
llm-oss-landscape
Open Source Landscapes and Insights Produced by AntOSS
Stars: 195
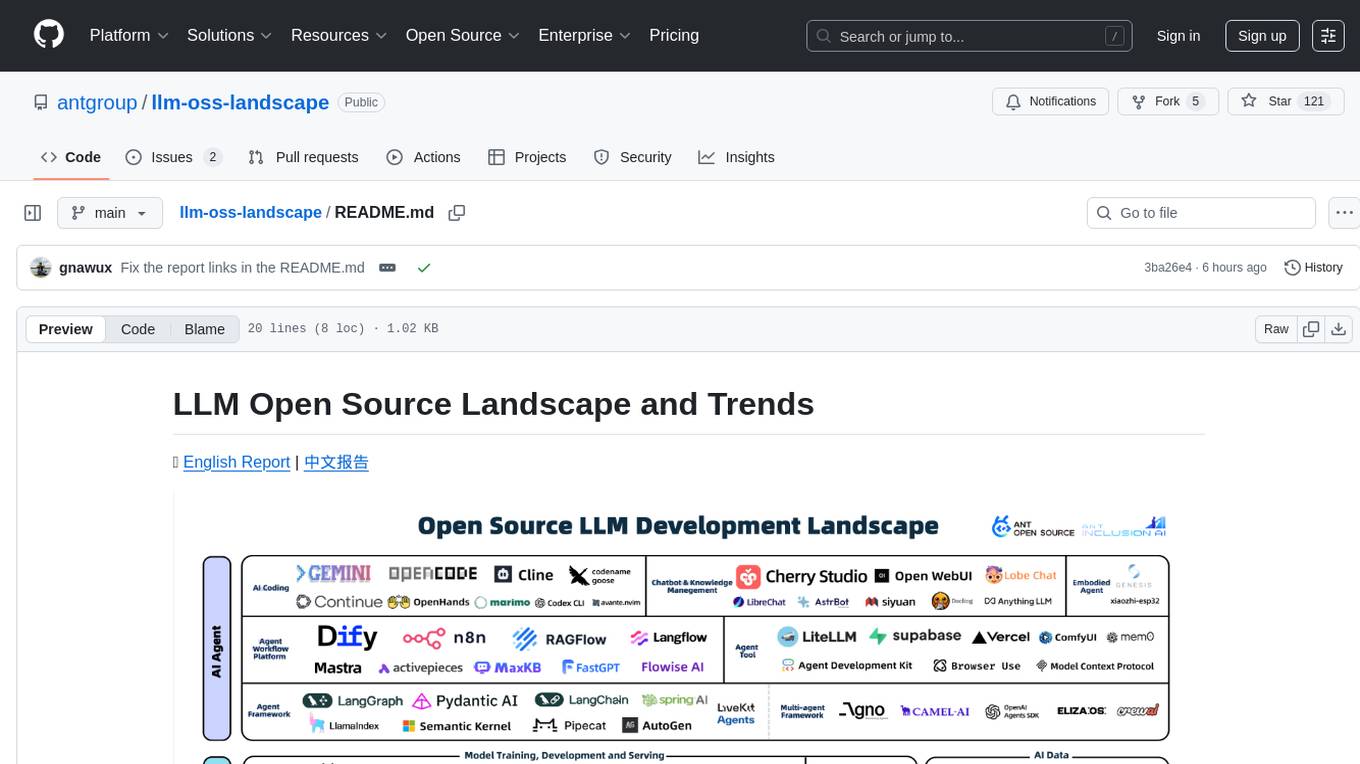
The LLM Open Source Landscape and Trends project aims to provide insights into the rapidly evolving open source ecosystem, highlighting current trends and notable projects. The project is dedicated to maintaining and sharing new insights, fostering open collaboration with the community. Contributions of high-quality insights, data stories, and use cases are encouraged through PR submissions to the `data-stories` folder.
README:
Report 1.0 🌐️ English Report | 中文报告
Report 2.0 🌐️ English Report | 中文报告

Online Interactive Version: https://antoss-landscape.my.canva.site
We utilize OpenRank to assess community engagement and project vitality. Our current selection criteria requires projects to achieve an OpenRank score of at least 50 for the most recent month.
To explore OpenRank trends for any GitHub repository, install the HyperCRX browser extension.
As Ant Group's Open Source Team, our mission is to decode the evolution of the large language model development ecosystem through comprehensive community data analysis. We seek to identify emerging trends and understand which leading projects are driving innovation in this rapidly evolving space.
Our panoramic analysis and trend research aims to harness insights from the open-source community to inform and guide the strategic evolution of Ant's technological architecture and development practices.
We are dedicated to maintaining this initiative continuously, releasing fresh insights regularly, and fostering collaborative growth with the broader community through open participation.
We welcome contributions of high-quality insights, compelling data stories, and innovative use cases. Please submit your contributions via pull requests to the data_stories directory.
If you notice any projects missing from our landscape analysis, we encourage you to share your feedback through our dedicated issue tracker.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llm-oss-landscape
Similar Open Source Tools
llm-oss-landscape
The LLM Open Source Landscape and Trends project aims to provide insights into the rapidly evolving open source ecosystem, highlighting current trends and notable projects. The project is dedicated to maintaining and sharing new insights, fostering open collaboration with the community. Contributions of high-quality insights, data stories, and use cases are encouraged through PR submissions to the `data-stories` folder.
open-deep-research
Open Deep Research is a comprehensive repository that provides resources, tools, and information for deep learning research. It includes datasets, pre-trained models, code implementations, research papers, and tutorials to support researchers and developers in the field of deep learning. The repository aims to facilitate collaboration, knowledge sharing, and innovation in the deep learning community.

God-Level-AI
A drill of scientific methods, processes, algorithms, and systems to build stories & models. An in-depth learning resource for humans. This repository is designed for individuals aiming to excel in the field of Data and AI, providing video sessions and text content for learning. It caters to those in leadership positions, professionals, and students, emphasizing the need for dedicated effort to achieve excellence in the tech field. The content covers various topics with a focus on practical application.
aishare
Aishare is a collaborative platform for sharing AI models and datasets. It allows users to upload, download, and explore various AI models and datasets. Users can also rate and comment on the shared resources, providing valuable feedback to the community. Aishare aims to foster collaboration and knowledge sharing in the field of artificial intelligence.
context-portal
Context-portal is a versatile tool for managing and visualizing data in a collaborative environment. It provides a user-friendly interface for organizing and sharing information, making it easy for teams to work together on projects. With features such as customizable dashboards, real-time updates, and seamless integration with popular data sources, Context-portal streamlines the data management process and enhances productivity. Whether you are a data analyst, project manager, or team leader, Context-portal offers a comprehensive solution for optimizing workflows and driving better decision-making.
PurpleLlama
Purple Llama is an umbrella project that aims to provide tools and evaluations to support responsible development and usage of generative AI models. It encompasses components for cybersecurity and input/output safeguards, with plans to expand in the future. The project emphasizes a collaborative approach, borrowing the concept of purple teaming from cybersecurity, to address potential risks and challenges posed by generative AI. Components within Purple Llama are licensed permissively to foster community collaboration and standardize the development of trust and safety tools for generative AI.
LLMs-in-Finance
This repository focuses on the application of Large Language Models (LLMs) in the field of finance. It provides insights and knowledge about how LLMs can be utilized in various scenarios within the finance industry, particularly in generating AI agents. The repository aims to explore the potential of LLMs to enhance financial processes and decision-making through the use of advanced natural language processing techniques.
awesome-LLM-resources
This repository is a curated list of resources for learning and working with Large Language Models (LLMs). It includes a collection of articles, tutorials, tools, datasets, and research papers related to LLMs such as GPT-3, BERT, and Transformer models. Whether you are a researcher, developer, or enthusiast interested in natural language processing and artificial intelligence, this repository provides valuable resources to help you understand, implement, and experiment with LLMs.
CrossIntelligence
CrossIntelligence is a powerful tool for data analysis and visualization. It allows users to easily connect and analyze data from multiple sources, providing valuable insights and trends. With a user-friendly interface and customizable features, CrossIntelligence is suitable for both beginners and advanced users in various industries such as marketing, finance, and research.
ai-collection
The ai-collection repository is a collection of various artificial intelligence projects and tools aimed at helping developers and researchers in the field of AI. It includes implementations of popular AI algorithms, datasets for training machine learning models, and resources for learning AI concepts. The repository serves as a valuable resource for anyone interested in exploring the applications of artificial intelligence in different domains.
GenAiGuidebook
GenAiGuidebook is a comprehensive resource for individuals looking to begin their journey in GenAI. It serves as a detailed guide providing insights, tips, and information on various aspects of GenAI technology. The guidebook covers a wide range of topics, including introductory concepts, practical applications, and best practices in the field of GenAI. Whether you are a beginner or an experienced professional, this resource aims to enhance your understanding and proficiency in GenAI.
emerging-trajectories
Emerging Trajectories is an open source library for tracking and saving forecasts of political, economic, and social events. It provides a way to organize and store forecasts, as well as track their accuracy over time. This can be useful for researchers, analysts, and anyone else who wants to keep track of their predictions.
Awesome-LLM-Safety
Welcome to our Awesome-llm-safety repository! We've curated a collection of the latest, most comprehensive, and most valuable resources on large language model safety (llm-safety). But we don't stop there; included are also relevant talks, tutorials, conferences, news, and articles. Our repository is constantly updated to ensure you have the most current information at your fingertips.
cs-self-learning
This repository serves as an archive for computer science learning notes, codes, and materials. It covers a wide range of topics including basic knowledge, AI, backend & big data, tools, and other related areas. The content is organized into sections and subsections for easy navigation and reference. Users can find learning resources, programming practices, and tutorials on various subjects such as languages, data structures & algorithms, AI, frameworks, databases, development tools, and more. The repository aims to support self-learning and skill development in the field of computer science.
RAG-To-Know
RAG-To-Know is a versatile tool for knowledge extraction and summarization. It leverages the RAG (Retrieval-Augmented Generation) framework to provide a seamless way to retrieve and summarize information from various sources. With RAG-To-Know, users can easily extract key insights and generate concise summaries from large volumes of text data. The tool is designed to streamline the process of information retrieval and summarization, making it ideal for researchers, students, journalists, and anyone looking to quickly grasp the essence of complex information.

open-webui-tools
Open WebUI Tools Collection is a set of tools for structured planning, arXiv paper search, Hugging Face text-to-image generation, prompt enhancement, and multi-model conversations. It enhances LLM interactions with academic research, image generation, and conversation management. Tools include arXiv Search Tool and Hugging Face Image Generator. Function Pipes like Planner Agent offer autonomous plan generation and execution. Filters like Prompt Enhancer improve prompt quality. Installation and configuration instructions are provided for each tool and pipe.
For similar tasks

Awesome-Segment-Anything
Awesome-Segment-Anything is a powerful tool for segmenting and extracting information from various types of data. It provides a user-friendly interface to easily define segmentation rules and apply them to text, images, and other data formats. The tool supports both supervised and unsupervised segmentation methods, allowing users to customize the segmentation process based on their specific needs. With its versatile functionality and intuitive design, Awesome-Segment-Anything is ideal for data analysts, researchers, content creators, and anyone looking to efficiently extract valuable insights from complex datasets.

Time-LLM
Time-LLM is a reprogramming framework that repurposes large language models (LLMs) for time series forecasting. It allows users to treat time series analysis as a 'language task' and effectively leverage pre-trained LLMs for forecasting. The framework involves reprogramming time series data into text representations and providing declarative prompts to guide the LLM reasoning process. Time-LLM supports various backbone models such as Llama-7B, GPT-2, and BERT, offering flexibility in model selection. The tool provides a general framework for repurposing language models for time series forecasting tasks.

crewAI
CrewAI is a cutting-edge framework designed to orchestrate role-playing autonomous AI agents. By fostering collaborative intelligence, CrewAI empowers agents to work together seamlessly, tackling complex tasks. It enables AI agents to assume roles, share goals, and operate in a cohesive unit, much like a well-oiled crew. Whether you're building a smart assistant platform, an automated customer service ensemble, or a multi-agent research team, CrewAI provides the backbone for sophisticated multi-agent interactions. With features like role-based agent design, autonomous inter-agent delegation, flexible task management, and support for various LLMs, CrewAI offers a dynamic and adaptable solution for both development and production workflows.
Transformers_And_LLM_Are_What_You_Dont_Need
Transformers_And_LLM_Are_What_You_Dont_Need is a repository that explores the limitations of transformers in time series forecasting. It contains a collection of papers, articles, and theses discussing the effectiveness of transformers and LLMs in this domain. The repository aims to provide insights into why transformers may not be the best choice for time series forecasting tasks.

pytorch-forecasting
PyTorch Forecasting is a PyTorch-based package for time series forecasting with state-of-the-art network architectures. It offers a high-level API for training networks on pandas data frames and utilizes PyTorch Lightning for scalable training on GPUs and CPUs. The package aims to simplify time series forecasting with neural networks by providing a flexible API for professionals and default settings for beginners. It includes a timeseries dataset class, base model class, multiple neural network architectures, multi-horizon timeseries metrics, and hyperparameter tuning with optuna. PyTorch Forecasting is built on pytorch-lightning for easy training on various hardware configurations.
spider
Spider is a high-performance web crawler and indexer designed to handle data curation workloads efficiently. It offers features such as concurrency, streaming, decentralization, headless Chrome rendering, HTTP proxies, cron jobs, subscriptions, smart mode, blacklisting, whitelisting, budgeting depth, dynamic AI prompt scripting, CSS scraping, and more. Users can easily get started with the Spider Cloud hosted service or set up local installations with spider-cli. The tool supports integration with Node.js and Python for additional flexibility. With a focus on speed and scalability, Spider is ideal for extracting and organizing data from the web.
AI_for_Science_paper_collection
AI for Science paper collection is an initiative by AI for Science Community to collect and categorize papers in AI for Science areas by subjects, years, venues, and keywords. The repository contains `.csv` files with paper lists labeled by keys such as `Title`, `Conference`, `Type`, `Application`, `MLTech`, `OpenReviewLink`. It covers top conferences like ICML, NeurIPS, and ICLR. Volunteers can contribute by updating existing `.csv` files or adding new ones for uncovered conferences/years. The initiative aims to track the increasing trend of AI for Science papers and analyze trends in different applications.

pytorch-forecasting
PyTorch Forecasting is a PyTorch-based package designed for state-of-the-art timeseries forecasting using deep learning architectures. It offers a high-level API and leverages PyTorch Lightning for efficient training on GPU or CPU with automatic logging. The package aims to simplify timeseries forecasting tasks by providing a flexible API for professionals and user-friendly defaults for beginners. It includes features such as a timeseries dataset class for handling data transformations, missing values, and subsampling, various neural network architectures optimized for real-world deployment, multi-horizon timeseries metrics, and hyperparameter tuning with optuna. Built on pytorch-lightning, it supports training on CPUs, single GPUs, and multiple GPUs out-of-the-box.
For similar jobs

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.