
transcribe-anything
Input a local file or url and this service will transcribe it using Whisper AI. Completely private and Free 🤯🤯🤯
Stars: 621
Transcribe-anything is a front-end app that utilizes Whisper AI for transcription tasks. It offers an easy installation process via pip and supports GPU acceleration for faster processing. The tool can transcribe local files or URLs from platforms like YouTube into subtitle files and raw text. It is known for its state-of-the-art translation service, ensuring privacy by keeping data local. Notably, it can generate a 'speaker.json' file when using the 'insane' backend, allowing speaker-assigned text de-chunkification. The tool also provides options for language translation and embedding subtitles into videos.
README:
![]()
![]()
![]()
![]()
Over 300+⭐'s because this program this app just works! This whisper front-end app is the only one to generate a speaker.json file which partitions the conversation by who doing the speaking.
Easiest whisper implementation to install and use. Just install with pip install transcribe-anything. GPU acceleration is automatic, using the blazingly fast insanely-fast-whisper as the backend for --device insane. This is the only tool to optionally produces a speaker.json file, representing speaker-assigned text that has been de-chunkified.
Hardware acceleration on Windows/Linux/MacOS Arm (M1, M2, +) via --device insane
Input a local file or youtube/rumble url and this tool will transcribe it using Whisper AI into subtitle files and raw text.
Uses whisper AI so this is state of the art translation service - completely free. 🤯🤯🤯
Your data stays private and is not uploaded to any service.
The new version now has state of the art speed in transcriptions, thanks to the new backend --device insane, as well as producing a speaker.json file.
pip install transcribe-anything
# slow cpu mode, works everywhere
transcribe-anything https://www.youtube.com/watch?v=dQw4w9WgXcQ
# insanely fast using the insanely-fast-whisper backend.
transcribe-anything https://www.youtube.com/watch?v=dQw4w9WgXcQ --device insane
# translate from any language to english
transcribe-anything https://www.youtube.com/watch?v=dQw4w9WgXcQ --device insane --task translateIf you pass in --device insane on a cuda platform then this tool will use this state of the art version of whisper: https://github.com/Vaibhavs10/insanely-fast-whisper, which is MUCH faster and has a pipeline for speaker identification (diarization) using the --hf_token option.
Also note, insanely-fast-whisper (--device insane) included in this project has been fixed to work with python 3.11. The upstream version is still broken on python 3.11 as of 1/22/2024.
When diarization is enabled via --hf_token (hugging face token) then the output json will contain speaker info labeled as SPEAKER_00, SPEAKER_01 etc. For licensing agreement reasons, you must get your own hugging face token if you want to enable this feature. Also there is an additional step to agree to the user policies for the pyannote.audio located here: https://huggingface.co/pyannote/segmentation-3.0. If you don't do this then you'll see runtime exceptions from pyannote when the --hf_token is used.
What's special to this app is that we also generate a speaker.json which is a de-chunkified version of the output json speaker section.
[
{
"speaker": "SPEAKER_00",
"timestamp": [
0.0,
7.44
],
"text": "for that. But welcome, Zach Vorhees. Great to have you back on. Thank you, Matt. Craving me back onto your show. Man, we got a lot to talk about.",
"reason": "beginning"
},
{
"speaker": "SPEAKER_01",
"timestamp": [
7.44,
33.52
],
"text": "Oh, we do. 2023 was the year that OpenAI released, you know, chat GPT-4, which I think most people would say has surpassed average human intelligence, at least in test taking, perhaps not in, you know, reasoning and things like that. But it was a major year for AI. I think that most people are behind the curve on this. What's your take of what just happened in the last 12 months and what it means for the future of human cognition versus machine cognition?",
"reason": "speaker-switch"
},
{
"speaker": "SPEAKER_00",
"timestamp": [
33.52,
44.08
],
"text": "Yeah. Well, you know, at the beginning of 2023, we had a pretty weak AI system, which was a chat GPT 3.5 turbo was the best that we had. And then between the beginning of last",
"reason": "speaker-switch"
}
]Note that speaker.json is only generated when using --device insane and not for --device cuda nor --device cpu.
Insane mode eats up a lot of memory and it's common to get out of memory errors while transcribing. For example a 3060 12GB nividia card produced out of memory errors are common for big content. If you experience this then pass in --batch-size 8 or smaller. Note that any arguments not recognized by transcribe-anything are passed onto the backend transcriber.
Also, please don't use distil-whisper/distil-large-v2, it produces extremely bad stuttering and it's not entirely clear why this is. I've had to switch it out of production environments because it's so bad. It's also non-deterministic so I think that somehow a fallback non-zero temperature is being used, which produces these stutterings.
cuda is the original AI model supplied by openai. It's more stable but MUCH slower. It also won't produce a speaker.json file which looks like this:
--embed. This app will optionally embed subtitles directly "burned" into an output video.
This front end app for whisper boasts the easiest install in the whisper ecosystem thanks to isolated-environment. You can simply install it with pip, like this:
pip install transcribe-anythingGPU acceleration will be automatically enabled for windows and linux. Mac users are stuck with --device cpu mode. But it's possible that --device insane and --model mps on Mac M1+ will work, but this has been completely untested.
transcribe-anything https://www.youtube.com/watch?v=dQw4w9WgXcQWill output:
Detecting language using up to the first 30 seconds. Use `--language` to specify the language
Detected language: English
[00:00.000 --> 00:27.000] We're no strangers to love, you know the rules, and so do I
[00:27.000 --> 00:31.000] I've built commitments while I'm thinking of
[00:31.000 --> 00:35.000] You wouldn't get this from any other guy
[00:35.000 --> 00:40.000] I just wanna tell you how I'm feeling
[00:40.000 --> 00:43.000] Gotta make you understand
[00:43.000 --> 00:45.000] Never gonna give you up
[00:45.000 --> 00:47.000] Never gonna let you down
[00:47.000 --> 00:51.000] Never gonna run around and desert you
[00:51.000 --> 00:53.000] Never gonna make you cry
[00:53.000 --> 00:55.000] Never gonna say goodbye
[00:55.000 --> 00:58.000] Never gonna tell a lie
[00:58.000 --> 01:00.000] And hurt you
[01:00.000 --> 01:04.000] We've known each other for so long
[01:04.000 --> 01:09.000] Your heart's been aching but you're too shy to say it
[01:09.000 --> 01:13.000] Inside we both know what's been going on
[01:13.000 --> 01:17.000] We know the game and we're gonna play it
[01:17.000 --> 01:22.000] And if you ask me how I'm feeling
[01:22.000 --> 01:25.000] Don't tell me you're too much to see
[01:25.000 --> 01:27.000] Never gonna give you up
[01:27.000 --> 01:29.000] Never gonna let you down
[01:29.000 --> 01:33.000] Never gonna run around and desert you
[01:33.000 --> 01:35.000] Never gonna make you cry
[01:35.000 --> 01:38.000] Never gonna say goodbye
[01:38.000 --> 01:40.000] Never gonna tell a lie
[01:40.000 --> 01:42.000] And hurt you
[01:42.000 --> 01:44.000] Never gonna give you up
[01:44.000 --> 01:46.000] Never gonna let you down
[01:46.000 --> 01:50.000] Never gonna run around and desert you
[01:50.000 --> 01:52.000] Never gonna make you cry
[01:52.000 --> 01:54.000] Never gonna say goodbye
[01:54.000 --> 01:57.000] Never gonna tell a lie
[01:57.000 --> 01:59.000] And hurt you
[02:08.000 --> 02:10.000] Never gonna give
[02:12.000 --> 02:14.000] Never gonna give
[02:16.000 --> 02:19.000] We've known each other for so long
[02:19.000 --> 02:24.000] Your heart's been aching but you're too shy to say it
[02:24.000 --> 02:28.000] Inside we both know what's been going on
[02:28.000 --> 02:32.000] We know the game and we're gonna play it
[02:32.000 --> 02:37.000] I just wanna tell you how I'm feeling
[02:37.000 --> 02:40.000] Gotta make you understand
[02:40.000 --> 02:42.000] Never gonna give you up
[02:42.000 --> 02:44.000] Never gonna let you down
[02:44.000 --> 02:48.000] Never gonna run around and desert you
[02:48.000 --> 02:50.000] Never gonna make you cry
[02:50.000 --> 02:53.000] Never gonna say goodbye
[02:53.000 --> 02:55.000] Never gonna tell a lie
[02:55.000 --> 02:57.000] And hurt you
[02:57.000 --> 02:59.000] Never gonna give you up
[02:59.000 --> 03:01.000] Never gonna let you down
[03:01.000 --> 03:05.000] Never gonna run around and desert you
[03:05.000 --> 03:08.000] Never gonna make you cry
[03:08.000 --> 03:10.000] Never gonna say goodbye
[03:10.000 --> 03:12.000] Never gonna tell a lie
[03:12.000 --> 03:14.000] And hurt you
[03:14.000 --> 03:16.000] Never gonna give you up
[03:16.000 --> 03:23.000] If you want, never gonna let you down Never gonna run around and desert you
[03:23.000 --> 03:28.000] Never gonna make you hide Never gonna say goodbye
[03:28.000 --> 03:42.000] Never gonna tell you I ain't ready
from transcribe_anything.api import transcribe
transcribe(
url_or_file="https://www.youtube.com/watch?v=dQw4w9WgXcQ",
output_dir="output_dir",
)Works for Ubuntu/MacOS/Win32(in git-bash) This will create a virtual environment
> cd transcribe_anything
> ./install.sh
# Enter the environment:
> source activate.shThe environment is now active and the next step will only install to the local python. If the terminal
is closed then to get back into the environment cd transcribe_anything and execute source activate.sh
-
pip install transcribe-anything- The command
transcribe_anythingwill magically become available.
- The command
transcribe_anything <YOUTUBE_URL>
- OpenAI whisper
- insanely-fast-whisper
- yt-dlp: https://github.com/yt-dlp/yt-dlp
- static-ffmpeg
- Every commit is tested for standard linters and a batch of unit tests.
- 2.7.39: Fix
--hf-tokenusage for insanely fast whisper backend. - 2.7.37: Fixed breakage due to numpy 2.0 being released.
- 2.7.36: Fixed some ffmpeg dependencies.
- 2.7.35: All
ffmpegcommands are nowstatic_ffmpegcommands. Fixes issue. - 2.7.34: Various fixes.
- 2.7.33: Fixes linux
- 2.7.32: Fixes mac m1 and m2.
- 2.7.31: Adds a warning if using python 3.12, which isn't supported yet in the backend.
- 2.7.30: adds --query-gpu-json-path
- 2.7.29: Made to json -> srt more robust for
--device insane, bad entries will be skipped but warn. - 2.7.28: Fixes bad title fetching with weird characters.
- 2.7.27:
pytorch-audioupgrades broke this package. Upgrade to latest version to resolve. - 2.7.26: Add model option
distil-whisper/distil-large-v2 - 2.7.25: Windows (Linux/MacOS) bug with
--device insaneand python 3.11 installing wronginsanely-fast-whisperversion. - 2.7.22: Fixes
transcribe-anythingon Linux. - 2.7.21: Tested that Mac Arm can run
--device insane. Added tests to ensure this. - 2.7.20: Fixes wrong type being returned when speaker.json happens to be empty.
- 2.7.19: speaker.json is now in plain json format instead of json5 format
- 2.7.18: Fixes tests
- 2.7.17: Fixes speaker.json nesting.
- 2.7.16: Adds
--save_hf_token - 2.7.15: Fixes 2.7.14 breakage.
- 2.7.14: (Broken) Now generates
speaker.jsonwhen diarization is enabled. - 2.7.13: Default diarization model is now pyannote/speaker-diarization-3.1
- 2.7.12: Adds srt_swap for line breaks and improved isolated_environment usage.
- 2.7.11:
--device insanenow generates a *.vtt translation file - 2.7.10: Better support for namespaced models. Trims text output in output json. Output json is now formatted with indents. SRT file is now printed out for
--device insane - 2.7.9: All SRT translation errors fixed for
--device insane. All tests pass. - 2.7.8: During error of
--device insane, write out the error.json file into the destination. - 2.7.7: Better error messages during failure.
- 2.7.6: Improved generation of out.txt, removes linebreaks.
- 2.7.5:
--device insanenow generates better conforming srt files. - 2.7.3: Various fixes for the
insanemode backend. - 2.7.0: Introduces an
insanely-fast-whisper, enable by using--device insane - 2.6.0: GPU acceleration now happens automatically on Windows thanks to
isolated-environment. This will also prevent interference with different versions of torch for other AI tools. - 2.5.0:
--model largenow aliases to--model large-v3. Use--model large-legacyto use original large model. - 2.4.0: pytorch updated to 2.1.2, gpu install script updated to same + cuda version is now 121.
- 2.3.9: Fallback to
cpudevice ifgpudevice is not compatible. - 2.3.8: Fix --models arg which
- 2.3.7: Critical fix: fixes dependency breakage with open-ai. Fixes windows use of embedded tool.
- 2.3.6: Fixes typo in readme for installation instructions.
- 2.3.5: Now has
--embedto burn the subtitles into the video itself. Only works on local mp4 files at the moment. - 2.3.4: Removed
out.mp3and instead use a temporary wav file, as that is faster to process. --no-keep-audio has now been removed. - 2.3.3: Fix case where there spaces in name (happens on windows)
- 2.3.2: Fix windows transcoding error
- 2.3.1: static-ffmpeg >= 2.5 now specified
- 2.3.0: Now uses the official version of whisper ai
- 2.2.1: "test_" is now prepended to all the different output folder names.
- 2.2.0: Now explictly setting a language will put the file in a folder with that language name, allowing multi language passes without overwriting.
- 2.1.2: yt-dlp pinned to new minimum version. Fixes downloading issues from old lib. Adds audio normalization by default.
- 2.1.1: Updates keywords for easier pypi finding.
- 2.1.0: Unknown args are now assumed to be for whisper and passed to it as-is. Fixes https://github.com/zackees/transcribe-anything/issues/3
- 2.0.13: Now works with python 3.9
- 2.0.12: Adds --device to argument parameters. This will default to CUDA if available, else CPU.
- 2.0.11: Automatically deletes files in the out directory if they already exist.
- 2.0.10: fixes local file issue https://github.com/zackees/transcribe-anything/issues/2
- 2.0.9: fixes sanitization of path names for some youtube videos
- 2.0.8: fix
--output_dirnot being respected. - 2.0.7:
install_cuda.sh->install_cuda.py - 2.0.6: Fixes twitter video fetching. --keep-audio -> --no-keep-audio
- 2.0.5: Fix bad filename on trailing urls ending with /, adds --keep-audio
- 2.0.3: GPU support is now added. Run the
install_cuda.shscript to enable. - 2.0.2: Minor cleanup of file names (no more out.mp3.txt, it's now out.txt)
- 2.0.1: Fixes missing dependencies and adds whisper option.
- 2.0.0: New! Now a front end for Whisper ai!
- Insanely Fast whisper for GPU
- Fast Whisper for CPU
- A better whisper CLI that supports more options but has a manual install.
- Subtitles translator:
- Forum post on how to avoid stuttering
- More stable transcriptions:
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for transcribe-anything
Similar Open Source Tools
transcribe-anything
Transcribe-anything is a front-end app that utilizes Whisper AI for transcription tasks. It offers an easy installation process via pip and supports GPU acceleration for faster processing. The tool can transcribe local files or URLs from platforms like YouTube into subtitle files and raw text. It is known for its state-of-the-art translation service, ensuring privacy by keeping data local. Notably, it can generate a 'speaker.json' file when using the 'insane' backend, allowing speaker-assigned text de-chunkification. The tool also provides options for language translation and embedding subtitles into videos.

openai-cf-workers-ai
OpenAI for Workers AI is a simple, quick, and dirty implementation of OpenAI's API on Cloudflare's new Workers AI platform. It allows developers to use the OpenAI SDKs with the new LLMs without having to rewrite all of their code. The API currently supports completions, chat completions, audio transcription, embeddings, audio translation, and image generation. It is not production ready but will be semi-regularly updated with new features as they roll out to Workers AI.
voice-chat-ai
Voice Chat AI is a project that allows users to interact with different AI characters using speech. Users can choose from various characters with unique personalities and voices, and have conversations or role play with them. The project supports OpenAI, xAI, or Ollama language models for chat, and provides text-to-speech synthesis using XTTS, OpenAI TTS, or ElevenLabs. Users can seamlessly integrate visual context into conversations by having the AI analyze their screen. The project offers easy configuration through environment variables and can be run via WebUI or Terminal. It also includes a huge selection of built-in characters for engaging conversations.
99
The AI client 99 is designed for Neovim users to streamline requests to AI and limit them to restricted areas. It supports visual, search, and debug functionalities. Users must have a supported AI CLI installed such as opencode, claude, or cursor-agent. The tool allows for configuration of completions, referencing rules and files to add context to requests. 99 supports multiple AI CLI backends and providers. Users can report bugs by providing full running debug logs and are advised not to request features directly. Known usability issues include long function definition problems, duplication of comment definitions in lua and jsdoc, visual selection sending the whole file, occasional issues with auto-complete, and potential errors with 'export function' prompts.
openorch
OpenOrch is a daemon that transforms servers into a powerful development environment, running AI models, containers, and microservices. It serves as a blend of Kubernetes and a language-agnostic backend framework for building applications on fixed-resource setups. Users can deploy AI models and build microservices, managing applications while retaining control over infrastructure and data.
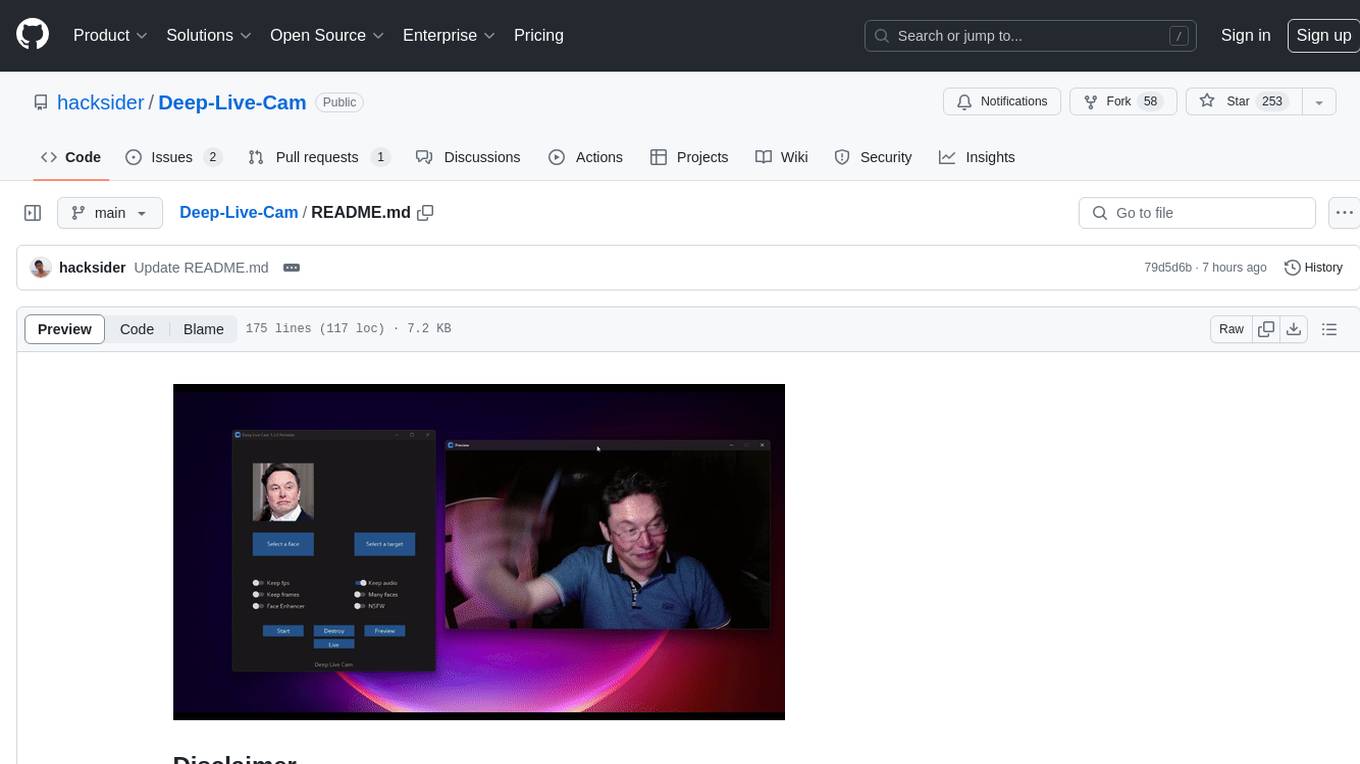
Deep-Live-Cam
Deep-Live-Cam is a software tool designed to assist artists in tasks such as animating custom characters or using characters as models for clothing. The tool includes built-in checks to prevent unethical applications, such as working on inappropriate media. Users are expected to use the tool responsibly and adhere to local laws, especially when using real faces for deepfake content. The tool supports both CPU and GPU acceleration for faster processing and provides a user-friendly GUI for swapping faces in images or videos.

1backend
1Backend is a flexible and scalable platform designed for running AI models on private servers and handling high-concurrency workloads. It provides a ChatGPT-like interface for users and a network-accessible API for machines, serving as a general-purpose backend framework. The platform offers on-premise ChatGPT alternatives, a microservices-first web framework, out-of-the-box services like file uploads and user management, infrastructure simplification acting as a container orchestrator, reverse proxy, multi-database support with its own ORM, and AI integration with platforms like LlamaCpp and StableDiffusion.

smartcat
Smartcat is a CLI interface that brings language models into the Unix ecosystem, allowing power users to leverage the capabilities of LLMs in their daily workflows. It features a minimalist design, seamless integration with terminal and editor workflows, and customizable prompts for specific tasks. Smartcat currently supports OpenAI, Mistral AI, and Anthropic APIs, providing access to a range of language models. With its ability to manipulate file and text streams, integrate with editors, and offer configurable settings, Smartcat empowers users to automate tasks, enhance code quality, and explore creative possibilities.
Discord-AI-Selfbot
Discord-AI-Selfbot is a Python-based Discord selfbot that uses the `discord.py-self` library to automatically respond to messages mentioning its trigger word using Groq API's Llama-3 model. It functions as a normal Discord bot on a real Discord account, enabling interactions in DMs, servers, and group chats without needing to invite a bot. The selfbot comes with features like custom AI instructions, free LLM model usage, mention and reply recognition, message handling, channel-specific responses, and a psychoanalysis command to analyze user messages for insights on personality.
UltraSinger
UltraSinger is a tool under development that automatically creates UltraStar.txt, midi, and notes from music. It pitches UltraStar files, adds text and tapping, creates separate UltraStar karaoke files, re-pitches current UltraStar files, and calculates in-game score. It uses multiple AI models to extract text from voice and determine pitch. Users should mention UltraSinger in UltraStar.txt files and only use it on Creative Commons licensed songs.
node_characterai
Node.js client for the unofficial Character AI API, an awesome website which brings characters to life with AI! This repository is inspired by RichardDorian's unofficial node API. Though, I found it hard to use and it was not really stable and archived. So I remade it in javascript. This project is not affiliated with Character AI in any way! It is a community project. The purpose of this project is to bring and build projects powered by Character AI. If you like this project, please check their website.
aiorun
aiorun is a Python package that provides a `run()` function as the starting point of your `asyncio`-based application. The `run()` function handles everything needed during the shutdown sequence of the application, such as creating a `Task` for the given coroutine, running the event loop, adding signal handlers for `SIGINT` and `SIGTERM`, cancelling tasks, waiting for the executor to complete shutdown, and closing the loop. It automates standard actions for asyncio apps, eliminating the need to write boilerplate code. The package also offers error handling options and tools for specific scenarios like TCP server startup and smart shield for shutdown.

kwaak
Kwaak is a tool that allows users to run a team of autonomous AI agents locally from their own machine. It enables users to write code, improve test coverage, update documentation, and enhance code quality while focusing on building innovative projects. Kwaak is designed to run multiple agents in parallel, interact with codebases, answer questions about code, find examples, write and execute code, create pull requests, and more. It is free and open-source, allowing users to bring their own API keys or models via Ollama. Kwaak is part of the bosun.ai project, aiming to be a platform for autonomous code improvement.

HuggingFaceGuidedTourForMac
HuggingFaceGuidedTourForMac is a guided tour on how to install optimized pytorch and optionally Apple's new MLX, JAX, and TensorFlow on Apple Silicon Macs. The repository provides steps to install homebrew, pytorch with MPS support, MLX, JAX, TensorFlow, and Jupyter lab. It also includes instructions on running large language models using HuggingFace transformers. The repository aims to help users set up their Macs for deep learning experiments with optimized performance.
robocorp
Robocorp is a platform that allows users to create, deploy, and operate Python automations and AI actions. It provides an easy way to extend the capabilities of AI agents, assistants, and copilots with custom actions written in Python. Users can create and deploy tools, skills, loaders, and plugins that securely connect any AI Assistant platform to their data and applications. The Robocorp Action Server makes Python scripts compatible with ChatGPT and LangChain by automatically creating and exposing an API based on function declaration, type hints, and docstrings. It simplifies the process of developing and deploying AI actions, enabling users to interact with AI frameworks effortlessly.
tiny-ai-client
Tiny AI Client is a lightweight tool designed for easy usage and switching of Language Model Models (LLMs) with support for vision and tool usage. It aims to provide a simple and intuitive interface for interacting with various LLMs, allowing users to easily set, change models, send messages, use tools, and handle vision tasks. The core logic of the tool is kept minimal and easy to understand, with separate modules for vision and tool usage utilities. Users can interact with the tool through simple Python scripts, passing model names, messages, tools, and images as required.
For similar tasks
transcribe-anything
Transcribe-anything is a front-end app that utilizes Whisper AI for transcription tasks. It offers an easy installation process via pip and supports GPU acceleration for faster processing. The tool can transcribe local files or URLs from platforms like YouTube into subtitle files and raw text. It is known for its state-of-the-art translation service, ensuring privacy by keeping data local. Notably, it can generate a 'speaker.json' file when using the 'insane' backend, allowing speaker-assigned text de-chunkification. The tool also provides options for language translation and embedding subtitles into videos.
AudioNotes
AudioNotes is a system built on FunASR and Qwen2 that can quickly extract content from audio and video, and organize it using large models into structured markdown notes for easy reading. Users can interact with the audio and video content, install Ollama, pull models, and deploy services using Docker or locally with a PostgreSQL database. The system provides a seamless way to convert audio and video into structured notes for efficient consumption.
StoryToolkitAI
StoryToolkitAI is a film editing tool that utilizes AI to transcribe, index scenes, search through footage, and create stories. It offers features like full video indexing, automatic transcriptions and translations, compatibility with OpenAI GPT and ollama, story editor for screenplay writing, speaker detection, project file management, and more. It integrates with DaVinci Resolve Studio 18 and offers planned features like automatic topic classification and integration with other AI tools. The tool is developed by Octavian Mot and is actively being updated with new features based on user needs and feedback.
decipher
Decipher is a tool that utilizes AI-generated transcription subtitles to automatically add subtitles to videos. It eliminates the need for manual transcription, making videos more accessible. The tool uses OpenAI's Whisper, a State-of-the-Art speech recognition system trained on a large dataset for improved robustness to accents, background noise, and technical language.

you2txt
You2Txt is a tool developed for the Vercel + Nvidia 2-hour hackathon that converts any YouTube video into a transcribed .txt file. The project won first place in the hackathon and is hosted at you2txt.com. Due to rate limiting issues with YouTube requests, it is recommended to run the tool locally. The project was created using Next.js, Tailwind, v0, and Claude, and can be built and accessed locally for development purposes.
MemoAI
MemoAI is an AI-powered tool that provides podcast, video-to-text, and subtitling capabilities for immediate use. It supports audio and video transcription, model selection for paragraph effects, local subtitles translation, text translation using Google, Microsoft, Volcano Translation, DeepL, and AI Translation, speech synthesis in multiple languages, and exporting text and subtitles in common formats. MemoAI is designed to simplify the process of transcribing, translating, and creating subtitles for various media content.

glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.