
VideoCaptioner
🎬 卡卡字幕助手 | VideoCaptioner - 基于 LLM 的智能字幕助手 - 视频字幕生成、断句、校正、字幕翻译全流程处理!- A powered tool for easy and efficient video subtitling.
Stars: 4908
VideoCaptioner is a video subtitle processing assistant based on a large language model (LLM), supporting speech recognition, subtitle segmentation, optimization, translation, and full-process handling. It is user-friendly and does not require high configuration, supporting both network calls and local offline (GPU-enabled) speech recognition. It utilizes a large language model for intelligent subtitle segmentation, correction, and translation, providing stunning subtitles for videos. The tool offers features such as accurate subtitle generation without GPU, intelligent segmentation and sentence splitting based on LLM, AI subtitle optimization and translation, batch video subtitle synthesis, intuitive subtitle editing interface with real-time preview and quick editing, and low model token consumption with built-in basic LLM model for easy use.
README:
卡卡字幕助手(VideoCaptioner)操作简单且无需高配置,支持网络调用和本地离线(支持调用GPU)两种方式进行语音识别,利用可用通过大语言模型进行字幕智能断句、校正、翻译,字幕视频全流程一键处理!为视频配上效果惊艳的字幕。
最新版本已经支持 VAD 、 人声分离、 字级时间戳 批量字幕等实用功能
- 🎯 无需GPU即可使用强大的语音识别引擎,生成精准字幕
- ✂️ 基于 LLM 的智能分割与断句,字幕阅读更自然流畅
- 🔄 AI字幕多线程优化与翻译,调整字幕格式、表达更地道专业
- 🎬 支持批量视频字幕合成,提升处理效率
- 📝 直观的字幕编辑查看界面,支持实时预览和快捷编辑
- 🤖 消耗模型 Token 少,且内置基础 LLM 模型,保证开箱即用

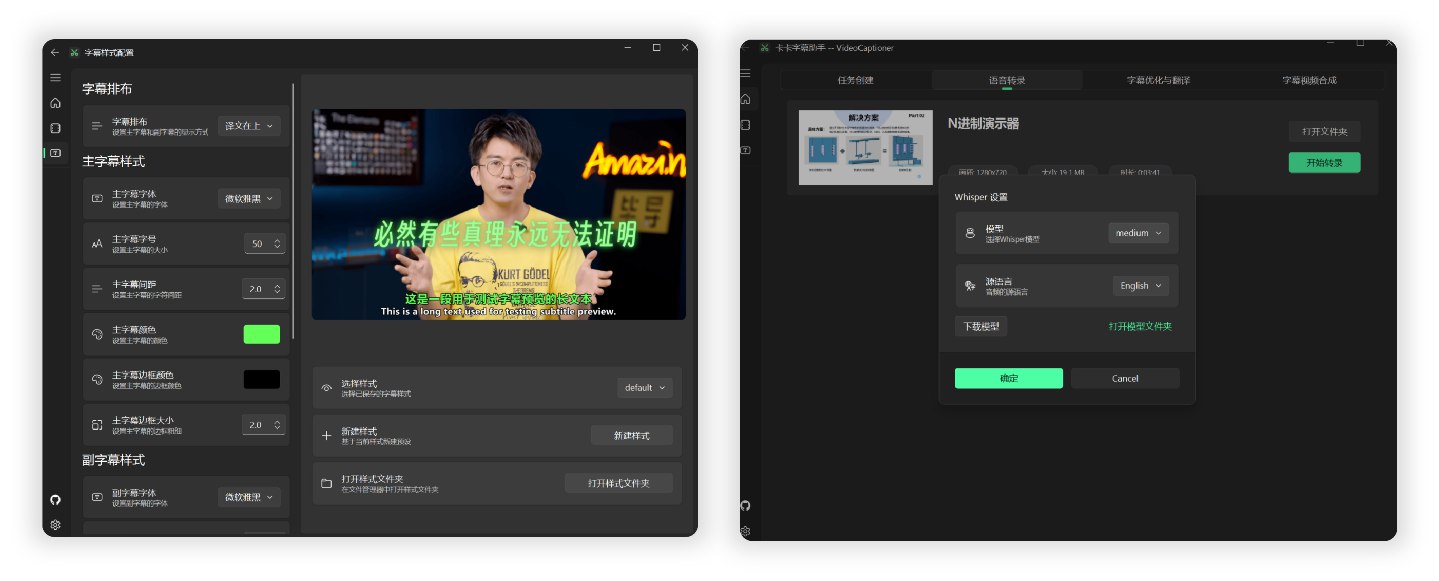
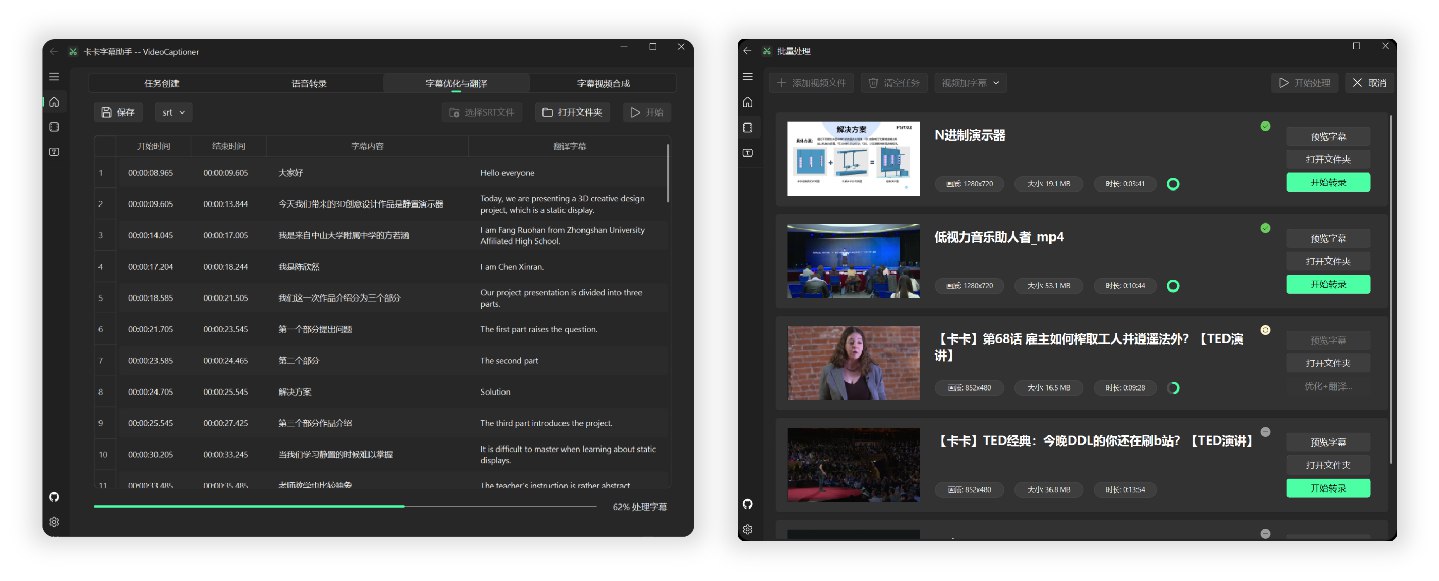
全流程处理一个14分钟1080P的 B站英文 TED 视频,调用本地 Whisper 模型进行语音识别,使用 gpt-4o-mini 模型优化和翻译为中文,总共消耗时间约 4 分钟。
近后台计算,模型优化和翻译消耗费用不足 ¥0.01(以OpenAI官方价格为计算)
具体字幕和视频合成的效果的测试结果图片,请参考 TED视频测试
软件较为轻量,打包大小不足 60M,已集成所有必要环境,下载后可直接运行。
-
打开安装包进行安装
-
LLM API 配置,(用于字幕断句、校正),可使用 ✨本项目的中转站
-
翻译配置,选择是否启用翻译,翻译服务(默认使用微软翻译,质量一般,推荐使用大模型翻译)
-
语音识别配置(默认使用B接口,中英以外的语言请使用本地转录)
-
拖拽视频文件到软件窗口,即可全自动处理
提示:每一个步骤均支持单独处理,均支持文件拖拽。软件具体模型选择和参数配置说明,请查看下文。
MacOS 用户
由于本人缺少 Mac,所以没法测试和打包,暂无法提供 MacOS 的可执行程序。
Mac 用户请自行使用下载源码和安装 python 依赖运行。(本地 Whisper 功能暂不支持 MacOS)
- 安装 ffmpeg 和 Aria2 下载工具
brew install ffmpeg
brew install aria2
brew install python@3.**- 克隆项目
git clone https://github.com/WEIFENG2333/VideoCaptioner.git
cd VideoCaptioner- 安装依赖
python3.** -m venv venv
source venv/bin/activate
pip install -r requirements.txt- 运行程序
python main.pyDocker 部署(beta)
目前本项目streamlit应用因为项目重构过,Docker不可以使用。欢迎各位PR贡献新代码。
git clone https://github.com/WEIFENG2333/VideoCaptioner.git
cd VideoCaptioner
docker build -t video-captioner .使用自定义API配置运行:
docker run -d \
-p 8501:8501 \
-v $(pwd)/temp:/app/temp \
-e OPENAI_BASE_URL="你的API地址" \
-e OPENAI_API_KEY="你的API密钥" \
--name video-captioner \
video-captioner打开浏览器访问:http://localhost:8501
- 容器内已预装ffmpeg等必要依赖
- 如需使用其他模型,请通过环境变量配置
LLM 大模型是用来字幕段句、字幕优化、以及字幕翻译(如果选择了LLM 大模型翻译)。
| 配置项 | 说明 |
|---|---|
| SiliconCloud |
SiliconCloud 官网配置方法请参考配置文档 该并发较低,建议把线程设置为5以下。 |
| DeepSeek |
DeepSeek 官网,建议使用 deepseek-v3 模型,官方网站最近服务好像并不太稳定。 |
| Ollama本地 | Ollama 官网 |
| 内置公益模型 | 内置基础大语言模型(gpt-4o-mini)(公益服务不稳定,强烈建议请使用自己的模型API) |
| OpenAI兼容接口 | 如果有其他服务商的API,可直接在软件中填写。base_url 和api_key |
注:如果用的 API 服务商不支持高并发,请在软件设置中将“线程数”调低,避免请求错误。
如果希望高并发⚡️,或者希望在在软件内使用使用 OpenAI 或者 Claude 等优质大模型进行字幕校正和翻译。
可使用本项目的✨LLM API中转站✨: https://api.videocaptioner.cn
其支持高并发,性价比极高,且有国内外大量模型可挑选。
注册获取key之后,设置中按照下面配置:
BaseURL: https://api.videocaptioner.cn/v1
API-key: 个人中心-API 令牌页面自行获取。
💡 模型选择建议 (本人在各质量层级中精选出的高性价比模型):
-
高质量之选:
claude-3-5-sonnet-20241022(耗费比例:3) -
较高质量之选:
gemini-2.0-flash、deepseek-chat(耗费比例:1) -
中质量之选:
gpt-4o-mini、gemini-1.5-flash(耗费比例:0.15)
本站支持超高并发,软件中线程数直接拉满即可~ 处理速度非常快~
更详细的API配置教程:中转站配置配置
| 配置项 | 说明 |
|---|---|
| LLM 大模型翻译 | 🌟 翻译质量最好的选择。使用 AI 大模型进行翻译,能更好理解上下文,翻译更自然。需要在设置中配置 LLM API(比如 OpenAI、DeepSeek 等) |
| DeepLx 翻译 | 翻译较可靠。基于 DeepL 翻译, 需要要配置自己的后端接口。 |
| 微软翻译 | 使用微软的翻译服务, 速度非常快 |
| 谷歌翻译 | 谷歌的翻译服务,速度快,但需要能访问谷歌的网络环境 |
推荐使用 LLM 大模型翻译 ,翻译质量最好。
| 接口名称 | 支持语言 | 运行方式 | 说明 |
|---|---|---|---|
| B接口 | 仅支持中文、英文 | 在线 | 免费、速度较快 |
| J接口 | 仅支持中文、英文 | 在线 | 免费、速度较快 |
| WhisperCpp | 中文、日语、韩语、英文等 99 种语言,外语效果较好 | 本地 | (实际使用不稳定)需要下载转录模型 中文建议medium以上模型 英文等使用较小模型即可达到不错效果。 |
| fasterWhisper 👍 | 中文、英文等多99种语言,外语效果优秀,时间轴更准确 | 本地 | (🌟极力推荐🌟)需要下载程序和转录模型 支持CUDA,速度更快,转录准确。 超级准确的时间戳字幕。 建议优先使用 |
Whisper 版本有 WhisperCpp 和 fasterWhisper(推荐) 两种,后者效果更好,都需要自行在软件内下载模型。
| 模型 | 磁盘空间 | 内存占用 | 说明 |
|---|---|---|---|
| Tiny | 75 MiB | ~273 MB | 转录很一般,仅用于测试 |
| Small | 466 MiB | ~852 MB | 英文识别效果已经不错 |
| Medium | 1.5 GiB | ~2.1 GB | 中文识别建议至少使用此版本 |
| Large-v2 👍 | 2.9 GiB | ~3.9 GB | 效果好,配置允许情况推荐使用 |
| Large-v3 | 2.9 GiB | ~3.9 GB | 社区反馈可能会出现幻觉/字幕重复问题 |
推荐模型: Large-v2 稳定且质量较好。
注:以上模型国内网络可直接在软件内下载。
- 在"字幕优化与翻译"页面,包含"文稿匹配"选项,支持以下一种或者多种内容,辅助校正字幕和翻译:
| 类型 | 说明 | 填写示例 |
|---|---|---|
| 术语表 | 专业术语、人名、特定词语的修正对照表 | 机器学习->Machine Learning 马斯克->Elon Musk 打call -> 应援 图灵斑图 公交车悖论 |
| 原字幕文稿 | 视频的原有文稿或相关内容 | 完整的演讲稿、课程讲义等 |
| 修正要求 | 内容相关的具体修正要求 | 统一人称代词、规范专业术语等 填写内容相关的要求即可,示例参考 |
- 如果需要文稿进行字幕优化辅助,全流程处理时,先填写文稿信息,再进行开始任务处理
- 注意: 使用上下文参数量不高的小型LLM模型时,建议控制文稿内容在1千字内,如果使用上下文较大的模型,则可以适当增加文稿内容。
无特殊需求,一般不填写。
如果使用URL下载功能时,如果遇到以下情况:
- 下载视频网站需要登录信息才可以下载;
- 只能下载较低分辨率的视频;
- 网络条件较差时需要验证;
- 请参考 Cookie 配置说明 获取Cookie信息,并将cookies.txt文件放置到软件安装目录的
AppData目录下,即可正常下载高质量视频。
程序简单的处理流程如下:
语音识别转录 -> 字幕断句(可选) -> 字幕优化翻译(可选) -> 字幕视频合成
软件利用大语言模型(LLM)在理解上下文方面的优势,对语音识别生成的字幕进一步处理。有效修正错别字、统一专业术语,让字幕内容更加准确连贯,为用户带来出色的观看体验!
- 支持国内外主流视频平台(B站、Youtube、小红书、TikTok、X、西瓜视频、抖音等)
- 自动提取视频原有字幕处理
- 提供多种接口在线识别,效果媲美剪映(免费、高速)
- 支持本地Whisper模型(保护隐私、可离线)
- 自动优化专业术语、代码片段和数学公式格式
- 上下文进行断句优化,提升阅读体验
- 支持文稿提示,使用原有文稿或者相关提示优化字幕断句
- 结合上下文的智能翻译,确保译文兼顾全文
- 通过Prompt指导大模型反思翻译,提升翻译质量
- 使用序列模糊匹配算法、保证时间轴完全一致
- 丰富的字幕样式模板(科普风、新闻风、番剧风等等)
- 多种格式字幕视频(SRT、ASS、VTT、TXT)
针对小白用户,对一些软件内的选项说明:
-
VAD过滤:开启后,VAD(语音活动检测)将过滤无人声的语音片段,从而减少幻觉现象。建议保持默认开启状态。如果不懂,其他VAD选项建议直接保持默认即可。 -
音频分离:开启后,使用MDX-Net进行降噪处理,能够有效分离人声和背景音乐,从而提升音频质量。建议只在嘈杂的视频中开启。
-
智能断句:开启后,全流程处理时生成字级时间戳,然后通过LLM大模型进行断句,从而在视频有更完美的观看体验。有按照句子断句和按照语义断句两种模式。可根据自己的需求配置。 -
字幕校正:开启后,会通过LLM大模型对字幕内容进行校正(如:英文单词大小写、标点符号、错别字、数学公式和代码的格式等),提升字幕的质量。 -
反思翻译:开启后,会通过LLM大模型进行反思翻译,提升翻译的质量。相应的会增加请求的时间和消耗的Token。(选项在 设置页-LLM大模型翻译-反思翻译 中开启。) -
文稿提示:填写后,这部分也将作为提示词发送给大模型,辅助字幕优化和翻译。
-
视频合成:开启后,会根据合成字幕视频;关闭将跳过视频合成的流程。 -
软字幕:开启后,字幕不会烧录到视频中,处理速度极快。但是软字幕需要一些播放器(如PotPlayer)支持才可以进行显示播放。而且软字幕的样式不是软件内调整的字幕样式,而是播放器默认的白色样式。
安装软件的主要目录结构说明如下:
VideoCaptioner/
├── runtime/ # 运行环境目录
├── resources/ # 软件资源文件目录(二进制程序、图标等,以及下载的faster-whisper程序)
├── work-dir/ # 工作目录,处理完成的视频和字幕文件保存在这里
├── AppData/ # 应用数据目录
├── cache/ # 缓存目录,缓存转录、大模型请求的数据。
├── models/ # 存放 Whisper 模型文件
├── logs/ # 日志目录,记录软件运行状态
├── settings.json # 存储用户设置
└── cookies.txt # 视频平台的 cookie 信息(下载高清视频时需要)
└── VideoCaptioner.exe # 主程序执行文件
-
字幕断句的质量对观看体验至关重要。软件能将逐字字幕智能重组为符合自然语言习惯的段落,并与视频画面完美同步。
-
在处理过程中,仅向大语言模型发送文本内容,不包含时间轴信息,这大大降低了处理开销。
-
在翻译环节,我们采用吴恩达提出的"翻译-反思-翻译"方法论。这种迭代优化的方式确保了翻译的准确性。
-
填入 YouTube 链接时进行处理时,会自动下载视频的字幕,从而省去转录步骤,极大地节省操作时间。
作者是一名大三学生,个人能力和项目都还有许多不足,项目也在不断完善中,如果在使用过程遇到的Bug,欢迎提交 Issue 和 Pull Request 帮助改进项目。
2025.02.07
### Bug 修复与其他改进 - 修复谷歌翻译语言不正确的问题。 - 修部微软翻译不准确的问题。 - 修复运行设备不选择cuda时显示报 winError的错误 - 修复合成失败的问题 - 修复ass单语字幕没有内容的问题2024.2.06
- 完整重构代码架构,优化整体性能
- 字幕优化与翻译功能模块分离,提供更灵活的处理选项
- 新增批量处理功能:支持批量字幕、批量转录、批量字幕视频合成
- 全面优化 UI 界面与交互细节
- 扩展 LLM 支持:新增 SiliconCloud、DeepSeek、Ollama、Gemini、ChatGLM 等模型
- 集成多种翻译服务:DeepLx、Bing、Google、LLM
- 新增 faster-whisper-large-v3-turbo 模型支持
- 新增多种 VAD(语音活动检测)方法
- 支持自定义反思翻译开关
- 字幕断句支持语义/句子两种模式
- 字幕断句、优化、翻译提示词的优化
- 字幕、转录缓存机制的优化
- 优化中文字幕自动换行功能
- 新增竖屏字幕样式
- 改进字幕时间轴切换机制,消除闪烁问题
- 修复 Whisper API 无法使用问题
- 新增多种字幕视频格式支持
- 修复部分情况转录错误的问题
- 优化视频工作目录结构
- 新增日志查看功能
- 新增泰语、德语等语言的字幕优化
- 修复诸多Bug...
2024.12.07
- 新增 Faster-whisper 支持,音频转字幕质量更优
- 支持Vad语音断点检测,大大减少幻觉现象
- 支持人声音分离,分离视频背景噪音
- 支持关闭视频合成
- 新增字幕最大长度设置
- 新增字幕末尾标点去除设置
- 优化和翻译的提示词优化
- 优化LLM字幕断句错误的情况
- 修复音频转换格式不一致问题
2024.11.23
- 新增 Whisper-v3 模型支持,大幅提升语音识别准确率
- 优化字幕断句算法,提供更自然的阅读体验
- 修复检测模型可用性时的稳定性问题
2024.11.20
- 支持自定义调节字幕位置和样式
- 新增字幕优化和翻译过程的实时日志查看
- 修复使用 API 时的自动翻译问题
- 优化视频工作目录结构,提升文件管理效率
2024.11.17
- 支持双语/单语字幕灵活导出
- 新增文稿匹配提示对齐功能
- 修复字幕导入时的稳定性问题
- 修复非中文路径下载模型的兼容性问题
2024.11.13
- 新增 Whisper API 调用支持
- 支持导入 cookie.txt 下载各大视频平台资源
- 字幕文件名自动与视频保持一致
- 软件主页新增运行日志实时查看
- 统一和完善软件内部功能
如果觉得项目对你有帮助,可以给项目点个Star,这将是对我最大的鼓励和支持!
捐助支持


For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for VideoCaptioner
Similar Open Source Tools
VideoCaptioner
VideoCaptioner is a video subtitle processing assistant based on a large language model (LLM), supporting speech recognition, subtitle segmentation, optimization, translation, and full-process handling. It is user-friendly and does not require high configuration, supporting both network calls and local offline (GPU-enabled) speech recognition. It utilizes a large language model for intelligent subtitle segmentation, correction, and translation, providing stunning subtitles for videos. The tool offers features such as accurate subtitle generation without GPU, intelligent segmentation and sentence splitting based on LLM, AI subtitle optimization and translation, batch video subtitle synthesis, intuitive subtitle editing interface with real-time preview and quick editing, and low model token consumption with built-in basic LLM model for easy use.
ChatTTS-Forge
ChatTTS-Forge is a powerful text-to-speech generation tool that supports generating rich audio long texts using a SSML-like syntax and provides comprehensive API services, suitable for various scenarios. It offers features such as batch generation, support for generating super long texts, style prompt injection, full API services, user-friendly debugging GUI, OpenAI-style API, Google-style API, support for SSML-like syntax, speaker management, style management, independent refine API, text normalization optimized for ChatTTS, and automatic detection and processing of markdown format text. The tool can be experienced and deployed online through HuggingFace Spaces, launched with one click on Colab, deployed using containers, or locally deployed after cloning the project, preparing models, and installing necessary dependencies.
WeClone
WeClone is a tool that fine-tunes large language models using WeChat chat records. It utilizes approximately 20,000 integrated and effective data points, resulting in somewhat satisfactory outcomes that are occasionally humorous. The tool's effectiveness largely depends on the quantity and quality of the chat data provided. It requires a minimum of 16GB of GPU memory for training using the default chatglm3-6b model with LoRA method. Users can also opt for other models and methods supported by LLAMA Factory, which consume less memory. The tool has specific hardware and software requirements, including Python, Torch, Transformers, Datasets, Accelerate, and other optional packages like CUDA and Deepspeed. The tool facilitates environment setup, data preparation, data preprocessing, model downloading, parameter configuration, model fine-tuning, and inference through a browser demo or API service. Additionally, it offers the ability to deploy a WeChat chatbot, although users should be cautious due to the risk of account suspension by WeChat.

LLM-TPU
LLM-TPU project aims to deploy various open-source generative AI models on the BM1684X chip, with a focus on LLM. Models are converted to bmodel using TPU-MLIR compiler and deployed to PCIe or SoC environments using C++ code. The project has deployed various open-source models such as Baichuan2-7B, ChatGLM3-6B, CodeFuse-7B, DeepSeek-6.7B, Falcon-40B, Phi-3-mini-4k, Qwen-7B, Qwen-14B, Qwen-72B, Qwen1.5-0.5B, Qwen1.5-1.8B, Llama2-7B, Llama2-13B, LWM-Text-Chat, Mistral-7B-Instruct, Stable Diffusion, Stable Diffusion XL, WizardCoder-15B, Yi-6B-chat, Yi-34B-chat. Detailed model deployment information can be found in the 'models' subdirectory of the project. For demonstrations, users can follow the 'Quick Start' section. For inquiries about the chip, users can contact SOPHGO via the official website.
video-subtitle-remover
Video-subtitle-remover (VSR) is a software based on AI technology that removes hard subtitles from videos. It achieves the following functions: - Lossless resolution: Remove hard subtitles from videos, generate files with subtitles removed - Fill the region of removed subtitles using a powerful AI algorithm model (non-adjacent pixel filling and mosaic removal) - Support custom subtitle positions, only remove subtitles in defined positions (input position) - Support automatic removal of all text in the entire video (no input position required) - Support batch removal of watermark text from multiple images.
md
The WeChat Markdown editor automatically renders Markdown documents as WeChat articles, eliminating the need to worry about WeChat content layout! As long as you know basic Markdown syntax (now with AI, you don't even need to know Markdown), you can create a simple and elegant WeChat article. The editor supports all basic Markdown syntax, mathematical formulas, rendering of Mermaid charts, GFM warning blocks, PlantUML rendering support, ruby annotation extension support, rich code block highlighting themes, custom theme colors and CSS styles, multiple image upload functionality with customizable configuration of image hosting services, convenient file import/export functionality, built-in local content management with automatic draft saving, integration of mainstream AI models (such as DeepSeek, OpenAI, Tongyi Qianwen, Tencent Hanyuan, Volcano Ark, etc.) to assist content creation.
Langchain-Chatchat
LangChain-Chatchat is an open-source, offline-deployable retrieval-enhanced generation (RAG) large model knowledge base project based on large language models such as ChatGLM and application frameworks such as Langchain. It aims to establish a knowledge base Q&A solution that is friendly to Chinese scenarios, supports open-source models, and can run offline.
HivisionIDPhotos
HivisionIDPhoto is a practical algorithm for intelligent ID photo creation. It utilizes a comprehensive model workflow to recognize, cut out, and generate ID photos for various user photo scenarios. The tool offers lightweight cutting, standard ID photo generation based on different size specifications, six-inch layout photo generation, beauty enhancement (waiting), and intelligent outfit swapping (waiting). It aims to solve emergency ID photo creation issues.
pi-browser
Pi-Browser is a CLI tool for automating browsers based on multiple AI models. It supports various AI models like Google Gemini, OpenAI, Anthropic Claude, and Ollama. Users can control the browser using natural language commands and perform tasks such as web UI management, Telegram bot integration, Notion integration, extension mode for maintaining Chrome login status, parallel processing with multiple browsers, and offline execution with the local AI model Ollama.
llmio
LLMIO is a Go-based LLM load balancing gateway that provides a unified REST API, weight scheduling, logging, and modern management interface for your LLM clients. It helps integrate different model capabilities from OpenAI, Anthropic, Gemini, and more in a single service. Features include unified API compatibility, weight scheduling with two strategies, visual management dashboard, rate and failure handling, and local persistence with SQLite. The tool supports multiple vendors' APIs and authentication methods, making it versatile for various AI model integrations.
Lim-Code
LimCode is a powerful VS Code AI programming assistant that supports multiple AI models, intelligent tool invocation, and modular architecture. It features support for various AI channels, a smart tool system for code manipulation, MCP protocol support for external tool extension, intelligent context management, session management, and more. Users can install LimCode from the plugin store or via VSIX, or build it from the source code. The tool offers a rich set of features for AI programming and code manipulation within the VS Code environment.
jimeng-free-api-all
Jimeng AI Free API is a reverse-engineered API server that encapsulates Jimeng AI's image and video generation capabilities into OpenAI-compatible API interfaces. It supports the latest jimeng-5.0-preview, jimeng-4.6 text-to-image models, Seedance 2.0 multi-image intelligent video generation, zero-configuration deployment, and multi-token support. The API is fully compatible with OpenAI API format, seamlessly integrating with existing clients and supporting multiple session IDs for polling usage.
LunaBox
LunaBox is a lightweight, fast, and feature-rich tool for managing and tracking visual novels, with the ability to customize game categories, automatically track playtime, generate personalized reports through AI analysis, import data from other platforms, backup data locally or on cloud services, and ensure privacy and security by storing sensitive data locally. The tool supports multi-dimensional statistics, offers a variety of customization options, and provides a user-friendly interface for easy navigation and usage.

Qwen-TensorRT-LLM
Qwen-TensorRT-LLM is a project developed for the NVIDIA TensorRT Hackathon 2023, focusing on accelerating inference for the Qwen-7B-Chat model using TRT-LLM. The project offers various functionalities such as FP16/BF16 support, INT8 and INT4 quantization options, Tensor Parallel for multi-GPU parallelism, web demo setup with gradio, Triton API deployment for maximum throughput/concurrency, fastapi integration for openai requests, CLI interaction, and langchain support. It supports models like qwen2, qwen, and qwen-vl for both base and chat models. The project also provides tutorials on Bilibili and blogs for adapting Qwen models in NVIDIA TensorRT-LLM, along with hardware requirements and quick start guides for different model types and quantization methods.

Chinese-Mixtral-8x7B
Chinese-Mixtral-8x7B is an open-source project based on Mistral's Mixtral-8x7B model for incremental pre-training of Chinese vocabulary, aiming to advance research on MoE models in the Chinese natural language processing community. The expanded vocabulary significantly improves the model's encoding and decoding efficiency for Chinese, and the model is pre-trained incrementally on a large-scale open-source corpus, enabling it with powerful Chinese generation and comprehension capabilities. The project includes a large model with expanded Chinese vocabulary and incremental pre-training code.
ai-daily-digest
AI Daily Digest is a tool that fetches the latest articles from the top 90 Hacker News technology blogs recommended by Andrej Karpathy. It uses AI multi-dimensional scoring to curate a structured daily digest. The tool supports Gemini by default and can automatically degrade to OpenAI compatible API. It offers a five-step processing pipeline including RSS fetching, time filtering, AI scoring and classification, AI summarization and translation, and trend summarization. The generated daily digest includes sections like today's highlights, must-read articles, data overview, and categorized article lists. The tool is designed to be dependency-free, bilingual, with structured summaries, visual statistics, intelligent categorization, trend insights, and persistent configuration memory.
For similar tasks
VideoCaptioner
VideoCaptioner is a video subtitle processing assistant based on a large language model (LLM), supporting speech recognition, subtitle segmentation, optimization, translation, and full-process handling. It is user-friendly and does not require high configuration, supporting both network calls and local offline (GPU-enabled) speech recognition. It utilizes a large language model for intelligent subtitle segmentation, correction, and translation, providing stunning subtitles for videos. The tool offers features such as accurate subtitle generation without GPU, intelligent segmentation and sentence splitting based on LLM, AI subtitle optimization and translation, batch video subtitle synthesis, intuitive subtitle editing interface with real-time preview and quick editing, and low model token consumption with built-in basic LLM model for easy use.

TeroSubtitler
Tero Subtitler is an open source, cross-platform, and free subtitle editing software with a user-friendly interface. It offers fully fledged editing with SMPTE and MEDIA modes, support for various subtitle formats, multi-level undo/redo, search and replace, auto-backup, source and transcription modes, translation memory, audiovisual preview, timeline with waveform visualizer, manipulation tools, formatting options, quality control features, translation and transcription capabilities, validation tools, automation for correcting errors, and more. It also includes features like exporting subtitles to MP3, importing/exporting Blu-ray SUP format, generating blank video, generating video with hardcoded subtitles, video dubbing, and more. The tool utilizes powerful multimedia playback engines like mpv, advanced audio/video manipulation tools like FFmpeg, tools for automatic transcription like whisper.cpp/Faster-Whisper, auto-translation API like Google Translate, and ElevenLabs TTS for video dubbing.
subtitler
Subtitles by fframes is a free, local, on-device AI video transcription tool with a user-friendly GUI. It allows users to transcribe video content, edit transcribed cues, style the subtitles, and render them directly onto the video. The tool provides a convenient way to create accurate subtitles for videos without the need for an internet connection.
oneclick-subtitles-generator
A comprehensive web application for auto-subtitling videos and audio, translating SRT files, generating AI narration with voice cloning, creating background images, and rendering professional subtitled videos. Designed for content creators, educators, and general users who need high-quality subtitle generation and video production capabilities.
subtitle-translator-electron
Subtitle Translator is a tool that utilizes ChatGPT to translate subtitles in various formats such as .ass, .srt, .ssa, and .vtt. It supports multiple languages and provides translations based on context from preceding and following sentences. Users can download the stable version from the Releases page and contribute through pull requests. The tool aims to simplify the process of translating subtitles for different media content.

gpt-subtrans
GPT-Subtrans is an open-source subtitle translator that utilizes large language models (LLMs) as translation services. It supports translation between any language pairs that the language model supports. Note that GPT-Subtrans requires an active internet connection, as subtitles are sent to the provider's servers for translation, and their privacy policy applies.
chatgpt-subtitle-translator
This tool utilizes the OpenAI ChatGPT API to translate text, with a focus on line-based translation, particularly for SRT subtitles. It optimizes token usage by removing SRT overhead and grouping text into batches, allowing for arbitrary length translations without excessive token consumption while maintaining a one-to-one match between line input and output.
AiNiee
AiNiee is a tool focused on AI translation, capable of automatically translating RPG SLG games, Epub TXT novels, Srt Lrc subtitles, and more. It provides features for configuring AI platforms, proxies, and translation settings. Users can utilize this tool for translating game scripts, novels, and subtitles efficiently. The tool supports multiple AI platforms and offers tutorials for beginners. It also includes functionalities for extracting and translating game text, with options for customizing translation projects and managing translation tasks effectively.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.