
uwazi
Uwazi is a web-based, open-source solution for building and sharing document collections
Stars: 299
Uwazi is a flexible database application designed for capturing and organizing collections of information, with a focus on document management. It is developed and supported by HURIDOCS, benefiting human rights organizations globally. The tool requires NodeJs, ElasticSearch, ICU Analysis Plugin, MongoDB, Yarn, and pdftotext for installation. It offers production and development installation guides, including Docker setup. Uwazi supports hot reloading, unit and integration testing with JEST, and end-to-end testing with Nightmare or Puppeteer. The system requirements include RAM, CPU, and disk space recommendations for on-premises and development usage.
README:

![]()
Uwazi is a flexible database application to capture and organise collections of information with a particular focus on document management. HURIDOCS started Uwazi and is supporting dozens of human rights organisations globally to use the tool.
Read the user guide
Before anything else you will need to install the application dependencies:
- NodeJs 20.19.6 For ease of update, use nvm.
-
ElasticSearch 8.18.0 Please note that ElasticSearch requires Java. Follow the instructions to install the package manually, you also probably need to disable ml module in the ElasticSearch config file:
xpack.ml.enabled: false - ICU Analysis Plugin (recommended) Adds support for number sorting in texts and solves other language sorting nuances. This option is activated by setting the env var USE_ELASTIC_ICU=true before running the server (defaults to false/unset).
- MongoDB 7.0.24 The MongoDB installation needs to be configured as a Replica Set. It can be a single-node replica set, but Replica Set must be initialized. If you have a previous version installed, please follow the instructions on how to upgrade here.
- mongosh The new mongosh dependency needs to be added.
- Yarn
- pdftotext (Poppler) tested to work on version 22.12 but it's recommended to use the latest available for your platform. Make sure to install libjpeg-dev if you build from source.
If you want to use the latest development code:
$ git clone https://github.com/huridocs/uwazi.git
$ cd uwazi
$ yarn install
$ yarn blank-state
There may be an issue with pngquant not running correctly. If you encounter this issue, you are probably missing the library libpng-dev. Please run:
$ sudo rm -rf node_modules
$ sudo apt-get install libpng-dev
$ yarn install
Infrastructure dependencies (ElasticSearch, ICU Analysis Plugin, MongoDB, Redis and Minio (S3 storage) can be installed and run via Docker Compose. ElasticSearch container will claim 2Gb of memory so be sure your Docker Engine is alloted at least 3Gb of memory (for Mac and Windows users).
$ ./run start$ yarn hot
This will launch a webpack server and nodemon app server for hot reloading any changes you make.
$ yarn webpack-server
This will launch a webpack server. You can also pass --analyzeto get detailed info on the webpack build.
We test using the JEST framework (built on top of Jasmine). To run the unit and integration tests, execute
$ yarn test
This will run the entire test suite, both on server and client apps.
Some suites need MongoDB configured in Replica Set mode to run properly. The provided Docker Compose file runs MongoDB in Replica Set mode and initializes the cluster automatically, if you are using your own mongo installation Refer to MongoDB's documentation for more information.
There are also Cypress components tests. It's recommended that Cypress tests are run with Chrome or Chrome based browsers.
You can run individual tests with the Cypress UI:
$ yarn cypress
or you can run tests in headless mode:
$ yarn cy-components --browser chrome
Running end-to-end tests requires a running Uwazi app. For End-to-End testing, we have a full set of fixtures that test the overall functionality. It's not advised to run these tests on production environments, since an incorrectly configured run can have unwanted effects on the production database.
Note that if you already have an instance running, this will likely throw an error of ports already being used. Only one instance of Uwazi may be run in the same port at the same time.
The Uwazi APP needs to run on a specific database and with a specific ElasticSearch index. This is configured via environment variables when starting the application.
Start UWazi:
$ DATABASE_NAME=uwazi_e2e INDEX_NAME=uwazi_e2e yarn hot
On a different console tab, run:
$ yarn e2e-puppeteer
This will trigger a run of all the Puppeteer tests.
You can run test individually:
yarn e2e-puppeteer-all path/to/test.test.ts
Start Uwazi:
$ DATABASE_NAME=uwazi_e2e INDEX_NAME=uwazi_e2e yarn hot
On a different console tab, run:
$ yarn cypress
This will open the Cypress interface where you can select the tests to run. It's recommended that Cypress tests are run with Chrome or Chrome based browsers.
You can run tests in headless mode, and run individual suites via:
$ yarn cy-e2e --browser chrome --spec path/to/test.cy.ts
Cypress tests that use our Information Extraction features need to run Uwazi together with a dummy service that mimics the external services needed for the features.
To run these tests you also need to add the following environment variables when running Uwazi:
$ EXTERNAL_SERVICES=true FEATURE_FLAG_PARAGRAPH_EXTRACTION=true PARAGRAPH_EXTRACTION_URL=http://localhost:5051 DATABASE_NAME=uwazi_e2e INDEX_NAME=uwazi_e2e yarn hot
The application's default login is admin / change this password now
Note the subtle nudge ;)
- For big files with a small database footprint (such as video, audio and images) you'll need more HD space than CPU or RAM
- For text documents you should consider some decent RAM as ElasticSearch is pretty greedy on memory for full text search
The bare minimum you need to be able to run Uwazi on-prem without bottlenecks is:
- 4 GB of RAM (reserve 2 for Elastic and 2 for everything else)
- 2 CPU cores
- 20 GB of disk space
For development:
- 8GB of RAM (depending on whether the services are running)
- 4 CPU cores
- 20 GB of disk space
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for uwazi
Similar Open Source Tools
uwazi
Uwazi is a flexible database application designed for capturing and organizing collections of information, with a focus on document management. It is developed and supported by HURIDOCS, benefiting human rights organizations globally. The tool requires NodeJs, ElasticSearch, ICU Analysis Plugin, MongoDB, Yarn, and pdftotext for installation. It offers production and development installation guides, including Docker setup. Uwazi supports hot reloading, unit and integration testing with JEST, and end-to-end testing with Nightmare or Puppeteer. The system requirements include RAM, CPU, and disk space recommendations for on-premises and development usage.

geti-sdk
The Intel® Geti™ SDK is a python package that enables teams to rapidly develop AI models by easing the complexities of model development and enhancing collaboration between teams. It provides tools to interact with an Intel® Geti™ server via the REST API, allowing for project creation, downloading, uploading, deploying for local inference with OpenVINO, setting project and model configuration, launching and monitoring training jobs, and media upload and prediction. The SDK also includes tutorial-style Jupyter notebooks demonstrating its usage.

geti-sdk
The Intel® Geti™ SDK is a python package that enables teams to rapidly develop AI models by easing the complexities of model development and fostering collaboration. It provides tools to interact with an Intel® Geti™ server via the REST API, allowing for project creation, downloading, uploading, deploying for local inference with OpenVINO, configuration management, training job monitoring, media upload, and prediction. The repository also includes tutorial-style Jupyter notebooks demonstrating SDK usage.
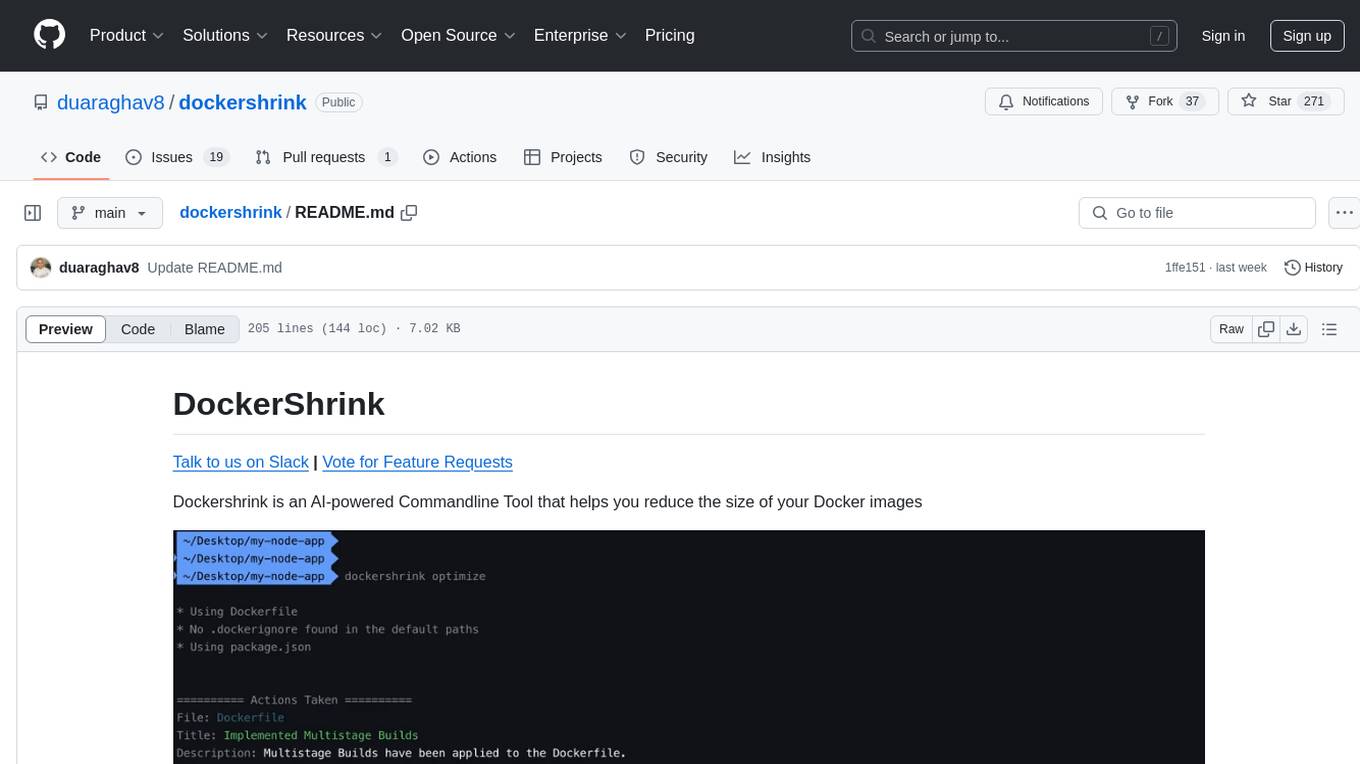
dockershrink
Dockershrink is an AI-powered Commandline Tool designed to help reduce the size of Docker images. It combines traditional Rule-based analysis with Generative AI techniques to optimize Image configurations. The tool supports NodeJS applications and aims to save costs on storage, data transfer, and build times while increasing developer productivity. By automatically applying advanced optimization techniques, Dockershrink simplifies the process for engineers and organizations, resulting in significant savings and efficiency improvements.

LARS
LARS is an application that enables users to run Large Language Models (LLMs) locally on their devices, upload their own documents, and engage in conversations where the LLM grounds its responses with the uploaded content. The application focuses on Retrieval Augmented Generation (RAG) to increase accuracy and reduce AI-generated inaccuracies. LARS provides advanced citations, supports various file formats, allows follow-up questions, provides full chat history, and offers customization options for LLM settings. Users can force enable or disable RAG, change system prompts, and tweak advanced LLM settings. The application also supports GPU-accelerated inferencing, multiple embedding models, and text extraction methods. LARS is open-source and aims to be the ultimate RAG-centric LLM application.

cognita
Cognita is an open-source framework to organize your RAG codebase along with a frontend to play around with different RAG customizations. It provides a simple way to organize your codebase so that it becomes easy to test it locally while also being able to deploy it in a production ready environment. The key issues that arise while productionizing RAG system from a Jupyter Notebook are: 1. **Chunking and Embedding Job** : The chunking and embedding code usually needs to be abstracted out and deployed as a job. Sometimes the job will need to run on a schedule or be trigerred via an event to keep the data updated. 2. **Query Service** : The code that generates the answer from the query needs to be wrapped up in a api server like FastAPI and should be deployed as a service. This service should be able to handle multiple queries at the same time and also autoscale with higher traffic. 3. **LLM / Embedding Model Deployment** : Often times, if we are using open-source models, we load the model in the Jupyter notebook. This will need to be hosted as a separate service in production and model will need to be called as an API. 4. **Vector DB deployment** : Most testing happens on vector DBs in memory or on disk. However, in production, the DBs need to be deployed in a more scalable and reliable way. Cognita makes it really easy to customize and experiment everything about a RAG system and still be able to deploy it in a good way. It also ships with a UI that makes it easier to try out different RAG configurations and see the results in real time. You can use it locally or with/without using any Truefoundry components. However, using Truefoundry components makes it easier to test different models and deploy the system in a scalable way. Cognita allows you to host multiple RAG systems using one app. ### Advantages of using Cognita are: 1. A central reusable repository of parsers, loaders, embedders and retrievers. 2. Ability for non-technical users to play with UI - Upload documents and perform QnA using modules built by the development team. 3. Fully API driven - which allows integration with other systems. > If you use Cognita with Truefoundry AI Gateway, you can get logging, metrics and feedback mechanism for your user queries. ### Features: 1. Support for multiple document retrievers that use `Similarity Search`, `Query Decompostion`, `Document Reranking`, etc 2. Support for SOTA OpenSource embeddings and reranking from `mixedbread-ai` 3. Support for using LLMs using `Ollama` 4. Support for incremental indexing that ingests entire documents in batches (reduces compute burden), keeps track of already indexed documents and prevents re-indexing of those docs.

crawlee-python
Crawlee-python is a web scraping and browser automation library that covers crawling and scraping end-to-end, helping users build reliable scrapers fast. It allows users to crawl the web for links, scrape data, and store it in machine-readable formats without worrying about technical details. With rich configuration options, users can customize almost any aspect of Crawlee to suit their project's needs.
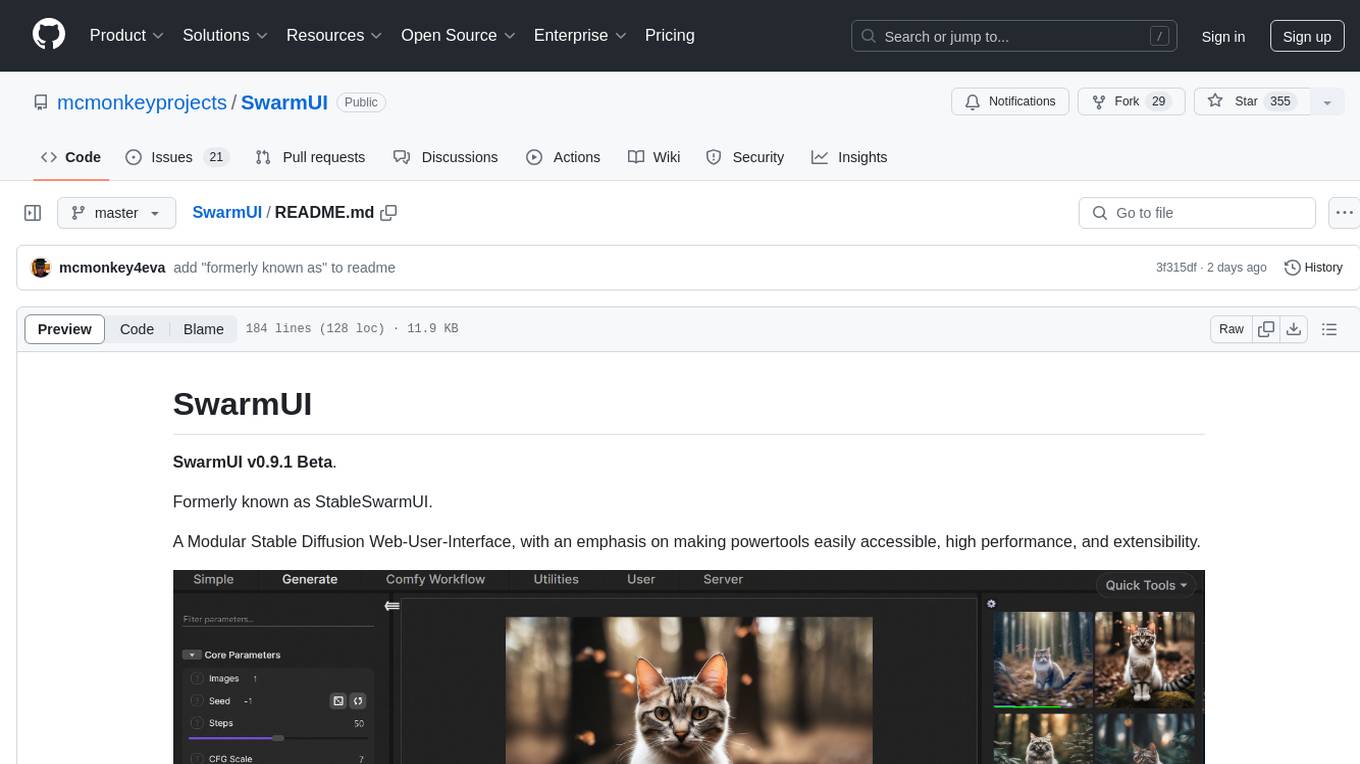
SwarmUI
SwarmUI is a modular stable diffusion web-user-interface designed to make powertools easily accessible, high performance, and extensible. It is in Beta status, offering a primary Generate tab for beginners and a Comfy Workflow tab for advanced users. The tool aims to become a full-featured one-stop-shop for all things Stable Diffusion, with plans for better mobile browser support, detailed 'Current Model' display, dynamic tab shifting, LLM-assisted prompting, and convenient direct distribution as an Electron app.
open-source-slack-ai
This repository provides a ready-to-run basic Slack AI solution that allows users to summarize threads and channels using OpenAI. Users can generate thread summaries, channel overviews, channel summaries since a specific time, and full channel summaries. The tool is powered by GPT-3.5-Turbo and an ensemble of NLP models. It requires Python 3.8 or higher, an OpenAI API key, Slack App with associated API tokens, Poetry package manager, and ngrok for local development. Users can customize channel and thread summaries, run tests with coverage using pytest, and contribute to the project for future enhancements.
kubeai
KubeAI is a highly scalable AI platform that runs on Kubernetes, serving as a drop-in replacement for OpenAI with API compatibility. It can operate OSS model servers like vLLM and Ollama, with zero dependencies and additional OSS addons included. Users can configure models via Kubernetes Custom Resources and interact with models through a chat UI. KubeAI supports serving various models like Llama v3.1, Gemma2, and Qwen2, and has plans for model caching, LoRA finetuning, and image generation.
SeaGOAT
SeaGOAT is a local search tool that leverages vector embeddings to enable you to search your codebase semantically. It is designed to work on Linux, macOS, and Windows and can process files in various formats, including text, Markdown, Python, C, C++, TypeScript, JavaScript, HTML, Go, Java, PHP, and Ruby. SeaGOAT uses a vector database called ChromaDB and a local vector embedding engine to provide fast and accurate search results. It also supports regular expression/keyword-based matches. SeaGOAT is open-source and licensed under an open-source license, and users are welcome to examine the source code, raise concerns, or create pull requests to fix problems.

aici
The Artificial Intelligence Controller Interface (AICI) lets you build Controllers that constrain and direct output of a Large Language Model (LLM) in real time. Controllers are flexible programs capable of implementing constrained decoding, dynamic editing of prompts and generated text, and coordinating execution across multiple, parallel generations. Controllers incorporate custom logic during the token-by-token decoding and maintain state during an LLM request. This allows diverse Controller strategies, from programmatic or query-based decoding to multi-agent conversations to execute efficiently in tight integration with the LLM itself.

bedrock-claude-chatbot
Bedrock Claude ChatBot is a Streamlit application that provides a conversational interface for users to interact with various Large Language Models (LLMs) on Amazon Bedrock. Users can ask questions, upload documents, and receive responses from the AI assistant. The app features conversational UI, document upload, caching, chat history storage, session management, model selection, cost tracking, logging, and advanced data analytics tool integration. It can be customized using a config file and is extensible for implementing specialized tools using Docker containers and AWS Lambda. The app requires access to Amazon Bedrock Anthropic Claude Model, S3 bucket, Amazon DynamoDB, Amazon Textract, and optionally Amazon Elastic Container Registry and Amazon Athena for advanced analytics features.

dataline
DataLine is an AI-driven data analysis and visualization tool designed for technical and non-technical users to explore data quickly. It offers privacy-focused data storage on the user's device, supports various data sources, generates charts, executes queries, and facilitates report building. The tool aims to speed up data analysis tasks for businesses and individuals by providing a user-friendly interface and natural language querying capabilities.

airbyte_serverless
AirbyteServerless is a lightweight tool designed to simplify the management of Airbyte connectors. It offers a serverless mode for running connectors, allowing users to easily move data from any source to their data warehouse. Unlike the full Airbyte-Open-Source-Platform, AirbyteServerless focuses solely on the Extract-Load process without a UI, database, or transform layer. It provides a CLI tool, 'abs', for managing connectors, creating connections, running jobs, selecting specific data streams, handling secrets securely, and scheduling remote runs. The tool is scalable, allowing independent deployment of multiple connectors. It aims to streamline the connector management process and provide a more agile alternative to the comprehensive Airbyte platform.
bugbug
Bugbug is a tool developed by Mozilla that leverages machine learning techniques to assist with bug and quality management, as well as other software engineering tasks like test selection and defect prediction. It provides various classifiers to suggest assignees, detect patches likely to be backed-out, classify bugs, assign product/components, distinguish between bugs and feature requests, detect bugs needing documentation, identify invalid issues, verify bugs needing QA, detect regressions, select relevant tests, track bugs, and more. Bugbug can be trained and tested using Python scripts, and it offers the ability to run model training tasks on Taskcluster. The project structure includes modules for data mining, bug/commit feature extraction, model implementations, NLP utilities, label handling, bug history playback, and GitHub issue retrieval.
For similar tasks
uwazi
Uwazi is a flexible database application designed for capturing and organizing collections of information, with a focus on document management. It is developed and supported by HURIDOCS, benefiting human rights organizations globally. The tool requires NodeJs, ElasticSearch, ICU Analysis Plugin, MongoDB, Yarn, and pdftotext for installation. It offers production and development installation guides, including Docker setup. Uwazi supports hot reloading, unit and integration testing with JEST, and end-to-end testing with Nightmare or Puppeteer. The system requirements include RAM, CPU, and disk space recommendations for on-premises and development usage.
Zettelgarden
Zettelgarden is a human-centric, open-source personal knowledge management system that helps users develop and maintain their understanding of the world. It focuses on creating and connecting atomic notes, thoughtful AI integration, and scalability from personal notes to company knowledge bases. The project is actively evolving, with features subject to change based on community feedback and development priorities.
lap
Lap is a lightning-fast, cross-platform photo manager that prioritizes user privacy and local AI processing. It allows users to organize and browse their photos efficiently, with features like natural language search, smart face recognition, and similar image search. Lap does not require importing photos, syncs seamlessly with the file system, and supports multiple libraries. Built for performance with a Rust core and lazy loading, Lap offers a delightful user experience with beautiful design, customization options, and multi-language support. It is a great alternative to cloud-based photo services, offering excellent organization, performance, and no vendor lock-in.
postman-mcp-server
The Postman MCP Server connects Postman to AI tools, enabling AI agents and assistants to access workspaces, manage collections and environments, evaluate APIs, and automate workflows through natural language interactions. It supports various tool configurations like Minimal, Full, and Code, catering to users with different needs. The server offers authentication via OAuth for the best developer experience and fastest setup. Use cases include API testing, code synchronization, collection management, workspace and environment management, automatic spec creation, and client code generation. Designed for developers integrating AI tools with Postman's context and features, supporting quick natural language queries to advanced agent workflows.
basdonax-ai-rag
Basdonax AI RAG v1.0 is a repository that contains all the necessary resources to create your own AI-powered secretary using the RAG from Basdonax AI. It leverages open-source models from Meta and Microsoft, namely 'Llama3-7b' and 'Phi3-4b', allowing users to upload documents and make queries. This tool aims to simplify life for individuals by harnessing the power of AI. The installation process involves choosing between different data models based on GPU capabilities, setting up Docker, pulling the desired model, and customizing the assistant prompt file. Once installed, users can access the RAG through a local link and enjoy its functionalities.
Local-File-Organizer
The Local File Organizer is an AI-powered tool designed to help users organize their digital files efficiently and securely on their local device. By leveraging advanced AI models for text and visual content analysis, the tool automatically scans and categorizes files, generates relevant descriptions and filenames, and organizes them into a new directory structure. All AI processing occurs locally using the Nexa SDK, ensuring privacy and security. With support for multiple file types and customizable prompts, this tool aims to simplify file management and bring order to users' digital lives.
Notate
Notate is a powerful desktop research assistant that combines AI-driven analysis with advanced vector search technology. It streamlines research workflow by processing, organizing, and retrieving information from documents, audio, and text. Notate offers flexible AI capabilities with support for various LLM providers and local models, ensuring data privacy. Built for researchers, academics, and knowledge workers, it features real-time collaboration, accessible UI, and cross-platform compatibility.
ai-chunking
AI Chunking is a powerful Python library for semantic document chunking and enrichment using AI. It provides intelligent document chunking capabilities with various strategies to split text while preserving semantic meaning, particularly useful for processing markdown documentation. The library offers multiple chunking strategies such as Recursive Text Splitting, Section-based Semantic Chunking, and Base Chunking. Users can configure chunk sizes, overlap, and support various text formats. The tool is easy to extend with custom chunking strategies, making it versatile for different document processing needs.
For similar jobs

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.