tool requires API keys for Perplexity AI and Google Gemini, and supports global installation for system-wide access. It offers various commands for different tasks and integrates with Cursor Composer for AI agent usage.
elasticsearch-labs
This repository contains executable Python notebooks, sample apps, and resources for testing out the Elastic platform. Users can learn how to use Elasticsearch as a vector database for storing embeddings, build use cases like retrieval augmented generation (RAG), summarization, and question answering (QA), and test Elastic's leading-edge capabilities like the Elastic Learned Sparse Encoder and reciprocal rank fusion (RRF). It also allows integration with projects like OpenAI, Hugging Face, and LangChain to power LLM-powered applications. The repository enables modern search experiences powered by AI/ML.

llm-vscode
llm-vscode is an extension designed for all things LLM, utilizing llm-ls as its backend. It offers features such as code completion with 'ghost-text' suggestions, the ability to choose models for code generation via HTTP requests, ensuring prompt size fits within the context window, and code attribution checks. Users can configure the backend, suggestion behavior, keybindings, llm-ls settings, and tokenization options. Additionally, the extension supports testing models like Code Llama 13B, Phind/Phind-CodeLlama-34B-v2, and WizardLM/WizardCoder-Python-34B-V1.0. Development involves cloning llm-ls, building it, and setting up the llm-vscode extension for use.
rag-gpt
RAG-GPT is a tool that allows users to quickly launch an intelligent customer service system with Flask, LLM, and RAG. It includes frontend, backend, and admin console components. The tool supports cloud-based and local LLMs, offers quick setup for conversational service robots, integrates diverse knowledge bases, provides flexible configuration options, and features an attractive user interface.
For similar tasks

serverless-chat-langchainjs
This sample shows how to build a serverless chat experience with Retrieval-Augmented Generation using LangChain.js and Azure. The application is hosted on Azure Static Web Apps and Azure Functions, with Azure Cosmos DB for MongoDB vCore as the vector database. You can use it as a starting point for building more complex AI applications.

ChatGPT-Telegram-Bot
ChatGPT Telegram Bot is a Telegram bot that provides a smooth AI experience. It supports both Azure OpenAI and native OpenAI, and offers real-time (streaming) response to AI, with a faster and smoother experience. The bot also has 15 preset bot identities that can be quickly switched, and supports custom bot identities to meet personalized needs. Additionally, it supports clearing the contents of the chat with a single click, and restarting the conversation at any time. The bot also supports native Telegram bot button support, making it easy and intuitive to implement required functions. User level division is also supported, with different levels enjoying different single session token numbers, context numbers, and session frequencies. The bot supports English and Chinese on UI, and is containerized for easy deployment.

supersonic
SuperSonic is a next-generation BI platform that integrates Chat BI (powered by LLM) and Headless BI (powered by semantic layer) paradigms. This integration ensures that Chat BI has access to the same curated and governed semantic data models as traditional BI. Furthermore, the implementation of both paradigms benefits from the integration: * Chat BI's Text2SQL gets augmented with context-retrieval from semantic models. * Headless BI's query interface gets extended with natural language API. SuperSonic provides a Chat BI interface that empowers users to query data using natural language and visualize the results with suitable charts. To enable such experience, the only thing necessary is to build logical semantic models (definition of metric/dimension/tag, along with their meaning and relationships) through a Headless BI interface. Meanwhile, SuperSonic is designed to be extensible and composable, allowing custom implementations to be added and configured with Java SPI. The integration of Chat BI and Headless BI has the potential to enhance the Text2SQL generation in two dimensions: 1. Incorporate data semantics (such as business terms, column values, etc.) into the prompt, enabling LLM to better understand the semantics and reduce hallucination. 2. Offload the generation of advanced SQL syntax (such as join, formula, etc.) from LLM to the semantic layer to reduce complexity. With these ideas in mind, we develop SuperSonic as a practical reference implementation and use it to power our real-world products. Additionally, to facilitate further development we decide to open source SuperSonic as an extensible framework.
chat-ollama
ChatOllama is an open-source chatbot based on LLMs (Large Language Models). It supports a wide range of language models, including Ollama served models, OpenAI, Azure OpenAI, and Anthropic. ChatOllama supports multiple types of chat, including free chat with LLMs and chat with LLMs based on a knowledge base. Key features of ChatOllama include Ollama models management, knowledge bases management, chat, and commercial LLMs API keys management.
ChatIDE
ChatIDE is an AI assistant that integrates with your IDE, allowing you to converse with OpenAI's ChatGPT or Anthropic's Claude within your development environment. It provides a seamless way to access AI-powered assistance while coding, enabling you to get real-time help, generate code snippets, debug errors, and brainstorm ideas without leaving your IDE.

azure-search-openai-javascript
This sample demonstrates a few approaches for creating ChatGPT-like experiences over your own data using the Retrieval Augmented Generation pattern. It uses Azure OpenAI Service to access the ChatGPT model (gpt-35-turbo), and Azure AI Search for data indexing and retrieval.
xiaogpt
xiaogpt is a tool that allows you to play ChatGPT and other LLMs with Xiaomi AI Speaker. It supports ChatGPT, New Bing, ChatGLM, Gemini, Doubao, and Tongyi Qianwen. You can use it to ask questions, get answers, and have conversations with AI assistants. xiaogpt is easy to use and can be set up in a few minutes. It is a great way to experience the power of AI and have fun with your Xiaomi AI Speaker.

googlegpt
GoogleGPT is a browser extension that brings the power of ChatGPT to Google Search. With GoogleGPT, you can ask ChatGPT questions and get answers directly in your search results. You can also use GoogleGPT to generate text, translate languages, and more. GoogleGPT is compatible with all major browsers, including Chrome, Firefox, Edge, and Safari.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.