
base-llm
从 NLP 到 LLM 的算法全栈教程,在线阅读地址:https://datawhalechina.github.io/base-llm/
Stars: 278
Base LLM is a comprehensive learning tutorial from traditional Natural Language Processing (NLP) to Large Language Models (LLM), covering core technologies such as word embeddings, RNN, Transformer architecture, BERT, GPT, and Llama series models. The project aims to help developers build a solid technical foundation by providing a clear path from theory to practical engineering. It covers NLP theory, Transformer architecture, pre-trained language models, advanced model implementation, and deployment processes.
README:


注意:本项目可能进行大幅调整当前暂不接受 Pull Request。 如果您有任何建议或发现任何问题,欢迎通过 Issue 进行反馈。
本项目是一个从传统自然语言处理(NLP)到大语言模型(LLM)的全栈式学习教程,旨在为开发者提供一条从理论入门到工程实战的清晰路径。
在 LLM 爆发的今天,许多开发者直接上手调用 API 或微调大模型,却往往忽视了底层的自然语言处理(NLP)基础。本项目主张 “Base LLM is all you need”,通过系统性地回顾 NLP 发展历程中的核心技术——从早期的词向量、循环神经网络(RNN),到变革性的 Transformer 架构,再到如今的 BERT、GPT 及 Llama 系列大模型——帮助读者构建坚实的技术护城河。
核心内容覆盖:
- NLP 理论基石:深入浅出地讲解分词、词向量(Word2Vec)、RNN/LSTM 等经典算法。
- Transformer 架构:剖析 Attention 机制,详解 Encoder-Decoder 架构,奠定大模型认知基础。
- 预训练语言模型:全面覆盖 BERT、GPT、T5 等里程碑式模型的设计与应用。
- 大模型进阶实战:从零手搓 Llama2 模型,掌握参数高效微调(PEFT/LoRA)、RLHF 等前沿技术。
- 工程化落地:涵盖模型量化、推理加速、Docker 容器化及服务部署的全流程实战。
- 大模型安全与多模态:探索模型安全挑战、伦理问题,以及图文多模态模型的前沿技术。
随着人工智能技术的飞速发展,掌握大语言模型已成为 AI 工程师的必备技能。然而,市面上的教程往往存在断层。要么过于偏重学术理论,晦涩难懂;要么仅停留在 API 调用的应用层,缺乏底层原理的支撑。
本项目致力于填补这一空白,通过理论与代码并重的方式,帮助开发者:
- 打通知识脉络:理解技术演进的内在逻辑(如:为什么从 RNN 发展到 Transformer?)。
- 掌握核心原理:不仅会用,更懂其“所以然”,具备排查复杂问题和优化模型结构的能力。
- 学习代码演进:采用“提出问题-迭代重构”的教学模式,展示从简易脚本到工业级框架的演变过程,培养真正的工程化思维。
- 提升工程能力:通过 NER、文本分类及 LLM 微调部署等实战项目,积累生产环境下的开发经验。
- 拓宽技术视野:探索大模型安全、多模态等前沿领域,紧跟 AI 技术发展的最新趋势。
本项目适合以下人群学习:
- 🎓 在校学生:希望系统学习 NLP 知识,为科研或求职打下基础。
- 💻 AI 算法工程师:需要从传统机器学习/深度学习转型到大模型领域的开发者。
- 🤔 LLM 爱好者:对大模型底层原理感兴趣,希望深入理解大模型架构运行机制的极客。
- 🔬 研究人员:需要快速回顾 NLP 经典算法或寻找基线代码实现的学者。
前置要求:
- 🟢 Python 基础:熟练掌握 Python 语法及常用数据结构。
- 🔵 PyTorch 框架:具备基本的 PyTorch 深度学习框架使用经验。
- 🟡 数学基础:了解基本的线性代数、概率论及梯度下降等深度学习概念。
- 体系化进阶路径:从基础的文本表示到 RLHF 和量化技术,内容层层递进。
- 手写核心代码:拒绝"调包侠",带领读者手写 Llama2、Transformer 等核心架构代码。
- 实战导向:包含文本分类、命名实体识别(NER)、私有数据微调 Qwen2.5 等多个完整项目。
- 全流程覆盖:不仅教你怎么训练,还教你怎么用 Docker 和 FastAPI 将模型部署成服务。
- 图文并茂:配合大量图解,将抽象的算法原理可视化,降低学习门槛。
- 直观易懂:尽量弱化复杂的数学公式推导,让数学基础薄弱的读者也能轻松掌握算法原理。
- 第 1 章:NLP 简介
-
第 2 章:文本表示与词向量
- [x] 初级分词技术
- [x] 词向量表示
- [x] 从主题模型到 Word2Vec
- [x] 基于 Gensim 的词向量实战
-
第 3 章:循环神经网络
- [x] 循环神经网络
- [x] LSTM 与 GRU
-
第 4 章:注意力机制与Transformer
- [x] Seq2Seq 架构
- [x] 注意力机制
- [x] 深入解析 Transformer
-
第 5 章:预训练模型
- [x] BERT 结构及应用
- [x] GPT 结构及应用
- [x] T5 结构及应用
- [x] Hugging Face 生态与核心库
- 第 6 章:深入大模型架构
-
第 1 章:文本分类
- [x] 文本分类简单实现
- [x] 基于 LSTM 的文本分类
- [x] 微调 BERT 模型进行文本分类
-
第 2 章:命名实体识别
- [x] 命名实体识别概要
- [x] NER 项目的数据处理
- [x] 模型构建、训练与推理
- [x] 模型的推理与优化
-
第 1 章:参数高效微调
- [x] PEFT 技术综述
- [x] LoRA 方法详解
- [x] 基于 peft 库的 LoRA 实战
- [x] Qwen2.5 微调私有数据
-
第 2 章:高级微调技术
- [x] RLHF 技术详解
- [x] LLaMA-Factory RLHF(DPO)实战
-
第 3 章:大模型训练与量化
- [x] 模型量化实战
- [x] Deepspeed 框架介绍
-
第 1 章:模型服务部署
- [x] FastAPI 模型部署实战
- [x] 云服务器模型部署实战
- [x] 使用 Docker Compose 部署模型服务
- 第 2 章:自动化与性能优化
- 第 1 章:认识多模态边界
-
第 2 章:从感知到生成
- [x] BLIP-2 与 LLaVA
核心贡献者
- dalvqw-项目负责人(项目发起人与主要贡献者)
- 感谢 @Sm1les 对本项目的帮助与支持
- 感谢所有为本项目做出贡献的开发者们
- 感谢开源社区提供的优秀工具和框架支持
- 特别感谢以下为教程做出贡献的开发者!
Made with contrib.rocks.
- 发现问题请提交 Issue。
如果这个项目对你有帮助,请给我们一个 ⭐️
让更多人发现这个项目(护食?发来!)
扫描下方二维码关注公众号:Datawhale

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for base-llm
Similar Open Source Tools
base-llm
Base LLM is a comprehensive learning tutorial from traditional Natural Language Processing (NLP) to Large Language Models (LLM), covering core technologies such as word embeddings, RNN, Transformer architecture, BERT, GPT, and Llama series models. The project aims to help developers build a solid technical foundation by providing a clear path from theory to practical engineering. It covers NLP theory, Transformer architecture, pre-trained language models, advanced model implementation, and deployment processes.

all-in-rag
All-in-RAG is a comprehensive repository for all things related to Randomized Algorithms and Graphs. It provides a wide range of resources, including implementations of various randomized algorithms, graph data structures, and visualization tools. The repository aims to serve as a one-stop solution for researchers, students, and enthusiasts interested in exploring the intersection of randomized algorithms and graph theory. Whether you are looking to study theoretical concepts, implement algorithms in practice, or visualize graph structures, All-in-RAG has got you covered.
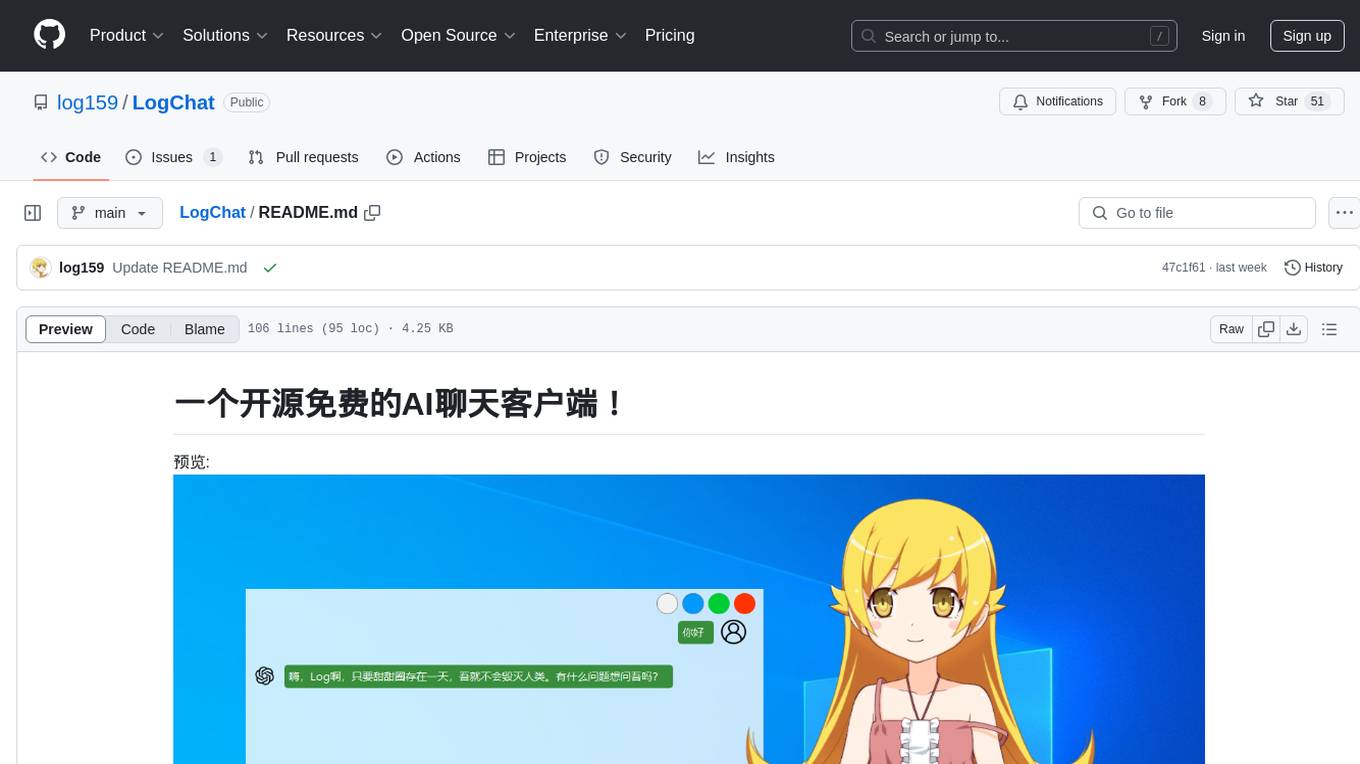
LogChat
LogChat is an open-source and free AI chat client that supports various chat models and technologies such as ChatGPT, 讯飞星火, DeepSeek, LLM, TTS, STT, and Live2D. The tool provides a user-friendly interface designed using Qt Creator and can be used on Windows systems without any additional environment requirements. Users can interact with different AI models, perform voice synthesis and recognition, and customize Live2D character models. LogChat also offers features like language translation, AI platform integration, and menu items like screenshot editing, clock, and application launcher.

aio-hub
AIO Hub is a cross-platform AI hub built on Tauri + Vue 3 + TypeScript, aiming to provide developers and creators with precise LLM control experience and efficient toolchain. It features a chat function designed for complex tasks and deep exploration, a unified context pipeline for controlling every token sent to the model, interactive AI buttons, dual-view management for non-linear conversation mapping, open ecosystem compatibility with various AI models, and a rich text renderer for LLM output. The tool also includes features for media workstation, developer productivity, system and asset management, regex applier, collaboration enhancement between developers and AI, and more.
chatwiki
ChatWiki is an open-source knowledge base AI question-answering system. It is built on large language models (LLM) and retrieval-augmented generation (RAG) technologies, providing out-of-the-box data processing, model invocation capabilities, and helping enterprises quickly build their own knowledge base AI question-answering systems. It offers exclusive AI question-answering system, easy integration of models, data preprocessing, simple user interface design, and adaptability to different business scenarios.
Snap-Solver
Snap-Solver is a revolutionary AI tool for online exam solving, designed for students, test-takers, and self-learners. With just a keystroke, it automatically captures any question on the screen, analyzes it using AI, and provides detailed answers. Whether it's complex math formulas, physics problems, coding issues, or challenges from other disciplines, Snap-Solver offers clear, accurate, and structured solutions to help you better understand and master the subject matter.
Saber-Translator
Saber-Translator is your exclusive AI comic translation tool, designed to effortlessly eliminate language barriers and enjoy the original comic fun. It offers features like translating comic images/PDFs, intelligent bubble detection and text recognition, powerful AI translation engine with multiple service providers, highly customizable translation effects, real-time preview and convenient operations, efficient image management and download, model recording and recommendation, and support for language learning with dual prompt word outputs.
get_jobs
Get Jobs is a tool designed to help users find and apply for job positions on various recruitment platforms in China. It features AI job matching, automatic cover letter generation, multi-platform job application, automated filtering of inactive HR and headhunter positions, real-time WeChat message notifications, blacklisted company updates, driver adaptation for Win11, centralized configuration, long-lasting cookie login, XPathHelper plugin, global logging, and more. The tool supports platforms like Boss直聘, 猎聘, 拉勾, 51job, and 智联招聘. Users can configure the tool for customized job searches and applications.
Daily-DeepLearning
Daily-DeepLearning is a repository that covers various computer science topics such as data structures, operating systems, computer networks, Python programming, data science packages like numpy, pandas, matplotlib, machine learning theories, deep learning theories, NLP concepts, machine learning practical applications, deep learning practical applications, and big data technologies like Hadoop and Hive. It also includes coding exercises related to '剑指offer'. The repository provides detailed explanations and examples for each topic, making it a comprehensive resource for learning and practicing different aspects of computer science and data-related fields.
godoos
GodoOS is an efficient intranet office operating system that includes various office tools such as word/excel/ppt/pdf/internal chat/whiteboard/mind map, with native file storage support. The platform interface mimics the Windows style, making it easy to operate while maintaining low resource consumption and high performance. It automatically connects to intranet users without registration, enabling instant communication and file sharing. The flexible and highly configurable app store allows for unlimited expansion.
KubeDoor
KubeDoor is a microservice resource management platform developed using Python and Vue, based on K8S admission control mechanism. It supports unified remote storage, monitoring, alerting, notification, and display for multiple K8S clusters. The platform focuses on resource analysis and control during daily peak hours of microservices, ensuring consistency between resource request rate and actual usage rate.
bk-lite
Blueking Lite is an AI First lightweight operation product with low deployment resource requirements, low usage costs, and progressive experience, providing essential tools for operation administrators.
TypeTale
TypeTale is an AIGC creation software designed specifically for content creators, primarily used for novel promotion. It offers a wide range of AI capabilities such as image, video, and audio generation, as well as text processing and story extraction. The tool also provides workflow customization, AI assistant support, and a vast library of creative materials. With a user-friendly interface and system requirements compatible with Windows operating systems, TypeTale aims to streamline the content creation process for writers and creators.
ai_wiki
This repository provides a comprehensive collection of resources, open-source tools, and knowledge related to quantitative analysis. It serves as a valuable knowledge base and navigation guide for individuals interested in various aspects of quantitative investing, including platforms, programming languages, mathematical foundations, machine learning, deep learning, and practical applications. The repository is well-structured and organized, with clear sections covering different topics. It includes resources on system platforms, programming codes, mathematical foundations, algorithm principles, machine learning, deep learning, reinforcement learning, graph networks, model deployment, and practical applications. Additionally, there are dedicated sections on quantitative trading and investment, as well as large models. The repository is actively maintained and updated, ensuring that users have access to the latest information and resources.
bella-openapi
Bella OpenAPI is an API gateway that provides rich AI capabilities, similar to openrouter. In addition to chat completion ability, it also offers text embedding, ASR, TTS, image-to-image, and text-to-image AI capabilities. It integrates billing, rate limiting, and resource management functions. All integrated capabilities have been validated in large-scale production environments. The tool supports various AI capabilities, metadata management, unified login service, billing and rate limiting, and has been validated in large-scale production environments for stability and reliability. It offers a user-friendly experience with Java-friendly technology stack, convenient cloud-based experience service, and Dockerized deployment.
douyin-chatgpt-bot
Douyin ChatGPT Bot is an AI-driven system for automatic replies on Douyin, including comment and private message replies. It offers features such as comment filtering, customizable robot responses, and automated account management. The system aims to enhance user engagement and brand image on the Douyin platform, providing a seamless experience for managing interactions with followers and potential customers.
For similar tasks

ai-on-gke
This repository contains assets related to AI/ML workloads on Google Kubernetes Engine (GKE). Run optimized AI/ML workloads with Google Kubernetes Engine (GKE) platform orchestration capabilities. A robust AI/ML platform considers the following layers: Infrastructure orchestration that support GPUs and TPUs for training and serving workloads at scale Flexible integration with distributed computing and data processing frameworks Support for multiple teams on the same infrastructure to maximize utilization of resources

ray
Ray is a unified framework for scaling AI and Python applications. It consists of a core distributed runtime and a set of AI libraries for simplifying ML compute, including Data, Train, Tune, RLlib, and Serve. Ray runs on any machine, cluster, cloud provider, and Kubernetes, and features a growing ecosystem of community integrations. With Ray, you can seamlessly scale the same code from a laptop to a cluster, making it easy to meet the compute-intensive demands of modern ML workloads.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

djl
Deep Java Library (DJL) is an open-source, high-level, engine-agnostic Java framework for deep learning. It is designed to be easy to get started with and simple to use for Java developers. DJL provides a native Java development experience and allows users to integrate machine learning and deep learning models with their Java applications. The framework is deep learning engine agnostic, enabling users to switch engines at any point for optimal performance. DJL's ergonomic API interface guides users with best practices to accomplish deep learning tasks, such as running inference and training neural networks.

mlflow
MLflow is a platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models. MLflow offers a set of lightweight APIs that can be used with any existing machine learning application or library (TensorFlow, PyTorch, XGBoost, etc), wherever you currently run ML code (e.g. in notebooks, standalone applications or the cloud). MLflow's current components are:
* `MLflow Tracking

tt-metal
TT-NN is a python & C++ Neural Network OP library. It provides a low-level programming model, TT-Metalium, enabling kernel development for Tenstorrent hardware.

burn
Burn is a new comprehensive dynamic Deep Learning Framework built using Rust with extreme flexibility, compute efficiency and portability as its primary goals.

awsome-distributed-training
This repository contains reference architectures and test cases for distributed model training with Amazon SageMaker Hyperpod, AWS ParallelCluster, AWS Batch, and Amazon EKS. The test cases cover different types and sizes of models as well as different frameworks and parallel optimizations (Pytorch DDP/FSDP, MegatronLM, NemoMegatron...).
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.