
Daily-DeepLearning
🔥机器学习/深度学习/Python/大模型/多模态/LLM/deeplearning/Python/Algorithm interview/NLP Tutorial
Stars: 666
Daily-DeepLearning is a repository that covers various computer science topics such as data structures, operating systems, computer networks, Python programming, data science packages like numpy, pandas, matplotlib, machine learning theories, deep learning theories, NLP concepts, machine learning practical applications, deep learning practical applications, and big data technologies like Hadoop and Hive. It also includes coding exercises related to '剑指offer'. The repository provides detailed explanations and examples for each topic, making it a comprehensive resource for learning and practicing different aspects of computer science and data-related fields.
README:
欢迎来到 Daily-DearnLearning,原本这是一个为了自己打造的深度学习知识库(⬇️滑到最下面或者看目录,可以看以前的和机器学习、深度学习相关的内容),涵盖计算机基础课程、Python快速入门、数据科学包的使用、机器学习、深度学习、自然语言处理、LLM等。
我在17年的时候就根据Google的《Attention is all you need》做了一些学习、复现,那会已经快毕业了,舍友问我:“你觉得NLP什么时候能成熟?”,我当时信誓旦旦的说:“至少得几十年吧。”,后来阴差阳错没有做算法的工作,跌跌撞撞进了体制内。2018年,Bert刚出现,当时还在想,怎么NLP也要学图像开始做大力出奇迹的事情了吗,再后来Elmo、GPT-2,再到chatGPT的效果出现了爆炸式的提升,我有点按耐不住了,人工智能的斯普特尼克时刻(Sputnik moment)真的要来了吗。打算从头和大家一起学习,回到这个令人兴奋的领域。(24年11、12月开始关注deepseek,结果25年的1月R1发布之后,在全球大火,这个奇点时刻似乎越来越近了)
纠结了一阵子,要不要把Daily-DeepLearning改成Daily-LLM,想了想还是算了吧,反正现在都是基于deeplearning。
要说LLM,大家第一反应应该都是《Attention is all you need》这篇论文了吧。在那之前,因为李飞飞教授推动的ImageNet数据集、GPU算力的提升,那时像CNN刚刚开始流行起来,多少人入门都是用Tensoflow或者Theano写一个手写数字识别。后来开始有人在NLP领域,用word2vec和LSTM的组合,在很多领域里做到SOTA的效果。后来就是2017年,由Google团队提出的这篇里程碑式的论文。
这里其实有三个核心的创新点(完整解析文档《Attention is all you need》解析)
第一个是模型的主体结构不再是CNN、RNN的变种,用了用self-Attention为主的Transformer结构,所以这篇论文的标题才会说这是all you need嘛。这种方法解决了无法并行计算并且长距离捕捉予以的问题。自注意力机制解析
第二个是多头注意力机制Multi-Head Attention,把输入映射到多个不同的空间,并行计算注意力,有点像CV的RGB、进阶版的词向量的感觉,捕捉不同维度的语义信息,比如语法、语意、上下文信息等等。多头注意力机制解析
第三个是用了位置编码Positional Encoding,这个点很巧妙,因为以前RNN、Lstm输入的时候是顺序输入的,虽然慢,但是正是这种序列化的表示。位置编码机制解析
PS:如果对编码不太了解,可以看看以前的编码方式,比如机器学习时期的词袋模型TF-IDF 或者深度学习时期的词向量
如果这三个核心点都理解了,我们可以开始看看整个Transformer的结构。如果你以前习惯了RNN/LSTM的结构,对于这种全新的架构会有点懵逼。其实整个结构很干净,没有什么花里胡哨的。用我的理解方式就是,首先有两个部分Encoder和Decoder。Encoder是用来提取输入序列的特征,Decoder是生成输出序列。比如在翻译任务中,Encoder处理源语言,Decoder生成目标语言。(Encoder可以并行处理所有输入,Decoder和Lstm类似,每一步是依赖之前的输出的)Transformer解析
PS:除了核心的创新外,里面还是用到了前馈神经网络、残差连接、层归一化这些以前的技术。
以机器翻译为例
# Encoder
输入序列:["我", "爱", "自然语言处理"]
↓
词嵌入 + 位置编码 → [向量1, 向量2, 向量3]
↓
经过6个编码器层的处理:
每个层包含:
1. 多头自注意力(关注整个输入序列)
2. 前馈神经网络(特征变换)
3. 残差连接 + 层归一化
↓
输出上下文表示:包含"我-爱-处理"关系的综合特征矩阵
# Decoder
已生成部分:["I"]
↓
输入:["<start>", "I"](起始符 + 已生成词)
↓
经过6个解码器层的处理:
每个层包含:
1. 掩码多头注意力(仅关注已生成部分)
2. 编码-解码注意力(连接编码器输出)
3. 前馈神经网络
4. 残差连接 + 层归一化
↓
预测下一个词:"love"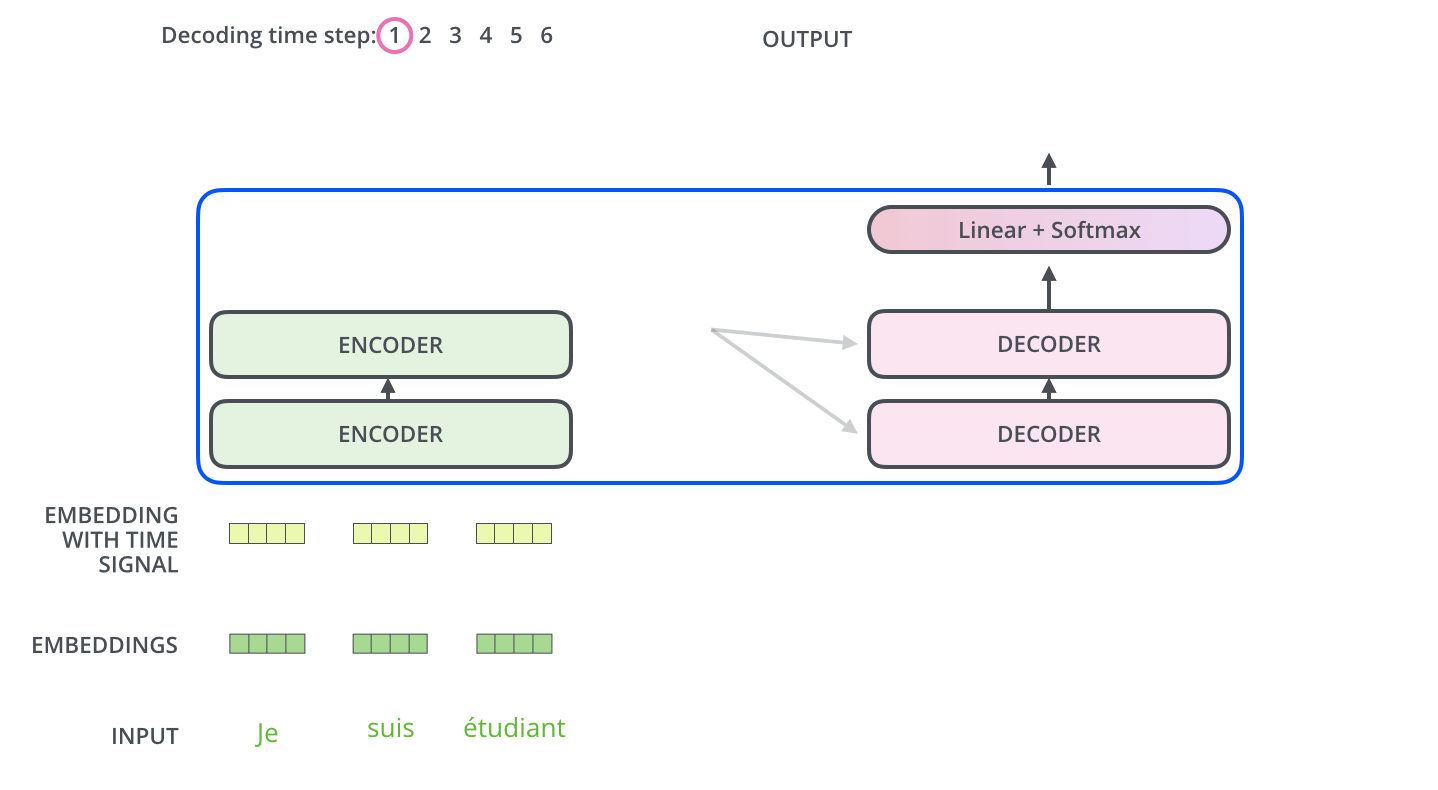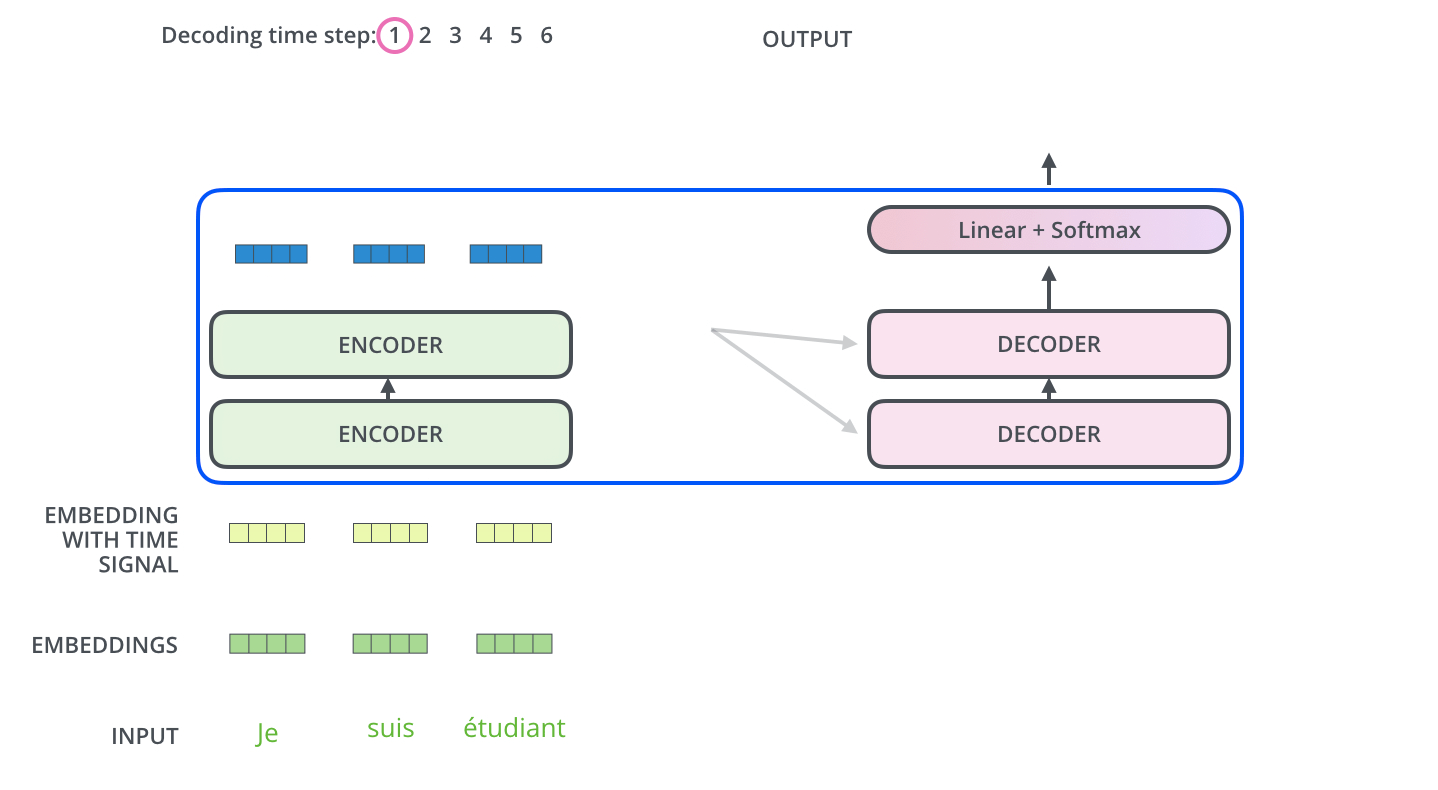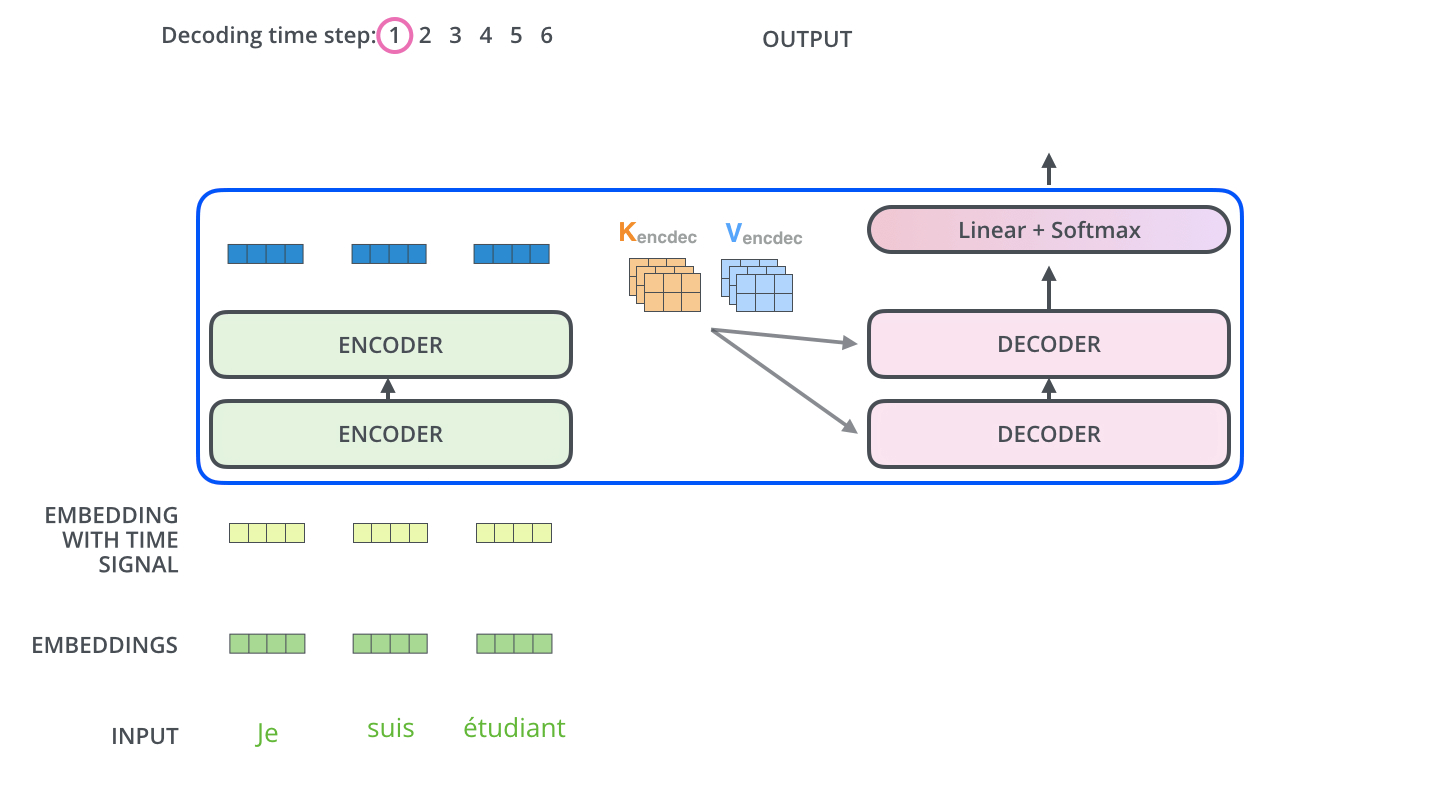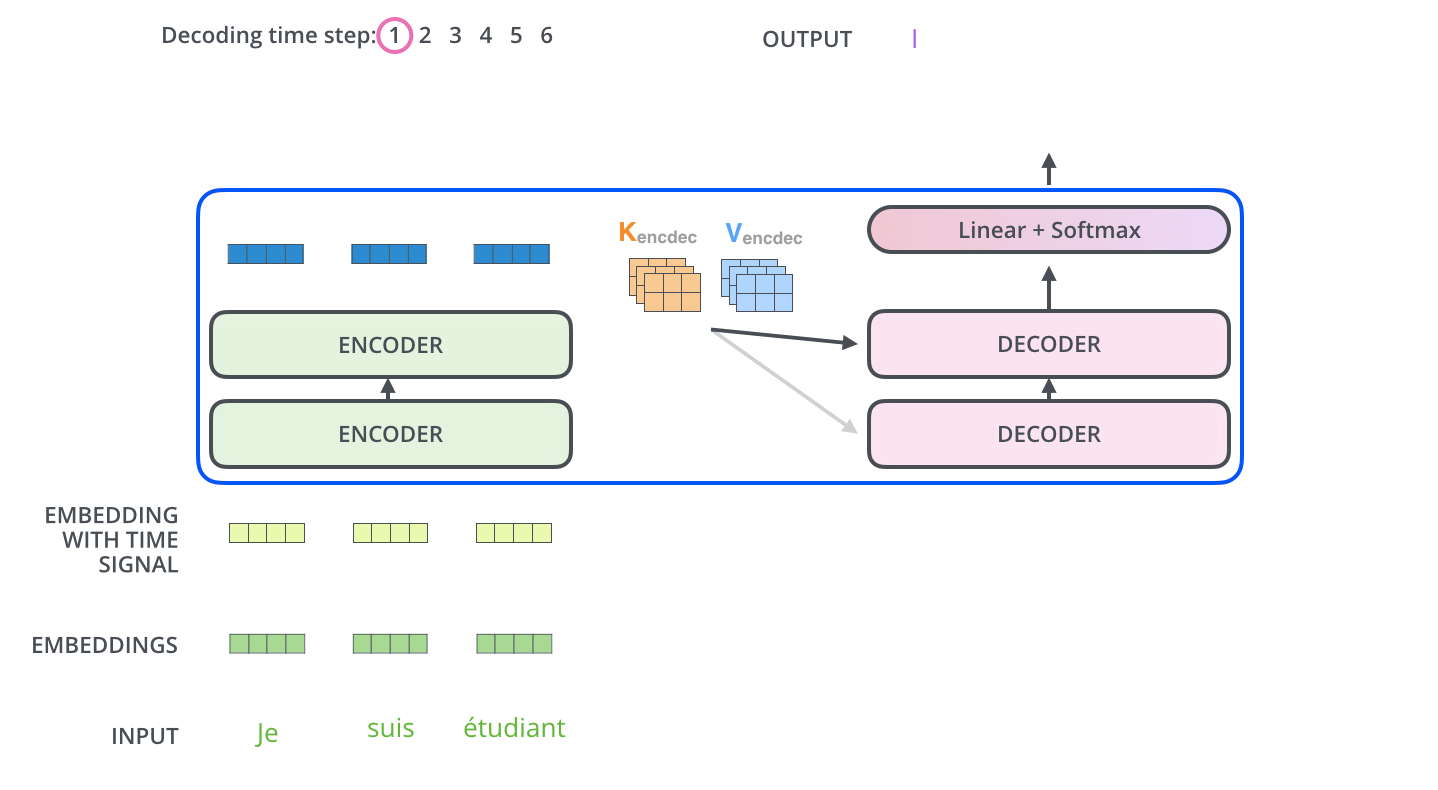
通过这个图,基本上能理解Transformer的90%了,有一个比较特殊的点是Decoder的掩码注意力机制。Decoder在生成目标序列的时候,是自回归的,也就是一个一个词生成的。比如在翻译的时候,先生成第一个词,然后用第一个词生成第二个词,依此类推。这时候在训练的时候,怎么确保解码器不会看到未来的信息呢?比如在预测第三个词的时候,模型不应该知道第三个词之后的正确答案,否则会导致信息泄漏,影响模型的泛化能力。
这时候就需要掩码注意力机制了。掩码的作用应该是掩盖掉当前位置之后的位置,使得在计算注意力权重的时候,后面的位置不会被考虑到。具体来说,在自注意力计算的时候,生成一个上三角矩阵,对角线以上的元素设置为负无穷或者一个很小的数,这样在softmax之后,这些位置的权重就会接近零。

比如,对于一个长度为4的序列,掩码矩阵可能如下:
[[0, -inf, -inf, -inf],
[0, 0, -inf, -inf],
[0, 0, 0, -inf],
[0, 0, 0, 0]] # 0表示保留,-inf表示掩盖当计算注意力时,每个位置只能看到自己和前面的位置。例如,第二个位置只能关注第一个和第二个位置,第三个位置可以关注前三个,依此类推。掩码解析
自从Transformer架构提出后,在NLP领域开始涌现出了一系列有意思的工作。
完整的复现推荐这个Harvard NLP PyTorch实现Transformer
我们也可以使用BLEU数据集进行简单的复现Transformer复现
论文戳这里:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Bert比较特殊的地方在于采用了双向上下文建模,通过掩码语言模型(Masked language Model),同时利用左右两侧上下文,解决传统模型中的单向性问题。还有很重要的一点,从Bert看来是,形成了“预训练+微调”的新范式,统一了多种NLP任务的框架,仅需在预训练模型基础上添加简单任务头即可适配下游任务。当时在11项NLP任务上刷新SOTA,开启了大规模预训练模型(Pre-trained Language Model, PLM)时代。Bert解析
Bert的双向上下文建模改变了文本表示的学习方式,通过Transformer的编码器结构同时捕捉文本中每个词的左右两侧上下文信息,从而更全面地理解语言语义。
输入表示上使用词嵌入(WordPiece) + 位置嵌入(Position) + 段落嵌入(Segment)
整体模型:
输入层 → Embedding → Transformer Encoder × L → 输出层- 输入层:将文本转化成768维向量(BERT-base)
- Encoder层数:BERT-base(L=12)、BERT-large(L=24)
- 输出层:根据任务选择输出形式(如
[CLS]向量用于分类)
单层 Encoder 的详细计算流程:
输入向量 → LayerNorm → 多头自注意力 → 残差连接 → LayerNorm → 前馈网络 → 残差连接 → 输出我们可以使用BLEU数据集进行简单的复现Bert复现
数据结构
操作系统
计算机网络
Day01: 变量、字符串、数字和运算符
Day02: 列表、元组
Day03: 字典、集合
Day04: 条件语句、循环
Day05: 函数的定义与调用
Day06: 迭代、生成器、迭代器
Day07: 高阶函数、装饰器
Day08: 面向对象编程
Day09: 类的高级特性
Day10: 错误处理与调试
Day11: 文件操作
Day12: 多线程与多进程
Day13: 日期时间、集合、结构体
Day14: 协程与异步编程
Day15: 综合实践
NumPy
Pandas
Matplotlib
理论
- 逻辑回归
- EM 算法
- 集成学习
- 随机森林与 GBDT
- ID3/C4.5 算法
- K-means
- K 最近邻
- 贝叶斯
- XGBoost/LightGBM
- Gradient Boosting
- Boosting Tree
- 回归树
- XGBoost
- GBDT 分类
- GBDT 回归
- LightGBM
- CatBoost
实战
- NumPy 实战:创建 ndarray
- Pandas 实战:加载数据
- Matplotlib 实战:直线图
理论
实战
如果你有任何问题或建议,欢迎通过以下方式联系我们:
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Daily-DeepLearning
Similar Open Source Tools
Daily-DeepLearning
Daily-DeepLearning is a repository that covers various computer science topics such as data structures, operating systems, computer networks, Python programming, data science packages like numpy, pandas, matplotlib, machine learning theories, deep learning theories, NLP concepts, machine learning practical applications, deep learning practical applications, and big data technologies like Hadoop and Hive. It also includes coding exercises related to '剑指offer'. The repository provides detailed explanations and examples for each topic, making it a comprehensive resource for learning and practicing different aspects of computer science and data-related fields.
chatwiki
ChatWiki is an open-source knowledge base AI question-answering system. It is built on large language models (LLM) and retrieval-augmented generation (RAG) technologies, providing out-of-the-box data processing, model invocation capabilities, and helping enterprises quickly build their own knowledge base AI question-answering systems. It offers exclusive AI question-answering system, easy integration of models, data preprocessing, simple user interface design, and adaptability to different business scenarios.
ai_wiki
This repository provides a comprehensive collection of resources, open-source tools, and knowledge related to quantitative analysis. It serves as a valuable knowledge base and navigation guide for individuals interested in various aspects of quantitative investing, including platforms, programming languages, mathematical foundations, machine learning, deep learning, and practical applications. The repository is well-structured and organized, with clear sections covering different topics. It includes resources on system platforms, programming codes, mathematical foundations, algorithm principles, machine learning, deep learning, reinforcement learning, graph networks, model deployment, and practical applications. Additionally, there are dedicated sections on quantitative trading and investment, as well as large models. The repository is actively maintained and updated, ensuring that users have access to the latest information and resources.
LLM_book
LLM_book is a learning record and roadmap for programmers with a certain AI foundation to learn Large Language Models (LLM). It covers topics such as PyTorch basics, Transformer architecture, langchain basics, foundational concepts of large models, fine-tuning methods, RAG (Retrieval-Augmented Generation), and building intelligent agents using LLM. The repository provides learning materials, code implementations, and documentation to help users progress in understanding and implementing LLM technologies.
AcademicForge
Academic Forge is a collection of skills integrated for academic writing workflows. It provides a curated set of skills related to academic writing and research, allowing for precise skill calls, avoiding confusion between similar skills, maintaining focus on research workflows, and receiving timely updates from original authors. The forge integrates carefully selected skills covering various areas such as bioinformatics, clinical research, data analysis, scientific writing, laboratory automation, machine learning, databases, AI research, model architectures, fine-tuning, post-training, distributed training, optimization, inference, evaluation, agents, multimodal tasks, and machine learning paper writing. It is designed to streamline the academic writing and AI research processes by providing a cohesive and community-driven collection of skills.

aio-hub
AIO Hub is a cross-platform AI hub built on Tauri + Vue 3 + TypeScript, aiming to provide developers and creators with precise LLM control experience and efficient toolchain. It features a chat function designed for complex tasks and deep exploration, a unified context pipeline for controlling every token sent to the model, interactive AI buttons, dual-view management for non-linear conversation mapping, open ecosystem compatibility with various AI models, and a rich text renderer for LLM output. The tool also includes features for media workstation, developer productivity, system and asset management, regex applier, collaboration enhancement between developers and AI, and more.
bella-openapi
Bella OpenAPI is an API gateway that provides rich AI capabilities, similar to openrouter. In addition to chat completion ability, it also offers text embedding, ASR, TTS, image-to-image, and text-to-image AI capabilities. It integrates billing, rate limiting, and resource management functions. All integrated capabilities have been validated in large-scale production environments. The tool supports various AI capabilities, metadata management, unified login service, billing and rate limiting, and has been validated in large-scale production environments for stability and reliability. It offers a user-friendly experience with Java-friendly technology stack, convenient cloud-based experience service, and Dockerized deployment.
Snap-Solver
Snap-Solver is a revolutionary AI tool for online exam solving, designed for students, test-takers, and self-learners. With just a keystroke, it automatically captures any question on the screen, analyzes it using AI, and provides detailed answers. Whether it's complex math formulas, physics problems, coding issues, or challenges from other disciplines, Snap-Solver offers clear, accurate, and structured solutions to help you better understand and master the subject matter.

LabelQuick
LabelQuick_V2.0 is a fast image annotation tool designed and developed by the AI Horizon team. This version has been optimized and improved based on the previous version. It provides an intuitive interface and powerful annotation and segmentation functions to efficiently complete dataset annotation work. The tool supports video object tracking annotation, quick annotation by clicking, and various video operations. It introduces the SAM2 model for accurate and efficient object detection in video frames, reducing manual intervention and improving annotation quality. The tool is designed for Windows systems and requires a minimum of 6GB of memory.
MaiMBot
MaiMBot is an intelligent QQ group chat bot based on a large language model. It is developed using the nonebot2 framework, utilizes LLM for conversation abilities, MongoDB for data persistence, and NapCat for QQ protocol support. The bot features keyword-triggered proactive responses, dynamic prompt construction, support for images and message forwarding, typo generation, multiple replies, emotion-based emoji responses, daily schedule generation, user relationship management, knowledge base, and group impressions. Work-in-progress features include personality, group atmosphere, image handling, humor, meme functions, and Minecraft interactions. The tool is in active development with plans for GIF compatibility, mini-program link parsing, bug fixes, documentation improvements, and logic enhancements for emoji sending.
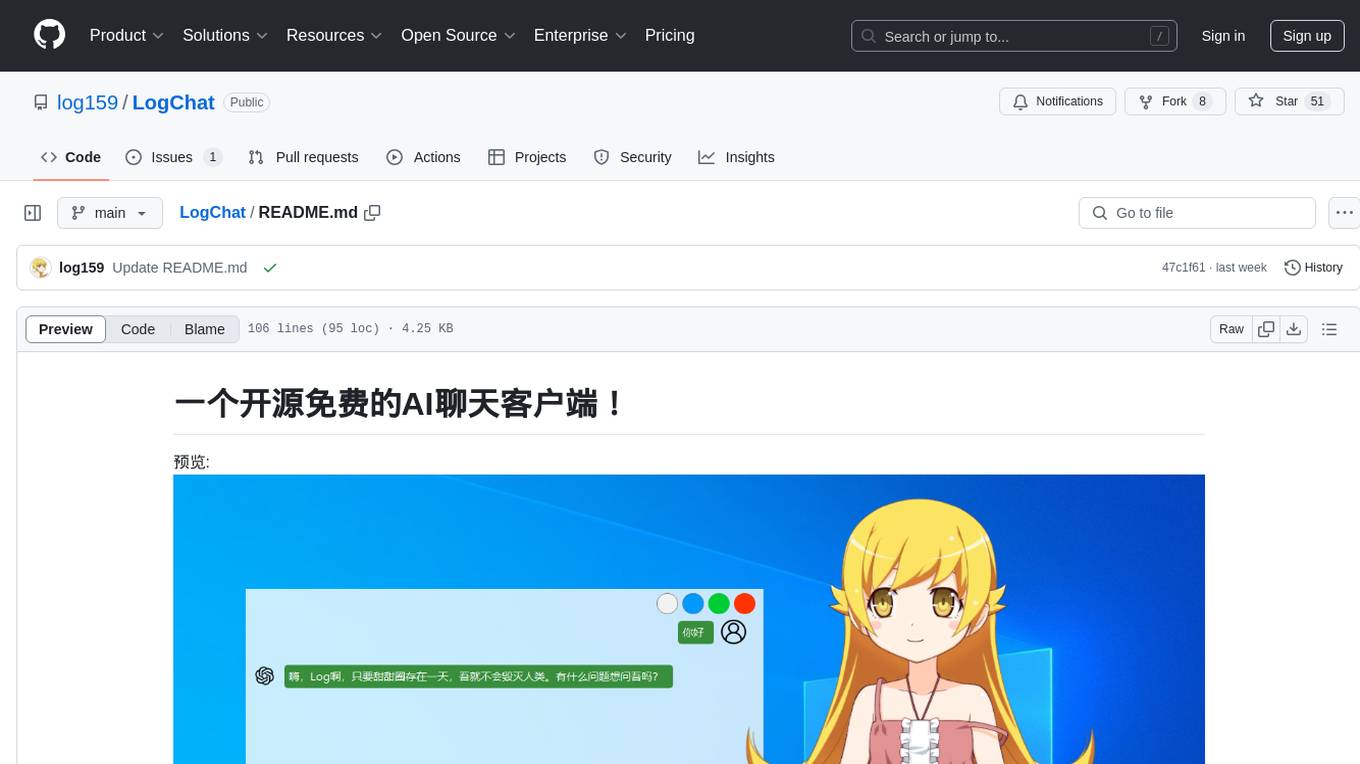
LogChat
LogChat is an open-source and free AI chat client that supports various chat models and technologies such as ChatGPT, 讯飞星火, DeepSeek, LLM, TTS, STT, and Live2D. The tool provides a user-friendly interface designed using Qt Creator and can be used on Windows systems without any additional environment requirements. Users can interact with different AI models, perform voice synthesis and recognition, and customize Live2D character models. LogChat also offers features like language translation, AI platform integration, and menu items like screenshot editing, clock, and application launcher.
bk-lite
Blueking Lite is an AI First lightweight operation product with low deployment resource requirements, low usage costs, and progressive experience, providing essential tools for operation administrators.
FastDeploy
FastDeploy is an inference and deployment toolkit for large language models and visual language models based on PaddlePaddle. It provides production-ready deployment solutions with core acceleration technologies such as load-balanced PD disaggregation, unified KV cache transmission, OpenAI API server compatibility, comprehensive quantization format support, advanced acceleration techniques, and multi-hardware support. The toolkit supports various hardware platforms like NVIDIA GPUs, Kunlunxin XPUs, Iluvatar GPUs, Enflame GCUs, and Hygon DCUs, with plans for expanding support to Ascend NPU and MetaX GPU. FastDeploy aims to optimize resource utilization, throughput, and performance for inference and deployment tasks.
Flux-AI-Pro
Flux AI Pro - NanoBanana Edition is a high-performance, single-file AI image generation solution built on Cloudflare Workers. It integrates top AI providers like Pollinations.ai, Infip/Ghostbot, Aqua Server, Kinai API, and Airforce API to offer a serverless, fast, and feature-rich creative experience. It provides seamless interface for generating high-quality AI art without complex server setups. The tool supports multiple languages, smart language detection, RTL support, AI prompt generator, high-definition image generation, and local history storage with export/import functionality.
ai-money-maker-handbook
The 'ai-money-maker-handbook' repository is a collection of information on using AI to earn extra income through side jobs. It includes strategies, resources, and verified methods for making money with AI technology in various fields. The repository provides insights on leveraging AI tools, platforms, and techniques to generate additional revenue streams in the AI era.
DeepBattler
DeepBattler is a tool designed for Hearthstone Battlegrounds players, providing real-time strategic advice and insights to improve gameplay experience. It integrates with the Hearthstone Deck Tracker plugin and offers voice-assisted guidance. The tool is powered by a large language model (LLM) and can match the strength of top players on EU servers. Users can set up the tool by adding dependencies, configuring the plugin path, and launching the LLM agent. DeepBattler is licensed for personal, educational, and non-commercial use, with guidelines on non-commercial distribution and acknowledgment of external contributions.
For similar tasks

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

sorrentum
Sorrentum is an open-source project that aims to combine open-source development, startups, and brilliant students to build machine learning, AI, and Web3 / DeFi protocols geared towards finance and economics. The project provides opportunities for internships, research assistantships, and development grants, as well as the chance to work on cutting-edge problems, learn about startups, write academic papers, and get internships and full-time positions at companies working on Sorrentum applications.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

zep-python
Zep is an open-source platform for building and deploying large language model (LLM) applications. It provides a suite of tools and services that make it easy to integrate LLMs into your applications, including chat history memory, embedding, vector search, and data enrichment. Zep is designed to be scalable, reliable, and easy to use, making it a great choice for developers who want to build LLM-powered applications quickly and easily.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

mojo
Mojo is a new programming language that bridges the gap between research and production by combining Python syntax and ecosystem with systems programming and metaprogramming features. Mojo is still young, but it is designed to become a superset of Python over time.

pandas-ai
PandasAI is a Python library that makes it easy to ask questions to your data in natural language. It helps you to explore, clean, and analyze your data using generative AI.

databend
Databend is an open-source cloud data warehouse that serves as a cost-effective alternative to Snowflake. With its focus on fast query execution and data ingestion, it's designed for complex analysis of the world's largest datasets.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.