
chonkie
🦛 CHONK docs with Chonkie ✨ — The lightweight ingestion library for fast, efficient and robust RAG pipelines
Stars: 3749
Chonkie is a feature-rich, easy-to-use, fast, lightweight, and wide-support chunking library designed to efficiently split texts into chunks. It integrates with various tokenizers, embedding models, and APIs, supporting 56 languages and offering cloud-ready functionality. Chonkie provides a modular pipeline approach called CHOMP for text processing, chunking, post-processing, and exporting. With multiple chunkers, refineries, porters, and handshakes, Chonkie offers a comprehensive solution for text chunking needs. It includes 24+ integrations, 3+ LLM providers, 2+ refineries, 2+ porters, and 4+ vector database connections, making it a versatile tool for text processing and analysis.
README:
![]()



The lightweight ingestion library for fast, efficient and robust RAG pipelines
Installation • Usage • Chunkers • Integrations • Benchmarks
Tired of making your gazillionth chunker? Sick of the overhead of large libraries? Want to chunk your texts quickly and efficiently? Chonkie the mighty hippo is here to help!
🚀 Feature-rich: All the CHONKs you'd ever need 🔄 End-to-end: Fetch, CHONK, refine, embed and ship straight to your vector DB! ✨ Easy to use: Install, Import, CHONK ⚡ Fast: CHONK at the speed of light! zooooom 🪶 Light-weight: No bloat, just CHONK 🔌 32+ integrations: Works with your favorite tools and vector DBs out of the box! 💬 ️Multilingual: Out-of-the-box support for 56 languages ☁️ Cloud-Friendly: CHONK locally or in the Cloud 🦛 Cute CHONK mascot: psst it's a pygmy hippo btw ❤️ Moto Moto's favorite python library
Chonkie is a chunking library that "just works" ✨
Using pip:
pip install chonkieOr using uv (faster):
uv pip install chonkieChonkie follows the rule of minimum installs.
Have a favorite chunker? Read our docs to install only what you need.
Don't want to think about it? Simply install all (Not recommended for production environments).
Using pip:
pip install "chonkie[all]"Or using uv:
uv pip install "chonkie[all]"Here's a basic example to get you started:
# First import the chunker you want from Chonkie
from chonkie import RecursiveChunker
# Initialize the chunker
chunker = RecursiveChunker()
# Chunk some text
chunks = chunker("Chonkie is the goodest boi! My favorite chunking hippo hehe.")
# Access chunks
for chunk in chunks:
print(f"Chunk: {chunk.text}")
print(f"Tokens: {chunk.token_count}")You can also use the chonkie.Pipeline to chain components together and handle complex workflows. Read more about pipelines in the docs!
from chonkie import Pipeline
# Create a pipeline with multiple chunking and refinement steps
pipe = (
Pipeline()
.chunk_with("recursive", tokenizer="gpt2", chunk_size=2048, recipe="markdown")
.chunk_with("semantic", chunk_size=512)
.refine_with("overlap", context_size=128)
.refine_with("embeddings", embedding_model="sentence-transformers/all-MiniLM-L6-v2")
)
# CHONK some Texts!
doc = pipe.run(texts="Chonkie is the goodest boi! My favorite chunking hippo hehe.")
# Access the processed chunks in the `doc` object
for chunk in doc.chunks:
print(chunk.text)Check out more usage examples in the docs!
Chonkie provides several chunkers to help you split your text efficiently for RAG applications. Here's a quick overview of the available chunkers:
| Name | Alias | Description |
|---|---|---|
TokenChunker |
token |
Splits text into fixed-size token chunks. |
FastChunker |
fast |
SIMD-accelerated byte-based chunking at 100+ GB/s. Install with chonkie[fast]. |
SentenceChunker |
sentence |
Splits text into chunks based on sentences. |
RecursiveChunker |
recursive |
Splits text hierarchically using customizable rules to create semantically meaningful chunks. |
SemanticChunker |
semantic |
Splits text into chunks based on semantic similarity. Inspired by the work of Greg Kamradt. |
LateChunker |
late |
Embeds text and then splits it to have better chunk embeddings. |
CodeChunker |
code |
Splits code into structurally meaningful chunks. |
NeuralChunker |
neural |
Splits text using a neural model. |
SlumberChunker |
slumber |
Splits text using an LLM to find semantically meaningful chunks. Also known as "AgenticChunker". |
More on these methods and the approaches taken inside the docs
Chonkie boasts 32+ integrations across tokenizers, embedding providers, LLMs, refineries, porters, vector databases, and utilities, ensuring it fits seamlessly into your existing workflow.
👨🍳 Chefs & 📁 Fetchers! Text preprocessing and data loading!
Chefs handle text preprocessing, while Fetchers load data from various sources.
| Component | Class | Description | Optional Install |
|---|---|---|---|
chef |
TextChef |
Text preprocessing and cleaning. | default |
fetcher |
FileFetcher |
Load text from files and directories. | default |
🏭 Refine your CHONKs with Context and Embeddings! Chonkie supports 2+ refineries!
Refineries help you post-process and enhance your chunks after initial chunking.
| Refinery Name | Class | Description | Optional Install |
|---|---|---|---|
overlap |
OverlapRefinery |
Merge overlapping chunks based on similarity. | default |
embeddings |
EmbeddingsRefinery |
Add embeddings to chunks using any provider. | chonkie[semantic] |
🐴 Exporting CHONKs! Chonkie supports 2+ Porters!
Porters help you save your chunks easily.
| Porter Name | Class | Description | Optional Install |
|---|---|---|---|
json |
JSONPorter |
Export chunks to a JSON file. | default |
datasets |
DatasetsPorter |
Export chunks to HuggingFace datasets. | chonkie[datasets] |
🤝 Shake hands with your DB! Chonkie connects with 8+ vector stores!
Handshakes provide a unified interface to ingest chunks directly into your favorite vector databases.
| Handshake Name | Class | Description | Optional Install |
|---|---|---|---|
chroma |
ChromaHandshake |
Ingest chunks into ChromaDB. | chonkie[chroma] |
elastic |
ElasticHandshake |
Ingest chunks into Elasticsearch. | chonkie[elastic] |
mongodb |
MongoDBHandshake |
Ingest chunks into MongoDB. | chonkie[mongodb] |
pgvector |
PgvectorHandshake |
Ingest chunks into PostgreSQL with pgvector. | chonkie[pgvector] |
pinecone |
PineconeHandshake |
Ingest chunks into Pinecone. | chonkie[pinecone] |
qdrant |
QdrantHandshake |
Ingest chunks into Qdrant. | chonkie[qdrant] |
turbopuffer |
TurbopufferHandshake |
Ingest chunks into Turbopuffer. | chonkie[tpuf] |
weaviate |
WeaviateHandshake |
Ingest chunks into Weaviate. | chonkie[weaviate] |
🪓 Slice 'n' Dice! Chonkie supports 5+ ways to tokenize!
Choose from supported tokenizers or provide your own custom token counting function. Flexibility first!
| Name | Description | Optional Install |
|---|---|---|
character |
Basic character-level tokenizer. Default tokenizer. | default |
word |
Basic word-level tokenizer. | default |
byte |
Byte-level tokenizer operating on UTF-8 encoded bytes. | default |
tokenizers |
Load any tokenizer from the Hugging Face tokenizers library. |
chonkie[tokenizers] |
tiktoken |
Use OpenAI's tiktoken library (e.g., for gpt-4). |
chonkie[tiktoken] |
transformers |
Load tokenizers via AutoTokenizer from HF transformers. |
chonkie[neural] |
default indicates that the feature is available with the default pip install chonkie.
To use a custom token counter, you can pass in any function that takes a string and returns an integer! Something like this:
def custom_token_counter(text: str) -> int:
return len(text)
chunker = RecursiveChunker(tokenizer=custom_token_counter)You can use this to extend Chonkie to support any tokenization scheme you want!
🧠 Embed like a boss! Chonkie links up with 9+ embedding pals!
Seamlessly works with various embedding model providers. Bring your favorite embeddings to the CHONK party! Use AutoEmbeddings to load models easily.
| Provider / Alias | Class | Description | Optional Install |
|---|---|---|---|
model2vec |
Model2VecEmbeddings |
Use Model2Vec models. |
chonkie[model2vec] |
sentence-transformers |
SentenceTransformerEmbeddings |
Use any sentence-transformers model. |
chonkie[st] |
openai |
OpenAIEmbeddings |
Use OpenAI's embedding API. | chonkie[openai] |
azure-openai |
AzureOpenAIEmbeddings |
Use Azure OpenAI embedding service. | chonkie[azure-openai] |
cohere |
CohereEmbeddings |
Use Cohere's embedding API. | chonkie[cohere] |
gemini |
GeminiEmbeddings |
Use Google's Gemini embedding API. | chonkie[gemini] |
jina |
JinaEmbeddings |
Use Jina AI's embedding API. | chonkie[jina] |
voyageai |
VoyageAIEmbeddings |
Use Voyage AI's embedding API. | chonkie[voyageai] |
litellm |
LiteLLMEmbeddings |
Use LiteLLM for 100+ embedding models. | chonkie[litellm] |
🧞♂️ Power Up with Genies! Chonkie supports 5+ LLM providers!
Genies provide interfaces to interact with Large Language Models (LLMs) for advanced chunking strategies or other tasks within the pipeline.
| Genie Name | Class | Description | Optional Install |
|---|---|---|---|
gemini |
GeminiGenie |
Interact with Google Gemini APIs. | chonkie[gemini] |
openai |
OpenAIGenie |
Interact with OpenAI APIs. | chonkie[openai] |
azure-openai |
AzureOpenAIGenie |
Interact with Azure OpenAI APIs. | chonkie[azure-openai] |
groq |
GroqGenie |
Fast inference on Groq hardware. | chonkie[groq] |
cerebras |
CerebrasGenie |
Fastest inference on Cerebras hardware. | chonkie[cerebras] |
You can also use the OpenAIGenie to interact with any LLM provider that supports the OpenAI API format, by simply changing the model, base_url, and api_key parameters. For example, here's how to use the OpenAIGenie to interact with the Llama-4-Maverick model via OpenRouter:
from chonkie import OpenAIGenie
genie = OpenAIGenie(model="meta-llama/llama-4-maverick",
base_url="https://openrouter.ai/api/v1",
api_key="your_api_key")🛠️ Utilities & Helpers! Chonkie includes handy tools!
Additional utilities to enhance your chunking workflow.
| Utility Name | Class | Description | Optional Install |
|---|---|---|---|
hub |
Hubbie |
Simple wrapper for HuggingFace Hub operations. | chonkie[hub] |
viz |
Visualizer |
Rich console visualizations for chunks. | chonkie[viz] |
With Chonkie's wide range of integrations, you can easily plug it into your existing infrastructure and start CHONKING!
"I may be smol hippo, but I pack a big punch!" 🦛
Chonkie is not just cute, it's also fast and efficient! Here's how it stacks up against the competition:
Size📦
- Wheel Size: 505KB (vs 1-12MB for alternatives)
- Installed Size: 49MB (vs 80-171MB for alternatives)
- With Semantic: Still 10x lighter than the closest competition!
Speed⚡
- Token Chunking: 33x faster than the slowest alternative
- Sentence Chunking: Almost 2x faster than competitors
- Semantic Chunking: Up to 2.5x faster than others
Check out our detailed benchmarks to see how Chonkie races past the competition! 🏃♂️💨
Want to help grow Chonkie? Check out CONTRIBUTING.md to get started! Whether you're fixing bugs, adding features, or improving docs, every contribution helps make Chonkie a better CHONK for everyone.
Remember: No contribution is too small for this tiny hippo! 🦛
Chonkie would like to CHONK its way through a special thanks to all the users and contributors who have helped make this library what it is today! Your feedback, issue reports, and improvements have helped make Chonkie the CHONKIEST it can be.
And of course, special thanks to Moto Moto for endorsing Chonkie with his famous quote:
"I like them big, I like them chonkie." ~ Moto Moto
If you use Chonkie in your research, please cite it as follows:
@software{chonkie2025,
author = {Minhas, Bhavnick AND Nigam, Shreyash},
title = {Chonkie: The lightweight ingestion library for fast, efficient and robust RAG pipelines},
year = {2025},
publisher = {GitHub},
howpublished = {\url{https://github.com/chonkie-inc/chonkie}},
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for chonkie
Similar Open Source Tools
chonkie
Chonkie is a feature-rich, easy-to-use, fast, lightweight, and wide-support chunking library designed to efficiently split texts into chunks. It integrates with various tokenizers, embedding models, and APIs, supporting 56 languages and offering cloud-ready functionality. Chonkie provides a modular pipeline approach called CHOMP for text processing, chunking, post-processing, and exporting. With multiple chunkers, refineries, porters, and handshakes, Chonkie offers a comprehensive solution for text chunking needs. It includes 24+ integrations, 3+ LLM providers, 2+ refineries, 2+ porters, and 4+ vector database connections, making it a versatile tool for text processing and analysis.
summarize
The 'summarize' tool is designed to transcribe and summarize videos from various sources using AI models. It helps users efficiently summarize lengthy videos, take notes, and extract key insights by providing timestamps, original transcripts, and support for auto-generated captions. Users can utilize different AI models via Groq, OpenAI, or custom local models to generate grammatically correct video transcripts and extract wisdom from video content. The tool simplifies the process of summarizing video content, making it easier to remember and reference important information.
worker-vllm
The worker-vLLM repository provides a serverless endpoint for deploying OpenAI-compatible vLLM models with blazing-fast performance. It supports deploying various model architectures, such as Aquila, Baichuan, BLOOM, ChatGLM, Command-R, DBRX, DeciLM, Falcon, Gemma, GPT-2, GPT BigCode, GPT-J, GPT-NeoX, InternLM, Jais, LLaMA, MiniCPM, Mistral, Mixtral, MPT, OLMo, OPT, Orion, Phi, Phi-3, Qwen, Qwen2, Qwen2MoE, StableLM, Starcoder2, Xverse, and Yi. Users can deploy models using pre-built Docker images or build custom images with specified arguments. The repository also supports OpenAI compatibility for chat completions, completions, and models, with customizable input parameters. Users can modify their OpenAI codebase to use the deployed vLLM worker and access a list of available models for deployment.
skylos
Skylos is a privacy-first SAST tool for Python, TypeScript, and Go that bridges the gap between traditional static analysis and AI agents. It detects dead code, security vulnerabilities (SQLi, SSRF, Secrets), and code quality issues with high precision. Skylos uses a hybrid engine (AST + optional Local/Cloud LLM) to eliminate false positives, verify via runtime, find logic bugs, and provide context-aware audits. It offers automated fixes, end-to-end remediation, and 100% local privacy. The tool supports taint analysis, secrets detection, vulnerability checks, dead code detection and cleanup, agentic AI and hybrid analysis, codebase optimization, operational governance, and runtime verification.
code-cli
Autohand Code CLI is an autonomous coding agent in CLI form that uses the ReAct pattern to understand, plan, and execute code changes. It is designed for seamless coding experience without context switching or copy-pasting. The tool is fast, intuitive, and extensible with modular skills. It can be used to automate coding tasks, enforce code quality, and speed up development. Autohand can be integrated into team workflows and CI/CD pipelines to enhance productivity and efficiency.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students
agentic
Agentic is a standard AI functions/tools library optimized for TypeScript and LLM-based apps, compatible with major AI SDKs. It offers a set of thoroughly tested AI functions that can be used with favorite AI SDKs without writing glue code. The library includes various clients for services like Bing web search, calculator, Clearbit data resolution, Dexa podcast questions, and more. It also provides compound tools like SearchAndCrawl and supports multiple AI SDKs such as OpenAI, Vercel AI SDK, LangChain, LlamaIndex, Firebase Genkit, and Dexa Dexter. The goal is to create minimal clients with strongly-typed TypeScript DX, composable AIFunctions via AIFunctionSet, and compatibility with major TS AI SDKs.

optillm
optillm is an OpenAI API compatible optimizing inference proxy implementing state-of-the-art techniques to enhance accuracy and performance of LLMs, focusing on reasoning over coding, logical, and mathematical queries. By leveraging additional compute at inference time, it surpasses frontier models across diverse tasks.
roam-code
Roam is a tool that builds a semantic graph of your codebase and allows AI agents to query it with one shell command. It pre-indexes your codebase into a semantic graph stored in a local SQLite DB, providing architecture-level graph queries offline, cross-language, and compact. Roam understands functions, modules, tests coverage, and overall architecture structure. It is best suited for agent-assisted coding, large codebases, architecture governance, safe refactoring, and multi-repo projects. Roam is not suitable for real-time type checking, dynamic/runtime analysis, small scripts, or pure text search. It offers speed, dependency-awareness, LLM-optimized output, fully local operation, and CI readiness.
MetaScreener
MetaScreener is a local Python tool for AI-assisted systematic review workflows. It utilizes a Hierarchical Consensus Network (HCN) of 4 open-source LLMs with calibrated confidence aggregation, covering the full systematic review pipeline including literature screening, data extraction, and risk-of-bias assessment in a single tool. It offers a multi-LLM ensemble, 3 systematic review modules, reproducibility features, framework-agnostic criteria support, multiple input/output formats, interactive mode, CLI and Web UI, evaluation toolkit, and more.
StableToolBench
StableToolBench is a new benchmark developed to address the instability of Tool Learning benchmarks. It aims to balance stability and reality by introducing features like Virtual API System, Solvable Queries, and Stable Evaluation System. The benchmark ensures consistency through a caching system and API simulators, filters queries based on solvability using LLMs, and evaluates model performance using GPT-4 with metrics like Solvable Pass Rate and Solvable Win Rate.
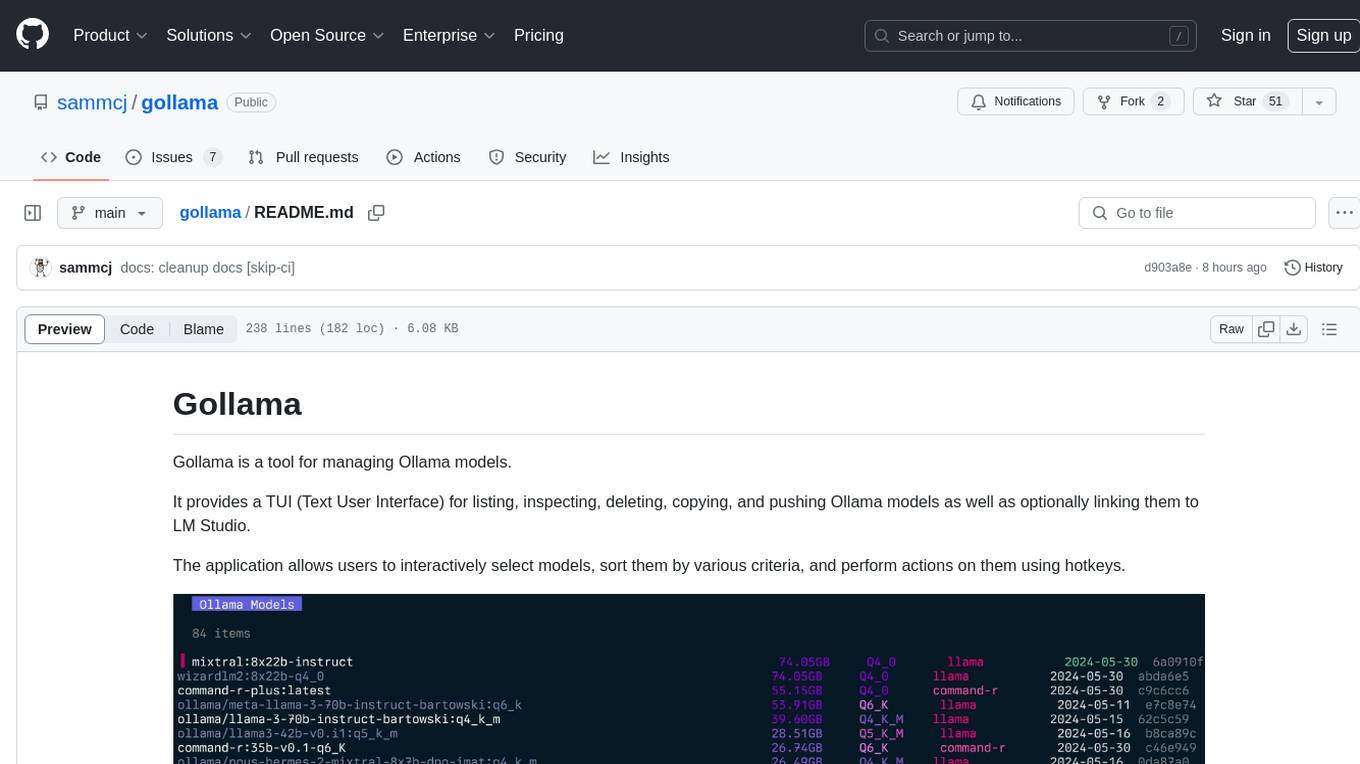
gollama
Gollama is a tool designed for managing Ollama models through a Text User Interface (TUI). Users can list, inspect, delete, copy, and push Ollama models, as well as link them to LM Studio. The application offers interactive model selection, sorting by various criteria, and actions using hotkeys. It provides features like sorting and filtering capabilities, displaying model metadata, model linking, copying, pushing, and more. Gollama aims to be user-friendly and useful for managing models, especially for cleaning up old models.
free-chat
Free Chat is a forked project from chatgpt-demo that allows users to deploy a chat application with various features. It provides branches for different functionalities like token-based message list trimming and usage demonstration of 'promplate'. Users can control the website through environment variables, including setting OpenAI API key, temperature parameter, proxy, base URL, and more. The project welcomes contributions and acknowledges supporters. It is licensed under MIT by Muspi Merol.

StableToolBench
StableToolBench is a new benchmark developed to address the instability of Tool Learning benchmarks. It aims to balance stability and reality by introducing features such as a Virtual API System with caching and API simulators, a new set of solvable queries determined by LLMs, and a Stable Evaluation System using GPT-4. The Virtual API Server can be set up either by building from source or using a prebuilt Docker image. Users can test the server using provided scripts and evaluate models with Solvable Pass Rate and Solvable Win Rate metrics. The tool also includes model experiments results comparing different models' performance.
pup
Pup is a CLI tool designed to give AI agents access to Datadog's observability platform. It offers over 200 commands across 33 Datadog products, allowing agents to fetch metrics, identify errors, and track issues efficiently. Pup ensures that AI agents have the necessary tooling to perform tasks seamlessly, making Datadog the preferred choice for AI-native workflows. With features like self-discoverable commands, structured JSON/YAML output, OAuth2 + PKCE for secure access, and comprehensive API coverage, Pup empowers AI agents to monitor, log, analyze metrics, and enhance security effortlessly.
DownEdit
DownEdit is a fast and powerful program for downloading and editing videos from top platforms like TikTok, Douyin, and Kuaishou. Effortlessly grab videos from user profiles, make bulk edits throughout the entire directory with just one click. Advanced Chat & AI features let you download, edit, and generate videos, images, and sounds in bulk. Exciting new features are coming soon—stay tuned!
For similar tasks

phospho
Phospho is a text analytics platform for LLM apps. It helps you detect issues and extract insights from text messages of your users or your app. You can gather user feedback, measure success, and iterate on your app to create the best conversational experience for your users.

OpenFactVerification
Loki is an open-source tool designed to automate the process of verifying the factuality of information. It provides a comprehensive pipeline for dissecting long texts into individual claims, assessing their worthiness for verification, generating queries for evidence search, crawling for evidence, and ultimately verifying the claims. This tool is especially useful for journalists, researchers, and anyone interested in the factuality of information.

open-parse
Open Parse is a Python library for visually discerning document layouts and chunking them effectively. It is designed to fill the gap in open-source libraries for handling complex documents. Unlike text splitting, which converts a file to raw text and slices it up, Open Parse visually analyzes documents for superior LLM input. It also supports basic markdown for parsing headings, bold, and italics, and has high-precision table support, extracting tables into clean Markdown formats with accuracy that surpasses traditional tools. Open Parse is extensible, allowing users to easily implement their own post-processing steps. It is also intuitive, with great editor support and completion everywhere, making it easy to use and learn.

spaCy
spaCy is an industrial-strength Natural Language Processing (NLP) library in Python and Cython. It incorporates the latest research and is designed for real-world applications. The library offers pretrained pipelines supporting 70+ languages, with advanced neural network models for tasks such as tagging, parsing, named entity recognition, and text classification. It also facilitates multi-task learning with pretrained transformers like BERT, along with a production-ready training system and streamlined model packaging, deployment, and workflow management. spaCy is commercial open-source software released under the MIT license.

NanoLLM
NanoLLM is a tool designed for optimized local inference for Large Language Models (LLMs) using HuggingFace-like APIs. It supports quantization, vision/language models, multimodal agents, speech, vector DB, and RAG. The tool aims to provide efficient and effective processing for LLMs on local devices, enhancing performance and usability for various AI applications.

ontogpt
OntoGPT is a Python package for extracting structured information from text using large language models, instruction prompts, and ontology-based grounding. It provides a command line interface and a minimal web app for easy usage. The tool has been evaluated on test data and is used in related projects like TALISMAN for gene set analysis. OntoGPT enables users to extract information from text by specifying relevant terms and provides the extracted objects as output.

lima
LIMA is a multilingual linguistic analyzer developed by the CEA LIST, LASTI laboratory. It is Free Software available under the MIT license. LIMA has state-of-the-art performance for more than 60 languages using deep learning modules. It also includes a powerful rules-based mechanism called ModEx for extracting information in new domains without annotated data.

liboai
liboai is a simple C++17 library for the OpenAI API, providing developers with access to OpenAI endpoints through a collection of methods and classes. It serves as a spiritual port of OpenAI's Python library, 'openai', with similar structure and features. The library supports various functionalities such as ChatGPT, Audio, Azure, Functions, Image DALL·E, Models, Completions, Edit, Embeddings, Files, Fine-tunes, Moderation, and Asynchronous Support. Users can easily integrate the library into their C++ projects to interact with OpenAI services.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.
BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.