
chatWeb
ChatWeb can crawl web pages, read PDF, DOCX, TXT, and extract the main content, then answer your questions based on the content, or summarize the key points.
Stars: 867
ChatWeb is a tool that can crawl web pages, extract text from PDF, DOCX, TXT files, and generate an embedded summary. It can answer questions based on text content using chatAPI and embeddingAPI based on GPT3.5. The tool calculates similarity scores between text vectors to generate summaries, performs nearest neighbor searches, and designs prompts to answer user questions. It aims to extract relevant content from text and provide accurate search results based on keywords. ChatWeb supports various modes, languages, and settings, including temperature control and PostgreSQL integration.
README:
ChatWeb can crawl any webpage or extract text from PDF, DOCX, TXT files, and generate an embedded summary. It can also answer your questions based on the content of the text. It is implemented using the chatAPI and embeddingAPI based on gpt3.5, as well as a vector database.
The basic principle is similar to existing projects such as chatPDF and automated customer service AI.
Crawl web pages Extract text content Use GPT3.5's embedding API to generate vectors for each paragraph Calculate the similarity score between each paragraph's vector and the entire text's vector to generate a summary Store the vector-text mapping in a vector database Generate keywords from user input Generate a vector from the keywords Use the vector database to perform a nearest neighbor search and return a list of the most similar texts Use GPT3.5's chat API to design a prompt that answers the user's question based on the most similar texts in the list. The idea is to extract relevant content from a large amount of text and then answer questions based on that content, which can achieve a similar effect to breaking through token limits.
An improvement was made to generate vectors based on keywords rather than the user's question, which increases the accuracy of searching for relevant texts.
- Install Python3
- Download this repository by running
git clone https://github.com/SkywalkerDarren/chatWeb.git - Navigate to the directory by running
cd chatWeb - Copy
config.example.jsontoconfig.json - Edit
config.jsonand setopen_ai_keyto your OpenAI API key - Install dependencies by running
pip3 install -r requirements.txt - Start the application by running
python3 main.py
if you prefer, you can also run this project using docker:
- build the container using
docker-compose build(only needed once when you are not planning to contibute to this repo) - copy
config.example.jsontoconfig.jsonand set all the needed stuff. The example config is already fine for running with docker, no need to change anything there, if you don't have the OPEN_AI_KEY in your env variables you can set it here too, or later if you run this app. - run the container: `docker-compose up"
- open the application in browser:
http://localhost:7860
- Edit
config.json, setlanguagetoEnglishor other language
- Edit
config.jsonand setmodetoconsole,api, orwebuito choose the startup mode. - In
consolemode, type/helpto view commands. - In
apimode, an API service can be provided to the outside world.api_portandapi_hostcan be set inconfig.json. - In
webuimode, a web user interface service can be provided.webui_portcan be set inconfig.json, defaulting tohttp://127.0.0.1:7860.
- Edit
config.jsonand setuse_streamtotrue.
- Edit
config.jsonand settemperatureto a value between 0 and 1. - The smaller the value, the more conservative and stable the response will be. The larger the value, the more daring the response may be, possibly resulting in "hallucinations."
- Edit
config.jsonand addopen_ai_proxyfor your proxy address, for example:
"open_ai_proxy": {
"http": "socks5://127.0.0.1:1081",
"https": "socks5://127.0.0.1:1081"
}
- Edit
config.jsonand setuse_postgrestotrue. - Install PostgreSQL.
- The default SQL address is
postgresql://localhost:5432/mydb, or you can set it inconfig.json.
- The default SQL address is
- Install the pgvector plugin.
Compile and install the extension (support Postgres 11+).
git clone --branch v0.4.0 https://github.com/pgvector/pgvector.git
cd pgvector
make
make install # may need sudoThen load it in the database you want to use it in
CREATE EXTENSION vector;
- Install dependency with pip:
pip3 install psycopg2
Please enter the link to the article or the file path of the PDF/TXT/DOCX document: https://gutenberg.ca/ebooks/hemingwaye-oldmanandthesea/hemingwaye-oldmanandthesea-00-e.html
Please wait for 10 seconds until the webpage finishes loading.
The article has been retrieved, and the number of text fragments is: 663
...
=====================================
Query fragments used tokens: 7219, cost: $0.0028876
Query fragments used tokens: 7250, cost: $0.0029000000000000002
Query fragments used tokens: 7188, cost: $0.0028752
Query fragments used tokens: 7177, cost: $0.0028708
Query fragments used tokens: 2378, cost: $0.0009512000000000001
Embeddings have been created with 663 embeddings, using 31212 tokens, costing $0.0124848
The embeddings have been saved.
=====================================
Please enter your query (/help to view commands):- [x] Support for pdf/txt/docx files
- [x] Support for in-memory storage without a database (faiss)
- [x] Support for Stream
- [x] Support for API
- [x] Support for proxies
- [x] Add Colab support
- [x] Add language support
- [x] Support for temperature
- [x] Support for webui
- [ ] Other features that have not been thought of yet
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for chatWeb
Similar Open Source Tools
chatWeb
ChatWeb is a tool that can crawl web pages, extract text from PDF, DOCX, TXT files, and generate an embedded summary. It can answer questions based on text content using chatAPI and embeddingAPI based on GPT3.5. The tool calculates similarity scores between text vectors to generate summaries, performs nearest neighbor searches, and designs prompts to answer user questions. It aims to extract relevant content from text and provide accurate search results based on keywords. ChatWeb supports various modes, languages, and settings, including temperature control and PostgreSQL integration.

blinkid-android
The BlinkID Android SDK is a comprehensive solution for implementing secure document scanning and extraction. It offers powerful capabilities for extracting data from a wide range of identification documents. The SDK provides features for integrating document scanning into Android apps, including camera requirements, SDK resource pre-bundling, customizing the UX, changing default strings and localization, troubleshooting integration difficulties, and using the SDK through various methods. It also offers options for completely custom UX with low-level API integration. The SDK size is optimized for different processor architectures, and API documentation is available for reference. For any questions or support, users can contact the Microblink team at help.microblink.com.

parsera
Parsera is a lightweight Python library designed for scraping websites using LLMs. It offers simplicity and efficiency by minimizing token usage, enhancing speed, and reducing costs. Users can easily set up and run the tool to extract specific elements from web pages, generating JSON output with relevant data. Additionally, Parsera supports integration with various chat models, such as Azure, expanding its functionality and customization options for web scraping tasks.
fish-ai
fish-ai is a tool that adds AI functionality to Fish shell. It can be integrated with various AI providers like OpenAI, Azure OpenAI, Google, Hugging Face, Mistral, or a self-hosted LLM. Users can transform comments into commands, autocomplete commands, and suggest fixes. The tool allows customization through configuration files and supports switching between contexts. Data privacy is maintained by redacting sensitive information before submission to the AI models. Development features include debug logging, testing, and creating releases.

paxml
Pax is a framework to configure and run machine learning experiments on top of Jax.
nextjs-openai-doc-search
This starter project is designed to process `.mdx` files in the `pages` directory to use as custom context within OpenAI Text Completion prompts. It involves building a custom ChatGPT style doc search powered by Next.js, OpenAI, and Supabase. The project includes steps for pre-processing knowledge base, storing embeddings in Postgres, performing vector similarity search, and injecting content into OpenAI GPT-3 text completion prompt.
SirChatalot
A Telegram bot that proves you don't need a body to have a personality. It can use various text and image generation APIs to generate responses to user messages. For text generation, the bot can use: * OpenAI's ChatGPT API (or other compatible API). Vision capabilities can be used with GPT-4 models. Function calling can be used with Function calling. * Anthropic's Claude API. Vision capabilities can be used with Claude 3 models. Function calling can be used with tool use. * YandexGPT API Bot can also generate images with: * OpenAI's DALL-E * Stability AI * Yandex ART This bot can also be used to generate responses to voice messages. Bot will convert the voice message to text and will then generate a response. Speech recognition can be done using the OpenAI's Whisper model. To use this feature, you need to install the ffmpeg library. This bot is also support working with files, see Files section for more details. If function calling is enabled, bot can generate images and search the web (limited).
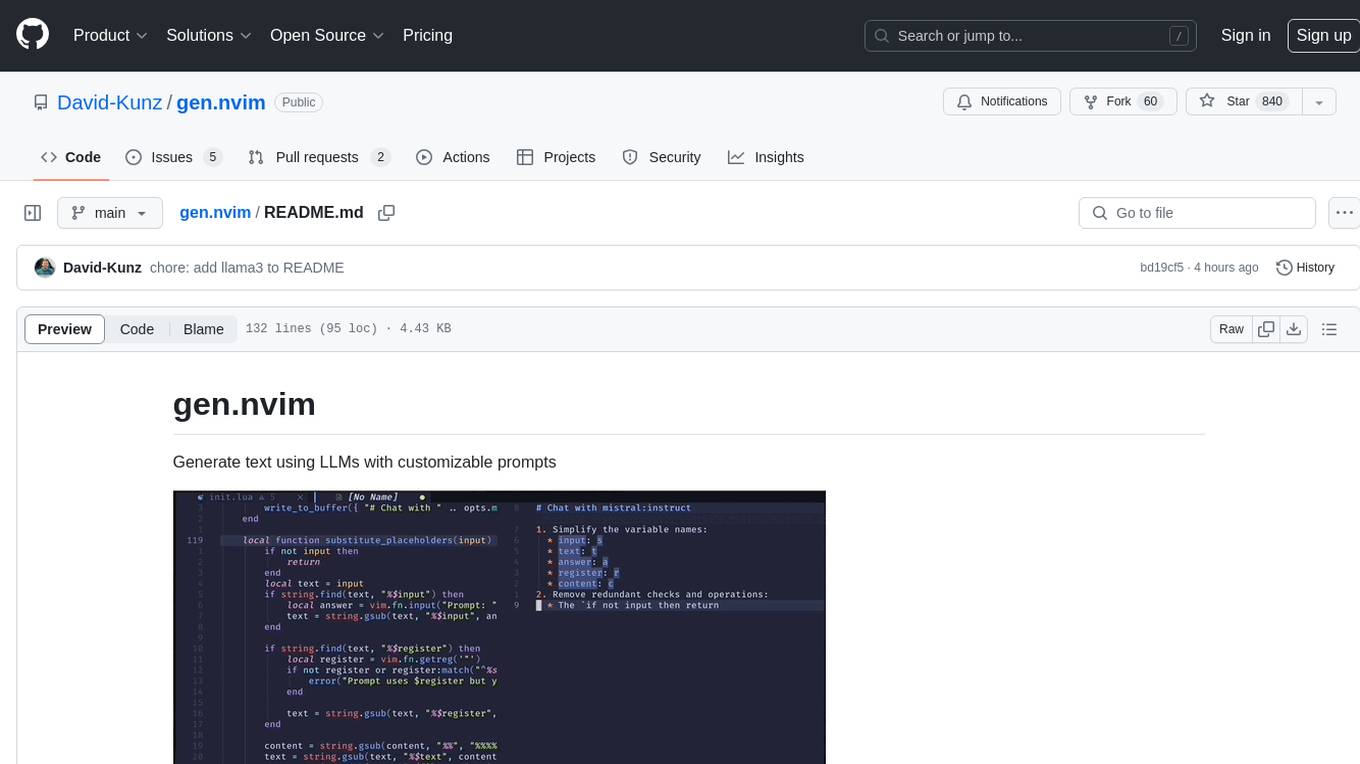
gen.nvim
gen.nvim is a tool that allows users to generate text using Language Models (LLMs) with customizable prompts. It requires Ollama with models like `llama3`, `mistral`, or `zephyr`, along with Curl for installation. Users can use the `Gen` command to generate text based on predefined or custom prompts. The tool provides key maps for easy invocation and allows for follow-up questions during conversations. Additionally, users can select a model from a list of installed models and customize prompts as needed.

ai2-scholarqa-lib
Ai2 Scholar QA is a system for answering scientific queries and literature review by gathering evidence from multiple documents across a corpus and synthesizing an organized report with evidence for each claim. It consists of a retrieval component and a three-step generator pipeline. The retrieval component fetches relevant evidence passages using the Semantic Scholar public API and reranks them. The generator pipeline includes quote extraction, planning and clustering, and summary generation. The system is powered by the ScholarQA class, which includes components like PaperFinder and MultiStepQAPipeline. It requires environment variables for Semantic Scholar API and LLMs, and can be run as local docker containers or embedded into another application as a Python package.
codespin
CodeSpin.AI is a set of open-source code generation tools that leverage large language models (LLMs) to automate coding tasks. With CodeSpin, you can generate code in various programming languages, including Python, JavaScript, Java, and C++, by providing natural language prompts. CodeSpin offers a range of features to enhance code generation, such as custom templates, inline prompting, and the ability to use ChatGPT as an alternative to API keys. Additionally, CodeSpin provides options for regenerating code, executing code in prompt files, and piping data into the LLM for processing. By utilizing CodeSpin, developers can save time and effort in coding tasks, improve code quality, and explore new possibilities in code generation.
gpt-cli
gpt-cli is a command-line interface tool for interacting with various chat language models like ChatGPT, Claude, and others. It supports model customization, usage tracking, keyboard shortcuts, multi-line input, markdown support, predefined messages, and multiple assistants. Users can easily switch between different assistants, define custom assistants, and configure model parameters and API keys in a YAML file for easy customization and management.
laragenie
Laragenie is an AI chatbot designed to understand and assist developers with their codebases. It runs on the command line from a Laravel app, helping developers onboard to new projects, understand codebases, and provide daily support. Laragenie accelerates workflow and collaboration by indexing files and directories, allowing users to ask questions and receive AI-generated responses. It supports OpenAI and Pinecone for processing and indexing data, making it a versatile tool for any repo in any language.

vectorflow
VectorFlow is an open source, high throughput, fault tolerant vector embedding pipeline. It provides a simple API endpoint for ingesting large volumes of raw data, processing, and storing or returning the vectors quickly and reliably. The tool supports text-based files like TXT, PDF, HTML, and DOCX, and can be run locally with Kubernetes in production. VectorFlow offers functionalities like embedding documents, running chunking schemas, custom chunking, and integrating with vector databases like Pinecone, Qdrant, and Weaviate. It enforces a standardized schema for uploading data to a vector store and supports features like raw embeddings webhook, chunk validation webhook, S3 endpoint, and telemetry. The tool can be used with the Python client and provides detailed instructions for running and testing the functionalities.
aire
Aire is a modern Laravel form builder with a focus on expressive and beautiful code. It allows easy configuration of form components using fluent method calls or Blade components. Aire supports customization through config files and custom views, data binding with Eloquent models or arrays, method spoofing, CSRF token injection, server-side and client-side validation, and translations. It is designed to run on Laravel 5.8.28 and higher, with support for PHP 7.1 and higher. Aire is actively maintained and under consideration for additional features like read-only plain text, cross-browser support for custom checkboxes and radio buttons, support for Choices.js or similar libraries, improved file input handling, and better support for content prepending or appending to inputs.
AirspeedVelocity.jl
AirspeedVelocity.jl is a tool designed to simplify benchmarking of Julia packages over their lifetime. It provides a CLI to generate benchmarks, compare commits/tags/branches, plot benchmarks, and run benchmark comparisons for every submitted PR as a GitHub action. The tool freezes the benchmark script at a specific revision to prevent old history from affecting benchmarks. Users can configure options using CLI flags and visualize benchmark results. AirspeedVelocity.jl can be used to benchmark any Julia package and offers features like generating tables and plots of benchmark results. It also supports custom benchmarks and can be integrated into GitHub actions for automated benchmarking of PRs.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

book
Podwise is an AI knowledge management app designed specifically for podcast listeners. With the Podwise platform, you only need to follow your favorite podcasts, such as "Hardcore Hackers". When a program is released, Podwise will use AI to transcribe, extract, summarize, and analyze the podcast content, helping you to break down the hard-core podcast knowledge. At the same time, it is connected to platforms such as Notion, Obsidian, Logseq, and Readwise, embedded in your knowledge management workflow, and integrated with content from other channels including news, newsletters, and blogs, helping you to improve your second brain 🧠.

extractor
Extractor is an AI-powered data extraction library for Laravel that leverages OpenAI's capabilities to effortlessly extract structured data from various sources, including images, PDFs, and emails. It features a convenient wrapper around OpenAI Chat and Completion endpoints, supports multiple input formats, includes a flexible Field Extractor for arbitrary data extraction, and integrates with Textract for OCR functionality. Extractor utilizes JSON Mode from the latest GPT-3.5 and GPT-4 models, providing accurate and efficient data extraction.

Scrapegraph-ai
ScrapeGraphAI is a Python library that uses Large Language Models (LLMs) and direct graph logic to create web scraping pipelines for websites, documents, and XML files. It allows users to extract specific information from web pages by providing a prompt describing the desired data. ScrapeGraphAI supports various LLMs, including Ollama, OpenAI, Gemini, and Docker, enabling users to choose the most suitable model for their needs. The library provides a user-friendly interface through its `SmartScraper` class, which simplifies the process of building and executing scraping pipelines. ScrapeGraphAI is open-source and available on GitHub, with extensive documentation and examples to guide users. It is particularly useful for researchers and data scientists who need to extract structured data from web pages for analysis and exploration.

databerry
Chaindesk is a no-code platform that allows users to easily set up a semantic search system for personal data without technical knowledge. It supports loading data from various sources such as raw text, web pages, files (Word, Excel, PowerPoint, PDF, Markdown, Plain Text), and upcoming support for web sites, Notion, and Airtable. The platform offers a user-friendly interface for managing datastores, querying data via a secure API endpoint, and auto-generating ChatGPT Plugins for each datastore. Chaindesk utilizes a Vector Database (Qdrant), Openai's text-embedding-ada-002 for embeddings, and has a chunk size of 1024 tokens. The technology stack includes Next.js, Joy UI, LangchainJS, PostgreSQL, Prisma, and Qdrant, inspired by the ChatGPT Retrieval Plugin.

auto-news
Auto-News is an automatic news aggregator tool that utilizes Large Language Models (LLM) to pull information from various sources such as Tweets, RSS feeds, YouTube videos, web articles, Reddit, and journal notes. The tool aims to help users efficiently read and filter content based on personal interests, providing a unified reading experience and organizing information effectively. It features feed aggregation with summarization, transcript generation for videos and articles, noise reduction, task organization, and deep dive topic exploration. The tool supports multiple LLM backends, offers weekly top-k aggregations, and can be deployed on Linux/MacOS using docker-compose or Kubernetes.

SemanticFinder
SemanticFinder is a frontend-only live semantic search tool that calculates embeddings and cosine similarity client-side using transformers.js and SOTA embedding models from Huggingface. It allows users to search through large texts like books with pre-indexed examples, customize search parameters, and offers data privacy by keeping input text in the browser. The tool can be used for basic search tasks, analyzing texts for recurring themes, and has potential integrations with various applications like wikis, chat apps, and personal history search. It also provides options for building browser extensions and future ideas for further enhancements and integrations.

1filellm
1filellm is a command-line data aggregation tool designed for LLM ingestion. It aggregates and preprocesses data from various sources into a single text file, facilitating the creation of information-dense prompts for large language models. The tool supports automatic source type detection, handling of multiple file formats, web crawling functionality, integration with Sci-Hub for research paper downloads, text preprocessing, and token count reporting. Users can input local files, directories, GitHub repositories, pull requests, issues, ArXiv papers, YouTube transcripts, web pages, Sci-Hub papers via DOI or PMID. The tool provides uncompressed and compressed text outputs, with the uncompressed text automatically copied to the clipboard for easy pasting into LLMs.

Agently-Daily-News-Collector
Agently Daily News Collector is an open-source project showcasing a workflow powered by the Agent ly AI application development framework. It allows users to generate news collections on various topics by inputting the field topic. The AI agents automatically perform the necessary tasks to generate a high-quality news collection saved in a markdown file. Users can edit settings in the YAML file, install Python and required packages, input their topic idea, and wait for the news collection to be generated. The process involves tasks like outlining, searching, summarizing, and preparing column data. The project dependencies include Agently AI Development Framework, duckduckgo-search, BeautifulSoup4, and PyYAM.