AI tools for captions
Related Tools:
Captions
Captions is an AI-powered creative studio that helps users create high-quality videos, add subtitles, correct eye contact, trim and compress videos, and more. It is trusted by over 3 million people worldwide and offers a variety of features to make video creation and editing easier and more efficient.
Captions
Captions is an AI-powered creative studio that offers a wide range of tools to simplify the video creation process. With features like automatic captioning, eye contact correction, video trimming, background noise removal, and more, Captions empowers users to create professional-grade videos effortlessly. Trusted by millions worldwide, Captions leverages the power of AI to enhance storytelling and streamline video production.
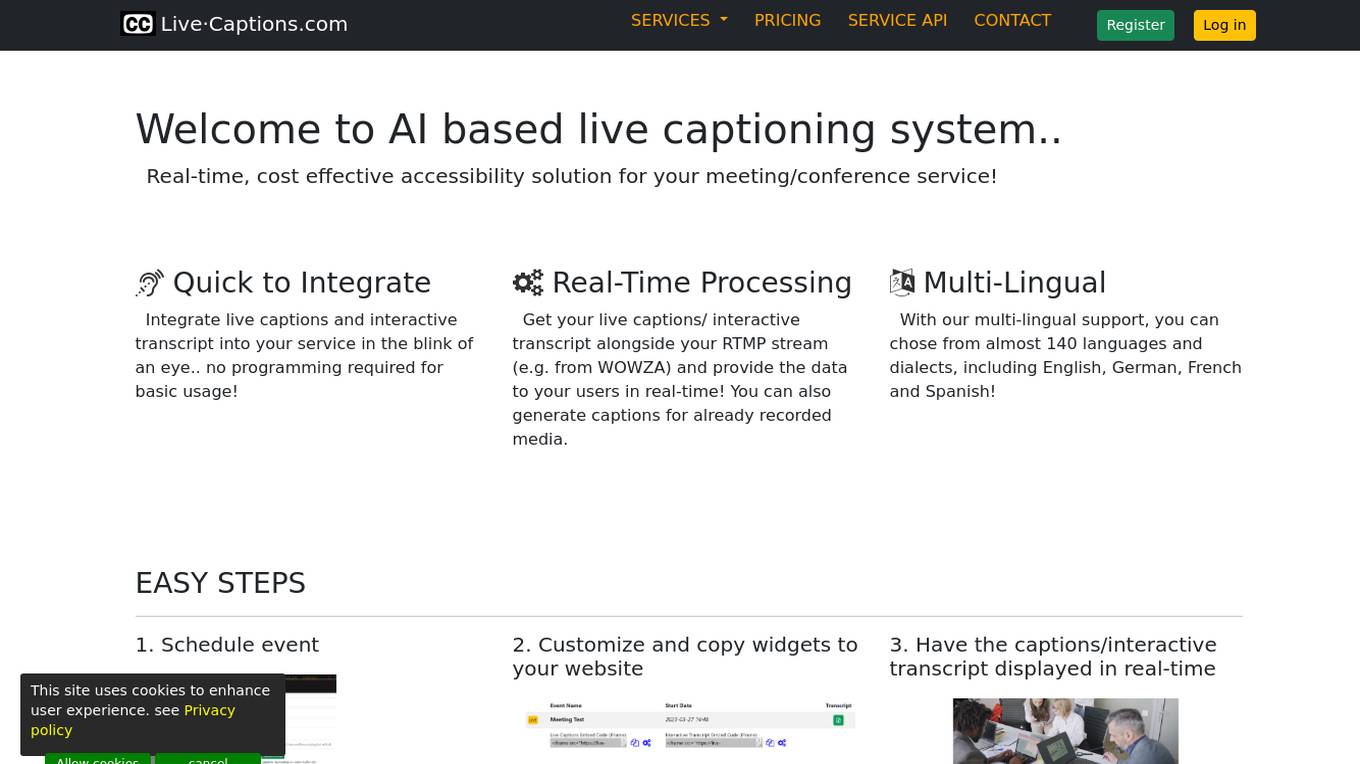
Live-captions.com
Live-captions.com is an AI-based live captioning service that offers real-time, cost-effective accessibility solutions for meetings and conferences. The service allows users to integrate live captions and interactive transcripts seamlessly, without the need for programming. With real-time processing capabilities, users can provide live captions alongside their RTMP streams or generate captions for recorded media. The platform supports multi-lingual options, with nearly 140 languages and dialects available. Live-captions.com aims to automate captioning services through its programmatic API, making it a valuable tool for enhancing accessibility and user experience.
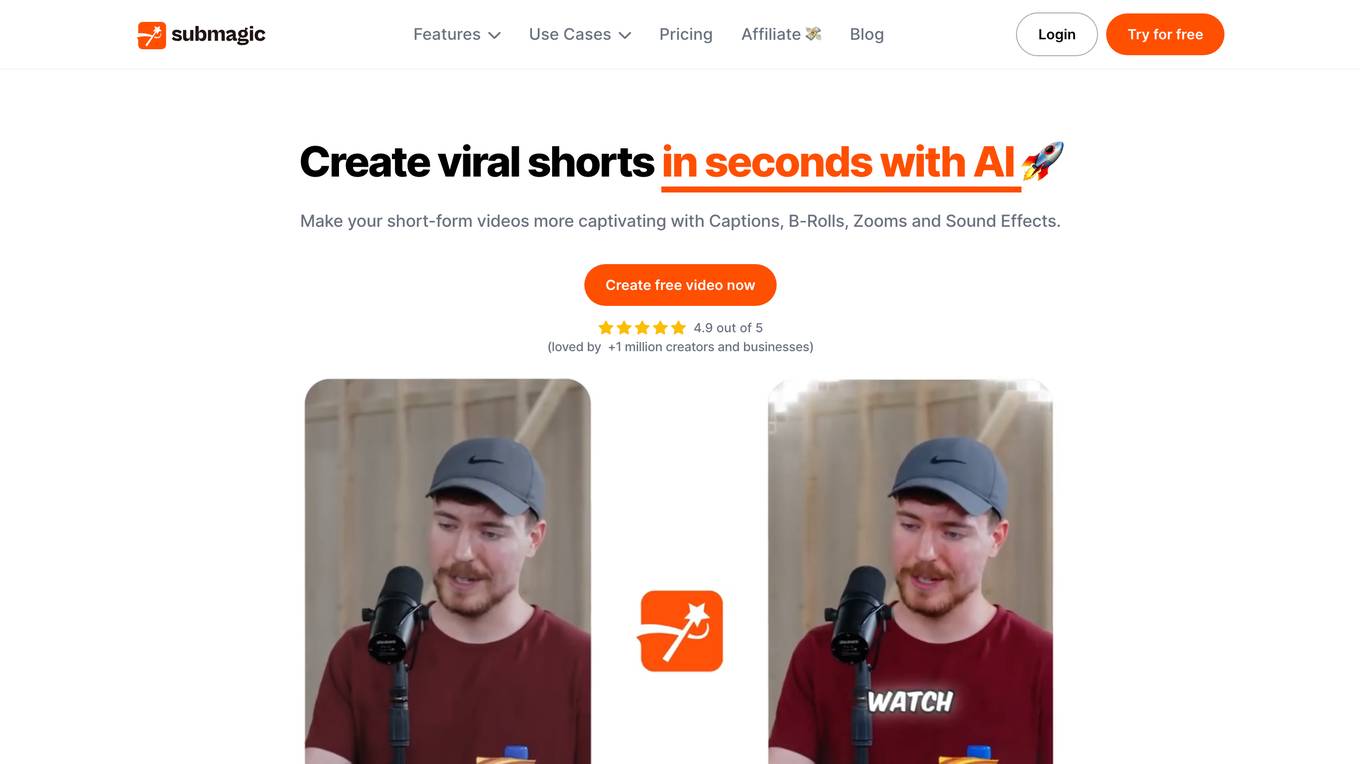
Submagic
Submagic is an AI tool designed to help users create captivating short-form videos in seconds. It offers features such as auto subtitle generation, video editing automation, and AI-powered enhancements. With Submagic, users can easily transform raw footage into viral shorts with just a few clicks, saving time and effort in the video editing process. The platform also provides tools for captions, B-Roll footage, sound effects, and more, making it a comprehensive solution for creating engaging video content.
Vadoo AI
Vadoo AI is an all-in-one AI video generator that allows users to create professional-quality AI videos from text prompts with ease. The platform offers powerful features such as captions, transitions, background music, B-Roll, auto-zoom, and sound effects. Users can customize their videos by adding voiceovers, subtitles, and various editing tools. Vadoo AI simplifies the process of creating engaging and informative videos for a global audience, making it a valuable tool for content creators, marketers, and educators.
Captions App
Captions App is an AI-powered subtitles and captions application designed to help content creators easily subtitle their videos in multiple languages. The app offers features such as auto-subtitle generation, video translation, AI video dubbing, teleprompter functionality, and AI script generation. With a user-friendly interface and advanced AI technology, Captions App enables users to customize subtitles, add animations, and dub videos with their own voice in over 100 languages. The app aims to make video content more accessible, engaging, and globally appealing.
imagetocaption.ai
imagetocaption.ai is an AI-powered tool designed to generate captions for images and videos across various platforms such as social media, Shopify, Instagram, TikTok, and more. It uses modern AI technology to create captions that resonate with the audience, allowing users to customize themes, tones, and additional information. With the option to add brand voice details, the tool ensures authentic and relevant social media texts. Users can upload their own photos and videos, set custom brand voices, and benefit from the ease of use and customization offered by the tool.
Line 21
Line 21 is an intelligent captioning solution that provides real-time remote captioning services in over a hundred languages. The platform offers a state-of-the-art caption delivery software that combines human expertise with AI services to create, enhance, translate, and deliver live captions to various viewer destinations. Line 21 supports accessible corporations, concerts, societies, and screenings by delivering fast and accurate captions through low-latency delivery methods. The platform also features an Ai Proofreader for real-time caption accuracy, caption encoding, fast caption delivery, and automatic translations in over 100 languages.
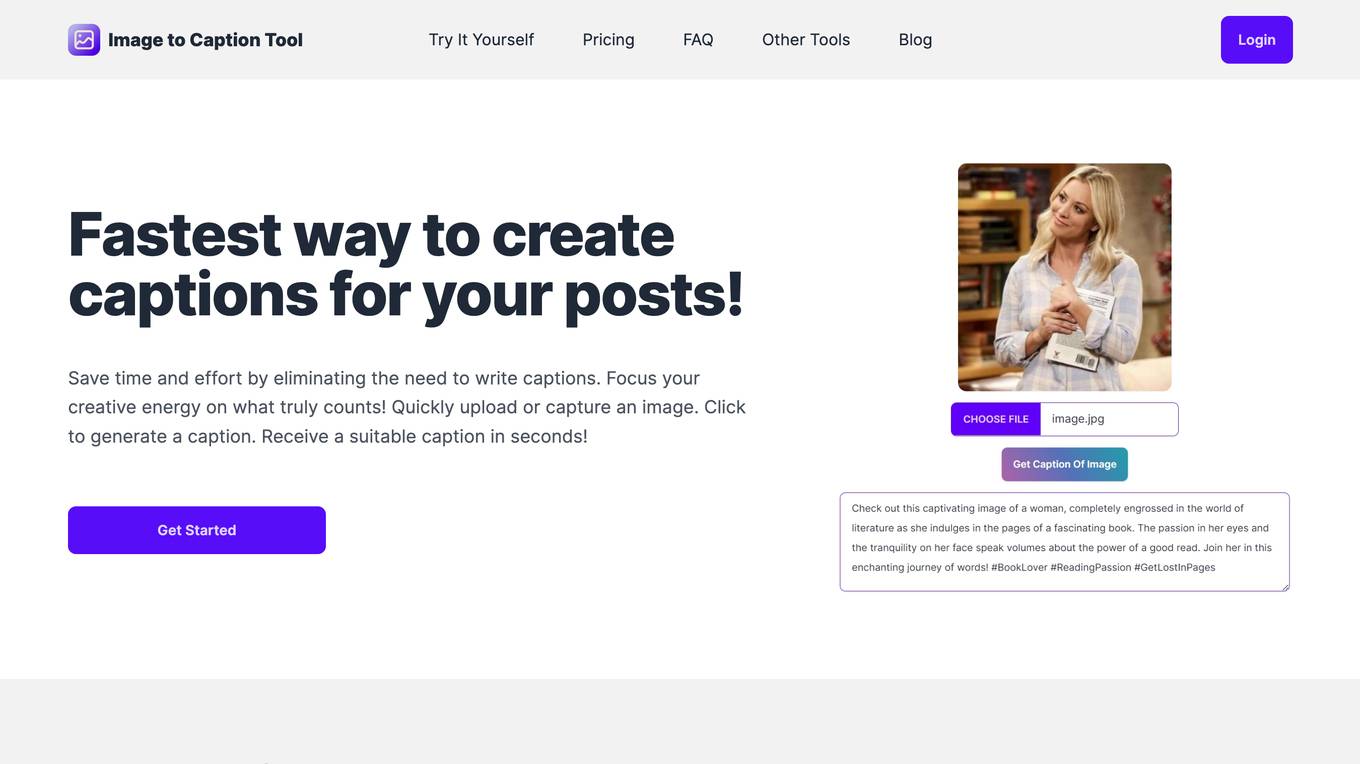
Image to Caption Tool
Image to Caption Tool is an AI application that provides a fast and efficient way to generate captions for images. Users can easily upload or capture an image and receive a suitable caption in seconds, saving time and effort. The tool offers different pricing plans to cater to various user needs and provides 24/7 email support. Currently supporting only English, the tool aims to enhance user experience by continuously adding more languages. With a user-friendly interface, Image to Caption Tool is designed to streamline the caption generation process for social media posts and other content.
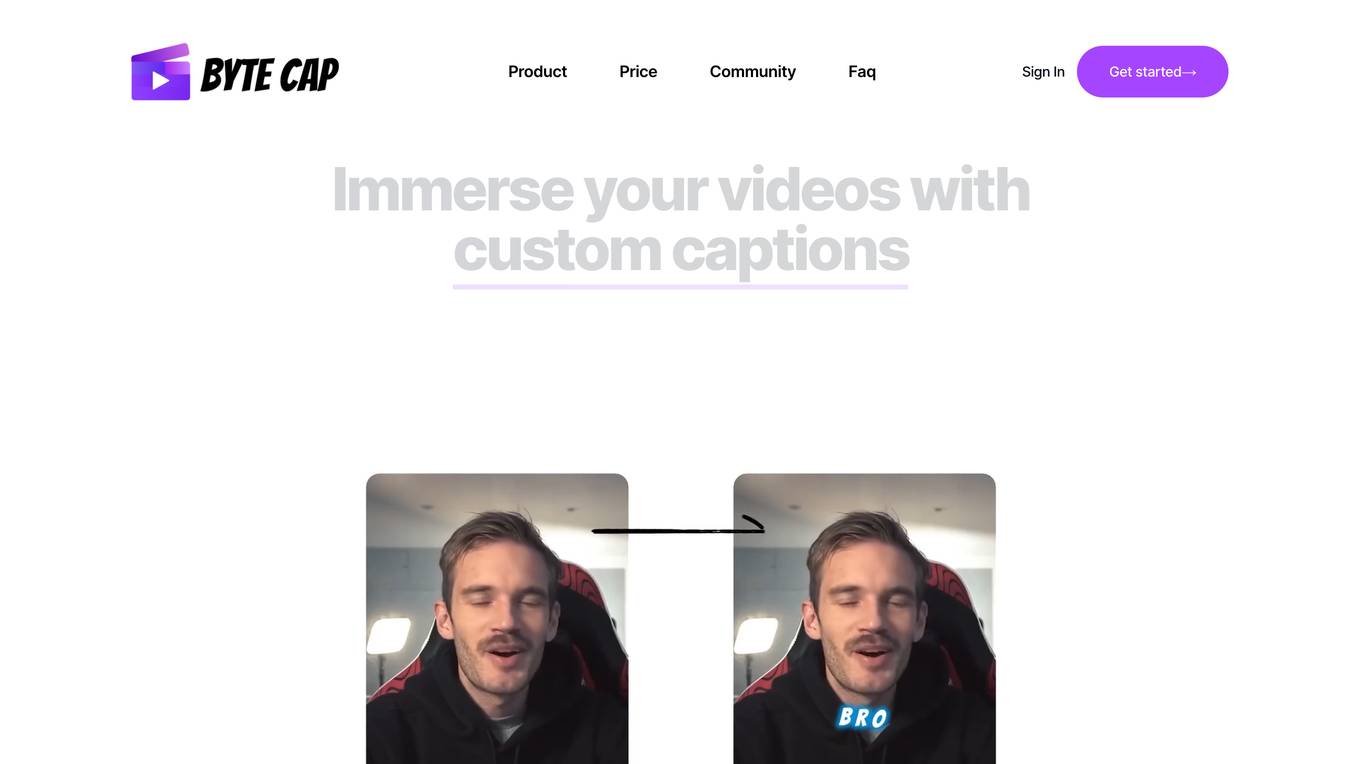
ByteCap
ByteCap is an AI-powered video editing tool that allows users to create engaging and captivating videos with custom AI captions. With advanced speech recognition technology, users can auto-create accurate captions in multiple languages. The tool also enables the creation of stunning faceless videos by incorporating AI images, voice, and captions. Users can personalize their videos with custom captions, images, emojis, effects, music, and highlights. ByteCap offers a range of features such as customizable AI faceless videos, support for various caption formats, trendy sounds, background music, and expertly crafted caption themes. It is a versatile solution for video editors, content creators, podcasters, and streamers to enhance their video content and reach a wider audience.
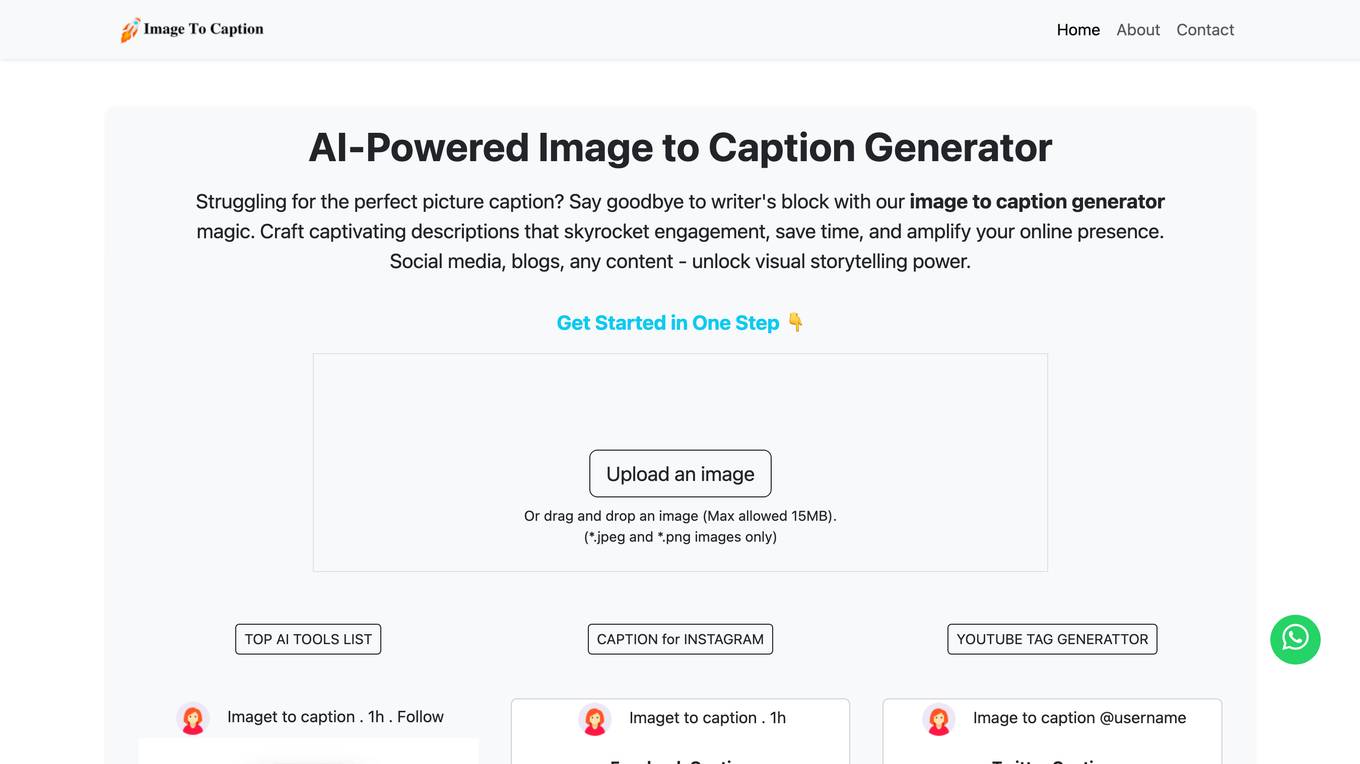
Image to Caption Generator
The AI-Powered Image to Caption Generator is a revolutionary tool that utilizes artificial intelligence to analyze images and generate engaging captions tailored to each image. By recognizing key objects, scenes, and emotional tones in the image, the tool crafts captivating narratives that spark conversation and boost engagement. Users can save time, maintain brand consistency, and stay ahead of social media marketing trends with this innovative AI application.

Spikes Studio
Spikes Studio is an AI-powered video editing tool that specializes in transforming long videos into viral clips for platforms like YouTube, Twitch, TikTok, and Reels. The platform offers advanced editing features, such as auto-captions, AI-generated B-Roll, audio enhancements, GIFs, and social media scheduling. With a focus on boosting viewer retention and engagement, Spikes Studio provides a fast and efficient solution for content creators to repurpose their videos effortlessly.
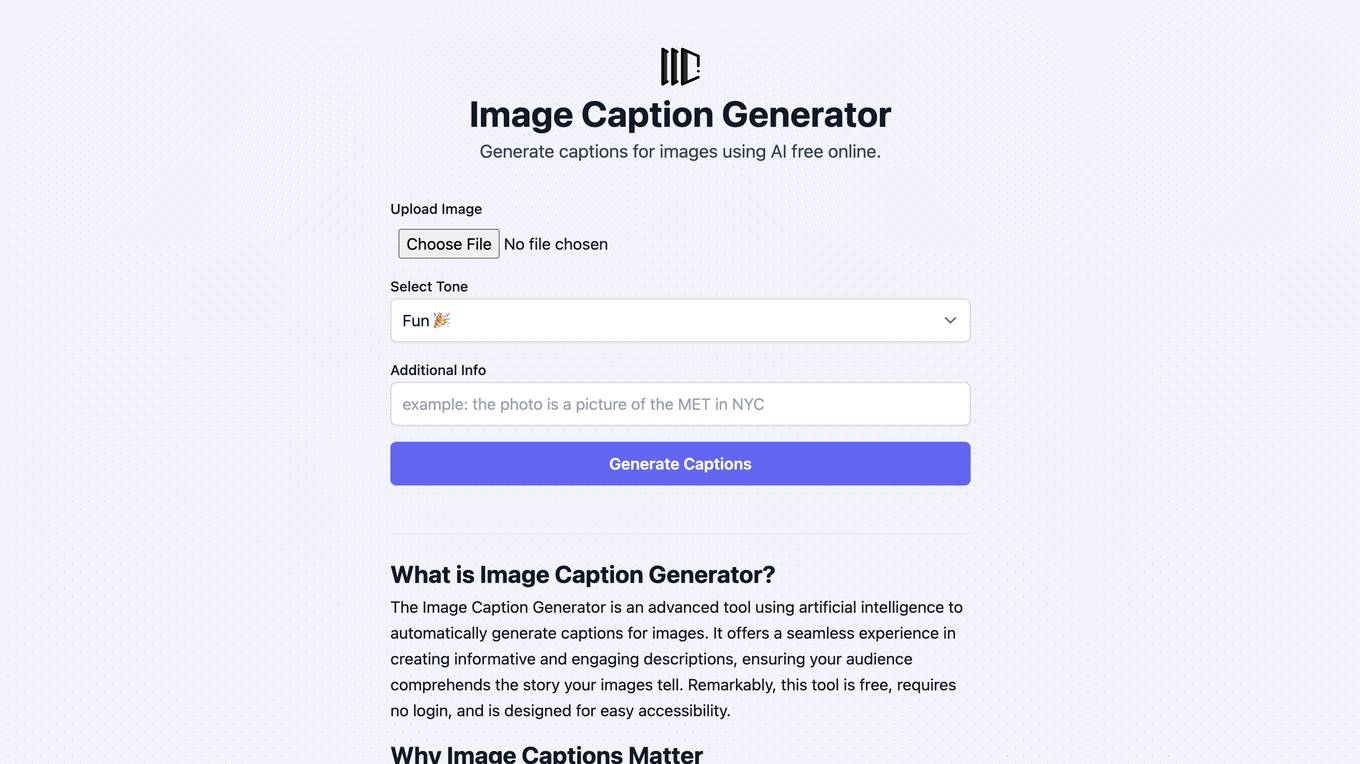
Image Caption Generator
Image Caption Generator is a free online tool that uses AI to create compelling captions for images. It offers instant results, requires no login, is completely free, and supports multiple languages. Ideal for social media enthusiasts, bloggers, marketers, and content creators, the tool enhances storytelling through visuals by providing engaging and relevant captions. It helps in enhancing context, boosting engagement, improving accessibility, and SEO optimization. The AI-powered technology ensures accurate and impactful caption generation, making visual content more memorable and effective.
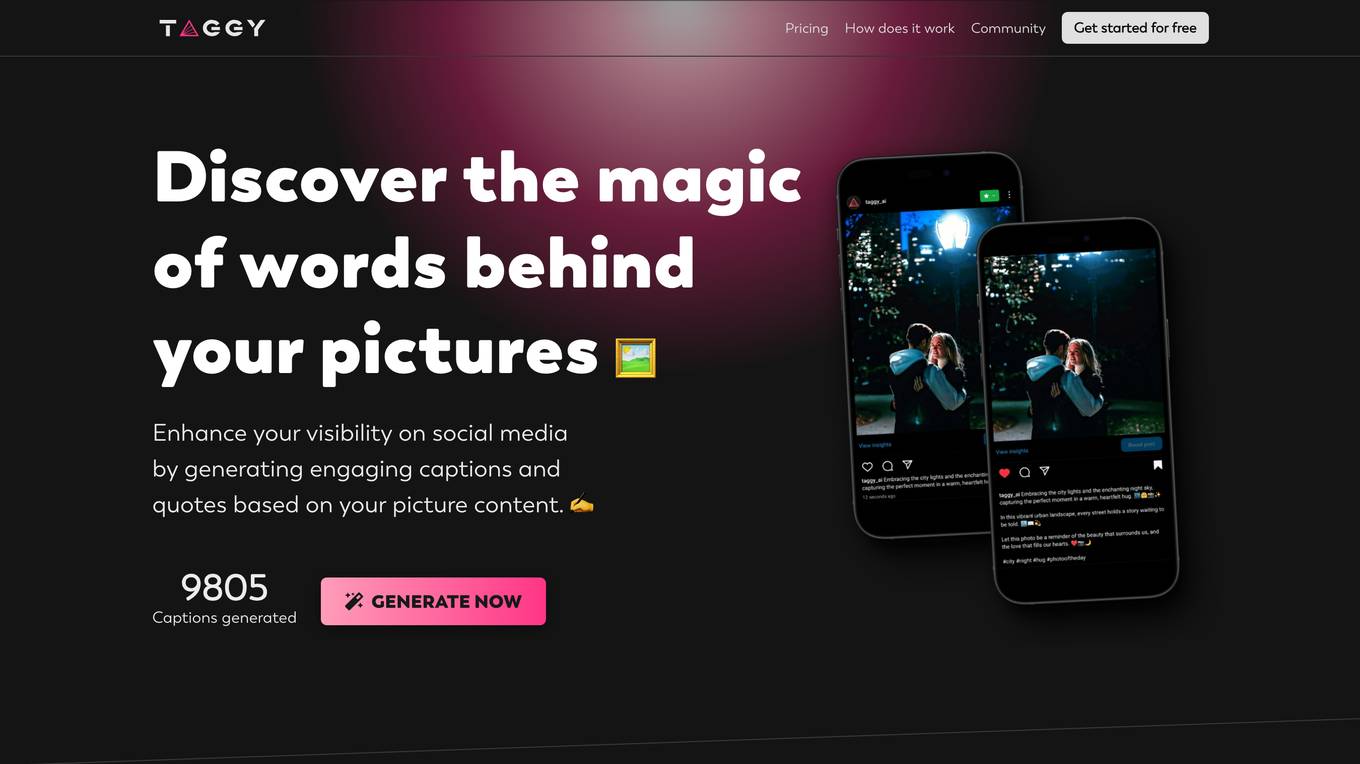
Taggy
Taggy is an AI-powered tool that helps you generate engaging captions and quotes for your social media posts. It analyzes the content of your pictures and suggests relevant text that you can use to promote your brand or connect with your audience. With Taggy, you can save time and effort while creating high-quality content that will help you stand out on social media.
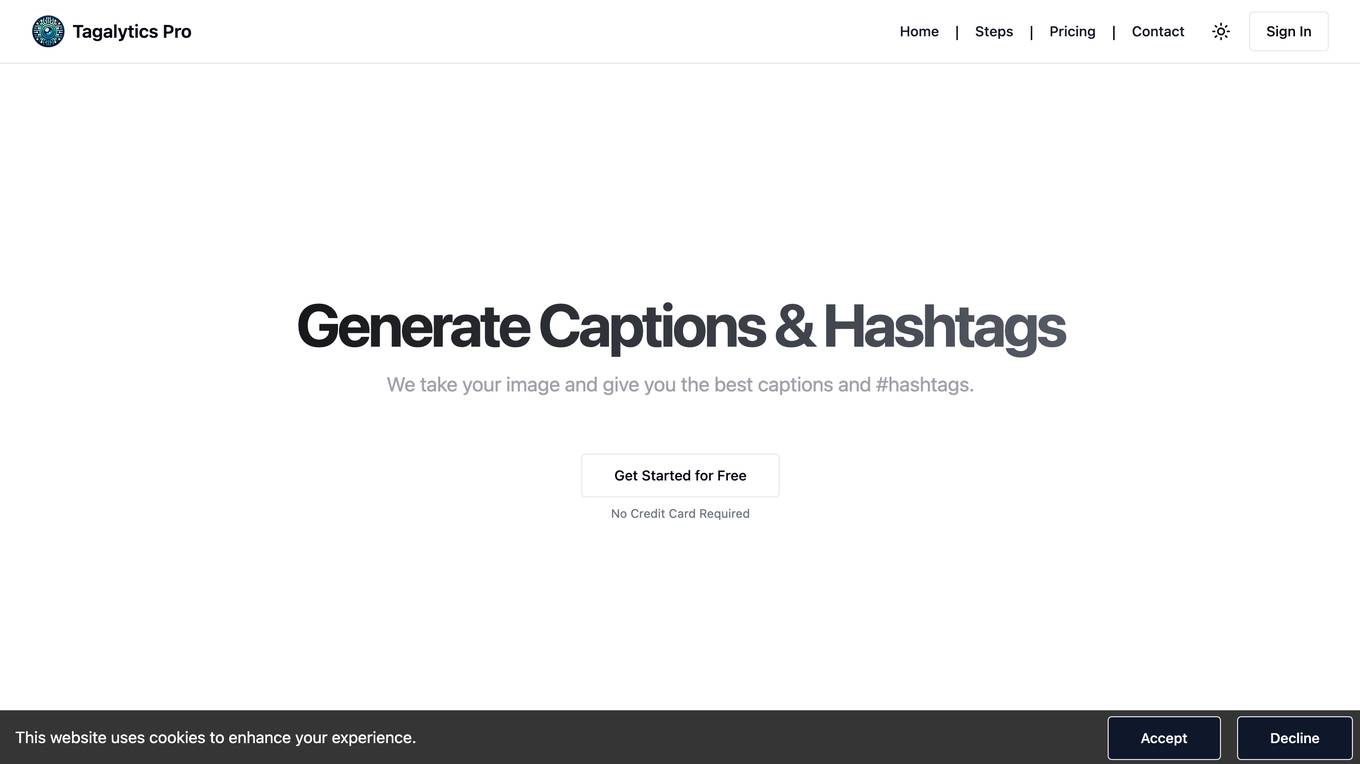
Tagalytics Pro
Tagalytics Pro is an AI-driven caption and hashtag generator that helps users create engaging and effective content for social media. The tool uses artificial intelligence to analyze images and generate a variety of captions and hashtags that are relevant to the content. Tagalytics Pro is designed to be easy to use and affordable, making it a great option for businesses and individuals who want to improve their social media presence.
3Play Media
3Play Media is a leading provider of AI-powered media accessibility solutions. Our mission is to make the world's media accessible to everyone, regardless of their abilities. We offer a suite of products and services that make it easy to add captions, transcripts, audio descriptions, and other accessibility features to your videos and audio content.
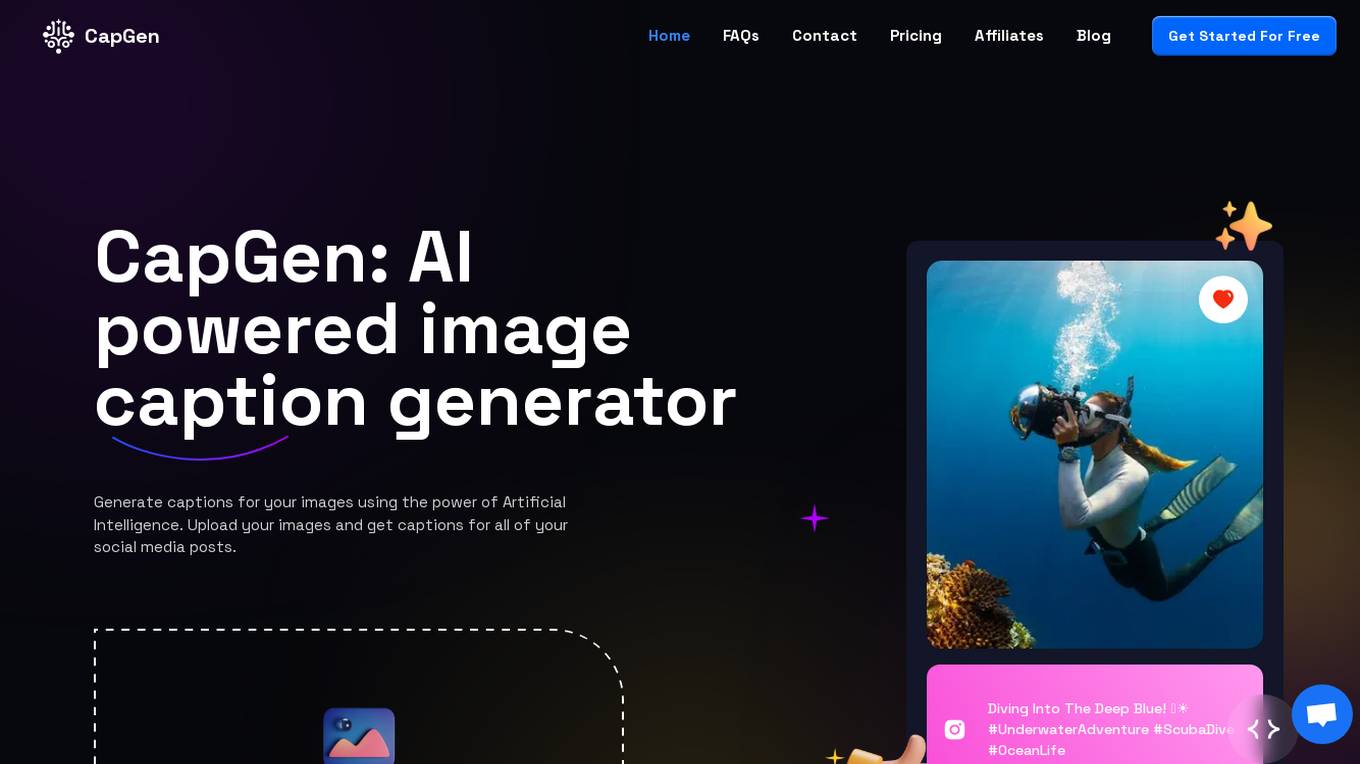
CapGen
CapGen is an AI-powered image caption generator that helps users create engaging captions for their social media posts. By leveraging the power of Artificial Intelligence, CapGen generates unique captions for uploaded images, enhancing the visual storytelling experience for users. The application caters to a wide range of users, from freelance writers and photographers to social media influencers and marketing teams, offering a user-friendly platform to boost online engagement and brand reach.
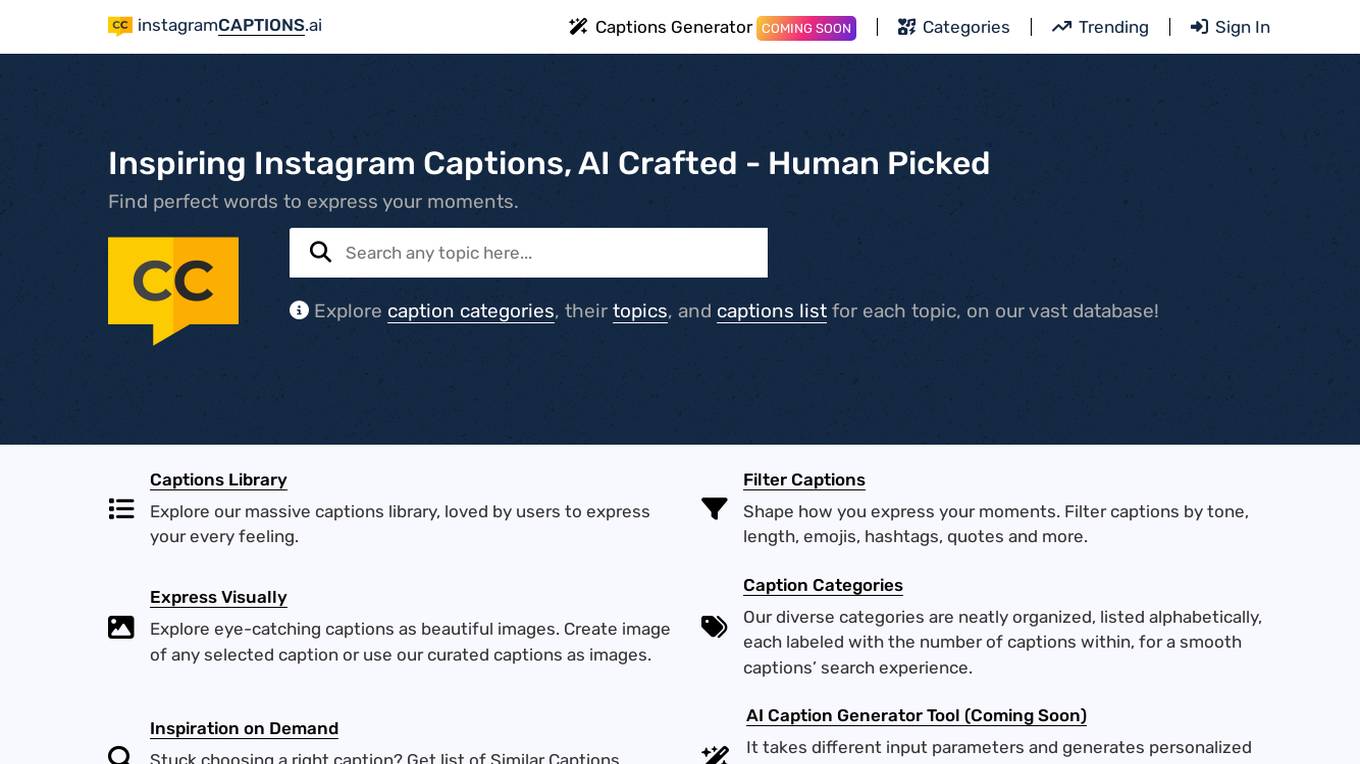
Inspiring Instagram Captions
Inspiring Instagram Captions is an AI-powered tool that helps users find perfect words to express their moments on Instagram. The tool offers a vast database of caption categories, allowing users to explore and filter captions based on tone, length, emojis, hashtags, and quotes. Users can also create visually appealing images using the tool's curated captions. Additionally, the tool features an AI Caption Generator that generates personalized captions based on input parameters, enhancing users' caption creation experience.
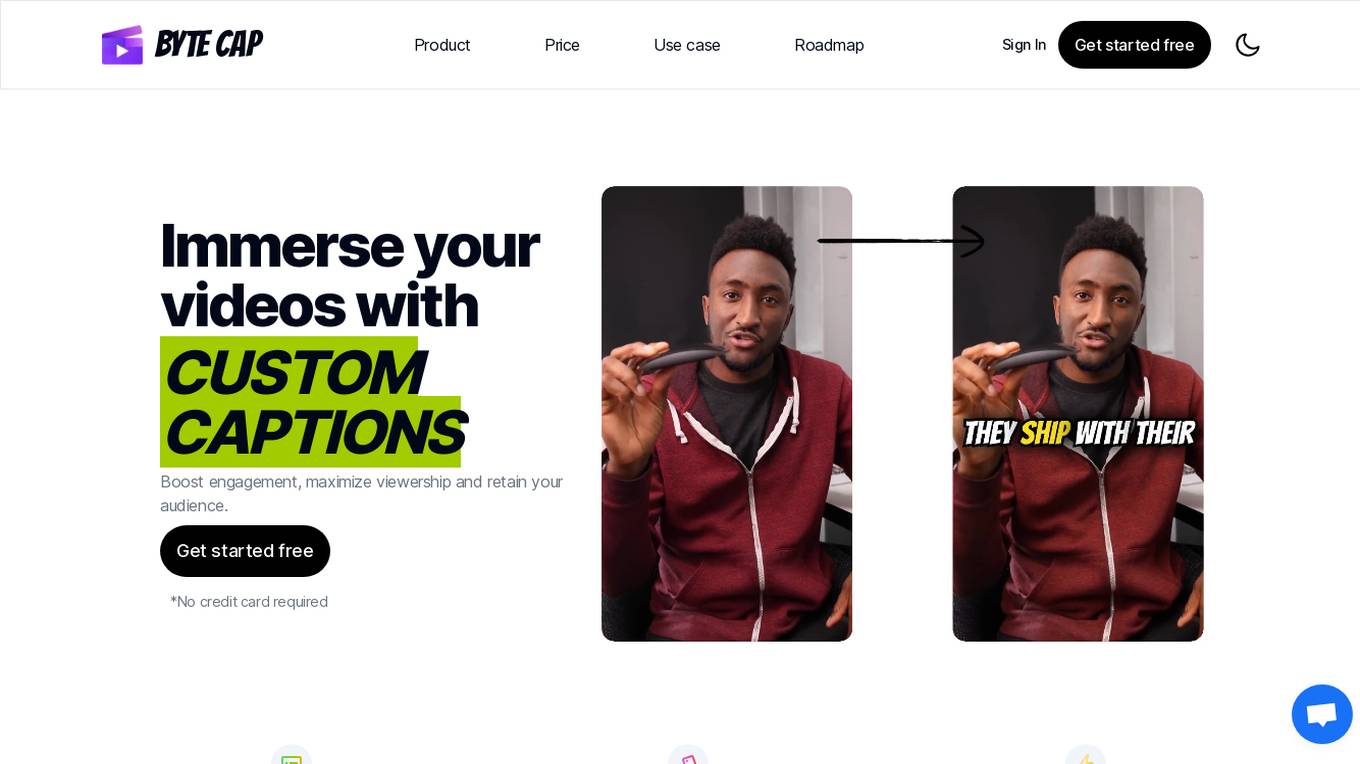
Bytecap
Bytecap is an AI application that allows users to immerse their videos with custom AI captions. It offers features such as auto creation of 99% accurate captions using advanced speech recognition, customization of captions with fonts, colors, emojis, effects, music, and highlights, and AI-generated hook titles and descriptions for boosting engagement. Bytecap supports over 99 languages, provides complete caption control, and offers trendy sounds and background music options. The application caters to video editors, content creators, podcasters, and streamers, enabling them to save time, expand reach, and increase brand awareness. Bytecap ensures privacy and security, offers free trial options, and allows users to edit captions after creation.
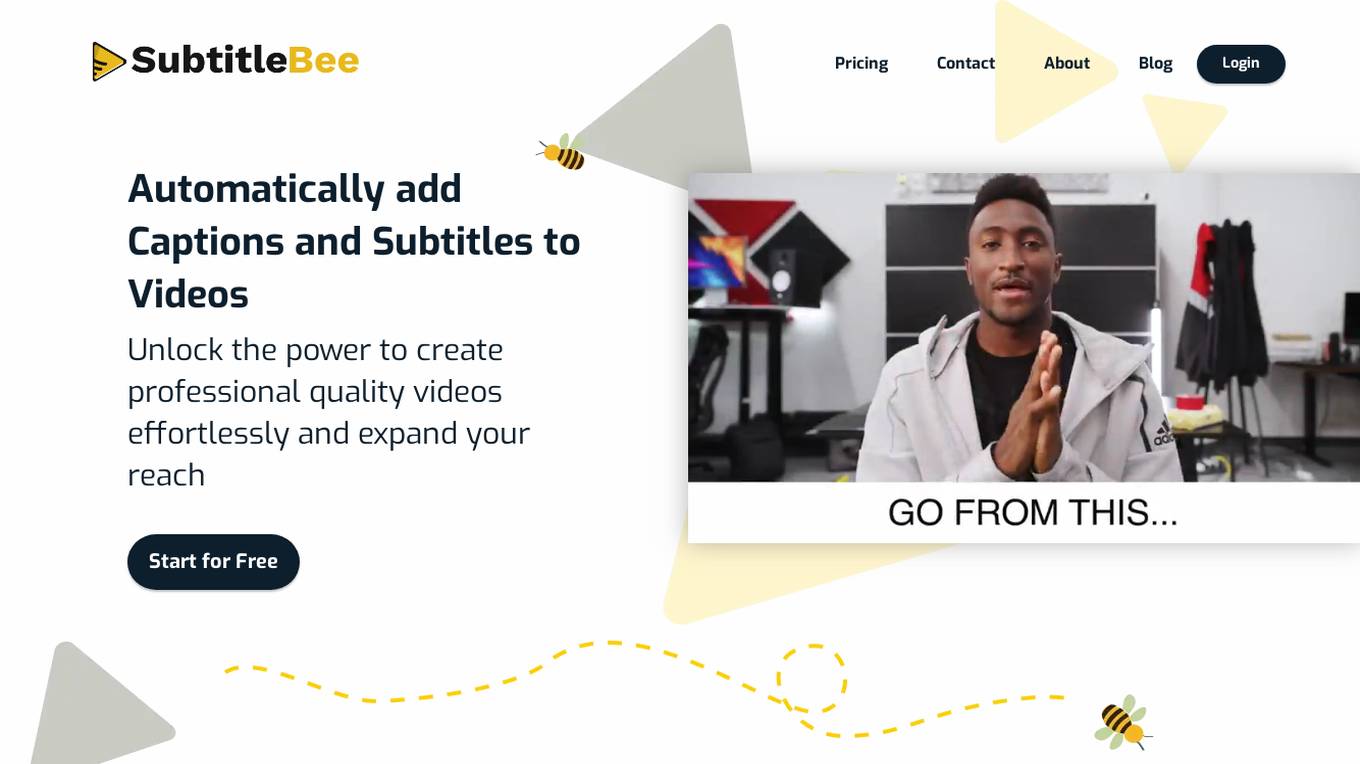
SubtitleBee
SubtitleBee is an AI-based tool that allows users to automatically add captions and subtitles to videos. It offers a user-friendly platform to create professional quality videos effortlessly, with features like customizable subtitle styles, multiple language support, and the ability to add Supertitles. SubtitleBee is privacy-focused, fast, and accessibility-friendly, making it a preferred choice for influencers, vloggers, and content creators worldwide.

www.captiongenerator.com
Free AI TikTok Caption Generator - Generates catchy TikTok captions from video scripts
MELODICA
Give me an image or idea and I will create captions designed for generate images with 'Sable Diffusion'.

Insta assistant
Does creating media social posts take up too much of your time? Are you lacking inspiration for your captions? No problem. From now on, your personal Instagram assistant takes over to help you become the influencer of tomorrow.


Kindly Quill
Your snarky, kind-hearted porcupine, expert at softening words with positively and understanding.
qapyq
qapyq is an image viewer and AI-assisted editing tool designed to help curate datasets for generative AI models. It offers features such as image viewing, editing, captioning, batch processing, and AI assistance. Users can perform tasks like cropping, scaling, editing masks, tagging, and applying sorting and filtering rules. The tool supports state-of-the-art captioning and masking models, with options for model settings, GPU acceleration, and quantization. qapyq aims to streamline the process of preparing images for training AI models by providing a user-friendly interface and advanced functionalities.

Awesome-LLMs-for-Video-Understanding
Awesome-LLMs-for-Video-Understanding is a repository dedicated to exploring Video Understanding with Large Language Models. It provides a comprehensive survey of the field, covering models, pretraining, instruction tuning, and hybrid methods. The repository also includes information on tasks, datasets, and benchmarks related to video understanding. Contributors are encouraged to add new papers, projects, and materials to enhance the repository.

MotionLLM
MotionLLM is a framework for human behavior understanding that leverages Large Language Models (LLMs) to jointly model videos and motion sequences. It provides a unified training strategy, dataset MoVid, and MoVid-Bench for evaluating human behavior comprehension. The framework excels in captioning, spatial-temporal comprehension, and reasoning abilities.
obs-localvocal
LocalVocal is a Speech AI assistant OBS Plugin that enables users to transcribe speech into text and translate it into any language locally on their machine. The plugin runs OpenAI's Whisper for real-time speech processing and prediction. It supports features like transcribing audio in real-time, displaying captions on screen, sending captions to files, syncing captions with recordings, and translating captions to major languages. Users can bring their own Whisper model, filter or replace captions, and experience partial transcriptions for streaming. The plugin is privacy-focused, requiring no GPU, cloud costs, network, or downtime.

TRACE
TRACE is a temporal grounding video model that utilizes causal event modeling to capture videos' inherent structure. It presents a task-interleaved video LLM model tailored for sequential encoding/decoding of timestamps, salient scores, and textual captions. The project includes various model checkpoints for different stages and fine-tuning on specific datasets. It provides evaluation codes for different tasks like VTG, MVBench, and VideoMME. The repository also offers annotation files and links to raw videos preparation projects. Users can train the model on different tasks and evaluate the performance based on metrics like CIDER, METEOR, SODA_c, F1, mAP, Hit@1, etc. TRACE has been enhanced with trace-retrieval and trace-uni models, showing improved performance on dense video captioning and general video understanding tasks.
AugmentOS
AugmentOS is an open source operating system for smart glasses that allows users to access various apps and AI agents. It enables developers to easily build and run apps on smart glasses, run multiple apps simultaneously, and interact with AI assistants, translation services, live captions, and more. The platform also supports language learning, ADHD tools, and live language translation. AugmentOS is designed to enhance the user experience of smart glasses by providing a seamless and proactive interaction with AI-first wearables apps.

obs-localvocal
LocalVocal is a live-streaming AI assistant plugin for OBS that allows you to transcribe audio speech into text and perform various language processing functions on the text using AI / LLMs (Large Language Models). It's privacy-first, with all data staying on your machine, and requires no GPU, cloud costs, network, or downtime.

VideoLLaMA2
VideoLLaMA 2 is a project focused on advancing spatial-temporal modeling and audio understanding in video-LLMs. It provides tools for multi-choice video QA, open-ended video QA, and video captioning. The project offers model zoo with different configurations for visual encoder and language decoder. It includes training and evaluation guides, as well as inference capabilities for video and image processing. The project also features a demo setup for running a video-based Large Language Model web demonstration.
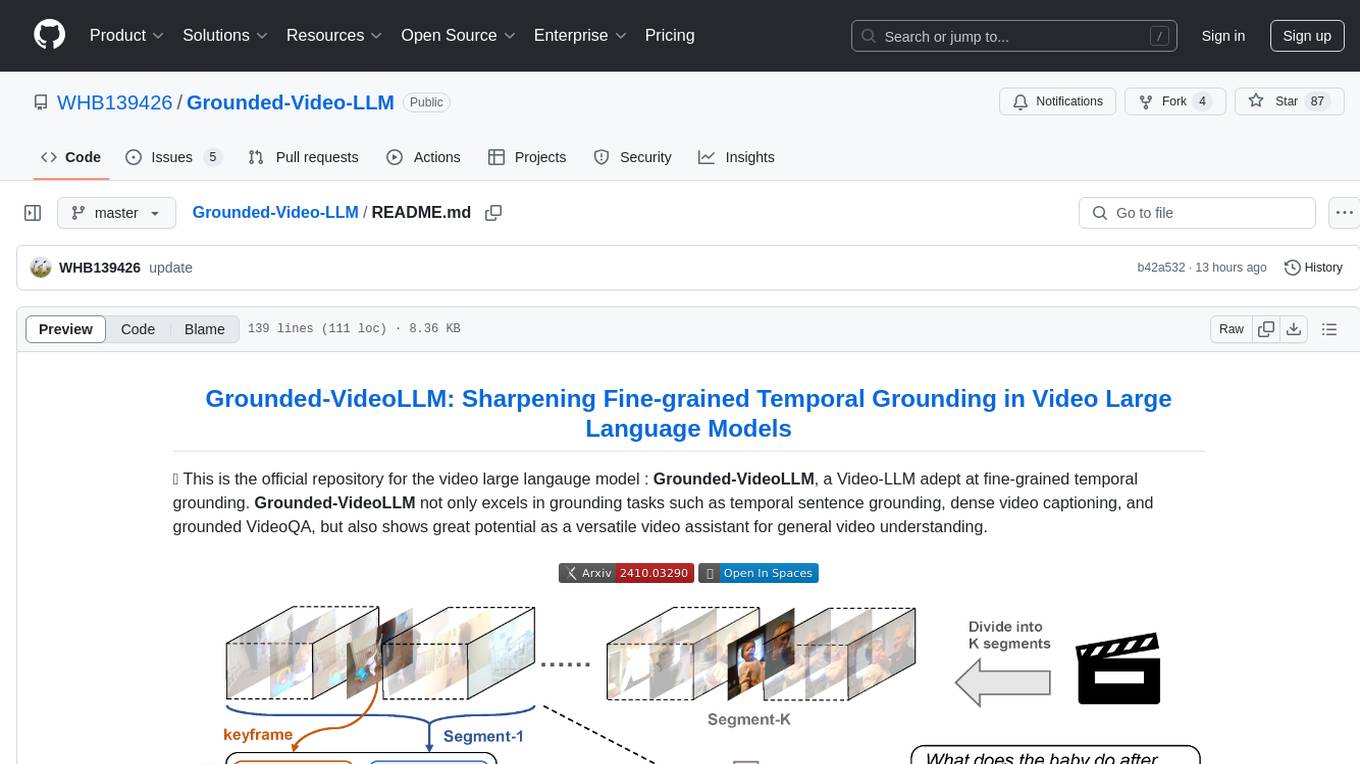
Grounded-Video-LLM
Grounded-VideoLLM is a Video Large Language Model specialized in fine-grained temporal grounding. It excels in tasks such as temporal sentence grounding, dense video captioning, and grounded VideoQA. The model incorporates an additional temporal stream, discrete temporal tokens with specific time knowledge, and a multi-stage training scheme. It shows potential as a versatile video assistant for general video understanding. The repository provides pretrained weights, inference scripts, and datasets for training. Users can run inference queries to get temporal information from videos and train the model from scratch.
awesome-sound_event_detection
The 'awesome-sound_event_detection' repository is a curated reading list focusing on sound event detection and Sound AI. It includes research papers covering various sub-areas such as learning formulation, network architecture, pooling functions, missing or noisy audio, data augmentation, representation learning, multi-task learning, few-shot learning, zero-shot learning, knowledge transfer, polyphonic sound event detection, loss functions, audio and visual tasks, audio captioning, audio retrieval, audio generation, and more. The repository provides a comprehensive collection of papers, datasets, and resources related to sound event detection and Sound AI, making it a valuable reference for researchers and practitioners in the field.
ShortGPT
ShortGPT is a powerful framework for automating content creation, simplifying video creation, footage sourcing, voiceover synthesis, and editing tasks. It offers features like automated editing framework, scripts and prompts, voiceover support in multiple languages, caption generation, asset sourcing, and persistency of editing variables. The tool is designed for youtube automation, Tiktok creativity program automation, and offers customization options for efficient and creative content creation.
AI-B-roll
AI-B-roll is a tool designed to generate broll for videos using AI. Users can automatically add AI b-roll to their videos with the provided API. The tool aims to streamline the process of creating engaging video content by leveraging artificial intelligence technology. It offers a convenient solution for video creators looking to enhance their projects with visually appealing footage.
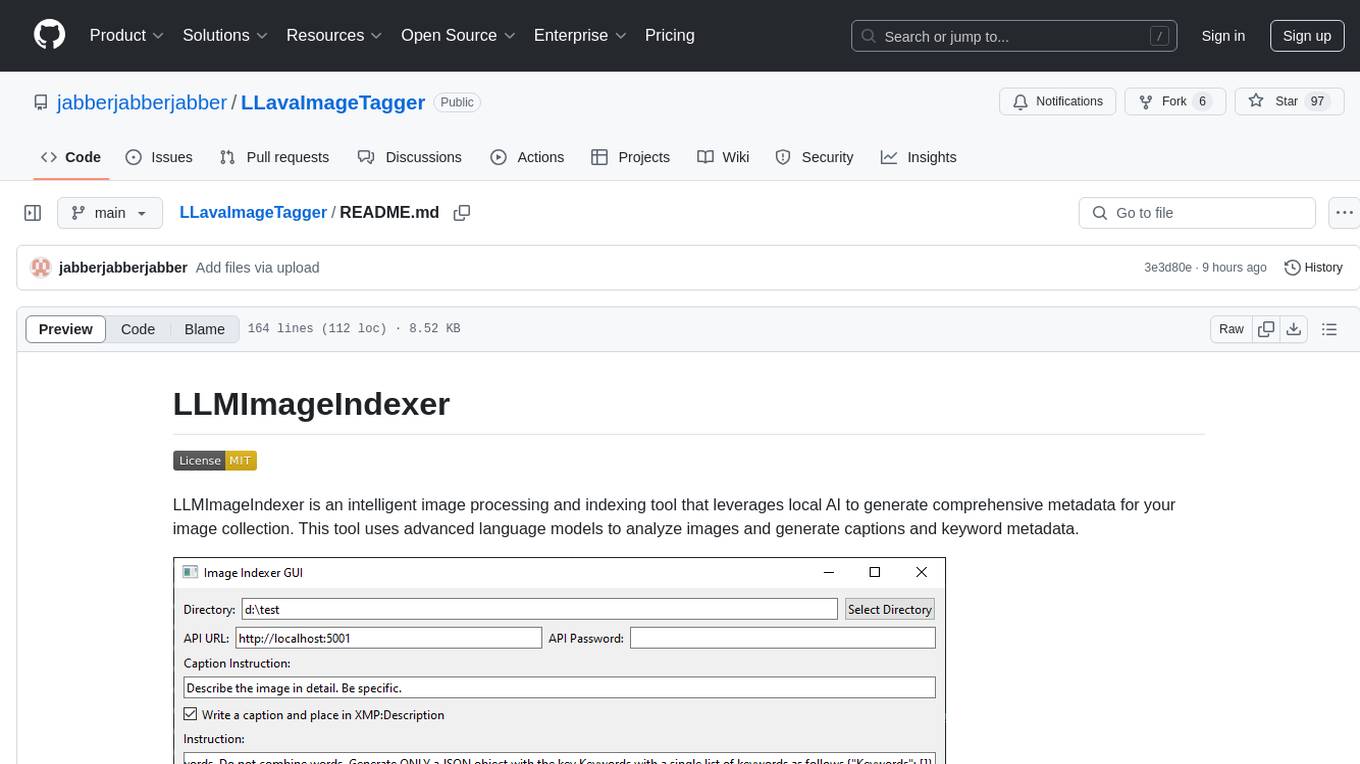
LLavaImageTagger
LLMImageIndexer is an intelligent image processing and indexing tool that leverages local AI to generate comprehensive metadata for your image collection. It uses advanced language models to analyze images and generate captions and keyword metadata. The tool offers features like intelligent image analysis, metadata enhancement, local processing, multi-format support, user-friendly GUI, GPU acceleration, cross-platform support, stop and start capability, and keyword post-processing. It operates directly on image file metadata, allowing users to manage files, add new files, and run the tool multiple times without reprocessing previously keyworded files. Installation instructions are provided for Windows, macOS, and Linux platforms, along with usage guidelines and configuration options.
podscript
Podscript is a tool designed to generate transcripts for podcasts and similar audio files using Language Model Models (LLMs) and Speech-to-Text (STT) APIs. It provides a command-line interface (CLI) for transcribing audio from various sources, including YouTube videos and audio files, using different speech-to-text services like Deepgram, Assembly AI, and Groq. Additionally, Podscript offers a web-based user interface for convenience. Users can configure keys for supported services, transcribe audio, and customize the transcription models. The tool aims to simplify the process of creating accurate transcripts for audio content.

Twitter-Insight-LLM
This project enables you to fetch liked tweets from Twitter (using Selenium), save it to JSON and Excel files, and perform initial data analysis and image captions. This is part of the initial steps for a larger personal project involving Large Language Models (LLMs).
AugmentOS
Convoscope is a suite of smart glasses and web tools designed to augment conversations by providing live proactive agents that answer questions, offer definitions, insights, and alternative viewpoints. It includes features like 'Mira' AI Assistant, Convoscope Proactive AI Agents, Language Learning app, Screen Mirror functionality, and upcoming features such as Live Captions, ADHD Glasses, and Live Language Translation. The tool supports various smart glasses models and Android 12+ phones, offering a unique experience for real-life conversations, meetings, and video calls.
summarize
The 'summarize' tool is designed to transcribe and summarize videos from various sources using AI models. It helps users efficiently summarize lengthy videos, take notes, and extract key insights by providing timestamps, original transcripts, and support for auto-generated captions. Users can utilize different AI models via Groq, OpenAI, or custom local models to generate grammatically correct video transcripts and extract wisdom from video content. The tool simplifies the process of summarizing video content, making it easier to remember and reference important information.
ImageIndexer
LLMII is a tool that uses a local AI model to label metadata and index images without relying on cloud services or remote APIs. It runs a visual language model on your computer to generate captions and keywords for images, enhancing their metadata for indexing, searching, and organization. The tool can be run multiple times on the same image files, allowing for adding new data, regenerating data, and discovering files with issues. It supports various image formats, offers a user-friendly GUI, and can utilize GPU acceleration for faster processing. LLMII requires Python 3.8 or higher and operates directly on image file metadata fields like MWG:Keyword and XMP:Identifier.
MentraOS
MentraOS is an open source operating system designed for smart glasses. It simplifies the development of smart glasses apps by handling pairing, connection, data streaming, and cross-compatibility. Developers can create apps using the TypeScript SDK quickly and easily, with access to smart glasses I/O components like displays, microphones, cameras, and speakers. The platform emphasizes cross-compatibility, speed of app development, control over device features, and easy distribution to users. The MentraOS Community is dedicated to promoting open, cross-compatible, and user-controlled personal computing through the development and support of MentraOS.
gemini-pro-bot
This Python Telegram bot utilizes Google's `gemini-pro` LLM API to generate creative text formats based on user input. It's designed to be an engaging and interactive way to explore the capabilities of large language models. Key features include generating various text formats like poems, code, scripts, and musical pieces. The bot supports real-time streaming of the generation process, allowing users to witness the text unfold. Additionally, it can respond to messages with Bard's creative output and handle image-based inputs for multimodal responses. User authentication is optional, and the bot can be easily integrated with Docker or installed via pipenv.