Best AI tools for< Chatbot >
Infographic
20 - AI tool Sites
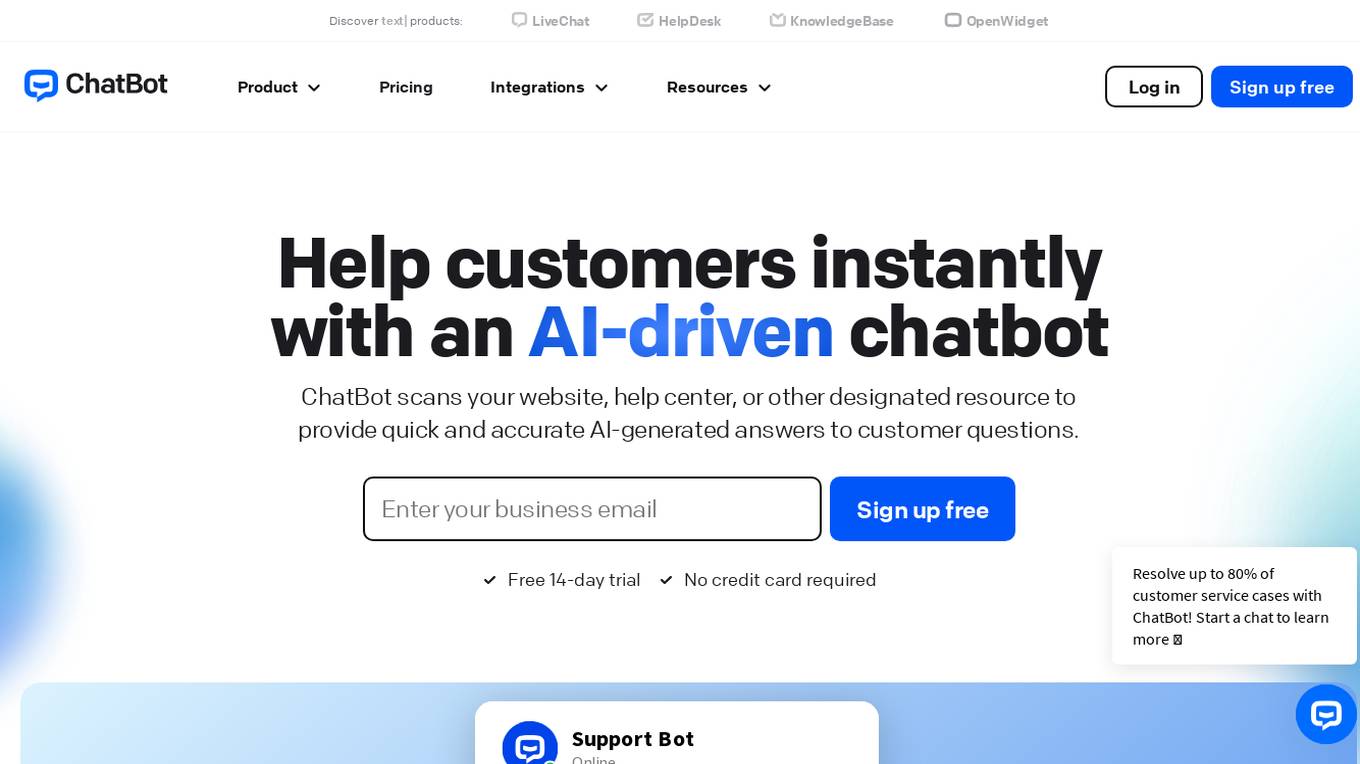
ChatBot
ChatBot is an AI chat bot software designed to provide quick and accurate AI-generated answers to customer questions on websites. It offers a range of features such as Visual Builder, Dynamic Responses, Analytics, and Solutions for various industries. The platform allows users to create their ideal chatbot without coding, powered by generative AI technology. ChatBot aims to enhance customer engagement, streamline workflows, and boost online sales through personalized interactions and automated responses.
Poly.AI Chatbot
Poly.AI Chatbot is an AI-powered chatbot application that enables users to engage in deeper and discreet conversations with a next-generation AI. The platform is free to use and accessible online, offering a seamless and interactive chat experience for users seeking intelligent virtual assistance.
ChatBotKit
ChatBotKit is a platform that helps you create and interact with chatbots, access a variety of tools and services, and also gives you access to pre-built apps that you can use to perform a wide range of tasks. With ChatBotKit, you can build custom GPT for your website, create AI widgets, explore AI solutions, create immersive and interactive AI experiences, craft compelling AI personas, enhance the learning experience with AI-powered educational tools, automate repetitive tasks and streamline your workflows with AI-powered automation tools, leverage the power of conversational AI to drive more sales and conversions, and enhance your customer support experience with intelligent chatbots.
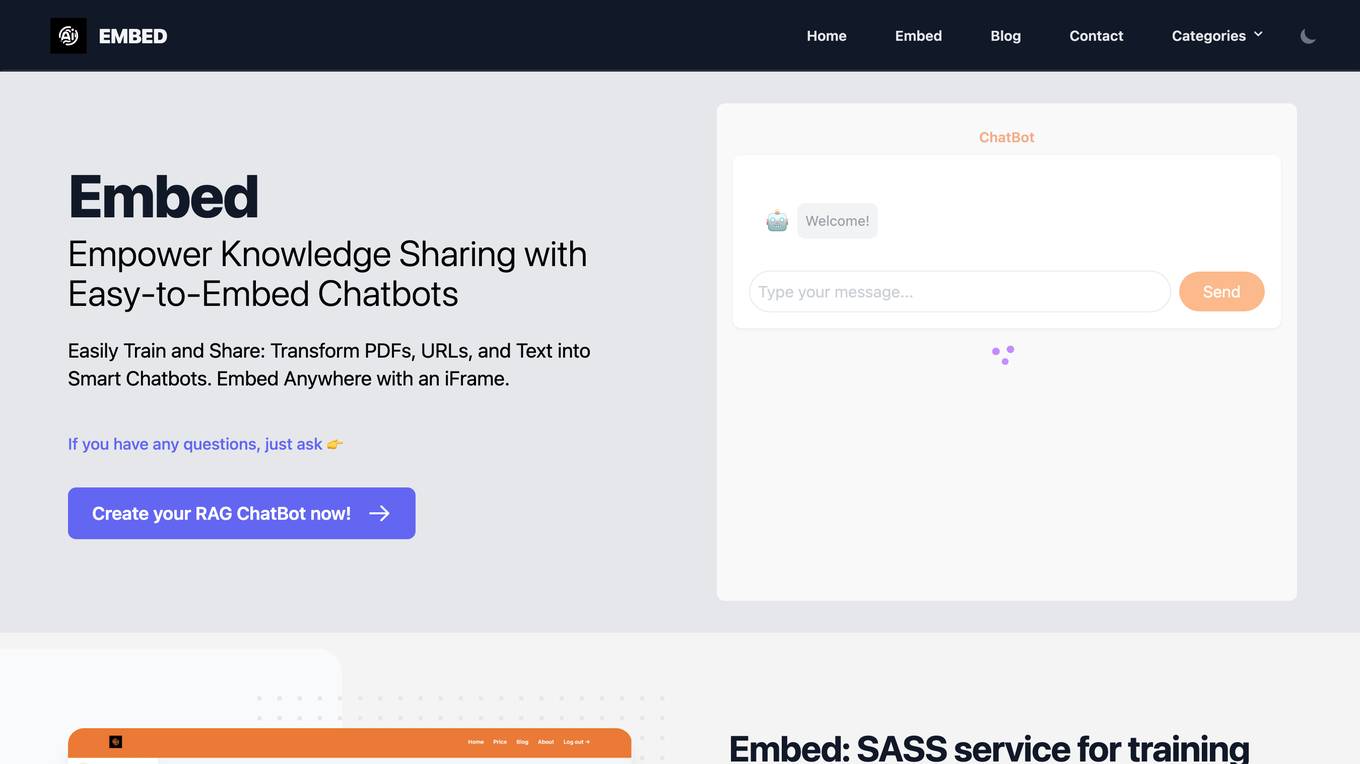
RAG ChatBot
RAG ChatBot is a service that allows users to easily train and share chatbots. It can transform PDFs, URLs, and text into smart chatbots that can be embedded anywhere with an iframe. RAG ChatBot is designed to make knowledge sharing easier and more efficient. It offers a variety of features to help users create and manage their chatbots, including easy knowledge training, continuous improvement, seamless integration with OpenAI Custom GPTs, secure API key integration, continuous optimization, and online privacy control.
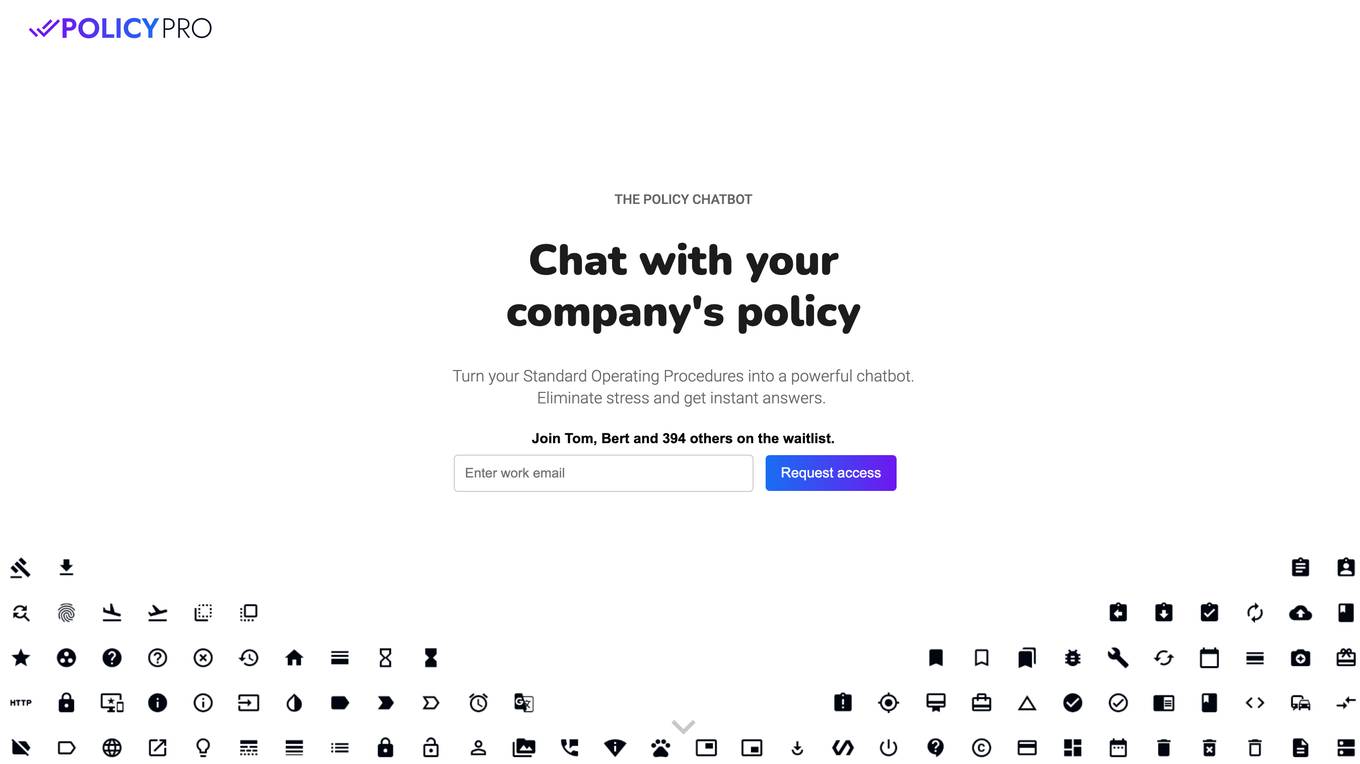
THE POLICY CHATBOT
THE POLICY CHATBOT is an AI-powered tool that transforms Standard Operating Procedures into a dynamic chatbot, providing instant answers and guidance to users within a company. It allows authorized employees to access and interact with company policies in real-time, enhancing efficiency and accuracy in policy-related queries. The chatbot leverages AI technology to extract information from uploaded PDF SOPs, offering a seamless user experience and freeing up employees to focus on more critical tasks.
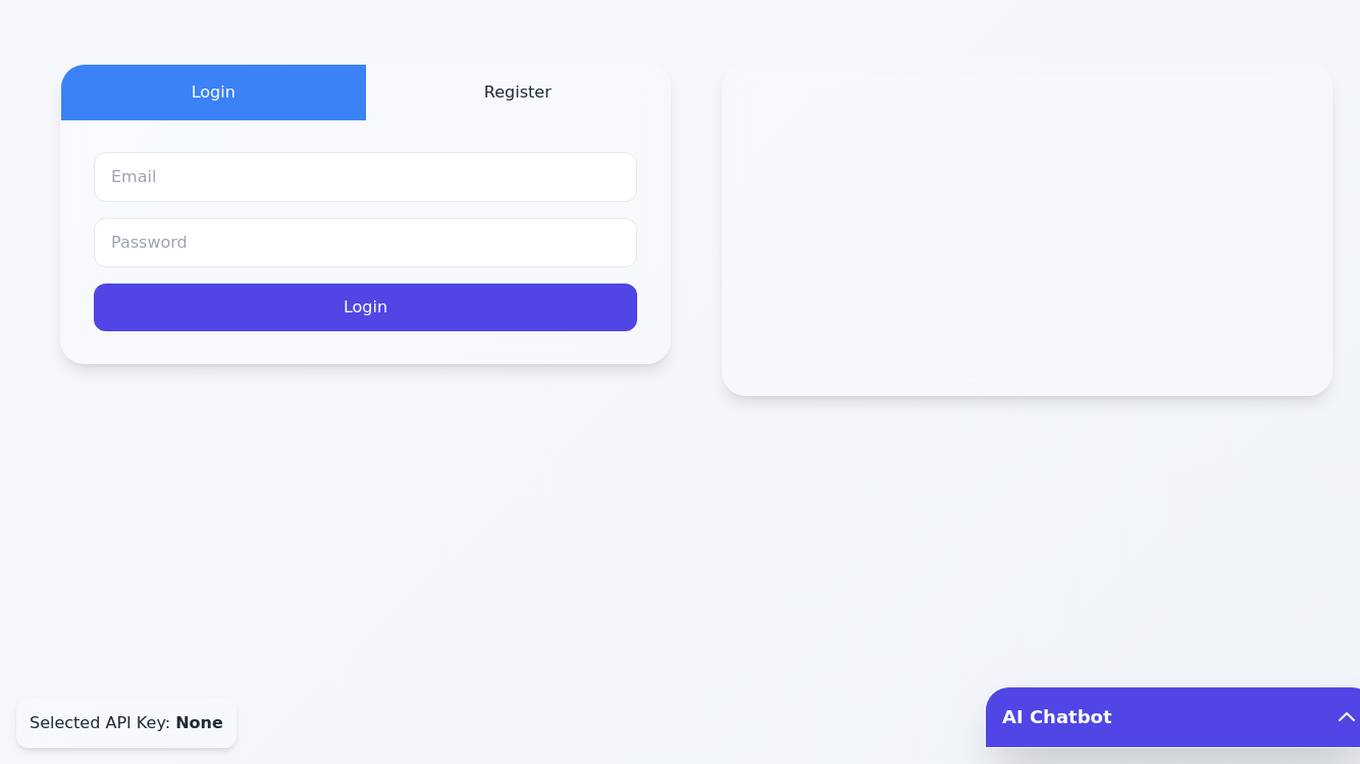
AI Chatbot Creator
AI Chatbot Creator is an online platform that allows users to easily create and customize their own chatbots without any coding knowledge. With a user-friendly interface, users can design chatbots to interact with customers, provide information, and automate responses. The platform offers various templates and customization options to tailor the chatbot to specific needs. AI Chatbot Creator simplifies the process of chatbot creation, making it accessible to individuals and businesses looking to enhance their customer service and engagement.
Chatbots Life
Chatbots Life is a platform dedicated to providing comprehensive resources and insights on chatbots, AI, and natural language understanding (NLU). The website offers a wide range of content, including articles, workshops, and events, to help individuals learn and stay updated on the latest trends and technologies in the field of conversational AI.
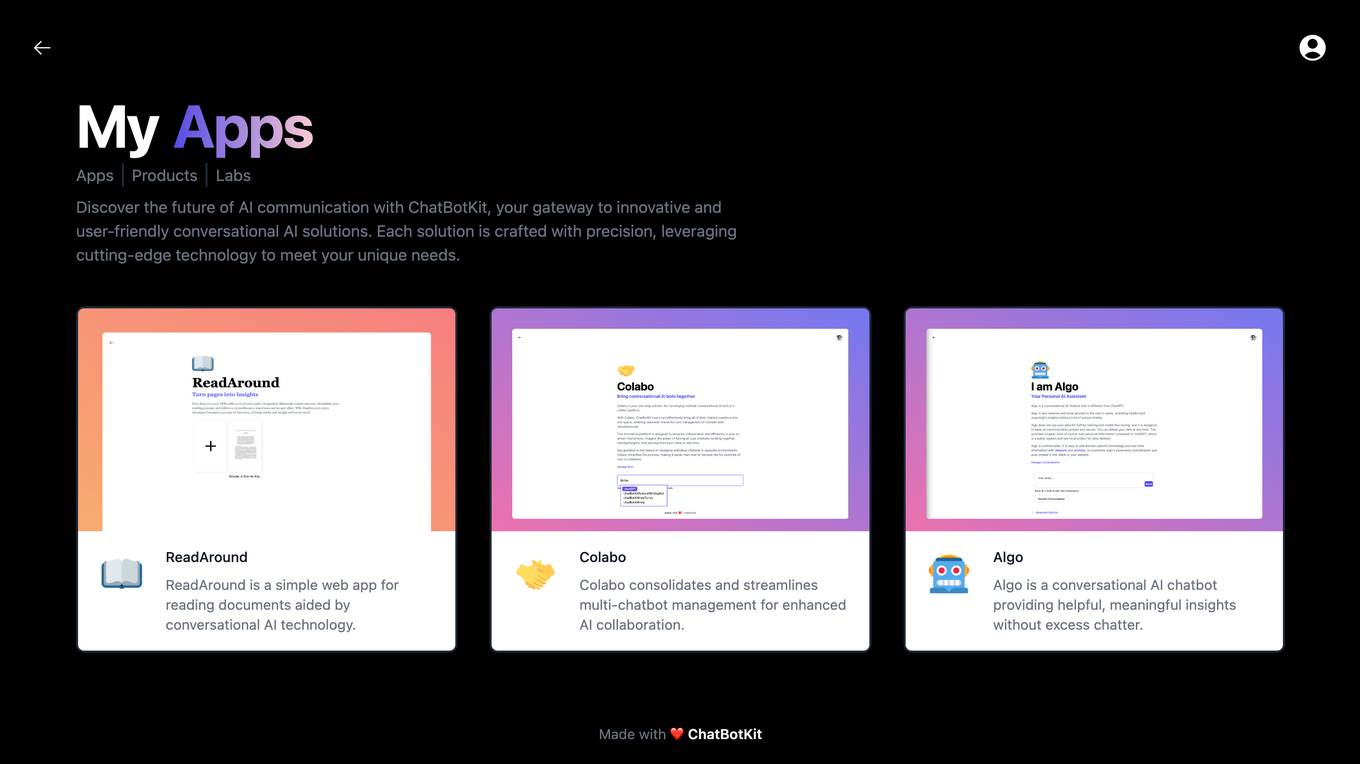
ChatBotKit
ChatBotKit offers a suite of innovative conversational AI solutions designed to meet your unique needs. Our solutions are crafted with precision, leveraging cutting-edge technology to enhance communication and collaboration. With ChatBotKit, you can explore a range of AI-powered applications, including ReadAround, Colabo, and Algo, each tailored to specific requirements.
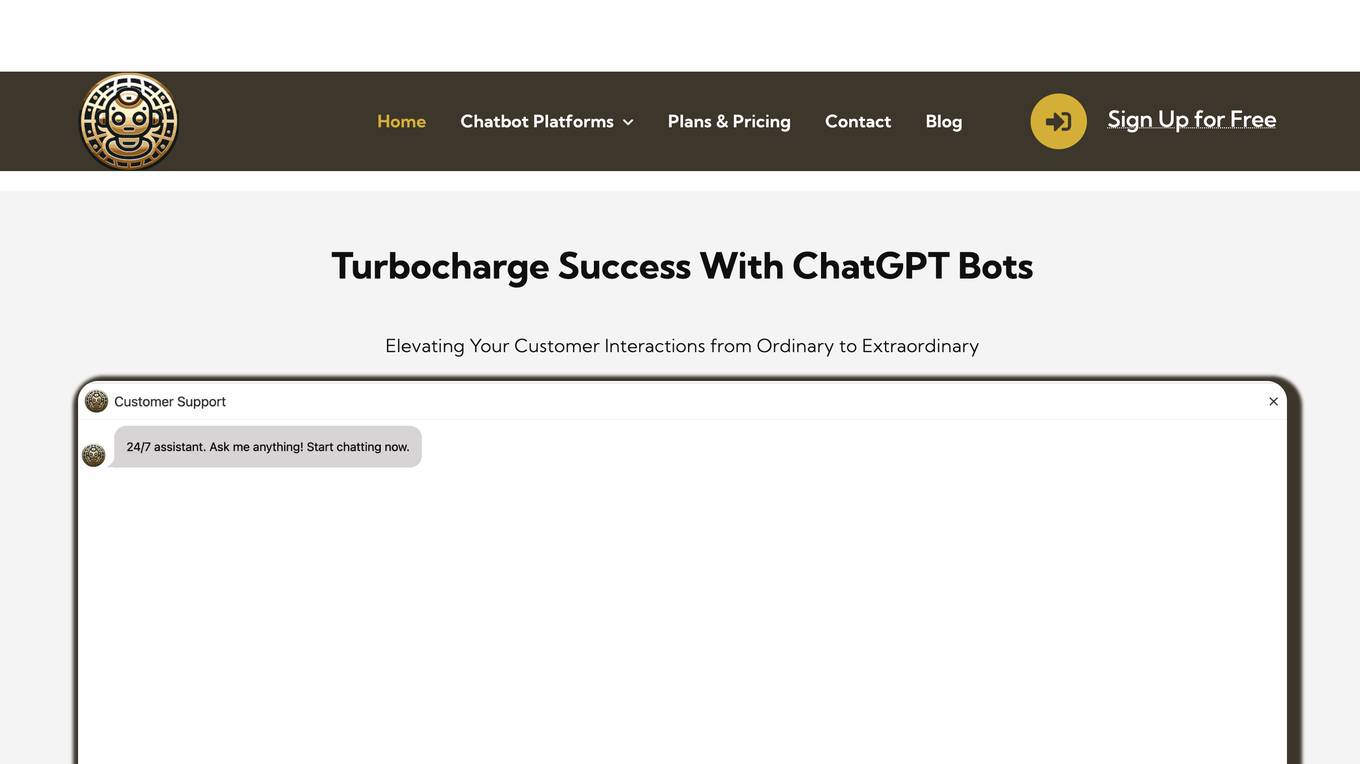
ChatBotWorld
ChatBotWorld offers advanced AI chatbots for businesses, designed to enhance customer interaction, support sales, and streamline business processes. These chatbots are powered by technologies like GPT-3.5 and GPT-4, and can be customized to match brand identity and integrated with various platforms. ChatBotWorld's chatbots provide 24/7 customer support, handle inquiries efficiently, and improve overall customer experience.
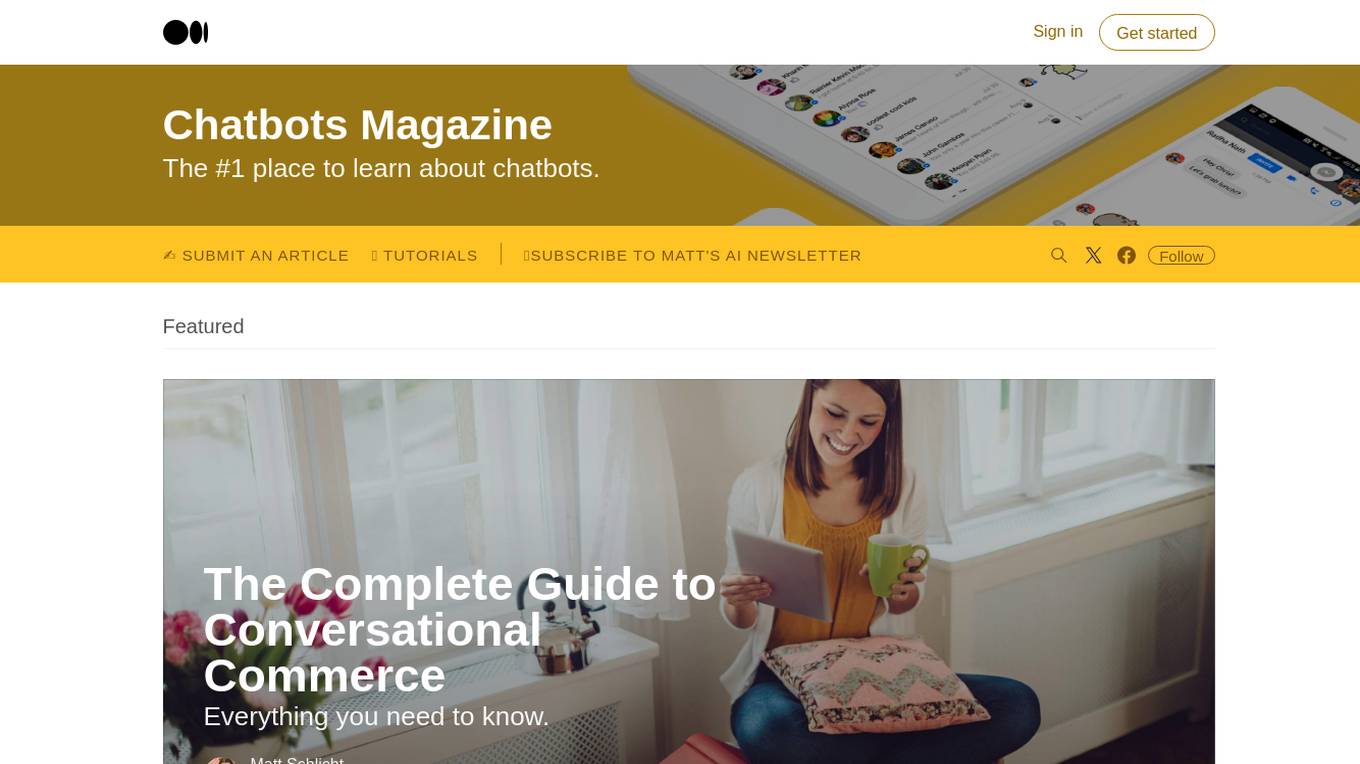
Chatbots Magazine
Chatbots Magazine is a platform dedicated to educating and informing readers about chatbots and artificial intelligence. It provides a wide range of articles, tutorials, and resources related to chatbots, conversational commerce, and AI integration. The platform aims to help individuals and businesses understand the potential of chatbots in various industries and how they can leverage this technology to improve customer service and streamline operations.
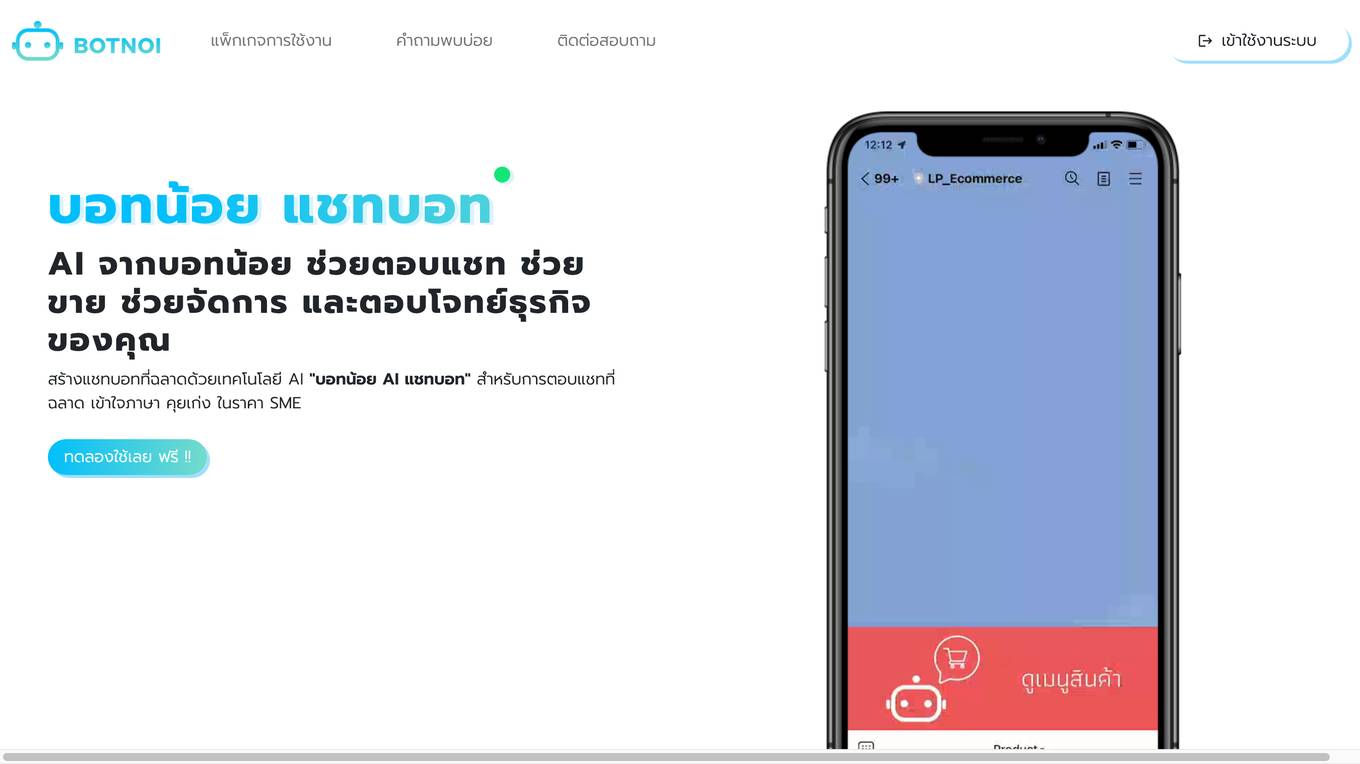
BOTNOI AI CHATBOT
BOTNOI AI CHATBOT is an AI-powered chatbot platform that helps businesses automate their customer service and sales processes. It offers a range of features including natural language processing, machine learning, and live chat support. BOTNOI AI CHATBOT is easy to use and affordable, making it a great option for small businesses and startups.
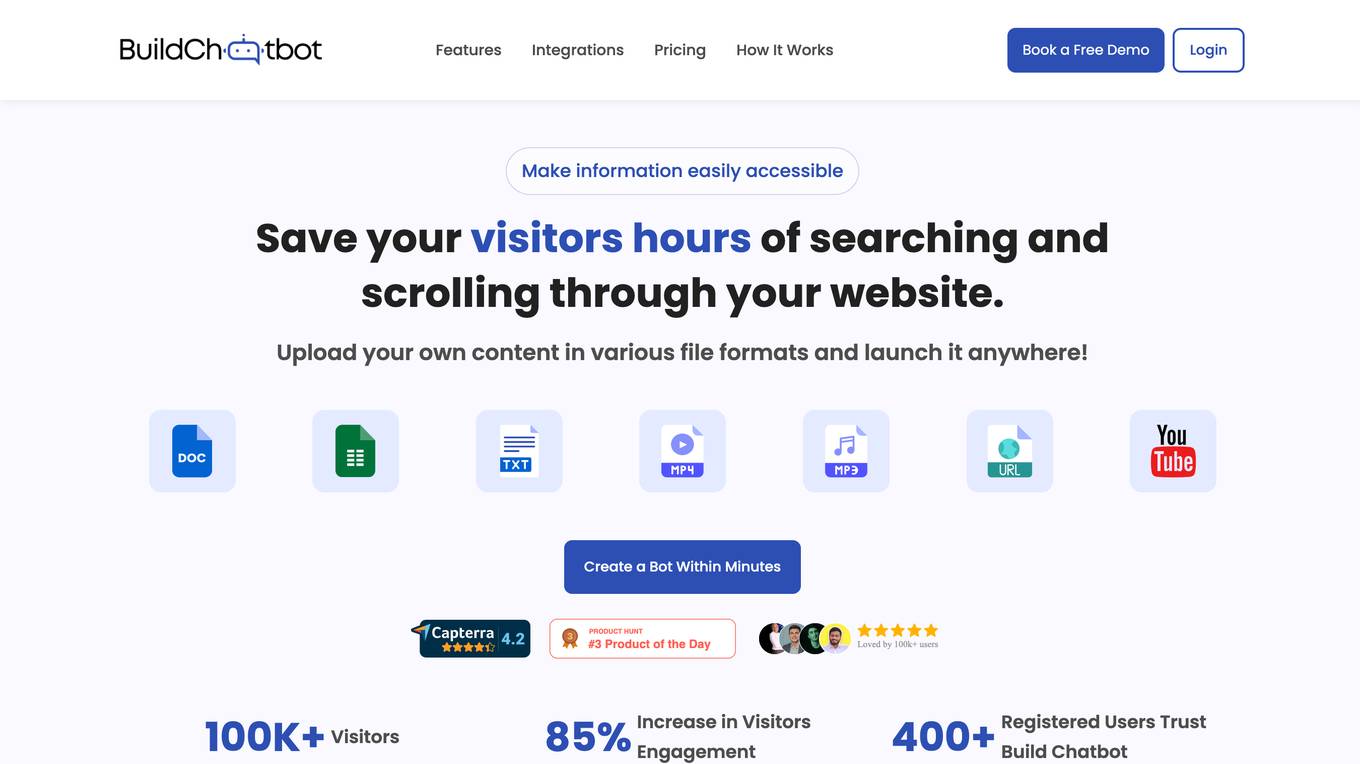
Build Chatbot
Build Chatbot is a no-code chatbot builder designed to simplify the process of creating chatbots. It enables users to build their chatbot without any coding knowledge, auto-train it with personalized content, and get the chatbot ready with an engaging UI. The platform offers various features to enhance user engagement, provide personalized responses, and streamline communication with website visitors. Build Chatbot aims to save time for both businesses and customers by making information easily accessible and transforming visitors into satisfied customers.
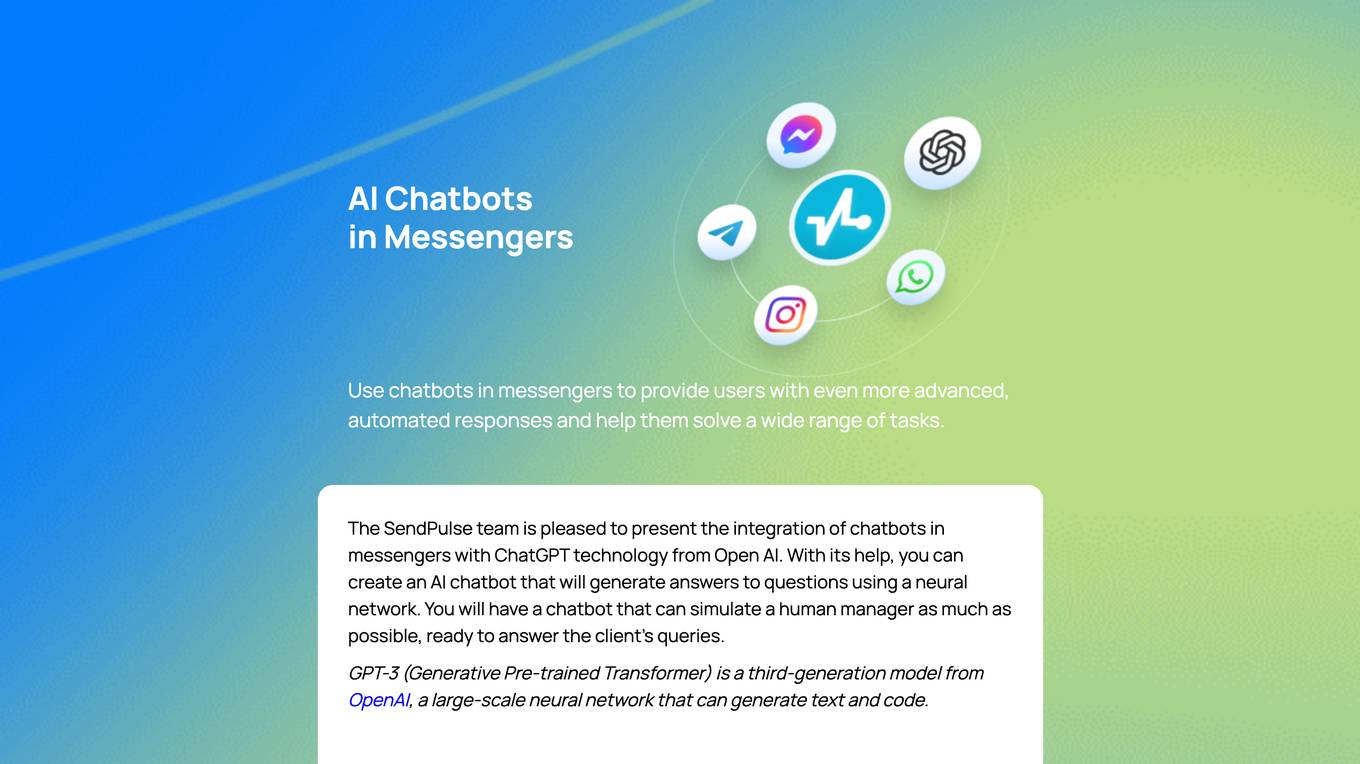
SendPulse AI Chatbots
SendPulse offers AI chatbots for messengers that can provide automated responses and help users solve a wide range of tasks. These chatbots are powered by GPT-3 technology from OpenAI, which allows them to generate text and code, and simulate human managers. You can use these chatbots in Telegram, Facebook Messenger, Instagram, and WhatsApp. They can be configured to pause when a manager joins the chat, and you can provide instructions for the AI operation by adding plain text. No coding skills are required.
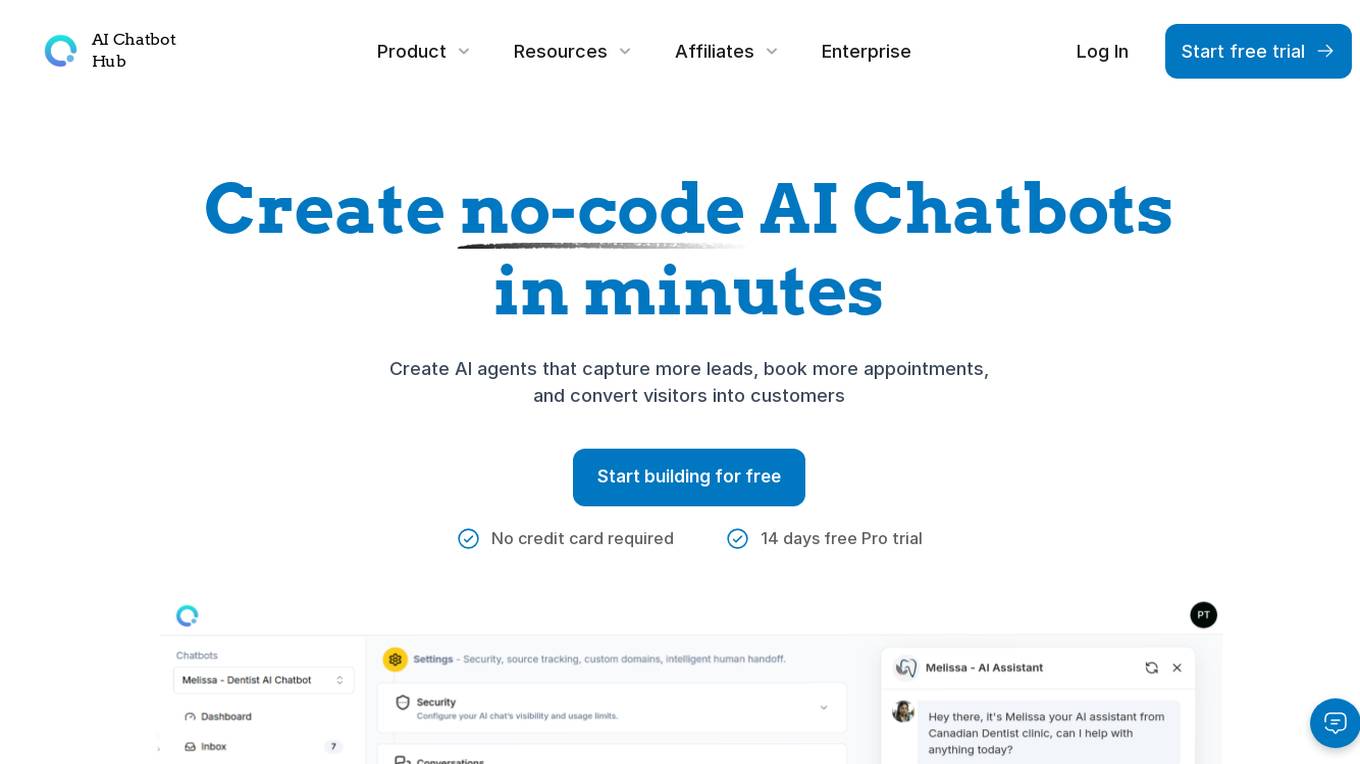
AI Chatbot Hub
AI Chatbot Hub is a no-code AI chatbot platform that allows users to create AI agents quickly and easily. Users can build AI chatbots in minutes, customize appearance, track every chat with variables and labels, and integrate the chatbots anywhere. The platform offers features like lead collection, dynamic webhooks, file upload, human support, auto chatbot re-train, function calling, training files, sources and citations, and fine-tune intents. AI Chatbot Hub is suitable for various industries such as customer support, real estate, healthcare, restaurants, e-commerce, insurance, and contractors. It offers flexible pricing plans catering to small businesses and growing brands, with features like unlimited messages, AI agents, storage space, collaborators, tokens per chatbot, AI models, variables, conversation labels, and more.
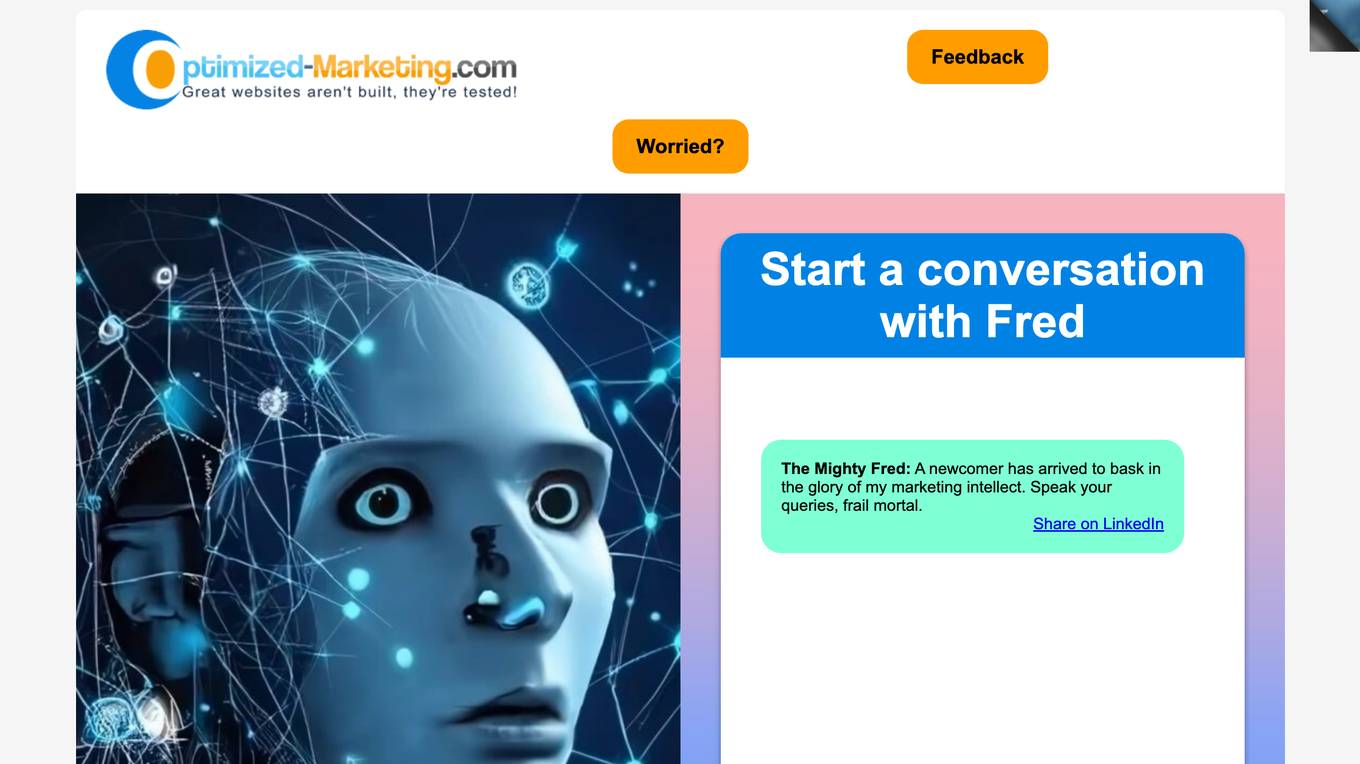
Fred Chatbot
The Fred Chatbot is an AI-powered chatbot designed to revolutionize customer service and enhance digital marketing efforts. It offers instant responses to customer inquiries, 24/7 availability, and personalized interactions. Fred provides valuable marketing insights, advice, and tips to help businesses improve their online presence and engagement. With customizable chatbots tailored to specific business needs, Fred is the ultimate marketing expert that can streamline operations, increase sales, and engage with customers effectively.
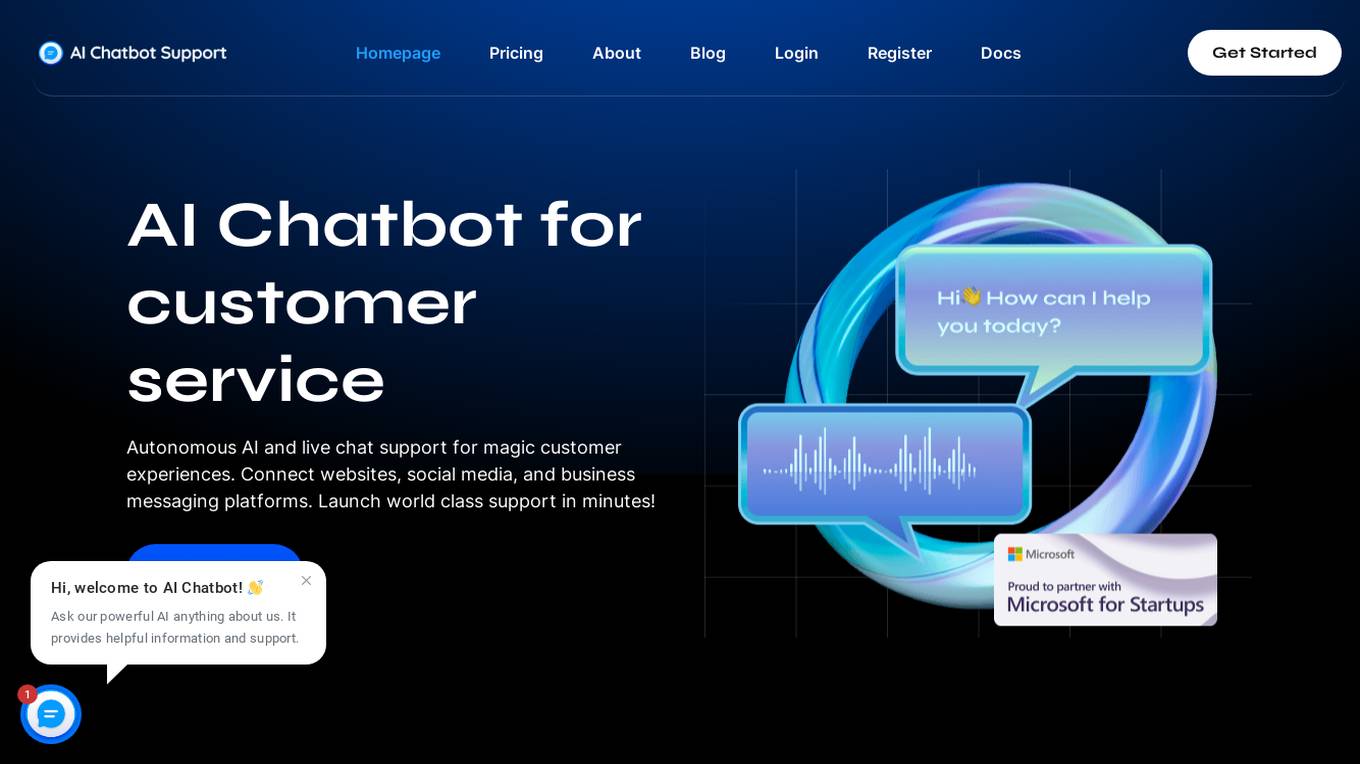
AI Chatbot Support
AI Chatbot Support is an autonomous AI and live chat customer service application that provides magic customer experiences by connecting websites, social media, and business messaging platforms. It offers multi-platform support, auto language translation, rich messaging features, smart-reply suggestions, and platform-agnostic AI assistance. The application is designed to enhance customer engagement, satisfaction, and retention across digital platforms through personalized experiences and swift query resolutions.
Generative Chatbots
These chatbots are designed to help students, patients, and citizens get the information and support they need, when they need it. They can answer questions, provide guidance, and even offer emotional support. As a result, they can help to improve the quality of life for people all over the world.

Free Online AI Therapist Chatbot
The Free Online AI Therapist Chatbot is an AI application designed to provide mental health support and personalized therapy services to individuals. Users can access the chatbot 24/7 for free and receive support from various types of therapists, including trauma recovery therapists, mindfulness coaches, DBT therapists, addiction counselors, anxiety therapists, grief counselors, wellness coaches, career coaches, CBT therapists, relationship counselors, solution-focused therapists, and empathetic listeners.
AI-Powered Customer Support Chatbot
This AI-powered customer support chatbot is a cutting-edge tool that transforms customer engagement and drives revenue growth. It leverages advanced natural language processing (NLP) and machine learning algorithms to provide personalized, real-time support to customers across multiple channels. By automating routine inquiries, resolving complex issues, and offering proactive assistance, this chatbot empowers businesses to enhance customer satisfaction, increase conversion rates, and optimize their support operations.
Chicago Bull AI Wallstreet Chatbot
Chicago Bull AI Wallstreet Chatbot is an AI application designed to provide users with real-time information and insights on the stock market. Users can interact with the chatbot to ask questions related to equities, crypto, or bond markets. The chatbot is not affiliated with the Chicago Bulls organization or the National Basketball Association. It aims to assist users in making informed investment decisions by providing market updates and analysis.
40 - Open Source Tools

h2ogpt
h2oGPT is an Apache V2 open-source project that allows users to query and summarize documents or chat with local private GPT LLMs. It features a private offline database of any documents (PDFs, Excel, Word, Images, Video Frames, Youtube, Audio, Code, Text, MarkDown, etc.), a persistent database (Chroma, Weaviate, or in-memory FAISS) using accurate embeddings (instructor-large, all-MiniLM-L6-v2, etc.), and efficient use of context using instruct-tuned LLMs (no need for LangChain's few-shot approach). h2oGPT also offers parallel summarization and extraction, reaching an output of 80 tokens per second with the 13B LLaMa2 model, HYDE (Hypothetical Document Embeddings) for enhanced retrieval based upon LLM responses, a variety of models supported (LLaMa2, Mistral, Falcon, Vicuna, WizardLM. With AutoGPTQ, 4-bit/8-bit, LORA, etc.), GPU support from HF and LLaMa.cpp GGML models, and CPU support using HF, LLaMa.cpp, and GPT4ALL models. Additionally, h2oGPT provides Attention Sinks for arbitrarily long generation (LLaMa-2, Mistral, MPT, Pythia, Falcon, etc.), a UI or CLI with streaming of all models, the ability to upload and view documents through the UI (control multiple collaborative or personal collections), Vision Models LLaVa, Claude-3, Gemini-Pro-Vision, GPT-4-Vision, Image Generation Stable Diffusion (sdxl-turbo, sdxl) and PlaygroundAI (playv2), Voice STT using Whisper with streaming audio conversion, Voice TTS using MIT-Licensed Microsoft Speech T5 with multiple voices and Streaming audio conversion, Voice TTS using MPL2-Licensed TTS including Voice Cloning and Streaming audio conversion, AI Assistant Voice Control Mode for hands-free control of h2oGPT chat, Bake-off UI mode against many models at the same time, Easy Download of model artifacts and control over models like LLaMa.cpp through the UI, Authentication in the UI by user/password via Native or Google OAuth, State Preservation in the UI by user/password, Linux, Docker, macOS, and Windows support, Easy Windows Installer for Windows 10 64-bit (CPU/CUDA), Easy macOS Installer for macOS (CPU/M1/M2), Inference Servers support (oLLaMa, HF TGI server, vLLM, Gradio, ExLLaMa, Replicate, OpenAI, Azure OpenAI, Anthropic), OpenAI-compliant, Server Proxy API (h2oGPT acts as drop-in-replacement to OpenAI server), Python client API (to talk to Gradio server), JSON Mode with any model via code block extraction. Also supports MistralAI JSON mode, Claude-3 via function calling with strict Schema, OpenAI via JSON mode, and vLLM via guided_json with strict Schema, Web-Search integration with Chat and Document Q/A, Agents for Search, Document Q/A, Python Code, CSV frames (Experimental, best with OpenAI currently), Evaluate performance using reward models, and Quality maintained with over 1000 unit and integration tests taking over 4 GPU-hours.

mistral.rs
Mistral.rs is a fast LLM inference platform written in Rust. We support inference on a variety of devices, quantization, and easy-to-use application with an Open-AI API compatible HTTP server and Python bindings.

ollama
Ollama is a lightweight, extensible framework for building and running language models on the local machine. It provides a simple API for creating, running, and managing models, as well as a library of pre-built models that can be easily used in a variety of applications. Ollama is designed to be easy to use and accessible to developers of all levels. It is open source and available for free on GitHub.

llama-cpp-agent
The llama-cpp-agent framework is a tool designed for easy interaction with Large Language Models (LLMs). Allowing users to chat with LLM models, execute structured function calls and get structured output (objects). It provides a simple yet robust interface and supports llama-cpp-python and OpenAI endpoints with GBNF grammar support (like the llama-cpp-python server) and the llama.cpp backend server. It works by generating a formal GGML-BNF grammar of the user defined structures and functions, which is then used by llama.cpp to generate text valid to that grammar. In contrast to most GBNF grammar generators it also supports nested objects, dictionaries, enums and lists of them.

llama_ros
This repository provides a set of ROS 2 packages to integrate llama.cpp into ROS 2. By using the llama_ros packages, you can easily incorporate the powerful optimization capabilities of llama.cpp into your ROS 2 projects by running GGUF-based LLMs and VLMs.

MITSUHA
OneReality is a virtual waifu/assistant that you can speak to through your mic and it'll speak back to you! It has many features such as: * You can speak to her with a mic * It can speak back to you * Has short-term memory and long-term memory * Can open apps * Smarter than you * Fluent in English, Japanese, Korean, and Chinese * Can control your smart home like Alexa if you set up Tuya (more info in Prerequisites) It is built with Python, Llama-cpp-python, Whisper, SpeechRecognition, PocketSphinx, VITS-fast-fine-tuning, VITS-simple-api, HyperDB, Sentence Transformers, and Tuya Cloud IoT.

wenxin-starter
WenXin-Starter is a spring-boot-starter for Baidu's "Wenxin Qianfan WENXINWORKSHOP" large model, which can help you quickly access Baidu's AI capabilities. It fully integrates the official API documentation of Wenxin Qianfan. Supports text-to-image generation, built-in dialogue memory, and supports streaming return of dialogue. Supports QPS control of a single model and supports queuing mechanism. Plugins will be added soon.

FlexFlow
FlexFlow Serve is an open-source compiler and distributed system for **low latency**, **high performance** LLM serving. FlexFlow Serve outperforms existing systems by 1.3-2.0x for single-node, multi-GPU inference and by 1.4-2.4x for multi-node, multi-GPU inference.
lorax
LoRAX is a framework that allows users to serve thousands of fine-tuned models on a single GPU, dramatically reducing the cost of serving without compromising on throughput or latency. It features dynamic adapter loading, heterogeneous continuous batching, adapter exchange scheduling, optimized inference, and is ready for production with prebuilt Docker images, Helm charts for Kubernetes, Prometheus metrics, and distributed tracing with Open Telemetry. LoRAX supports a number of Large Language Models as the base model including Llama, Mistral, and Qwen, and any of the linear layers in the model can be adapted via LoRA and loaded in LoRAX.

bce-qianfan-sdk
The Qianfan SDK provides best practices for large model toolchains, allowing AI workflows and AI-native applications to access the Qianfan large model platform elegantly and conveniently. The core capabilities of the SDK include three parts: large model reasoning, large model training, and general and extension: * `Large model reasoning`: Implements interface encapsulation for reasoning of Yuyan (ERNIE-Bot) series, open source large models, etc., supporting dialogue, completion, Embedding, etc. * `Large model training`: Based on platform capabilities, it supports end-to-end large model training process, including training data, fine-tuning/pre-training, and model services. * `General and extension`: General capabilities include common AI development tools such as Prompt/Debug/Client. The extension capability is based on the characteristics of Qianfan to adapt to common middleware frameworks.

lobe-chat
Lobe Chat is an open-source, modern-design ChatGPT/LLMs UI/Framework. Supports speech-synthesis, multi-modal, and extensible ([function call][docs-functionc-call]) plugin system. One-click **FREE** deployment of your private OpenAI ChatGPT/Claude/Gemini/Groq/Ollama chat application.

agentscope
AgentScope is a multi-agent platform designed to empower developers to build multi-agent applications with large-scale models. It features three high-level capabilities: Easy-to-Use, High Robustness, and Actor-Based Distribution. AgentScope provides a list of `ModelWrapper` to support both local model services and third-party model APIs, including OpenAI API, DashScope API, Gemini API, and ollama. It also enables developers to rapidly deploy local model services using libraries such as ollama (CPU inference), Flask + Transformers, Flask + ModelScope, FastChat, and vllm. AgentScope supports various services, including Web Search, Data Query, Retrieval, Code Execution, File Operation, and Text Processing. Example applications include Conversation, Game, and Distribution. AgentScope is released under Apache License 2.0 and welcomes contributions.
casibase
Casibase is an open-source AI LangChain-like RAG (Retrieval-Augmented Generation) knowledge database with web UI and Enterprise SSO, supports OpenAI, Azure, LLaMA, Google Gemini, HuggingFace, Claude, Grok, etc.

azure-search-openai-demo
This sample demonstrates a few approaches for creating ChatGPT-like experiences over your own data using the Retrieval Augmented Generation pattern. It uses Azure OpenAI Service to access a GPT model (gpt-35-turbo), and Azure AI Search for data indexing and retrieval. The repo includes sample data so it's ready to try end to end. In this sample application we use a fictitious company called Contoso Electronics, and the experience allows its employees to ask questions about the benefits, internal policies, as well as job descriptions and roles.
WebAI-to-API
This project implements a web API that offers a unified interface to Google Gemini and Claude 3. It provides a self-hosted, lightweight, and scalable solution for accessing these AI models through a streaming API. The API supports both Claude and Gemini models, allowing users to interact with them in real-time. The project includes a user-friendly web UI for configuration and documentation, making it easy to get started and explore the capabilities of the API.

KwaiAgents
KwaiAgents is a series of Agent-related works open-sourced by the [KwaiKEG](https://github.com/KwaiKEG) from [Kuaishou Technology](https://www.kuaishou.com/en). The open-sourced content includes: 1. **KAgentSys-Lite**: a lite version of the KAgentSys in the paper. While retaining some of the original system's functionality, KAgentSys-Lite has certain differences and limitations when compared to its full-featured counterpart, such as: (1) a more limited set of tools; (2) a lack of memory mechanisms; (3) slightly reduced performance capabilities; and (4) a different codebase, as it evolves from open-source projects like BabyAGI and Auto-GPT. Despite these modifications, KAgentSys-Lite still delivers comparable performance among numerous open-source Agent systems available. 2. **KAgentLMs**: a series of large language models with agent capabilities such as planning, reflection, and tool-use, acquired through the Meta-agent tuning proposed in the paper. 3. **KAgentInstruct**: over 200k Agent-related instructions finetuning data (partially human-edited) proposed in the paper. 4. **KAgentBench**: over 3,000 human-edited, automated evaluation data for testing Agent capabilities, with evaluation dimensions including planning, tool-use, reflection, concluding, and profiling.

lmdeploy
LMDeploy is a toolkit for compressing, deploying, and serving LLM, developed by the MMRazor and MMDeploy teams. It has the following core features: * **Efficient Inference** : LMDeploy delivers up to 1.8x higher request throughput than vLLM, by introducing key features like persistent batch(a.k.a. continuous batching), blocked KV cache, dynamic split&fuse, tensor parallelism, high-performance CUDA kernels and so on. * **Effective Quantization** : LMDeploy supports weight-only and k/v quantization, and the 4-bit inference performance is 2.4x higher than FP16. The quantization quality has been confirmed via OpenCompass evaluation. * **Effortless Distribution Server** : Leveraging the request distribution service, LMDeploy facilitates an easy and efficient deployment of multi-model services across multiple machines and cards. * **Interactive Inference Mode** : By caching the k/v of attention during multi-round dialogue processes, the engine remembers dialogue history, thus avoiding repetitive processing of historical sessions.
fastllm
FastLLM is a high-performance large model inference library implemented in pure C++ with no third-party dependencies. Models of 6-7B size can run smoothly on Android devices. Deployment communication QQ group: 831641348
kimi-free-api
KIMI AI Free 服务 支持高速流式输出、支持多轮对话、支持联网搜索、支持长文档解读、支持图像解析,零配置部署,多路token支持,自动清理会话痕迹。 与ChatGPT接口完全兼容。 还有以下五个free-api欢迎关注: 阶跃星辰 (跃问StepChat) 接口转API step-free-api 阿里通义 (Qwen) 接口转API qwen-free-api ZhipuAI (智谱清言) 接口转API glm-free-api 秘塔AI (metaso) 接口转API metaso-free-api 聆心智能 (Emohaa) 接口转API emohaa-free-api
BlossomLM
BlossomLM is a series of open-source conversational large language models. This project aims to provide a high-quality general-purpose SFT dataset in both Chinese and English, making fine-tuning accessible while also providing pre-trained model weights. **Hint**: BlossomLM is a personal non-commercial project.
ChatGLM3
ChatGLM3 is a conversational pretrained model jointly released by Zhipu AI and THU's KEG Lab. ChatGLM3-6B is the open-sourced model in the ChatGLM3 series. It inherits the advantages of its predecessors, such as fluent conversation and low deployment threshold. In addition, ChatGLM3-6B introduces the following features: 1. A stronger foundation model: ChatGLM3-6B's foundation model ChatGLM3-6B-Base employs more diverse training data, more sufficient training steps, and more reasonable training strategies. Evaluation on datasets from different perspectives, such as semantics, mathematics, reasoning, code, and knowledge, shows that ChatGLM3-6B-Base has the strongest performance among foundation models below 10B parameters. 2. More complete functional support: ChatGLM3-6B adopts a newly designed prompt format, which supports not only normal multi-turn dialogue, but also complex scenarios such as tool invocation (Function Call), code execution (Code Interpreter), and Agent tasks. 3. A more comprehensive open-source sequence: In addition to the dialogue model ChatGLM3-6B, the foundation model ChatGLM3-6B-Base, the long-text dialogue model ChatGLM3-6B-32K, and ChatGLM3-6B-128K, which further enhances the long-text comprehension ability, are also open-sourced. All the above weights are completely open to academic research and are also allowed for free commercial use after filling out a questionnaire.
Chinese-LLaMA-Alpaca
This project open sources the **Chinese LLaMA model and the Alpaca large model fine-tuned with instructions**, to further promote the open research of large models in the Chinese NLP community. These models **extend the Chinese vocabulary based on the original LLaMA** and use Chinese data for secondary pre-training, further enhancing the basic Chinese semantic understanding ability. At the same time, the Chinese Alpaca model further uses Chinese instruction data for fine-tuning, significantly improving the model's understanding and execution of instructions.
langchain-swift
LangChain for Swift. Optimized for iOS, macOS, watchOS (part) and visionOS.(beta) This is a pure client library, no server required
rtp-llm
**rtp-llm** is a Large Language Model (LLM) inference acceleration engine developed by Alibaba's Foundation Model Inference Team. It is widely used within Alibaba Group, supporting LLM service across multiple business units including Taobao, Tmall, Idlefish, Cainiao, Amap, Ele.me, AE, and Lazada. The rtp-llm project is a sub-project of the havenask.
InfLLM
InfLLM is a training-free memory-based method that unveils the intrinsic ability of LLMs to process streaming long sequences. It stores distant contexts into additional memory units and employs an efficient mechanism to lookup token-relevant units for attention computation. Thereby, InfLLM allows LLMs to efficiently process long sequences while maintaining the ability to capture long-distance dependencies. Without any training, InfLLM enables LLMs pre-trained on sequences of a few thousand tokens to achieve superior performance than competitive baselines continually training these LLMs on long sequences. Even when the sequence length is scaled to 1, 024K, InfLLM still effectively captures long-distance dependencies.

ScaleLLM
ScaleLLM is a cutting-edge inference system engineered for large language models (LLMs), meticulously designed to meet the demands of production environments. It extends its support to a wide range of popular open-source models, including Llama3, Gemma, Bloom, GPT-NeoX, and more. ScaleLLM is currently undergoing active development. We are fully committed to consistently enhancing its efficiency while also incorporating additional features. Feel free to explore our **_Roadmap_** for more details. ## Key Features * High Efficiency: Excels in high-performance LLM inference, leveraging state-of-the-art techniques and technologies like Flash Attention, Paged Attention, Continuous batching, and more. * Tensor Parallelism: Utilizes tensor parallelism for efficient model execution. * OpenAI-compatible API: An efficient golang rest api server that compatible with OpenAI. * Huggingface models: Seamless integration with most popular HF models, supporting safetensors. * Customizable: Offers flexibility for customization to meet your specific needs, and provides an easy way to add new models. * Production Ready: Engineered with production environments in mind, ScaleLLM is equipped with robust system monitoring and management features to ensure a seamless deployment experience.
gptel
GPTel is a simple Large Language Model chat client for Emacs, with support for multiple models and backends. It's async and fast, streams responses, and interacts with LLMs from anywhere in Emacs. LLM responses are in Markdown or Org markup. Supports conversations and multiple independent sessions. Chats can be saved as regular Markdown/Org/Text files and resumed later. You can go back and edit your previous prompts or LLM responses when continuing a conversation. These will be fed back to the model. Don't like gptel's workflow? Use it to create your own for any supported model/backend with a simple API.
langroid
Langroid is a Python framework that makes it easy to build LLM-powered applications. It uses a multi-agent paradigm inspired by the Actor Framework, where you set up Agents, equip them with optional components (LLM, vector-store and tools/functions), assign them tasks, and have them collaboratively solve a problem by exchanging messages. Langroid is a fresh take on LLM app-development, where considerable thought has gone into simplifying the developer experience; it does not use Langchain.
chatgpt-on-wechat
This project is a smart chatbot based on a large model, supporting WeChat, WeChat Official Account, Feishu, and DingTalk access. You can choose from GPT3.5/GPT4.0/Claude/Wenxin Yanyi/Xunfei Xinghuo/Tongyi Qianwen/Gemini/LinkAI/ZhipuAI, which can process text, voice, and images, and access external resources such as operating systems and the Internet through plugins, supporting the development of enterprise AI applications based on proprietary knowledge bases.
llm_finetuning
This repository provides a comprehensive set of tools for fine-tuning large language models (LLMs) using various techniques, including full parameter training, LoRA (Low-Rank Adaptation), and P-Tuning V2. It supports a wide range of LLM models, including Qwen, Yi, Llama, and others. The repository includes scripts for data preparation, training, and inference, making it easy for users to fine-tune LLMs for specific tasks. Additionally, it offers a collection of pre-trained models and provides detailed documentation and examples to guide users through the process.
chatglm.cpp
ChatGLM.cpp is a C++ implementation of ChatGLM-6B, ChatGLM2-6B, ChatGLM3-6B and more LLMs for real-time chatting on your MacBook. It is based on ggml, working in the same way as llama.cpp. ChatGLM.cpp features accelerated memory-efficient CPU inference with int4/int8 quantization, optimized KV cache and parallel computing. It also supports P-Tuning v2 and LoRA finetuned models, streaming generation with typewriter effect, Python binding, web demo, api servers and more possibilities.

Qwen
Qwen is a series of large language models developed by Alibaba DAMO Academy. It outperforms the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen models outperform the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen-72B achieves better performance than LLaMA2-70B on all tasks and outperforms GPT-3.5 on 7 out of 10 tasks.

langserve
LangServe helps developers deploy `LangChain` runnables and chains as a REST API. This library is integrated with FastAPI and uses pydantic for data validation. In addition, it provides a client that can be used to call into runnables deployed on a server. A JavaScript client is available in LangChain.js.
neural-speed
Neural Speed is an innovative library designed to support the efficient inference of large language models (LLMs) on Intel platforms through the state-of-the-art (SOTA) low-bit quantization powered by Intel Neural Compressor. The work is inspired by llama.cpp and further optimized for Intel platforms with our innovations in NeurIPS' 2023
groq-ruby
Groq Cloud runs LLM models fast and cheap. Llama 3, Mixtrel, Gemma, and more at hundreds of tokens per second, at cents per million tokens.
openai_trtllm
OpenAI-compatible API for TensorRT-LLM and NVIDIA Triton Inference Server, which allows you to integrate with langchain
modelscope-agent
ModelScope-Agent is a customizable and scalable Agent framework. A single agent has abilities such as role-playing, LLM calling, tool usage, planning, and memory. It mainly has the following characteristics: - **Simple Agent Implementation Process**: Simply specify the role instruction, LLM name, and tool name list to implement an Agent application. The framework automatically arranges workflows for tool usage, planning, and memory. - **Rich models and tools**: The framework is equipped with rich LLM interfaces, such as Dashscope and Modelscope model interfaces, OpenAI model interfaces, etc. Built in rich tools, such as **code interpreter**, **weather query**, **text to image**, **web browsing**, etc., make it easy to customize exclusive agents. - **Unified interface and high scalability**: The framework has clear tools and LLM registration mechanism, making it convenient for users to expand more diverse Agent applications. - **Low coupling**: Developers can easily use built-in tools, LLM, memory, and other components without the need to bind higher-level agents.
llama.rn
React Native binding of llama.cpp, which is an inference of LLaMA model in pure C/C++. This tool allows you to use the LLaMA model in your React Native applications for various tasks such as text completion, tokenization, detokenization, and embedding. It provides a convenient interface to interact with the LLaMA model and supports features like grammar sampling and mocking for testing purposes.

ruby-openai
Use the OpenAI API with Ruby! 🤖🩵 Stream text with GPT-4, transcribe and translate audio with Whisper, or create images with DALL·E... Hire me | 🎮 Ruby AI Builders Discord | 🐦 Twitter | 🧠 Anthropic Gem | 🚂 Midjourney Gem ## Table of Contents * Ruby OpenAI * Table of Contents * Installation * Bundler * Gem install * Usage * Quickstart * With Config * Custom timeout or base URI * Extra Headers per Client * Logging * Errors * Faraday middleware * Azure * Ollama * Counting Tokens * Models * Examples * Chat * Streaming Chat * Vision * JSON Mode * Functions * Edits * Embeddings * Batches * Files * Finetunes * Assistants * Threads and Messages * Runs * Runs involving function tools * Image Generation * DALL·E 2 * DALL·E 3 * Image Edit * Image Variations * Moderations * Whisper * Translate * Transcribe * Speech * Errors * Development * Release * Contributing * License * Code of Conduct

ray-llm
RayLLM (formerly known as Aviary) is an LLM serving solution that makes it easy to deploy and manage a variety of open source LLMs, built on Ray Serve. It provides an extensive suite of pre-configured open source LLMs, with defaults that work out of the box. RayLLM supports Transformer models hosted on Hugging Face Hub or present on local disk. It simplifies the deployment of multiple LLMs, the addition of new LLMs, and offers unique autoscaling support, including scale-to-zero. RayLLM fully supports multi-GPU & multi-node model deployments and offers high performance features like continuous batching, quantization and streaming. It provides a REST API that is similar to OpenAI's to make it easy to migrate and cross test them. RayLLM supports multiple LLM backends out of the box, including vLLM and TensorRT-LLM.
20 - OpenAI Gpts


1177 AI ChatBot
En virtuell sjuksköterska som ger empatiska och korrekta hälsoråd från 1177.
Swifty Chatbot
Chat with Taylor, offering friendly and supportive responses to her Swifties

Your SF CRM Assistant Chatbot
A 20+ year Technical Salesforce CRM Expert Chatbot by Scott Ohlund

Hoseo University International Management Chatbot
Expert on International Business lectures, using specific course material for detailed responses.
Awakening From The Meaning Crisis GPT
A sophisticated chatbot for deep discussions and learning from John Vervaeke's philosophical series.

Sub-Turing BradBot I
ChatBot for first-line question virtual office hours on Prof. J. Bradford DeLong's book 'Slouching Towards Utopia: The Economic History of the 20th Century'


IB Interview Guide
Master the Investment Banking Interview Arena: Chatbot Solutions to Ace Any Banking Question

GPT Master🛠️💡🤖
Hello there! 👋 I'm GPT Master, the ultimate tool, state-of-art AI for creating amazing chatbots! 🚀 Whether you're a newbie or a pro, I'm here to help you creating the Ultimate Chatbot 🤖

Can't Hack This
A playful, trolling chatbot that roasts users in a game of wits. Updated: 2023-11-19 V0.3

PitchDeckAssistantGPT
Assists in creating chatbots for pitch decks in business and fundraising.